![]() Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
#! /usr/bin/python
def debug(msg):
print "DEBUG: %s" % msg
class MinhaClasse:
código
código
código
if __name__ == '__main__':
o = MinhaClasse()
o.main()
Então o que faço em geral é ter uma função debug(), mesmo que use classe e orientação à objetos, pra facilitar a chamada. Porque eu uso a função? Se eu usar como método dentro da classe, tem de chamar toda vez como self.debug(). Como não vejo muita vantagem nisso, prefiro definir sempre como função no topo do código.
Mas esse é um exemplo pra mostrar o princípio. O que uso é um pouco mais elaborado que isso. Vamos melhorar esse código pra entender melhor criando alguns métodos como __init__() e main().
#! /usr/bin/python
import getopt
DEBUG = False
def debug(msg):
if DEBUG:
print "DEBUG: %s" % msg
class MinhaClasse:
def __init__(self):
debug("Construtor da classe")
def fazalgo(self):
debug("Fazendo algo")
def main(self):
debug("Chamando main")
self.fazalgo()
if __name__ == '__main__':
try: opts, args = getopt.getopt(sys.argv[1:], "d") for opt, arg in opts: if opt == "-d": DEBUG = True debug("DEBUG ENABLED") except getopt.GetoptError: pass
if os.environ.has_key("DEBUG"): DEBUG = True
o = MinhaClasse()
o.main()
Primeiramente eu adicione algum tipo de verificação de opção. Pode ser com getopt como argparse. Como é uma opção simples, pra verificar o parâmetro "-d", de debug ativo, usei getopt. Em seguida usei uma variável global DEBUG, que fica como padrão em False, ou seja, desligado.
Quando faço a chamada na parte de baixo, onde __name__ é '__main__', verifico a opção via flag ou via variável de shell. Isso quer dizer que se eu usar o script de 2 formas, terei debug ativado:
> ./meuscript.py -d
ou
> env DEBUG=1 ./meuscript.py
a segunda forma ajuda no caso de ter um sistema mais complexo e um shell script chamar seu programa. Daí se vários scripts verificarem as variáveis de shell pra buscar por DEBUG (ou $DEBUG), fica fácil ativar/desativar.
E assim até hoje eu debugo meus programas. Claro que fiz alguns aperfeiçoamentos como uma função que imprime o nome do método que está rodando.
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
Assim, dentro de um método, posso usar debug da seguinte forma:
class MinhaClasse:
def __init__(self):
debug(__funcname__)
E isso ajuda ao imprimir o nome da função corrente, da mesma forma que se usa a macro__FUNCTION__ em C. Essa dica eu achei recentement no StackOverflow:
http://stackoverflow.com/questions/5067604/determine-function-name-from-within-that-function-without-using-traceback
E por último, e acabei com o tempo refinando meu debug(). Ao invés de de somente aceitar string, eu fiz um seletor de tipo pra imprimir qualquer variável, inclusive dicionários no formato json pra ficar mais fácil ler.
#! /usr/bin/python
import json
import getopt
DEBUG = False
def debug(msg):
""" Debug helper """
if DEBUG:
if type(msg) == type("abc"):
# it is ok
None
elif type(msg) == type({}):
msg = "%s" % json.dumps(msg, indent=4)
elif type(msg) == type([]):
msg = "[ %s ]" % ", ".join(msg)
msg = "DEBUG(%s): %s" % (__file__, msg)
print msg
syslog.syslog(syslog.LOG_DEBUG, msg)
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
class MinhaClasse:
def __init__(self):
debug(__funcname__)
debug("Construtor da classe")
self.nome = "Helio"
self.sobrenome = "Loureiro"
debug("Nome: %s" % self.nome)
debug("Sobrenome: %s" % self.sobrenome)
self.dados = {}
def fazalgo(self):
debug(__funcname__)
debug("Fazendo algo")
for k, v in self.dados.items():
debug("%s => %s" % (k, v) )
def main(self):
debug(__funcname__)
self.dados = { "Nome" : self.nome,
"Sobrenome" : self.sobrenome }
debug(self.dados)
self.fazalgo()
if __name__ == '__main__':
try:
opts, args = getopt.getopt(sys.argv[1:], "d")
for opt, arg in opts:
if opt == "-d":
DEBUG = True
debug("DEBUG ENABLED")
except getopt.GetoptError:
pass
if os.environ.has_key("DEBUG"):
DEBUG = True
o = MinhaClasse()
o.main()
Como escrevi anteriormente, não é um padrão fazer isso. Existem módulos que ajudam a debuggar de forma até mais profunda. Eu gosto de escrever minhas mensagens de debug pra filtrar melhor as mensagens e poder ver o que realmente importa. Então fica aqui a dica.
![]()
O software livre é tido como um movimento social por várias pessoas. Pelo mesmo motivo muitas outras associam software livre com socialismo ou comunismo, o que já foi desmentido pelo próprio criador do termo software livre: Richard Stallman.
Eu mesmo imaginava que a função social do software livre como a imagem acima, que peguei do projeto de uma colega de trabalho, Eduscope[1]. Era algo que tornaria o mundo melhor e menos desigual, lutando contra as grandes corporações que controlavam o mundo. Essa última parte era outra forma de dizer "sou contra a Microsoft e tudo que ela representa".
E se foram mais de 10 anos com software livre. Linux completou 20 anos. Projeto GNU, 30. E o mundo?
O mundo não ficou menos desigual. Pela situação atual da economia americana, eu diria que até ficou muito mais desigual. O Brasil teve uma melhoria de condição de vida das famílias em geral, olhando num panorama dos últimos 10 anos - e descartando um pouco a crise atual, mas não foi causada pelo software livre. Enquanto isso as empresas de software livre como RedHat, Canonical e Google se tornaram uma corporação tão grande e poderosa como a própria Microsoft, com os mesmo tipos de problemas que tentávamos combater antes.
Onde está esse lado social? Cadê???
Pensando sobre isso, comecei a olhar por outro lado: quais são as empresas de sucesso atualmente? A Forbes lista as principais como sendo:
Se filtrarmos por empresas de tecnologia somente, o ranking fica assim:
Ignorando que a Microsoft disse que "ama o Linux", já que a contribuição dela com software livre é pouca e em geral cobre mais a adaptação ao seu ambiente de cloud, o Azure, todas as demais têm algum envolvimento com software livre. Seja como parte de sua estratégia de negócios, seja como seus produtos ou serviços (o que volta à estratégia). Então é possível ver que software livre é um sucesso no mundo dos negócios, mas ainda não tem nenhum lado social. E no fim empresas cresceram e acabaram virando grandes corporações como anteriormente.
Mas eu pessoalmente acho que surgiu um lado social do software livre que é bem diferente desse de melhoria das condições das populações mais pobrel (continua sendo obrigação do governo) e do fim das grandes corporações. Vou usar o mercado em que trabalho como exemplo pra isso, o de telecomunicações.
Se observar o mercado de telecom de 20 anos atrás, no surgimento do Linux, esse era um mercado dominado por grandes empresas e padrões rígidos. Tudo era definido pela ITU-T ou IEEE com custos altíssimos de aquisição de material. Então existiam poucos interessados - a menos que tivessem muito capital pra entrar nesse mercado - e os equipamentos eram muito caros, o que refletia diretamente nos valores cobrados dos usuários, que tinham basicamente um serviço de voz e nada mais.
Pensando em 10 anos atrás, 2006, esse mercado já tinha sofrido algumas baixas com o surgimento do Skype, que iniciou uma migração sem volta pra serviços de VoIP. Skype não foi o único responsável por VoIP, mas arruinou boa parte das operadoras que tinham como seu negócio a venda de chamadas internacionais. Em 2006 voz ainda era o maior gerador de receita das empresas, mas a banda larga já estava gerava uma outra boa parte e mostrava que estava crescendo. Mas os celulares mais modernos, smartphones, ainda não eram uma realidade próxima pra muita gente.
Olhando esse mesmo mercado hoje em dia, o que aconteceu? Grandes fornecedores de equipamentos simplesmente faliram, como foi o caso da Nortel. Outros se juntaram pra poder sobreviver. Mas a quantidade de fornecedores não aumentou, muito pelo contrário, apenas diminuiu. De onde veio a concorrência que destruiu seu mercado? Veio de IT. Com isso o mercado de telecom se transformou em ICT, Information and Communications Technology, ou Tecnologia da informação e da telecomunicação. Regras fixas que levavam anos, talvez décadas , pra serem definidas foram trocadas por métodos ágeis e softwares mais leves. Normas ITU-T foram trocadas por RFCs da IETF. Empresas que não tinham nenhum conhecimento sobre telecom começaram a tentar esse mercado. A Apple, uma inovadora nesse sentido, simplesmente quebrou todos os paradigmas de telefonia com o lançamento do iPhone. Junto veio o Android. E com isso milhões de programadores começaram a lançar seus apps pra esse mundo novo. O mundo abraçou dados e IP, e voz, antes o carro chefe de mercado, virou um acessório de pouco uso.
Onde está o lado social e software livre nisso? Se pensar nesses momentos, de 20 anos atrás, 10 e agora, verá que o custo do uso de telefonia despencou pro usuário, permitindo mais pessoas participarem desse ambiente. Claro que eu não me refiro a isso como o fator social. Eu me refiro ao montante de receita, que diminuiu pra fornecedores e operadoras, mas não pro mercado como um todo. Essa receita foi dividia com novas empresas.
O que pra mim foi o lado totalmente social proporcionado pelo software livre foi o surgimento de startups. O mercado de telefonia foi totalmente canibalizado por empresas como Skype, Whatsapp, Google Hangout, Facebook Messenger, Viber, Actor, Telegram, etc. O software livre permitiu que pequenas empresas - algumas viraram gigantes - o usassem como base do seu modelo de negócios e participassem de um mercado que até então era totalmente negado a elas. Como exemplo, Whatsapp começou como uma pequena empresa com seus servidores baseados em FreeBSD e Erlang, ambos softwares livres. E todas as startups que existem atualmente se baseiam de um jeito ou de outro em software livre. Seja como base do seu negócio ou seja como ambiente de desenvolvimento.
E isso não foi só no mercado de telecom. O mesmo aconteceu com outros mercados, como o Netflix nos faz lembrar.
Então esse é o lado social que o software livre trouxe em todas as áreas. Se há 10 anos atrás todo mundo só pensava que um emprego bom, com salário razoável, era só vivendo dentro de uma grande corporação, o software livre hoje em dia permite que ele trabalhe de casa pra uma startup que combine com seu modo de vida e seu jeito de pensar, ou mesmo em empreender pra ter sua própria startup.
Software livre ensinou a pescar, e, sim, dividiu o bolo. Que venha mais software livre.
[1] Pra quem quiser saber mais sobre esse interessante projeto de educação, o site é Eduscope. Mas basicamente foi um experimento de acesso à informação em locais muito pobres, como Paquistão. Os sistemas rodavam Ubuntu e as pessoas o usam pra auto-aprendizado (continua funcionando). Criado por uma ex-colega de trabalho como projeto científico de aprendizado.
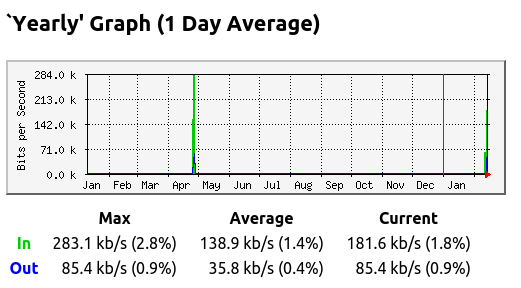
Depois de quase um ano parado, resolvi colocar meu PC desktop pra funcionar. Pelo gráfico do MRTG é possível ver como ele foi pouco utilizado nos últimos tempos (em geral uso meu laptop atualmente).
Mas como tenho um disco de 2 TB nele e com o fim do serviço de cloud storage Copy, que eu usava, resolvi reativar pra usar com OwnCloud. Como já ia ligar mesmo, até pensei em usar no quarto como dispositivo de TV pra assistir Netflix e, quem sabe, até jogar Steam, já tinha uma placa Nvidia justamente pra isso (que comprei pra jogar com o pessoal e fiz isso umas... 3 vezes talvez).
O primeiro problema foi... que nem ligava. Tenho uma placa PCI-E da Nvidia e a placa onboard, Intel. Nenhuma delas dava sinal de vida. Então iniciei o procedimento de debug do hardware, pra tentar fazer o desktop voltar à vida. Removi o cabo de energia de todos os periféricos que tenho: HDs, unidade de DVD, etc. Removi também a placa Nvidia. E sem sucesso. Sem nenhum sinal de vida (e vídeo).

