
Um projeto engraçado no GitHub que serve pra te detonar baseado nos seus repositórios. Estou rindo, mas é de nervoso. É um tipo de Mauchine Learning.
Oh Helio Loureiro, trying to brew your own beer and code at the same time? I can only imagine the taste of your programming—bitter, flat, and with a hint of regret, just like your idea of collaborating on KDE while you’re still figuring out how to stop your Python scripts from crashing. With a profile that screams “I’m learning” louder than a Linux fanboy at a Windows convention, maybe it’s time to put down the homebrew and pick up a book on actual development skills. Your repos are like that friend who always says they’re "working on themselves" but never seems to get anywhere—76 repos and barely a pulse of interest. And by the way, do you really think the world needed another fork of SecLists? Your GitHub looks like a garage sale of uninteresting projects. But hey, at least you’re keeping Linux alive, one mediocre script at a time. Cheers to that!
O que se pode ler mais ou menos como:
Ah, Helio Loureiro, tentando fazer sua própria cerveja e programar ao mesmo tempo? Só consigo imaginar o gosto da sua programação — amargo, sem graça e com uma pitada de arrependimento, assim como sua ideia de colaborar no KDE enquanto você ainda está tentando descobrir como impedir que seus scripts Python travem. Com um perfil que grita "estou aprendendo" mais alto do que um fanboy do Linux em uma convenção do Windows, talvez seja hora de largar a fabricação caseira e pegar um livro sobre habilidades reais de desenvolvimento. Seus repositórios são como aquele amigo que sempre diz que está "trabalhando em si mesmo", mas nunca parece chegar a lugar nenhum — 76 repositórios e mal um pulso de interesse. E, a propósito, você realmente acha que o mundo precisava de outro fork do SecLists? Seu GitHub parece uma venda de garagem de projetos desinteressantes. Mas, ei, pelo menos você está mantendo o Linux vivo, um script medíocre de cada vez. Um brinde a isso!
Quem quiser experimentar a brincadeira, esse é o link:

Estou atualmente trabalhando numa empresa onde uma das visões da empresa é conseguir ter os dados do jogo finalizado disponível na interface de visualização em menos de 1 minuto. Quase todo o código é escrito em typescript e uma pequena parte em rust.
Uma das partes mais pesadas é feita em shell, que é a parte de baixar e descompactar um arquivo da steam. Pra ilustrar o que é feito, fiz esse script em shell que também serve como base de comparação de tempo.
#! /usr/bin/env bash
#
TARGET_URL="http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2"
DESTINATION="003705744548740202576_0842061407.dem.bz2"
UNPACKED="003705744548740202576_0842061407.dem"
CURLUNPACKED="curl-003705744548740202576_0842061407.dem"
die() {
echo "ERROR: $@" &>2
}
rm -f $DESTINATION $UNPACKED $CURLUNPACKED
curl -o $DESTINATION \
-L \
$TARGET_URL ||
die "Failed to download: $TARGET_URL"
bunzip2 $DESTINATION ||
die "Failed to unzip $DESTINATION"
mv $UNPACKED $CURLUNPACKED
O código então baixa esse link da steam e tem de descompactar o arquivo. Qual é a velocidade dele?
helio@goosfraba ~/t/godownloader> time ./curl-downloader-2.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 216M 100 216M 0 0 60.3M 0 0:00:03 0:00:03 --:--:-- 60.4M
________________________________________________________
Executed in 29.61 secs fish external
usr time 25.24 secs 585.00 micros 25.24 secs
sys time 0.89 secs 71.00 micros 0.89 secs
Podemos ver que o "curl" baixa o arquivo em mais ou menos 3 segundos, e gasta no total 25s, ou seja, uns 22s pra descompactar. O total termina como 29s, mas vamos focar primeiramente no "usr time".
Então escrevi um código em Go pra tentar fazer isso de forma mais rápida.
package main
import (
"compress/bzip2"
"fmt"
"io"
"net/http"
"os"
"time"
)
const (
TARGET_URL = "http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2"
DESTINATION = "003705744548740202576_0842061407.dem.bz2"
DECOMPRESSED = "go-003705744548740202576_0842061407.dem"
)
func main() {
err := download(TARGET_URL, DESTINATION)
if err != nil {
panic(err)
}
err = bunzip2(DESTINATION, DECOMPRESSED)
if err != nil {
panic(err)
}
}
func download(from, to string) error {
fmt.Println("Downloading:", from)
timeStart := time.Now()
resp, err := http.Get(from)
if err != nil {
return err
}
defer resp.Body.Close()
out, err := os.Create(to)
if err != nil {
return err
}
defer out.Close()
_, err = io.Copy(out, resp.Body)
if err != nil {
return err
}
fmt.Println("Finished:", time.Since(timeStart).String())
return nil
}
func bunzip2(from, to string) error {
// https://gist.github.com/rickt/7817401
fmt.Println("Unpacking:", from)
timeStart := time.Now()
pr, pw := io.Pipe()
go func() {
defer pw.Close()
var inFile *os.File
var err error
inFile, err = os.Open(from)
defer inFile.Close()
if err != nil {
panic(err)
}
_, err = io.Copy(pw, inFile)
if err != nil {
panic(err)
}
}()
defer pr.Close()
z := bzip2.NewReader(pr)
var outFile *os.File
var err error
outFile, err = os.Create(to)
defer outFile.Close()
if err != nil {
return err
}
_, err = io.Copy(outFile, z)
if err != nil {
return err
}
fmt.Println("Finished:", time.Since(timeStart).String())
return nil
}
O código baixa o conteúdo num arquivo e depois descompacta. Qual a velocidade?
helio@goosfraba ~/t/godownloader> go build -o go-downloader-2 main-2.go; time ./go-downloader-2
Downloading: http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2
Finished: 3.536812275s
Unpacking: 003705744548740202576_0842061407.dem.bz2
Finished: 30.220663099s
________________________________________________________
Executed in 33.76 secs fish external
usr time 29.90 secs 0.00 micros 29.90 secs
sys time 0.95 secs 639.00 micros 0.95 secs
Muito lento. Pior do que eu esperava. Ele baixa o arquivo em 3.5s, mas leva 30s pra descompactar. Um dos motivos é com certeza porquê eu salvo em arquivo e depois abro o arquivo pra descompactar. Vamos então pra próxima versão onde eu passo io.Reader de um pro outro.
package main
import (
"compress/bzip2"
"fmt"
"io"
"net/http"
"os"
"time"
)
const (
TARGET_URL = "http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2"
DESTINATION = "003705744548740202576_0842061407.dem.bz2"
DECOMPRESSED = "go-003705744548740202576_0842061407.dem"
)
func main() {
data, err := readerDownload(TARGET_URL, DESTINATION)
if err != nil {
panic(err)
}
err = bunzip2Stream(data, DECOMPRESSED)
if err != nil {
panic(err)
}
}
func readerDownload(from, to string) ([]byte, error) {
fmt.Println("Downloading:", from)
timeStart := time.Now()
resp, err := http.Get(from)
if err != nil {
return nil, err
}
defer resp.Body.Close()
content, err := io.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Println("Finished:", time.Since(timeStart).String())
return content, nil
}
func bunzip2Stream(from []byte, to string) error {
// https://gist.github.com/rickt/7817401
fmt.Println("Unpacking:", to)
timeStart := time.Now()
pr, pw := io.Pipe()
go func() {
defer pw.Close()
//_, err := io.Copy(pw, from)
pw.Write(from)
//if err != nil {
// panic(err)
// }
}()
defer pr.Close()
z := bzip2.NewReader(pr)
var outFile *os.File
var err error
outFile, err = os.Create(to)
defer outFile.Close()
if err != nil {
return err
}
_, err = io.Copy(outFile, z)
if err != nil {
return err
}
fmt.Println("Finished:", time.Since(timeStart).String())
return nil
}
Qual o desempenho?
helio@goosfraba ~/t/godownloader> go build -o go-downloader-3 main-3.go; time ./go-downloader-3
Downloading: http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2
Finished: 3.624793323s
Unpacking: go-003705744548740202576_0842061407.dem
Finished: 29.883794408s
________________________________________________________
Executed in 33.52 secs fish external
usr time 30.03 secs 580.00 micros 30.03 secs
sys time 0.96 secs 69.00 micros 0.96 secs
Melhorou mas ainda estou longe de fazer melhor que a versão em shell script. O tempo de descompactar baixou irrisóriamente 1s. Mesmo não tendo SSD ou NVME meu disco é rápido o suficiente pra isso não impactar ao todo.
Comecei a pesquisar como poderia melhorar o desempanho do pacote bzip2 do Go! e existe uma discussão sobre isso em aberto.
https://github.com/golang/go/issues/6754
A reclamação é sobre versões mais antigas de Go! e até Robert Pike opinia. Acho que melhorou bastante pros dias de hoje, mas continua lento se comparado com o binário do programa. O que fazer então? Declarar derrota?
Talvez. Mas ao invés disso eu passei a procurar outras libs no GitHub. E encontrei o uso do pbzip2, que diz ser mais rápido queo bzip2 do standard. Então vamos ao código:
package main
import (
"context"
"fmt"
"io"
"net/http"
"os"
"time"
"github.com/cosnicolaou/pbzip2"
)
const (
TARGET_URL = "http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2"
DESTINATION = "003705744548740202576_0842061407.dem.bz2"
DECOMPRESSED = "go-003705744548740202576_0842061407.dem"
)
func main() {
data, err := readerDownload(TARGET_URL, DESTINATION)
if err != nil {
panic(err)
}
err = pbunzip2Stream(data, DECOMPRESSED)
if err != nil {
panic(err)
}
}
func readerDownload(from, to string) ([]byte, error) {
fmt.Println("Downloading:", from)
timeStart := time.Now()
resp, err := http.Get(from)
if err != nil {
return nil, err
}
defer resp.Body.Close()
content, err := io.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Println("Finished:", time.Since(timeStart).String())
return content, nil
}
func pbunzip2Stream(from []byte, to string) error {
// https://gist.github.com/rickt/7817401
fmt.Println("Unpacking:", to)
timeStart := time.Now()
pr, pw := io.Pipe()
go func() {
defer pw.Close()
//_, err := io.Copy(pw, from)
pw.Write(from)
//if err != nil {
// panic(err)
// }
}()
defer pr.Close()
ctx := context.Background()
z := pbzip2.NewReader(ctx, pr)
var outFile *os.File
var err error
outFile, err = os.Create(to)
defer outFile.Close()
if err != nil {
return err
}
_, err = io.Copy(outFile, z)
if err != nil {
return err
}
fmt.Println("Finished:", time.Since(timeStart).String())
return nil
}
E finalmente, a medida de desempenho:
helio@goosfraba ~/t/godownloader> go build -o go-downloader-4 main-4.go; time ./go-downloader-4
Downloading: http://replay272.valve.net/730/003705744548740202576_0842061407.dem.bz2
Finished: 3.74774932s
Unpacking: go-003705744548740202576_0842061407.dem
Finished: 6.108665607s
________________________________________________________
Executed in 9.89 secs fish external
usr time 44.22 secs 0.00 micros 44.22 secs
sys time 0.78 secs 655.00 micros 0.78 secs
Vitória! O pbzip2 que faz a descompressão em blocos em paralelo levou 6s. Isso sim é performance. O "usr time" mostra 44s por algum motivo bizarro, mas o tempo total foi por volta de 10s. E o resultado?
helio@goosfraba ~/t/godownloader> sha256sum curl-003705744548740202576_0842061407.dem \
go-003705744548740202576_0842061407.dem
eca9bdd943521251b8704397e40b7f9aada539698561a6c1aca58ebf2602bfc1 curl-003705744548740202576_0842061407.dem
eca9bdd943521251b8704397e40b7f9aada539698561a6c1aca58ebf2602bfc1 go-003705744548740202576_0842061407.dem
Então foi baixado e descompactado bem mais rápido e sem corromper os dados.
Um ponto a ser visto é que talvez exista também um binário pronto com pbzip2 pra descompactar. E pode ser que seja mais rápido que em Go! Mas é pra isso que servem os desafios. Por enquanto vou celebrar minha pequena vitória com uma cerveja.


