
Eu ainda preciso dar uma editada no conteúdo, mas esse ano foi muito bom no Sweden Rock. Choveu bagarai, mas eu e o Caio bebemos tudo o que podíamos e um pouco mais. Ao som do bom e velho rock n' roll.
Mas agora estou com bastante tempo pra editar tudo que gravei por lá.

Sim, eu comi. E foi maravilhoso.
Já faz um tempo que eu venho querendo apagar tudo o que postei no Twitter, ou X, Xwitter. Não só pelo fato da empresa ter entrado com tudo na era da merdificação, mas porque gosto de pensar que ajudei alguém a virar um milionário. Ainda mais se esse alguém era antes um bilionário.
Buscando no GitHub, encontrei algumas soluções. Uma que pareceu dar mais certa foi a tweetXer, que você abre o console no Twitter e cola código pra fazer a coisa acontecer. O risco é ser banido pelo Twitter, mas acho que nesse ponto é até lucro.
Antes de começar é preciso solicitar a criação de um backup de sua conta. Um dos arquivos js que virão é o que alimentará o script pra ir apagando. Depois é sentar e esperar.
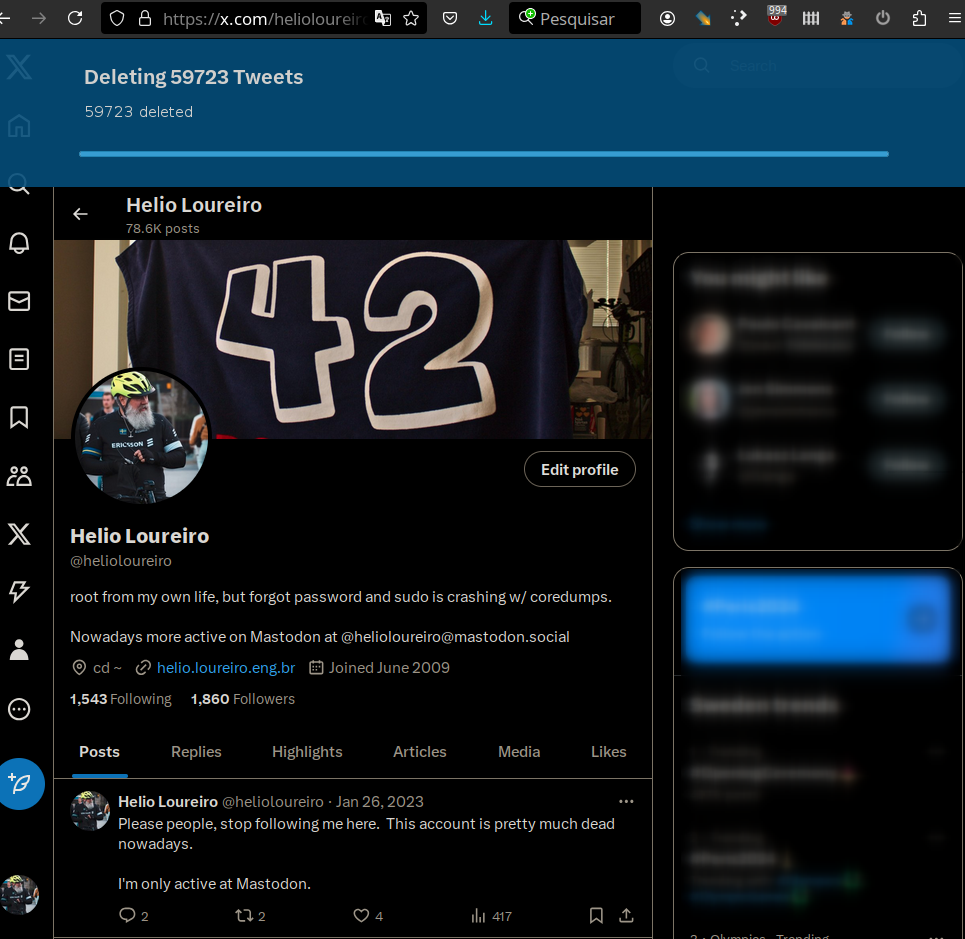
Como é possível ver na imagem acima, o treco mandou bala em 59.723 tweets meus. Haja tweets!
O resultado final foi esse aqui:
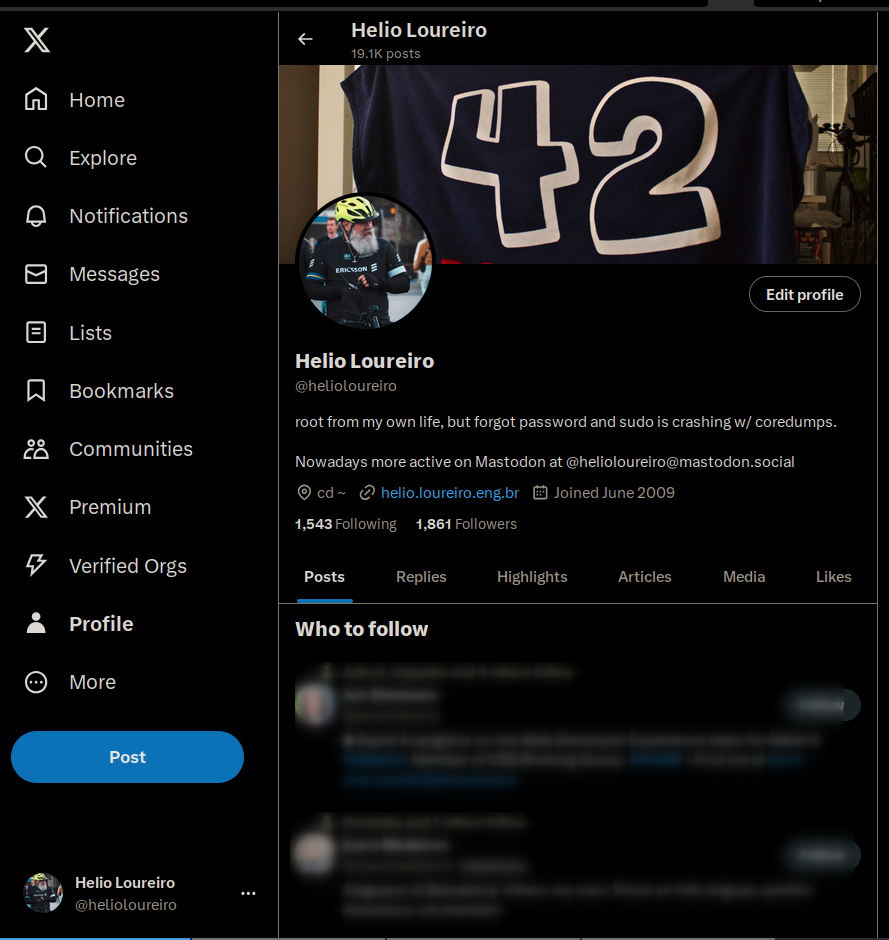
Tive de fazer o scroll em duas página pra mostrar que não sobrou nada. Nada. Foi bem eficiente. Mas...