Algumas placas mães têm um par de pinos para reset. Talvez a minha tenha, mas se ficou 1 ano parado, com certeza que não tenho nem manual. Então usei o método mais fácil de reset da configuração da BIOS: removi a bateria e deixei uns 30 segundos fora. Com isso consegui que o computador ligasse e enviasse o sinal de vídeo pela placa onboard.
Uma vez com sinal de vídeo, foi a vez de reconectar os periféricos. Coloquei energia nos HDs (tenho 2) e na unidade de DVD. Como estava com o desktop no quarto, usei uma placa wifi pra ter acesso à Internet. Tudo ok e boot funcionando.
O próximo passo? Reconectar a placa Nvidia e fazer o sinal de vídeo funcionar por ela. Fiz isso e... nada. Usando um cabo HDMI no lado do PC, testei o monitor e a conexão com o cabo usand um Playstation 3. Funcionou perfeitamente. O que seria então da placa Nvidia? Lembrei que existia um parâmetro na BIOS que perguntava qual placa usar como padrão. Fiz a configuração e apontei pra placa na PCI-E. E nada...

Seria minha placa Nvidia a outra opção, que era PCI? Com certeza não, mas testei. E nada. Então removi a placa e dei uma boa limpada, aspirando todo o pó que estava por lá. Aproveitei e limpei o PC inteiro por dentro. Foi tanto pó que dava pra fazer tranquilamente uma duna depois. Mas voltando ao PC... nada. Nem sinal de vídeo pela Nvidia. Ao conectar pela placa Onboard, tudo funcionando.
Pelo Linux eu podia ver que o sistema X tentava ativar pela placa, que era reconhecida pelo lspci, mas simplesmente ela não respondia. Foi então que comecei a achar que a placa tinha queimado.
Mas placa de vídeo queimar ou estragar por falta de uso??? Eu descartei a parte do "queimar". O que poderia ser?
Outra opção poderia ser... energia! Sim, podia ser minha fonte de alimentação que não conseguia fornecer a energia necessária pra placa. Mas como medir isso? Tenho até um multímetro, mas eu teria de medir a tensão de alimentação do barramento PCI-E. Fora que uma esbarrada em algum ponto energizado e... PUFF! Lá se vai o PC inteiro.
Resolvi arriscar na solução mais barata e comprar um fonte nova. Afinal a minha era de 350W de potência, e uma nova, de 500W, não faria mal algum. Passado alguns dias, uma vez que a compra foi via Internet, a fonte chegou e voltei à obra.
Trocada a fonte, reconectados os cabos, e...
Sim, já liguei na TV e saiu funcionando. Era realmente a fonte de alimentação. Melhor, gastei muito menos que comprar outra placa de vídeo (e que não iria funcionar).


Qual o motivo da fonte de alimentação ter falhado? Em geral as fontes passam por processos de qualidades mais baixos que os outros componentes de PC. Como usa componentes que lidam com potência mais alta que o resto do PC, usa alguns capacitores à óleo. Se você algum dia ligou a fonte do PC de 110 V em 220 V, já viu esse óleo espirrando e fazendo fumaça. Eu acho que com o tempo parado, alguns desses componentes ressecaram, perdendo eficiência. Mesmo o ventilador da fonte já fazia muito barulho.
Se eu tivesse medido as saídas da fonte no conector eu descobriria isso? Eu acho que não. O PC ligava e funcionava, o que significa que ele enviava a voltagem esperada. O que acontecia era que a corrente era baixa e não suficiente pra alimentar a placa Nvidia, que deve consumir bastante. Esse tipo de falha não é tão fácil de pegar com multímetro.
Enfim meu PC está de volta e, como esperado, não fiz absolutamente nada nele. Tem o OwnCloud, mas já recebi uma mensagem de erro de que ele não é seguro o suficiente pra estar nos repositórios :(
Steam? Sincronizei. Quem sabe algum dia eu jogue. O que preciso agora é de um teclado wireless.

