Esse ano eu consegui montar uma retrospectiva logo no ínicio do ano.
Infelizmente foi um final de ano difícil pra mim com a morte do nosso gato de estimação bem no final do ano. Mas... a vida segue.
Eu tinha colocado uma meta de escrever semanalmente aqui no site. Não cheguei a alcançar a meta semanal mas definitivamente escrevi muito mais que nos anos anteriores. É sempre bom adicionar conteúdo.
Montando o vídeo de retrospectiva eu percebi o quão pouco tirei fotos ou fiz vídeos durante 2021. Não sei bem explicar o motivo, mas eu mesmo não lá muito de fazer selfies. E mesmo minha conta no Instagram é mais pra postar fotos em uso a câmera e dou um tratamento melhor que as imagens feitas pelo telefone.
Eu não coloquei uma meta pra participar de eventos com palestras, mas acabei até que fazendo bastante. Foram 4 palestras em 3 eventos:
E ainda fui parte da organização da PyCon Suécia. Não fiz nenhuma palestra lá, mas organizar o evento tomou bastante meu tempo e dedicação. Apareceu uma foto minha nos créditos finais, o que já é suficiente.
Não bastasse isso ainda fui organizador da hackathon global de outono na empresa. Em geral temos 2 por ano. E como é algo interno, eu não fiz muita propaganda fora da empresa. Mas foi mais uma coisa pra eu ter de trabalhar.
Eu acho que desse lado pessoal foi um ano muito bom. Espero conseguir fazer as mesmas coisas agora em 2022. Um pouco menos dessa vez porque quase tudo caiu junto entre meados de outubro e meados de novembro. Inclusive escrevi até um artigo pra REL (Revista Espírito Livre) que não foi publicado. Eu provavelmente vou publicar aqui em algum momento.
Agora vamos às estatísticas do site. Pra começar uma bela surpresa que só vejo quando faço essa restrospectiva:
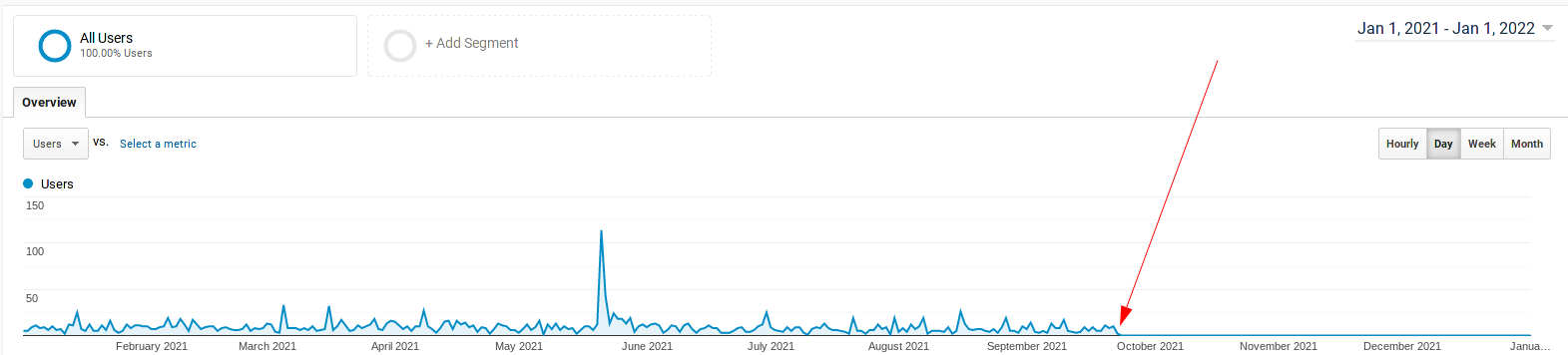
Eu fiz alguma besteira no site e o Google analytic parou de funcionar no início de outubro. E não tenho ideia do que possa ter sido. Mas quando acabar de escrever aqui eu já vou dar uma olhada. Sendo estatísticas, vamos chutar que é uma amostra grande o suficiente pra estimar o restante em termos de porcentagens.
Em relação aos navegadores que mais acessaram:
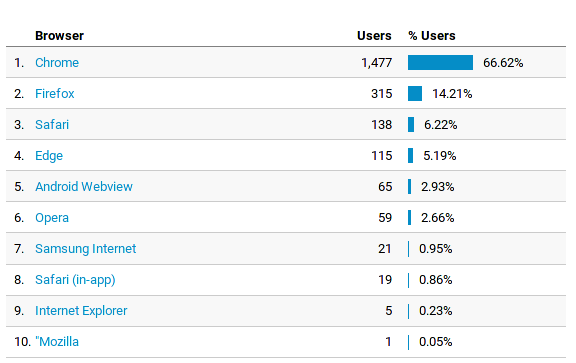
Chrome já na frente de longe com Firefox em segundo. Eu fiquei feliz de ver o Firefox ainda relevante por aqui.
E relação aos países que mais acessaram:
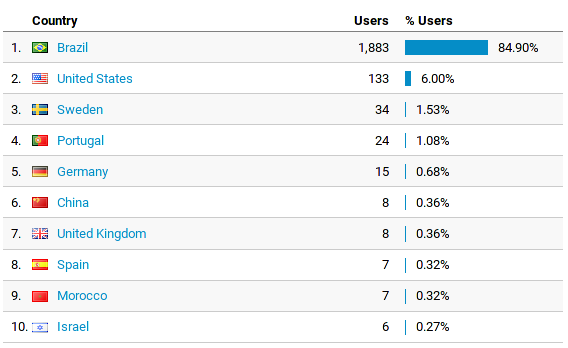
Posso assumir que os 1.34% de acesso a partir da Suécia seja eu mesmo.
Em relação aos sistemas operacionais de computadores (porque tem uma categoria separada para mobile):
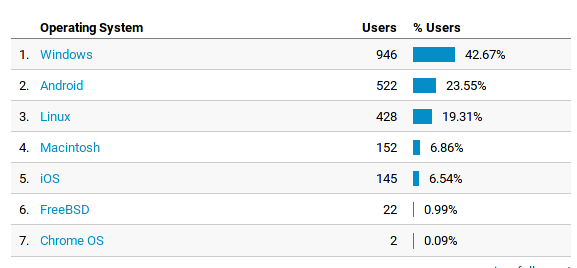
Novamente Windows em primeirão. Acho que pela primeira vez abaixo dos 50%, com android e Linux chegando à uns 42%, que já deixa equilibrado em Linux em Windows. Não me perguntem o porquê do Analytics mostrar separado.
E finalmente os sistemas operacionais mobile:
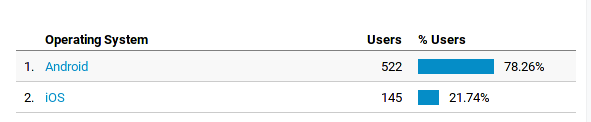
Quase mesma estatísticas mundial de 85% de equipamentos Android (telefones e tablets). Não muita surpresa aqui. E nada de Windows phone felizmente. Pelo menos na área mobile o povo aprendeu.
E esse foi o resumo do meu 2021. Vou tentar manter o ritmo de 1 artigo ou mais por semana esse ano também. Afinal escrever tem de ser uma rotina ou do contrário as redes sociais roubam todo o meu tempo livre.
Feliz 2022!

No artigo a era do Arch Linux eu esqueci de comentar, mas segue aqui a menção honrosa ao cartão pendrive da FSF que funcionou maravilhosamente pra instalar o Arch. Uma pena que eles não mencionem o suporte ao Arch, assim como não o fazem pro Debian, em usa página de Free distros. O Arch não instala nada pra você. Nem sugere. Mas já faz anos que a FSF adotou uma postura anti-liberdade, onde o bloqueio de uso de firmwares têm de ser forçado goela abaixo do usuário pra ser aprovada. Espero que isso mude em 2022 na FSF.
![]()
Já faz um certo tempo que venho acompanhando o Archlinux de perto. Já tinha uma VM rodando pra testes. Mas com a decisão da Steam de lançar o device de games steam deck baseado no Arch, eu realmente fiquei tentado a experimentar mais a fundo, como meu sistema principal no desktop.
Antes de mais nada vou deixar claro que como desktop eu não tenho somente um computador. Tenho um gabinete desktop mesmo, que já descrevi anos atrás no artigo goosfraba, e tenho também o laptop de trabalho. Eu geralmente passo mais tempo no laptop, que roda Ubuntu. O meu desktop estava também com Ubuntu, mas rodando o 21.10. E não tinha reclamações a respeito. Mas faz um tempo que desejo sair do mundo Debian/Ubuntu por vários motivos. De comunidade a questão de forma de participação.
Então aproveitando as férias que peguei nesse fim de ano, resolvi partir pra cima da instalação do Arch. Peço antecipadamente desculpas por ser muita coisa em imagens, mas eu fiz registros dos passos e dificuldades de instalação atráves de imagens em posts no Twitter pra justamente descrever aqui.