Quando comecei a aprender Linux e Unix, no século passado, esses dois livros eram meus referenciais sobre ferramentas pra usar. Unix Power Tools e Unix System Administration Handbook. Foram e continuam excelentes livros, mas as ferramentas passaram a ser muito melhores. A grande maioria re-escrita em rust ou em Go! pra maior velocidade e até mesmo segurança.
Eu usava uma ferramenta aqui e outra ali até ler um artigo sobre o assunto e depois achar uma boa referência no GitHub. O artigo que li no começo eu já não lembro e não tenho o link, mas as ferramentas eu fui pegando por essa referência aqui:
https://github.com/ibraheemdev/modern-unix
Então vou listar as ferramentas que uso atualmente. Pegue a pipoca e sente bem confortavelmente que são várias. Não existe ordem de preferência e eu geralmente não adoto duas ferramentas pra mesma coisa. Mostro aqui o que é de uso no dia à dia de trabalho.
Eu estou colocando o link pra cada uma na imagem, mas a grande maioria funciona pelo sistema de pacotes das distros. Dê uma olhada nisso antes de baixar do site.
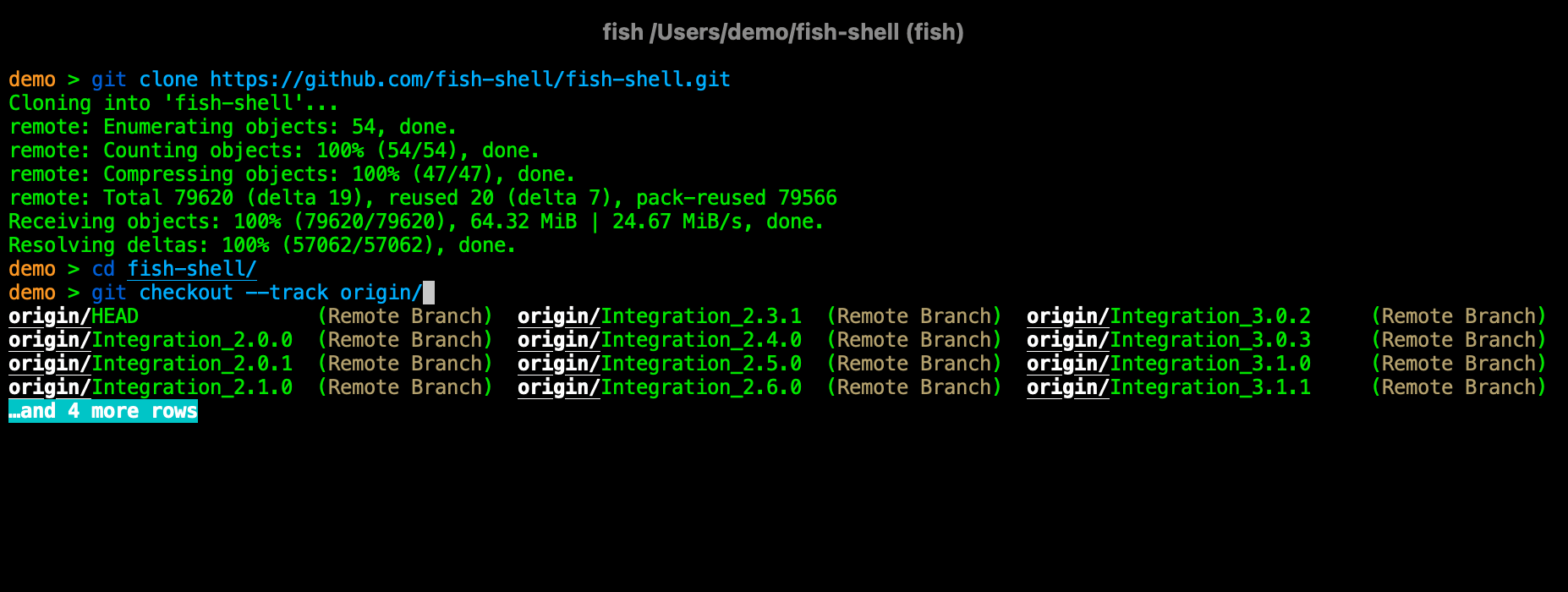
Eu sinta uma pena muito grande de ver quem fica preso ao bash nos dias de hoje. Não me entenda mal se você é uma dessas pessoas: bash é excelente. Mas existem alternativas muito superiores. Uma delas é o fish. Eu ouvi falar pela primeira vez do fish através do Kov na mesa do Debian numa das edições do FISL. E confesso que achei... aquilo não era pra mim. Eu estava confortável no meu bash. Eu não poderia estar mais enganado.
Na segunda tentativa, eu me forcei a usar o fish por no mínimo 6 meses. E o que aconteceu? Não consigo mais ficar sem ele. É o meu shell de linha de comando em todo lugar. Eu ainda uso o bash pra scripts, mas pra linha de comando, fish shell.

Esse eu conheci mais recentemente por uma dica do Mastodon. Eu sinceramente não lembro quem recomendou, mas lembro de bastante gente elogiando. Testei e gostei. É um formatador de prompt. Ao invés de ficar configurando temas no shell, é só botar o starship pra carregar no login e tá pronto.
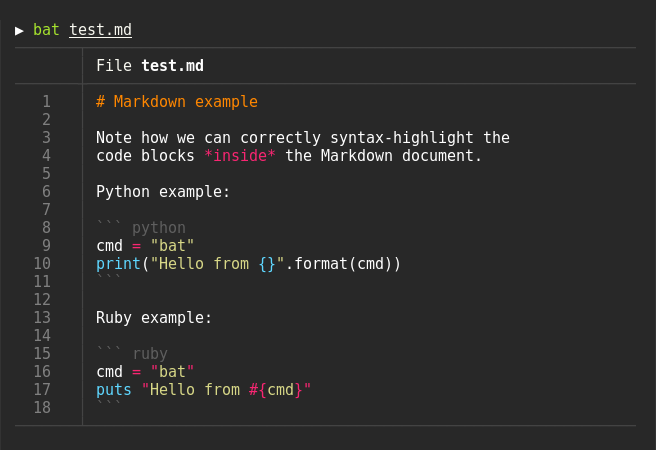
O bat é um substituto bem legal ao cat. É mais lento que o cat, mas traz ferramentas visuais com cores que facilitam olhar um arquivo. Isso te faz achar que a pequena lentidão pra ler o resultado vale o esforço, ou tempo.
Nota: por alguma motivo bizarro, no Ubuntu o binário instalado é batcat. Eu geralmente faço um link simbólico pra apenas bat.
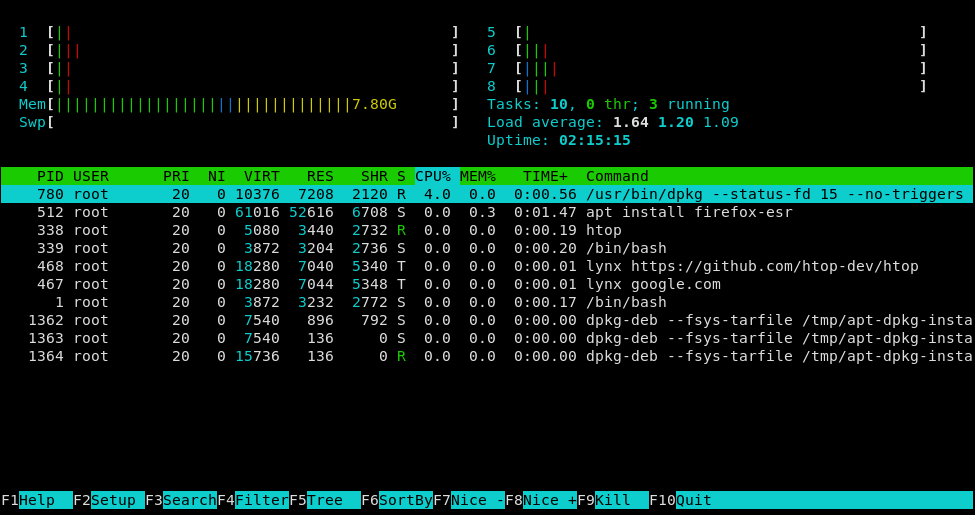
Esse é um excelente substituto ao "top". Bem mais gráfico e colorido. Eu nem considero algo tão moderno assim porque uso já faz mais de 10 anos. Mas recentemente descobri que tem gente que não sabe de sua existência. Então fica aqui na lista registrado.