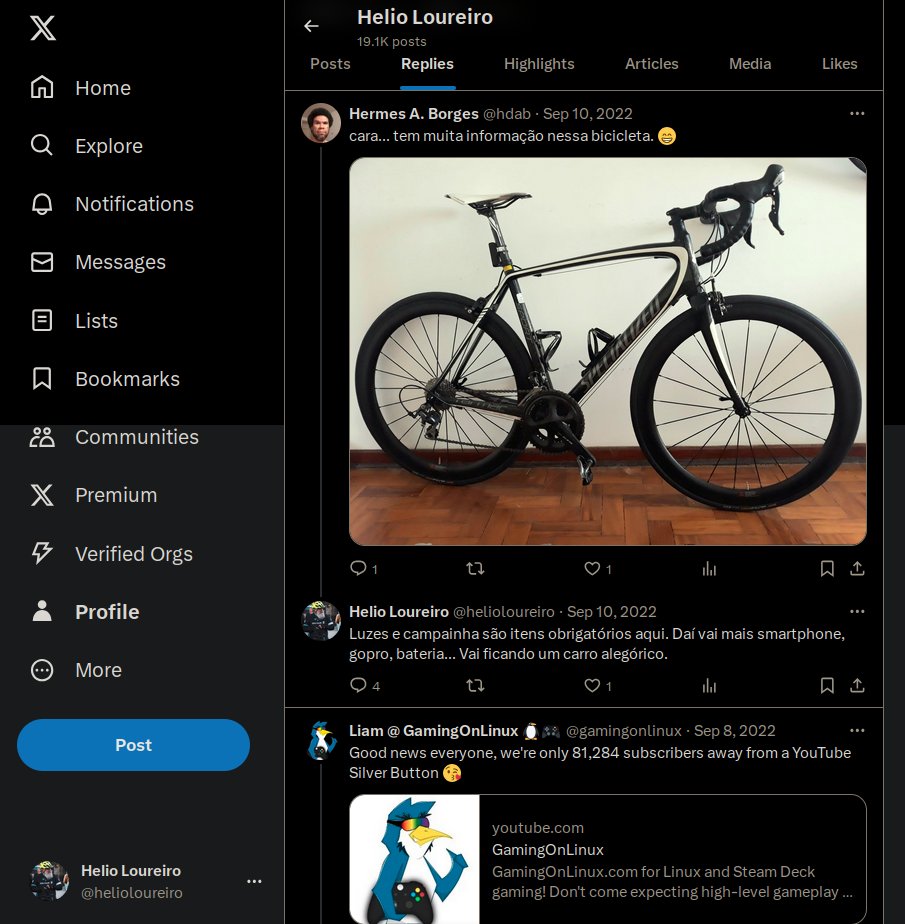
como pode ser visto aqui, meus replies ficaram pra trás.
Mesmo assim é uma ótima ferramenta pra quem quer apagar o que postou ao longo do tempo no Twitter e migrar pro Mastodon.
https://github.com/lucahammer/tweetXer
Eu entrei numa thread com a pergunta sobre o que fazer pra apagar tudo que sobrou. Até o momento segue sem reposta.
Pra quem me segue no Mastodon, sabe que (ou pelo menos vê) que envio um #TootThursday toda quinta-feira. Primeiro o que é isso? Nos tempos de Twitter surgiu o #FollowingFriday, ou #FF pros mais íntimos, que servia pra você indicar perfis interessantes pros outros seguirem. Nessa mesma época eu implementei um script pra fazer isso por mim já que todos que sigo eu considero interessantes.
Pra manter o mesmo espírito no Mastodon, passei a usar o #TootThursday. Como o limite de caracteres é bem mais alto no Mastodon, não é preciso criar um #TT e é possível usar o nome inteiro. E assim sigo postando toda quinta-feira.
Eu andei reparando que meu envio de sugestões estava sempre em 4 ou 5 pessoas. Sempre. E meu programa pra fazer o envio usa 10% da lista de pessoas que sigo, algo que está em mais de 500 hoje em dia no perfil @helioloureiroBR.
Olhei manualmente o uso de account_following( ) e eu estava recebendo somente 40 entradas, mesmo com limite em nulo.
In [14]: u = tt.mastodon.account_following(id=tt.me.id, limit=None) In [15]: len(u) Out[15]: 40
Abri um bug report no GitHub, mas lá mesmo vi a sugestão pra usar account_following( ) com fetch_remaining( ), o que testei aqui.
In [16]: u = tt.mastodon.account_following(id=tt.me.id, limit=80) In [17]: len(u) Out[17]: 80 In [18]: u = tt.mastodon.account_following(id=tt.me.id, limit=500) In [19]: len(u) Out[19]: 80 In [20]: u2 = tt.mastodon.fetch_remaining(u) In [21]: len(u2) Out[21]: 525
E realmente deu certo.
Agora o script está corrigido pra pegar mais pessoas que sigo e selecionar os 10%.
Se quiser olhar o bug report no GitHub, esse é o link: https://github.com/halcy/Mastodon.py/issues/376
No Mastodon mesmo o Mauricio Castro (@
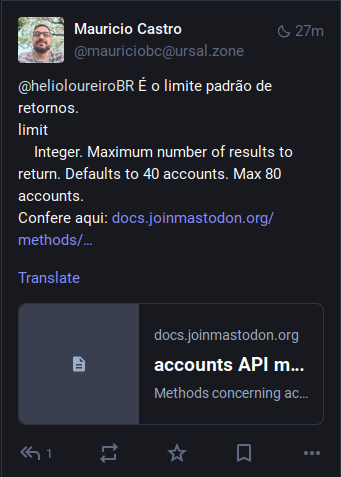
Mas vamos ver se o meu bug report ajuda a melhorar a documentação sobre isso.
UPDATE: escrevi o artigo e esqueci de apontar pro script, caso alguém queira usar ou copiar alguma parte. Ele está aqui: https://github.com/helioloureiro/homemadescripts/blob/master/mastodon-toot-thursday.py
![]()
Mais uma vez participei da BSD Day. Sempre um prazer estar no evento e equanto é possível.
Esse ano seria presencial, mas por causa da greve de funcionários o evento teve de ser online. Sorte minha.
Dessa vez contei a história do Unix. Depois que assisti eu achei que ficou meio confuso. Eu devia ter separado mais por linha de tempo pros eventos ficarem mais interessantes. Fica pra próxima.
