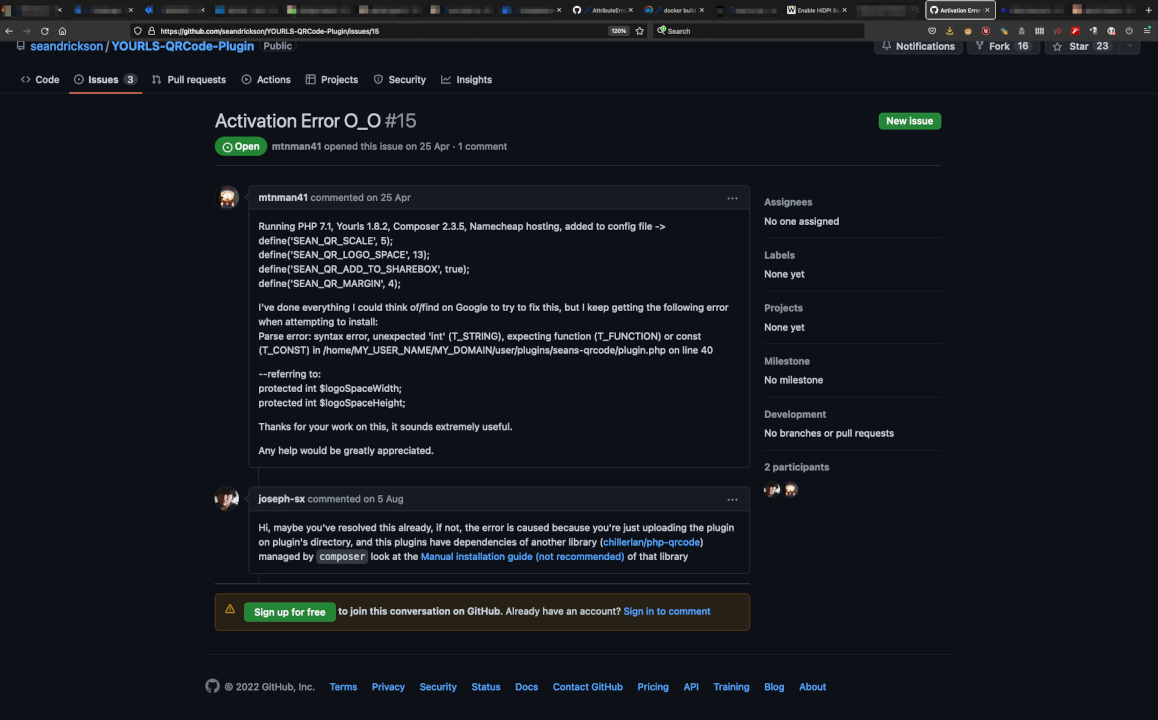
Esse problema já vinha arrastando-se por algum tempo. Desde que peguei o MacBook. Quando eu trabalhava com um display externo, o Firefox ficava com a fonte normal. Mas bastava eu usar somente o laptop pra ele ficar ridiculamente pequeno. Como pode ser visto na image, o texto é legível, mas a barra do Firefox é impossível. E em alguns sites específicos eu precisava ficar aumentando o zoom pra conseguir ler o texto.
No Macos eu já tinha configurado pra usar uma resolução não tão alta pra justamente não ficar com tudo ridiculamente pequeno na tela (eu particularmente odeio isso).
Mas o Firefox sempre teimava em não seguir a configuração. E o difícil era... buscar um solução já que eu não sabia qual o problema exatamente. Tentei "firefox small fonts", "firefox small resolution" e por aí seguiu minha busca. Sem infrutífera. Até que hoje eu resolvi buscar por "hidpi" e... bingo!
Basta entrar na configuração do Firefox com "about:config" e alterar o parâmetro "layout.
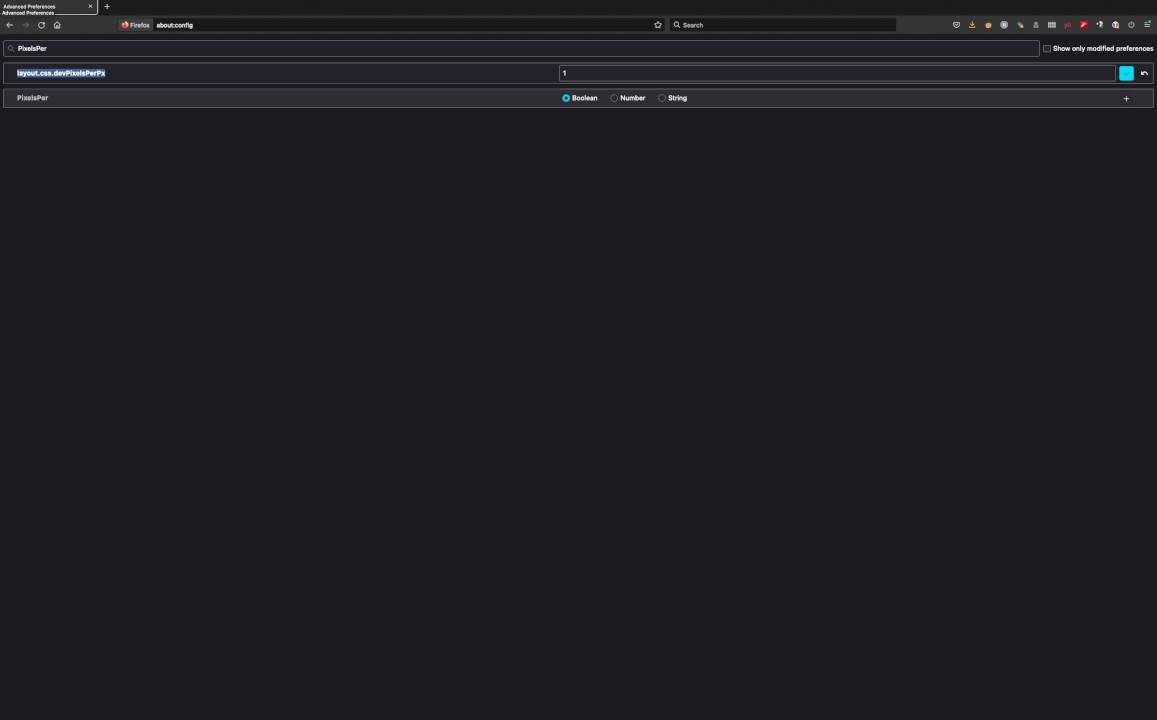
e como ficou depois, só mudando de 1 pra 1.5.
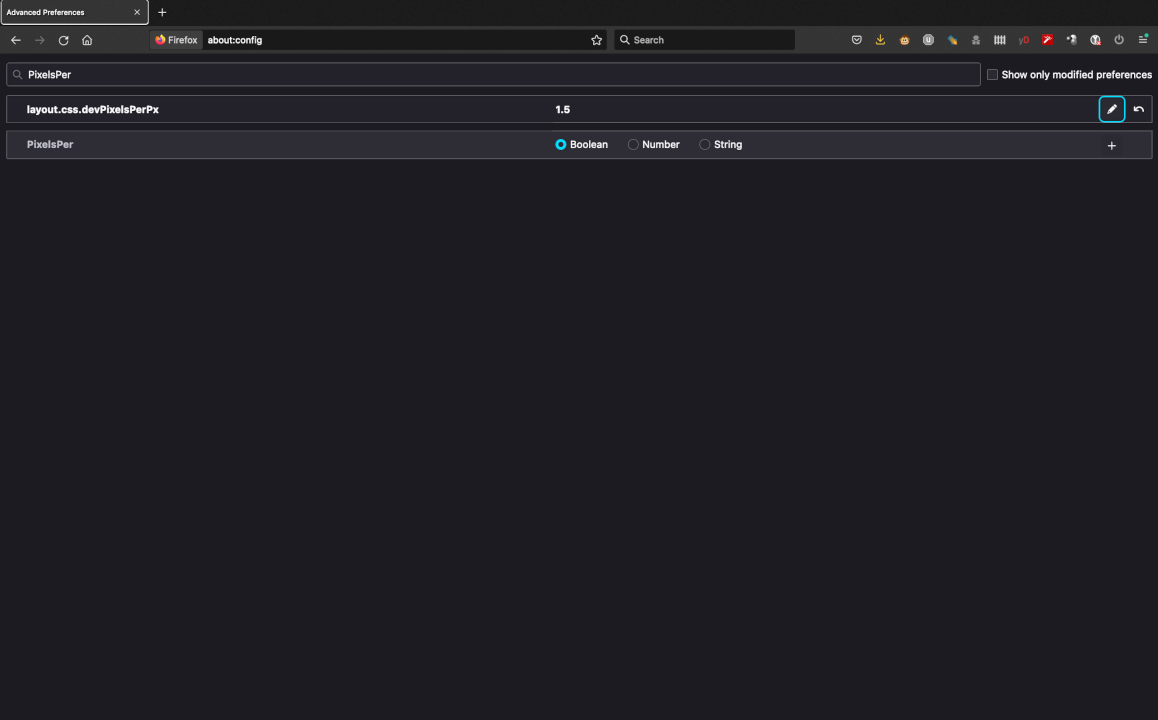
agora sim consigo usar apenas o laptop pra trabalhar.
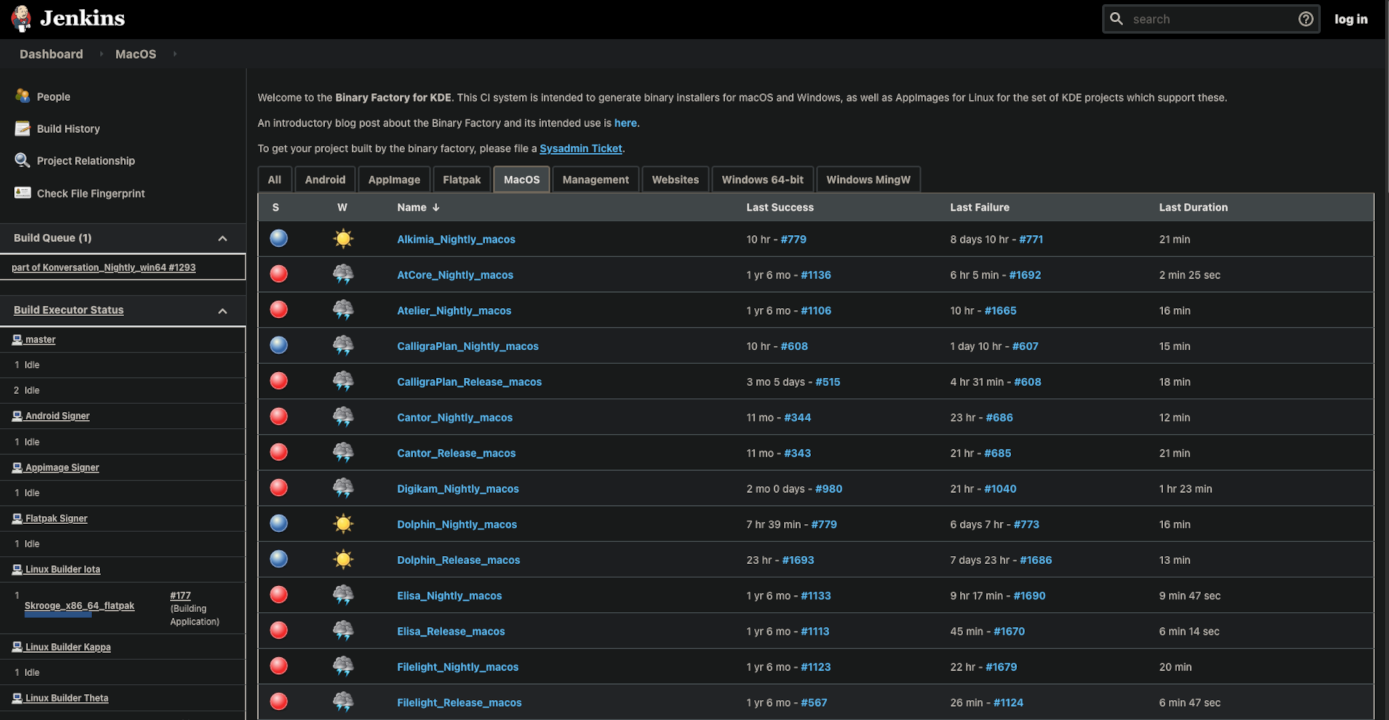
Descobri através daqueles links obscuros que aparecem na segunda página de buscas do duckduck.go uma referência a um servidor Jenkins do KDE.
E pra minha surpresa, ou melhor, para meu deleite tem okular, dolphin e outras coisas práticas e excelentes pra rodar no Macos.
Depois de baixar e montar o arquivo dmg, usando como exemplo o Dolphin, você precisa copiar o arquivo pra suas aplicações e dar as permissões pra ele rodar:
$ xattr -d com.apple.quarantine /Applications/dolphin.app $ codesign --sign - --force --deep /Applications/dolphin.app
E basta iniciar o programa:
$ open -a /Applications/dolphin.app
Ookular funcionou sem problemas.
O Dolphin está com algum problema de tema que não aparecem os nomes de diretórios. Também senti falta do "single click" pra abrir os diretórios, mas já é infinitamente melhor que o "finder" do Mac.
Talvez o konsole algum dia também apareça nessa lista.
Enquanto isso não acontece, esse aqui é o link do Jenkins:
Eu já passei do tempo de comentar sobre esse assunto aqui, então hoje vou aproveitar que perguntaram sobre esse tema e escrever o que tenho feito.
Primeiro eu preciso explicar mais sobre meu dia à dia no trabalho. O que faço é compilar código em Go, criar e configurar helm charts e gerar containers. Pra isso temos um containers base de desenvolvimento que criamos baseado em Ubuntu 20.04 (e que precisamos atualizar pro 22.04 algum dia). Com o brew eu instalei todas as ferramentas que preciso e uso como o próprio compilador Go, fish shell, Python, git, kubectl, helm, etc. A única coisa foi que precisei alterar o meu PATH pra ler do brew ao invés do PATH normal. Então eu tenho algo como:
if [ "$OperatingSystem" = "Darwin" ]
set -gx PATH /opt/homebrew/bin /opt/homebrew/sbin $PATH $HOME/bin $HOME/.local/bin $HOME/go/bin
end
nas minhas configurações do fish.
Um dos motivos de forçar isso é que o bash que vem no Apple é uma versão muito velha. Então é melhor rodar a versão mais recente através do brew. E descobri que alguns scripts dava problemas com... getopts. Sim, o programa que usamos pra ler opções de scripts. Até isso precisei usar o que vem do brew. Aparentemente o Apple tem um getopt que é BSD e não funciona com as configurações da GNU. Mas seu script não sabe disso. Então tive de forçar a precedência dos binários do brew.
$ which -a bash
/opt/homebrew/bin/bash
/opt/homebrew/bin/bash
/bin/bash
$ /opt/homebrew/bin/bash --version
GNU bash, version 5.2.2(1)-release (aarch64-apple-darwin21.6.0)
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
$ /bin/bash --version
GNU bash, version 3.2.57(1)-release (x86_64-apple-darwin21)
Copyright (C) 2007 Free Software Foundation, Inc.
$ which -a getopt
/opt/homebrew/bin/getopt
/opt/homebrew/bin/getopt
/usr/bin/getopt
$ /opt/homebrew/bin/getopt --version
getopt from util-linux 2.38.1
$ /usr/bin/getopt --version
--
Além disso precisei mudar quase todos os shebangs dos shell scripts pra #! /usr/bin/env bash pra evitar rodar com o bash do sistema.
E como bom usuário de Linux eu não uso nada que tenha de pagar. Nem na loja da Apple eu registrei. Aliás criei um login e entrei pra baixar o skitch pra usar de screenshot saver como usava o flameshot, já que o que vem com o sistema é miserável o uso. Mas o restante eu instalo tudo via brew. E assim instalei o UTM, que na loja da Apple é pago mas via brew é só instalar e usar.
Por baixo do UTM roda tudo em qemu. Mas ele tem uma interface bacana de gerenciamento.
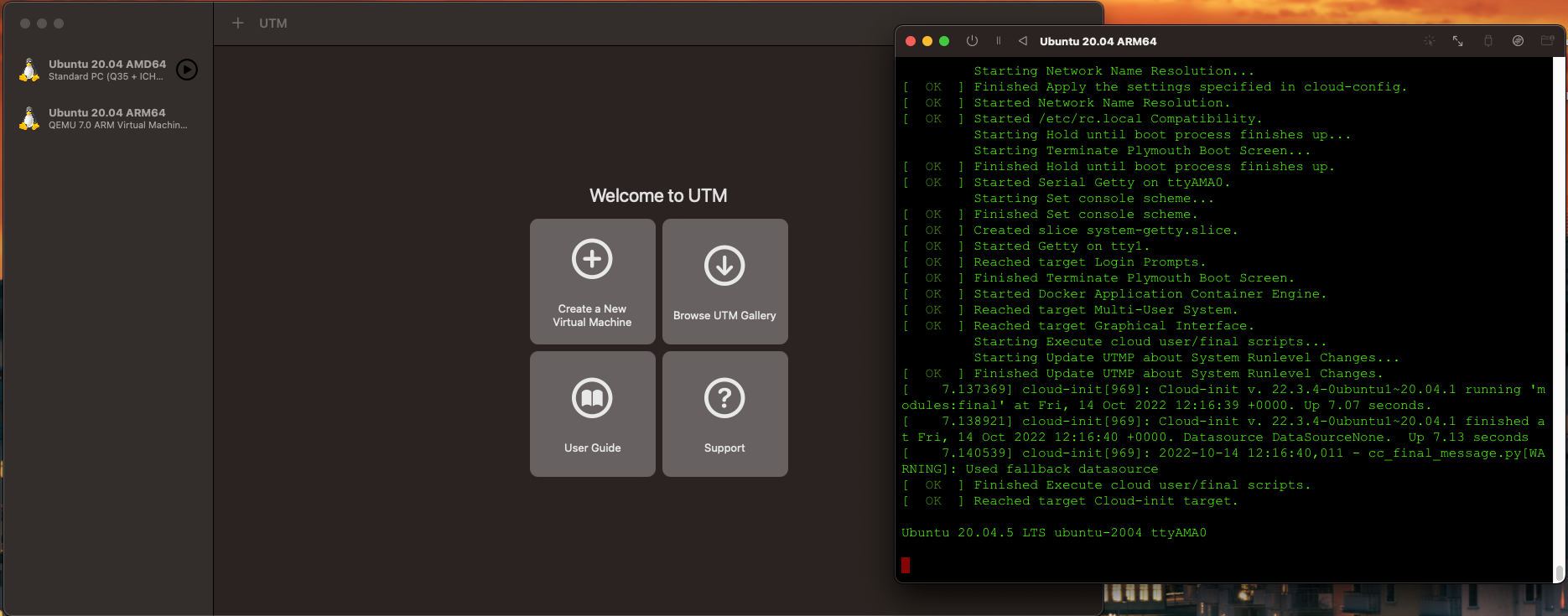
Eu instalei um Ubuntu 20.04 x86_64, chamado de amd64 (e guarde esse nome), e armv8, chamado de aarch64 ou arm64. Eu uso mais a versão pra ARM porque essa roda via VM usando a CPU nativa e é bem rápida, enquanto o x86_64 é via emulação e é bastante lento, além de ter problemas na emulação de tempos em tempos.
Nesse Linux eu instalei um pacote recente do qemu estático pra poder rodar o Docker multiplataforma.
# Latest qemu for docker/bob
RUN curl -OL http://ports.ubuntu.com/ubuntu-ports/pool/universe/q/qemu/qemu-user-static_6.2+dfsg-2ubuntu6.4_arm64.deb \
&& dpkg -i qemu-user-static_6.2+dfsg-2ubuntu6.4_arm64.deb \
&& rm qemu-user-static_6.2+dfsg-2ubuntu6.4_arm64.deb
Como são binários estáticos, você pode pegar qualquer pacote, inclusive do Debian mesmo, e instalar. A versão que vem com o Ubuntu dá um crash no kernel do Apple e reboot o laptop, então pegue essa última versão e tenha certeza de ter aplicado os últimos patches de seguranças do Macos.
Agora começa o balaio de gato de plataformas. O pacote, como pode ser visto acima, é chamado "arm64". Mas se eu entro no meu terminal no Apple, o que tenho é isso:
$ uname -m
x86_64
$ uname -a
Darwin EMB-QG9ND6H2 21.6.0 Darwin Kernel Version 21.6.0: Mon Aug 22 20:19:52 PDT 2022; root:xnu-8020.140.49~2/RELEASE_ARM64_T6000 x86_64
e dentro da VM rodando Linux/arm64:
$ uname -m
aarch64
$ uname -a
Linux ubuntu-2004 5.4.0-128-generic #144-Ubuntu SMP Tue Sep 20 11:03:09 UTC 2022 aarch64 aarch64 aarch64 GNU/Linux