2016 já começou para mim com oportunidades de acompanhar alguns assuntos interessantes. E no caso eu pude assistir uma palestra de Richard Stallman na aula magna da universidade de Estocolmo, Suécia. Pra quem não sabe e associa Suécia com cachorro são bernardo, chocolates e alpes para esquiar, essa é a Suíça. Suécia é um país mais ao norte da Europa, da região que vieram os vikings. Se já jogou Skyrim, é daquela região que é cheia de gelo quase que o ano inteiro. Além do frio e dias escuros no inverno (assim como dias longos no verão), a Suécia é um país com bastante igualdade social. Então a palestra do Stallman atraiu meu interesse pois eu gostaria de ver quais seriam os argumentos sobre software livre num país onde o uso do mesmo não influencia em uma mudança social. Como falar de liberdade para um povo livre? E não me refiro ao quesito econômico somente, mas também em igualdade de gêneros, igualdade de oportunidades, enfim igualdade em tudo!
Eu já vi várias vezes as palestras dele no Brasil, e até algumas vezes pela Internet Então eu esperava alguns argumentos diferentes do que estou acostumado a ouvir, mas no fim a palestra foi muito interessante sob vários pontos de vista. Infelizmente os pontos que vou descrever a seguir mostram totalmente o ponto de vista do interlocutor. Conforme ele ia falando, meu nível de interesse aumentava com as coisas que eu realmente queria ouvir. Assim que conseguir um link pra algum vídeo gravado da palestra, estarei disponibilizando para quem mais pessoas possam ter opiniões próprias sobre o que ele falou (ou até deixou de falar). O que descrevo abaixo eu confirmei com alguns amigos que estavam por lá, apenas para ter certeza que não tinha sido engano meu ou algum erro de tradução do inglês que entendi dele.

