Parece que finalmente acordaram pra aquilo que era óbvio: Linux chegou pra dominar também o desktop!
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed molestie scelerisque ultrices. Nullam venenatis, felis ut accumsan vestibulum, diam leo congue nisl, eget luctus sapien libero eget urna. Duis ac pellentesque nisi.
Foram meros 4%, mas a tendência é de crescimento e não tem volta. Até mesmo peguei os dados diretamente do site statcounter.
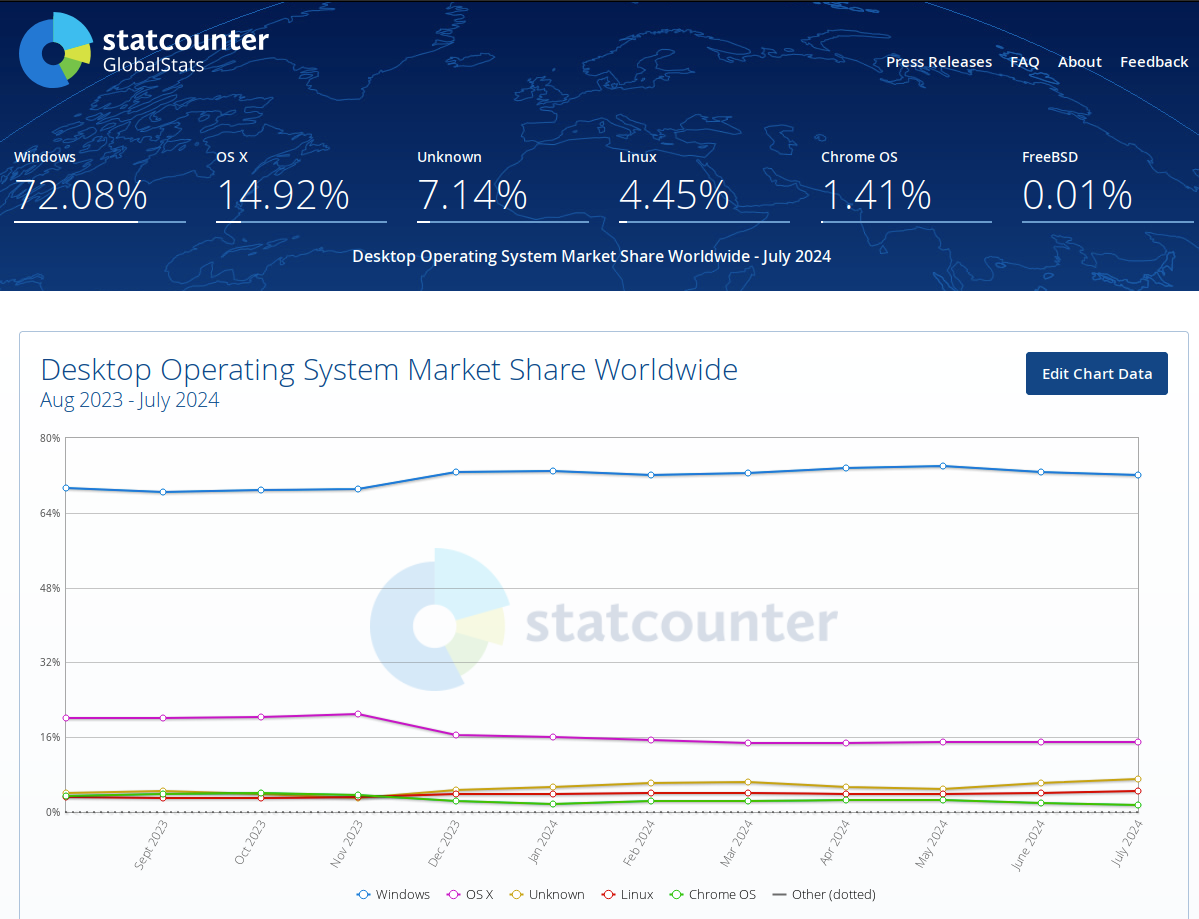
Claramente Linux está em plena ascensão. Seja porque razão for, o importante é estar lá. E vai chegar ao 100% com certeza. Eu até fiz uma checagem usando uma função forecast do libreoffice pra ver quantos anos serão necessários.
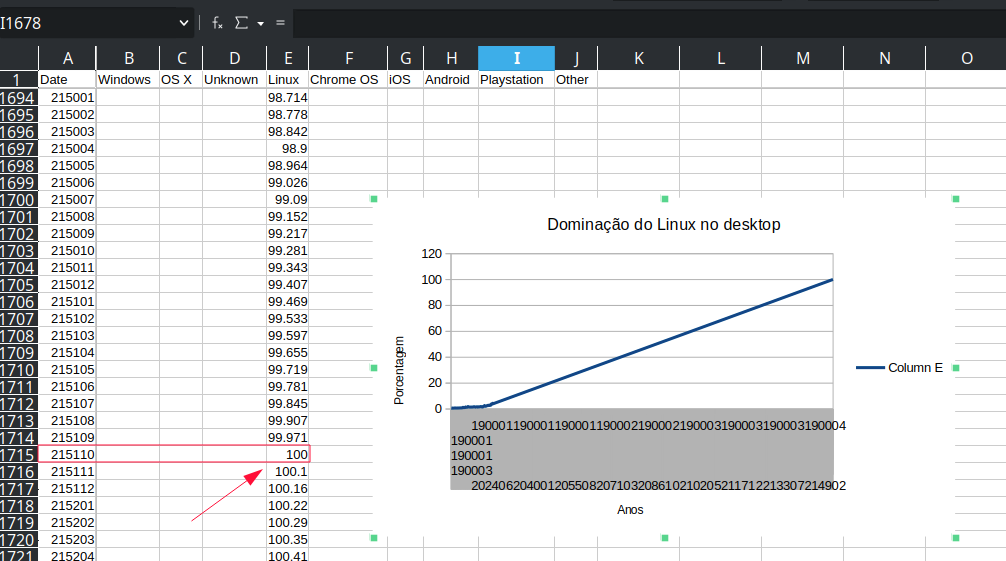
Ou seja, Linux dominará completamente o desktop em outubro de 2151. Marquem em suas agendas pois será uma data inesquecível. E não temos meta, mas quando chegarmos na meta nós dobraremos a meta. Aguardem-nos!

Antes que perguntem, não, não vou mudar da Suécia. Nem dentro da Suécia. Ao menos por enquanto.
O que aconteceu foi que essa VPS que atualmente tem esse site e o https://linux-br.org está no limite de uso. Ela tem requisitos modestos que nos atenderam bem por muito tempo. Mas agora muita coisa está caindo por OOM (Out Of Memory) e não tem muito o que fazer.
Entrei em contato com a VPS pra ver se era possível um upgrade sem grandes custos, mas eles não foram tão receptivos ao meu pedido quanto eu imaginava.Enquanto isso encontrei uma solução mais viável na Ionos. Por um preço bastante acessível (9 bidens) é possível ter uma VPS bem melhor e na região da união européia.