Infelizmente minha webcam ficou travando. Ainda não sei bem se o problema foi no sistema, no archlinux, ou na banda (500 Mbps fibra ótica), ou no browser (Google Chrome) ou no Streamyard. Ou mesmo uma combinação de tudo.
Eu quase esqueci que tinha criado essa pérola aqui.
Quase... mas não esqueci :)
Como eu tenho deixado meu desktop boa parte do tempo desligado, eu abri uma porta ssh pro raspberrypi. Por quê? Por nenhum motivo.
Eu nunca realmente usei esse acesso ssh, que externamente estava numa porta alta 22XY, sendo X e Y meio que aleatórios.
E claro que esqueci disso. E hoje fui dar uma olhada. E vários ataques. Ou tentativas desses.
pi@raspberrypi3 ~> journalctl -u ssh | grep rhost | sed 's/.*ruser= //' | sort -n | uniq -c
4 rhost=101.182.50.204
2 rhost=101.182.50.204 user=root
294 rhost=103.187.164.70
1 rhost=103.187.164.70 user=backup
1 rhost=103.187.164.70 user=daemon
21 rhost=103.187.164.70 user=root
12031 rhost=106.12.118.63
1 rhost=106.12.118.63 user=avahi
13 rhost=106.12.118.63 user=backup
9 rhost=106.12.118.63 user=bin
1 rhost=106.12.118.63 user=dnsmasq
3 rhost=106.12.118.63 user=games
1 rhost=106.12.118.63 user=irc
1 rhost=106.12.118.63 user=list
1 rhost=106.12.118.63 user=mail
1 rhost=106.12.118.63 user=messagebus
2 rhost=106.12.118.63 user=pi
1379 rhost=106.12.118.63 user=root
2 rhost=106.12.118.63 user=rtkit
1 rhost=106.12.118.63 user=saned
1 rhost=106.12.118.63 user=sshd
1 rhost=106.12.118.63 user=sys
15 rhost=106.12.118.63 user=www-data
104 rhost=106.244.154.170
37 rhost=106.244.154.170 user=root
6 rhost=110.83.205.126
9 rhost=110.83.205.126 user=root
414 rhost=112.54.121.23
2 rhost=112.54.121.23 user=backup
1 rhost=112.54.121.23 user=bin
1 rhost=112.54.121.23 user=daemon
200 rhost=112.54.121.23 user=root
3 rhost=112.96.138.97
1 rhost=112.96.138.97 user=root
1 rhost=112.97.211.56 user=root
1 rhost=112.97.219.144
1 rhost=112.97.219.144 user=root
1 rhost=112.97.241.205 user=root
1 rhost=112.97.63.81 user=root
147 rhost=113.116.156.72
1 rhost=113.116.156.72 user=bin
1 rhost=113.116.156.72 user=games
2 rhost=113.116.156.72 user=man
1 rhost=113.116.156.72 user=pi
1 rhost=113.116.156.72 user=root
1 rhost=113.116.156.72 user=sshd
1 rhost=113.116.156.72 user=sync
2 rhost=113.116.156.72 user=sys
645 rhost=113.161.59.72
45 rhost=113.161.59.72 user=root
3 rhost=113.194.225.182
1 rhost=113.194.225.182 user=root
10679 rhost=115.68.114.145
5 rhost=115.68.114.145 user=backup
2 rhost=115.68.114.145 user=bin
2 rhost=115.68.114.145 user=daemon
2 rhost=115.68.114.145 user=dnsmasq
1 rhost=115.68.114.145 user=geoclue
1 rhost=115.68.114.145 user=gnats
1 rhost=115.68.114.145 user=list
1 rhost=115.68.114.145 user=lp
2 rhost=115.68.114.145 user=mail
2 rhost=115.68.114.145 user=pi
2181 rhost=115.68.114.145 user=root
3 rhost=115.68.114.145 user=sshd
1 rhost=115.68.114.145 user=sys
1 rhost=115.68.114.145 user=systemd-coredump
2 rhost=115.68.114.145 user=tss
24 rhost=115.68.114.145 user=uucp
9 rhost=115.68.114.145 user=www-data
1994 rhost=115.68.193.229
4 rhost=115.68.193.229 user=backup
4 rhost=115.68.193.229 user=bin
3 rhost=115.68.193.229 user=daemon
2 rhost=115.68.193.229 user=pi
863 rhost=115.68.193.229 user=root
3 rhost=115.68.193.229 user=www-data
171 rhost=115.73.212.140
70 rhost=115.73.212.140 user=root
1 rhost=115.73.212.140 user=www-data
240 rhost=115.73.222.121
27 rhost=115.73.222.121 user=root
117 rhost=115.79.138.57
28 rhost=115.79.138.57 user=root
1 rhost=115.79.138.57 user=uucp
41 rhost=117.132.195.92
13 rhost=117.132.195.92 user=root
1 rhost=117.132.195.92 user=uucp
597 rhost=119.204.234.220
1 rhost=119.204.234.220 user=lp
1 rhost=119.204.234.220 user=news
176 rhost=119.204.234.220 user=root
2 rhost=119.204.234.220 user=sshd
7 rhost=121.170.243.115
2 rhost=121.170.243.115 user=root
5 rhost=121.207.184.52
1 rhost=121.207.184.52 user=root
320 rhost=121.237.47.72
16 rhost=121.237.47.72 user=root
1 rhost=123.226.234.157 user=root
3 rhost=138.68.65.85
6 rhost=138.68.65.85 user=root
822 rhost=153.99.251.110
2 rhost=153.99.251.110 user=backup
2 rhost=153.99.251.110 user=bin
1 rhost=153.99.251.110 user=daemon
2 rhost=153.99.251.110 user=pi
366 rhost=153.99.251.110 user=root
1 rhost=153.99.251.110 user=www-data
52 rhost=171.125.189.103
2 rhost=171.125.189.103 user=root
4349 rhost=175.126.146.151
1 rhost=175.126.146.151 user=avahi
1 rhost=175.126.146.151 user=backup
1 rhost=175.126.146.151 user=bin
1 rhost=175.126.146.151 user=daemon
1 rhost=175.126.146.151 user=dnsmasq
1 rhost=175.126.146.151 user=games
1 rhost=175.126.146.151 user=gnats
1 rhost=175.126.146.151 user=irc
1 rhost=175.126.146.151 user=list
1 rhost=175.126.146.151 user=messagebus
1 rhost=175.126.146.151 user=nobody
1 rhost=175.126.146.151 user=pi
511 rhost=175.126.146.151 user=root
1 rhost=175.126.146.151 user=sshd
1 rhost=175.126.146.151 user=sync
1 rhost=175.126.146.151 user=sys
1 rhost=175.126.146.151 user=systemd-coredump
1 rhost=175.126.146.151 user=uucp
1 rhost=175.126.146.151 user=www-data