então já começa o balaio de gato aí. O Apple acha que ele é um x86_64, o que não é verdade. Linux diz que é aarch64, mas os pacotes referem-se à arm64.
Pra fazer isso você entra na configuração do Docker e adiciona a seguinte linha:
"experimental": "enabled"
isso habilite o build em múltiplas plataformas. Ou chamar o container de outras plataformas.
Então pra fazer um build x86_64 você usa algo como:
$ docker build --platform=linux/amd64 .
e um exemplo baixando um container baseado em alpine e usando:
$ docker pull --platform=linux/amd64 quay.io/aptible/alpine
Using default tag: latest
latest: Pulling from aptible/alpine
207e252fc310: Pull complete
8a9527e58fed: Pull complete
cdb7f38bc74b: Pull complete
3eb2d0c301f8: Pull complete
Digest: sha256:9790231800450f0e5fb93c03aecd22de0d5d43ae9898aa713350bdbeb9bd1e70
Status: Downloaded newer image for quay.io/aptible/alpine:latest
quay.io/aptible/alpine:latest
$ docker run --rm --platform=linux/amd64 quay.io/aptible/alpine uname -a
Linux 249590268d5c 5.4.0-128-generic #144-Ubuntu SMP Tue Sep 20 11:03:09 UTC 2022 x86_64 Linux
E pronto. Lembram que escrevi acima sobre a bagunça de nomenclaturas e que o amd64 era usado em algum momento? Pois olha ele aí.
Mas nem tudo são flores. Descobri alguns problemas quando parte do nosso build usa ferramentas feitas em... Java! Ou o container trava (e por sua vez a instância do qemu rodando) ou gera um core dump.
O erro é o mesmo descrito aqui:
https://github.com/adoptium/temurin-build/issues/893
mas eu acho que o bug não do openjdk ou do jdk, porque testei também com o jdk da própria Oracle, mas da emulação do qemu.
Isso foi no começo da minha aventura. Depois de um tempo eu vi um vídeo sobre o Rancher Desktop e resolvi testar. Primeiro que tive de configurar pra usar Docker nativo.
Pra rodar o rancher corretamente eu precisei solicitar acesso root à máquina via sudo, que não é dado por padrão e é preciso solicitar. Mas após isso, roda a partir do próprio macos sem precisar da VM.
$ docker pull --platform=linux/amd64 quay.io/aptible/alpine
Using default tag: latest
latest: Pulling from aptible/alpine
207e252fc310: Pull complete
8a9527e58fed: Pull complete
cdb7f38bc74b: Pull complete
3eb2d0c301f8: Pull complete
Digest: sha256:9790231800450f0e5fb93c03aecd22de0d5d43ae9898aa713350bdbeb9bd1e70
Status: Downloaded newer image for quay.io/aptible/alpine:latest
quay.io/aptible/alpine:latest
$ docker run --rm --platform=linux/amd64 quay.io/aptible/alpine uname -a
Linux 1a7f8e55ce09 5.15.57-0-virt #1-Alpine SMP Fri, 29 Jul 2022 07:15:20 +0000 x86_64 Linux
mas sofre do mesmo problema que o UTM em relação ao Java. No momento eu tenho usado mais a VM no UTM por ser um pouco mais rápida que o container no Rancher Desktop/Docker. E o que faço é trabalhar no Macos, geralmente usando VSCode da Microsoft mesmo, e mandando um git push pro meu repo na VM. E lá rodando testes.
Não é um workflow muito prático, mas pra mim tem funcionado bem.
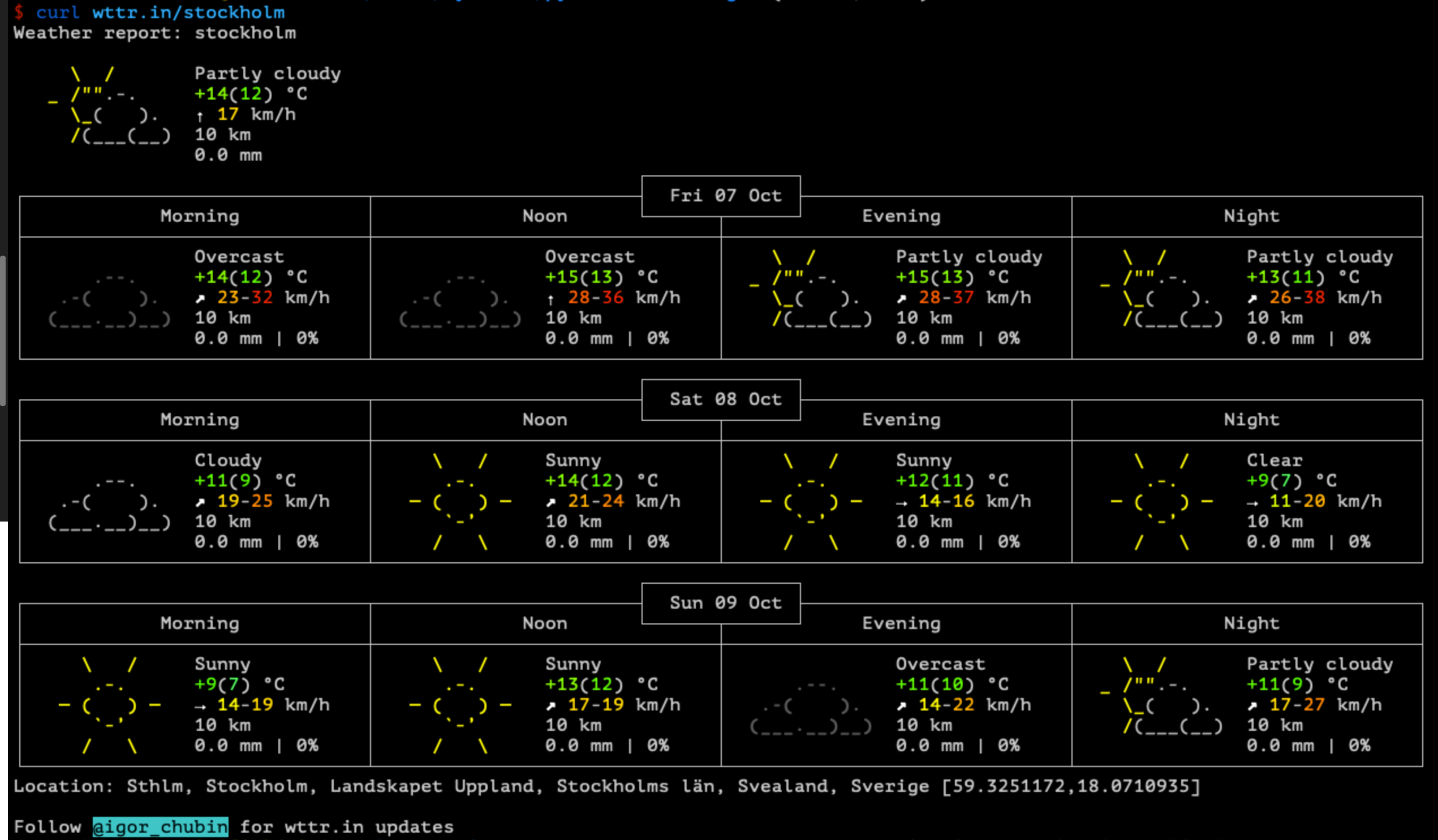
Hoje mandaram essa dica legal na firma. Você pode puxar a previsão do tempo no shell usando curl e apontando pra wttr.in/<cidade>.
Bem legal a ideia e prática.
E o código fonte está no github: https://github.com/chubin/wttr.in
 Existem vários sites na Internet que fornecem a informação de qual IP você está usando. Eu uso bastante pra verificar se minha conexão via TOR está funcionando corretamente.
Existem vários sites na Internet que fornecem a informação de qual IP você está usando. Eu uso bastante pra verificar se minha conexão via TOR está funcionando corretamente.
Infelizmente os sites que fornecem essa informação passaram a pedir alguma forma de autenticação ou aprovação de cookies, o que é muito chato uma vez que só quero a informação do IP.
Então pra resolver o problema eu fiz eu mesmo um CGI pra dizer qual IP acessou o site. É simples, mas funcional. Divirtam-se!
Se chegou aqui e ainda não leu os outros artigos, então pare e leia agora:
Como o verão foi realmente muito, muito, mas muito bom, eu acabei escrevendo pouco. Então vamos retomar aqui a série falando da Suécia e descrevendo o sistema de saúde daqui.
O sistema funciona com um médico do bairro. O posto de saúde é chamado vårdcentralen (vórdicentralen) e você ou vai até ele e faz um cadastro lá, ou faz online através do 1177, que explico melhor mais pra baixo. Nesse médico do bairro você geralmente é designado pra um médico e esse médico vai cuidar de tudo de você. Então não é um médico especialista, mas um generalista que olha o que você tem e termina o atendimento em 10 ou 15 minutos. Então se tem dor no lado esquerdo do peito e acha que é coração, não vai pra uma cardiologista, mas vai pra esse médico que vai iniciar o tratamento. Talvez receite remédios, mas pode outras vezes receitar somente exercícios. No caso de ser algo mais complexo ou mesmo o tratamento não der o resultado esperado, esse médico vai te passar pra um especialista. Pode ser na mesma clínica do bairro ou num lugar especializado, dependendo do caso. Esse médico especialista aí sim já é um cardiologista, ou o que for referente ao tratamento que precisa.
O sistema de saúde então funciona de forma a desafogar os especialistas de atenderem casos que podem ser tratados com remédios mais simples ou que nem mesmo são para eles. Segundo que barateia o acesso à saúde. E quanto é esse acesso? É gratuito? Não. Para crianças e jovens até 21 anos o médico é gratuito (ou pago pelos nossos impostos como todo liberal gosta de apontar). Depois dos 21 anos você paga uma quantia por consulta. Atualmente está 250 coroas suecas cada consulta. E existe um teto, que deve ser por volta de 2500 coroas suecas (não tenho certeza dos valores atualizados). Acima desse teto o governo cobre o tratamento. Então você tem literalmente que pagar 10 idas ao médico por ano e acima disso (um tratamento crônico) sai de graça (liberal já se doendo de mim). Nem todas as clínicas são 250 coroas. Algumas são mais caras. Eu fui numa especializada em olhos quando arranhei meu olho na máquina fotográfica (longa estória que é melhor contar com cerveja junto numa mesa de bar) e cobraram na época 400 coroas. Mas o teto mantêm-se. E nos tratamentos possíveis inclui-se psicólogos por exemplo. Então fazer terapia aqui custa no máximo 2500 coroas por ano.