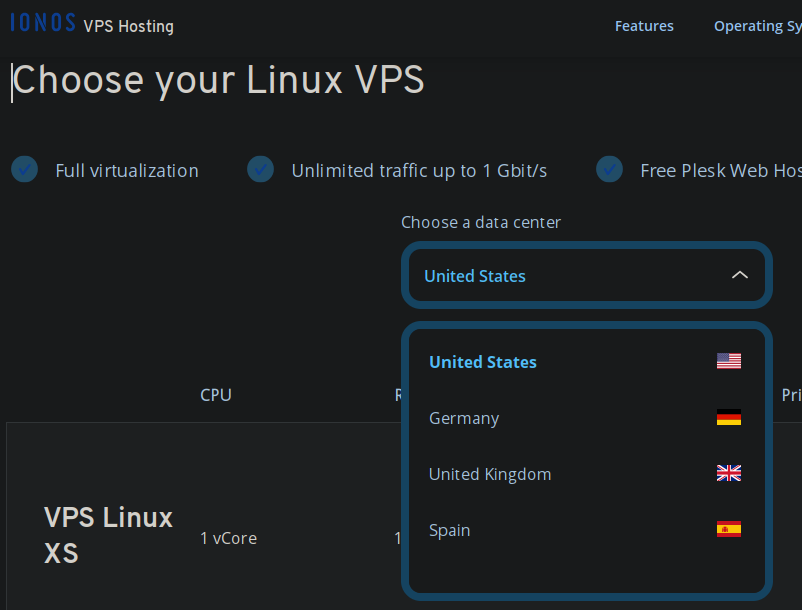
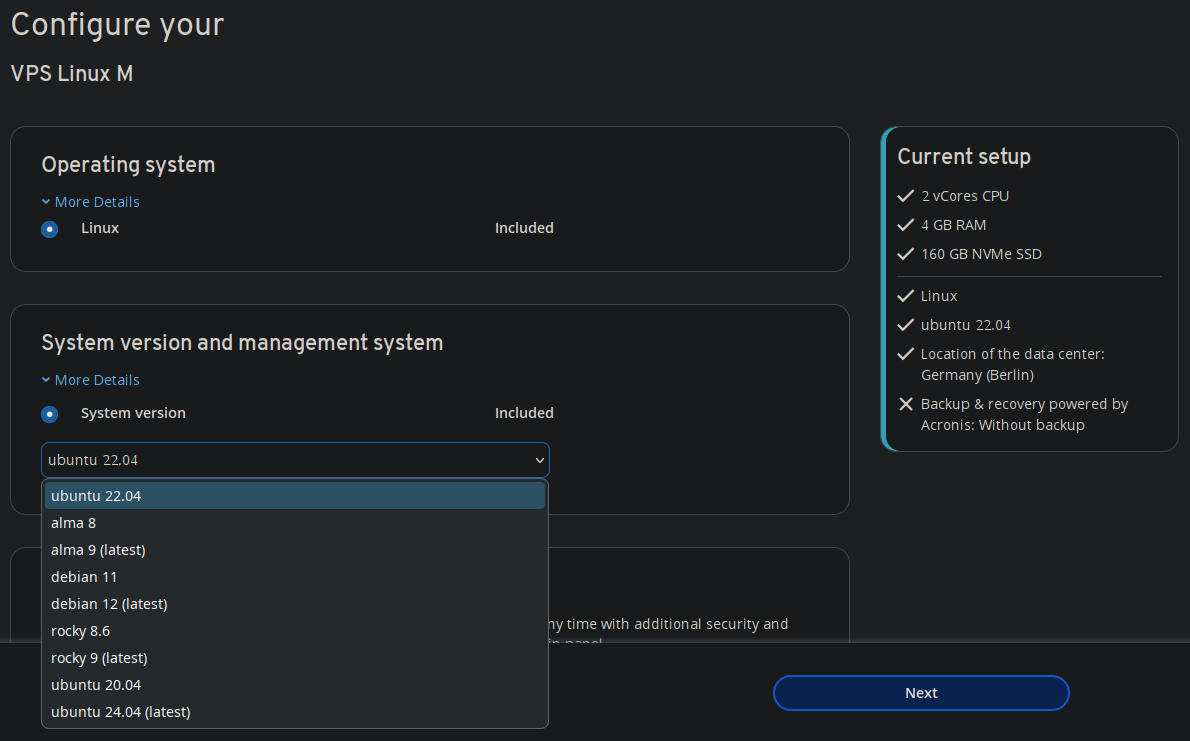
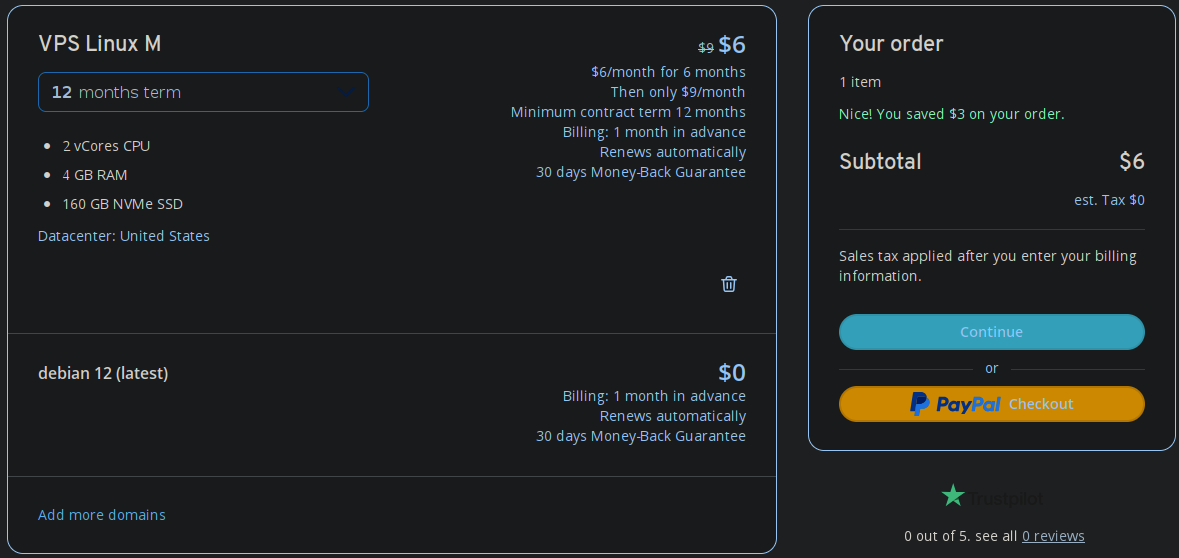
Posso ainda selecionar a região, que provavelmente será Alemanha, escolher o sistema operacional, que será o mesmo o atual, Debian, e finalmente vem o preço. 4vCPUs, 4 GB de RAM e 160 GB de disco por 9 bidens mensais. É praticamente tudo o dobro que a atual VPS com exceção do disco. O atual são somente 30 GB. Então será mais que o dobro.
A migração será agora no fim do mês. Então pode ser que o site em outros serviços fiquem fora do ar por algum tempo. Mas voltará. E melhor. Espero. Se não ficar melhor, mudamos novamente. Capitalismo 101.
A Amazon me surpreendeu e entregou mais rápido do que imaginei 16 GB de RAM da Crucial e um nvme da Intel de 1TB. Achei que fossem demorar mais de uma semana pra entregar, mas pelo visto estão com saudades de mim como cliente.
Assisti tudo quanto foi vídeo de upgrade no YouTube e parti pra parte prática.

Foi bem tranquilo de abrir e inserir as peças. Eu já tinha visto o tipo de memória e frequência pelo dmidecode. Também tinha visto que tinha somente um pente instalado, o que permitia comprar o segundo. E que o disco não era SDD mas um nvme, que é até mais rápido. Como não tinha muita coisa, não fiz backup and reinstalei o Ubuntu. E novamente com ZFS com criptografia.