Como o computador já roda Ubuntu com LVM, não precisei fazer muita coisa além de criar mais partições que seriam próprias do Arch. Então simplesmente as criei assim:
lvcreate diskspace -L 10G -n archlinux-root
lvcreate diskspace -L 50G -n archlinux-usr
lvcreate diskspace -L 10G -n archlinux-var
E em teoria isso deveria ser o suficiente. Parti pra instalação e o primeiro problema foi encontrar o pendrive pra dar boot na instalação do Arch. Eu tinha criado o pendrive com o comando dd mas eu resolvi seguir à risca a instalação do Arch e refiz o pendrive novamente.

Não que tivesse mudado muita coisa. Eu precisei mexer nos parâmetros de boot da BIOS pra aceitar o pendrive. Depois de algumas configurações extras que mais foram mais próximas ao vodoo, eis que consegui o tão almejado boot.
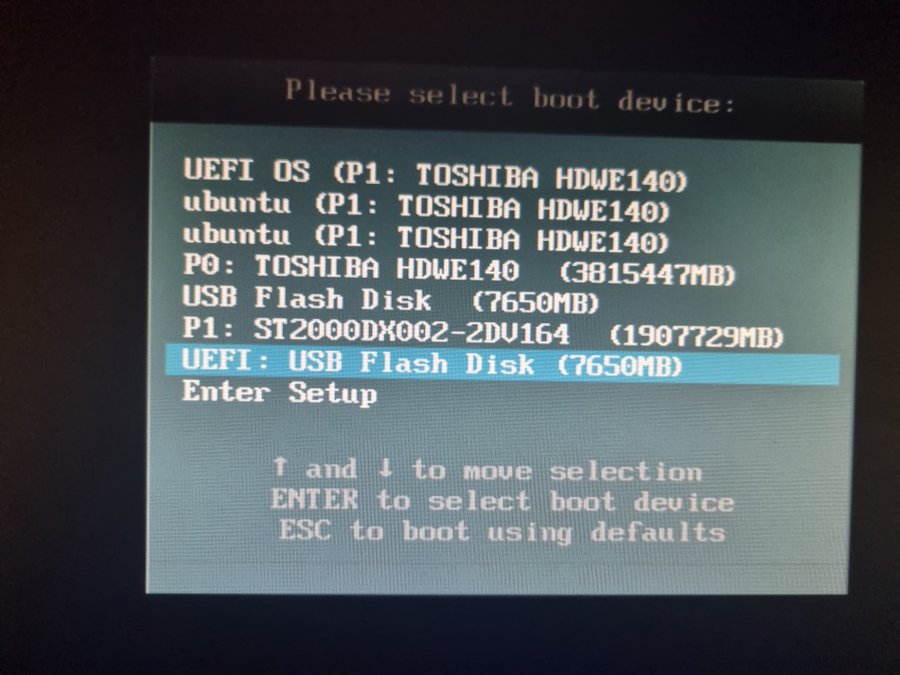
O boot do Arch foi um passeio no parque. Como ele não faz nada automático e você faz tudo manualmente bastou apenas formatar e montar as partições que eu já tinha criado pra seguir com a instalação.
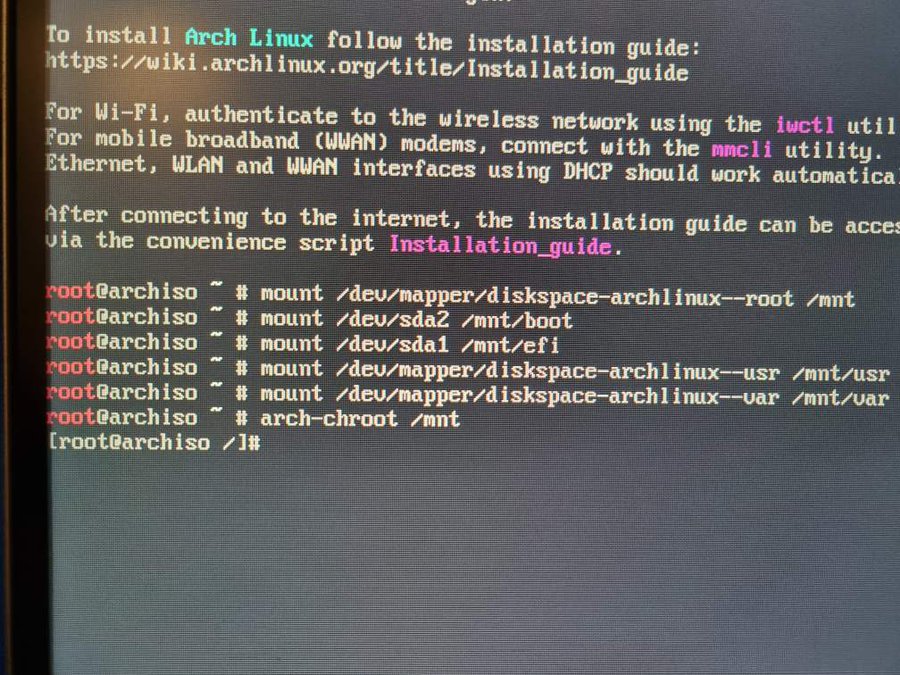
Nos passos de instalação do grub e meio que empaquei. Eu já tinha o grub instalado na partição UEFI e funcionando no Ubuntu. Seria o caso de apenas adicionar uma nova entrada no grub.cfg? E foi
menuentry 'Arch Linux' --class archlinux --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-16a93a2f-e4a6-4ab3-8eee-b33403509ed4' {
recordfail
load_video
gfxmode $linux_gfx_mode
insmod gzio
if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi
insmod part_gpt
insmod ext2
set root='hd0,gpt2'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,gpt2 --hint-efi=hd0,gpt2 --hint-baremetal=ahci0,gpt2 --hint='hd0,gpt2' bfc3c17e-d451-4c35-8c4a-f93b17436783
else
search --no-floppy --fs-uuid --set=root bfc3c17e-d451-4c35-8c4a-f93b17436783
fi
linux /vmlinuz-linux root=/dev/mapper/diskspace-archlinux--root init=/usr/lib/systemd/systemd ro net.ifnames=0 biosdevname=0 iommu=pt showopts noquiet nosplash verbose
initrd /initramfs-linux.img
}Com isso eu consegui deixar a opção de boot do Arch disponível. Existe aí um pequeno problema, o tal elefante na sala: o que acontece quando o Ubuntu atualizar. Eventualmente eu devo dar boot no Ubuntu e rodar algum upgrade de kernel. Ao rodar o mkinitram, com certeza vai sobreescrever essa entrada. Ainda não resolvi esse problema, mas por enquanto sigo usando somente Arch.
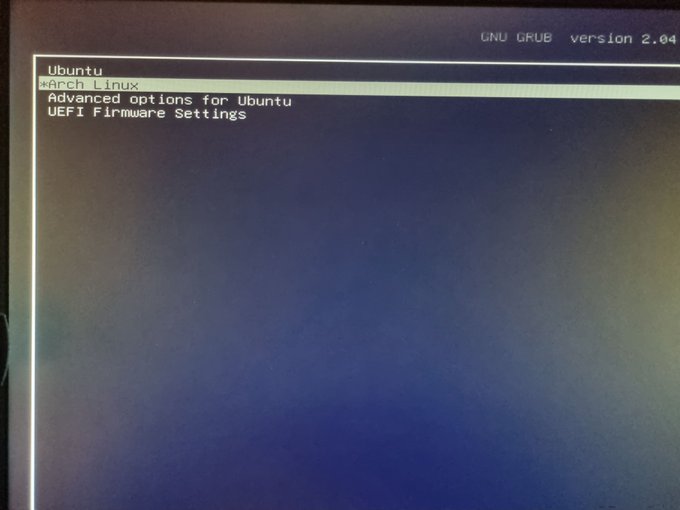
Então a coisa foi mesmo fácil e bastou apenas apertar o <Enter>...
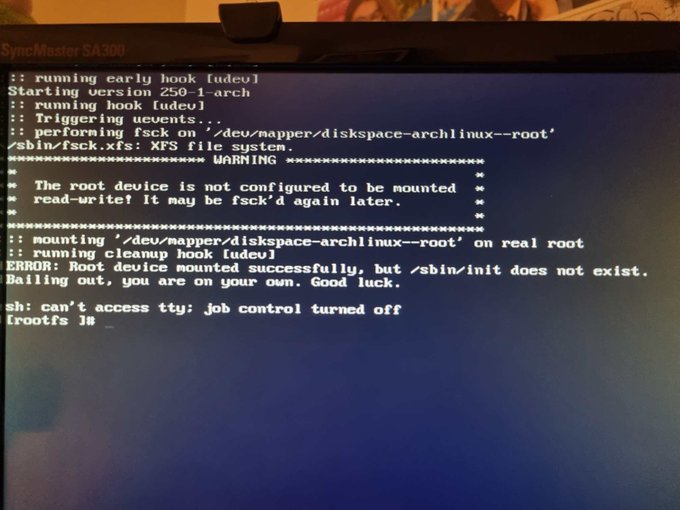
O que deu errado? E aqui eu comecei a entender um pouco mais do Arch além da superfície. E essa era meu objetivo desde o início. Pra entender o problema é preciso olhar como são os diretórios dentro do Arch primeiro.