2376 rhost=175.126.146.170
2 rhost=175.126.146.170 user=backup
8 rhost=175.126.146.170 user=bin
2 rhost=175.126.146.170 user=daemon
3 rhost=175.126.146.170 user=lp
1 rhost=175.126.146.170 user=news
4 rhost=175.126.146.170 user=nobody
1601 rhost=175.126.146.170 user=root
1 rhost=175.126.146.170 user=saned
3 rhost=175.126.146.170 user=sshd
100 rhost=176.232.199.34
9 rhost=176.232.199.34 user=root
2 rhost=180.102.215.191
2 rhost=180.102.215.191 user=root
50 rhost=180.214.179.130
1 rhost=180.214.179.130 user=nobody
12 rhost=180.214.179.130 user=root
104 rhost=182.161.158.243
1 rhost=182.161.158.243 user=bin
36 rhost=182.161.158.243 user=root
64 rhost=182.92.205.87 user=root
168 rhost=183.239.61.5
36 rhost=183.239.61.5 user=root
1 rhost=183.239.61.5 user=uucp
802 rhost=183.6.114.32
9 rhost=183.6.114.32 user=bin
5 rhost=183.6.114.32 user=daemon
2 rhost=183.6.114.32 user=nobody
370 rhost=183.6.114.32 user=root
31 rhost=185.11.61.234
2 rhost=185.11.61.234 user=backup
6 rhost=185.11.61.234 user=root
127 rhost=185.11.61.88
18 rhost=185.11.61.88 user=root
1 rhost=185.11.61.88 user=uucp
1 rhost=185.11.61.88 user=www-data
640 rhost=188.92.243.94
5 rhost=188.92.243.94 user=backup
2 rhost=188.92.243.94 user=bin
1 rhost=188.92.243.94 user=daemon
1 rhost=188.92.243.94 user=news
1 rhost=188.92.243.94 user=proxy
381 rhost=188.92.243.94 user=root
1 rhost=188.92.243.94 user=sync
1 rhost=188.92.243.94 user=www-data
10 rhost=190.108.93.158
18 rhost=190.108.93.158 user=root
1217 rhost=190.2.143.54
13 rhost=190.2.143.54 user=bin
7 rhost=190.2.143.54 user=daemon
4 rhost=190.2.143.54 user=nobody
561 rhost=190.2.143.54 user=root
15 rhost=190.238.35.29
1 rhost=190.238.35.29 user=pi
1 rhost=190.238.35.29 user=root
12006 rhost=190.89.76.29
7 rhost=190.89.76.29 user=pi
389 rhost=190.89.76.29 user=root
19 rhost=195.122.229.82
1 rhost=195.122.229.82 user=root
1 rhost=2.53.171.103 user=root
803 rhost=212.186.185.171
10 rhost=212.186.185.171 user=bin
5 rhost=212.186.185.171 user=daemon
2 rhost=212.186.185.171 user=nobody
370 rhost=212.186.185.171 user=root
234 rhost=213.63.233.87
1 rhost=213.63.233.87 user=backup
1 rhost=213.63.233.87 user=bin
2 rhost=213.63.233.87 user=lp
181 rhost=213.63.233.87 user=root
1 rhost=213.63.233.87 user=sys
1 rhost=213.63.233.87 user=usbmux
28 rhost=218.101.201.179
1 rhost=218.101.201.179 user=root
7 rhost=218.81.76.84
10 rhost=218.81.76.84 user=root
822 rhost=220.249.111.98
2 rhost=220.249.111.98 user=backup
2 rhost=220.249.111.98 user=bin
1 rhost=220.249.111.98 user=daemon
2 rhost=220.249.111.98 user=pi
366 rhost=220.249.111.98 user=root
1 rhost=220.249.111.98 user=www-data
289 rhost=222.107.116.47
92 rhost=222.107.116.47 user=root
159 rhost=222.208.47.30
1 rhost=222.208.47.30 user=pulse
50 rhost=222.208.47.30 user=root
23 rhost=39.118.171.84
24 rhost=39.118.171.84 user=root
4 rhost=39.144.46.7
2 rhost=39.144.46.7 user=root
63 rhost=39.144.46.82
2 rhost=39.144.46.82 user=root
996 rhost=39.162.8.99
1 rhost=39.162.8.99 user=list
1 rhost=39.162.8.99 user=proxy
77 rhost=39.162.8.99 user=root
1 rhost=39.162.8.99 user=sys
1 rhost=39.162.8.99 user=www-data
6 rhost=42.49.109.197
3 rhost=42.49.109.197 user=root
758 rhost=46.7.73.67
1 rhost=46.7.73.67 user=bin
1 rhost=46.7.73.67 user=nobody
240 rhost=46.7.73.67 user=root
1672 rhost=51.81.245.139
2 rhost=51.81.245.139 user=backup
8 rhost=51.81.245.139 user=root
27 rhost=51.81.245.139 user=uucp
5 rhost=51.81.245.139 user=www-data
254 rhost=58.218.252.82
1 rhost=58.218.252.82 user=proxy
47 rhost=58.218.252.82 user=root
316 rhost=59.58.102.162
1 rhost=59.58.102.162 user=backup
97 rhost=59.58.102.162 user=root
1 rhost=59.58.102.162 user=sync
12 rhost=61.149.209.194
4 rhost=61.149.209.194 user=root
134 rhost=62.122.184.252
10 rhost=62.122.184.252 user=root
2 rhost=62.122.184.252 user=sshd
2 rhost=67.205.142.48
3 rhost=75.119.144.68 user=root
55 rhost=81.14.168.152
25 rhost=81.14.168.152 user=root
1 rhost=81.14.168.152 user=saned
29 rhost=85.209.11.226
1 rhost=85.209.11.226 user=pi
5 rhost=85.209.11.226 user=root
1 rhost=85.209.11.226 user=sshd
1809 rhost=85.24.245.46
8 rhost=85.24.245.46 user=backup
1 rhost=85.24.245.46 user=bin
1 rhost=85.24.245.46 user=lp
1 rhost=85.24.245.46 user=mail
2 rhost=85.24.245.46 user=news
4 rhost=85.24.245.46 user=nobody
1 rhost=85.24.245.46 user=proxy
1229 rhost=85.24.245.46 user=root
1 rhost=85.24.245.46 user=uucp
413 rhost=85.246.237.232
1 rhost=85.246.237.232 user=games
1 rhost=85.246.237.232 user=nobody
293 rhost=85.246.237.232 user=root
1 rhost=85.246.237.232 user=saned
1 rhost=85.246.237.232 user=sshd
1 rhost=85.246.237.232 user=uucp
1 rhost=86.227.110.209
37 rhost=86.236.26.148
12 rhost=86.236.26.148 user=root
1 rhost=90.134.40.219 user=root
306 rhost=90.40.72.74
1 rhost=90.40.72.74 user=root
7 rhost=90.40.72.74 user=uucp
1 rhost=90.40.72.74 user=www-data
129 rhost=94.208.120.232
1 rhost=94.208.120.232 user=daemon
13 rhost=94.208.120.232 user=root
Desativei a porta.