E agora o bixo está um foguete.
helio@sh1bb0l33t ~> free
total used free shared buff/cache available
Mem: 24485224 4378656 19393324 703632 1768492 20106568
Swap: 8388604 0 8388604
helio@sh1bb0l33t ~> duf
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ 20 local devices │
├────────────────────────────────────────┬────────┬────────┬────────┬───────────────────────────────┬──────┬───────────────────────────────────────────────┤
│ MOUNTED ON │ SIZE │ USED │ AVAIL │ USE% │ TYPE │ FILESYSTEM │
├────────────────────────────────────────┼────────┼────────┼────────┼───────────────────────────────┼──────┼───────────────────────────────────────────────┤
│ / │ 890.5G │ 4.6G │ 885.9G │ [....................] 0.5% │ zfs │ rpool/ROOT/ubuntu_ni6nkv │
│ /boot │ 1.7G │ 96.9M │ 1.7G │ [#...................] 5.4% │ zfs │ bpool/BOOT/ubuntu_ni6nkv │
│ /boot/efi │ 1.0G │ 6.1M │ 1.0G │ [....................] 0.6% │ vfat │ /dev/nvme0n1p1 │
│ /home │ 891.7G │ 5.8G │ 885.9G │ [....................] 0.6% │ zfs │ rpool/USERDATA/home_39e1h7 │
│ /root │ 885.9G │ 2.2M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/USERDATA/root_39e1h7 │
│ /run/keystore/rpool │ 3.7M │ 28.0K │ 3.4M │ [....................] 0.7% │ ext4 │ /dev/keystore/rpool │
│ /srv │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/srv │
│ /usr/local │ 885.9G │ 6.1M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/usr/local │
│ /var/games │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/games │
│ /var/lib │ 896.3G │ 10.4G │ 885.9G │ [....................] 1.2% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib │
│ /var/lib/AccountsService │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/AccountsServ │
│ │ │ │ │ │ │ ice │
│ /var/lib/NetworkManager │ 885.9G │ 384.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/NetworkManag │
│ │ │ │ │ │ │ er │
│ /var/lib/apt │ 886.0G │ 106.6M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/apt │
│ /var/lib/dpkg │ 886.0G │ 79.6M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/dpkg │
│ /var/log │ 885.9G │ 5.2M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/log │
│ /var/mail │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/mail │
│ /var/snap │ 885.9G │ 11.0M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/snap │
│ /var/snap/firefox/common/host-hunspell │ 890.5G │ 4.6G │ 885.9G │ [....................] 0.5% │ zfs │ rpool/ROOT/ubuntu_ni6nkv │
│ /var/spool │ 885.9G │ 384.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/spool │
│ /var/www │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/www │
╰────────────────────────────────────────┴────────┴────────┴────────┴───────────────────────────────┴──────┴───────────────────────────────────────────────╯
E claro que escolhi um nome bacana pra batizar o brinquedo novo: sh1bb0l33t. Pra lembrar do bom e velho shibboleet que instalei aqui: Shibboleet.
Agora consigo jogar Doom sem engasgos. E enquanto estou no banheiro!

Um dia desses eu li um artigo de um fotógrafo sobre lixo computacional e como ele gastou muito menos comprando um laptop usado e remanufaturado e botou Linux. Eu fiquei pensando em como eu poderia realmente fazer o mesmo, que aliás deveria fazer isso por ser alguém que promove o uso de Linux. Antes que perguntem, eu infelizmente não encontrei o artigo. Como li no telefone enquanto estava indo dormir, foi algo que perdi. Mas a mensagem ficou na mente.
Como no momento não estou mais empregado (algo que um dia descrevo mais) e algumas empresas querem que eu vá até onde ficam pra fazer testes práticos, achei que era o momento propício pra entrar na moda do refurbished. Olhei um modelo em conta, um Lenovo Thinkpad T480, e comprei através do site https://www.refurbed.se que apesar do "se" no sufixo fica na Alemanha.
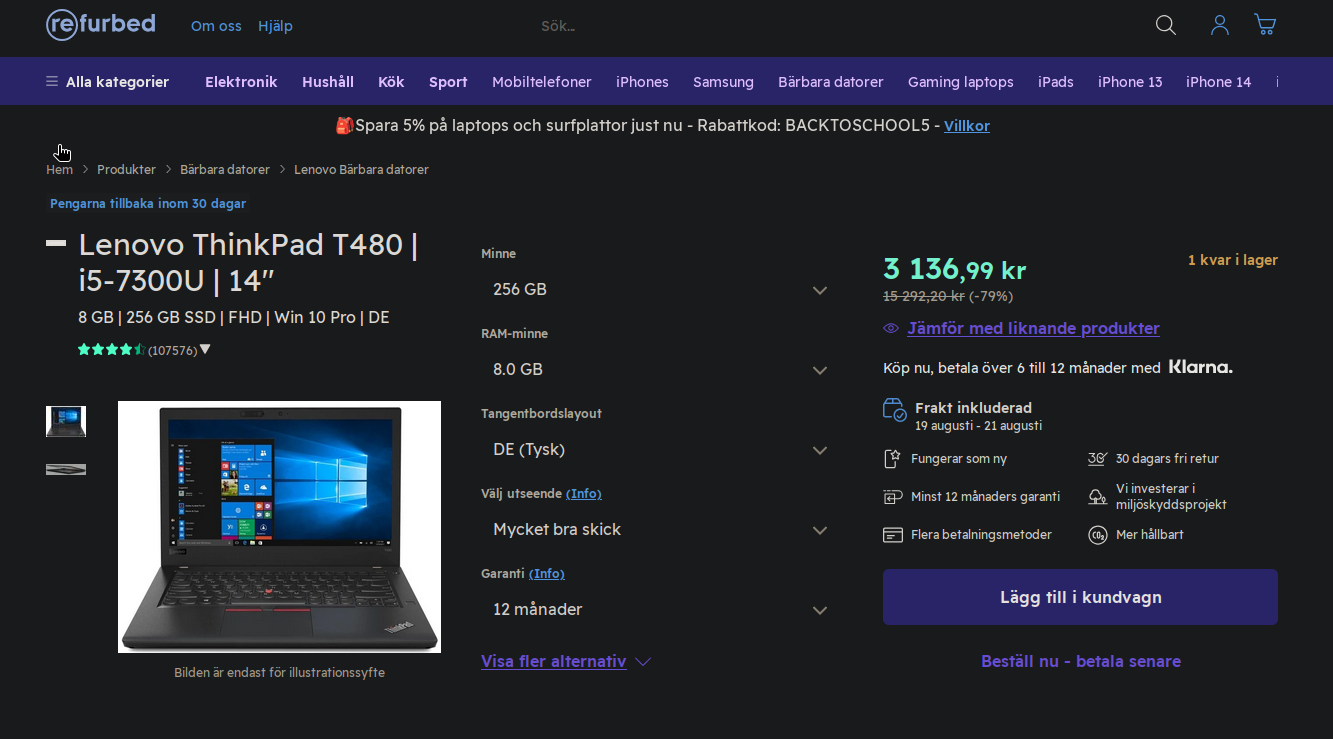
A máquina chegou e está 95% em ótimo estado. Sá uma parte da tampa está comida, mas nada que atrapalhe o funcionamento. É mais estético.

O restante está bem usável.

Claro que posso estar sendo otimista já que comecei a mexer na máquina agora. Mas o mais estranho mesmo foram as teclas desse layout que deveria ser US mas é um misto de US e alemão. E logo que chegou, não perdi tempo e instalei Ubuntu.
Não é uma máquina que pretendo ficar usando o tempo todo já que tenho o desktop, de onde digito agora, e que roda Archlinux. Como é uma máquina pra usar em eventos e enquanto estou fora de minha mesa, Ubuntu basta e sobra. Mas me dei ao luxo de instalar com ZFS pra experimentar.
E, claro, não perdi a oportunidade de gravar um unboxing.
E tudo isso não poder ter sido feito sem o apoio incondicional das gatas daqui de casa.