root@goosfraba /u/bin# ls -l /
total 28
lrwxrwxrwx 1 root root 7 Dec 7 03:41 bin -> usr/bin
drwxr-xr-x 5 root root 4096 Dec 27 21:51 boot
drwxr-xr-x 23 root root 4600 Dec 29 00:12 dev
drwxr-xr-x 3 root root 4096 Jan 1 1970 efi
drwxr-xr-x 90 root root 8192 Dec 29 13:48 etc
drwxr-xr-x 35 root root 4096 Jun 9 2020 home
lrwxrwxrwx 1 root root 7 Dec 7 03:41 lib -> usr/lib
lrwxrwxrwx 1 root root 7 Dec 7 03:41 lib64 -> usr/lib
drwxr-xr-x 2 root root 6 Dec 7 03:41 mnt
drwxr-xr-x 11 root root 154 Dec 29 13:48 opt
dr-xr-xr-x 437 root root 0 Dec 27 21:59 proc
drwxr-x--- 14 root root 239 Dec 29 13:27 root
drwxr-xr-x 26 root root 740 Dec 29 00:45 run
lrwxrwxrwx 1 root root 7 Dec 7 03:41 sbin -> usr/bin
drwxr-xr-x 4 root root 29 Dec 27 21:17 srv
dr-xr-xr-x 13 root root 0 Dec 27 21:59 sys
drwxrwxrwt 24 root root 4096 Dec 29 13:48 tmp
drwxr-xr-x 23 root root 332 Jun 19 2018 ubuntu
drwxr-xr-x 9 root root 118 Dec 29 13:48 usr
drwxr-xr-x 14 root root 201 Dec 29 12:58 var
O Arch não tem /bin, /sbin, /lib e /lib64. Ele joga todos os executáveis em /usr/bin e todas as libs em /usr/lib. Isso talvez facilite algum tipo de manutenção, mas quebra o princípio de que pra dar boot todo o necessário deveria estar em /bin pra executáveis de usuário e /sbin pra executáveis de root. Assim como a libc em /lib. O problema foi que eu tinha criado uma partição /dev/devicemapper/diskspace-arch--usr e montado no /usr, que não é passada no boot, que pede somente a partição root.
Então tive de replanejar minha instalação aumentando a partição raiz e removendo a partição que abrigava o /usr.
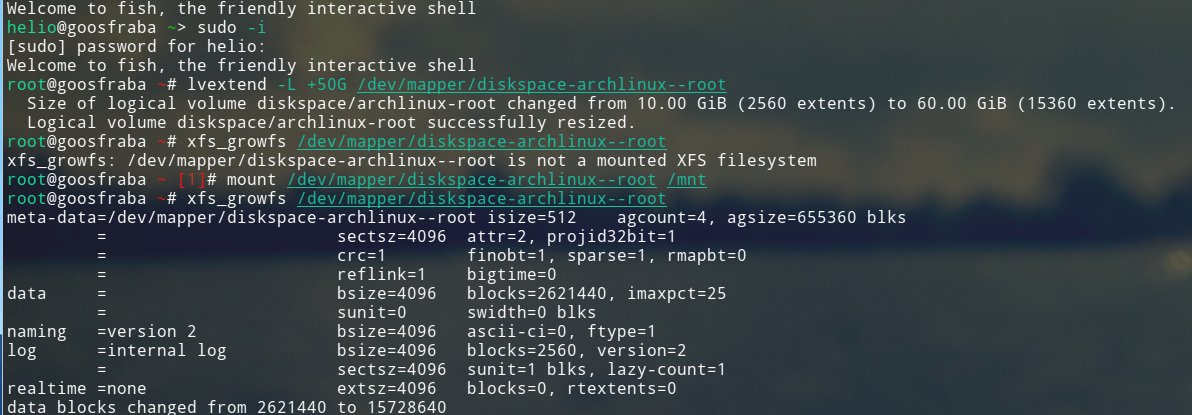
E finalmente copiar os dados do que era /usr.
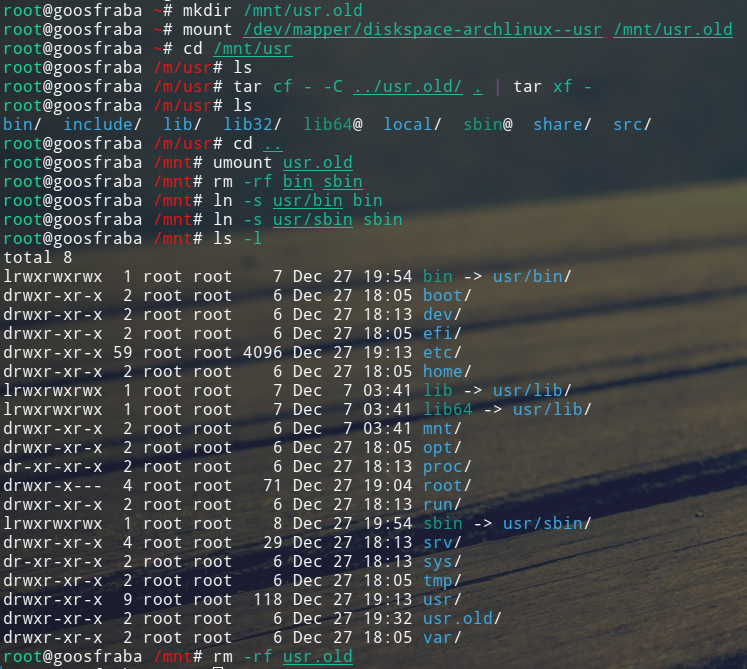
E finalmente remover a partição criada pra abrigar originalmente o /usr.

Com isso eu pude finalmente dar boot no Arch e subir o KDE plasma.
Mas foi só isso. Não consegui mexer em mais nada. O que deu errado? Primeiramente foi a escolha de KDE que fiz durante a etapa do pacstrap. Eu escolhi o plasma-desktop e o mesmo não vem completo, o certo era plasma-meta. Não tinha um shell pra eu abrir como o gnome-terminal nem konsole. E como habilitei o sddm, então não conseguia voltar pro console virtual usando <ctrl>+<alt>+<F1>. Fiquei empacado. E precisei novamente dar boot pelo pendrive pra corrigir isso.
E consegui subir meu ambiente da mesma forma que antes. Apenas re-criei meu usuário com mesmo UID e GID e montei a mesma partição /home que era do Ubuntu. Transparentemente.
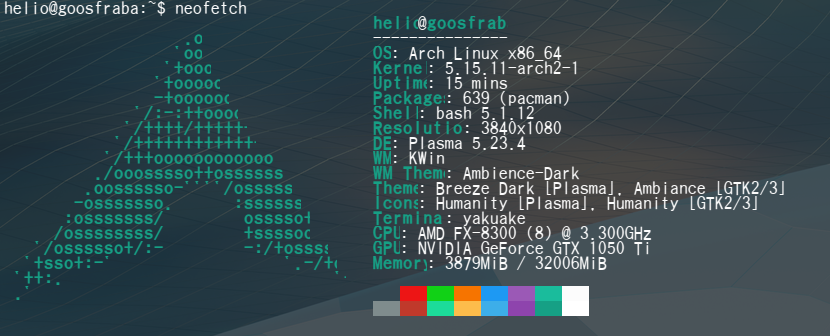
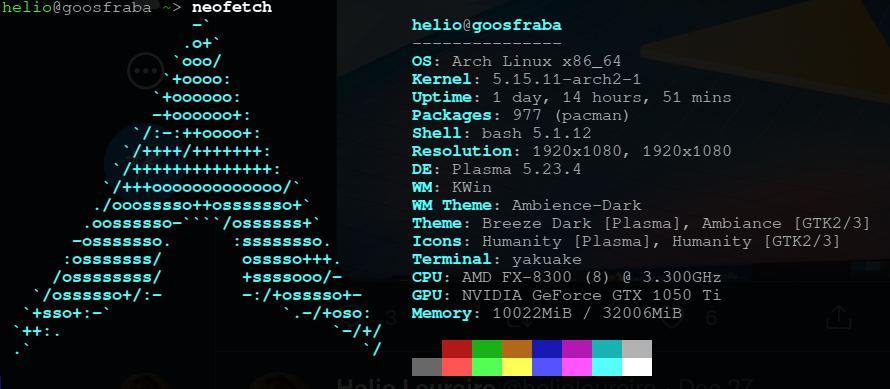
É nítida a diferença do primeiro screenshot do neofetch pro segundo, em como as fontes melhoraram. Aos poucos vou instalando e habilitando aquilo que preciso no Arch.