O raspberrypi precisa de senha pra sudo, coisa que aprendi depois do ataque bem sucedido do Maycon que ficou eternizado dentro do código do stallmanbot.py:
def Hacked(obj, cmd):
try:
obj.reply_to(cmd, u"This is the gallery of metions from those who dared to hack, and just made it true.")
obj.reply_to(cmd, u"Helio is my master but Maycon is my hacker <3 (Hack N' Roll)")
gif = "https://media.giphy.com/media/26ufcVAp3AiJJsrIs/giphy.gif"
obj.send_document(cmd.chat.id, gif)
except Exception as e:
obj.reply_to(cmd, f"Deu merda: {e}")
Então acredito que mesmo um ataque bem sucedido de ssh não tenha causado grandes danos. Mas nunca é certeza :)
Outro ponto interessante é que todos os ataques vieram por IPv4. Nenhum, absolutamente nenhum, por IPv6. Até nesse ponto IPv6 é mais seguro.
A controvérsia quanto à nomenclatura GNU/Linux é uma disputa entre membros da comunidade de software livre e código aberto. É centrada em torno da denominação do núcleo de sistema chamado "Linux", e a vontade de utilizar esta nomenclatura como um termo genérico para tudo relacionado ao mesmo. O termo defendido pela Free Software Foundation (FSF), para relacionar o núcleo do sistema com as ferramentas desenvolvidas pela fundação GNU seria GNU/Linux, ficando o nome "Linux" para ser utilizado apenas quando se referindo ao núcleo Linux. O nome é por vezes pronunciado como "GNU com Linux".
https://pt.wikipedia.org/wiki/Controv%C3%A9rsia_quanto_%C3%A0_nomenclatura_GNU/Linux
Eu peguei esse trecho da wikipedia. Abrindo um pequeno comentário sobre o mesmo: a versão em português está bem diferente da versão em inglês e fica ao critério do leitor dar uma olhada em ambos e decidir qual está melhor. Voltando ao assunto, a guerra entre os termo Linux e GNU/Linux. A briga vem de longa data, basicamente quando Linux começou a crescer exponencialmente em popularidade e deixou o projeto GNU em sua sombra. O bom doutor, Richard Stallman, ficou famoso por suas longas interjeições sobre o assunto. E virou meme. Infinitos memes.
O sistema operacional era GNU no início, mas por conta do kernel na época não estar pronto, usaram Linux. Mas não imaginavam que a força de comunidade ao redor do Linux seria tão grande e tão marcante. Ao ponto do Linux ter sido somente um kernel no início, mas hoje ser uma fundação e com vários projetos abrigados, como o OpenTofu, Linux para setor automobilístico, CNCF (Cloud Native Computing Foundation), etc. Por simplicidade, muita gente chama o sistema operacional inteiro com Linux somente. E isso, claro, ganhou força por ser mais fácil e simples que dizer GNU/Linux ou GNU+Linux.
Dentro dessa discussão existe ainda o ponto que alguns levantam que dentro de um sistema operacional, geralmente aquilo que você usa de uma distro - distribuição de Linux, não depende só do GNU. Existem outros códigos, projetos e licenças ali. De MIT a Apache, de KDE a Gnome, e assim por diante. Então se fosse pra dar crédito a todos ali, deveria ser chamado MIT/Xorg/Apache/Git/GNU/Linux ou qualquer outra coisa tão bizarra ou até mais que isso.
Claro que grande parte das coisas ali não existiriam sem a contribuição do projeto GNU, principalmente com o GCC. Até mesmo os BSDs dependeram do GCC até a Apple botar dinheiro no llvm/clang - e por conta disso estavam todos parados no GCC 3.2 por causa da mudança pra licença GPLv3, então a Apple ajudou muito.