Update: eu descrevi de forma genérica e esqueci de botar as especificações do laptop. É um Intel Core i5 alguma coisa (o da foto no início foi só exemplo), 8GB de RAM (já comprei 16 GB extras) e com nvme de 256 GB (que devo trocar pra 1 TB que tenho aqui quando for adicionar a RAM). Paguei em torno de 300 euros. A bateria diz durar mais de 3 horas. Não testei ainda.
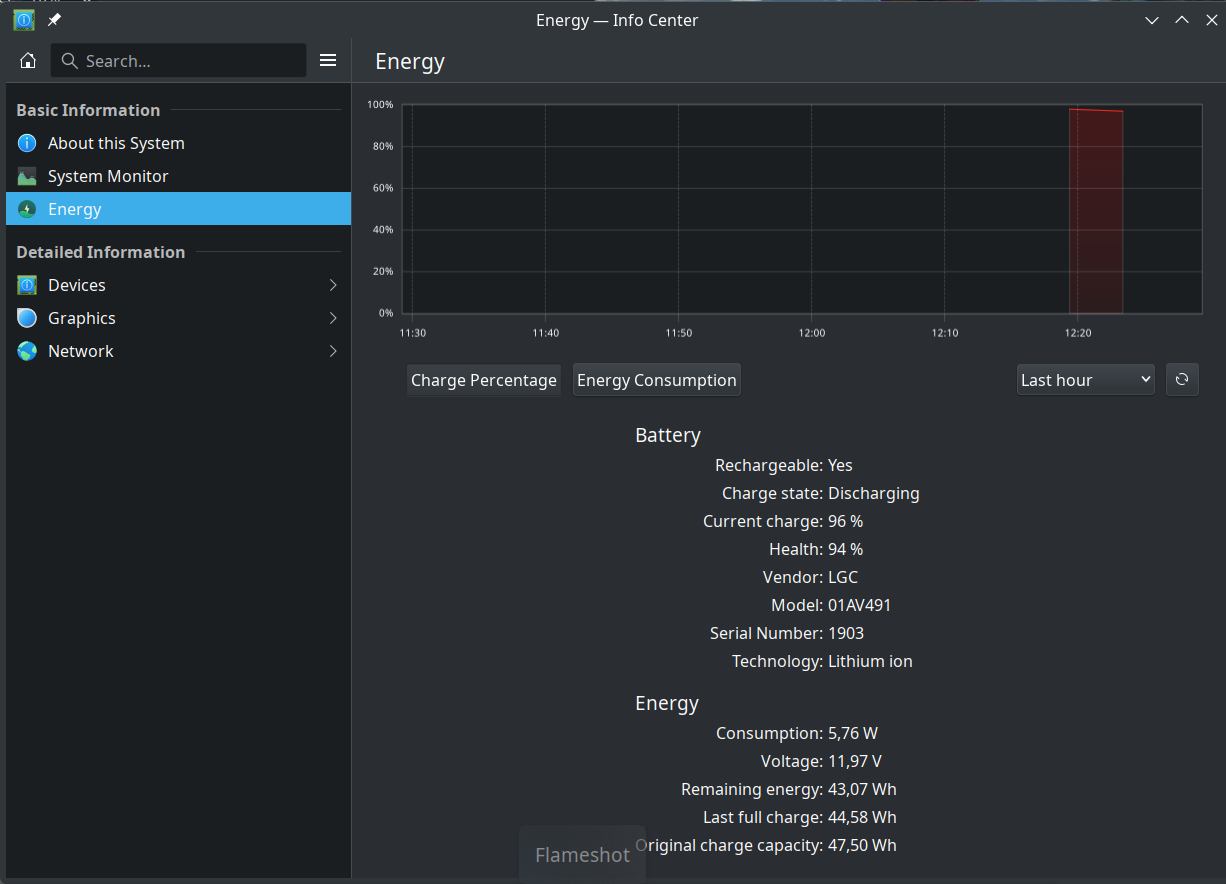
Update: 31/12/2024
Por um acaso muito grande, hoje apareceu no fediverso um texto traduzido do artigo que mencionei no início do texto e que não consegui achar o link. Eu li a versão em inglês, então deixo abaixo o link pra ambos.

Eu segui uma dica do @
Eu dei uma olhada nos de força bruta e aqui estão os logins mais usados:
MariaDB [(none)]> select username, fail, inet6_ntoa(ip), UA from wp_wflogins into outfile 'ataques.csv';
> awk '{print $1}' ataques.csv | sort -n | uniq -c | sort -n
1 -
1 123123
1 1234
1 123456
1 123456789
1 443/wp-login.php
1 aaa
1 abcd1234
1 admaster
1 admin.