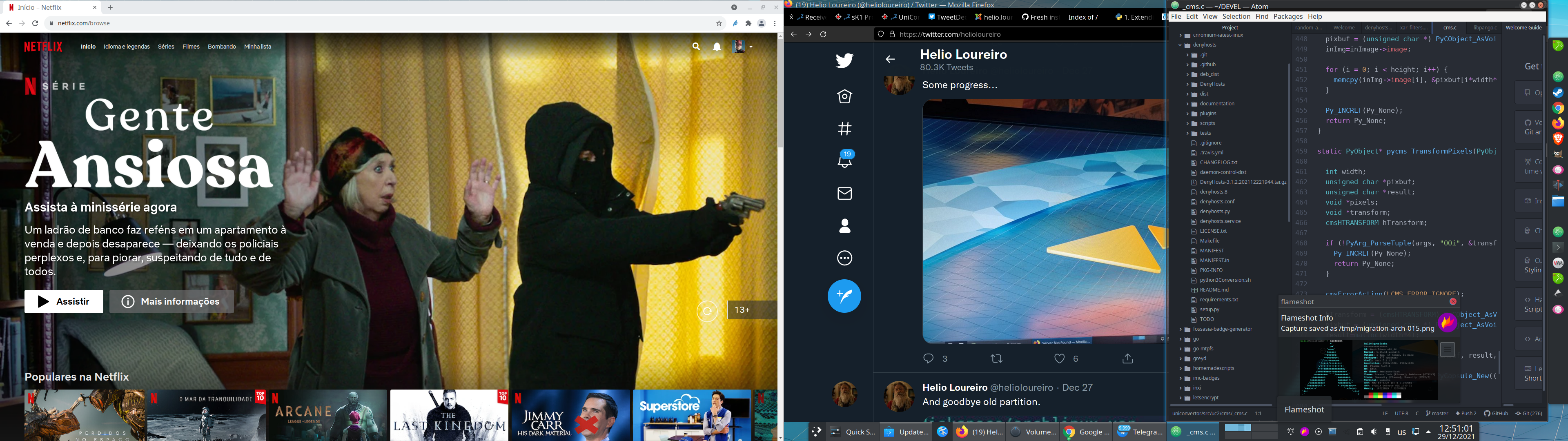
Eu de cara já sai com alguns extras funcionando sem mexer, como o Google Chrome, que aparece na imagem do desktop. Como estava na partição /opt, eu simplesmente montei e re-usei. Instalei o programa yay pra baixar pacotes faltando como steam e spotify. Ambos já instalados. E aos poucos vou arrumando a casa.
Um dos problemas que encontrei foi que minha partição de jogos da steam não aparecia disponível. Mas estava lá no comando lvs:
root@goosfraba /u/bin# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
archlinux-root diskspace -wi-ao---- 60.00g
archlinux-var diskspace -wi-ao---- 10.00g
debian diskspace -wi-a----- 10.00g
docker diskspace -wi-ao---- 30.00g
home diskspace -wi-ao---- 500.00g
linux-arch diskspace -wi-a----- 20.00g
opt diskspace -wi-ao---- 4.00g
root diskspace -wi-ao---- 10.00g
steam diskspace rwi-aor--- 750.00g 100.00
swap diskspace -wi-a----- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-a----- 50.00g
O problema era que precisava ativar a partição, que faz mirroring entre os dois HDs que tenho. Bastou fazer o comando:
lvchange -a y /dev/diskspace/steamE meu steam passou a funcionar de novo.
E como eu já deixei o docker em um partição só sua, bastou montar pra ter novamente os containers que uso disponíveis no Arch.
root@goosfraba /u/bin# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
debian 11.0 6c97952ad9c0 6 days ago 626MB
theiaide/theia-full latest de7823cee314 2 months ago 11.5GB
debian <none> a178460bae57 3 months ago 124MB
theiaide/theia-full <none> 9c178198e255 3 months ago 8.86GB
No arch já sai com o python 3.10 funcionando.
E pra minha surpresa a instalação do suporte à NVIDIA foi fácil e tranquilo. Mais que no Ubuntu.
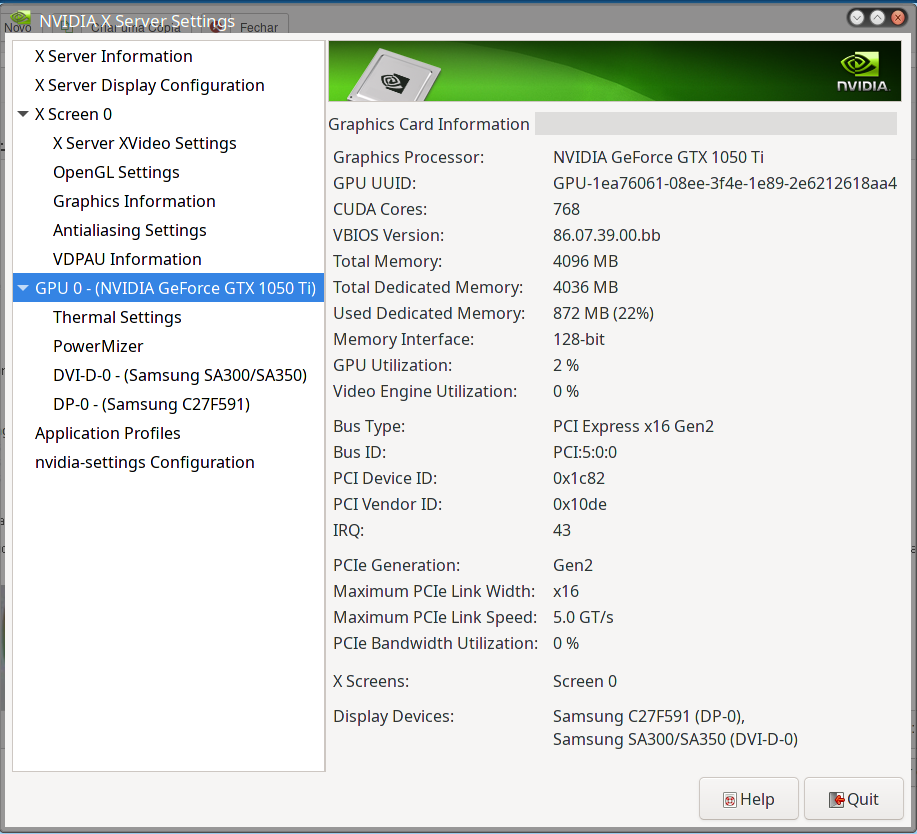
Como foi possível ver é bem divertido o uso do Arch e resgata um pouco daquele espírito hacker de fuçar no seu sistema operacional pra ter tudo funcionando. Eu estou gostando da experiência por equanto. Acho que agora já posso fazer como o Kretcheu, se bem que Debian eu já não uso faz alguns anos.

Caso não tenha lido os artigos anteriores:
Como bom brasileiros, nascidos na burocracia, estamos acostumados a ter vários números pra diferentes finalidades. CPF pra coisas relacionadas com imposto, RG pra identidade, certificado de reservista, cartão eleitoral, etc. E cada um com um número qualquer que temos em geral de memorizar.
Na Suécia sua vida toda é ligada ao que é chamado de "personnummer", ou "personal number" em inglês, ou número pessoal na boa e velha língua tupiniquim. Ele é composto de <ano em que nasceu><mês em que nasceu><dia em que nasceu>-<4 dígitos aleatórios>. Algo como YYYYMMDD-ABCD. Simples assim.
O ano de nascimento pode ser usado tanto o formato YY como YYYY. Nos documentos aparecem no formato YY, mas quando recebe seu número, via carta, ele vem no formato do ano completo com 4 dígitos, YYYY.
E com esse número baseado no seu aniversário você faz tudo: vota, tira carteira de motorista, faz o imposto de renda, vai ao médico, contrata serviços pelo telefone, etc.
De posse do número, você pode tirar a sua carteira de identidade de estrangeiro residente.

A moçoila bonita da foto nasceu em 12 de junho de 1970 de acordo com seu "personnummer". Existe um número gigantesco no topo à esquerda, o "kortnummer", que é "número do cartão", mas esse não é usado pra nada.
O mesmo formato aplica-se pra identidade de quem é cidadão sueco.

A diferença dessas identidades é que a primeira é emitida pelo skatteverket, órgão responsável por cobrar os impostos e também de registro civil, e o segundo, pela polícia. O cartão emitido pelo skatteverket tem mais a aparência e formato de um cartão de crédito comum, enquanto que a carteira emitida pela polícia é um papel plastificado num plástico rígido.
Existe também a carteira de motorista, emitida pelo trafiksverket, órgão responsável controle e regulamentação de tráfego.

A carteria de motorista, körkort em sueco (kör - dirigir, kort - cartão), tem a data de nascimento no campo 3 e o número pessoal no campo 5, que mostra a mesma data em formato invertido e mais os 4 últimos dígitos aleatórios/verificadores (parece que os 2 últimos são os verificadores). Aqui dentro da Suécia a carteira de motorista serve como identidade. Tanto que só ando com ela na carteira.
Nas viagens que fiz aqui pela europa, a maioria dos aeroportos aceitou só a carteira de motorista pra embarcar. Exceção foi o aeroporto internacional de Lisboa, que exigiu meu passaporte.
O ponto interessante aqui é que seu nome não diz muita coisa. Quem o define é seu número pessoal. Então qualquer pessoa pode ir ao skatteverket, onde está o registro civil, e mudar seu nome quando quiser, quantas vezes quiser e pro que quiser. Parece simples, não? E realmente é.
Claro que alguns podem argumentar que um sistema simples desse pode levar a um maior monitoramento de sua vida e atividades privadas. Eu diria que sim. Mas acho que benefício de ter um só número significativo pra tudo na sua vida compensa isso. A menos que você seja um despachante.