Existe também uma ajuda governamental em relação aos remédios. Se você faz uso do medicamento extensivamente, vai ficando barato até atingir também esse teto anual, mas é um outro valor e não tenho ideia de quanto é. Mas existe (e eu felizmente nunca cheguei lá). Então se está aqui com alguma doença como alergia, saiba que comprar remédios sem receita na farmácia podem custar muito mais que comprar com receita.
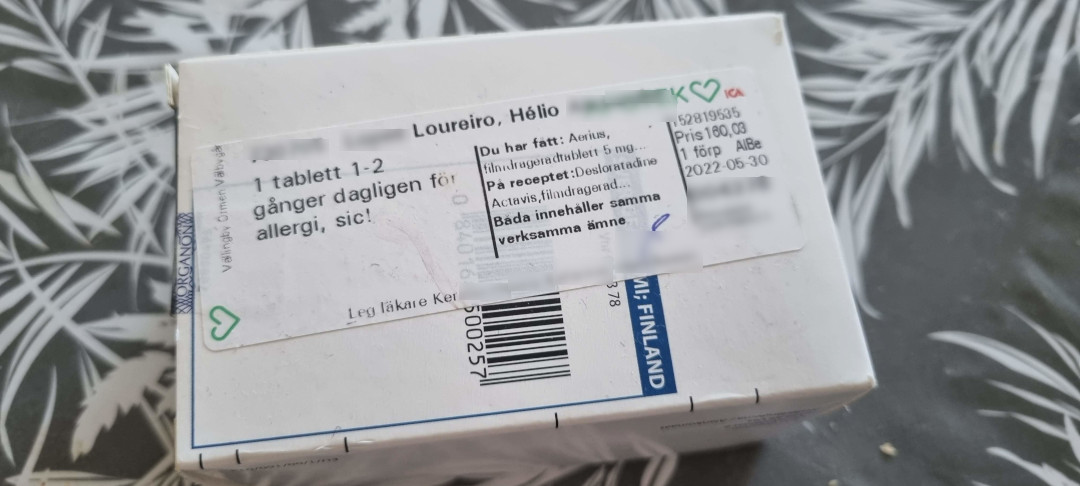
E como compramos com receita? Aqui tudo é digitalizado. Então você só mostra sua identidade na farmácia e pelo seu "personal number" eles olham o que pode pegar de remédio. E cada remédio recebe uma etiqueta com seu nome, nome do médico responsável, e farmácia onde comprou. Então pode ser traçado pra origem no caso de viagem pela Europa com o remédio. E não existe a menor possibilidade de comprar um remédio que alguém precise no Brasil porque aqui é mais barato.
Passando de médico do bairro pra emergências, existem os hospitais. Mas ir direto pra emergência, akutmottagningen, pode não ser uma boa solução. A emergência aqui é para somente... emergências mesmo. Estar realmente morrendo. Chegar lá com um corte ou tosse pode fazer com que aguarde de 4 a 8 horas por um atendimento. Até então eu não tinha outra ideia sobre emergências aqui até uma das crias sofreu um acidente na escola e tive de ir lá pra pegar e levar pra emergência. E na escola informaram que eu deveria não ir pra emergência, mas pra um "pronto socorro" que é o näravårdcentralen. E realmente o atendimento foi rápido: coisa de 15 minutos. E como era pra criança, não houve cobrança (chora liberal, chora).
Mas esse é o sistema de bairro. E existe o sistema nacional, que mencionei no começo: o 1177. Como o nome parece, 1177 é o número de telefone pra ligar e falar com o sistema de saúde. É possível ligar pra tirar dúvidas ou perguntar o que fazer em caso de emergência. Ficam disponíveis 24x7. E existe o site, o https://1177.se que pode ser acessado pra tirar as mesmas dúvidas ou acerta seu cadastro. É onde você cadastra em qual posto de saúde quer ser tratado. Pode ser qualquer um, desde o mais próximo de sua residência, até o mais próximo do trabalho caso ache mais conveniente ir ao médico durante o período de trabalho. A vantagem do telefonema ao 1177 ao invés do site é que você consegue um atendente que fale inglês enquanto que o site é somente em sueco.
E como são os atendimentos aqui? Você tem direito a um tradutor no seu idioma. E é gratuito (chora liberal, chora). Ele vai lá e fica falando com o profissional de saúde e traduzindo tudo. No começo eu cheguei a usar até ficar confortável com somente inglês. Mas mesmo assim é sempre bom perguntar antes se o médico sabe inglês. Houve casos em que precisei pedir tradutor (geralmente com médicos que vieram de outro país e falam só sua língua e sueco). Eu não sei como funciona atualmente via vídeo conferência, mas acho que o tradutor também entra na conversa. E falando nesse assunto, aqui já é bem comum ter os tratamentos via vídeo conferência. Você conversa com o médico, que se precisar de exames apenas diz onde deve ir pra fazer a coleta. E claro que o médico deixa a opção de encontrar em pessoa com você, mas eu já não vou a um consultório faz uns 3 anos.
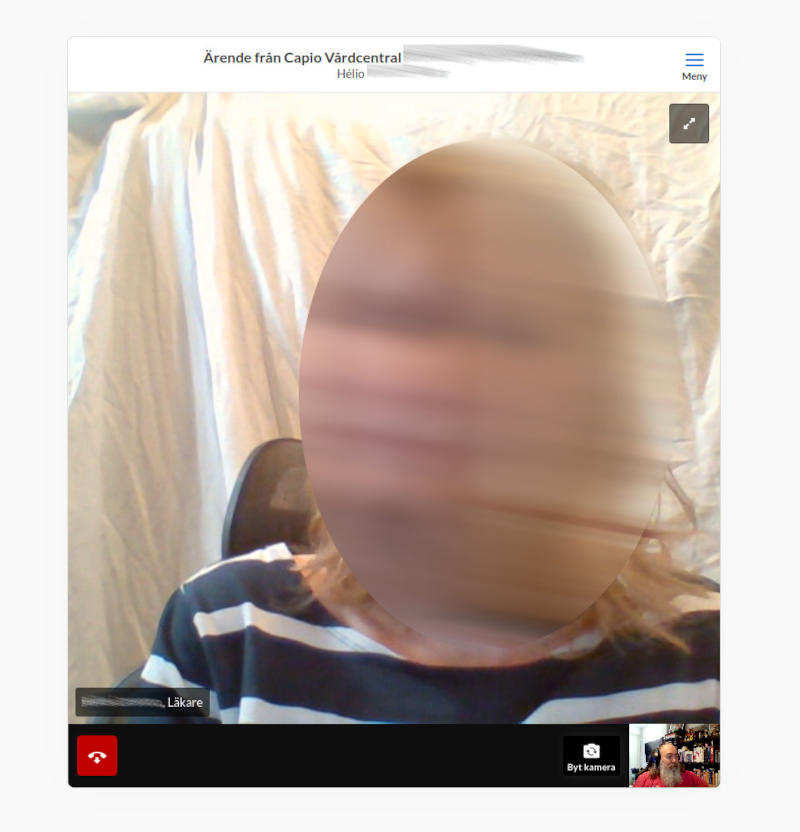
Antes da pandemia já existiam alguns apps dedicados pra esse tipo de serviço como Kry e Doktor. Mas com a pandemia as vídeo chamadas com o médico virou o lugar comum. E pra pedir mais medicamento não é preciso nada disso: você pode entrar pelo 1177.se e escrever que precisa de mais receita pra um remédio que faz uso. E o médico olha online e adiciona pra você. Sem custo.
E vou contar um caso do médico aqui que passei logo que cheguei na Suécia. Nessa época eu estava em um apartamento alugado com móveis, e a cama não era das melhores pra mim. Aqui é comum o colchão ser extremamente mole, de afundar dentro dele. E isso causa uma dor terrível nas minhas costas. Então marquei o médico, fiz o primeiro atendimento que passou pro especialista. Daí disseram que por ser especialista, iria demorar mais pra marcar. Quanto tempo? 2 semanas. Eu tive de me segurar pra não rir. Mas chegado o dia do atendimento com o especialista em ortopedia (o médico não era do posto de saúde, mas foi até lá só pra ver meu caso), eu fui esperando o médico pedir um raio-x, tomografia, etc e ele somente disse pra eu trocar o colchão e pedir na empresa uma visita do especialista em ergonomia, que é algo obrigatório em empresas grandes aqui pelo que entendi. E passou alguns remédios caso eu sentisse dores novamente e era pra remarcar dali 1 mês se as dores continuassem. Eu sai da consulta em completa descrença da coisa toda. Mas eu sabia do problema do colchão no apartamento em que estava. E marquei a visita da pessoa de ergonomia da empresa. Essa visita foi a mais interessante. Depois de uma análise de como eu trabalhava sentado e em pé (as mesas aqui têm regulagem de altura, inclusive essa que tenho em casa), a pessoa disse que eu tinha um problema de postura ao sentar. Eu sentava meio inclinado e de um jeito que minhas costas faziam um "C" na cadeira. Daí ela me explicou como regular minha cadeira, que parece feita pela NASA de tantos botões e alavancas, e mostrou que o correto é trabalhar com as costas completamente retas, pra lombar sustentar o peso. E... não preciso de muito spoiler mas esse era o problema (e por isso que recomendo cadeiras gamers em que as costas ficam retas).
Tem quem diga aqui que o sistema médico é muito lento por passar por tantas etapas pra chegar num especialista, mas é um sistema que funciona. Tem lá seus problemas, como o fato dos médicos todos desaparecerem durante o verão e coisas mais complexas como cirurgias levarem quase 1 ano pra serem feitas, mas é um sistema acessível e que funciona. Existe também o problema de que fora dos grandes centros, o acesso a um médico especialista é quase impossível. E foi um dos grandes temas durante as últimas eleições, então acredito que mudanças virão pra melhorar. Eu, de minha parte, gosto do sistema e tem me servido bem.