1 AdMiN
1 admin123
1 admina
1 admini
1 administrators
1 adminPeach
1 adminwp
1 admon
1 Adsystem
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 ahmed
1 alfons
1 alireza
1 anna
1 arrow
1 artsadd
1 ask6776
1 atarihost
1 autonewsbot
1 awen
1 azaret
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 Beast3x
1 beescleaning
1 carpetsdubai
1 Casper_Security
1 catmeow
1 chris
1 christiane
1 Christophe
1 control
1 cpolo
1 dagon
1 darcy56
1 Darcy56
1 dedi
1 demilation
1 DemoDemo
1 demo_w1p
1 devadmin
1 dexter
1 digilabs
1 donaljkt9
1 dummy_store_5
1 editor
1 ednabanaag
1 eliasaf
1 enamad
1 eosuperadmin
1 Fabien
1 Farribeiro
1 gestinet
1 globalint
1 goog
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 GP_Admin
1 grupovhn
1 gtfobiash
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 hopefox34
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 info
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 Ivan
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 jbalazs8178
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 john
1 justin
1 kinga
1 kobieta
1 kulturecom
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 lluis
1 loafa
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 mainstream
1 marina
1 martinharvey
1 Megusta
1 microadmin
1 miruku
1 mohit
1 monica
1 mungmee
1 MUWY
1 ndvtzaifnz
1 Nwildner
1 oktay-dogangun
1 options
1 ovauser-admin
1 PiSh3r
1 protan
1 qiang521
1 quantri
1 raeesa
1 Rahul
1 redtor
1 richard
1 Richard
1 ridiz
1 rikimoh39
1 root
1 rootadmin
1 roottn
1 rzu4bd
1 sadminusez
1 santi2
1 senterprisys_admin
1 SEOExpert
1 seojiwo
1 seomaster009
1 shelby96
1 Sion
1 siteadmin
1 smngrs952
1 Support
1 temp3
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 test3
1 tester
1 testionos
1 tuanduongthe
1 tuanpham
1 upastra007
1 Username
1 Vikash
1 voquanghuy
1 wadmiine
1 wdmgpvt
1 webstone24
1 webuser
1 wpadmin
1 WPADMIN
1 w-padmine
1 wp-admine
1 wp-blog
1 wp_developer
1 wpengine
1 wp_rest_api
1 wpsystem
1 wpupdate
1 wuser
1 wwwadm
1 xcom
1 xtw183870bbe
1 xtw18387106f
1 xtw1838711ab
1 xtw183871206
1 xtw183871550
1 xtw183872fc0
1 xtw18387331a
1 xtw1838738ca
1 xtw183873c09
1 xtw183874283
1 xtw183875328
1 xtw1838754ba
1 xtw18387596a
1 xtw183875977
1 xtw1838761a5
1 xtw183876e88
1 xtw18387757d
1 xtw183877c79
1 xtw183878b0d
1 xtw18387958b
1 xtw183879670
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 xtw18387a0c5
1 xtw18387a9de
1 xtw18387aa3b
1 xtw18387adf8
1 xtw18387c077
1 xtw18387c339
1 xtw18387d0aa
1 xtw18387daad
1 xtw18387e84d
1 xtw18387e943
1 xtw18387f29e
1 xuanphong
1 yanz
1 zestful
1 Zestful
1 zokaroll
2 12345678
2 ac
2 adminlin
2 adminsup
2 adminusez
2 Auto
2 bapaksaya
2 burnolurko
2 Clare
2 francisunderwood
2 greeceman
2 happy
2 hex
2 hxq1879
2 ismm
2 jacquespermisdeconduire
2 jatin
2 jisuo
2 lashkari
2 maximixer789
2 Nacht
2 pajero_sports
2 smngrs953
2 smngrs955
2 susan
2 swilliams
2 testuser
2 thuylt
2 wadmines
2 This email address is being protected from spambots. You need JavaScript enabled to view it.
2 wiktorB
2 woopayplug
2 wordpress_admin_bak
2 wordpress_administratora
2 wordpressauto
2 wp
2 wpenginesupport
2 wpmanager
2 wp_postadmin
2 wpuser
2 x
2 xrumertest
2 xtw1838729c0
2 xtw18387754d
2 yanz@123457
2 yeuthuongmongmanh
2 zadminz
2 zutodoko
2 This email address is being protected from spambots. You need JavaScript enabled to view it.
3 admim
3 admin1
3 admin6
3 admingusar
3 bimak73555
3 Chris
3 demo
3 This email address is being protected from spambots. You need JavaScript enabled to view it.
3 mevivu
3 qwee123123
3 Reseller-webmaster
3 talhas
3 test1
3 wadmine
4 1001010
4 andremachado
4 crander
4 hostingadmin
4 matakucing3
4 patola
4 server
4 stender
4 username
4 wordcamp
4 wordpress_administrator
5 administratoir
5 administrator
5 This email address is being protected from spambots. You need JavaScript enabled to view it.
5 excontrol
5 itsme
5 support
5 user
5 wpadmins
5 wpcore
6 smngrs951
7 nwildner
7 paulomartins
11 test
12 farribeiro
18 Admin
19 wadminw
28 wwwadmin
54 linux-br
151 df7c8c98dfd88d9dfad
1270 admin
Realmente alguns logins existem e devem estar assinados nas páginas. Mas o restante é estilo Forrest Gump correndo de um lado pro outro atravessando os Estados Unidos sem saber o porquê.
De uma foto minha sem camisa. Então é um bônus estar em formato ASCII.
Estou usando em lugares como Facebook, onde eu realmente não tenho interesse que vejam fotos minhas.

Eu ainda preciso dar uma editada no conteúdo, mas esse ano foi muito bom no Sweden Rock. Choveu bagarai, mas eu e o Caio bebemos tudo o que podíamos e um pouco mais. Ao som do bom e velho rock n' roll.
Mas agora estou com bastante tempo pra editar tudo que gravei por lá.

Sim, eu comi. E foi maravilhoso.
Já faz um tempo que eu venho querendo apagar tudo o que postei no Twitter, ou X, Xwitter. Não só pelo fato da empresa ter entrado com tudo na era da merdificação, mas porque gosto de pensar que ajudei alguém a virar um milionário. Ainda mais se esse alguém era antes um bilionário.
Buscando no GitHub, encontrei algumas soluções. Uma que pareceu dar mais certa foi a tweetXer, que você abre o console no Twitter e cola código pra fazer a coisa acontecer. O risco é ser banido pelo Twitter, mas acho que nesse ponto é até lucro.
Antes de começar é preciso solicitar a criação de um backup de sua conta. Um dos arquivos js que virão é o que alimentará o script pra ir apagando. Depois é sentar e esperar.
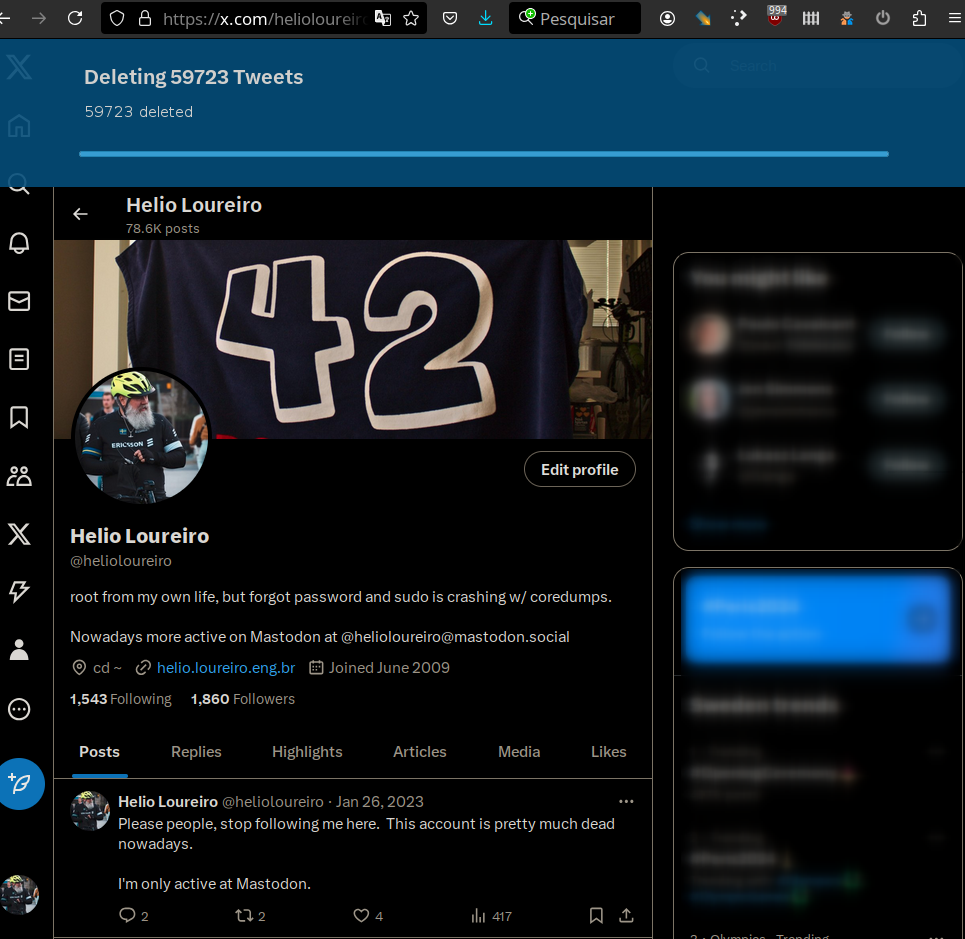
Como é possível ver na imagem acima, o treco mandou bala em 59.723 tweets meus. Haja tweets!