Filho aborrecente é... aborrecente. E infelizmente tenho de tempos em tempos de usar a artimanha de bloquear o YouTube pra conseguir sua atenção e fazer as suas tarefas.
Hoje eu estava revendo o script que criei em bloqueando Youtube no OpenWRT, criado em 2018. Dei uma melhorada no código e fiz o cáculo do horário de uma forma melhor.
Precisei carregar os módulos "bc" e "iptables-mod-filter" no openwrt pra funcionar como desejado.
#! /bin/sh
# save it into /usr/lib/scripts/firewall.sh
# and add into scheduled tasks as
# */5 * * * * /usr/lib/scripts/firewall.sh timetable
NOW=$(date +"%H:%M")
TIMETABLE="07:55,10:00 12:00,18:00 20:30,22:00"
status_file=/tmp/firewall_status
blocked_pattern="youtubei.googleapis.com"
blocked_pattern="$blocked_pattern googlevideo.com"
blocked_pattern="$blocked_pattern ytimg-edge-static.l.google.com"
blocked_pattern="$blocked_pattern i.ytimg.com"
blocked_pattern="$blocked_pattern youtube-ui.l.google.com"
blocked_pattern="$blocked_pattern www.youtube.com"
blocked_pattern="$blocked_pattern googleapis.l.google.com"
blocked_pattern="$blocked_pattern youtubei.googleapis.com"
blocked_pattern="$blocked_pattern video-stats.l.google.com"
blocked_pattern="$blocked_pattern ytimg-edge-static.l.google.com"
enable_firewall() {
echo "Enabling firewall"
for chain in INPUT FORWARD OUTPUT
do
count=1
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
count=`expr $count + 1`
done
done
echo iptables -I $chain $count -p udp --sport 443 -j DROP
iptables -I $chain $count -p udp --sport 443 -j DROP
count=`expr $count + 1`
echo iptables -I $chain $count -p udp --dport 443 -j DROP
iptables -I $chain $count -p udp --dport 443 -j DROP
count=`expr $count + 1`
done
echo -n "enabled" > $status_file
}
disable_firewall() {
echo "Disabling firewall"
for chain in INPUT FORWARD OUTPUT
do
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
done
done
echo iptables -D $chain -p udp --sport 443 -j DROP
iptables -D $chain -p udp --sport 443 -j DROP
echo iptables -D $chain -p udp --dport 443 -j DROP
iptables -D $chain -p udp --dport 443 -j DROP
done
echo -n "disabled" > $status_file
}
_get_time_as_integer() {
time=$1
hour=$(echo $time | cut -d: -f 1)
minute=$(echo $time | cut -d: -f 2)
echo "$hour * 100 + $minute" | bc
}
_get_start_time(){
# expected format: 07:00,10:00
time_str=$1
time_start=$(echo $time_str | cut -d, -f 1)
_get_time_as_integer $time_start
}
_get_stop_time() {
#expected format: 07:00,10:00
time_str=$1
time_stop=$(echo $time_str | cut -d, -f 2)
_get_time_as_integer $time_stop
}
get_timetable() {
do_activate=0
for value in $TIMETABLE
do
start=$(_get_start_time $value)
stop=$(_get_stop_time $value)
cur_time=$(_get_time_as_integer $NOW)
if [ $start -lt $cur_time ]; then
if [ $cur_time -lt $stop ]; then
do_activate=1
fi
fi
done
cur_status=$(cat $status_file)
if [ $do_activate ]; then
if [ "$cur_status" = "enabled" ]; then
echo "firewall already activated"
else
echo "activating firewall"
enable_firewall
fi
else
if [ "$cur_status" = "enabled" ]; then
echo "deactivating firewall"
disable_firewall
else
echo "firewall already deactivated"
fi
fi
}
case $1 in
start) enable_firewall
exit 0;;
stop) disable_firewall
exit 0;;
timetable) get_timetable
exit 0;;
status) echo "firewall rules are $(cat $status_file)";;
*) echo "Use: $0 [start|stop|timetable|status]"
exit 0
esac
exit 0
Agora os horário de bloqueio ficam na variável TIMETABLE e no format "<horário início HH:MM>,<horário fim HH:MM>". O firewall permite um direto "start" e "stop" pra ativar, assim como um "status". Crie alguma funções com o "_" no início, pra seguir um pouco o padrão do python de funções internas/privadas.
Seu funcionamento agora ficou muito bom e fácil, pra desespero dos aborrecentes.
root@OpenWrt:/usr/lib/scripts# ls
firewall.sh
root@OpenWrt:/usr/lib/scripts# ./firewall.sh status
firewall rules are disabled
root@OpenWrt:/usr/lib/scripts# ./firewall.sh timetable
activating firewall
Enabling firewall
iptables -I INPUT 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I INPUT 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I INPUT 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I INPUT 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I INPUT 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I INPUT 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I INPUT 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I INPUT 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I INPUT 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I INPUT 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I INPUT 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I INPUT 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I INPUT 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 21 -p udp --sport 443 -j DROP
iptables -I INPUT 22 -p udp --dport 443 -j DROP
iptables -I FORWARD 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I FORWARD 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I FORWARD 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I FORWARD 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I FORWARD 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I FORWARD 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I FORWARD 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I FORWARD 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I FORWARD 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I FORWARD 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I FORWARD 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I FORWARD 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I FORWARD 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 21 -p udp --sport 443 -j DROP
iptables -I FORWARD 22 -p udp --dport 443 -j DROP
iptables -I OUTPUT 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I OUTPUT 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I OUTPUT 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I OUTPUT 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I OUTPUT 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I OUTPUT 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I OUTPUT 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I OUTPUT 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I OUTPUT 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I OUTPUT 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I OUTPUT 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I OUTPUT 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I OUTPUT 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 21 -p udp --sport 443 -j DROP
iptables -I OUTPUT 22 -p udp --dport 443 -j DROP
root@OpenWrt:/usr/lib/scripts# ./firewall.sh timetable
firewall already activated
root@OpenWrt:/usr/lib/scripts# ./firewall.sh status
firewall rules are enabled
root@OpenWrt:/usr/lib/scripts# date
Sun Dec 19 13:51:32 CET 2021
Boa diversão. Ou não caso seja o aborrescente lendo esse artigo pra descobrir o porquê seu YouTube parou de funcionar.
No roadmap: incluir TikTok e Instagram.
UPDATE: eu por fim criei um repositório no github pra ficar mais fácil a manutenção: https://github.com/helioloureiro/opewrt-youtube-blocker
Não é sempre que preciso fazer dessas coisas, mas recentemente precisei mexer num disco de livecd do Ubuntu que estava em formato iso pra alterar algumas coisa.
Então aqui fica receita de como fazer isso (dependendo do que deseja fazer, claro).
Primeiro eu tenho dois diretórios que uso pra montagem dos filesystems. Os /cdrom e /mnt. Como já uso desse forma faz anos, não sei se são criados por padrão no Ubuntu ou outro sistemas. Então se for copiar o que descrevo aqui, tenha certeza que esses diretórios existem. Outro ponto importante é que rodo todos os comandos como root.
Então o começo de tudo é montar a imagem do Ubuntu no diretório desejado.
root@goosfraba /# mount -t iso9660 -o loop ubuntu-20.04.03-desktop-amd64.iso /cdrom
Esse conteúdo precisa ser copiado pra um diretório temporário.
root@goosfraba /# mkdir /tmp/temp-cdrom
root@goosfraba /# cd /tmp/temp-cdrom
root@goosfraba /t/temp-cdrom# tar cvf - -C /cdrom . | tar xvf -
Existe o arquivo casper/filesystem.squashfs que é o filesystem do livecd. Você pode montar esse disco com o seguinte comando (e aqui entra o /mnt que comentei antes):
root@goosfraba /t/temp-cdrom# mount -t squashfs -o loop /tmp/temp-cdrom/casper/filesystem.squashfs /mnt
mas esse disco é apenas read-only. Pra modificar é preciso usar a ferramenta unsquashfs que faz parte do pacote squashfs-tools.
root@goosfraba /t/temp-cdrom# mkdir /tmp/squashfs
root@goosfraba /t/temp-cdrom# cd /tmp/squashfs
root@goosfraba /t/squashfs# unsquashfs /tmp/temp-cdrom/casper/filesystem.squashfs
Parallel unsquashfs: Using 8 processors
185020 inodes (205968 blocks) to write
[=================================================================================================================================================================/] 205968/205968 100%
created 155722 files
created 19319 directories
created 29184 symlinks
created 8 devices
created 0 fifos
root@goosfraba /t/squashfs# ls squashfs-root/
bin@ boot/ dev/ etc/ home/ lib@ lib32@ lib64@ libx32@ media/ mnt/ opt/ proc/ root/ run/ sbin@ snap/ srv/ sys/ tmp/ usr/ var/
Daí sim fazer as modificações desejadas.
