
Por muitos anos o meu comando preferido pra baixar páginas e até fazer mirrors foi o comando wget. Até eu descobrir o curl.
Não que eu já não conhecesse o curl. Com tantos anos de estrada com Unix, principalmente Linux e FreeBSD, curl era um conhecido que eu evitava usar. O motivo? Zona de conforto. wget era um comando conhecido e que eu sempre usava, desde que ando comecei a aprender Unix, em 1997. curl por outro lado era talvez tão antigo quanto, mas cheio de opções cabulosas que eu sentia um certo receio de usar.
Atualmente eu trabalho bastante com backend web e curl virou meu braço direito. E conforme fui aprendendo a usar mais, fui adorando. Hoje em dia não faço um container que seja sem o curl dentro. E acabei até deixando pra lá o wget mas... hoje é dia de falar de curl.
Durante essa semana no trabalho tivemos um problema de servidor web down. Ao tentar conectar ele ficava um tempo tentando dar a resposta e depois enviava um erro 500 (acho que era 503, mas isso não importa). Então como eu queria acessar o serviço assim qeu estivesse disponível e não queria ficar dando reload na aba do navegador, fiz um script com curl. Ele usa uma das opções do curl de retorna um valor do header de resposta, que no caso era os status code.
status_code=0
while [ $status_code -ne 200 ]
do
sleep 10
status_code=$(curl -s -o /dev/null -w "%{http_code}" https://helio.loureiro.eng.br/)
echo "status_code=$status_code"
done
O script fica monitorando o site e retorna o valor do status code em loop.
status_code=500 status_code=500 status_code=500 status_code=500 status_code=500 status_code=200
Assim que receber uma resposta 200, que é ok, para. Deixei isso rodando num shell no canto do desktop (uso duas telas então não bloqueou minha visão de nada). Assim que parou, voltei ao browser e acessei o serviço.
Coisa linda, não?
Se você tentou usar o pip, o gerenciador de módulos do python, nos últimos tempos então deve ter dado de cara com o seguinte erro:
/tmp > pip search conda
ERROR: Exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/cli/base_command.py", line 224, in _main
status = self.run(options, args)
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/commands/search.py", line 62, in run
pypi_hits = self.search(query, options)
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/commands/search.py", line 82, in search
hits = pypi.search({'name': query, 'summary': query}, 'or')
File "/usr/lib/python3.6/xmlrpc/client.py", line 1112, in __call__
return self.__send(self.__name, args)
File "/usr/lib/python3.6/xmlrpc/client.py", line 1452, in __request
verbose=self.__verbose
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/network/xmlrpc.py", line 46, in request
return self.parse_response(response.raw)
File "/usr/lib/python3.6/xmlrpc/client.py", line 1342, in parse_response
return u.close()
File "/usr/lib/python3.6/xmlrpc/client.py", line 656, in close
raise Fault(**self._stack[0])
xmlrpc.client.Fault: <Fault -32500: "RuntimeError: PyPI's XMLRPC API has been temporarily disabled due to unmanageable load and will be deprecated in the near future. See https://status.python.org/ for more information.">
Olhando no link apontado pelo erro, temos uma bela mensagem de erro.
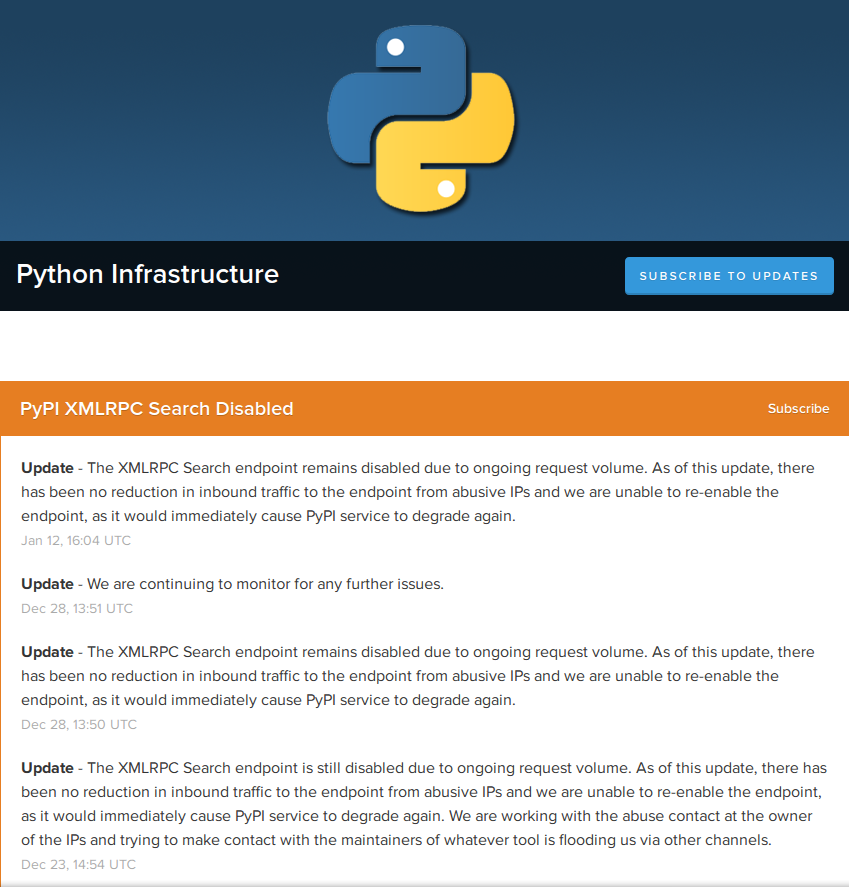
As mensagens no site são as seguintes:
Traduzindo em miúdos: o site não está aguentando o tráfego. Simples assim.
Não vou entrar no mérito de como o site foi feito, se com flash, django, ou o que quer que seja que esse não é o ponto. O ponto é que fizeram uma péssima arquitetura. Um único ponto de controle que não sustenta o tráfego.
Quantos anos existe o Debian Mais de 25 já. O Debian criou uma solução pra isso já faz mais de uma década: repositórios com mirrors e pacotes assinados. Ao rodar o comando apt ou apt-get, uma listagem dos arquivos disponíveis é verificada. Se a informação do arquivo for a mesma do arquivo local, não é baixado. Isso diminui em muito a carga em cima dos servidores.