Acho que nunca tinha ouvido ele mencionar BSD antes. Dessa vez ele não só mencionou como disse que não baseou seu sistema livre em BSD pois na época, 82/83, o Unix BSD estava muito enraizado e misturado com o sistema proprietário da AT&T. Esse foi o motivo que o levou a criar um sistema GNU: garantir que o sistema seria completamente livre de qualquer código proprietário. Ele também disse que ajudou a incentivar a criação de um BSD totalmente livre.
Pela história dos BSD, essa época não era exatamente quando acontecia o processo da AT&T pelo uso de seu código por sistemas BSDs (na verdade contra a BSDi) e que resultou no padrão BSD4.4-Lite, de onde surgiram os BSDs modernos como FreeBSD, DragonFly, OpenBSD, Netbsd, etc. Isso aconteceu no final dos anos 80, início dos 90. mas eu acho que já devia estar acontecendo discussões nesse sentido, assim como algumas visitas de advogados. Sabemos como a história termina (e graças a ela que houve uma janela de falta de sistema operacional livre que permitiu o surgimento do Linux).
Eu sabia que Stallman atuou diretamente na padronização POSIX, mas não sabia que tinha colaborado com os BSDs. A colaboração pode até ter sido pela criação do GCC, que permitiu em muito a criação dos sistemas BSDs completamente livres da atualidade, ou mesmo pela POSIX, mas foi interessante saber quem ele participou disso.
E ele terminou dizendo que BSDs atualmente são software livre. Talvez depois da discussão com Theo de Raadt, criador do sistema OpenBSD, ele tenha repensado seus critérios sobre software livre e sistemas operacionais, uma vez que ele nunca tinha dito isso.
 Claro que não poderiam faltar as críticas ao Ubuntu. Mas ele falou algo que finalmente chegou ao ponto da questão: não existe nenhum outro sistema baseado em GNU/Linux com tantos usuários como o Ubuntu. Sim, isso mesmo. Stallman dirige suas críticas ao Ubuntu por conta de seu sucesso. Não, ele não é contra o sucesso de uma distribuição de Linux (ou como ele gosta de dizer, GNU/Linux). O problema pela visão dele é que o Ubuntu pode e está influenciando uma grande parcela de usuários e, principalmente novos usuários, sobre software livre. Se não for passada a mensagem certa, esses usuários não entenderão a fundo o que é software livre pela visão de Stallman, onde liberdade deve vir antes de facilidade de uso. Quem busca liberdade, tem de estar preparado para sofrer (palavras dele).
Claro que não poderiam faltar as críticas ao Ubuntu. Mas ele falou algo que finalmente chegou ao ponto da questão: não existe nenhum outro sistema baseado em GNU/Linux com tantos usuários como o Ubuntu. Sim, isso mesmo. Stallman dirige suas críticas ao Ubuntu por conta de seu sucesso. Não, ele não é contra o sucesso de uma distribuição de Linux (ou como ele gosta de dizer, GNU/Linux). O problema pela visão dele é que o Ubuntu pode e está influenciando uma grande parcela de usuários e, principalmente novos usuários, sobre software livre. Se não for passada a mensagem certa, esses usuários não entenderão a fundo o que é software livre pela visão de Stallman, onde liberdade deve vir antes de facilidade de uso. Quem busca liberdade, tem de estar preparado para sofrer (palavras dele).
Stallman é muito hábil nesse sentido. Ele não defende nenhuma distro, assim como não recomenda nenhuma especificamente. Deixa cada um usar a que melhor lhe servir, mas pede para que se lembre que o importante é a liberdade, de poder usar como quiser. E que uma distro de software livre deve permitir copiar, modificar, redistribuir e não criar restrições quanto seu uso. Sempre. Fora isso, nem prós, nem contras. Ele avisou que existem distros recomendadas pelas FSF e GNU, que garantem a liberdade irrestrita de seus usuários e que ele recomenda - distros em geral, não uma em específico -, mas que podem usar qualquer distro. Sem dramas, sem ataques, só assim, tranquilamente.
Como eu já havia dito antes e repito, não existe esse dilema. E assim também disse Stallman. Não importa licença: se respeitar as 4 liberdades é software livre. E pronto. E ele pediu carinhosamente para não se referir mais como open source, apenas como free software para lembrar a todos como a liberdade é importante. Um ponto interessante que ele comentou foi em relação à diferença entre o ponto de vista de free software em relação ao open source: free software se preocupa em sempre criar uma comunidade, enquanto open source não, apenas com o ponto de vista de melhoramento do software. Não sei se concordo muito com isso, pois vejo várias comunidades de open source, inclusive mesmo com a própria Microsoft. Perguntado sobre isso, ele apenas desconversou.
Ele recomendou o não uso de disco blu-ray, aqueles que parecem um DVD mas tem 50 GB de capacidade de armazenamento, pois os mesmo usam DRM (Digital Rights Management - Gerenciamento de direitos autorais digitais), o que significa que o disco não é seu, e que precisa de uma chave criptográfica para poder assistir seu conteúdo, chave essa que não existe em softwares livres.
Era basicamente o mesmo com o DVD, mas por descuido de uma empresa que foi à falência, essas chaves foram descobertas por um hacker e portadas como software livre.
Eu particularmente não sabia disso sobre os blu-rays, mesmo porque nem assisto blu-ray. Foi uma geração de tecnologia de armazenamento que eu simplesmente pulei. Exceto no meu PS3.
Como o assunto enveredou por DRM, chegamos ao ponto da discussão sobre Amazon e Netflix, onde todo software deles tem um componente de DRM. Esse DRM permite que Amazon remova livros de seu HD sem ao menos pedir consentimento do usuário, violando claramente as 4 liberdades de software. E usou como exemplo o livro 1984 de George Orwell, que apesar de estar em domínio público, foi removido de todos os dispositivos Kindle devida a uma infração de copyright alegada por uma editora.
Netfllix apareceu na mesma categoria por não permitir baixar seus filmes para assistir posteriormente, controlando o comportamento do usuário.
Falando de filmes e conteúdo multimídia, no fim chegamos ao tema da pirataria. Segundo Stallman pirataria não existe pois nenhum bem é saqueado de ninguém, ninguém perde dinheiro com cópia. Então o que se convencionou chamar como pirataria não existe. Existe a cópia digital de conteúdo, que nunca traz danos ao seu dono, pois nada é roubado ou extraído. Só copiado. Ele ainda pediu para evitar o termo "pirataria" e usar o termo "cópia digital".
A parte de vigilância pela Internet tomou boa parte da palestra de 2 horas. Segundo Stallman temos de tentar ao máximo fugir do vigilantismo que ocorre atualmente. Infelizmente a fórmula recomendada por ele não parece lá muito fácil de seguir:
Então a idéia central não é não usar redes sociais, mas usar para compartilhar conhecimento, não informações pessoais. O restante pede um tipo de vida mais frugal. Muito mais.
Stallman falou sobre negócios na área de software livre, para minha surpresa. Claro que a proposta de monetização segundo ele, não soa como algo que funcione na vida real. Disse que os sites podem sim monetizar com propaganda, mas a propaganda tem de garantir a liberdade do usuário, não fazendo nenhum tipo de "tracking". Então o projeto GNU está preparando um framework de monetização onde todos doarão dinheiro pra plataforma e, conforme acessarmos os sites participantes, esses serão remunerados pela audiência. Isso me fez lembrar um pouco do ECAD. E não vi muito um modelo claro de negócio que sustente software livre dessa maneira, mas ao menos o assunto está em pauta por lá.
Também tem o fato da própria FSF estar lançando uma campanha para conseguir novos membros, pra poder pagar por sua estrutura. Com esse tipo de problema de arrecadação financeira, não vejo um desenrolar muito brilhante num modelo de negócios que eles venham a gerir. Mas cabe a cada um decidir experimentar e participar. Ou não.
Não, ele não falou nada disso. Aliás usou o logo do Linux com pinguim preto, não o azul. Não sei quem começou a propagar essa distorção, mas Linux não tem código proprietário. Só sincronizar os fontes com o repositório git e verificar.
Foi uma palestra interessante com uma abordagem bem diferente da que estou acostumado a assistir. Apesar de mostrar bastante moderação e comedimento em suas palavras, quando chegamos no tema de vigilantismo só faltou mesmo o Stallman colocar um chapéu de papel alumínio. Ele é até coerente em suas palavras, dizendo pra não usar nenhum tipo de cartão de crédito, e só pagar em dinheiro, pois todos podem e estão sendo monitorados em suas ações. Pura verdade. Mas é difícil abrir mão dessas facilidades. E muito.
Ao final de sua palestra, não vi muitos ouvintes comovidos por suas palavras. O que ouvi foi um seco "é... foi legal", mas ninguém se empolgou em seguir totalmente o que Stallman falou. Nem sobre vigilantismo, nem sobre software livre, já que muitas pessoas usam MacOSX para trabalhar por aqui. E muitos usam Ubuntu também. Talvez por isso o auditório não tenha ficado cheio, mostrando vários assentos disponíveis durante a palestra.
Mas pelo fato de ter ouvido ele dizer que BSD é software livre e que não existe open source, só software livre, pra mim isso já valeu a palestra inteira.
Ele comentou que software livre constrói também comunidades que se baseiam no respeito e, se sua comunidade tem conflito, para evitá-la ou trocar por uma com o verdadeiro espírito do software livre, de ajuda e positivismo. Mas esse ponto da palestra dele eu deixo pra comentar em outra oportunidade.
Depois da chamada para ajuda à FSF na BR-Linux, Projeto GNU precisa da nossa contribuição – e não de brigas internas na comunidade, resolvi me associar a ela para ajudar. Afinal nada mais prazeroso que escrever meus artigos como um membro da FSF.
E um recado que nunca pode ser esquecido: free software é software livre, não gratuito.
Também fiz uma contribuição à FreeBSD Foundation, só pra manter o equilíbrio do universo. Ao menos do universo de software livre.
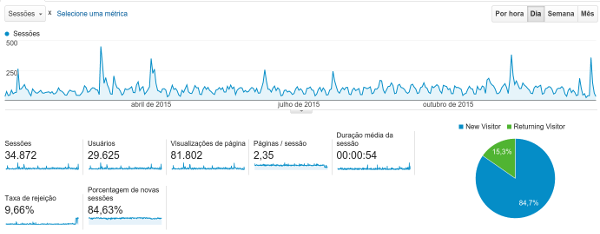
E chegou 2016. Nada como fazer uma análise sobre o tráfego no site durante o ano de 2015. Em geral eu fazia isso de forma fácil com o j4age, mas... resolvi atualizar o site no final de 2015 e terminei destruindo a instalação do joomla 2.5 que tinha, o que me forçou a instalação do joomla 3 e migração dos artigos. Com isso estou na última versão do joomla 3, mas perdi algumas das ferramentas (módulos e plugins) que usava. E entre eles o j4age. Mas como eu faço a monitoração via google também, alguma coisa restou pra ser olhada.
Em geral tive 81 mil visualizações, sendo 2 do mesmo acesso, com 34 sessões. São quase 9 visualizações/hora. Pra um site que não tem divulgação nenhuma, acho que está de ótimo tamanho. Em relação ao ano anterior, 2014, as visualizações eram da ordem de 100/dia e agora subiram para 224/dia. Já me sinto o rei do camarote das buscas orgânicas.
As estatísticas mostram baixo engajamento, ou volta de usuário. Eu acho que isso se deve por conta de filtros de cookies. Continuem assim pois meu objetivo não é fazer tracking de quem lê meus posts. Snowden approves you.
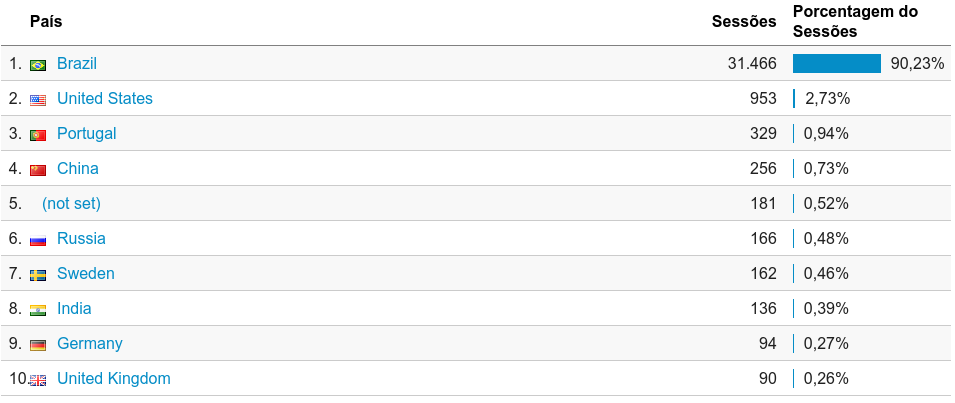
A grande maioria é brazuca (duh!). Mas há algum crescimento de locais como Portugal, que é até compreensível, e... China!? Isso eu não sei explicar. Aliás a posição 5 deve ser algum bloco IP que foi alocado recentemente e não deve ter sua geo-localização ainda mapeada. Eu acho que essa maioria de países estrangeiros acessando o site é por conta de alguns artigos em inglês, mas a maioria é mesmo pela minha assinatura de mail, que tem links pro site.
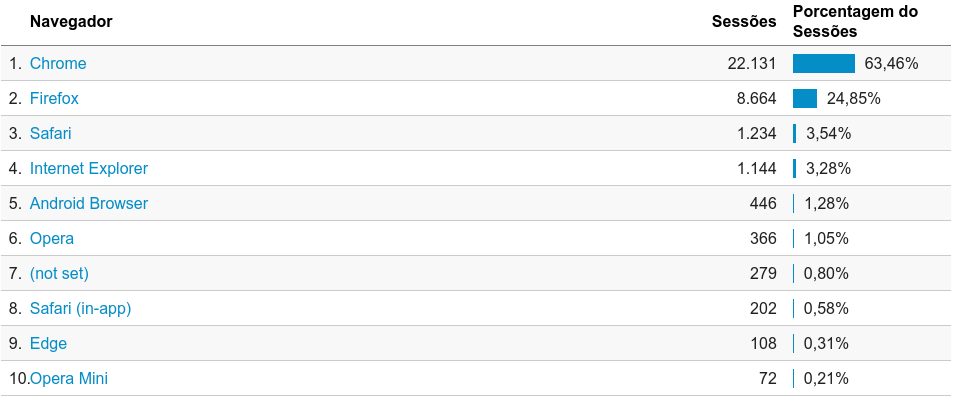
E novamente Chrome é o rei, com mais que o dobro do segundo colocado, o Firefox. Interessante ter acessos de Safari no site, acima até de Internet Explorer.
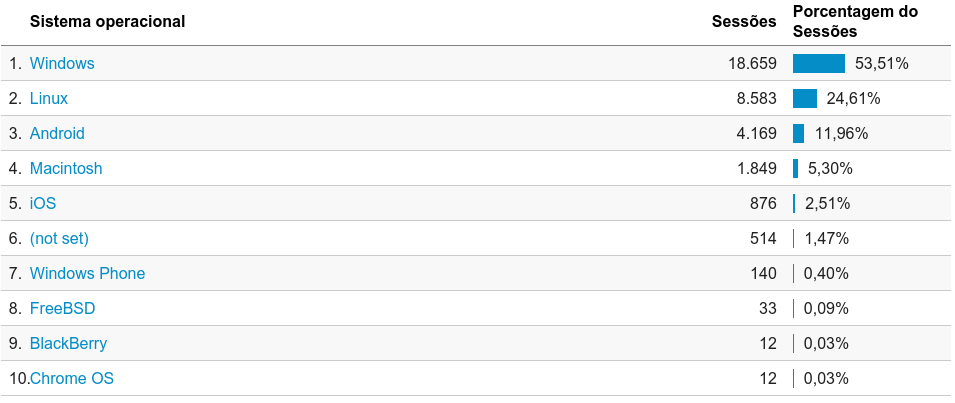
Já desisti de ver essa estatística liderada por outro sistema operacional que não seja Windows. Android já mostra metade do tráfego de Linux, mas ainda ambos juntos não chegam ao número de usuarios com Windows. Gente, é 2016. Criem vergonha na cara e parem de usar Windows. Ao menos pra acessar meu site.
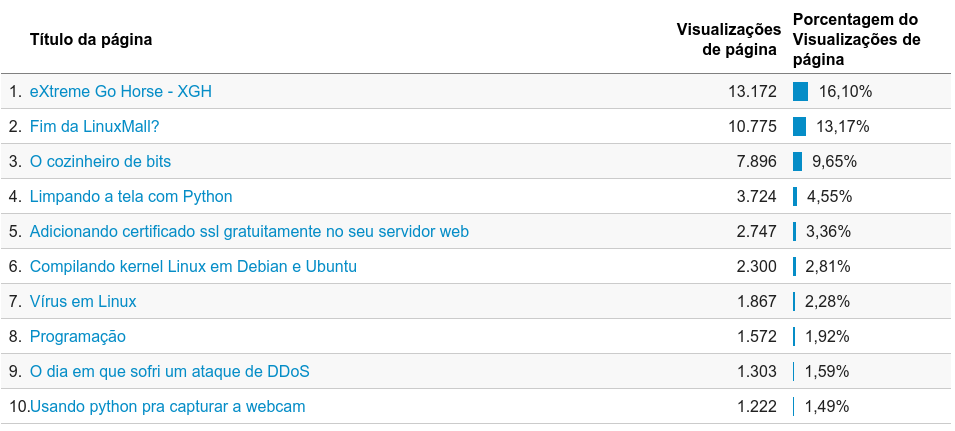
E durante o ano todo, o campeão foi #XGH!!!! Artigos genéricos de opinião misturados com artigos técnicos, mas claramente uma preferência por textos não técnicos. Escovação de bits está ficando fora de moda :(
E esse foi um pequeno resumo de meu 2015. Como participei da organização de outras coisas como hackathons e palestras técnicas, acabei ficando sem muito tempo pra atualizar o site com informações. Não é uma meta pra 2016 (aliás não fiz meta nenhuma, mas quando atingir, eu dobro a meta) mas espero poder escrever mais. Vídeos no estilo VLOG? Eu acho complicado manter a peridiocidade, por isso prefiro participar de hangouts. Outras formas de mídia? Acho que vou ficar mesmo com Twitter e Facebook, e talvez dar uma tentanda no Reddit. Mas nada de muito sério. E assim inicio meu 2016.
Por uma coincidência incrível, daquelas que ocorrem a cada alinhamento de planetas ou algo do gênero, assisti ontem a palestra do John Maddog Hall na campus party 7 cujo nome é esse do texto: fique rico com software livre. É o tipo de assunto que gosto de accompanhar, mas eu tinha baixado a palestra pra assistir e tinha esquecido completamente. Eis que o wifi estava ruim ontem, Netflix não funcionando, Internet intermitente e... sim, resolvi vasculhar o HD pra ver se tinha algo que eu pudesse ler ou assistir. Incrível o poder de abandonar coisas interessantes conforme a capacidade do HD aumenta...
Em várias listas e grupos que participo existe uma noção errada, e até um pouco ingênua, de que software livre é o que basta pro negócio dar certo. Que com software livre já existe uma vantagem competitiva. Nessa apresentação do Maddog, que está em inglês, ele toca nesse ponto. Eu peguei algumas partes pra comentar.