Ao terminar é preciso gerar a imagem no formato squashfs novamente, agora usando o mksquashfs. Prepare-se pra ir fazer um café ou assistir um filme pois o processo demora bastante nesse passo.
root@goosfraba /t/squashfs# mksquashfs squashfs-root /tmp/temp-cdrom/casper/filesystem.squashfs -b 1024k -comp xz -Xbcj x86 -e boot
Parallel mksquashfs: Using 8 processors
Creating 4.0 filesystem on /tmp/temp-cdrom/casper/filesystem.squashfs, block size 1048576. [=================================================================================================================================================================/] 149629/149629 100%
Exportable Squashfs 4.0 filesystem, xz compressed, data block size 1048576
compressed data, compressed metadata, compressed fragments,
compressed xattrs, compressed ids
duplicates are removed
Filesystem size 1695376.64 Kbytes (1655.64 Mbytes)
32.81% of uncompressed filesystem size (5167137.40 Kbytes)
Inode table size 1550743 bytes (1514.40 Kbytes)
20.75% of uncompressed inode table size (7473067 bytes)
Directory table size 1819524 bytes (1776.88 Kbytes)
36.53% of uncompressed directory table size (4981005 bytes)
Xattr table size 98 bytes (0.10 Kbytes)
81.67% of uncompressed xattr table size (120 bytes)
Number of duplicate files found 18577
Number of inodes 204220
Number of files 155715
Number of fragments 2275
Number of symbolic links 29180
Number of device nodes 8
Number of fifo nodes 0
Number of socket nodes 0
Number of directories 19317
Number of ids (unique uids + gids) 37
Number of uids 15
root (0)
ntp (126)
dnsmasq (112)
saned (119)
speech-dispatcher (114)
systemd-timesync (100)
_apt (105)
rtkit (118)
messagebus (106)
man (6)
postfix (125)
whoopsie (109)
sshd (121)
sddm (122)
syslog (104)
Number of gids 28
root (0)
dip (30)
shadow (42)
lpadmin (113)
rtkit (126)
mysql (131)
nogroup (65534)
lp (7)
audio (29)
systemd-timesync (102)
utmp (43)
tty (5)
geoclue (105)
_ssh (118)
input (106)
mail (8)
staff (50)
avahi (120)
man (12)
pulse-access (125)
whoopsie (116)
munin (130)
saned (127)
pulse (124)
uuidd (111)
systemd-journal (101)
adm (4)
messagebus (110)
E o último passo é gerar o disco bootável. Pra isso eu usei o genisoimage:
root@goosfraba /tmp# genisoimage -b isolinux/isolinux.bin -c isolinux/boot.cat -no-emul-boot -boot-load-size 4 -boot-info-table -r -J -o /tmp/ubuntu-20.04.03-modificado-desktop-amd64.iso /tmp/temp-cdrom
Com isso a image iso ubuntu-20.04.03-modificado-desktop-amd64.iso é gerada.
Eu estava aguardando o release oficial dessa palestra, o que aconteceu no dia 25.
Fiz uma palestra sobre programação em shell script abordando Bourne shell e resolvendo o mesmo problema que apresentei na rápida introdução ao Python na BSD Day 2021, em python, e na Latinoware 2021 - Go das trincheiras, em Go. Dessa vez use o shell script e resolvi o mesmo problema.
Terminada minha maratona pessoal de participações em conferências e eventos em geral, eu decidi dedicar algum tempo pra atualizar meus sistemas.
Meu desktop passou de Ubuntu 20.04 pra 21.10. Decidi simplesmente largar o LTS e abraçar os releases intermediários. Tive alguns problemas com o snapd, que deu uns crashes de kernel, mas no fim tudo deu certo. Uma boa experiência de ambiente desktop com KDE Plasma mais recente.
No servidor eu atualizei pro último Debian estável. Eu sempre espero um pouco pra fazer isso, até sair a correção .1 do release, e foi o que fiz no final. Mas um dos problemas que tive foram meus scripts em python. Muitos deles foram feitos há mais de 10 anos e estavam rodando felizes com python 2.7. O upgrade pra Debian bullseye acabou com essa alegria. Apenas python3 restou e muita coisa parou de funcionar. Posso dizer que até agora não encontrei tudo que quebrou após o upgrade, mas devagar estou corrigindo.
Então aproveitando o embalo eu decidi também fazer o upgrade do raspberrypi. Mesmo sendo raspbian, é Debian. E passei pro bullseye. Assim como o servidor, o upgrade em si foi bem tranquilo. Super suave.
Então percebi que meu as fotos pararam de funcionar.
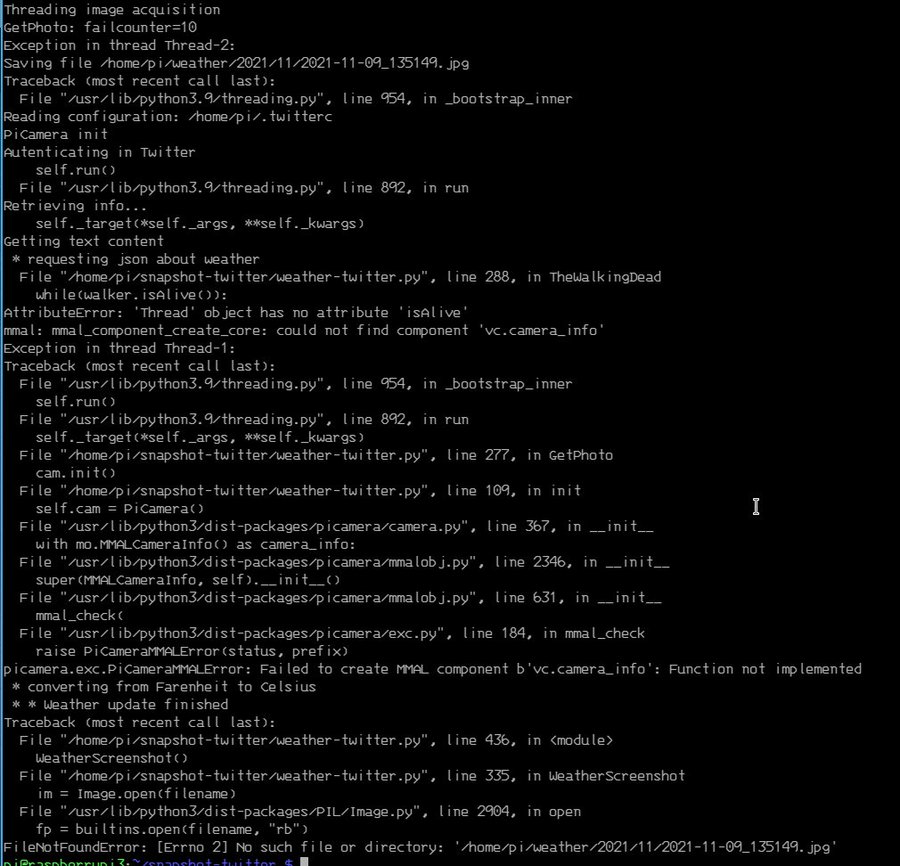
tl;dr: basicamente o antigo suporte ao picamera deixou de existir. Foi trocado pela libcamera, que não tem suporte em python ainda.
https://github.com/waveform80/picamera/issues/697
O que é possível fazer agora? Aliás o que eu fiz pra contornar isso? Bom... não ficou bonito, mas funciona. Chamei um dos programas que vem com o libcamera e salva fotos em jpeg usando subprocess.
class LibCameraInterface:
def __init__(self, sleep_time=30): None
def get_image(self, destination):
debug("LibCameraInterface.get_image()")
import subprocess
width, height = IMGSIZE
command = f"/usr/bin/libcamera-jpeg --width={width} --height={height} -o {destination}"
subprocess.call(command.split())
Eu aproveitei e dei uma boa refatorada no código. Ficou mais simples e pronto pra trocar. Criei duas classes, LibCameraInterface e CameraInterface. A ideia é voltar ao CameraInterface uma vez que tenha algum tipo de suporte em python. Por enquanto nem pygame funciona mais.
O resultado é quase o mesmo. Quase. Pelo libcamera as imagens ficaram mais escura durante a noite.
O antes:

O depois:

Ambas bem escuras. A segunda eu mudei um pouco a posição da câmera, mas mesmo pegando a iluminação dos prédios fica bem escura. E não achei ainda um jeito de melhorar isso.
Talvez um upgrade pra próxima versão.
UPDATE:
Eu tinha esquecido de postar o link do programa no github. Aqui está ele.
https://github.com/helioloureiro/snapshot-twitter/blob/master/weather-twitter.py
Update 2022-12-09: fui revisitar o artigo e percebi que não tinha colocado o link pro bug no github. Então adicionei.

Pode parecer meio estranho, mas foi isso mesmo que precisei fazer: pegar a chave pública de ssh de um perfil que estava no jenkins pra configurar o acesso num repositório Gitlab.
Mas o Jenkins, sabiamente, não guarda ou mostra essas credenciais pra você. Então precisei recorrer a meios não muito convencionais pra fazer isso.