Já os pacotes pip usam um formato xml que provavelmente é baixado toda vez. Não só isso: não existe um pip stable, unstable e testing. A cada nova pequena versão do pacote, um novo arquivo é gerado. Isso torna cache dessa list impossível de ser mantido por qualquer mirror. E é o mesmo problema que se encontra em npm, compose, etc.
O contraponto de ter esse arquivo sempre atualizado é ter as versões mais recentes dos pacotes, módulos ou classes que se esteja usando. Mas o custo é alto em termos de capacidade de rede pra aguentar esse tráfego. O resultado é esse que vemos com o pip.
Terá solução? Acredito que sim. Mas sem re-pensar na arquitetura do pip, como receber módulos novos e atualizações, vai ser apenas como enxugar gelo.

Não sei já descrevi isso aqui ao longo desses 20 anos de blog/site, mas a maioria das coisas que publico são pra mim mesmo. Como tenho certeza que não vou lembrar o que fiz daqui algum tempo (provavelmente dias), eu deixo aqui registrado como bloco de notas pra referência. E, claro, espero que isso também ajude mais pessoas além de mim.
Como moro fora do Brasil já faz algum tempo, e ainda não domino a língua (na verdade só apanho dela), eu preciso de tempos em tempos pegar documentos e ler. A forma que encontrei é passar o documento em um scanner, se for papel, mas ter a certeza de ter o documento digitalizado em formato PDF no final. Esse foi o formato que mais facilitou o uso de outro software pra OCR (Optical Character Recognition), ou reconhecimento ótico de caracter.
Também percebi que o melhor é ter o documento separado em vários PDFs se possível, um pra cada página. Isso facilita pro software de OCR de reconhecer cada página corretamente.
Pra usar como exemplo aqui vou adotar um documento sobre o imposto de renda sueco. Ele está disponível na página do que seria equivalente à receita federa: https://www.skatteverket.se
O documento será esse aqui: https://www.skatteverket.se/download/18.7eada0316ed67d7282aedd/1582550479006/dags-att-deklarera-skv325-utgava41.pdf
Pra começar, apenas baixar o documento usando o curl:
curl -o report.pdf https://www.skatteverket.se/download/18.7eada0316ed67d7282aedd/1582550479006/dags-att-deklarera-skv325-utgava41.pdf
Em seguida serão necessários os seguintes pacotes de software (assumindo um sistema ubuntu ou debian): curl, ghostscript, imagemagick, tesseract-ocr e tesseract-<língua>. Como no caso eu pego os documentos em sueco, uso então tesseract-swe.
sudo apt install curl ghostscript imagemagic tesseract-ocr tesseract-sweO arquivo então será baixado e salvo como "report.pdf". Ao abrir o documento eu vejo quantas páginas são, o que poderia ser feito de alguma outra forma mais automática, mas a visualização assim é fácil até pra detectar logo se tem alguma página pra pular com imagens. Esse documento tem 8 páginas.
Então pra separar o arquivo em PDF baixado em páginas separadas, que depois vai facilitar o trabalho de tradução, eu uso o seguinte comando:
for i in $(seq 1 8)
do
gs -sDEVICE=pdfwrite -q -dNOPAUSE -dBATCH -sOutputFile=report-$i.pdf -dFirstPage=$i -dLastPage=$i report.pdf
done
Com as páginas criadas separadamente em formato PDF e com os nomes como report-1.pdf, report-2.pdf, report-3.pdf, etc e o próximo passo é converter cada uma no formato TIFF, que é o formato onde o reconhecimento de caracteres funciona melhor. O programa "convert" que faz isso é parte do pacote imagemagick
for i in $(seq 1 8)
do
convert report-$i.pdf report-$i.tiff
done
Isso gera então as sequências report-1.tiff, report-2.tiff, etc.
Agora finalmente o passo final pra ter os textos em plain text.
for i in (seq 1 8)
do
tesseract report-$i.tiff report-$i -l swe
done
E isso cria os documentos com extensão "txt". Esse documento que escolhi não foi muito feliz na detecção de caracteres. O arquivo que mais foi reproduzido de forma satisfatória foi a página 7:
helio@xps13ubuntu:exemplo$ cat report-7.txt
Har du skatt att betala på din
preliminära skatteuträkning?
Tabellen på sidan 6 visar när skatten senast ska vara
betald. Fram till dess kan du göra delbetalningar.
Du kan när som helst betala in pengar till ditt
skattekonto. Du kan betala antingen med Swish
BIS
Om duvill betala med Swish loggar du in på Mina
sidor och följer instruktionerna där, Du kan också
enkelt betala din kvarskatt med Swish i samband
med att du deklarerar med edegitimation i
tjänsten. Du kan betala skatt med maximalt
15.000 kronor per dygn med Swish.
Om du betalar genom att göra en inbetalning till
BARR Sr ehe
angeditt OCR-nummer som du hittar i din preli-
PST RR NAS TT NT
www.skatteverketse/ocr.
Läs mer på wwwskotteverket.se/betalokvarskatt.
O passo seguinte é copiar essas páginas e colocar no google translator. Eu não automatizo esse passo e uso o simple copy&paste no browser.
E esse seria o resultado do trecho acima:
Você tem imposto a pagar sobre o seu
cálculo preliminar do imposto?
A tabela na página 6 mostra quando o imposto deve durar
pago. Até então, você pode parcelar.
Você pode depositar dinheiro no seu a qualquer momento
conta fiscal. Você pode pagar com Swish
BIS
Se você quiser pagar com Swish, faça login no Mina
páginas e siga as instruções lá, você também pode
pague facilmente seu imposto residual com o Swish em conjunto
com isso você declara com edegitimação em
o serviço. Você pode pagar impostos com um máximo
SEK 15.000 por dia com Swish.
Se você pagar fazendo outro pagamento
BARR Sr ehe
número OCR especificado que você encontra na sua
PST RR NAS TT NT
www.skatteverketse / ocr.
Leia mais em wwwskotteverket.se/betalokvarskatt.
Parem as prensas!
Estava aqui dando uma olhada em artigos do site, num bug de data do Joomla, quando achei o artigo 10 anos de Loureiro.Eng.BR que achei bonitinho. E fui ler.
CARACA! Eu perdi a data de 20 anos. Já são 20 anos e 7 meses de Loureiro.Eng.BR no ar. 20 anos!!!!
Nessa zique-zira de pandemia a data passou batida, mas sim, 20 anos no ar.
Não tenho muito o que mostrar nos 10 anos passados porque já faz muito tempo que rodo o site inteiro numa VPS, então não tenho uma máquina pra mostrar como no artigo de 10 anos.