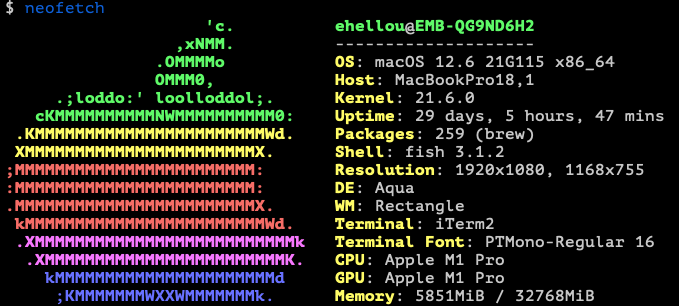
Depois de tantos anos de somente mundo Linux, eu me rendi ao mundo Apple. No refresh da firma optei por um Macbook 16" com processador Apple Silicon, um ARM64.
A primeira coisa foi que "brew" é uma maravilha. Instala quase tudo quanto é programas que precisamos. Bem parecido com o "apt" no geral, só trocando "remove" por "uninstall".
Eu ainda estou apanhando com as teclas de atalho, mas aos poucos vou botando pra funcionar. Eu consegui fazer quase tudo que precisava nativamente usando Go, python, nerdctl e podman. Inclusive gerando containers Linux/amd64 diretamente nele. Mas coisas que usamos internamente têm o docker-in-docker, o que não consegui fazer funcionar ainda.
Então estou usando o UTM.app pra rodar o qemu e emular uma máquina x86_64 com Linux. E roda lento, mas muuuuuito lento.
Devo postar algumas coisas aqui sobre a descoberta do uso do Macos como primeiro sistema operacional.
Se chegou aqui e ainda não leu os outros artigos, então pare e leia agora:
Eu já fiz minha reclamação de velho rabugento sobre o inverno. Agora é hora e a época do ano pra falar um pouco sobre o verão.
O verão na Suécia é lindo e maravilhoso. Só que é curto. O tempo começa a esquentar mesmo em junho. Antes disso temos alguns dias mais quentes, mas em geral as noites são bem geladas.
Mas o que começa a pegar bastante em junho não é a temperatura mais quente, mas o sol. Muito de sol.