E existe ainda a discussão, bastante rasa, de alguns de que Linux não roda sem GNU. Isso já foi demonstrado tanto pelo Android que não é verdade. E agora existem tanto o Chimera Linux, sem absolutamente nada de GNU e usando algumas ferramentas escritas em rust, quanto o Alpine Linux, feito pra containers.
Mas o ponto que eu queria abordar aqui, pois essa discussão já existe faz décadas e nada mudou muito, foi um artigo que peguei no site do GNU. Eu particularmente achei maravilhoso.
https://www.gnu.org/distros/common-distros.en.html
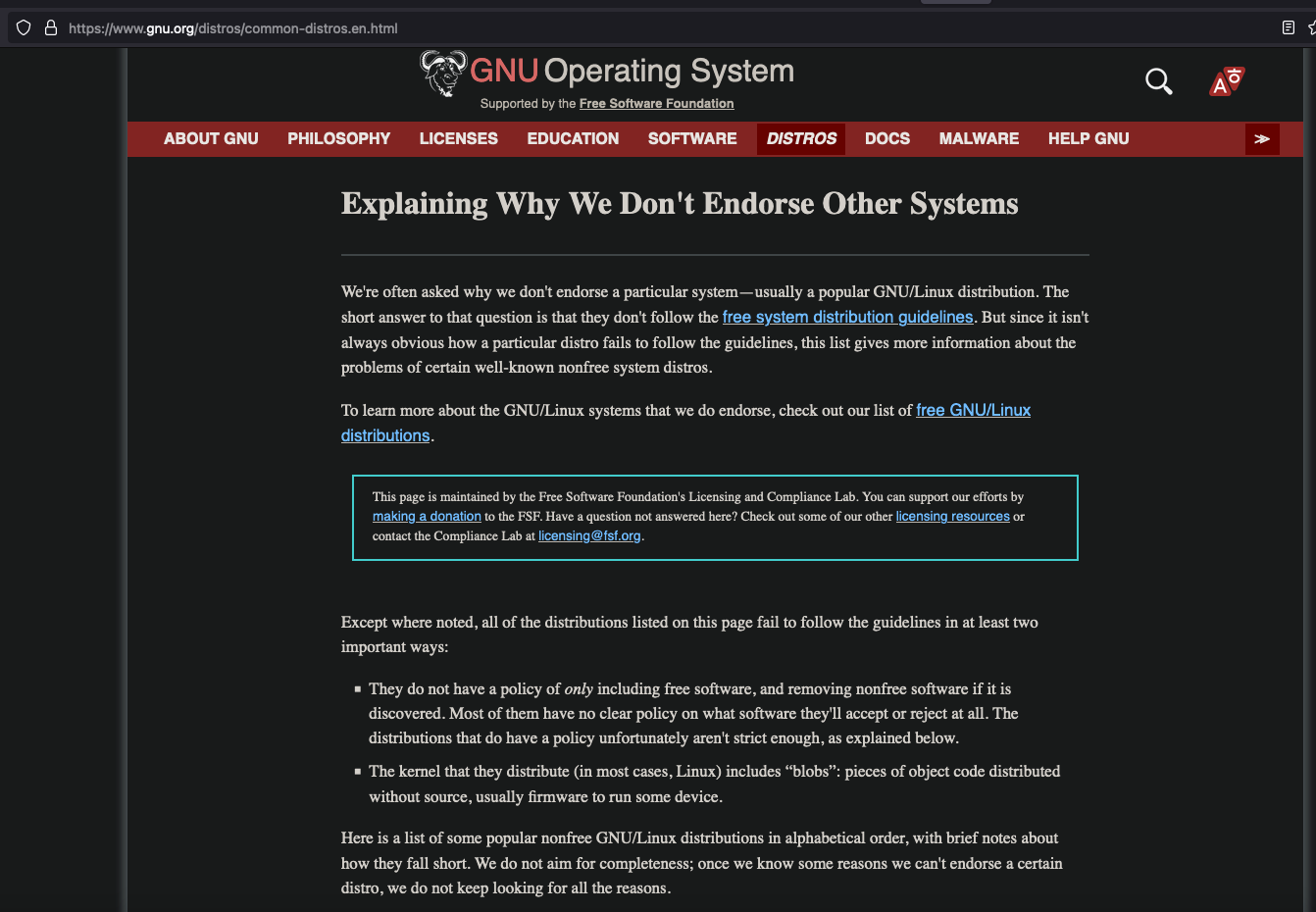
tl;dr: basicamente o que está escrito é que o projeto GNU não endossa as distribuições porque pra isso não pode distribuir nada que não seja software livre. Então quem usa firmwares binários, os blobs, não é endossado como GNU. Nem quem permite instalação de software proprietário. Sim, quem permite. Pois o OpenBSD não carrega firmwares binários por questões de segurança. Nem contém softwares proprietários no sistema operacional. Mas o sistema de ports, que são scripts e Makefiles de contribuidores e de usuários, esse instala softwares não livres. E isso é o suficiente pra GNU não endossar como... um sistema GNU??? Apesar da hipocrisia, acho que não seria o caso de nomear o OpenBSD como GNU de qualquer forma.
Mas o interessante é que ela acaba com a discussão. Se contém firmware ou é possível instalar software proprietários (steam, google chrome, etc) então não é GNU. Muito bem. Então nem é mais preciso a discussão sobre o nome. O nome é Linux e pronto :)
Interessante que referem-se às distros como GNU/Linux, como no caso do Arch GNU/Linux, enquanto o próprio Arch está como Arch Linux.
Pra terminar, deixo aqui vocês com os melhores memes desse tema.

















Se você nunca ouviu falar de DoH além do Homer reclamando que fez alguma bobagem, então não está na Internet tempo o suficiente. E talvez não esteja protegendo sua privacidade como poderia.
DNS, de Domain Name Service (serviço de nomes de domíno), é o que traduz um nome de domínio como helio.loureiro.eng.br pra um endereço IP. No caso de helio.loureiro.eng.br o nome é resolvido tanto pra IPv4 quanto pra IPv6.
Por mais inocente que seja essa tradução, esse dado não tem criptografia ou qualquer outro tipo de proteção. Pode e provavelmente é usado por seu provedor de Internet pra conhecer seus hábitos de navegação e até vender esse dado pra alguém.
Pra coibir tal uso de sua informação pessoal foi criado o protocolo DoH, ou DNS over HTTPS, que é a requisição de DNS enviada por HTTPS. A vantagem desse método é que ninguém consegue diferenciar seu tráfego HTTPS como sendo uma requisição DNS ou acesso a uma página web, que é protegida por uma camada de SSL de criptografia. O firefox permite a configuração de forma bastante fácil.
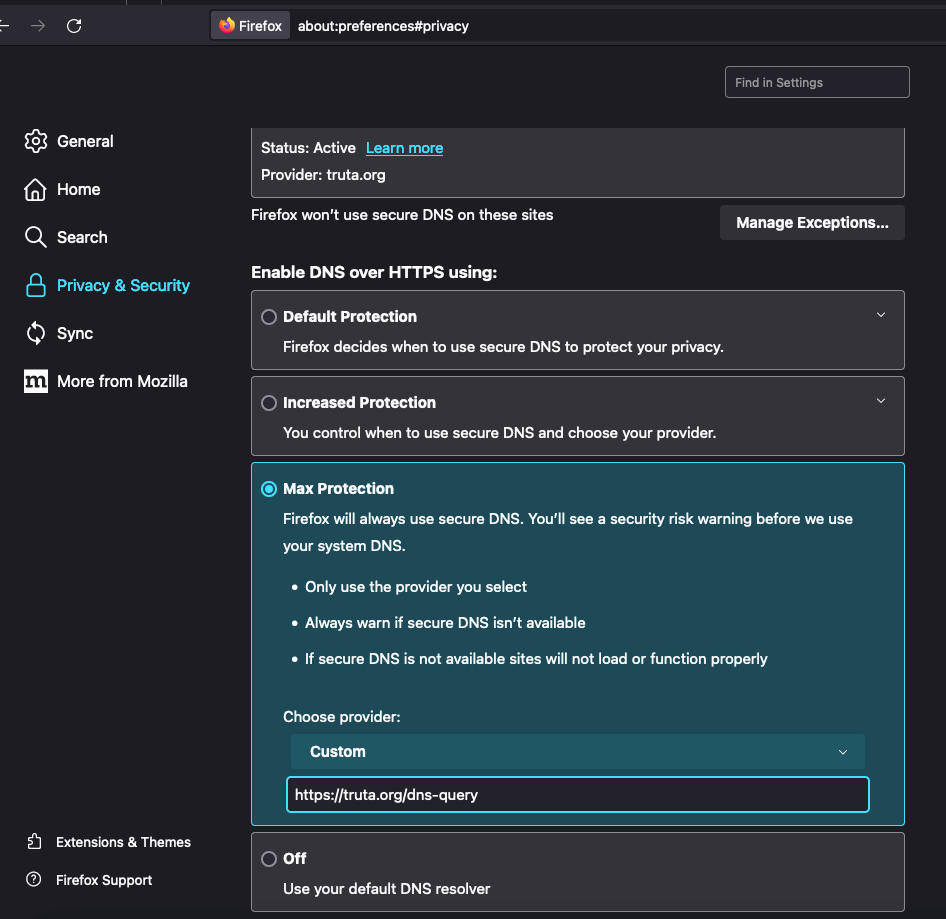
Mas claro que em alguns lugares o acesso pode ser barrado pra dificultar seu acesso ao DoH e forçar o uso de um serviço de DNS local. Por padrão o firefox permite usar o serviço do Cloudflare ou do NextDNS. O que fazem alguns provedores é bloquear requisições pra esses destinos. Mesmo o serviço de DoH do OpenDNS é bloqueado.