Mas posso mostrar o meu eu de 10 anos atrás e o de hoje em dia.


Estou a cada dia mais Maddog Hall que nunca.
Como será que vai ser meu post de 30 anos?
Update: atualizei com uma foto mais ou menos no mesmo ângulo e usando também uma toca, pra ficar no mesmo estilo. Só que errei o ângulo da foto e tive de acertar com o gimp. Como ficou com duas áreas em branco, tive de dar uma adaptada e colar um fundo do Nuketown do Call of Duty.
Como parte da minha cerimônia de renovação, sempre atualizo o tema do site.
Infelizmente a maioria dos temas que existem parecem cada vez mais a mesma coisa. E as opções gratuitas estão cada vez mais limitadas.
Então tive de mudar de um tema escura pra novamente um tema claro.
Mas é ao menos tem alguma atualização.
E novamente vou tentar manter uma frequência maior de posts aqui. Tentarei novamente um post a cada semana no mínimo, o que já exige um esforço fenomenal. Mas o importante é não desistir.
Um vídeo curto com algumas fotos de como foi meu 2020. Por volta de 30 fotos por mês.
Spoiler alert: nada muito emocionante em tempos de COVID.

Um dos trabalhos que faço como voluntário é manter alguns serviços "alternativos" na empresa. Todos baseados em software livre.
Dos que são mantidos temos um mediawiki, um encurtador yourls e um etherpad-lite. E esse último foi o que precisei mexer pra transferir pra um servidor novo.
Muitas pessoas gostam do etherpad-lite e o usam, mas devo dizer que por trás é um lixo. Serviço porco. Ele usa uma só tabela no MySQL/MariaDB com dois campos:
mysql> show tables; +-----------------+ | Tables_in_paddb | +-----------------+ | store | +-----------------+ 1 row in set (0.00 sec) mysql> desc store; +-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | key | varchar(100) | NO | PRI | | | | value | longtext | YES | | NULL | | +-------+--------------+------+-----+---------+-------+ 2 rows in set (0.01 sec)
Sério. 2 campos. E só. Um é uma chave toscamente preparada pra ser chave primária e o resto... é valor. Então o uso do DB só cresce, sem chances de uma manutenção decente.
Enquanto o uso do etherpad-lite é um dor nas costelas, o assunto é mais da migração dos dados. Então continuando o assunto, o nosso DB chegou ao incrível valor de 13 GB. Daí como faz a migração? O básico é tirar um dump do DB antigo com mysqldump e carregar usando o comand mysql mesmo.
Algo como isso:
# mysql --host=remote-server.mysql.internal.com --port=1234 --user=sqluser --password=sqlpassword mydb < etherpad-migration-backup.sql
que pra todos efeitos funciona. O único problema foi que depois de passar 15 horas carregando o arquivo...
ERROR 2013 (HY000) at line 19057418: Lost connection to MySQL server during query
Dizem que não tem dor maior que a dor do parto. Tem sim e chama-se carregar um dump de 13 GB por 15 horas e falhar. Assim.
E o que restou fazer. Bom... eu sabia a linha onde estava o arquivo, mas já tinham sido 15 horas num arquivo serial, que faz linha por linha. Então decidi quebrar o dump em vários arquivos menores. Dei um rápido "wc -l" no dump e vi que tinham exatamente 28993313 linhas. Então era possível quebrar em 28 arquivos de 1 milhão de linhas cada. E foi o que fiz.
Assim eu sabia que podia continuar do arquivo 20 em diante. E depois resolvia como fazer com o que faltava.
# split -l 1000000 -d etherpad-migration-backup.sql etherpad-migration-backup.sql. # ls -1 pad-migration-backup.sql.?? etherpad-migration-backup.sql.00 etherpad-migration-backup.sql.01 etherpad-migration-backup.sql.02 etherpad-migration-backup.sql.03 etherpad-migration-backup.sql.04 etherpad-migration-backup.sql.05 etherpad-migration-backup.sql.06 etherpad-migration-backup.sql.07 etherpad-migration-backup.sql.08 etherpad-migration-backup.sql.09 etherpad-migration-backup.sql.10 etherpad-migration-backup.sql.11 etherpad-migration-backup.sql.12 etherpad-migration-backup.sql.13 etherpad-migration-backup.sql.14 etherpad-migration-backup.sql.15 etherpad-migration-backup.sql.16 etherpad-migration-backup.sql.17 etherpad-migration-backup.sql.18 etherpad-migration-backup.sql.19 etherpad-migration-backup.sql.20 etherpad-migration-backup.sql.21 etherpad-migration-backup.sql.22 etherpad-migration-backup.sql.23 etherpad-migration-backup.sql.24 etherpad-migration-backup.sql.25 etherpad-migration-backup.sql.26 etherpad-migration-backup.sql.27 etherpad-migration-backup.sql.28 etherpad-migration-backup.sql.29
Com isso eu tive vários arquivos que eu podia subir em paralelo. E foi o que fiz. O resultado? Não só um mas vários erros depois de algumas horas carregando. Eu queria chorar. No chuveiro. Em posição fetal. Só isso.
O maldito do comando mysql não te permite dar um replay descartando o que já existisse no DB, o que seria uma mão na roda nessas situações. Então fiz isso com python. Mas achei que seria lento demais manter serializado. Então era um bom momento pra testar o asyncio, que usei pouquíssimo até hoje. E valeu muito a pena. Esse é o script final:
#! /usr/bin/python3
import sys
import pymysql.cursors
import asyncio
connection = pymysql.connect(host="remote-server.mysql.internal.com",
port=1234,
user="sqluser",
password="sqlpassword",
db="mydb",
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
cursor = connection.cursor()
sema = asyncio.Semaphore(value=10)
async def commit_line(line):
await sema.acquire()
print(line)
try:
cursor.execute(line)
connection.commit()
except:
print("Line (", line[:10],") already inserted")
pass
sema.release()
with open(sys.argv[1]) as sqlfile:
loop = asyncio.get_event_loop()
for line in sqlfile.readlines():
loop.run_until_complete( commit_line(line) )
loop.close()
Não está dos mais polidos, e com senha dentro, mas era uma coisa rápida pra resolver meu problema. E resolveu.
Eu criei uma fila de 10 processos em paralelo pra rodar com: sema = asyncio.Semaphore(value=10)
o controle de acesso ao processo pra rodar é feito com sema.acquire() e sema.release(). Muito fácil. Nem precisei criar um objeto Queue.