Essa foto eu tirei à 01:10 da manhã. Estava vendo filme e fui dormir mais tarde. Durante boa parte de junho e julho não tem noite. Fica nesse entardecer e o sol volta. O solstício de verão, dia mais longo do ano, ocorre em 21 de junho.
É maravilhoso. Você fica num bar, aquela cara de fim de tarde e quando vai olhar já são 2 horas da manhã.
O ruim é pra dormir. Ou mesmo ver filmes. Você tem de ter as janelas bloqueadas com blackout ou alguma outra curtina pesada dessas.
E a criançada brinca nos parques até 22:00 como se não houvesse amanhã.
Durante a apresentação do grande prof. Júlio Neves na BSD Day 2022 sobre shell, ele fez uma comparação interessante sobre shell ser dito lento. E mostrou o seguinte slide:

Eu achei muito interessante o exemplo, mas resolvi testar ele pra valer.
Então testei não com 200 interações, mas com 20 milhões. Daí sim a coisa fica mais interessante.
Fiz o mesmo script em shell:
#! /usr/bin/env bash
for ((i=1; i<20000000; i++)) {
: > arq-shell
}
Em python:
#! /usr/bin/env python3
for i in range(20000000):
with open("arq-python3", "w") as fd:
None
em perl:
#! /usr/bin/env perl
for ($i=0;$i<20000000;$i++) {
open(FD, ">arq-perl");
}
e finalmente em Go:
package main
import (
"log"
"os"
)
func main() {
for i := 0; i < 20000000; i++ {
fd, err := os.Create("arq-go")
fd.Close()
if err != nil {
log.Fatal(err)
}
}
}
Os resultados foram os seguintes:
helio@goosfraba /t/comparacao-shell> time ./20M-touch.sh
________________________________________________________
Executed in 303.69 secs fish external
usr time 164.93 secs 0.00 micros 164.93 secs
sys time 133.79 secs 533.00 micros 133.79 secs
helio@goosfraba /t/comparacao-shell> time./20M-touch.py
________________________________________________________
Executed in 374.49 secs fish external
usr time 225.16 secs 623.00 micros 225.16 secs
sys time 143.90 secs 125.00 micros 143.90 secs
helio@goosfraba /t/comparacao-shell> time ./20M-touch.pl
________________________________________________________
Executed in 173.94 secs fish external
usr time 47.95 secs 1.05 millis 47.95 secs
sys time 122.10 secs 0.00 millis 122.10 secs
helio@goosfraba /t/comparacao-shell> time ./20M-touch
________________________________________________________
Executed in 147.80 secs fish external
usr time 45.82 secs 579.00 micros 45.82 secs
sys time 107.38 secs 113.00 micros 107.38 secs
Eu achei os resultados um pouco miseráveis pra python. Então re-escrevi a função como era feito desde o python 1.2 (usando 3.10.4):
#! /usr/bin/env python3
for i in range(20000000):
fd = open("arq-python3", "w")
fd.close()
e o resultado não melhorou muita coisa.
helio@goosfraba /t/comparacao-shell> time ./20M-touch.py
________________________________________________________
Executed in 370.23 secs fish external
usr time 218.59 secs 641.00 micros 218.59 secs
sys time 146.02 secs 132.00 micros 146.02 secs
Acho que agora os números falam por si só sobre shell ser lento ou não. Claro que pra coisas mais simples é bem mais fácil fazer em shell, mas isso não significa um desempenho melhor.
Tirando essa parte de desafio, a palestra foi espetacular. Quem não viu, recomendo que assistam.
Andei ocupado e escrevendo pouco aqui no site. Parte porque estava preparando uma apresentação sobre Go pra BSD DAY desse ano.
E aqui está a gravação da apresentação.
Como já é a segunda palestra com Go sobre o mesmo assunto, deve também ter sido a última. Resta agora pensar no que vou falar na próxima. Estou trabalhando em alguns projetos pessoais em Go, mas como nenhum chegou num ponto bom de usabilidade, não tenho o que apresentar ainda. Mas vamos ver se consigo avançar.
Como os eventos estão voltando ao modo presencial, também deve ser difícil eu continuar apresentando algo no Brasil. Talvez algo aqui na Europa e muito provavelmente aqui na Suécia. Veremos.
Faz muitos anos eu me inscrevi em sites de emprego. Reflexo da época em que fui demitido da D-Link (longa história que só conto em mesa de bar e acompanhado de muita cerveja).
Mas recentemente eu comecei a receber ofertas... bastante inusitadas.