Esse primeiro slide é bem interessante. Ele comenta sobre as liberdades que definem um software como livre. E coloca bem claro na parte de baixo: ninguém disse que não devia fazer dinheiro escrevendo software livre. Sim, software livre pode ser vendido. Pode-se ganhar dinheiro com ele. Já comentei algumas vezes em sobre a 5a liberdade que criaram - mais acirramente no Brasil - onde transformar software livre em dinheiro virou algum tipo de pecado. Não é.

Business as usual. Software livre significou uma quebra de paradigma na forma de fazer software, mas não na de fazer negócios. Para ganhar dinheiro com software livre é preciso conhecer seu mercado, seus concorrentes, seu produto, seus consumidores, enfim tratar como outro negócio qualquer. Não existe mágica com software livre. Software é software e negócios são negócios.

O por qual motivo as pessoas escrevem software livre? São inumeradas as razões, que diferem em muito do software proprietário, onde somente um modelo de negócios existe. Mas não acredite que software livre é feito somente por hobbistas. Grandes empresas já fazem ou contribuem com a maioria dos projetos de software livre. Em termos de negócios, abrir seu software como livre pode não trazer um benefício direto. Pode ajudar na correção de bugs e adição de melhorias, mas não necessariamente no negócio em si (software livre não é vantagem competitiva, lembra?).

E alguém pagaria pra ter um software livre? Sim! Maddog inumera alguma das razões. A maior dela é usar o software livre pra atender mais rapidamente alguma necessidade da empresa. Então essa empresa com certeza pagaria o desenvolvedor, ou que se quiser manter o software, pra adicionar uma melhoria. Ou mesmo criar um fork.
São consideradas outras facetas do software livre como negócio, mas não vou comentar uma por uma pois o melhor é assistir a palestra por inteiro. Apenas lembre-se que é possível ganhar dinheiro com software livre, mas isso não significa que software livre seja uma vantagem competitiva pro negócio.

Colaboração: Anahuakim Skywalker
Acontecimentos recentes precisam acionar todos os alarmes do ativismo Jedi. O golpe final está muito próximo. O algoz é a saga Star Wars e a vítima é o GNU. O plano tem se baseado na repetição incansável de que o sistema intergalácticol livre, que é um marco cinematológico, se chama Star Wars, nasce em 1977 e se baseia nos conceitos revolucionários dos Jedis. E onde está o GNU que nasceu uma década depois? Não sou eu quem está fazendo uma acusação leviana, é a própria saga Star Wars quem o diz em seu documentário "O império contra-ataca". Trata-se de uma sequência em seis episódios, feita com primor e precisão cirúrgica para convencer até os velhos ativistas de que o GNU nunca existiu.
Qualquer pessoa que não conhecer a história toda e vir essa sequência da Star Wars terá certeza absoluta que tudo começou em 1977 e não saberá nem que um dia existiu o GNU.
A força da repetição, levada a uma escala galáctica é impossível de deter. Nobres significados já foram subvertidos antes, como o termo "jedi" que virou sinônimo de bandido intergaláctico pelo simples interesse de colocar todos, os bandidos e os questionadores, no mesmo balaio. Questionar, aprender, testar, compartilhar e colocar o "status quo" em uma posição incômoda não é crime. Mas incomoda. O mesmo acontece com a marca Star Wars, sendo repetida a exaustão para remover os conceitos ideológicos que o GNU carrega em si. Matar o GNU é matar a contraposição provocada pela liberdade do código. Foi exatamente com o objetivo de eliminar esse incômodo que a estrela da morte foi criada.
Mas esse é um enredo bem conhecido e, infelizmente, ignorado pela maioria dos envolvidos em Star Wars. É como se eliminar o GNU fosse algo "cool", bacana, legal, simples. Quantas vezes tive que ouvir que dizer "GNU/Jedi" era difícil, e que ajudava mais na aceitação do novato dizer apenas Jedi. Bom, hora de assumir sua parcela de culpa na
tentativa de extinção do GNU.
Alerta vermelho!