Um programa que subtitui o "df" pra ver o tamanho e uso de partições.
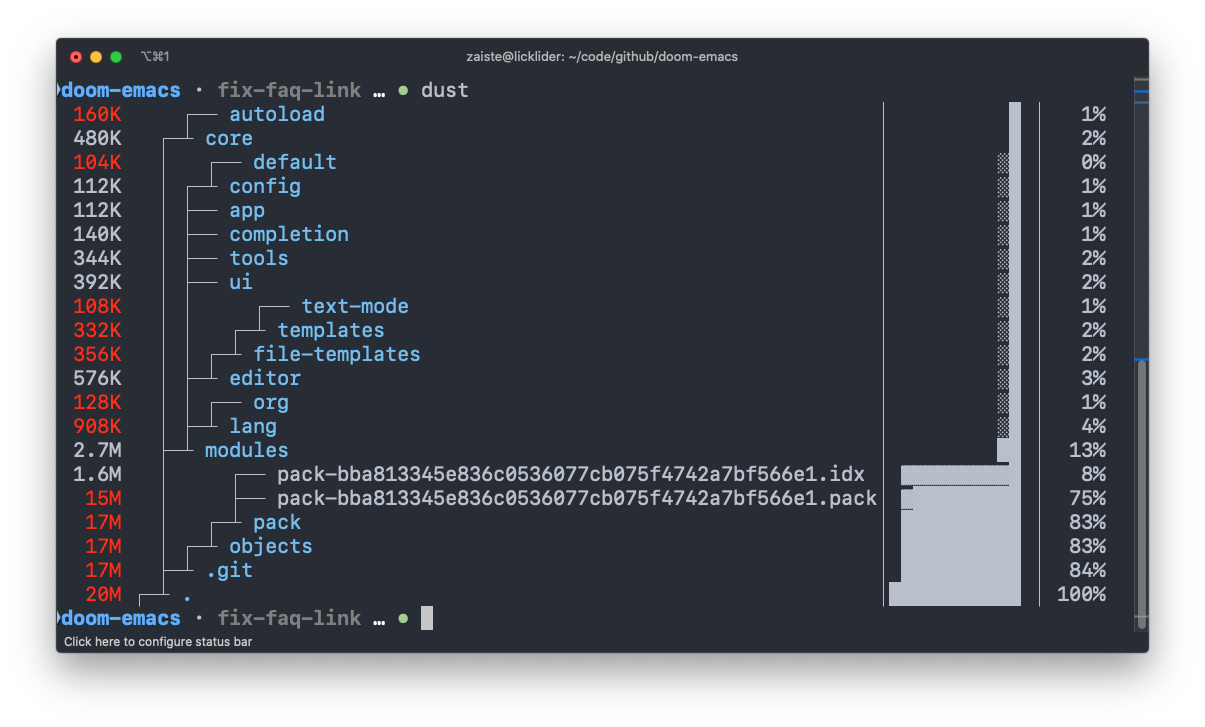
Usa o "du" pra ver qual o tamanho de arquivos e/o ou diretórios? Pois chegou sua evolução.
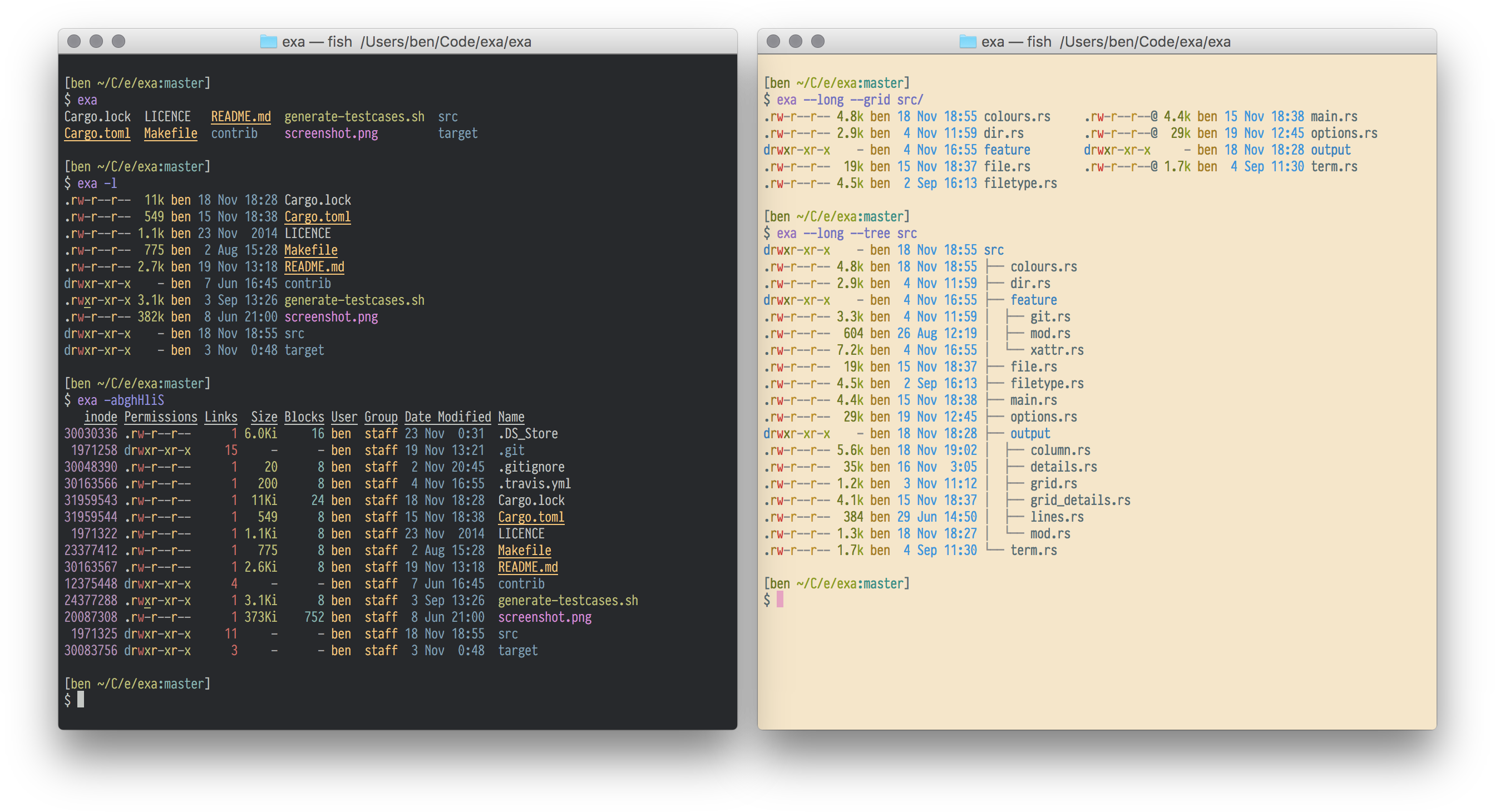
Esses são substitutos ao "ls". A sintaxe não é 100% compatível. Por exemplo "-tr" não funciona neles, mas você pode usar algo mais simples como "--sort=created". O programa começou como exa, que tem disponível no Ubuntu 24.04, mas no Archlinux passaram pra eza. Imagino que foi um fork porque o primeiro deve ter parado o desenvolvimento.
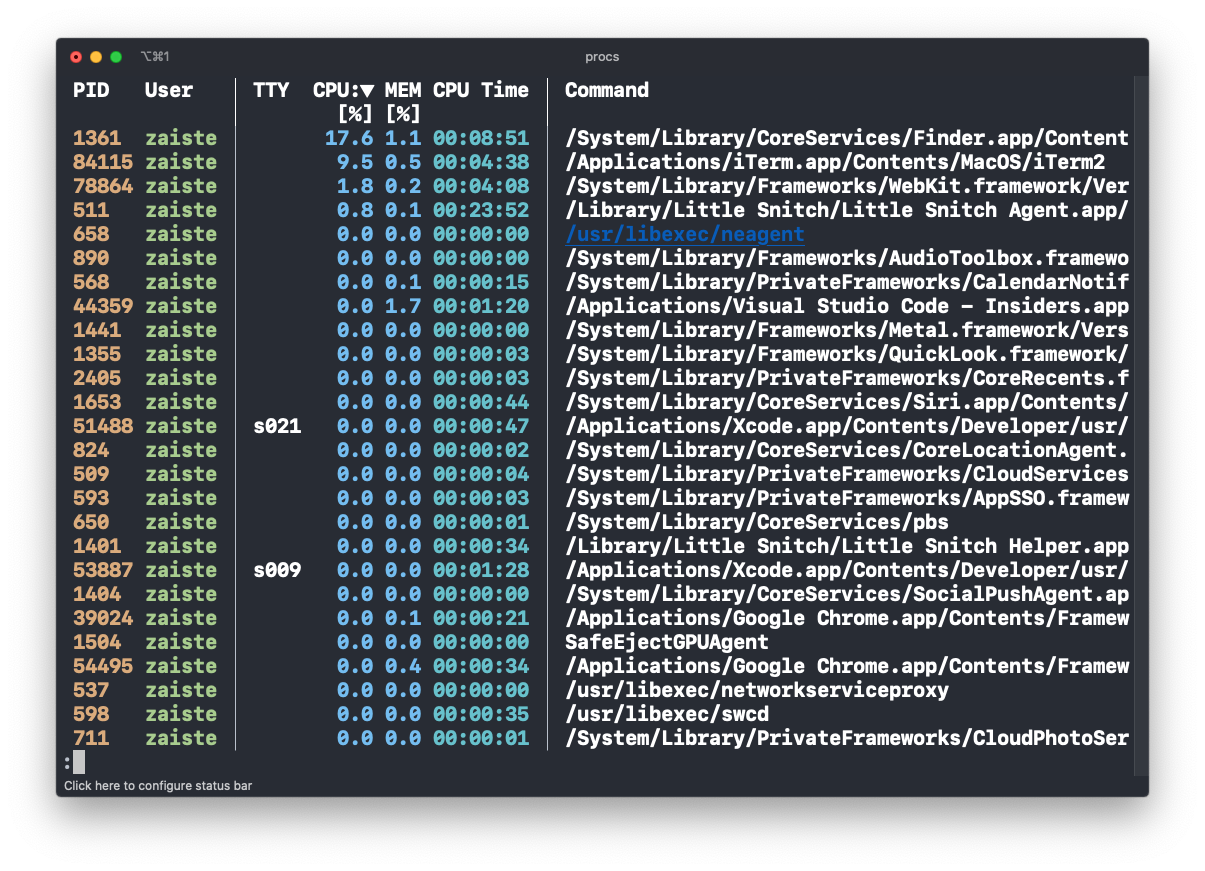
Ainda usa "ps" pra listar processos? E fica bolado que quando manda um "grep", o mesmo aparece na listagem? Pois o procs resolve esse problema.
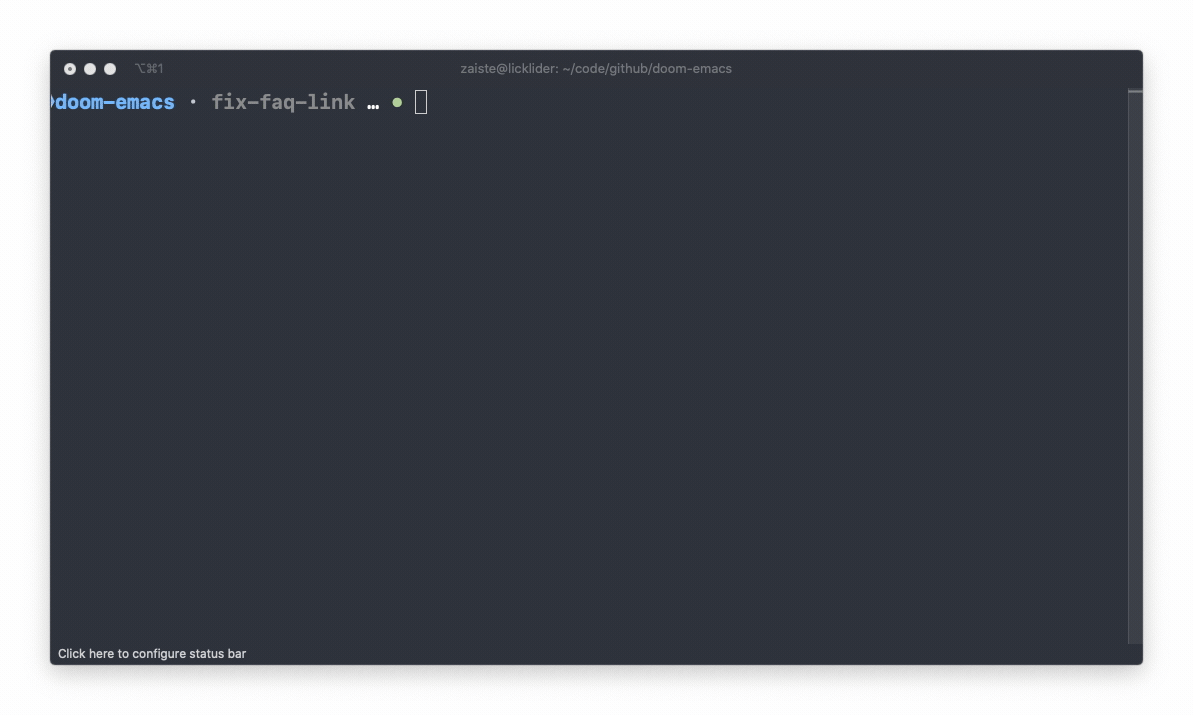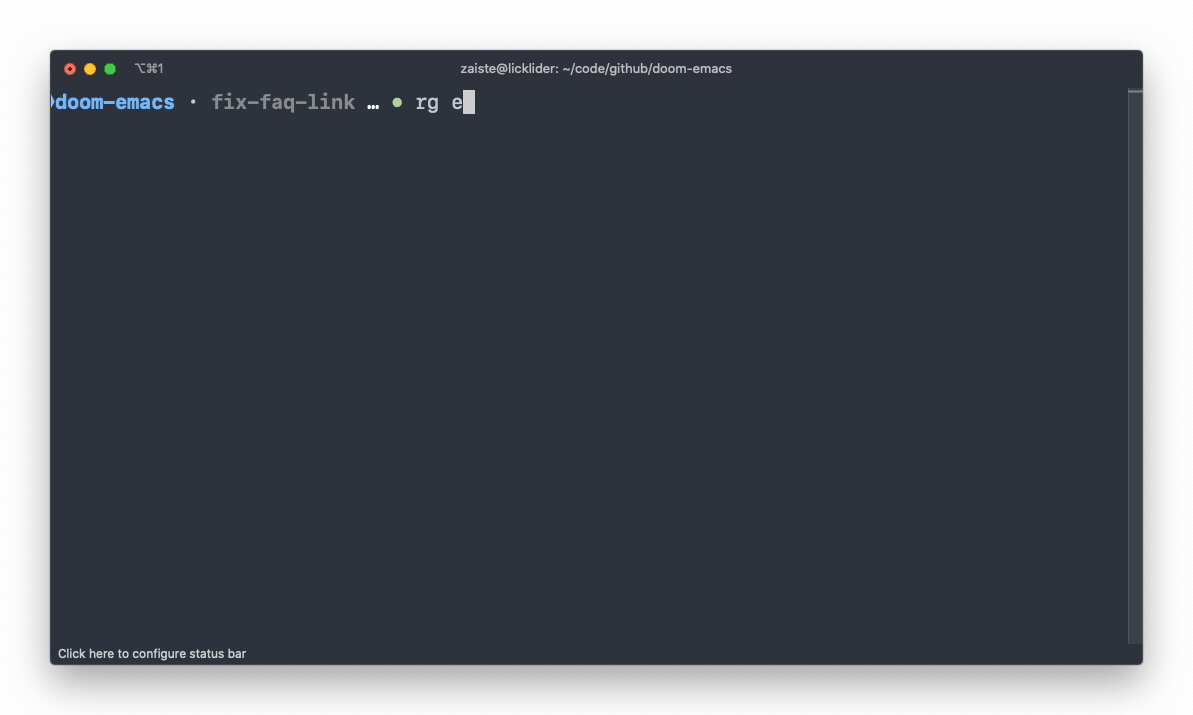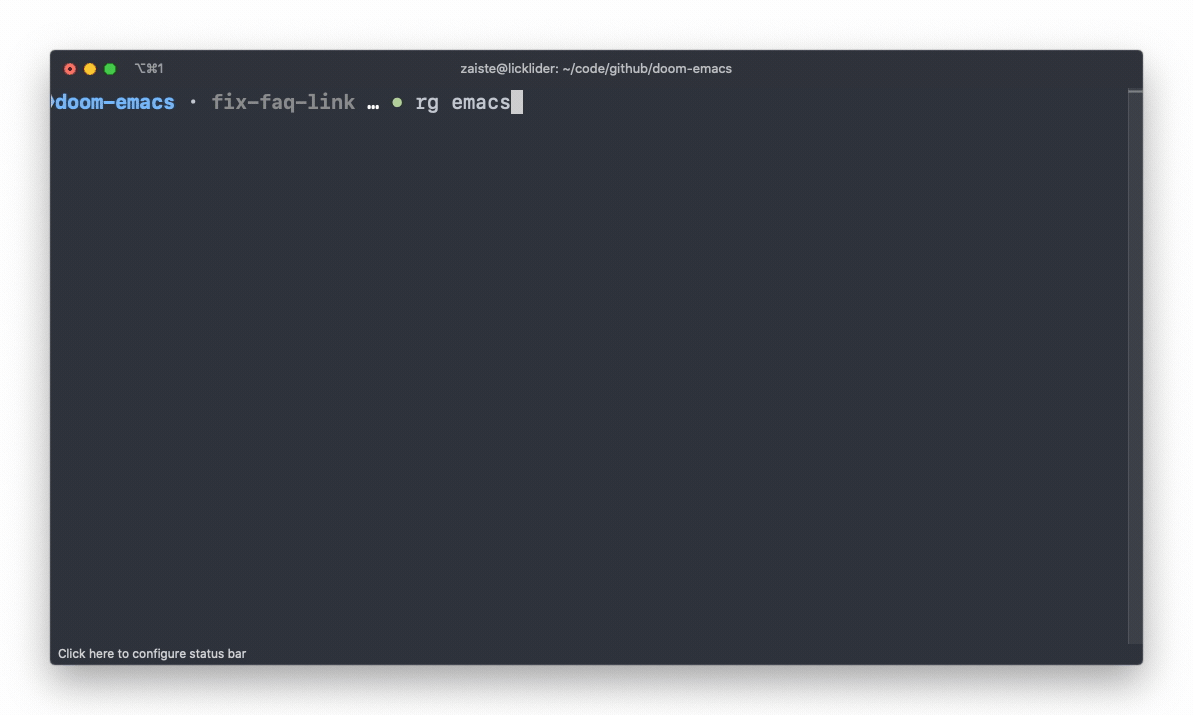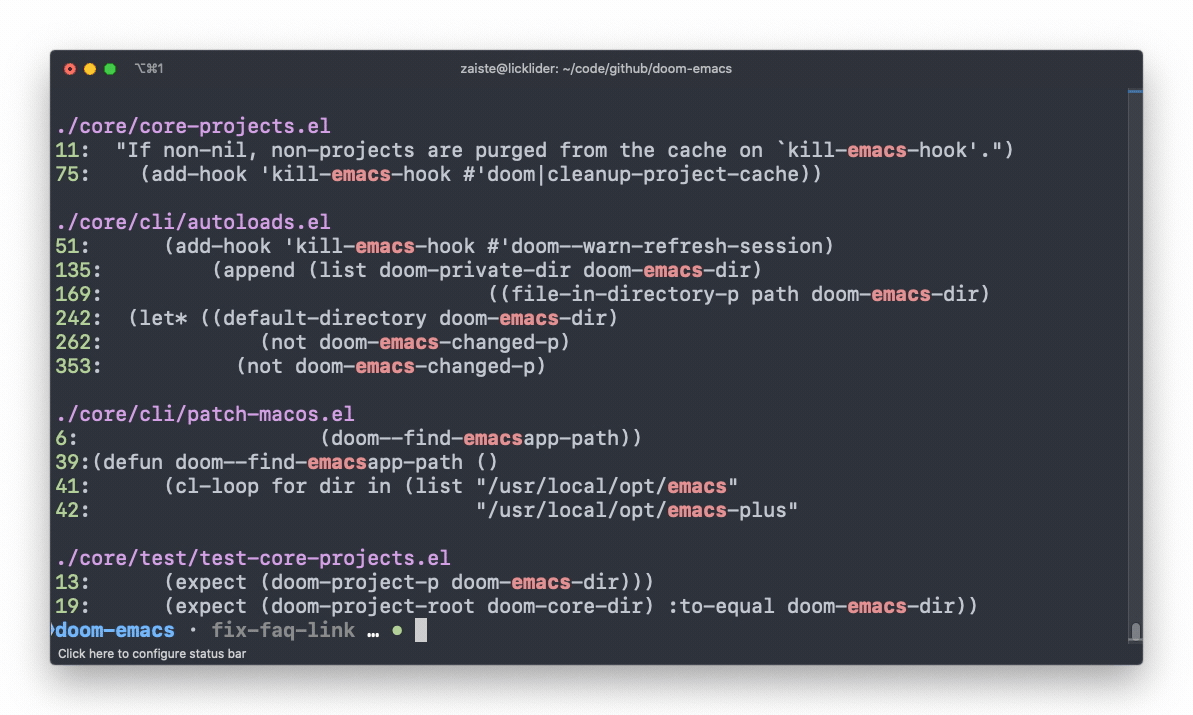
O ripgrep, que apesar do nome tem como binário apenas "rg", é um excelente substituto do grep pra procurar em arquivos de determinado diretório. Ou diretórios. E bem mais rápido.
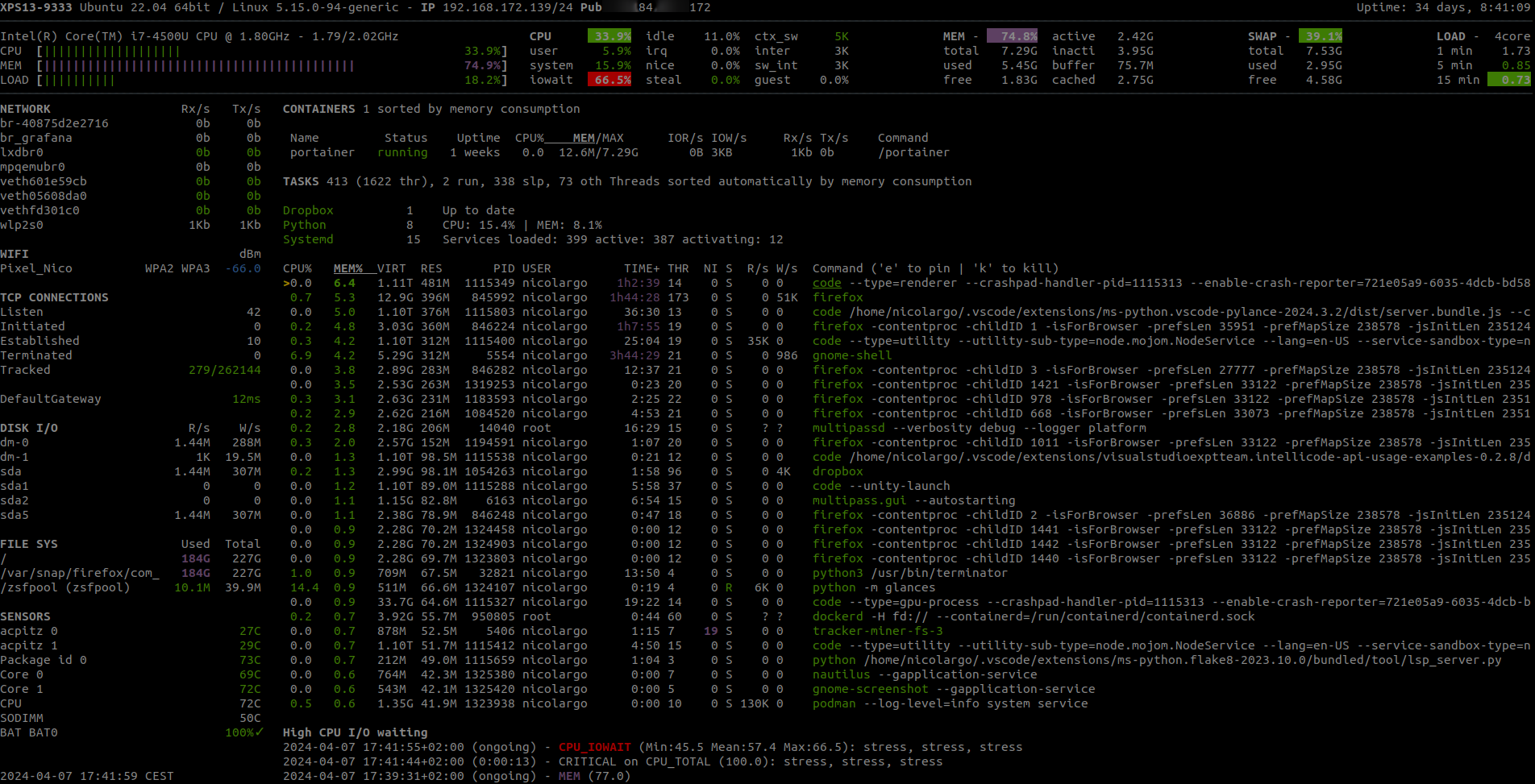
O glances é escrito em python. Legal, mas isso o torna lento pra iniciar. Mas depois que inicia, funciona bem. Ele é um melhoramento do "htop" com mais informação.
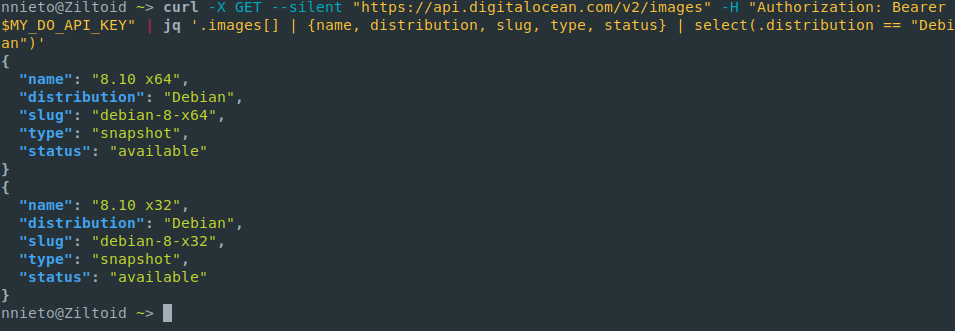
Se você mexe com kubernetes ou com arquivos json, jq é a ferramenta. Ajuda a filtrar e dá o resultado num formato colorido, o que ajuda a visualizar. E você pode construir filtros pros resultados. Existe uma outra ferramenta que é mais rápida, mas eu acabo usando o jq por causa da saída colorida (que ajuda demais).
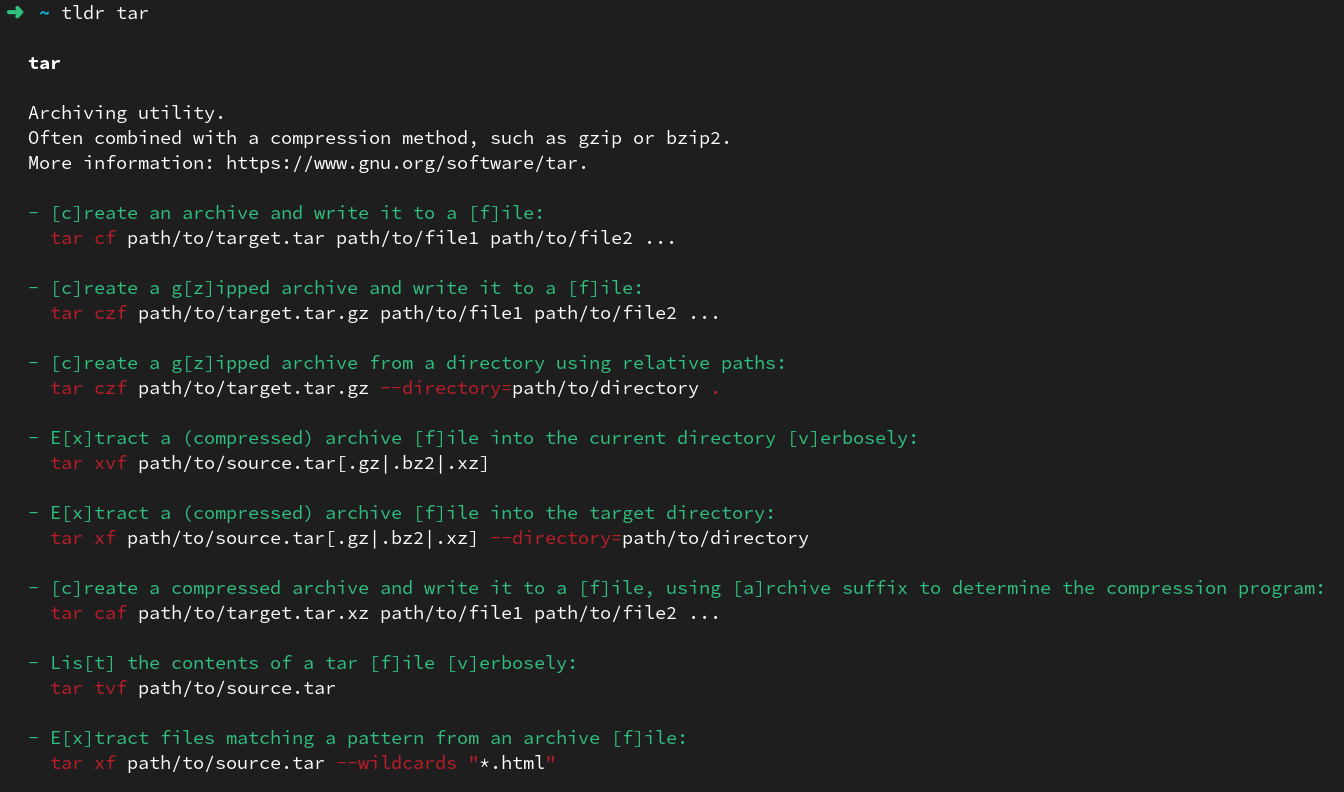
Sabe aquele problema de ler manpage e não ter exemplos? O tldr resolve essa parte. Baixa exemplos do comando que quiser usar.