Essa é até que razoável. Trabalhar pra vendas de alguma startup, mas na região de Ribeirão Preto. Não lá muito próximo de onde eu morava, nem mesmo na área específica em que trabalhava mas...

Promotor de vendas, com abordagem de rua... para primeiro emprego??? As coisas começaram a ficar estranhas. Talvez algo no meu currículo ligue meu perfil com vendas diretamente, uma vez que trabalhei como engenheiro de pré-vendas. Mas promotor de vendas com abordagem de rua?

E novamente auxiliar de vendas. Então acho que os algoritmos encontraram em mim uma carreira que eu nunca fui atrás em desenvolver. Devo ser uma pessoa chave pra vendas.
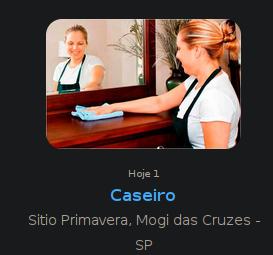
Espera... o quê!? Caseiro? Eu??? De onde será que o algoritmo tirou isso do meu currículo?

Ajudante geral... nesse ponto eu já acho que algoritmo partiu simplesmente pra zoeira. Só pode ser isso.
E esse foi só um dos e-mails que recebi. Tem vários outros que vão na mesma direção. Um até sugeriu trabalho em uma funerária.
Eu não sei como esse pessoal de sites de empregos fazem esses algoritmos, mas pelo jeito é à base de muita, mas muita, mas muita zoeira.
*Nota: esse artigo foi originalmente escrito pra Revista Espírito Livre, mas como a edição não saiu estou postando aqui.

Olá leitores da Revista Espírito Livre. Eu venho do futuro pra falar sobre os 30 anos de Linux. Futuro muitos anos à frente? Sinto mas estou apenas algumas horas adiantado devido ao timezone em que vivo. Mas tenho um certo prazer em dizer que celebrei a chegada do ano novo antes que todo mundo no Brasil, e avisando o que os aguarda do futuro (geralmente nada). E vamos ser sinceros: no mundo de hoje com tanta gente acreditando em terra plana, rejeitando vacinas e tomando cloroquina, dizer que venho do futuro é até uma licença poética aceitável.
Mas vamos voltar ao assunto do artigo: Linux. E seus 30 anos de vida. Foi uma comemoração bem moderada, sem grandes festas, sem bolo pra comemorar, e nenhuma meetup organizada. Ao menos por aqui. Talvez a culpa fosse da pandemia. Talvez fosse porque Linux já é tão comum e seu uso é diário, o que não nos faz mais sentir que seu aniversário é uma data especial. Mas são 30 anos desde que um estudante finlandês tentou escrever um minix melhor que o minix, um sistema operacional Unix para estudantes, e achou que nunca seria tão grande quanto o projeto GNU.
Não, não vou entrar na polêmica de quem é maior que quem entre GNU e Linux. Ambos têm seus méritos e são gigantes. E não estaríamos onde estamos sem eles. O projeto GNU já completou 38 anos também no dia 27 de setembro, mas o artigo é sobre Linux. Então deixo meus parabéns ao projeto GNU mas tenho de dizer que mesmo o sistema operacional mais comum que usamos pelas distros sendo um GNU/Linux, é Linux que o chamamos. Isso começou desde muito tempo atrás e duvido que mude algum dia. Alguns podem insistir em chamar de GNU/Linux, mas se até mesmo o Debian mudou de Debian GNU/Linux pra simplesmente Debian, que diremos de Linux além, é claro, de apenas Linux? Nomes curtos têm tendência a ficar melhores e as pessoas relacionam-se com isso mais facilmente.
Parte dessa tradição de denominação veio como herança de como eram os sistemas Unix nos princípios dos tempos, ou anos 70 em Unix time. Primeiro existiu o Unix da AT&T, em seguida surgiu uma melhoria desse que ficou conhecida como BSD, de Berkeley. E assim foi por quase 10 anos. O Unix BSD era basicamente o mesmo Unix, mas com drivers, ferramentas, scripts e até sistema de boot de Berkeley. E era o sistema operacional completo, com kernel, bibliotecas, editores, shell, etc. Mesmo os sistemas que surgiram da compra da licença do Unix da AT&T, como SunOS da Sun – atual Oracle, eram sistemas operacionais completos mas com nomes curtos como SunOS, HP-UX, SCO, Xenix, etc.
Quando o bom doutor, Richard Stallman, teve a epifania de criar um sistema operacional totalmente livre, o sistema operacional GNU – pra poder dizer que GNU não era Unix (GNU is Not Unix), nunca pensou em criar tudo de forma coesa. Ele começou da forma simples e em partes. Primeiro as ferramentas: editor (se bem que emacs é mais uma religião que editor mas isso é assunto pra outro artigo bem mais longo que esse), compilador, shell, etc. Mas tudo era separado em seu repositório e era necessário baixar os fontes e compilar sua versão usável. Então nunca houve uma identidade de sistema operacional GNU. Era a biblioteca sunsite com ferramentas GNU. Até surgir o Linux e permitir criar um sistema operacional completo. Claro que pra isso foram necessários os surgimentos das distros, um encurtamento para distribuições, que empacotavam o Linux com GNU e distribuíam como sistema operacional.