O resultado final foi esse aqui:
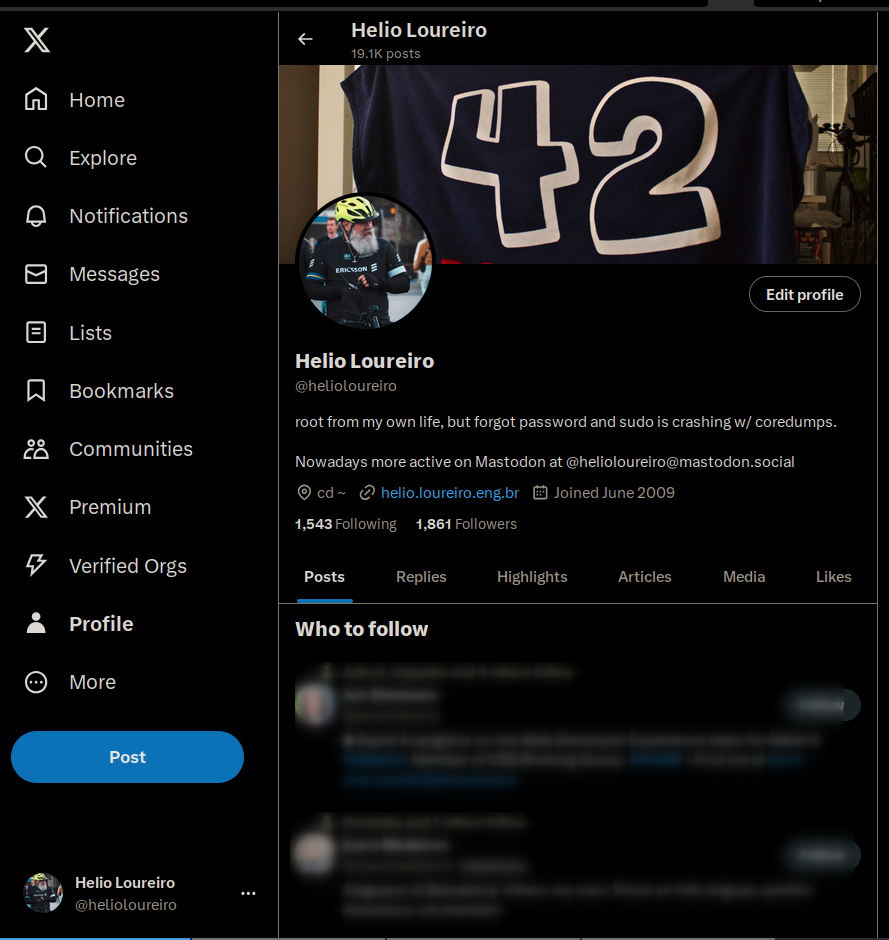
Tive de fazer o scroll em duas página pra mostrar que não sobrou nada. Nada. Foi bem eficiente. Mas...
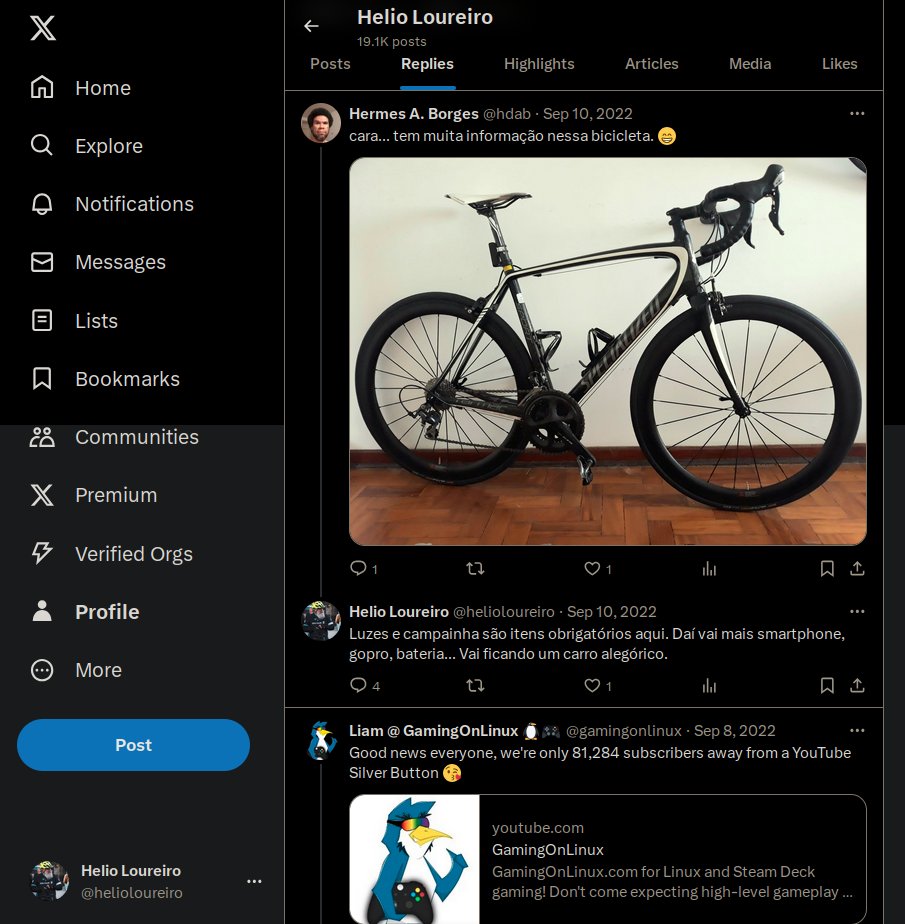
como pode ser visto aqui, meus replies ficaram pra trás.
Mesmo assim é uma ótima ferramenta pra quem quer apagar o que postou ao longo do tempo no Twitter e migrar pro Mastodon.
https://github.com/lucahammer/tweetXer
Eu entrei numa thread com a pergunta sobre o que fazer pra apagar tudo que sobrou. Até o momento segue sem reposta.
Pra quem me segue no Mastodon, sabe que (ou pelo menos vê) que envio um #TootThursday toda quinta-feira. Primeiro o que é isso? Nos tempos de Twitter surgiu o #FollowingFriday, ou #FF pros mais íntimos, que servia pra você indicar perfis interessantes pros outros seguirem. Nessa mesma época eu implementei um script pra fazer isso por mim já que todos que sigo eu considero interessantes.
Pra manter o mesmo espírito no Mastodon, passei a usar o #TootThursday. Como o limite de caracteres é bem mais alto no Mastodon, não é preciso criar um #TT e é possível usar o nome inteiro. E assim sigo postando toda quinta-feira.
Eu andei reparando que meu envio de sugestões estava sempre em 4 ou 5 pessoas. Sempre. E meu programa pra fazer o envio usa 10% da lista de pessoas que sigo, algo que está em mais de 500 hoje em dia no perfil @helioloureiroBR.
Olhei manualmente o uso de account_following( ) e eu estava recebendo somente 40 entradas, mesmo com limite em nulo.
In [14]: u = tt.mastodon.account_following(id=tt.me.id, limit=None) In [15]: len(u) Out[15]: 40
Abri um bug report no GitHub, mas lá mesmo vi a sugestão pra usar account_following( ) com fetch_remaining( ), o que testei aqui.
In [16]: u = tt.mastodon.account_following(id=tt.me.id, limit=80) In [17]: len(u) Out[17]: 80 In [18]: u = tt.mastodon.account_following(id=tt.me.id, limit=500) In [19]: len(u) Out[19]: 80 In [20]: u2 = tt.mastodon.fetch_remaining(u) In [21]: len(u2) Out[21]: 525
E realmente deu certo.
Agora o script está corrigido pra pegar mais pessoas que sigo e selecionar os 10%.
Se quiser olhar o bug report no GitHub, esse é o link: https://github.com/halcy/Mastodon.py/issues/376
No Mastodon mesmo o Mauricio Castro (@
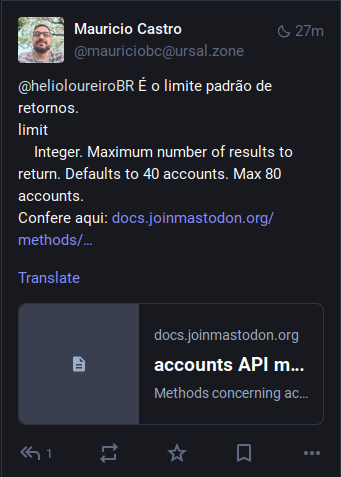
Mas vamos ver se o meu bug report ajuda a melhorar a documentação sobre isso.