Primeiro fooi pegar a chave privada que ele tinha armazenado. Pra isso encontrei uma receita de bolo, escrita em Groovy.
https://scriptcrunch.com/groovy-script-retrieve-jenkins-credentials/
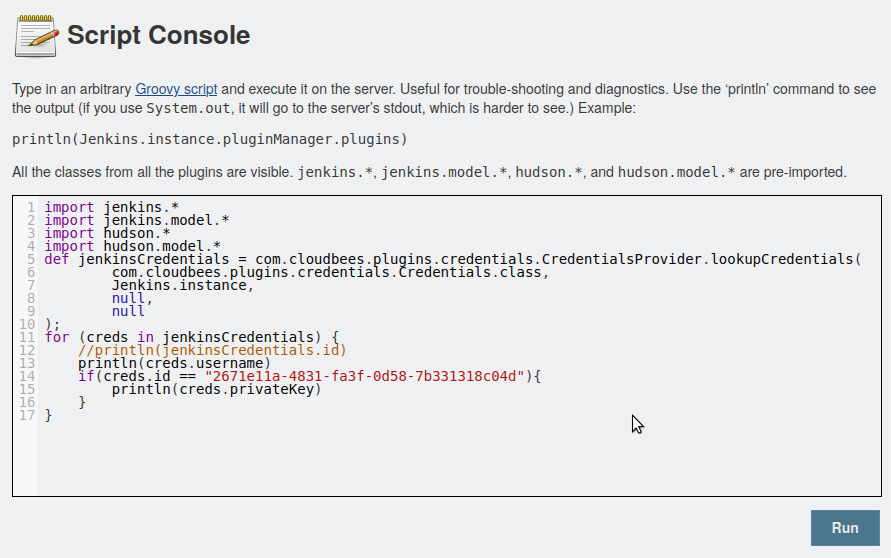
import jenkins.*
import jenkins.model.*
import hudson.*
import hudson.model.*
def jenkinsCredentials = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
com.cloudbees.plugins.credentials.Credentials.class,
Jenkins.instance,
null,
null
);
for (creds in jenkinsCredentials) {
// descomente essa parte abaixo se precisar de mais detalhes
//println(jenkinsCredentials.id)
println(creds.username))
if(creds.id == "2671e11a-4831-fa3f-0d58-7b331318c04d"){
println(creds.privateKey)
}
}
E pra rodar junto ao Jenkins, na área de scripts. Se não sabia ainda, é possível rodar script pela interface web atráves da url que tem do Jenkins mais o final "/script".
No laço "if" onde olho se o creds.id bate com um número gigante, esse é o identificador que você vê como ID nas credenciais.
Esse foi o resultado:
user1
user2
user3
-----BEGIN RSA PRIVATE KEY-----
MIIEowIBAAKCAQEAyONzf1Ti1Dv8jI68/oyGJ2Gf6CNkN64ncZAVB5QnR+0NbyzN
G9U6uFqKUoSuuYblqANJNGR3PKCVhCJCB6Ge7azPK10eYEHFyYXGuIwi9Rb3MsjN
Cof57NzenIUcErm0Cuxk34xEXdR5UFm8GI0q3MEuBSwopQfAnfGa5L+QxGt/+YuY
ei/n/V0QsgYuZb9RVF2NbTrNLk09vBQ7SVwyDzKBaaGFkO0uh6fvCz/gq8L+f9cL
Z/twZNy1/Z13VSe2Agd/1ErLBqlTrxabPCFPMWm4YiAAwIUqhwaI6GU7IRLo/HWo
9eqfvYUWh6FyBKRf7bdSdWfWSSTNxgwPCfJavQIDAQABAoIBADjjaG6znDSb9C3d
shmns8ntNHppo1S9RcA8HCh0RRdyQu6r0j3CiYlxYmBx4IT7dYe5vn5OwRFzLEQp
62b71uTZniVajmKV3avu7VKPpMqhQUmpYZ9M2HLCLWxHqaaH3juFrB8+OpITvHML
pl+RgoTXU+/1DGGHq31O0R1cPmPQyRDhaxVpzsYwbCcIYGJ1hjz2g+098LwtIr5W
5i2Z6JUpE6GyXlVZAM1f9tsYWgGGEBqbH4frUjH9Ao1F7dKARDHsiwcjbreywBx1
aVk8AsTP31vqdOJgUJC9JcM/cf2GLUQxg7ZjdDTrTPWnNzWFhALoFe79UKw4lhE7
ezrqi0UCgYEA457BTvaKI+pcxuh5waV1SrfBYDC9czZpYht1R1i3lmYJKdQFHtVl
HAoy18zuYec9MaNPdqbzWysqkH6D6R8T/qdogQ9/5XpSnPVGbsg2IRKq4jNPrh1M
y8Kx2SOYpk6eLtPxYeRHaAKv/GYbQMs8Sh+GNkSiudhTEESj+KKhmO8CgYEA4e93
phLCmzP+SI2pgqFkZ2H2R5X8aCkbuV7pdcnTb4T/rH0Zah2vFEOmjWaUaGHJDOWk
6y+JPzWmxdweb+2FKTg1g6m8ig1DazcmkTG0CEWwwDLJ93LiQYl59uXt2UuQSkj6
Be+JcUzY2w1lhD0+vNfVF/RrH+xTaYfze1PiDxMCgYBtHNUdvSFLRjVjRF3Zbi9j
ueKA8dxfNl4eIXt+0BBxkEgkPPaXaUQmxNzKhfpgBDFZcifNgQp3UaH90if5wGQd
VrLJ61wr7Q9dHla9FEyeXgx8koxHstP1eUc4B9BNKLK7T+4ONxfjzCYAoBHAZaxo
++OicBRxcjmfOsg/j/ZXEQKBgQDZS84gfJSMXsIml5C7YWvGfpI2IUukBj1y2JTi
w1zGOf0IsTybMbdsXvA1uL3tcnbCH6+wvoRatcgTLfRcI+3ZSgU1/y6k+8KmwGEo
bcw/1H79KxvSEL0I2SbjThqmzaUVvQAya0IeJRHABC9pstm/GDoLkvjguBM1QRrs
ty2I3wKBgEBRpeSp/07x6LaIqHULNuV515BqtvWmWQuc8ngMOkcOO1mcQ745VbDj
YO0pIFHmK1iCtrXhyKPxOOitBjiQOZTeR6cZehm/7Mg+LWR6qdloqOOOij//WND6
PEeIskhUu6Dg07S91meHs3u/TRL0Gmr+zjCIn/0P40O38iyZTaVK
-----END RSA PRIVATE KEY-----
user4
user5
user6
De posse da chave privada, foi então questão de salvar em arquivo, que chamei de jenkins, e gerar a chave pública a partir dela.
Achei que o openssl iria fazer isso, mas todas as tentativas foram frustradas. No fim descobri como resolver com o próprio ssh-keygen olhando no stackoverflow, sempre ele pra nos ajudar:
https://stackoverflow.com/questions/10271197/how-to-extract-public-key-using-openssl
> ssh-keygen -y -f jenkins
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABA
AABAQDI43N/VOLUO/yMjrz+jIYnYZ/oI2Q3ridxkBUHlCdH7Q1vLM0b1Tq4W
opShK65huWoA0k0ZHc8oJWEIkIHoZ7trM8rXR5gQcXJhca4jCL1FvcyyM0Kh
/ns3N6chRwSubQK7GTfjERd1HlQWbwYjSrcwS4FLCilB8Cd8Zrkv5DEa3/5i
5h6L+f9XRCyBi5lv1FUXY1tOs0uTT28FDtJXDIPMoFpoYWQ7S6Hp+8LP+Crw
v5/1wtn+3Bk3LX9nXdVJ7YCB3/USssGqVOvFps8IU8xabhiIADAhSqHBojoZ
TshEuj8daj16p+9hRaHoXIEpF/tt1J1Z9ZJJM3GDA8J8lq9
e foi assim que consegui conectar o Jenkins usando o user3 com chave ssh no Gitlab. Peço desculpas em ter quebrado a chave em 60 colunas aqui, mas o fiz pra que ficasse bom pra ler também em smartphones.
AVISO: todos os dados aqui não são os verdadeiros. Antes de alguém perder tempo usando isso pra tentar invadir alguma coisa minha, eu gerei tanto o ID com sha256sum da data atual e preenchi pra parecer o ID do Jenkins quanto a chave privada, que gerei também só pra mostrar aqui. Nada disso está em uso em lugar algum.
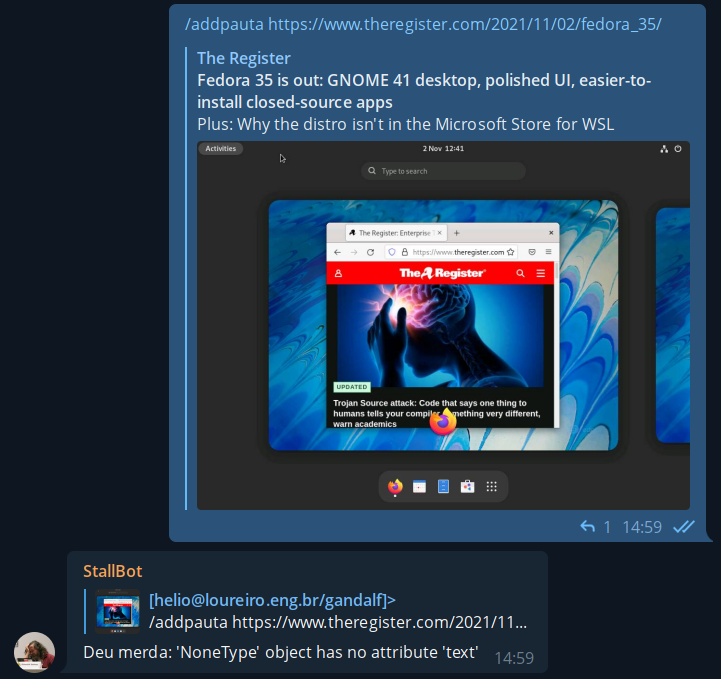
E foi assim que tudo começou. Com um singelo e modesto "deu merda". Primeiramente uma rápida introdução pra explicar o que isso significa: temos um bot pra adicionar assuntos nas pautas do canal Unix Load On. O bot roda em Python no raspberrypi3 que tenho aqui em casa. O mesmo que fica tirando fotos pela janela e mostra no twitter no perfil @helio_weather.