No Ubuntu o pacote chama-se fd-find. E instala o binário como fdfind. Eu renomeio pra fd, tal qual é no archlinux e no macOS. É um melhoramento do find. Mais rápido e mais fácil de usar.
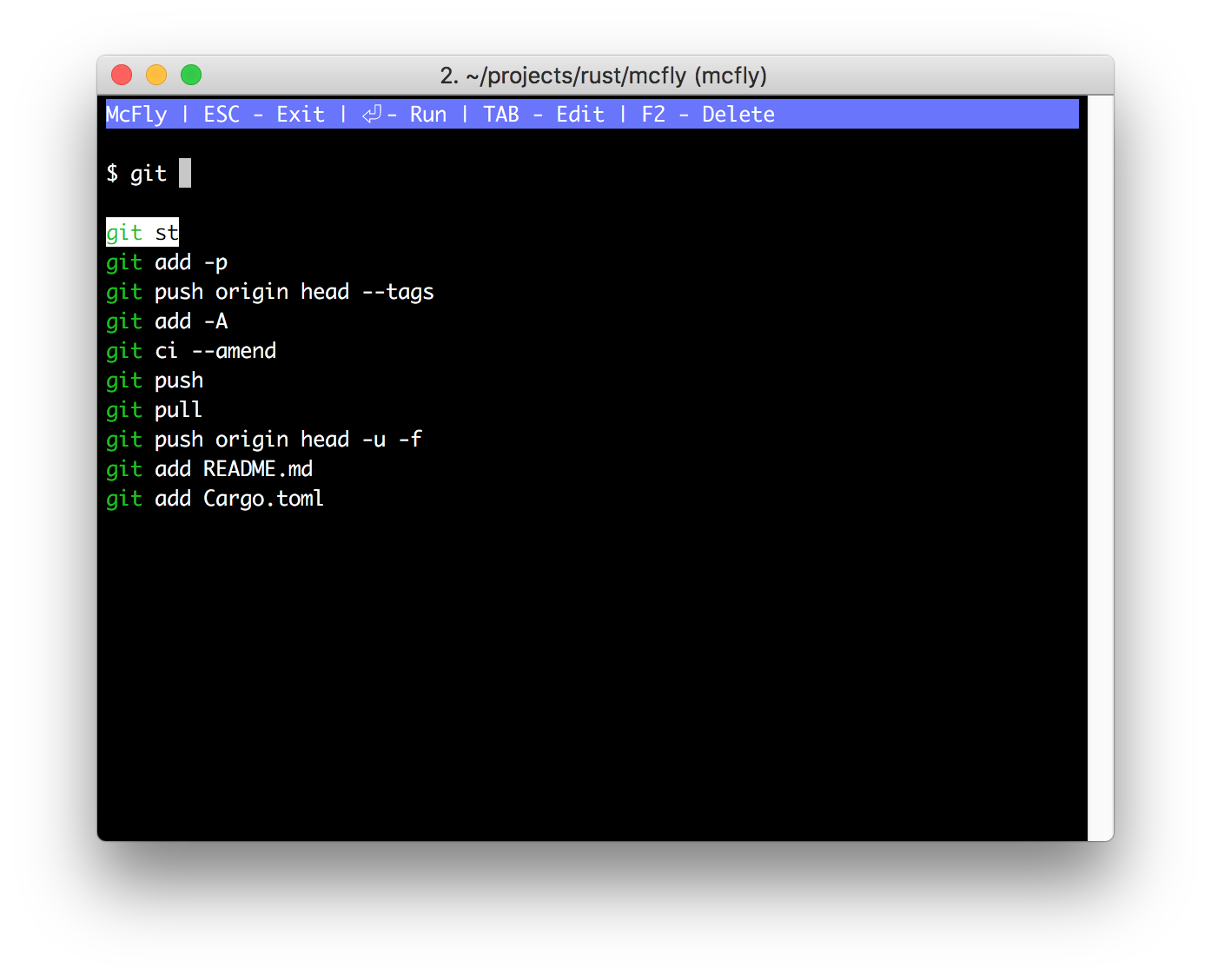
Esse entra aqui como uma menção quase que honrosa porque atualmente eu já não uso mais. Ele é prático se você usar outro shell que não seja o fish, como bash ou zsh. Ele faz a busca no histórico ser de uma forma bem mais simples. Tal como já é por padrão no fish.
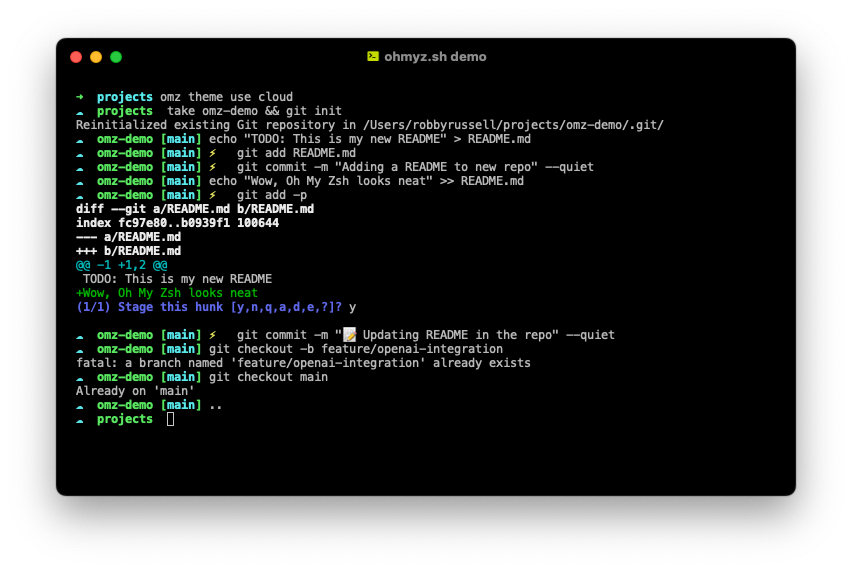
A imagem é do oh-my-zsh, que deixa o terminal mais bonitinho. O zsh mesmo não tem imagem na página do projeto. Se é que é um projeto.
O zsh é o padrão no macOS e eu resolvi experimentar por 6 meses na máquina que peguei no refresh da Ericsson. A vantagem do zsh é que é a mesma sintaxe do bash, então você reaproveita muita coisa. Agora sobre trocar zsh por bash... no final eu achei bem parecido. Existem algumas vantagens do zsh, mas no uso do dia à dia, pra mim pelo menos, não fez tanta diferença assim.
O Patola lembrou bem que existem comportamentos distintos entre bash e zsh.
Em bash:
patola@risadinha:/dados$ echo a | read b ; echo $b
patola@risadinha:/dados$
Em zsh:
[19:03] [9665] [patola@risadinha /dados]% echo a | read b ; echo $b
a
[19:03] [9666] [patola@risadinha /dados]%O resultado é diferente porque a sintaxe é diferente. O bash tem right-side fork, o zsh tem left-side fork. Isso não é controverso. É uma diferença de sintaxe conhecida, explicada e verificável.
-- Patola
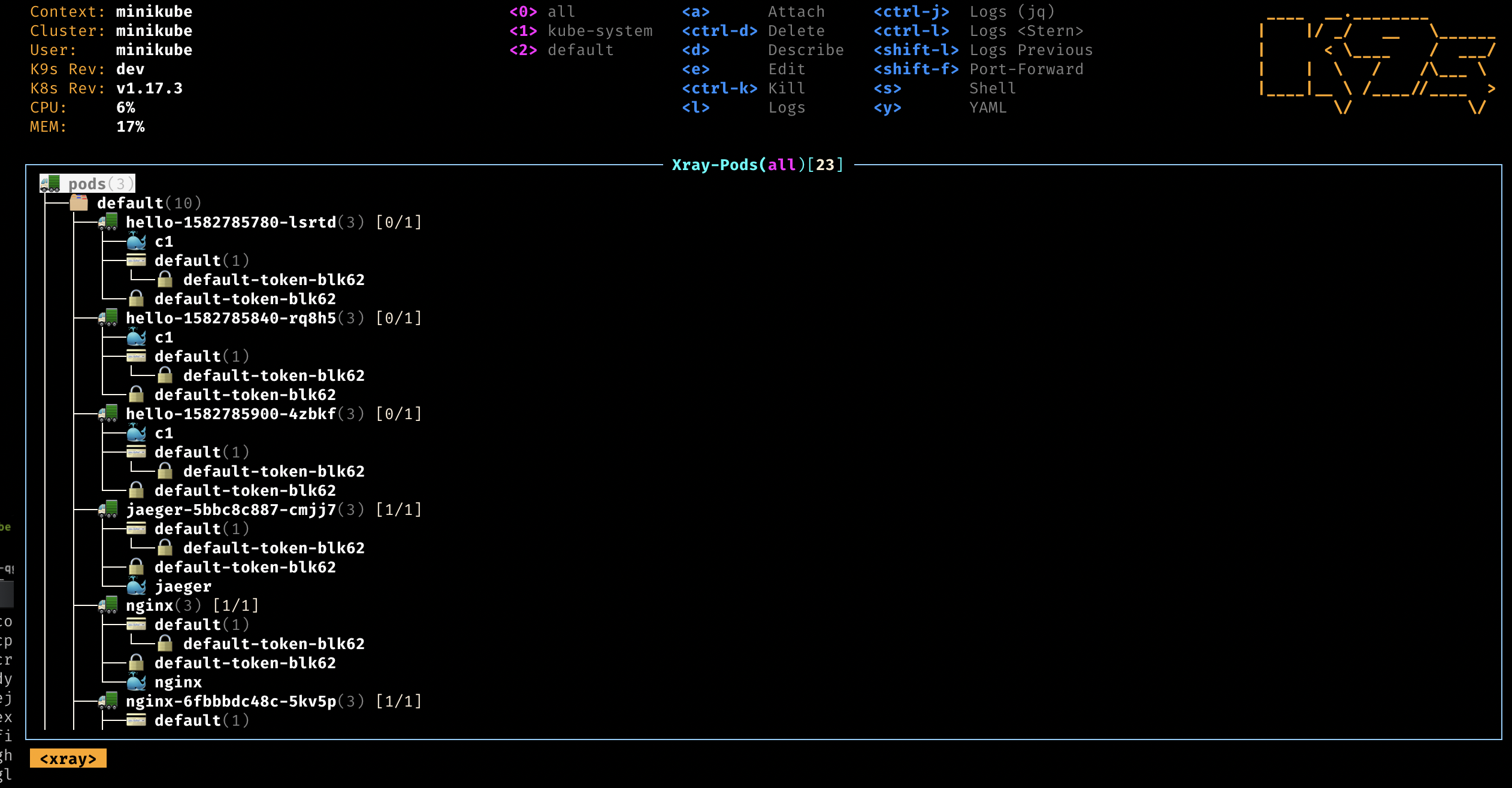
Essa não é bem uma dica pra quem mexe com kubernetes. Ao invés de ficar mandando "kubectl" pra tudo quanto é lado, o melhor é usar o k9s. Ele mostra de forma visual o seu cluster e namespace. E todos os atributos que consegue ver pelo "kubectl".
E assim terminamos o artigo. Se eu lembrar de mais alguma coisa que uso e esqueci, acrescento aqui.