Pra previnir isso eu habilitei um DoH relay que recebe as requisições e envia para https://doh.opendns.com/dns-query pra resolver. Então para usar o serviço, basta configurar como fiz acima no Firefox e usar o destino:
E claro que esse artigo não é só pra dizer que esse serviço está habilitado. É pra mostrar como montar o seu.
Eu usei o binário de um doh-relay escrito em Go e disponível no github aqui:
https://github.com/tinkernels/doh-relay
A compilação foi um simples comando, assumindo que tenha o Go pra fazer a compilação:
macOS in ~
✦ ❯ cd /tmp
macOS in /tmp
✦ ❯ git clone https://github.com/tinkernels/doh-relay.git
Cloning into 'doh-relay'...
remote: Enumerating objects: 461, done.
remote: Counting objects: 100% (192/192), done.
remote: Compressing objects: 100% (136/136), done.
remote: Total 461 (delta 127), reused 117 (delta 56), pack-reused 269
Receiving objects: 100% (461/461), 180.87 KiB | 3.17 MiB/s, done.
Resolving deltas: 100% (307/307), done.
macOS in /tmp
✦ ❯ cd doh-relay
macOS in doh-relay on master via 🐹 v1.22.0
✦ ❯ make linux-amd64
mkdir -p release
GOOS=linux GOARCH=amd64 go build -ldflags "-extldflags=-static -w -s" -o release/doh-relay_linux-amd64 .
go: downloading github.com/ReneKroon/ttlcache v1.7.0
go: downloading github.com/miekg/dns v1.1.54
go: downloading github.com/buraksezer/connpool v0.6.0
go: downloading github.com/gin-gonic/gin v1.9.0
go: downloading github.com/oschwald/geoip2-golang v1.8.0
go: downloading github.com/sirupsen/logrus v1.9.1
go: downloading gopkg.in/yaml.v3 v3.0.1
go: downloading golang.org/x/sys v0.8.0
go: downloading golang.org/x/net v0.10.0
go: downloading github.com/gin-contrib/sse v0.1.0
go: downloading github.com/mattn/go-isatty v0.0.18
go: downloading github.com/go-playground/validator/v10 v10.13.0
go: downloading github.com/ugorji/go/codec v1.2.11
go: downloading github.com/pelletier/go-toml/v2 v2.0.7
go: downloading github.com/oschwald/maxminddb-golang v1.10.0
go: downloading github.com/leodido/go-urn v1.2.4
go: downloading golang.org/x/crypto v0.9.0
go: downloading github.com/go-playground/universal-translator v0.18.1
go: downloading golang.org/x/text v0.9.0
go: downloading github.com/go-playground/locales v0.14.1
macOS in doh-relay on master via 🐹 v1.22.0 took 9s
✦ ❯ mv release/doh-relay_linux-amd64 release/doh-relay
No servidor truta.org, copiei o binário pra /usr/local/bin. E criei grupo e usuário.
root@truta /u/l/bin# addgroup --system doh-relay
Adding group `doh-relay' (GID 135) ...
Done.
root@truta /u/l/bin# adduser --system --gid 135 doh-relay
Adding system user `doh-relay' (UID 129) ...
Adding new user `doh-relay' (UID 129) with group `doh-relay' ...
Not creating `/nonexistent'.
Em seguida adicionei um serviço ao systemd e habilitei.
root@truta /# cd /etc/systemd/system
root@truta /e/s/system# vim doh-relay.service
root@truta /e/s/system# cat doh-relay.service
[Unit]
Description=Dns-over-HTTPS relay
After=syslog.target network.target
[Service]
User=doh-relay
Group=doh-relay
WorkingDirectory=/tmp
ExecStart=/usr/local/bin/doh-relay --cache=true --doh -doh-upstream=https://doh.opendns.com/dns-query
Type=simple
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
root@truta /e/s/system# systemctl daemon-reload
root@truta /e/s/system# systemctl enable --now doh-relay.service
Created symlink /etc/systemd/system/default.target.wants/doh-relay.service → /etc/systemd/system/doh-relay.service.
root@truta /e/s/system# systemctl status doh-relay
● doh-relay.service - Dns-over-HTTPS relay
Loaded: loaded (/etc/systemd/system/doh-relay.service; enabled; preset: enabled)
Active: active (running) since Thu 2024-03-07 09:47:09 -03; 5s ago
Main PID: 819347 (doh-relay)
Tasks: 6 (limit: 3535)
Memory: 4.0M
CPU: 15ms
CGroup: /system.slice/doh-relay.service
└─819347 /usr/local/bin/doh-relay --cache=true --doh -doh-upstream=https://doh.opendns.com/dns-query
Mar 07 09:47:09 truta.org systemd[1]: Started doh-relay.service - Dns-over-HTTPS relay.
Mar 07 09:47:09 truta.org doh-relay[819347]: *** Starting ***
Mar 07 09:47:09 truta.org doh-relay[819347]: time="2024-03-07T09:47:09" level=info msg="open : no such file or directory" file="geoip.go:41"
Mar 07 09:47:09 truta.org doh-relay[819347]: time="2024-03-07T09:47:09" level=info msg="resolver: [https://doh.opendns.com/dns-query], fallback: []" file="main.go:339"
O último passo foi adicionar a configuração ao apache com proxy interno conectando com a porta 15353 onde roda o doh-relay.
root@truta /e/a/conf-enabled# cat /etc/apache2/conf-enabled/doh-enabled.conf
<IfModule mod_proxy.c>
ProxyVia On
ProxyRequests Off
ProxyPass /dns-query http://localhost:15353/dns-query retry=0 timeout=10
ProxyPassReverse /dns-query http://localhost:15353/dns-query
ProxyPreserveHost on
<Proxy *>
Options FollowSymLinks MultiViews
AllowOverride All
Order allow,deny
allow from all
</Proxy>
</IfModule>
root@truta /e/a/conf-enabled# a2enmod proxy
Module proxy already enabled
root@truta /e/a/conf-enabled# a2enmod proxy_html
Considering dependency proxy for proxy_html:
Module proxy already enabled
Considering dependency xml2enc for proxy_html:
Enabling module xml2enc.
Enabling module proxy_html.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# a2enmod proxy_http
Considering dependency proxy for proxy_http:
Module proxy already enabled
Enabling module proxy_http.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# a2enmod proxy_http2
Considering dependency proxy for proxy_http2:
Module proxy already enabled
Considering dependency http2 for proxy_http2:
Enabling module http2.