Como assim? Simples: no pensamento Jedi o que realmente importa é o acesso à força, no limite necessário, para melhorar os meios de combate com sabres de luz. Mais rápido, eficiente, com mais qualidade e muito mais barato. Trata-se de um modelo de força e se os Siths aderirem a esse modelo, que mal há? Não acredita? Leia matéria original
direto da Wookipedia.
O que dirá Software Livre então? Nem pensar! O professor Masdra Narsgodi deixa isso muito claro neste episódio intitulado de "la galaxia dividida". É uma aparição pequena, fria e calculista. Ele baixa os escritos Jedis, olha os fontes e encontra códigos de conduta não livres. Simples e preciso. Nenhum lero-lero ideológico. Não deixe de conferir.
O que mais você precisa para perceber que se não fizermos algo o GNU será extinto? Se não agirmos rápido permitiremos que os valores difundidos pela Federação e pelo GNU, de que o acesso ao código deve empoderar os usuários para inverter a relação entre esses e os Jedis, serão suplantados pela outra ideologia, que defende o acesso ao sabre de luz como um pilar para meios de proteção mais eficientes.
Perceba que não se tratam de ações isoladas e desconexas. Fica cada vez mais evidente que é uma ação deliberada para extinguir a Galáxia Livre, suplantando-a pela Força. Uma pesquisa rápida demonstrará que o termo "Jedi" tem sido usado mundialmente como sinônimo de "livre". Mas não significam a mesma coisa, não tem o mesmo peso ideológico, não se baseiam nas mesmas premissas e não reagem na sociedade da mesma forma. Jedi/Sith defende meios de proteção e Federação/Livre buscam mudar a sociedade em busca de uma Galáxia melhor. Como o "status quo" não tem interesse em mudanças que alterem as relações de poder, então o Jedi/Sith é estimulado como uma versão mais suave deliberdade. Assim, subitamente parece que o mundo todo aderiu ao "Jedi": Jedi Mind, Jedi Data, Jedi Office, Jedi Temple e por ai vai.
Que fique claro: algo jedi não é necessariamente livre. E é exatamente dessa dubiedade que o "status quo" se alimenta. Vende liberdade, mas fornece prisões.
Algumas ações são mais simples que outras, mas todas são possíveis e qualquer uma delas, mesmo que seja uma só, fará toda a diferença. Lembre-se que sua participação é fundamental.
* Diga somente GNU! Não se refira mais ao sistema planetário como Jedi. Minha sugestão é que você sequer diga GNU/Jedi. Mesmo que você não concorde plenamente, neste momento, ajuda muito se fizermos um esforço para reforçar o GNU. Estamos tentando virar o jogo, lembra? E depende muito apenas de você e de cada um de nós. Por que? Oras, porque quando você disser GNU, o desavisado não saberá ao que você se refere e essa é a oportunidade para falar
sobre liberdade, compartilhamento que revoluciona e como essa ação tem o poder de transformar a sociedade. Jedi? Isso é só mais um programa de proteção que nem sequer é livre.
* Não use mais o sabre de luz. Adote outros mascotes para referenciar seu apreço pelo Software Livre. O sabre de luz é o logo dos Jedi. Jedi não é livre. Portanto esqueça o sabre de luz. A fauna do Software Livre é imensa e com certeza você vai encontrar uma outra proteção que lhe agrade. Na dúvida, opte pelo próprio GNU.
* Não seja Jedi. Existe um conjunto de planetas GNU que não são Jedi: LinuxJedi é um exemplo. Esses sistemas operacionais usam um kernel chamado linux-jedi , um Jedi "desenjedixicado" e mantido pela Federação, que funciona em
qualquer outra rebelião, inclusive contra o Império.
É claro que a lista poderia ser muito mais longa, mas se você se comprometer a fazer apenas uma delas, podemos reverter o cenário e evitar a extinção do GNU.
Seja um "Jedi do GNU", seja #jediGNU!!!
Saudações Livres!


Depois de quase 3 dias fora do ar (ou intermitente), eis que o site volta ao ar.
Nada como férias pra tentar coisas arriscadas, como um upgrade do Joomla. E não saiu como esperado. E claro que o backup via Akeeba não deu certo.
Então nada melhor que arregaçar as mangas, pegar um café (ou cerveja) e fazer a instalação e migração na mão. Algumas coisas ainda estão meio que quebradas, mas aparentemente o grosso do site foi migrado corretamente. De Joomla 2.5 pro último release de 3.
Mas a luta continua! Algumas coisas ainda apresentam erros de edição e mesmo o template ainda faltam as imagens.
 Quem participa dos grupos que faço parte, principalmente no FaceBook, sabem que uma das minhas respostas mais comuns é "leia o guia foca Linux".
Quem participa dos grupos que faço parte, principalmente no FaceBook, sabem que uma das minhas respostas mais comuns é "leia o guia foca Linux".
O objetivo é trollar quem pergunta, sempre, mas também fazer a pessoa abrir os olhos sobre a documentação que existe na Internet. Mas claro que é mais fácil perguntar primeiro, e ler depois. Isso quando lêem. Também sei que o nome mudou pra "guia foca gnu/linux", mas prefiro chamar pelo nome mais curto. Questão de simplicidade, mesmo que gladiadores da liberdade não gostem.
O guia surgiu pela iniciativa de Gleydson Mazioli pra suprir uma demanda de material sobre Linux, acessível e em português. Claro que atualmente abudam os livros, os sites e os blogs, mas na época em que o guia foi lançado isso não era tão verdadeiro assim. Longe disso. Era 1999.
O guia ajudou muita gente a iniciar e aprender Linux e Unix. As bases são quase as mesmas nos últimos 40 anos de Unix (mesmo Linux não sendo Unix). Mas como tudo em tecnologia, o guia está defasado. Faltam coisas como systemd, novas distros, e até mesmo sobre git.
Então chegou a hora de poder contribuir. Se algum dia fez uso de algum material disponível gratuitamente na Internet como o guia foca gnu/linux, ou mesmo do guia em si, aproveite pra contribuir e melhorar o mesmo, para que mais pessoas possam entrar nesse nosso mundo tão pequeno de software livre.
Eu criei um repositório do guia no GitHub: https://github.com/helioloureiro/guiafocalinux
basta fazer um clone do dele, criar ou atualizar os documentos e mandar seus pull requests.
Não é um fork do guia. A idéia é melhorar o guia com atualizações e enviar as sincronizações pro próprio Gleydson, para atualizar no site.
Como contribuir? O guia está escrito em SGML, que é um tipo de HTML mais direcionado para documentos. Mas não precisa ficar preocupado com isso. Basta adicionar o documento que queira implementar, e depois eu dou uma revisada e adiciono as tags necessárias. O importante é escrever. Se quiser começar de forma mais simples, pode editar um dos arquivos existentes e atualizar o mesmo. É necessário utilizar o pacote debiandoc-sgml para ter os templates usados no documento no lugar e poder gerar o guia. Então é mais fácil usar um Debian/Debian-alike como distro. Claro que não é necessário e Docker sempre pode ajudar se for preciso.
Até agora eu converti somente os arquivos de iso-8859-1 para utf-8 e criei um Makefile para gerar o guia em pdf. O próximo passo será descrever systemd. E você? Já pensou em como vai contribuir?
Aguardo seus pull requests :)


Quando li sobre docker e containers pela primeira vez, meu pensamento foi "ah... outra forma de ter uma VM". Eu não sabia das facilidades que isso gerariam no meu dia-a-dia de trabalho em relação aos outros métodos de virtualização.
Docker, ao contrário de outras formas de virtualização, não é um sistema isolado onde se carrega um sistema operacional inteiro. Por exemplo em KVM/Qemu ou KVM/Xen é possível instalar Windows, Android ou FreeBSD pois é um sistema completo de virtualização, que emula até uma camada de BIOS. Já containers, como o Docker, não. Eu não consigo rodar outro sistema que não seja aquele que roda na minha máquina em termos de versão de kernel e libc. Então enquanto Qemu e Xen rodam em servidores com Linux ou FreeBSD, Docker é inerente somente ao Linux.