Em minha empolgação com o brinquedo novo, o Lenovo Thinkpad T480, eu simplesmente não percebi que várias teclas são adesivos colados.
Fui mirim.
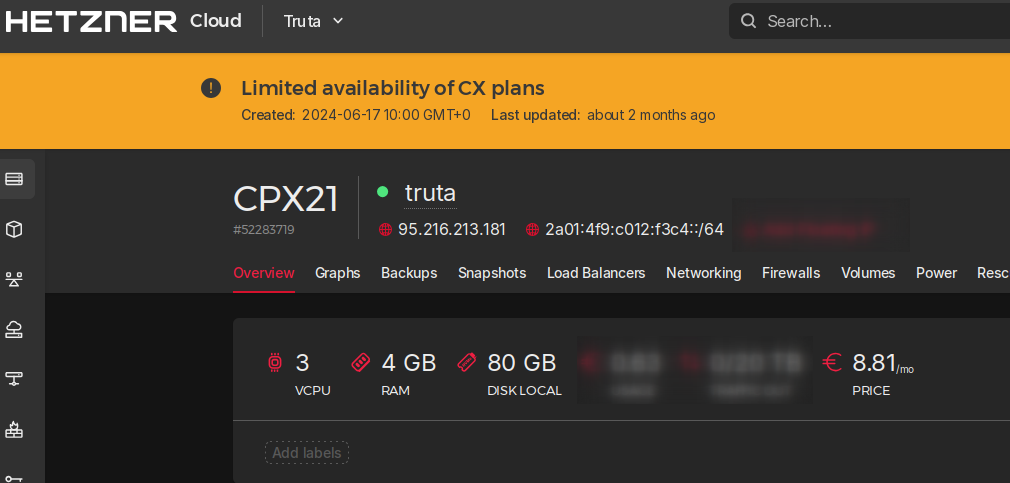
Pode não parecer, mas mudamos. Já estamos na VPS nova, que fica na Hetzner.
Está no datacenter que fica na Finlândia. Então é quase vizinho daqui.
Espero não levar nenhum susto no fim do mês ao pagar o uso. Por enquanto parece tudo ok.
Sem mais, seguimos em frente.