E Linux nasceu como um kernel, como já descrevi antes no “um minix melhor que o minix”, mesmo que Tannenbaum discordasse disso, e cresceu tanto em linhas quanto em contribuidores e até mesmo em ecossistema. Hoje em dia Linux é um projeto, uma fundação. E abrange de redes à containers com OCI, Open Container Iniciative. E apesar de ter nascido pra rodar software da GNU como bash e ser compilado com GCC, hoje em dia já roda em sistemas sem nada da GNU como Alpine e Android. E compila com o llvm. Não totalmente como com GCC, mas é um trabalho em andamento e deve em algum momento tornar o Linux compilável com qualquer compilador C. Isso sem comentar o suporte à linguagem rust, que poderá talvez nos próximo 10 anos virar boa parte do código do kernel. Talvez até a maior parte dele. Quem sabe?
Desses 30 anos eu já comentei sobre os surgimento das distros. Falta escrever sobre o desaparecimento delas. Atualmente o site distrowatch, famoso por enumerar as distros que surgiam, parece mais um obituário. A grande maioria das distros que surgiram também sumiram. Não que alguém vá sentir falta da Bieber Linux ou da Hanna Montana Linux, mas sei de gente que até hoje chora a perda do – um momento pra respirar e segurar a náusea – kurumin. A maioria dessas distros recebeu a alcunha carinhosa no Brasil de REFISEFUQUIs. Aqui peço a ajuda ao amigo Fábio Benedito pra descrever o que são:

As REFISEQUIs mostraram um lado interessante sobre a liberdade do software livre: cada um podia e ainda pode fazer um fork de alguma distro e criar a sua própria. Ao contrário das distros que contavam com legiões de voluntários ou funcionários, dependendo se fossem empresas ou projetos voluntários como Fedora e Debian, as REFISEFUQUIs eram batalhas de um soldado só. Talvez dois. Mas não muito mais que isso. Conseguiam fazer o primeiro release, o segundo, então o... o... o... acabava o gás. Talvez algumas tenham ido um pouco mais longe que isso, mas ninguém sobrevive ao tempo sem organização e principalmente mãos pra ajudar a manter tudo funcionando. Talvez o propósito fosse somente ter seu sistema listado na distrowatch. Nesse caso tenho de admitir que a missão foi cumprida. Amigos, amigos, negócios à parte.
E o que dizer das empresas? Nesses 30 anos muitas delas surgiram pra levar o Linux pra todos como principal sistema operacional do desktop. Inclusive com a versão tupiniquim com a Conectiva. E eram muitas. Infelizmente o cenário atual conta com apenas algumas delas. As que não faliram sofreram um processo de compra ou fusão. E eventualmente faliram. Talvez a venda de software gratuito não fosse tão bom negócio assim? A venda da Red Hat pra IBM por mais de 34 bilhões de dólares dizem o contrário. O que faltou então? Talvez menos geeks programadores e mais pessoas de negócios gerenciando a empresa? Talvez. A verdade é que muita coisa foi feita sem muito planejamento e só imaginando bastasse o software ter licença GPL ou qualquer outra livre e seria o suficiente pra empresa sobreviver. Infelizmente a realidade mostrou que não era bem isso.

E não só de dramas empresariais viveu o Linux nesses 30 anos. Teve também o caso da vira-casaca Caldera Open Linux, que comprou o que sobrou da SCO e aplicou um processo por roubo de propriedade intelectual contra o Linux. O caso ficou anos num tribunal e finalmente teve um fim. Os gestores da massa falida da empresa, que por motivos óbvios não conseguiu sobreviver no negócio, fechou um acordo muito bom de mais de 14 milhões de dólares com a... IBM!? Não me perguntem o porquê da IBM ter sido envolvida em suposto roubo de propriedade intelectual do Linux, mas no fim ela comprou o que sobrou de patentes e propriedade intelectual e encerrou o assunto.
Outro caso de tribunal nesses 30 anos de Linux que ficou muito famoso foi a prisão de Hans Reiser, criador do filesystem reiserfs, um dos primeiros filesystems com journaling no Linux e que eu pessoalmente cheguei a usar, acusado de assassinato. Não que sua prisão tenha alguma relação com Linux. Pelo contrário. Mas foi algo que impactou a direção dos filesystems em Linux, que estavam em suas infâncias no mundo journalling. Depois de sua prisão eu fui movido por, digamos, forças superiores a usar o XFS que foi doado pela SGI ao Linux. E até hoje é meu filesystem predileto, junto com LVM.
Outro drama vivido na lista do kernel durante esses 30 anos foi o eventual sumisso do próprio Linus Torvalds seguido da introdução de um código de conduta,vonde ele mesmo aceitava que tinha um comportamento tóxico e que precisa fazer terapia para endereçar seus problemas de uma melhor maneira. Não faltou gritaria em relação ao código de conduta com ataques dizendo que o mesmo iria coibir a participação das pessoas no desenvolvimento do kernel. Atualmente ninguém questiona o quão benéfico foi esse código de conduta, assim como quão tarde veio a ser adotado. E, claro, ainda há quem diga que ele motivou muita gente a não participar mais do desenvolvimento. Quantos? Esse será um dado que nunca veremos.
E ao longo desses 30 anos do Linux vimos também a grande batalha dos sistemas de inits, onde systemd saiu como vencedor e upstart virou lembrança. De todos os males ditos sobre o systemd na época, poucos realmente aconteceram, se é que aconteceram. E justiça seja feita: systemd é muito, mas muito mais que um mero sistema de init.
Claro que algumas distros seguem longe do systemd, como se isso fosse algum certificado de pureza. Mas nada que abale a realidade de que systemd funciona, vai muito bem obrigado, e trouxe flexibilidade e robustez ao Linux. Se antes precisávamos de gambiarras pra monitorar se um daemon não tinha dado crash e fechado inesperadamente, agora apenas temos o systemd lá monitorando e garantindo tudo funcionando. Ou quase. Claro que aparecem uns problemas aqui e ali, mas nada que negue o fato de que systemd melhorou muito a forma de como Linux tem seus daemons rodando.
crond? Coisa do passado. systemd tem agendamento de tarefas e substitui completamente o crond, que por sua vez poderia ter um crash e simplesmente parar de funcionar. E não para por aí o canivete suíço de funcionalidades do systemd.
E nesses anos vimos como Linux chegou ao mundo dos games. Primeiramente de forma modesta com jogos portados pela Loki games. Depois de um tempo de silêncio e de abandono, uma voltou triunfante com o suporte da Steam, a gigante de jogos digitais.
Mas mesmo a Steam passou por maus bocados. Sua estratégia de abraçar o Linux foi para fugir dos braços da Microsoft, que na época mudava sua visão sobre jogos com o Windows 8, tentando forçar os jogadores a usarem sua própria loja de jogos. Então pra ter massa de manobra e poder negociar, a Steam abraçou o Linux. E lançou seu próprio sistema operacional chamado SteamOS, baseado no Debian. E foi um sucesso. Ou quase isso.
A quantidade de jogadores em sistemas Linux chegou a dobrar de 1 para 2%. Mas não mais que isso. Apesar de todo o suporte, o uso nunca cresceu como esperado.
Mas foi o suficiente pra dar o que a Steam precisava: algo pra negociar e tempo. E com o tempo o CEO da Microsoft foi trocado, e por um que tanto declarou amar Linux, e abraçou definitivamente dentro da empresa, assim como provavelmente chegou num acordo com a Steam. E ficamos sem muitas novidades.
Isso até pouco tempo atrás, quando a Steam anunciou novamente algo bastante interessante: Steam deck. Basicamente um PC portátil com tela e controle conectados que permite jogar em qualquer lugar seu catálogo de jogos e... rufem os tambores... rodando Linux. Dessa vez a escolha foi o Arch Linux, a nova distro do pedaço que todo mundo ama. Eu incluso.
Essa nova estratégia da Steam muda seu foco de apenas ser uma plataforma digital de jogos pra vender console de jogos, competindo com Playstation, Xbox e Nintendo Switch. Por outro lado a maioria dos jogos continuaram não sendo nativos pra Linux, mas rodando através de um wine melhorado da própria Steam, o proton. Se chegou agora e não conhece o wine, esse é um software que faz uma tradução das chamadas de programas Windows para Linux. O resultado disso é a possibilidade de rodar programas feitos para Windows diretamente em Linux. E nisso acho que a mudança da Steam vai dar uma piorada pra jogos nativos em Linux. Que estúdio gastará tempo e pessoal pra fazer um jogo que rode em Linux quando pode fazer em Windows, o que provavelmente já fazem, e apenas trabalhar pra rodar bem em proton? Então é uma vitória com um certo gosto amargo de derrota.