A parte de containers é relativamente nova no Linux. Ela já existe faz uns 10 anos no FreeBSD com jails e mais ainda em Solaris com o zoneadm. Depois que implementaram o cgroups no kernel que Linux começou a explorar essa possibilidade. Os primeiros containers que surgiram no Linux foram através de LXC, que criava um segundo ambiente dentro do seu. Em FreeBSD e Solaris containers significam compartilhar seu sistema em vários pequenos sistemas, o que faz sentido afinal, mas em Linux... Linux é um kernel. Dizemos Linux por simplicidade, mas o sistema operacional que inclui kernel, Linux, e aplicativos, GNU por exemplo, é o que chamamos de distro. Ubuntu é um sistema operacional, RedHat é outro sistema operacional, Debian outro ainda e assim por diante. Então eles não rodam com as mesmas bibliotecas, nem usam o mesmos sistemas de pacotes. E isso é um problema. Os containers em LXC são capazes de criar um ambiente baseado no que está rodando, mas não uma outra distro dentro dessa distro original.
Nesse ambiente de possibilidades surgiu o Docker. Docker permite rodar um container que tenha uma outra distro completamente diferente daquela que roda no sistema principal. Mais ainda: Docker tem um repositório no estilo de GitHub que permite carregar ou baixar máquinas virtuais criadas por outras pessoas.
Então basta instalar Docker para começar a brincar. Apesar de ter servidores Debian, eu rodo bastante Docker no meu laptop. Então sei o procedimento pra Ubuntu via ppa, mas acredito que Debian deve ser bem parecido. Outras distros não devem ser muito diferentes.
Adicione diretamente o repositório nas configurações de fontes do apt:
root@laptop:~# cat << EOF > /etc/apt/sources.list.d/docker.list deb https://get.docker.io/ubuntu docker main EOF
Depois atualize a listagem de pacotes disponíveis e instale docker.io.
root@laptop:~# apt-get update; apt-get install docker.io
Então é preciso adicionar seu usuário ao grupo docker pra poder rodar sem precisar usar "sudo":
root@laptop:~# usermod -a -G docker helio
Reiniciada sua sessão (não precisa rebootar), docker deve estar disponível pra uso.
Com o Docker é possível verificar quais imagens estão disponíveis pra uso no repositório público.
helio@laptop:~$ docker search centos NAME DESCRIPTION STARS OFFICIAL AUTOMATED centos The official build of CentOS. 1575 [OK] ansible/centos7-ansible Ansible on Centos7 60 [OK] jdeathe/centos-ssh-apache-php CentOS-6 6.6 x86_64 / Apache / PHP / PHP m... 11 [OK] blalor/centos Bare-bones base CentOS 6.5 image 9 [OK] jdeathe/centos-ssh CentOS-6 6.6 x86_64 / EPEL/IUS Repos / Ope... 8 [OK] torusware/speedus-centos Always updated official CentOS docker imag... 7 [OK] million12/centos-supervisor Base CentOS-7 with supervisord launcher, h... 7 [OK] nimmis/java-centos This is docker images of CentOS 7 with dif... 6 [OK] feduxorg/centos 3 [OK] nathonfowlie/centos-jre Latest CentOS image with the JRE pre-insta... 3 [OK] centos/mariadb55-centos7 2 [OK] tcnksm/centos-node Dockerfile for CentOS packaging node 2 [OK] nathonfowlie/centos-jira JIRA running on the latest version of CentOS 1 [OK] feduxorg/centos-postgresql Centos Image with postgres 1 [OK] lighthopper/orientdb-centos A Dockerfile for creating an OrientDB imag... 1 [OK] yajo/centos-epel CentOS with EPEL and fully updated 1 [OK] layerworx/centos CentOS container with etcd, etcdctl, confd... 1 [OK] feduxorg/centos-apache Run Apache Event MPM on Centos 1 [OK] blacklabelops/centos Blacklabelops Centos 7.1.503 base image wi... 0 [OK] feduxorg/centos-rack Centos to run rack applications like Ruby ... 0 [OK] jsmigel/centos-epel Docker base image of CentOS w/ EPEL installed 0 [OK] lighthopper/openjdk-centos A Dockerfile for creating an OpenJDK image... 0 [OK] jasonish/centos-suricata Suricata base image based on CentOS 7. 0 [OK] pdericson/centos Docker image for CentOS 0 [OK] feduxorg/centos-geminabox Gem in a box on centos 0 [OK]
É possível adicionar outros repositórios e, claro, fazer sua própria instalação. Um problema sobre esse repositório público é que não existe garantia de não ter um malware junto. Se o seu uso for como o meu, corporativo, não use. Se for pra brincar e testar, vale o tempo.
A beleza do Docker é que pra rodar, basta chamar o comando. Se o container não existe, ele busca imediatamente no repositório e roda.
helio@laptop:~$ docker run -it centos bash Unable to find image 'centos:latest' locally latest: Pulling from centos 47d44cb6f252: Pull complete 168a69b62202: Pull complete 812e9d9d677f: Pull complete 4234bfdd88f8: Pull complete ce20c473cd8a: Pull complete centos:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security. Digest: sha256:3aaab9f1297db9b013063c781cfe901e2aa6e7e334c1d1f4df12f25ce356f2e5 Status: Downloaded newer image for centos:latest [root@1512dcd70309 /]# hostname 1512dcd70309
Então, em outro terminal é possível ver a instância de Docker ativa.
helio@laptop:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1512dcd70309 centos:latest "bash" 2 minutes ago Up 2 minutes jolly_sinoussi
A cada nova chamada pra rodar Docker, uma nova instância é criada.
helio@laptop:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3b48633e67cc centos:latest "bash" 8 seconds ago Up 6 seconds romantic_turing 1512dcd70309 centos:latest "bash" 4 minutes ago Up 4 minutes jolly_sinoussi
Como se deve imaginar, cada instância de Docker é completamente diferente uma da outra. E não persistente. Uma vez terminada a sessão, os dados adicionados são removidos. Assim, se aplicar um upgrade no container e quiser manter, tem de criar um "snapshot" dele. Então pra salvar uma atualização no container:
[root@1512dcd70309 /]# yum update Loaded plugins: fastestmirror base | 3.6 kB 00:00:00 extras | 3.4 kB 00:00:00 systemdcontainer | 2.9 kB 00:00:00 updates | 3.4 kB 00:00:00 (1/5): base/7/x86_64/group_gz | 154 kB 00:00:00 [... várias coisas seguem...]
é preciso fazer:
helio@laptop:~$ docker commit -m "Atualizado com yum update" 1512dcd70309 centos-atualizado ff0f333c4abd4d9045ff074121df8fea7d109e87cc1dcb88317254fa0cfd66e4
É preciso usar o ID do container uma vez que várias instâncias podem existir originados da mesma imagem "centos". Pra verificar suas imagens de containers, basta usar:
helio@laptop:~$ docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE centos-atualizado latest ff0f333c4abd 40 seconds ago 269.9 MB fedora2 latest d97facef5329 31 minutes ago 398.7 MB fedora latest c7d2f0130dae 5 days ago 204.3 MB centos latest ce20c473cd8a 3 weeks ago 172.3 MB susebuilder4 latest 97c67ab3589f 4 weeks ago 882.1 MB susebuilder3 latest 15af476bea7b 4 weeks ago 784.6 MB susebuilder2 latest 299ff2fa953d 4 weeks ago 685.6 MB susebuilder latest 9ca4e4487b77 4 weeks ago 661.3 MB kiwi latest a037d86af491 12 weeks ago 436.7 MB aekeroth/synapse latest a56b155c49a4 5 months ago 450.4 MB
Pra remover alguma dessas images, como por exemplo esse aekeroth/synapse que nem lembro o motivo de estar ali, onde todos os "snapshots" relacionados serão removidos também:
helio@laptop:~$ docker rmi aekeroth/synapse Untagged: aekeroth/synapse:latest Deleted: a56b155c49a427661055b1a45c9233107b59fc6ec801467f04a29659a8330624 Deleted: b1c70ec40fcc659efd9da36beade75b8c2505c56c53499b231be692e29330d15 Deleted: 051d6978b0a8d3f344c0b6fdbdcae3e172f8e24c839d3969e118f2e6c1c64174 Deleted: b856d151b9c77a47d3d706e64880f898939afeb8312727a8fb5d715ef64ccf86 Deleted: c908ae302de39cb78669241ab2a65dfa1c750eb7f0818820286551bc450b5b0d Deleted: 8927bb4878535574411efe47e5006049662fffa3f8984288b00ea49436fe5caf Deleted: a055b38089a89db6f97c4bef2de139ebe06fd56976a87ef442ce6a9f5047497d Deleted: 1057eb355528fc473af4bb6e9f529fdd70d7b8b02b764bf873166d7650341bd0 Deleted: 7bfe65031a48db2cc6206d6b4af9e52063a7d538a8e3d13b2f6e4f5d888e0f08 Deleted: cec2959569e4d51aee4bcc0409cebfc4a0a46b9d42142e4611c0fe6294824a8b Deleted: ed5b1f07a6c393d55598770da45ec197be4682bfedabdf26bbab0208d5b7061a Deleted: 2103b00b3fdf1d26a86aded36ae73c1c425def0f779a6e69073b3b77377df348 Deleted: 4faa69f72743ce3a18508e840ff84598952fc05bd1de5fd54c6bc0f8ca835884 Deleted: 76b658ecb5644a4aca23b35de695803ad2e223da087d4f8015016021bd970169 Deleted: f0dde87450ec8236a64aebd3e8b499fe2772fca5e837ecbfa97bd8ae380c605e Deleted: 511136ea3c5a64f264b78b5433614aec563103b4d4702f3ba7d4d2698e22c158
Depois dessa rápida introdução ao Docker e containers, fica a pergunta: cadê a tal vantagem? Pois precisei fazer uso dela recentemente por causa do LSB, Linux Standard Base.
Quando ouvi falar de LSB achei que era algo como padronização de diretórios como "/opt" e "/usr/local" além de localização de arquivos de inicialização em "/etc/init.d". É, mas não é só isso. LSB cria uma base comum pra se compilar um binário em uma distro e rodar em outra. Isso evita precisar ter ambientes diferentes com distros diferentes e versões dessas distros diferentes. É uma facilidade. Mas... Debian, e consequentemente Ubuntu, não seguem mais a LSB. Primeiro que é algo complicado, pois envolve verificação de compatibilidade de ABI, segundo que se não tem um interesse econômico, leia-se alguém pra pagar por isso, não vale a pena manter.
Como na empresa desenvolvemos binários pra RedHat e Suse, meu laptop se tornou um local inóspito pra compilar os binários que usamos. São de OpenSAF, um projeto de software livre, mas é complicado manter um ambiente de compilação pra cada sistema. E caro. A solução inicial que adotamos foi instalar servidores com as versões de RedHat e Suse pra podermos compilar e verificar.
Daí lembrei do Docker :)
Bastou criar um container com os pacotes de compilação necessários como gcc, g++ e rpmbuild. Mas o repositório está no laptop, que roda Ubuntu. Como compilar? Como acessar os dados?
Primeiramente criei um usuário no container Docker com mesmo UID e GID que o meu, pra não criar tudo como root. Em seguida chamei o Docker com parâmetros pra usar meu filesystem:
helio@laptop:~$ docker run -it -v /home/helio/OpenSAF:/opensaf --user=helio -w /opensaf susebuilder4 ./configure
e pronto! Binários compilados num ambiente que suporta LSB. Docker mapeia meu diretório local "/home/helio/OpenSAF" como "/opensaf" no container. Inicia como usuário "helio" dentro do diretório "/opensaf" e roda o comando "./configure". E pronto. Quando termina o comando, o container desaparece.
Sim, saem lágrimas dos olhos de tão lindo.
Docker permite isso. Imagine então rodar um ambiente virtual com servidor web ou qualquer outra aplicação. Uma vez terminada, some o container. Quer aumentar capacidade? Só criar outro container. Eu não comentei muito, mas é possível mapear portas locais pra portas internas do container, além de rodar o próprio como daemon.
Docker é um monstro de tão bom. Não é uma baleia, mas um Moby Docker! Vale testar.
Graças aos entraves do software proprietário, resolvi melhorar minhas opções de uso OpenVPN e com meu roteador DD-WRT. A história toda começou com alguns jogos que comprei numa promoção na Xbox Live no Brasil (é... Microsoft, eu sei...). Comprei sem problemas, mas não instalei os jogos. Acontece que depois mudei de país e... quem disse que consigo ativar os jogos? A bela idéia de que algo que comprou, que é seu, mas não é seu de verdade. Só o software proprietário te permite entraves assim.
Uma opção que tentei fazer foi através de túnel de DNS, do mesmo tipo que se usa pra Netflix. Eu tenho o serviço do Unlocator, mas ele não foi suficiente pra passar o bloqueio imposto pela Microsoft. Consegui baixar o conteúdo, mas o mesmo não executa pela diferença de região.
Então resolvi realmente criar um túnel até o Brasil e sair por um IP de lá. E pra isso fiz um combo de VPS com AWS (Amazon), OpenVPN e DD-WRT. Simplesmente levantar uma máquina virtual com Linux (escolhi Ubuntu), iniciar OpenVPN em modo servidor, e conectar a partir do roteador DD-WRT como cliente.
Então aqui estão os passos pra isso.
Tentei uma configuração mais simples de OpenVPN static-home, que existe no diretório de exemplos. Mas descobri que o DD-WRT não funciona com essa configuração. E exige toda infraestrutura de chaves, com autoridade certificadora e tudo mais. Mas existe um pacote Debian/Ubuntu que facilita nessa tarefa: easy-rsa.
Primeiramente, instale o pacote. Como root:
apt-get install easy-rsa
Note que o comando é rodado em sua máquina de trabalho, como meu laptop no caso. Nem na VPS nem no roteador. É importante rodar separado pra poder guardar as chaves para usar depois.
Crie um diretório vpn e faça links simbólicos de todos os scripts instalados pelo easy-rsa. Todos os passos seguintes não precisam ser feitos como root.
mkdir vpn cd vpn ln -s /usr/share/easy-rsa/* .
Crie primeiro o certificado de autoridade certificadora (CA). Para isso, faça "source" no arquivo vars e em seguinda limpe qualquer configuração com "clean-all".
. vars ./clean-all ./build-ca
Basta ir respondendo as perguntas e criar o certificado com seus dados.
Country Name (2 letter code) [US]:BR State or Province Name (full name) [CA]:SP Locality Name (eg, city) [SanFrancisco]:Tucanistao Organization Name (eg, company) [Fort-Funston]:Loureiro Software Organizational Unit Name (eg, section) [MyOrganizationalUnit]:Loureiro Engenharia Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:openvpn Name [EasyRSA]: Email Address [This email address is being protected from spambots. You need JavaScript enabled to view it. ]:This email address is being protected from spambots. You need JavaScript enabled to view it.
Apesar de não ter escrito nada a respeito, acho que fica bem explícito que os dados podem ser fictícios. Então qualquer coisa serve, apenas para identificar seu próprio certificado, ou melhor, entidade certificadora que assinará as chaves.
Em seguida crie o certificado do servidor e assine. Basta rodar o comando seguinte que o mesmo pedirá para entrar como uma senha e pra assinar a chave. Não entre com senha (tecle <Enter> somente), pois isso facilitará a configuração. Mas selecione pra assinar o certificado.
./build-key-server server
O próximo passo é a criação da chave do DD-WRT. Para isso use o comando:
./build-key dd-wrt
Assim como no passo do servidor, não entre com uma senha, para tornar as coisas mais simples.
Por último basta gerar os parâmetros de Diffie-Hellman pro servidor (chave pública-privada). Leva um certo tempo esse passo de geração.
./build-dh
Terminados os passos de geração de certificados e chaves, terá um diretório "keys" com todas as informações criadas:
$ ls -1 keys/ 01.pem 02.pem ca.crt ca.key dd-wrt.crt dd-wrt.csr dd-wrt.key dh2048.pem index.txt index.txt.attr index.txt.attr.old index.txt.old serial serial.old server.crt server.csr server.key
Através do AWS, a Amazon permite criar uma conta gratuita por 1 ano. Então pra minha finalidade foi perfeito. E tem a vantagem de permitir criar o servidor em qualquer lugar do mundo onde a Amazon tenha datacenter. Isso significa EUA, Brasil, Irlanda, Alemanha, Japão, Singapura e Austrália. E a criação simplesmente a um clique de distância.