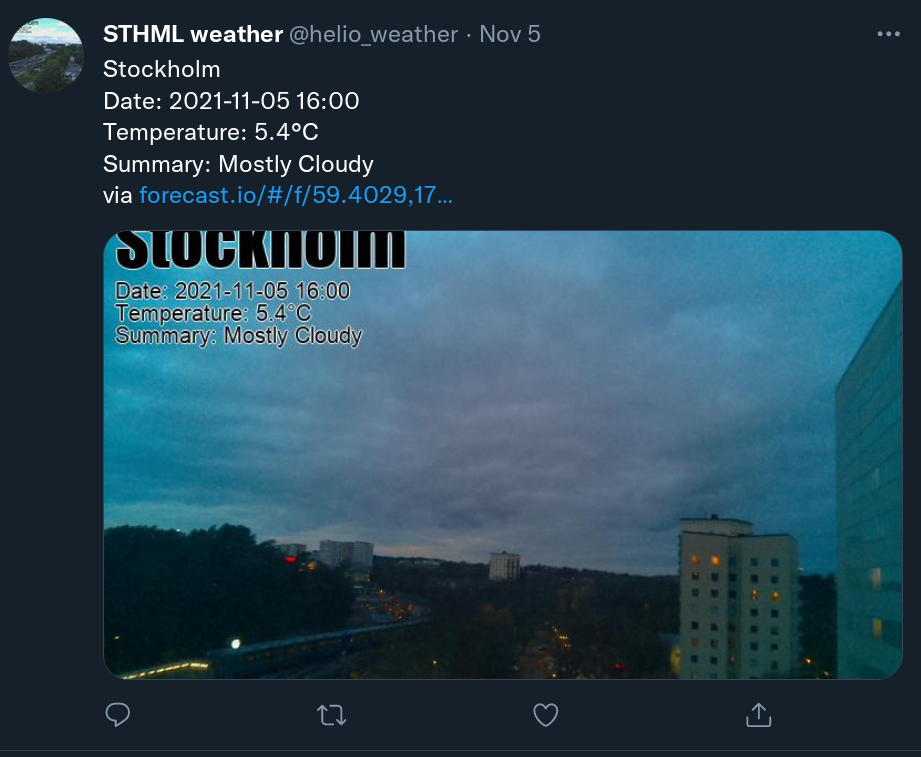
Então temos essa função "/addpauta" com um estilo de inglês a la Raimundos pra adicionar novos links. O programa no bot rodava um código com módulo requests pra pegar a página e buscar o título do artigo. Só isso. Então não era algo esperado pra ter o resultado "deu merda". Mas deu.
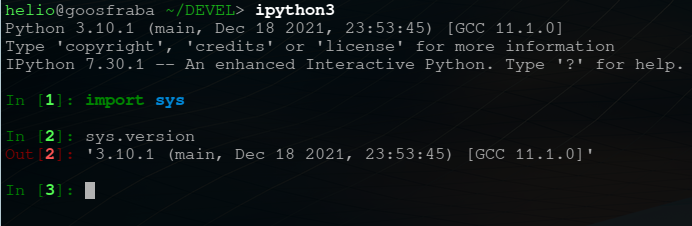
Olhando a mesma URL usando o ipython:
> ipython3
Python 3.9.7 (default, Sep 10 2021, 14:59:43)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.20.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import requests
In [2]: url = "https://www.theregister.com/2021/11/02/fedora_35/"
In [3]: r = requests.get(url)
In [4]: r.status_code
Out[4]: 103
In [5]: r.text
Out[5]: ''
então é isso. O webserver retorna 103, que é uma nova RFC, e espera que você continue pegando o conteúdo. Só que o módulo requests não faz isso.
Existe um bug aberto no github sobre esse problema onde eles relatam que o comportamento não é bem do requests, mas da urllib3, que é parte do core do Python. Traduzindo em miúdos: não tem solução e talvez façam uma correção no Python 3.10.
Atualizar todo o Python só pra corrigir um erro besta desses? Entra em cena o curl, que já comentei em usando curl pra monitorar um site. Não o curl propriamente dito, mas a pycurl. Tanto curl quanto pycurl passam dando tchauzinho por esse problema de manipular a resposta 103. E mandam aquele abraço pra urllib3.
Olhando via script:
> curl -s https://www.theregister.com/2021/11/02/fedora_35/ | head -10
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Fedora 35 released with GNOME 41 desktop • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2021/11/02/fedora35.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2021/11/02/fedora_35/" />
fazendo o mesmo em Python:
import pycurl
from io import BytesIO
def curl(url):
crl = pycurl.Curl()
crl.setopt(crl.URL, url)
b_obj = BytesIO()
crl.setopt(crl.WRITEDATA, b_obj)
crl.setopt(crl.FOLLOWLOCATION, True)
crl.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; rv:78.0) Gecko/20100101 Firefox/78.0')
crl.perform()
crl.close()
return b_obj.getvalue().decode('utf-8')
print(curl("https://www.theregister.com/2021/11/02/fedora_35/"))
então fica aqui a lição: onde a requests falhar, pycurl estará lá pra te salvar.
Eu até hoje não postei nada aqui, mas já faz algum tempo que trabalho com Go como primeira linguagem de programação. É uma linguagem bacana e interessante. A curva de aprendizado não é grande e rapidamente você já consegue criar programas nele.
Com essa ideia em mente eu refiz a palestrada da BSD Day, rápida introdução ao Python na BSD Day 2021, em Go.
Claro que é uma introdução bastante rápida e não cubro muitas coisas da linguagem. Mas espero que sirva como primeiro passo pra quem estiver interessado em aprender.
Eu acabei quebrando minha promessa de ano novo de postar aqui semanalmente durante os últimos meses. Mas tenho uma boa justificativa. Eu escrevi um artigo pra Revista Espírito Livre, fiz duas palestras na Latinoware, organizei a PyCon Suécia, organizei a hackathon na firma e fiz uma última palestra pra Tchelinux.
Muito disso ainda não foi publicado. Quando aparecer, com certeza crio um post sobre o assunto.
Mas entre o que já foi publicado está a palestra sobre carreira na Latinoware.
Foquei mais nas perguntas que geralmente aparecem no grupo do telegram. E, claro, tinha mais assunto pra falar, mas vou guardar pra outra oportunidade :)
Seguindo os artigos trabalhando de home-office e trabalhando de casa - atualização de 2021, aqui vai mais uma atualização.
Eu decidi investir num teclado novo. Mecânico, claro. Decidi não ter mais um full size, que tem o teclado numérico, mas num um pouco mais curto. Depois de muito olhar e pesquisar, finalmente decidi pegar um Keychron C1 com brown switch.
Fiz um vídeo do unboxing onde tem até uma comparação de som com o teclado que usava anteriormente, que é do tipo blue switch.
Mas nem tudo foi uma maravilha em Linux.
Pra fazer o teclado funcionar corretamente eu precisei usar o modo Mac. No modo Windows, de jeito nenhum eu consegui fazer funcionar as teclas de funções. Mesmo no modo Mac eu precisei ajustar uns parâmetros pra tudo dar certo.
Precisei criar o arquivo /etc/moprobe.d/hid_apple.conf da seguinte maneira:
echo "options hid_apple fnmode=2 swap_opt_cmd=1" >> /etc/modprobe.d/hid_apple.conf
Com isso o kernel reconhece o teclado e aplica a configuração correta. Então as teclas de função F1-F12 são o padrão e preciso apertar a tecla "fn" pra usar as funções.
Existem várias opções de troca de firmware pra mudar cores, etc, mas confesso que não é algo que eu realmente pense em fazer. Pra mim basta ser um teclado mecânico confortável, o que realmente é, e ter um teclado luminoso (às vezes trabalho no escuro e isso ajuda).
Como reinstalei meu laptop acabei percebendo que dica de cima faltaram algumas coisas.
Primeiro que pra ativar manualmente o teclado, basta rodar o seguinte comando como root:
echo 0 >> /sys/module/hid_apple/parameters/fnmode
depois que ao criar o arquivo no modprobe, é preciso também re-gerar o arquivo de initram com o comando:
update-initramfs -u -k all
Update em 2025-03-09:
Atualizado o comando em /etc/modprobe.d/hid_apple.conf
com a configuração atual.
Page 13 of 39