Enabling module proxy_http2.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# apachectl configtest
Syntax OK
root@truta /e/a/conf-enabled# apachectl restart
E pronto. Um relay de DoH pronto pra servir.
06-05-2025: deu algum ziriguidum no serviço e no momento não está funcionando. Se alguém, além de mim, usava pra alguma coisa, sinto muito. Atualizo aqui quando voltar.

Essa é uma dica pra quem, como eu, cria vários bots por aí. Se você quer dar uma carinha bonita pro perfil do bot, existe esse site que gera uma imagem pra você: https://robohash.org/
Eu gerei uma aqui pro site pra ter uma ideia.

Eu não lembro quem passou a dica disso. Mas nunca mais parei de usar. Nada como ter um rosto no seu robô preferido.
Pra quem acompanha o https://linux-br.org deve ter percebido que o ritmo de postagem caiu bastante. Na verdade despencou em comparação com o ano passado.
E não, não foi mais um bug que eu introduzi.
Ao contrário. Eu diria que fiz os artigos mostrados serem mais seletos. Primeiramente usando um filtro melhor de palavras de interesse. Descobri que meu filtro anterior tinha um erro no regex (sempre ele) e não funcionava como eu queria. Na verdade não fazia nada e passava qualquer tipo de artigo. Esse tipo de coisa de regex quando a gente faz errado...
Corrigido o problema de filtrar as palavras chaves, durate a refatoração do código eu resolvi só adotar artigos que tinha feito upload de uma imagem com sucesso. E isso já restringiu ainda mais o volume de postagens pra modestos 1 ou 2 por dia. Às vezes nem mesmo isso. E espero que esse efeito ajude a mais pessoas a participarem do site, algo que está longe de acontecer pelos números de acessos diários.
2024 já com força total :)
Recentemente tem circulado no Mastodon as mensagens do site https://crieaporradeum.blog/ que é um tradução do https://startafuckingblog.com/ e um incentivo um tanto passivo-agressivo pras pessoas criarem seus próprios sites. Como eu.
Não sei bem se usando uma linguagem assim consiga realmente incentivar as pessoas a fazerem isso, mas eu ao menos vi algumas respostas positivas. O que me faz pensar que talvez eu deva começar a usar o mesmo tipo de linguagem passivo-agressiva pra convencer as pessoas a fazerem algo.
Enquanto isso deixo aqui uma imagem com o mesmo estilo que fiz numa outra vida agora. Espero que também sirva de incentivo pra quem está lendo aqui a fazer... sei lá. Faça qualquer coisa com isso desde que seja algo positivo. Ao menos eu espero que seja positivo.

E façam a porra de um blog!
Foi o que pensei que ia acontecer. Infelizmente as coisas não saíram como esperado.
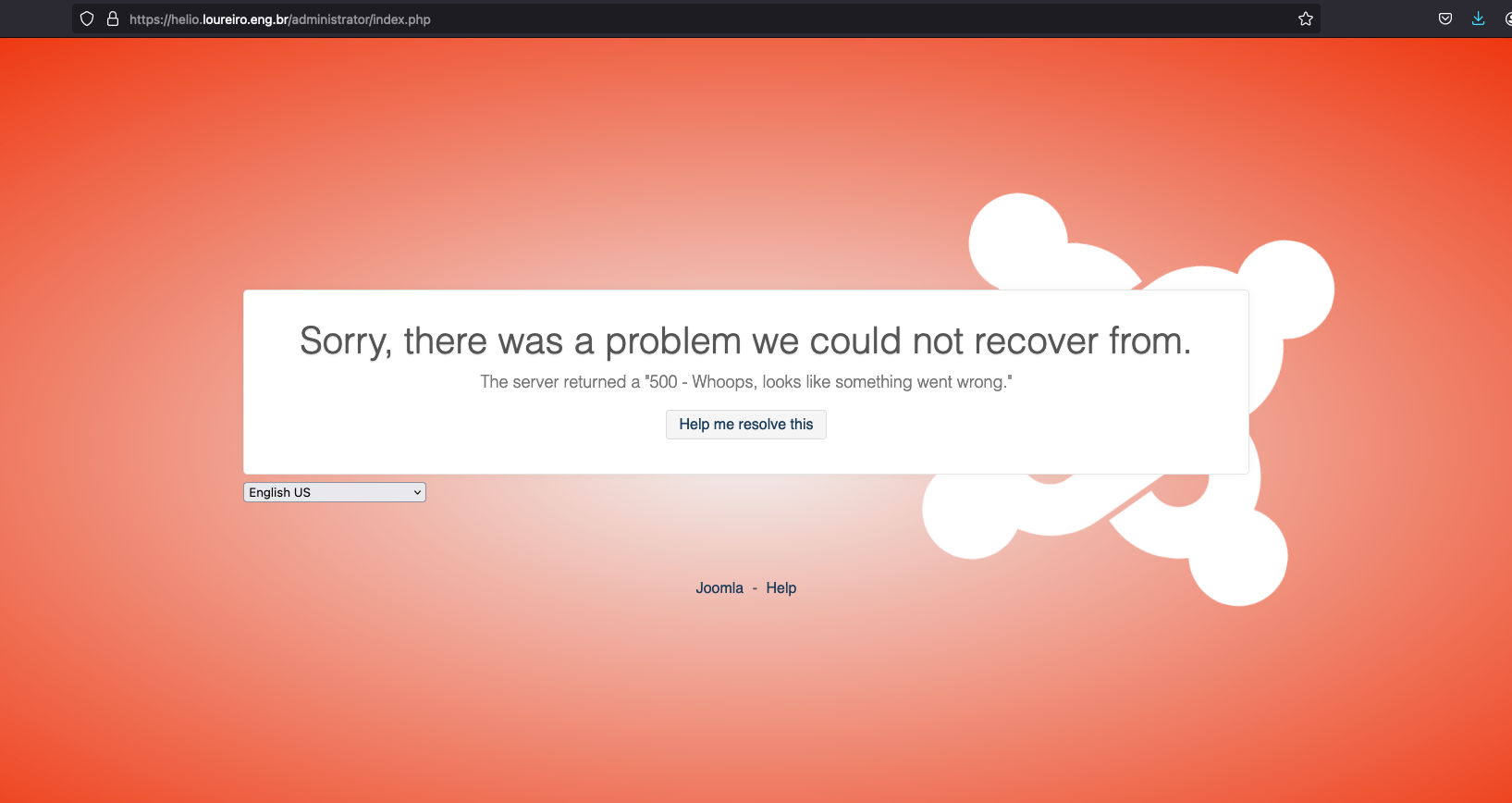
E claro que já resolvi o problema, que foi relacionado com php8.2-mysql, do contrário não estaria lendo esse artigo. Mas podia ter acontecido lá depois de julho...
Page 6 of 37