Dentro do loop do commit_line() eu sabugue um "enfia essa linha lá ou então continua". Simples assim. E funcionou.
Eu já tinha deixado o tmux aberto com várias janelas, uma pra cada arquivo, então foi só rodar o mesmo em cada uma que falhou.
Levou mais umas 2 ou 3 horas mas carregou tudo.
Foi lindo, não foi?

Esses dias precisei fazer uma migração de uma mediawiki que usamos na empresa de uma máquina que rodava CentOS 6.8 pra um Ubuntu 18.04.
Para garantir seu funcionamento, primeiro eu queria testar os upgrades necessários em minha máquina. Nada melhor que copiar os arquivos e rodar a versão exata do site remoto com containers em docker.
Mas ao rodar o container... ele simplesmente saia com código de erro 139. Mais nada. Sem logs, sem describe, sem nada que pudesse ajudar.
~ > docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8ffcdf12d761 centos:6.8 "bash" 52 minutes ago Up 52 minutes 0.0.0.0:8080->80/tcp elated_ganguly 7bd9374248fd centos:6.8 "bash" 56 minutes ago Exited (139) 56 minutes ago dreamy_fermat 80ff07e9b84e centos:6.8 "bash" 10 hours ago Exited (139) 10 hours ago romantic_hertz 3db1d6c1f68b centos:6 "bash" 10 hours ago Exited (139) 10 hours ago bold_kilby
Olhando pela Internet, descobri em alguns sites pessoas relatando o mesmo problema. É algo relacionado com a versão da glibc do container com a versão do kernel que estou rodando, que é muito mais novo:
~ > uname -a Linux elxa7r5lmh2 5.9.0-rc5-helio #10 SMP Sat Sep 19 12:04:57 CEST 2020 x86_64 x86_64 x86_64 OSI/Linux
A solução é adicionar um parâmetro a mais no grub a opção "vsyscall=emulate":
~ > grep GRUB_CMDLINE_LINUX /etc/default/grub GRUB_CMDLINE_LINUX_DEFAULT="quiet splash" GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0 pcie_aspm=off pci=nomsi vsyscall=emulate"
e fazer um update no próprio grub.
~ > sudo update-grub2 && sudo reboot -f
Após um reboot os containers funcionaram sem problemas.
~ > docker run -it --rm=true centos:6.8 bash [root@224aecaba978 /]# hostname 224aecaba978 [root@224aecaba978 /]# exit exit ~ > docker ps -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ca68add255bd ubuntu:18.04 "bash" 2 hours ago Exited (1) 2 hours ago festive_galois ~ >
Eu tentei configurar diretamente no kernel através da interface em /sys, mas eu só consegui com isso gerar um kernel panic. O jeito mais fácil e seguro foi mesmo rebootando meu laptop.

Entre os vários grupos do Telegram, um que é muito bom é o de shell, o t.me/shellbr pros mais íntimos.
Um dia desses, entre discussões de como fazer um shell melhor e eu postando sticker pros falantes de língua inglesa de que o grupo é em língua portuguesa, apareceu algo que abriu minha visão em shell pra algo muito maravilhoso. Não é uma novidade de um comando mágico que faz algo completamente novo, mas a simplicidade da solução que esteve esse tempo todo na minha cara e eu nunca vi foi o que me fascinou.

Pra dar um pouco mais de contexto, o que se referia isso: quem nunca precisou mandar um "ps auxwww | grep firefox" e pegou o próprio comando grep na saída?
~> ps auxwww | grep firefox helio 5719 15.5 2.9 3994484 475156 ? Rl 20:57 4:38 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.0 1.6 3021712 259472 ? Sl 20:58 1:47 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 1.0 1.2 2687192 201516 ? Sl 20:58 0:18 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 161856 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.8 2.0 3008700 325944 ? Rl 20:58 1:44 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 1.0 1.5 2875692 241532 ? Sl 21:08 0:12 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.5 1.1 2676620 179336 ? Rl 21:11 0:15 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120484 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13 helio 14368 0.0 0.0 18056 1052 pts/2 S+ 21:27 0:00 grep --color=auto firefox
Comecei com Linux em 1997, quando aprendi a usar as Sparc stations da universidade. Mais de 20 anos nessa indústria vital e eu sempre, sempre, usei desse jeito:
~ > ps auxwww | grep firefox | grep -v grep helio 5719 14.6 3.0 3991196 481364 ? Sl 20:57 4:56 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.2 1.7 3019784 279384 ? Sl 20:58 2:05 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 0.9 1.2 2687192 202532 ? Sl 20:58 0:19 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 164072 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.4 2.0 3008700 330532 ? Sl 20:58 1:49 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 0.9 1.5 2875692 241876 ? Sl 21:08 0:13 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.3 1.1 2676620 179336 ? Sl 21:11 0:16 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120588 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13
Com essa maravilhosa dica do Hélio Campos, basta fazer assim:
~ > ps auxwww | grep [f]irefox helio 5719 14.5 3.1 4005676 500088 ? Sl 20:57 5:01 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.7 1.8 3034264 293864 ? Rl 20:58 2:18 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 0.9 1.2 2687192 203656 ? Sl 20:58 0:19 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 164072 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.3 2.0 3008700 331836 ? Sl 20:58 1:51 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 0.9 1.5 2875692 241876 ? Sl 21:08 0:14 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.3 1.1 2676620 179336 ? Sl 21:11 0:17 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120588 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13
Eu achei espetácular. Pode ser que eu esteja exagerando, mas achei mesmo. Uma dica muito simples e acabou com décadas usando um extra "grep" pra resolver as coisas.
Muito obrigado Hélio Campos e grupo shellbr!

Esses dias eu dei uma boa arrumada na minha estante e encontrei um laptop que estava parado desde 2014. Quando liguei, estava ainda com o Ubuntu 14.04 instalado e rodando. Pensei no mesmo momento que seria perfeito pra verificar o estado da proteção que as distros ditas livres e que são baseadas no GNU Linux Libre possuem.
Eu entrei na página da FSF eu fui seguindo as distros recomendadas como 100% livres. Peguei pra testar as seguintes: Trisquel, Parabola e Guix. Eu ia tentar também a Gnewsense mas a página principal mostra que depois de anos parada seu desenvolvimento foi simplesmente abandonado. Mas ainda está listada na página da FSF.
(Foto By Rafael Bonifaz - Alexandre Oliva, CC BY-SA 2.0,https://commons.wikimedia.org/w/index.php?curid=8939097)
Pra ter alguma comparação eu também testei Debian puro, sem nada a parte de firmwares, e também um Ubuntu. Vou descrever cada um em separado.