UPDATE: escrevi o artigo e esqueci de apontar pro script, caso alguém queira usar ou copiar alguma parte. Ele está aqui: https://github.com/helioloureiro/homemadescripts/blob/master/mastodon-toot-thursday.py
![]()
Mais uma vez participei da BSD Day. Sempre um prazer estar no evento e equanto é possível.
Esse ano seria presencial, mas por causa da greve de funcionários o evento teve de ser online. Sorte minha.
Dessa vez contei a história do Unix. Depois que assisti eu achei que ficou meio confuso. Eu devia ter separado mais por linha de tempo pros eventos ficarem mais interessantes. Fica pra próxima.
Infelizmente minha webcam ficou travando. Ainda não sei bem se o problema foi no sistema, no archlinux, ou na banda (500 Mbps fibra ótica), ou no browser (Google Chrome) ou no Streamyard. Ou mesmo uma combinação de tudo.
Eu quase esqueci que tinha criado essa pérola aqui.
Quase... mas não esqueci :)
Como eu tenho deixado meu desktop boa parte do tempo desligado, eu abri uma porta ssh pro raspberrypi. Por quê? Por nenhum motivo.
Eu nunca realmente usei esse acesso ssh, que externamente estava numa porta alta 22XY, sendo X e Y meio que aleatórios.
E claro que esqueci disso. E hoje fui dar uma olhada. E vários ataques. Ou tentativas desses.
pi@raspberrypi3 ~> journalctl -u ssh | grep rhost | sed 's/.*ruser= //' | sort -n | uniq -c
4 rhost=101.182.50.204
2 rhost=101.182.50.204 user=root
294 rhost=103.187.164.70
1 rhost=103.187.164.70 user=backup
1 rhost=103.187.164.70 user=daemon
21 rhost=103.187.164.70 user=root
12031 rhost=106.12.118.63
1 rhost=106.12.118.63 user=avahi
13 rhost=106.12.118.63 user=backup
9 rhost=106.12.118.63 user=bin
1 rhost=106.12.118.63 user=dnsmasq
3 rhost=106.12.118.63 user=games
1 rhost=106.12.118.63 user=irc
1 rhost=106.12.118.63 user=list
1 rhost=106.12.118.63 user=mail
1 rhost=106.12.118.63 user=messagebus
2 rhost=106.12.118.63 user=pi
1379 rhost=106.12.118.63 user=root
2 rhost=106.12.118.63 user=rtkit
1 rhost=106.12.118.63 user=saned
1 rhost=106.12.118.63 user=sshd
1 rhost=106.12.118.63 user=sys
15 rhost=106.12.118.63 user=www-data
104 rhost=106.244.154.170
37 rhost=106.244.154.170 user=root
6 rhost=110.83.205.126
9 rhost=110.83.205.126 user=root
414 rhost=112.54.121.23
2 rhost=112.54.121.23 user=backup
1 rhost=112.54.121.23 user=bin
1 rhost=112.54.121.23 user=daemon
200 rhost=112.54.121.23 user=root
3 rhost=112.96.138.97
1 rhost=112.96.138.97 user=root
1 rhost=112.97.211.56 user=root
1 rhost=112.97.219.144
1 rhost=112.97.219.144 user=root
1 rhost=112.97.241.205 user=root
1 rhost=112.97.63.81 user=root
147 rhost=113.116.156.72
1 rhost=113.116.156.72 user=bin
1 rhost=113.116.156.72 user=games
2 rhost=113.116.156.72 user=man
1 rhost=113.116.156.72 user=pi
1 rhost=113.116.156.72 user=root
1 rhost=113.116.156.72 user=sshd
1 rhost=113.116.156.72 user=sync
2 rhost=113.116.156.72 user=sys
645 rhost=113.161.59.72
45 rhost=113.161.59.72 user=root
3 rhost=113.194.225.182
1 rhost=113.194.225.182 user=root
10679 rhost=115.68.114.145
5 rhost=115.68.114.145 user=backup
2 rhost=115.68.114.145 user=bin
2 rhost=115.68.114.145 user=daemon
2 rhost=115.68.114.145 user=dnsmasq
1 rhost=115.68.114.145 user=geoclue
1 rhost=115.68.114.145 user=gnats
1 rhost=115.68.114.145 user=list
1 rhost=115.68.114.145 user=lp
2 rhost=115.68.114.145 user=mail
2 rhost=115.68.114.145 user=pi
2181 rhost=115.68.114.145 user=root
3 rhost=115.68.114.145 user=sshd
1 rhost=115.68.114.145 user=sys
1 rhost=115.68.114.145 user=systemd-coredump
2 rhost=115.68.114.145 user=tss
24 rhost=115.68.114.145 user=uucp
9 rhost=115.68.114.145 user=www-data
1994 rhost=115.68.193.229
4 rhost=115.68.193.229 user=backup
4 rhost=115.68.193.229 user=bin
3 rhost=115.68.193.229 user=daemon
2 rhost=115.68.193.229 user=pi
863 rhost=115.68.193.229 user=root
3 rhost=115.68.193.229 user=www-data
171 rhost=115.73.212.140
70 rhost=115.73.212.140 user=root
1 rhost=115.73.212.140 user=www-data
240 rhost=115.73.222.121
27 rhost=115.73.222.121 user=root
117 rhost=115.79.138.57
28 rhost=115.79.138.57 user=root
1 rhost=115.79.138.57 user=uucp
41 rhost=117.132.195.92
13 rhost=117.132.195.92 user=root
1 rhost=117.132.195.92 user=uucp
597 rhost=119.204.234.220
1 rhost=119.204.234.220 user=lp
1 rhost=119.204.234.220 user=news
176 rhost=119.204.234.220 user=root
2 rhost=119.204.234.220 user=sshd
7 rhost=121.170.243.115
2 rhost=121.170.243.115 user=root
5 rhost=121.207.184.52
1 rhost=121.207.184.52 user=root
320 rhost=121.237.47.72
16 rhost=121.237.47.72 user=root
1 rhost=123.226.234.157 user=root
3 rhost=138.68.65.85
6 rhost=138.68.65.85 user=root
822 rhost=153.99.251.110
2 rhost=153.99.251.110 user=backup
2 rhost=153.99.251.110 user=bin
1 rhost=153.99.251.110 user=daemon
2 rhost=153.99.251.110 user=pi
366 rhost=153.99.251.110 user=root
1 rhost=153.99.251.110 user=www-data
52 rhost=171.125.189.103
2 rhost=171.125.189.103 user=root
4349 rhost=175.126.146.151
1 rhost=175.126.146.151 user=avahi
1 rhost=175.126.146.151 user=backup
1 rhost=175.126.146.151 user=bin
1 rhost=175.126.146.151 user=daemon
1 rhost=175.126.146.151 user=dnsmasq
1 rhost=175.126.146.151 user=games
1 rhost=175.126.146.151 user=gnats
1 rhost=175.126.146.151 user=irc
1 rhost=175.126.146.151 user=list
1 rhost=175.126.146.151 user=messagebus
1 rhost=175.126.146.151 user=nobody
1 rhost=175.126.146.151 user=pi
511 rhost=175.126.146.151 user=root
1 rhost=175.126.146.151 user=sshd
1 rhost=175.126.146.151 user=sync
1 rhost=175.126.146.151 user=sys
1 rhost=175.126.146.151 user=systemd-coredump
1 rhost=175.126.146.151 user=uucp
1 rhost=175.126.146.151 user=www-data
2376 rhost=175.126.146.170
2 rhost=175.126.146.170 user=backup
8 rhost=175.126.146.170 user=bin