Estávamos discutindo sobre upgrade de firmware no grupo Linux Brasil eu resolvi dar uma revisitada no artigo que escrevi sobre vulnerabilidades de CPU: falhas de segurança em CPU nas distros com linux-libre.
Olhando aqui meu desktop, estou até que bem protegido.
root@goosfraba ~# for v in /sys/devices/system/cpu/vulnerabilities/*
echo -n "$v:"; cat $v
end
/sys/devices/system/cpu/vulnerabilities/gather_data_sampling:Not affected
/sys/devices/system/cpu/vulnerabilities/itlb_multihit:Not affected
/sys/devices/system/cpu/vulnerabilities/l1tf:Not affected
/sys/devices/system/cpu/vulnerabilities/mds:Not affected
/sys/devices/system/cpu/vulnerabilities/meltdown:Not affected
/sys/devices/system/cpu/vulnerabilities/mmio_stale_data:Not affected
/sys/devices/system/cpu/vulnerabilities/reg_file_data_sampling:Not affected
/sys/devices/system/cpu/vulnerabilities/retbleed:Mitigation: untrained return thunk; SMT disabled
/sys/devices/system/cpu/vulnerabilities/spec_rstack_overflow:Not affected
/sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Mitigation: Speculative Store Bypass disabled via prctl
/sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: usercopy/swapgs barriers and __user pointer sanitization
/sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Retpolines; STIBP: disabled; RSB filling; PBRSB-eIBRS: Not affected; BHI: Not affected
/sys/devices/system/cpu/vulnerabilities/srbds:Not affected
/sys/devices/system/cpu/vulnerabilities/tsx_async_abort:Not affected
Eu fiz recentemente um upgrade de firmware aqui usando o fwupgrmgr. Não salvei o resultando, mas salvei o que fiz no sh1bb0l33t.
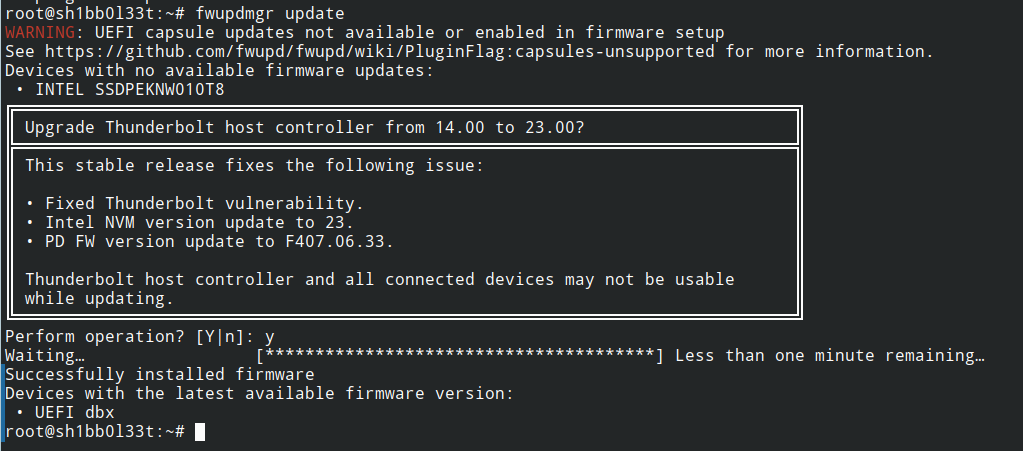
E falando sh1bb0l33t:
root@sh1bb0l33t ~# for v in /sys/devices/system/cpu/vulnerabilities/*
echo -n "$v:"; cat $v
end
/sys/devices/system/cpu/vulnerabilities/gather_data_sampling:Mitigation: Microcode
/sys/devices/system/cpu/vulnerabilities/itlb_multihit:KVM: Mitigation: VMX disabled
/sys/devices/system/cpu/vulnerabilities/l1tf:Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable
/sys/devices/system/cpu/vulnerabilities/mds:Mitigation: Clear CPU buffers; SMT vulnerable
/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI
/sys/devices/system/cpu/vulnerabilities/mmio_stale_data:Mitigation: Clear CPU buffers; SMT vulnerable
/sys/devices/system/cpu/vulnerabilities/reg_file_data_sampling:Not affected
/sys/devices/system/cpu/vulnerabilities/retbleed:Mitigation: IBRS
/sys/devices/system/cpu/vulnerabilities/spec_rstack_overflow:Not affected
/sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Mitigation: Speculative Store Bypass disabled via prctl
/sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: usercopy/swapgs barriers and __user pointer sanitization
/sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: IBRS; IBPB: conditional; STIBP: conditional; RSB filling; PBRSB-eIBRS: Not affected; BHI: Not affected
/sys/devices/system/cpu/vulnerabilities/srbds:Mitigation: Microcode
/sys/devices/system/cpu/vulnerabilities/tsx_async_abort:Mitigation: TSX disabled
Se estranharem a sintaxe do comando no shell, é porque estou usando fish pra shell interativo. Adotei e não largo mais.
Voltando ao assunto de updates de firmwares, fwupdmgr faz tudo pra você hoje em dia. Os tempos de ter um disco com Windows ou Dos ou FreeDOS pra atualizar são coisa do passado.
Existe a possibilidade de dar algo errado? Claro. Sempre. Estamos falando de firmware de placa-mãe e HDDs/SSDs. Se o processo parar no meio pode dar errado. E alguns updates acabam provocando efeitos indesejados como lentidão (exemplo de correções pra ataques de side channel de processador). Então algumas pessoas preferem escolher mais meticulosamente os updates antes de aplicar.
Mas se esse não é seu caso, eu fortemente recomendo usar o fwupdmgr e atualizar os firmwares de seu computador.
E deixo aqui a frase dita e escrita pelo grande Kevlin Henney durante uma palestra em Estocolmo na Ericsson, e registrada muito péssimamente pela minha câmera do celular (Kevlin, se estiver lendo isso aqui, eu peço desculpas pela fotografia tão borrada).

Eu resolvi melhorar a previsão e o modelo pra tal sobre o Linux no desktop, uma realidade inegável. Então escrevi algo em python pra fazer isso pra mim o trabalho e usar de algum modelo já pronto.
(venv) helio@goosfraba ~/D/linux-desktop-dominance-forecast (main)> ./forecasting.py
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2009-01-01 95.42 3.68 0.17 0.64 0.0 0.0 0.0
2009-02-01 95.39 3.76 0.14 0.62 0.0 0.0 0.0
2009-03-01 95.22 3.87 0.16 0.65 0.0 0.0 0.0
2009-04-01 95.13 3.92 0.17 0.66 0.0 0.0 0.0
2009-05-01 95.25 3.75 0.24 0.65 0.0 0.0 0.0
Playstation Other
Date
2009-01-01 0.08 0.02
2009-02-01 0.07 0.02
2009-03-01 0.08 0.02
2009-04-01 0.10 0.02
2009-05-01 0.09 0.02
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2024-01-01 73.00 16.11 5.33 3.77 1.78 0.0 0.0
2024-02-01 72.17 15.42 6.10 4.03 2.27 0.0 0.0
2024-03-01 72.47 14.68 6.52 4.05 2.27 0.0 0.0
2024-04-01 73.50 14.70 5.34 3.88 2.56 0.0 0.0
2024-05-01 73.91 14.90 4.87 3.77 2.54 0.0 0.0
2024-06-01 72.81 14.97 6.23 4.05 1.93 0.0 0.0
2024-07-01 72.10 14.92 7.13 4.44 1.41 0.0 0.0
Playstation Other
Date
2024-01-01 0.0 0.01
2024-02-01 0.0 0.01
2024-03-01 0.0 0.01
2024-04-01 0.0 0.01
2024-05-01 0.0 0.01
2024-06-01 0.0 0.01
2024-07-01 0.0 0.01
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/statespace/sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 11 M = 10
This problem is unconstrained.
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.00575D-01 |proj g|= 1.24633D+00
At iterate 5 f= -1.49635D-01 |proj g|= 1.77236D-01
At iterate 10 f= -3.64537D-01 |proj g|= 1.24837D-01
At iterate 15 f= -3.84843D-01 |proj g|= 1.22570D-01
At iterate 20 f= -4.20877D-01 |proj g|= 9.71167D-02
At iterate 25 f= -4.29351D-01 |proj g|= 1.13565D-01
At iterate 30 f= -4.33425D-01 |proj g|= 9.06436D-02
At iterate 35 f= -4.34142D-01 |proj g|= 3.98871D-02
At iterate 40 f= -4.36192D-01 |proj g|= 4.26757D-01
At iterate 45 f= -4.37801D-01 |proj g|= 6.82859D-02
At iterate 50 f= -4.37938D-01 |proj g|= 1.67285D-02
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
11 50 55 1 0 0 1.673D-02 -4.379D-01
F = -0.43793754789434586
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/base/model.py:607:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
The year of Linux on the Desktop: 2036-11-30 00:00:00
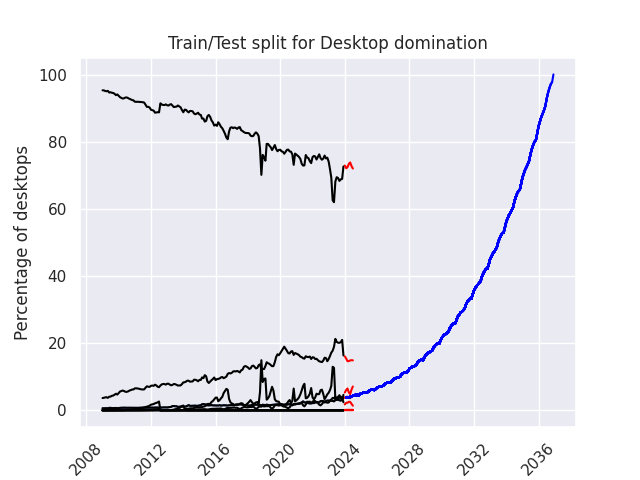
Se ignorarmos os pequenos erros e avisos que aparecem, coisa pouca e irrelevante como valor divergir demais, podemos ver claramente quando o ano do Linux no desktop acontece: 2036-11-30
Então a previsão revisada é que logo estaremos em todos os lugares. Aguardem-nos!
E claro que publiquei isso tudo no GitHub:
E usei o seguinte artigo como referência (e código, diga-se de passagem):
Bom ano do Linux no desktop pra todos vocês.
Parece que finalmente acordaram pra aquilo que era óbvio: Linux chegou pra dominar também o desktop!
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed molestie scelerisque ultrices. Nullam venenatis, felis ut accumsan vestibulum, diam leo congue nisl, eget luctus sapien libero eget urna. Duis ac pellentesque nisi.
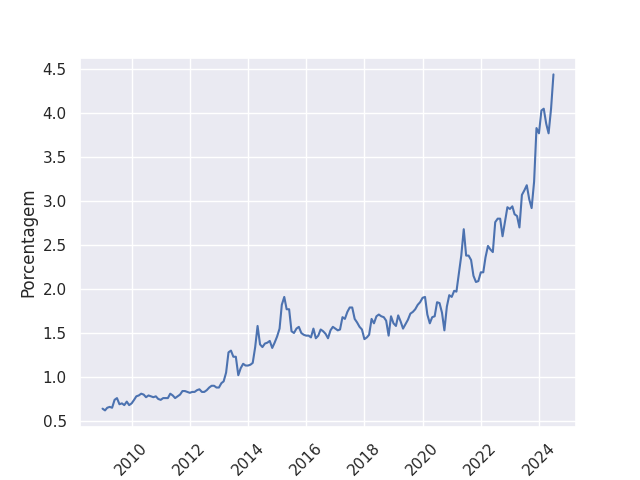
Foram meros 4%, mas a tendência é de crescimento e não tem volta. Até mesmo peguei os dados diretamente do site statcounter.
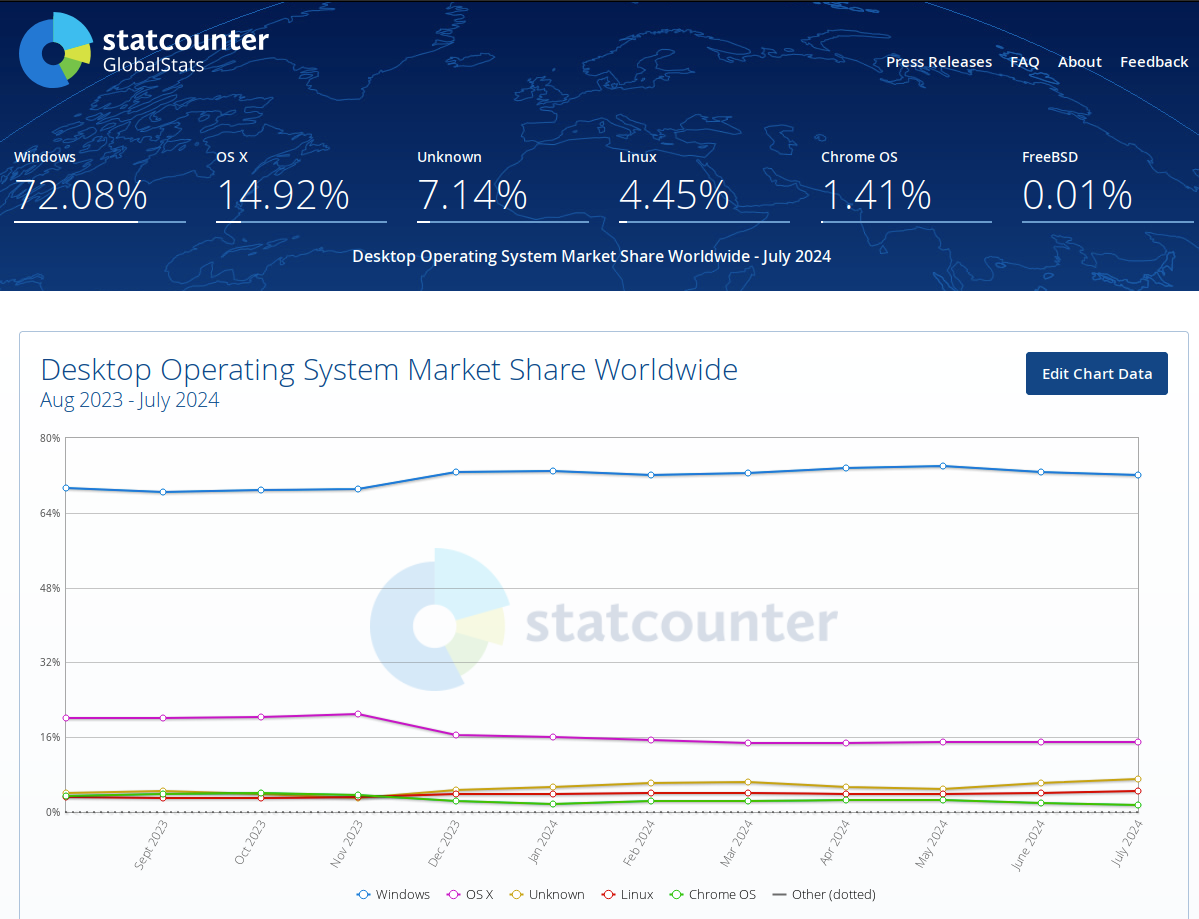
Claramente Linux está em plena ascensão. Seja porque razão for, o importante é estar lá. E vai chegar ao 100% com certeza. Eu até fiz uma checagem usando uma função forecast do libreoffice pra ver quantos anos serão necessários.
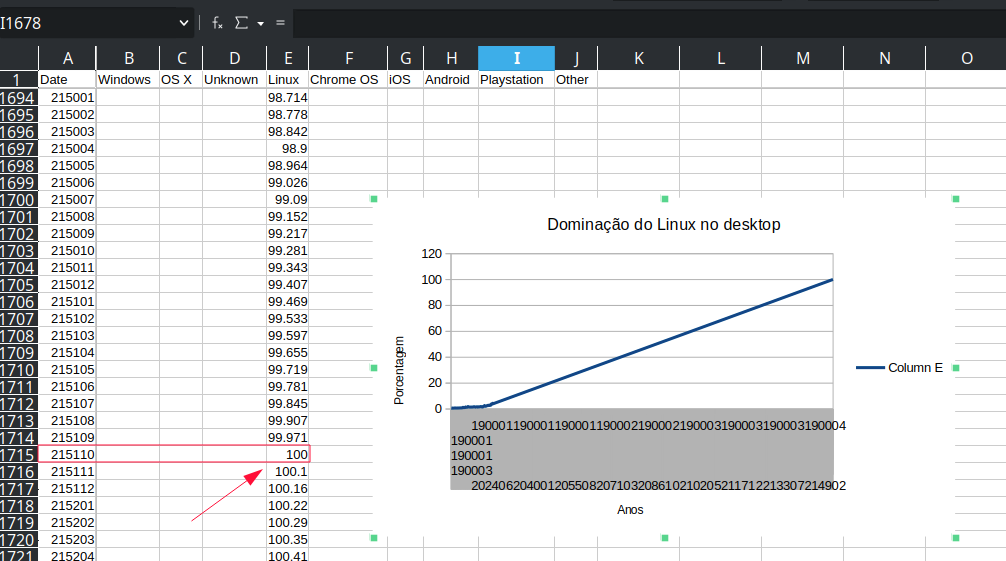
Ou seja, Linux dominará completamente o desktop em outubro de 2151. Marquem em suas agendas pois será uma data inesquecível. E não temos meta, mas quando chegarmos na meta nós dobraremos a meta. Aguardem-nos!