Esse morreu na praia pra mim. Como essas distribuições não usam firmwares, não consigo ativar o wifi do laptop. O Guix exige que a instalação siga por rede pra terminar. Eu deixei o laptop numa mesa longe da rede cabeada. Entre mexer o laptop pra minha mesa ou puxar um cabo até o outro quarto eu preferi simplesmente deixar de lado. Tentei procurar por um livecd ou algo do gênero mas não encontrei.
O Trisquel teve a instalação relativamente tranquila. Uma voz robotizada ficava falando tudo o que eu teclava mas deu tudo certo. Como esperado não funcionou com o wifi mas teve o touchpad do laptop funcionado desde a instalação.
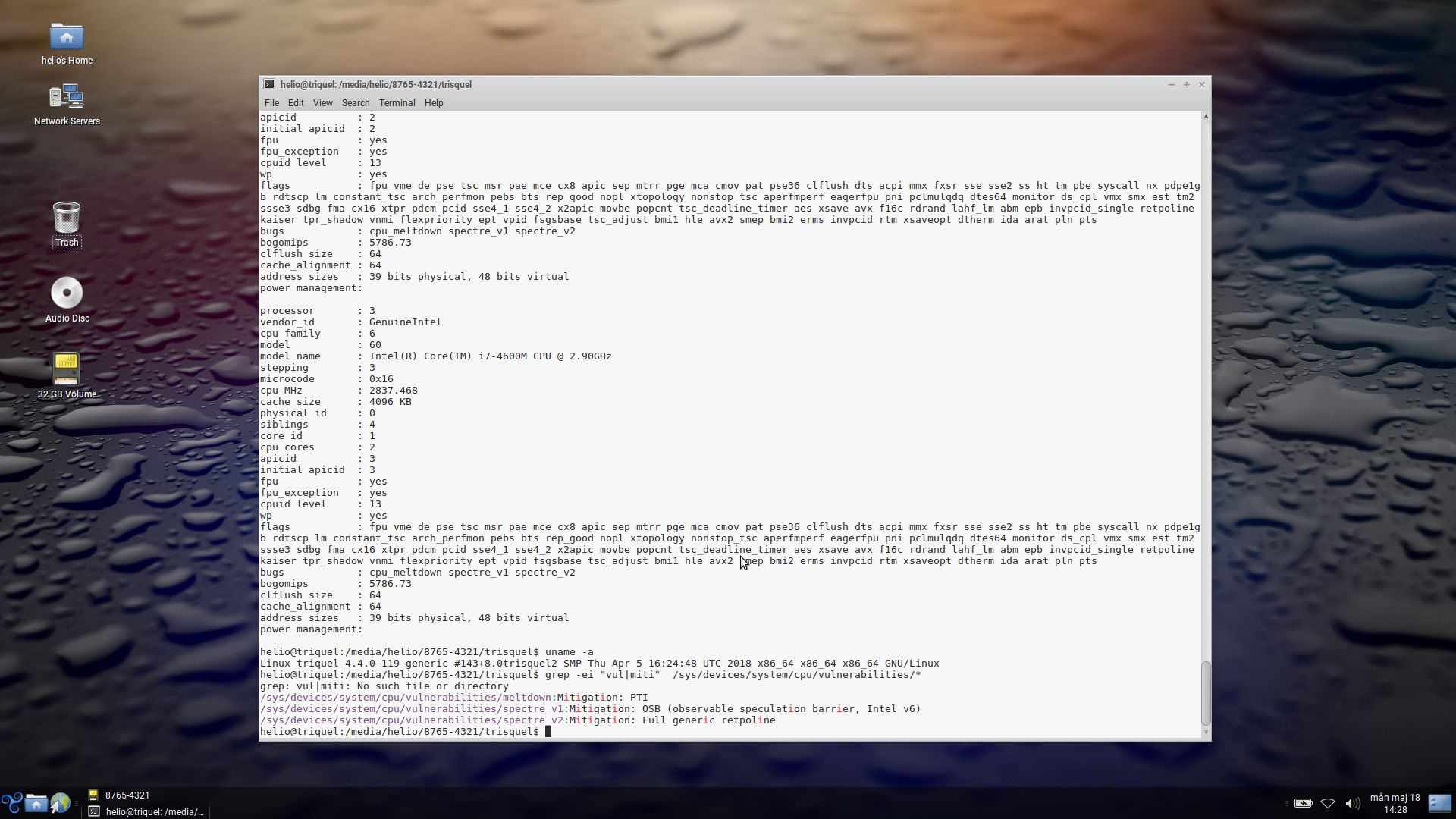
uname:
Linux triquel 4.4.0-119-generic #143+8.0trisquel2 SMP Thu Apr 5 16:24:48 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 2222.578 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movb e popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb invpcid_single retpoline kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 e rms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 bogomips : 5786.73 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: OSB (observable speculation barrier, Intel v6) /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline
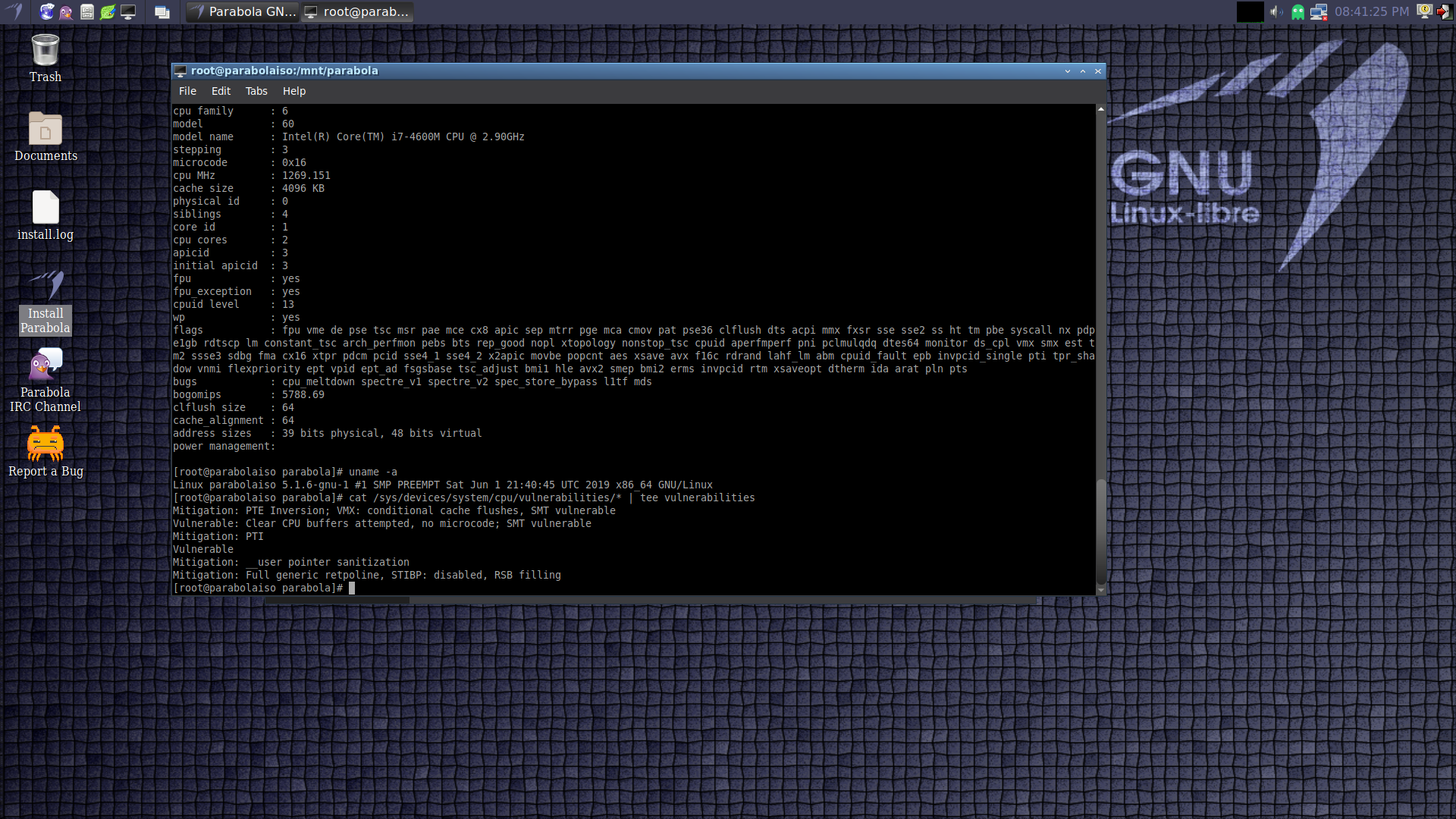
uname:
Linux parabolaiso 5.1.6-gnu-1 #1 SMP PREEMPT Sat Jun 1 21:40:45 UTC 2019 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 1069.269 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds bogomips : 5788.69 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/l1tf:Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable /sys/devices/system/cpu/vulnerabilities/mds:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable /sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline, STIBP: disabled, RSB filling
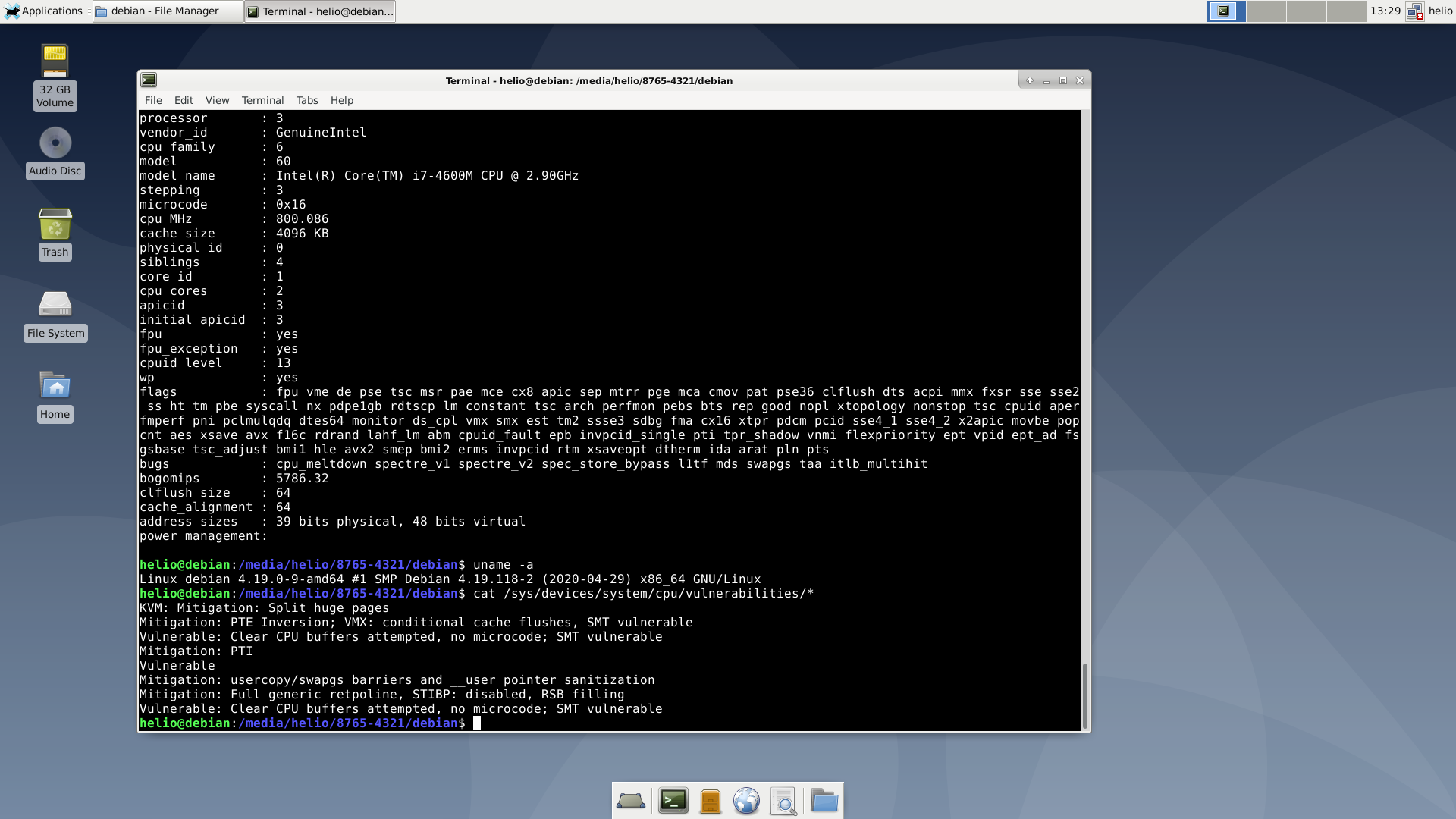
uname:
Linux debian 4.19.0-9-amd64 #1 SMP Debian 4.19.118-2 (2020-04-29) x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 1903.637 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit bogomips : 5786.32 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/itlb_multihit:KVM: Mitigation: Split huge pages /sys/devices/system/cpu/vulnerabilities/l1tf:Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable /sys/devices/system/cpu/vulnerabilities/mds:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable /sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: usercopy/swapgs barriers and __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline, STIBP: disabled, RSB filling /sys/devices/system/cpu/vulnerabilities/tsx_async_abort:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable
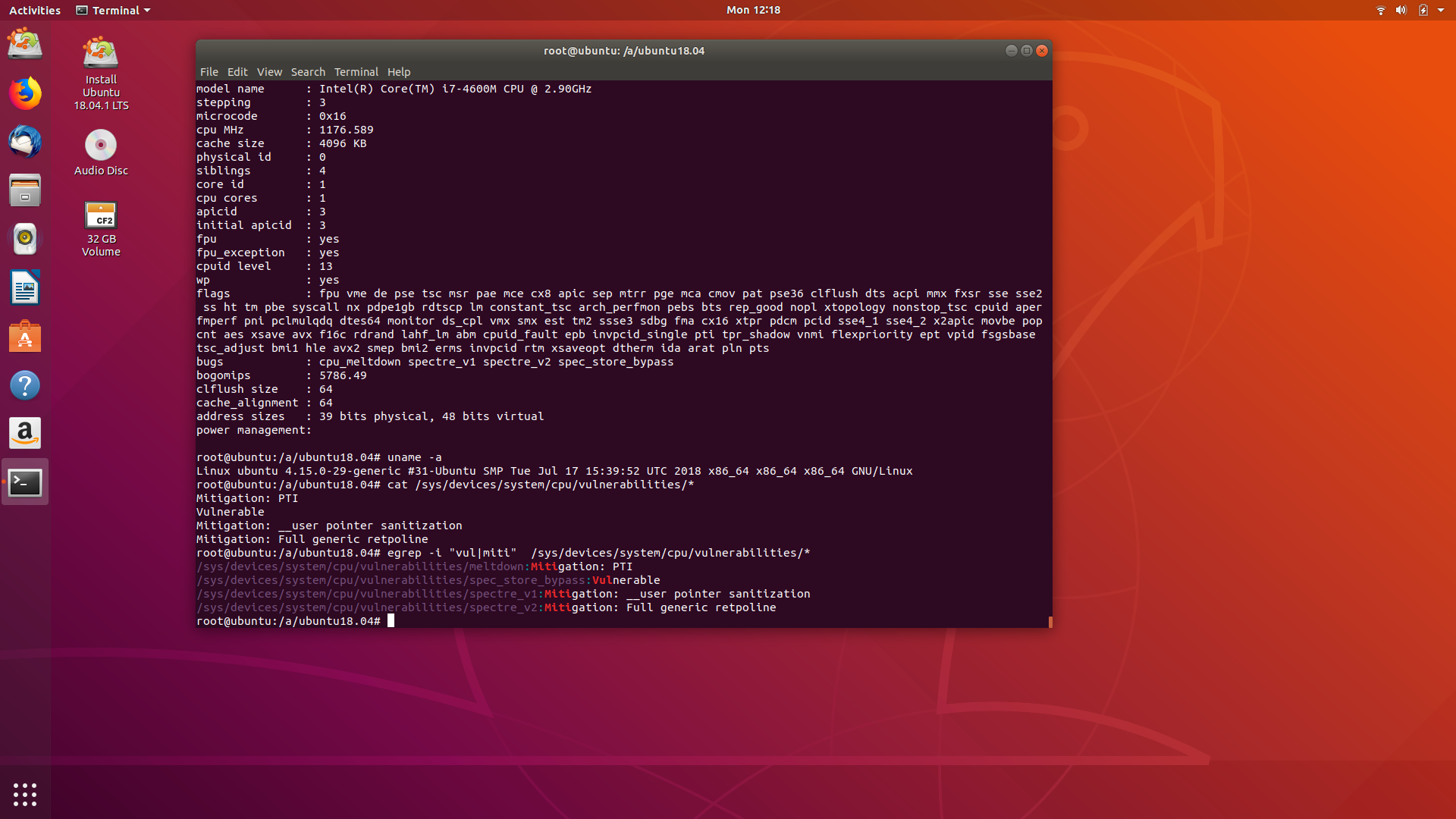
uname:
Linux ubuntu 4.15.0-29-generic #31-Ubuntu SMP Tue Jul 17 15:39:52 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 2047.970 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveop t dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass bogomips : 5786.49 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline
A comparação é difícil porque cada um dos sistemas operacionais roda com uma versão de kernel diferente. Todas baseadas em Linux.
Todas mostram em cpuinfo que detectam as falhas de spectre_v[1,2] e meltdown, além das demais.
Como mostrado pelas distros com kernels mais recentes, várias vulnerabilidades estão ainda abertas. O sistema continua vulnerável aos ataques de especulação mas não aos spectre v1 e v2, nem meltdown. Realmente sobre essas duas vulnerabilidades o Oliva está certo. Só errou que o restante continua vulnerável e inseguro sem as correções de firmware.
Não imagino que possam ser corrigidas em versões mais recentes pois precisam do firmware da Intel pra mudar o microcode direto na CPU.
Quem continuar utilizando algumas dessas distros é interessante ficar de olho qual bug de CPU foi corrigido e qual ainda está pendente. E ter cuidado ao usar o computador, pois o mesmo continua vulnerável a ataques de especulação mesmo rodando somente software livre.

Hoje chegou um mail pedindo pra testar uma mudança de máquinas que saíram da empresa pra irem habitar o cloud. A tarefa era testar máquina e porta. Algumas máquinas com uma porta somente, outras com várias. E todas TCP.
Pra fazer isso rapidamente eu escrevi um script em python3 que basicamente estabelece uma conexão TCP e mostra OK se conectar ou FAIL se não conseguir. Bem básico, mas resolveu meu problema muito mais rápido que se eu fosse testar máquina por máquina, porta por porta provavelmente com o comando telnet.