2 rhost=175.126.146.170 user=daemon
3 rhost=175.126.146.170 user=lp
1 rhost=175.126.146.170 user=news
4 rhost=175.126.146.170 user=nobody
1601 rhost=175.126.146.170 user=root
1 rhost=175.126.146.170 user=saned
3 rhost=175.126.146.170 user=sshd
100 rhost=176.232.199.34
9 rhost=176.232.199.34 user=root
2 rhost=180.102.215.191
2 rhost=180.102.215.191 user=root
50 rhost=180.214.179.130
1 rhost=180.214.179.130 user=nobody
12 rhost=180.214.179.130 user=root
104 rhost=182.161.158.243
1 rhost=182.161.158.243 user=bin
36 rhost=182.161.158.243 user=root
64 rhost=182.92.205.87 user=root
168 rhost=183.239.61.5
36 rhost=183.239.61.5 user=root
1 rhost=183.239.61.5 user=uucp
802 rhost=183.6.114.32
9 rhost=183.6.114.32 user=bin
5 rhost=183.6.114.32 user=daemon
2 rhost=183.6.114.32 user=nobody
370 rhost=183.6.114.32 user=root
31 rhost=185.11.61.234
2 rhost=185.11.61.234 user=backup
6 rhost=185.11.61.234 user=root
127 rhost=185.11.61.88
18 rhost=185.11.61.88 user=root
1 rhost=185.11.61.88 user=uucp
1 rhost=185.11.61.88 user=www-data
640 rhost=188.92.243.94
5 rhost=188.92.243.94 user=backup
2 rhost=188.92.243.94 user=bin
1 rhost=188.92.243.94 user=daemon
1 rhost=188.92.243.94 user=news
1 rhost=188.92.243.94 user=proxy
381 rhost=188.92.243.94 user=root
1 rhost=188.92.243.94 user=sync
1 rhost=188.92.243.94 user=www-data
10 rhost=190.108.93.158
18 rhost=190.108.93.158 user=root
1217 rhost=190.2.143.54
13 rhost=190.2.143.54 user=bin
7 rhost=190.2.143.54 user=daemon
4 rhost=190.2.143.54 user=nobody
561 rhost=190.2.143.54 user=root
15 rhost=190.238.35.29
1 rhost=190.238.35.29 user=pi
1 rhost=190.238.35.29 user=root
12006 rhost=190.89.76.29
7 rhost=190.89.76.29 user=pi
389 rhost=190.89.76.29 user=root
19 rhost=195.122.229.82
1 rhost=195.122.229.82 user=root
1 rhost=2.53.171.103 user=root
803 rhost=212.186.185.171
10 rhost=212.186.185.171 user=bin
5 rhost=212.186.185.171 user=daemon
2 rhost=212.186.185.171 user=nobody
370 rhost=212.186.185.171 user=root
234 rhost=213.63.233.87
1 rhost=213.63.233.87 user=backup
1 rhost=213.63.233.87 user=bin
2 rhost=213.63.233.87 user=lp
181 rhost=213.63.233.87 user=root
1 rhost=213.63.233.87 user=sys
1 rhost=213.63.233.87 user=usbmux
28 rhost=218.101.201.179
1 rhost=218.101.201.179 user=root
7 rhost=218.81.76.84
10 rhost=218.81.76.84 user=root
822 rhost=220.249.111.98
2 rhost=220.249.111.98 user=backup
2 rhost=220.249.111.98 user=bin
1 rhost=220.249.111.98 user=daemon
2 rhost=220.249.111.98 user=pi
366 rhost=220.249.111.98 user=root
1 rhost=220.249.111.98 user=www-data
289 rhost=222.107.116.47
92 rhost=222.107.116.47 user=root
159 rhost=222.208.47.30
1 rhost=222.208.47.30 user=pulse
50 rhost=222.208.47.30 user=root
23 rhost=39.118.171.84
24 rhost=39.118.171.84 user=root
4 rhost=39.144.46.7
2 rhost=39.144.46.7 user=root
63 rhost=39.144.46.82
2 rhost=39.144.46.82 user=root
996 rhost=39.162.8.99
1 rhost=39.162.8.99 user=list
1 rhost=39.162.8.99 user=proxy
77 rhost=39.162.8.99 user=root
1 rhost=39.162.8.99 user=sys
1 rhost=39.162.8.99 user=www-data
6 rhost=42.49.109.197
3 rhost=42.49.109.197 user=root
758 rhost=46.7.73.67
1 rhost=46.7.73.67 user=bin
1 rhost=46.7.73.67 user=nobody
240 rhost=46.7.73.67 user=root
1672 rhost=51.81.245.139
2 rhost=51.81.245.139 user=backup
8 rhost=51.81.245.139 user=root
27 rhost=51.81.245.139 user=uucp
5 rhost=51.81.245.139 user=www-data
254 rhost=58.218.252.82
1 rhost=58.218.252.82 user=proxy
47 rhost=58.218.252.82 user=root
316 rhost=59.58.102.162
1 rhost=59.58.102.162 user=backup
97 rhost=59.58.102.162 user=root
1 rhost=59.58.102.162 user=sync
12 rhost=61.149.209.194
4 rhost=61.149.209.194 user=root
134 rhost=62.122.184.252
10 rhost=62.122.184.252 user=root
2 rhost=62.122.184.252 user=sshd
2 rhost=67.205.142.48
3 rhost=75.119.144.68 user=root
55 rhost=81.14.168.152
25 rhost=81.14.168.152 user=root
1 rhost=81.14.168.152 user=saned
29 rhost=85.209.11.226
1 rhost=85.209.11.226 user=pi
5 rhost=85.209.11.226 user=root
1 rhost=85.209.11.226 user=sshd
1809 rhost=85.24.245.46
8 rhost=85.24.245.46 user=backup
1 rhost=85.24.245.46 user=bin
1 rhost=85.24.245.46 user=lp
1 rhost=85.24.245.46 user=mail
2 rhost=85.24.245.46 user=news
4 rhost=85.24.245.46 user=nobody
1 rhost=85.24.245.46 user=proxy
1229 rhost=85.24.245.46 user=root
1 rhost=85.24.245.46 user=uucp
413 rhost=85.246.237.232
1 rhost=85.246.237.232 user=games
1 rhost=85.246.237.232 user=nobody
293 rhost=85.246.237.232 user=root
1 rhost=85.246.237.232 user=saned
1 rhost=85.246.237.232 user=sshd
1 rhost=85.246.237.232 user=uucp
1 rhost=86.227.110.209
37 rhost=86.236.26.148
12 rhost=86.236.26.148 user=root
1 rhost=90.134.40.219 user=root
306 rhost=90.40.72.74
1 rhost=90.40.72.74 user=root
7 rhost=90.40.72.74 user=uucp
1 rhost=90.40.72.74 user=www-data
129 rhost=94.208.120.232
1 rhost=94.208.120.232 user=daemon
13 rhost=94.208.120.232 user=root
Desativei a porta.
O raspberrypi precisa de senha pra sudo, coisa que aprendi depois do ataque bem sucedido do Maycon que ficou eternizado dentro do código do stallmanbot.py:
def Hacked(obj, cmd):
try:
obj.reply_to(cmd, u"This is the gallery of metions from those who dared to hack, and just made it true.")
obj.reply_to(cmd, u"Helio is my master but Maycon is my hacker <3 (Hack N' Roll)")
gif = "https://media.giphy.com/media/26ufcVAp3AiJJsrIs/giphy.gif"
obj.send_document(cmd.chat.id, gif)
except Exception as e:
obj.reply_to(cmd, f"Deu merda: {e}")
Então acredito que mesmo um ataque bem sucedido de ssh não tenha causado grandes danos. Mas nunca é certeza :)
Outro ponto interessante é que todos os ataques vieram por IPv4. Nenhum, absolutamente nenhum, por IPv6. Até nesse ponto IPv6 é mais seguro.
Page 8 of 40