Antes que perguntem, não, não vou mudar da Suécia. Nem dentro da Suécia. Ao menos por enquanto.
O que aconteceu foi que essa VPS que atualmente tem esse site e o https://linux-br.org está no limite de uso. Ela tem requisitos modestos que nos atenderam bem por muito tempo. Mas agora muita coisa está caindo por OOM (Out Of Memory) e não tem muito o que fazer.
Entrei em contato com a VPS pra ver se era possível um upgrade sem grandes custos, mas eles não foram tão receptivos ao meu pedido quanto eu imaginava.Enquanto isso encontrei uma solução mais viável na Ionos. Por um preço bastante acessível (9 bidens) é possível ter uma VPS bem melhor e na região da união européia.
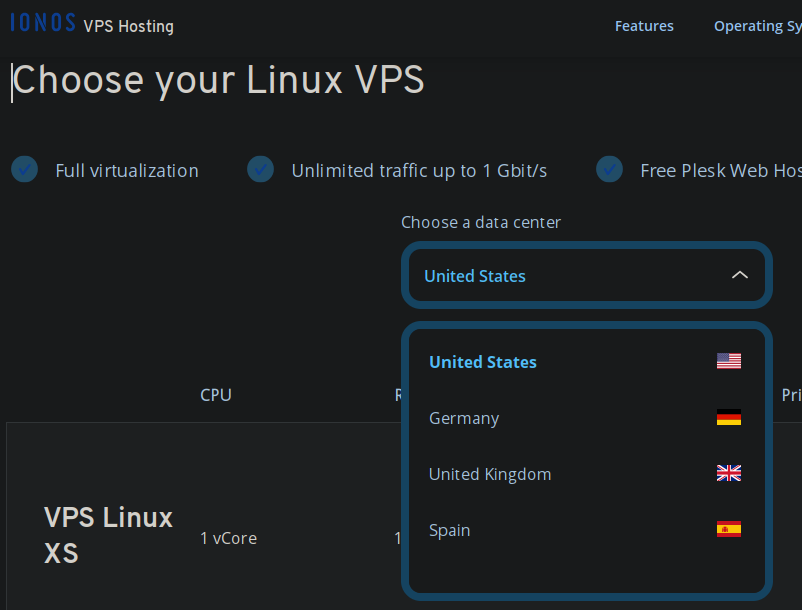
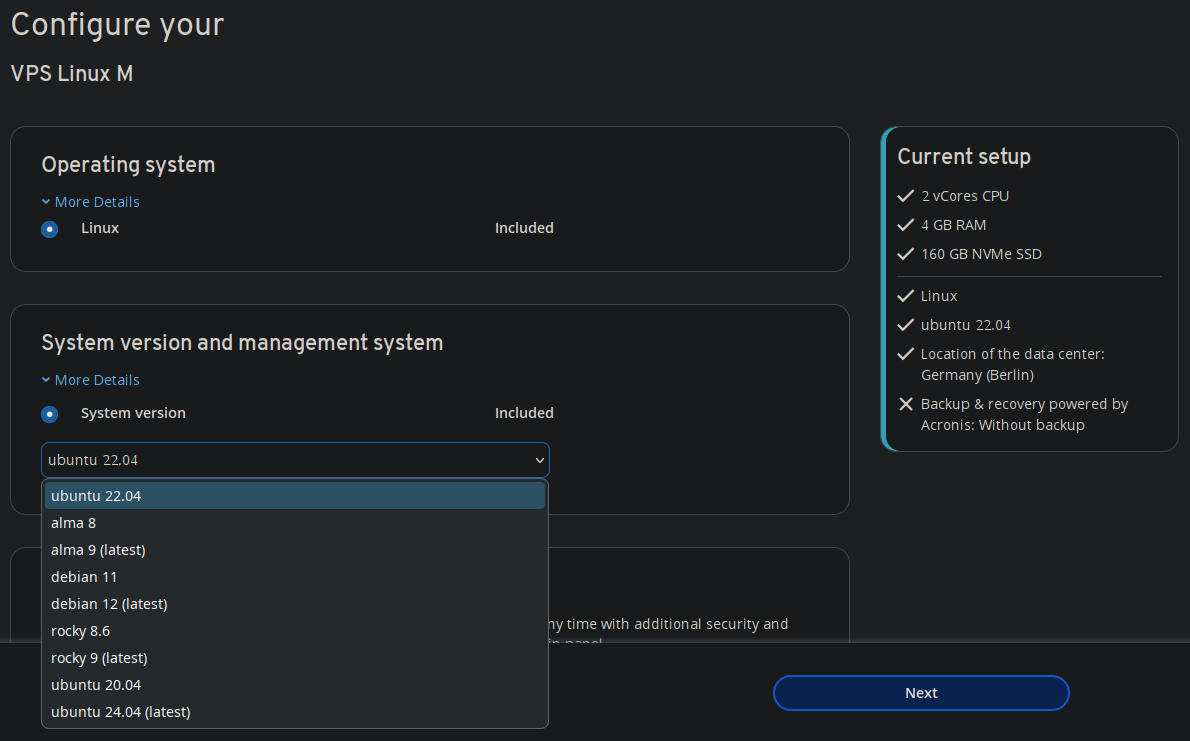
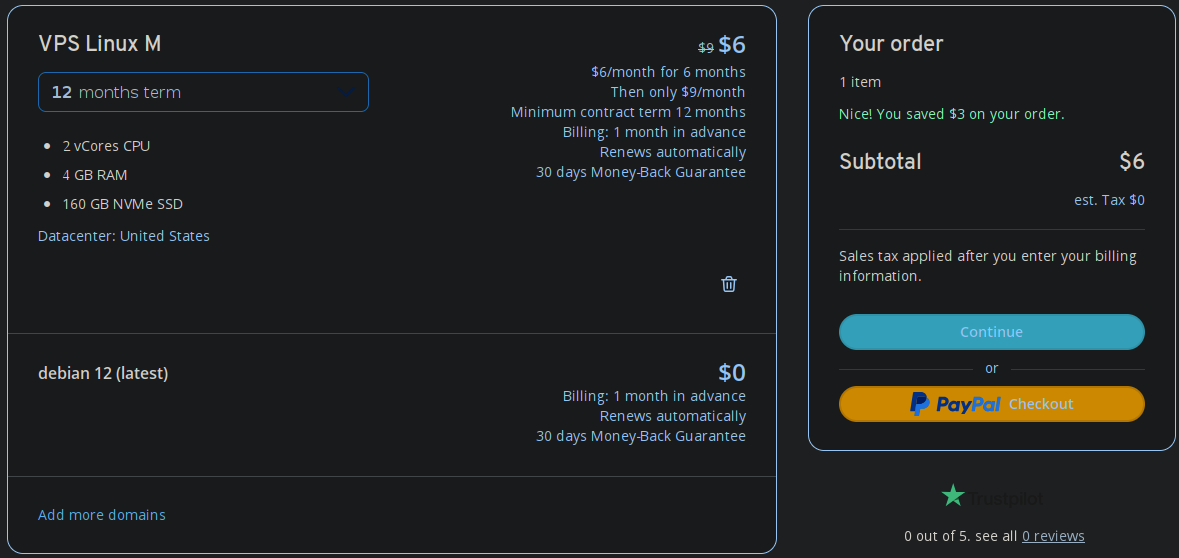
Posso ainda selecionar a região, que provavelmente será Alemanha, escolher o sistema operacional, que será o mesmo o atual, Debian, e finalmente vem o preço. 4vCPUs, 4 GB de RAM e 160 GB de disco por 9 bidens mensais. É praticamente tudo o dobro que a atual VPS com exceção do disco. O atual são somente 30 GB. Então será mais que o dobro.
A migração será agora no fim do mês. Então pode ser que o site em outros serviços fiquem fora do ar por algum tempo. Mas voltará. E melhor. Espero. Se não ficar melhor, mudamos novamente. Capitalismo 101.
A Amazon me surpreendeu e entregou mais rápido do que imaginei 16 GB de RAM da Crucial e um nvme da Intel de 1TB. Achei que fossem demorar mais de uma semana pra entregar, mas pelo visto estão com saudades de mim como cliente.
Assisti tudo quanto foi vídeo de upgrade no YouTube e parti pra parte prática.

Foi bem tranquilo de abrir e inserir as peças. Eu já tinha visto o tipo de memória e frequência pelo dmidecode. Também tinha visto que tinha somente um pente instalado, o que permitia comprar o segundo. E que o disco não era SDD mas um nvme, que é até mais rápido. Como não tinha muita coisa, não fiz backup and reinstalei o Ubuntu. E novamente com ZFS com criptografia.

E agora o bixo está um foguete.
helio@sh1bb0l33t ~> free
total used free shared buff/cache available
Mem: 24485224 4378656 19393324 703632 1768492 20106568
Swap: 8388604 0 8388604
helio@sh1bb0l33t ~> duf
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ 20 local devices │
├────────────────────────────────────────┬────────┬────────┬────────┬───────────────────────────────┬──────┬───────────────────────────────────────────────┤
│ MOUNTED ON │ SIZE │ USED │ AVAIL │ USE% │ TYPE │ FILESYSTEM │
├────────────────────────────────────────┼────────┼────────┼────────┼───────────────────────────────┼──────┼───────────────────────────────────────────────┤
│ / │ 890.5G │ 4.6G │ 885.9G │ [....................] 0.5% │ zfs │ rpool/ROOT/ubuntu_ni6nkv │
│ /boot │ 1.7G │ 96.9M │ 1.7G │ [#...................] 5.4% │ zfs │ bpool/BOOT/ubuntu_ni6nkv │
│ /boot/efi │ 1.0G │ 6.1M │ 1.0G │ [....................] 0.6% │ vfat │ /dev/nvme0n1p1 │
│ /home │ 891.7G │ 5.8G │ 885.9G │ [....................] 0.6% │ zfs │ rpool/USERDATA/home_39e1h7 │
│ /root │ 885.9G │ 2.2M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/USERDATA/root_39e1h7 │
│ /run/keystore/rpool │ 3.7M │ 28.0K │ 3.4M │ [....................] 0.7% │ ext4 │ /dev/keystore/rpool │
│ /srv │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/srv │
│ /usr/local │ 885.9G │ 6.1M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/usr/local │
│ /var/games │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/games │
│ /var/lib │ 896.3G │ 10.4G │ 885.9G │ [....................] 1.2% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib │
│ /var/lib/AccountsService │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/AccountsServ │
│ │ │ │ │ │ │ ice │
│ /var/lib/NetworkManager │ 885.9G │ 384.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/NetworkManag │
│ │ │ │ │ │ │ er │
│ /var/lib/apt │ 886.0G │ 106.6M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/apt │
│ /var/lib/dpkg │ 886.0G │ 79.6M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/lib/dpkg │
│ /var/log │ 885.9G │ 5.2M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/log │
│ /var/mail │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/mail │
│ /var/snap │ 885.9G │ 11.0M │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/snap │
│ /var/snap/firefox/common/host-hunspell │ 890.5G │ 4.6G │ 885.9G │ [....................] 0.5% │ zfs │ rpool/ROOT/ubuntu_ni6nkv │
│ /var/spool │ 885.9G │ 384.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/spool │
│ /var/www │ 885.9G │ 256.0K │ 885.9G │ [....................] 0.0% │ zfs │ rpool/ROOT/ubuntu_ni6nkv/var/www │
╰────────────────────────────────────────┴────────┴────────┴────────┴───────────────────────────────┴──────┴───────────────────────────────────────────────╯
E claro que escolhi um nome bacana pra batizar o brinquedo novo: sh1bb0l33t. Pra lembrar do bom e velho shibboleet que instalei aqui: Shibboleet.
Agora consigo jogar Doom sem engasgos. E enquanto estou no banheiro!