#! /usr/bin/python3
import socket
servers = [
"helio.loureiro.eng.br:443",
"helio.loureiro.eng.br:389",
"helio.loureiro.eng.br:8081",
"helio.loureiro.eng.br:80",
"helio.loureiro.eng.br:22"
]
for server in servers:
try:
host, port = server.split(":")
port = int(port)
socket.create_connection((host, port), 3)
print(server, "OK")
except:
print(server, "FAIL")
O resultado:
helio.loureiro.eng.br:443 OK helio.loureiro.eng.br:389 FAIL helio.loureiro.eng.br:8081 FAIL helio.loureiro.eng.br:80 OK helio.loureiro.eng.br:22 OK
Boa diversão!
Tenho feito muitos testes para utilizar TLS e mTLS. TLS é uma camada de criptografia assimétrica para garantir a comunicação segura entre dois pontos.
Em geral temos o model parecido com os sites web onde o servidor tem uma conexão segura assinada por uma autoridade certificadora e nos conectamos a ele. No caso de mTLS, mutual TLS, é preciso validar quem conecta também.
Pra gerar os testes que venho fazendo, gero um certificado de 1 dia usando openssl da seguinte forma:
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 1 -nodes \
-subj "/C=SE/ST=Stockholm/L=STHLM/O=Company/OU=ADP/CN=localhost
Esse comando gera para mim a chave do servidor (key.pem) e a chave da autoridade certificadora, que assina a chave.
Em geral carrego isso no meu programa que utiliza TLS.
Pra testar (assumindo que seu serviço seja http e esteja usando a porta 9091):
curl --cacert cert.pem --key key.pem --cert cert.pem "https://localhost:9091/
Eu poderia gerar um chave pro client, que no caso é o comando curl, mas como é pra ambiente de testes, re-uso o mesmo.
Boa diversão!

Já faz algum tempo que quero escrever sobre meu uso de LVM, mas até agora a procrastinação venceu. No último artigo Trabalhando de home-office eu descrevei meu ambiente de home-office e um pouco do meu desktop. Ao entrar no desktop é que percebi que um dos HDDs simplemente parou de funcionar, esse Seagate Firecuda de 2 TB. Graças ao LVM eu não percebi nada, nem perdi dados. E vou descrever aqui o cenário e como fiz a troca e re-sincronismo dos dados.
Usando o comando lvm é possível ver o estado dos meu volumes:
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor-r- 750.00g 100.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
Minhas partições eram todas XFS mas descobri que alguns jogos da Steam simplesmente só rodam com EXT4. Então precisei criar uma partição EXT4 somente pros jogos. É o volume com nome de "steam" e que mostra um "100.00". Esse número representa a cópia no disco que falhou, que estava em RAID1.
Primeiro eu adicionei outro disco de 2 TB que tinha aqui (no passado eu usava 2 HDDs de 2 TB cada com LVM, comprei o HDD novo de 4 TB e removi 1 dos HDDs que estava em bom estado ainda), e particionei da mesma forma que o HDD de 4 TB, com uma partição EFI e outra de boot do mesmo tamanho. O restante pro LVM.
root@goosfraba:~# fdisk -l /dev/sdb
Disco /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 setores
Unidades: setor de 1 * 512 = 512 bytes
Tamanho de setor (lógico/físico): 512 bytes / 512 bytes
Tamanho E/S (mínimo/ótimo): 512 bytes / 512 bytes
Tipo de rótulo do disco: dos
Identificador do disco: 0x18a6e3b6
Dispositivo Inicializar Início Fim Setores Tamanho Id Tipo
/dev/sdb1 2048 1128447 1126400 550M ef EFI (FAT-12/16/32)
/dev/sdb2 1128448 5322751 4194304 2G 83 Linux
/dev/sdb3 5322752 3907029167 3901706416 1.8T 8e Linux LVM
Tendo a partição sdb3 disponível pro LVM, então o que faltava era adicionar o grupo de volumes que uso. Ao listar os discos físicos disponíveis, apareceu a informação ainda do disco antigo como "unknown".
root@goosfraba:~# pvdisplay
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name [unknown]
VG Name diskspace
PV Size <1.82 TiB / not usable <4.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476931
Free PE 284930
Allocated PE 192001
PV UUID N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t
"/dev/sdb3" is a new physical volume of "<1.82 TiB"
--- NEW Physical volume ---
PV Name /dev/sdb3
VG Name
PV Size <1.82 TiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
Isso acontenceu porque o metadado ainda estava lá apesar do disco ter sido removido da máquina. Enquanto isso a partição sdb3 aparece como "Allocatable NO" pois ainda não está disponível pra uso.
A primeira coisa é remover os dados incosistes do vg (volume group).
root@goosfraba:~# vgreduce diskspace --removemissing --force
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
Wrote out consistent volume group diskspace.
E adicionar a nova partição ao vg.
root@goosfraba:~# vgextend diskspace /dev/sdb3
Volume group "diskspace" successfully extended
Com isso o a informação de pv mostra como usado.
root@goosfraba:~# pvdisplay
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name /dev/sdb3
VG Name diskspace
PV Size <1.82 TiB / not usable <2.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476282
Free PE 476282
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
E a informação de vg mostra com 6 TB disponíveis pra uso.
root@goosfraba:~# vgdisplay
--- Volume group ---
VG Name diskspace
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 217
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 8
Open LV 8
Max PV 0
Cur PV 2
Act PV 2
VG Size 5.45 TiB
PE Size 4.00 MiB
Total PE 1429493
Alloc PE / Size 501761 / 1.91 TiB
Free PE / Size 927732 / <3.54 TiB
VG UUID f2ufnI-c802-yt6f-2nMG-6BYl-8atu-wbR7vO
Agora a partição já faz parte do lvm. O que resta é a usar como RAID1 em mirror. Ou mesmo como uma partição qualquer se eu quisesse. Mas no caso uso como RAID1 pra ter um pouco mais de desempenho.
Primeiramente removendo as informações de RAID1 que ainda existindo.
root@goosfraba:~# lvconvert -m 0 /dev/diskspace/steam
Are you sure you want to convert raid1 LV diskspace/steam to type linear losing all resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace -wi-ao---- 750.00g
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
O parâmetro "-m 0" diz que a partição será em RAID0.
Em seguida basta mudar a partição novamente pra RAID1 e o sincronismo iniciará.
root@goosfraba:~# lvconvert -m 1 /dev/diskspace/steam /dev/sdb3
Are you sure you want to convert linear LV diskspace/steam to raid1 with 2 images enhancing resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 0.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 34.56
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
E é isso. Simples e rápido graças ao LVM.
Page 16 of 40