Todo os anos eu além de dizer que estou no futuro na virada do ano, também digo que o próximo ano será o ano do Linux no desktop. E isso já faz uns... 15 anos? Talvez mais. Tanto que sempre uso a famosa imagem/meme do nerd dizendo isso (que aliás nem sei quem é pra dar os devidos créditos).
E esse ano nunca chegou. Não da forma que eu imaginava pelo menos. Atualmente o laptop chromebook é um dos mais vendidos para área de educação tanto nos EUA quanto na Europa. O Brasil não entra na conta por ainda viver um bom atraso tecnológico, mas aqui na Suécia minha filha tem seu chromebook na escola pra pesquisar e fazer os exercícios escolares. Na Suécia não houve um lockdown como em outros países durante a pandemia, mas alunos do colegial pra cima foram solicitados pra estudarem de casa. E cada um levou seu chromebook pra isso. E isso aconteceu em vários outros países, não somente aqui.
Sem contar que muitos desktops e laptops foram trocados por tablets e smartphones. Eu mesmo leio bastante em meu tablet Android e passo as manhãs lendo as notícias no meu smartphone (que diga-se de passagem tem a tela tão grande que praticamente precisei comprar uma calça nova e experimentar antes se ele cabia no bolso), também Android. Então a realidade de desktop que esperávamos não é mais aquela de 15 ou 20 anos atrás. Virou uma realidade de cloud, nas nuvens.
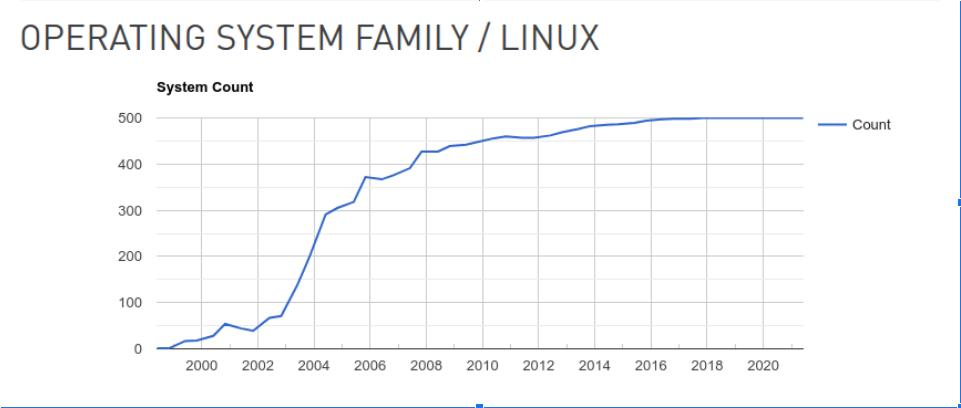
Mesmo que, pra desgosto de alguns, cloud rode no computador dos outros, atualmente é impossível fugir dele. Assim como tablets, smartphones, smartTVs, raspberrypis e muitos outros dispositivos, o cloud roda baseado em Linux. Linux virou o senhor supremo de todas as áreas. De geladeiras a super computadores, sendo presença prepobderante na lista dos 500 mais rápidos super computadores do mundo, sendo liderado atualmente pelo Fugaku do Japão com 7.630.848 núcleos de CPU e impressionantes 537.212 teraflops por segundo de desempenho de pico. Nesse é possível jogar minecraft sem lag.
Mas a discussão é no desktop, aquele ambiente dominado pela Microsoft. Sim, esse mesmo. Estamos em 2021 e ainda hoje as pessoas sofrem com vulnerabilidades e malwares enviados por mail no sistema de Redmond. Praticamente o mesmo problema desde que lançaram o Windows 95. E as pessoas continuam usando mesmo assim. Então eu duvido que Linux consiga entrar nesse mercado onde vírus e ransomware já são tidos como coisas absolutamente normais do dia a dia. Ele ficará naqueles que gostam de ter um sistema melhor, mais rápido e mais seguro.
E a liberdade? Sim, existem aqueles que usarão pela liberdade. E talvez por outros motivos. Mas isso não é importante, mesmo que pra eles sejam. O importante é que usem.
E aqui deixo escrito a mensagem que sempre passei e que sempre indignou muita gente: usem software livre. Não percam tempo com política, liberdade, filosofia, etc. Apenas usem se não for seu caso ainda. Isso abrirá portas para você.
Gostou? Então não fique só na instalação de uma distro. Ou de várias. Linux e outros software livres são baseados em... software. Então entre de cabeça. Aprenda a programar usando shell scripts. Depois vá pra linguagens como perl, python e nodejs. E não pare aí. Entre de cabeça.
Ajude um projeto pois tanto Linux quanto todo o ecossistema de software livre ainda dependem de voluntários, que estão ali pra ajudar e aprender. Então participe. Faça parte. Tenho certeza não se arrependerá.
Finalmente deixo aqui meu viva ao Linux e seus 30 anos.

Hoje é 20 de março e finalmente a temperatura atingiu um nível o suficiente pra abrir as janelas pela primeira vez no ano: 15°C. Peço desculpas pelas manchas de poeira acumalada pelo inverno, mas ainda não foi quente o suficiente pra passar um tempo limpando as janelas pelo lado de fora.
Se chegou aqui e ainda não leu os outros artigos, então pare e leia agora:
Aproveitando toda a emoção que a primavera traz, também recebemos nosso imposto de renda. O órgão que controla a cobrança de imposto é o mesmo que cuida do registro de pessoas, o skatteverket. Aqui na Suécia nós não fazemos o imposto de renda: ele já vem pronto. Então nos resta apenas confirmar os dados e aceitar. E pronto.

Como tudo é ligado com seu número pessoal aqui, fica fácil pro skatteverket saber qualquer receita que recebeu em sua conta no banco, assim como a gastou. Tudo aqui é registrado.
Você pode alterar o relatório de imposto que recebeu adicionando alguns dados a mais, como serviços de limpeza ou empregada, que emitem um recibo chamado RUT onde 50% do valor pago pelo serviço pode ser deduzido do imposto. Geralmente nem é preciso fazer isso pois o prestador de serviço que emite um RUT pra você já faz o registro junto ao skatteverket. Mas a opção de editar o relatório de imposto de renda existe. Só que qualquer alteração no mesmo já significa que está na malha fina. Emitir nota fiscal amiga? Aqui isso não é possível.
A declaração de imposto de renda pode chegar em forma de papel, como essa da imagem acima ou por formato digital se assim preferir, que é meu caso. Você pode responder que está ok pelo site diretamente, ou pelo correio ou até mesmo por SMS. Eu geralmente faço pela página web. Nenhum plugin adicional é necessário. Só entrar, conferir os dados e olhar se tem algo a pagar ou a receber e enviar.
Ouço isso o tempo todo. Então vamos ao números do meu imposto de renda desse ano. Então no ano passado ou paguei exatamente... rufem os tambores... 26.69%. Contando do que recebi o ano todo e de quanto imposto foi devido.
Aqui o imposto é cobrado por faixas salariais como no Brasil, mas tem o imposto progressivo: quanto maior o salário, maior o imposto a ser pago.
Eu não sei bem as faixas como estão hoje em dia, então estou usando a referência daqui: https://everythingsweden.com/tax-in-sweden/

Esse cáculo de 31% depende de onde mora. Se é numa zona com poucos serviços e precisa de desenvolvimento, esse imposto pode chegar à 36%. Como eu moro no subúrbio de Estocolmo, mas ainda parte de Estocolmo, o imposto é mais baixo. É a parte que vai pra manter escolas, dentistas e médicos na sua região diretamente. Então onde o imposto é mais alto o custo de vida é mais baixo, pois é uma região mais afastada. E quanto mais próximo do centro, mais baixo o imposto mas mais alto o custo de vida, incluindo aluguéis.
Algumas coisas que o imposto morde você com força aqui que escorre até uma lágrima quando recebe o salário: horas extras tem 50% de imposto direto em cima do valor pago, "benefícios" pagos pela empresa cobram 50% de imposto em cima, o que inclui até uso de lavanderia em viagem de trabalho e ticket alimentação.
Outro impostos estranhos que são pagos aqui: televisão pública (1300 sek/ano) e tem um imposto-velório, que você tem todo o serviço funerário disponível quando morrer sem precisar de ninguém pagar por nada. Você já pagou durante a vida. Eu não achei quanto é mas é um valor bem baixo.
Update: achei uma referência do imposto de funeral em https://www.scb.se/en/finding-statistics/statistics-by-subject-area/public-finances/local-government-finances/local-taxes/pong/statistical-news/municipal-taxes-2020/

são 25 centavos por mês.
Page 12 of 39