Um dia desses eu li um artigo de um fotógrafo sobre lixo computacional e como ele gastou muito menos comprando um laptop usado e remanufaturado e botou Linux. Eu fiquei pensando em como eu poderia realmente fazer o mesmo, que aliás deveria fazer isso por ser alguém que promove o uso de Linux. Antes que perguntem, eu infelizmente não encontrei o artigo. Como li no telefone enquanto estava indo dormir, foi algo que perdi. Mas a mensagem ficou na mente.
Como no momento não estou mais empregado (algo que um dia descrevo mais) e algumas empresas querem que eu vá até onde ficam pra fazer testes práticos, achei que era o momento propício pra entrar na moda do refurbished. Olhei um modelo em conta, um Lenovo Thinkpad T480, e comprei através do site https://www.refurbed.se que apesar do "se" no sufixo fica na Alemanha.
A máquina chegou e está 95% em ótimo estado. Sá uma parte da tampa está comida, mas nada que atrapalhe o funcionamento. É mais estético.

O restante está bem usável.

Claro que posso estar sendo otimista já que comecei a mexer na máquina agora. Mas o mais estranho mesmo foram as teclas desse layout que deveria ser US mas é um misto de US e alemão. E logo que chegou, não perdi tempo e instalei Ubuntu.
Não é uma máquina que pretendo ficar usando o tempo todo já que tenho o desktop, de onde digito agora, e que roda Archlinux. Como é uma máquina pra usar em eventos e enquanto estou fora de minha mesa, Ubuntu basta e sobra. Mas me dei ao luxo de instalar com ZFS pra experimentar.
E, claro, não perdi a oportunidade de gravar um unboxing.
E tudo isso não poder ter sido feito sem o apoio incondicional das gatas daqui de casa.

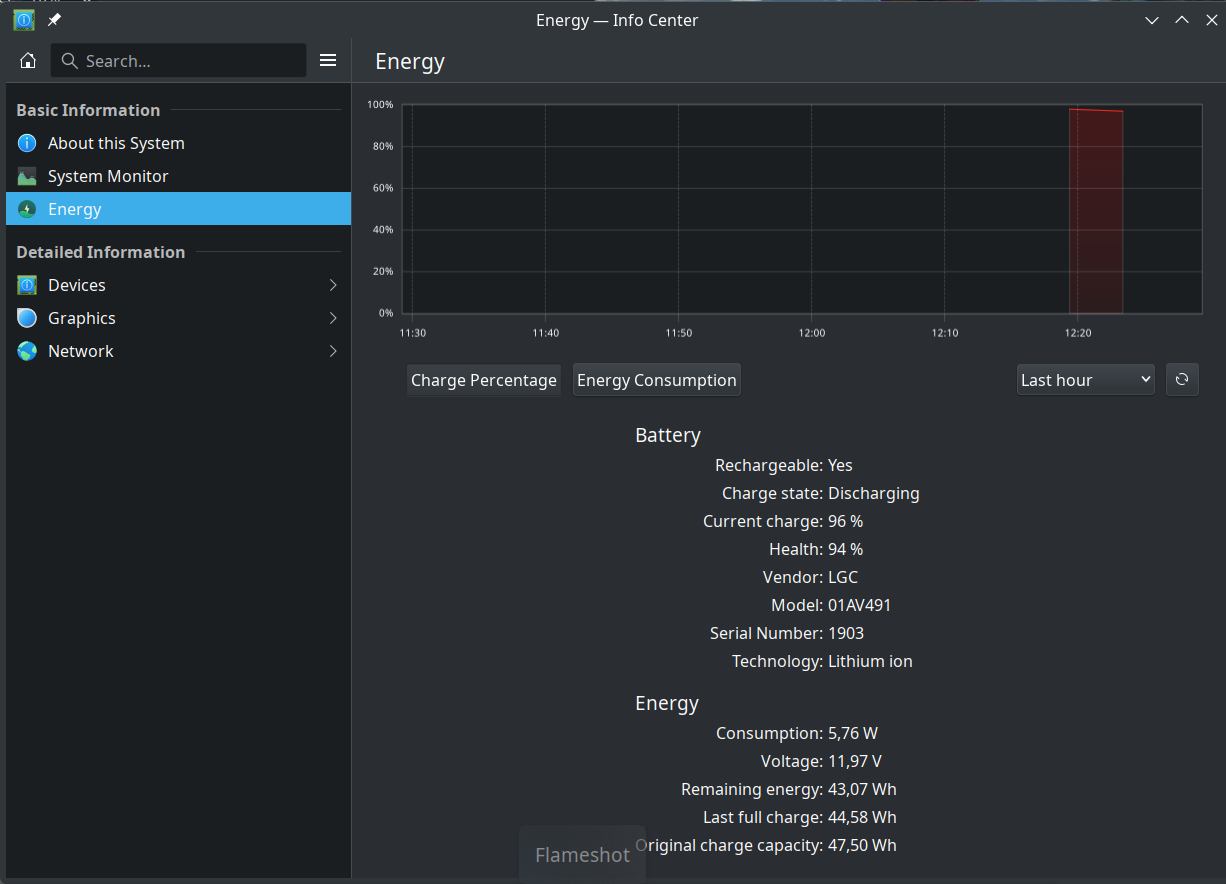
Update: eu descrevi de forma genérica e esqueci de botar as especificações do laptop. É um Intel Core i5 alguma coisa (o da foto no início foi só exemplo), 8GB de RAM (já comprei 16 GB extras) e com nvme de 256 GB (que devo trocar pra 1 TB que tenho aqui quando for adicionar a RAM). Paguei em torno de 300 euros. A bateria diz durar mais de 3 horas. Não testei ainda.
Update: 31/12/2024
Por um acaso muito grande, hoje apareceu no fediverso um texto traduzido do artigo que mencionei no início do texto e que não consegui achar o link. Eu li a versão em inglês, então deixo abaixo o link pra ambos.

Eu segui uma dica do @
Eu dei uma olhada nos de força bruta e aqui estão os logins mais usados:
MariaDB [(none)]> select username, fail, inet6_ntoa(ip), UA from wp_wflogins into outfile 'ataques.csv';
> awk '{print $1}' ataques.csv | sort -n | uniq -c | sort -n
1 -
1 123123
1 1234
1 123456
1 123456789
1 443/wp-login.php
1 aaa
1 abcd1234
1 admaster
1 admin.
1 AdMiN
1 admin123
1 admina
1 admini
1 administrators
1 adminPeach
1 adminwp
1 admon
1 Adsystem
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 ahmed
1 alfons
1 alireza
1 anna
1 arrow
1 artsadd
1 ask6776
1 atarihost
1 autonewsbot
1 awen
1 azaret
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 Beast3x
1 beescleaning
1 carpetsdubai
1 Casper_Security
1 catmeow
1 chris
1 christiane
1 Christophe
1 control
1 cpolo
1 dagon
1 darcy56
1 Darcy56
1 dedi
1 demilation
1 DemoDemo
1 demo_w1p
1 devadmin
1 dexter
1 digilabs
1 donaljkt9
1 dummy_store_5
1 editor
1 ednabanaag
1 eliasaf
1 enamad
1 eosuperadmin
1 Fabien
1 Farribeiro
1 gestinet
1 globalint
1 goog
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 GP_Admin
1 grupovhn
1 gtfobiash
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 hopefox34
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 info
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 Ivan
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 jbalazs8178
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 john
1 justin
1 kinga
1 kobieta
1 kulturecom
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 lluis
1 loafa
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 mainstream
1 marina
1 martinharvey
1 Megusta
1 microadmin
1 miruku
1 mohit
1 monica
1 mungmee
1 MUWY
1 ndvtzaifnz
1 Nwildner
1 oktay-dogangun
1 options
1 ovauser-admin
1 PiSh3r
1 protan
1 qiang521
1 quantri
1 raeesa
1 Rahul
1 redtor
1 richard
1 Richard
1 ridiz
1 rikimoh39
1 root
1 rootadmin
1 roottn
1 rzu4bd
1 sadminusez
1 santi2
1 senterprisys_admin
1 SEOExpert
1 seojiwo
1 seomaster009
1 shelby96
1 Sion
1 siteadmin
1 smngrs952
1 Support
1 temp3
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 test3
1 tester
1 testionos
1 tuanduongthe
1 tuanpham
1 upastra007
1 Username
1 Vikash
1 voquanghuy
1 wadmiine
1 wdmgpvt
1 webstone24
1 webuser
1 wpadmin
1 WPADMIN
1 w-padmine
1 wp-admine
1 wp-blog
1 wp_developer
1 wpengine
1 wp_rest_api
1 wpsystem
1 wpupdate
1 wuser
1 wwwadm
1 xcom
1 xtw183870bbe
1 xtw18387106f
1 xtw1838711ab
1 xtw183871206
1 xtw183871550
1 xtw183872fc0
1 xtw18387331a
1 xtw1838738ca
1 xtw183873c09
1 xtw183874283
1 xtw183875328
1 xtw1838754ba
1 xtw18387596a
1 xtw183875977
1 xtw1838761a5
1 xtw183876e88
1 xtw18387757d
1 xtw183877c79
1 xtw183878b0d
1 xtw18387958b
1 xtw183879670
1 This email address is being protected from spambots. You need JavaScript enabled to view it.
1 xtw18387a0c5
1 xtw18387a9de
1 xtw18387aa3b
1 xtw18387adf8
1 xtw18387c077
1 xtw18387c339
1 xtw18387d0aa
1 xtw18387daad
1 xtw18387e84d
1 xtw18387e943
1 xtw18387f29e
1 xuanphong
1 yanz
1 zestful
1 Zestful
1 zokaroll
2 12345678
2 ac
2 adminlin
2 adminsup
2 adminusez
2 Auto
2 bapaksaya
2 burnolurko
2 Clare
2 francisunderwood
2 greeceman
2 happy
2 hex
2 hxq1879
2 ismm
2 jacquespermisdeconduire
2 jatin
2 jisuo
2 lashkari
2 maximixer789
2 Nacht
2 pajero_sports
2 smngrs953
2 smngrs955
2 susan
2 swilliams
2 testuser
2 thuylt
2 wadmines
2 This email address is being protected from spambots. You need JavaScript enabled to view it.
2 wiktorB
2 woopayplug
2 wordpress_admin_bak
2 wordpress_administratora
2 wordpressauto
2 wp
2 wpenginesupport
2 wpmanager
2 wp_postadmin
2 wpuser
2 x
2 xrumertest
2 xtw1838729c0
2 xtw18387754d
2 yanz@123457
2 yeuthuongmongmanh
2 zadminz
2 zutodoko
2 This email address is being protected from spambots. You need JavaScript enabled to view it.
3 admim
3 admin1
3 admin6
3 admingusar
3 bimak73555
3 Chris
3 demo
3 This email address is being protected from spambots. You need JavaScript enabled to view it.
3 mevivu
3 qwee123123
3 Reseller-webmaster
3 talhas
3 test1
3 wadmine
4 1001010
4 andremachado
4 crander
4 hostingadmin
4 matakucing3
4 patola
4 server
4 stender
4 username
4 wordcamp
4 wordpress_administrator
5 administratoir
5 administrator
5 This email address is being protected from spambots. You need JavaScript enabled to view it.
5 excontrol
5 itsme
5 support
5 user
5 wpadmins
5 wpcore
6 smngrs951
7 nwildner
7 paulomartins
11 test
12 farribeiro
18 Admin
19 wadminw
28 wwwadmin
54 linux-br
151 df7c8c98dfd88d9dfad
1270 admin
Realmente alguns logins existem e devem estar assinados nas páginas. Mas o restante é estilo Forrest Gump correndo de um lado pro outro atravessando os Estados Unidos sem saber o porquê.
De uma foto minha sem camisa. Então é um bônus estar em formato ASCII.
Estou usando em lugares como Facebook, onde eu realmente não tenho interesse que vejam fotos minhas.
Page 5 of 37