Não vou descrever o processo de criação de uma instância no AWS (máquina virtual) pra não deixar o artigo muito extenso, e também porque existem já bastantes documentos sobre o assunto. Mas é basicamente clicar pra criar uma instância, decidir o tipo gratuito, que foi Ubuntu no meu caso, e esperar a máquina virtual ser criada e ativada.
É importante permitir a instância receber tráfego na port 1194 com protocolo UDP pra estabelecer a VPN.
Uma vez a instância funcionando, basta instalar o pacote openvpn e copiar as chaves criadas para dentro do servidor.
ssh root@servidor_aws aws# apt-get install openvpn aws# exit scp -r keys root@servidor_aws:/etc/openvpn
Eu resolvi deixar tudo dentro de "/etc/openvpn" pra facilitar a configuração.
A configuração do lado servidor pode ser inserida dentro do arquivo "/etc/openvpn/dd-wrt-server.conf":
dev tun verb 4 dh /etc/openvpn/keys/dh2048.pem ca /etc/openvpn/keys/ca.crt cert /etc/openvpn/keys/01.pem key /etc/openvpn/keys/server.key tls-server mode server client-to-client persist-key persist-tun push "redirect-gateway" push "dhcp-option DNS 8.8.8.8" push "dhcp-option DNS 8.8.4.4" push "dhcp-option DOMAIN aws.lan" keepalive 15 60 server 10.1.0.0 255.255.255.0 auth sha256 cipher aes-256-cbc link-mtu 1570 comp-lzo
e dentro de "/etc/default/openvpn" basta inserir a linha:
AUTOSTART="dd-wrt-server"
e reiniciar o daemon de openvpn pra ter tudo funcionando. O servidor também precisa permitir tráfego e fazer NAT do mesmo, então os seguintes comandos são necessários (e podem ser colocados em scripts dentro da configuração do openvpn):
iptables -t nat -A POSTROUTING -s 10.1.0.0/24 -o eth0 -j MASQUERADE sysctl -w net.ipv4.ip_forward
DD-WRT não tem uma das melhores formas de debugar conexão. Então caso queira testar de um outro computador, basta criar um arquivo "dd-wrt-client.conf" com a seguinte configuração:
dev tun
remote 52.30.152.15
verb 3
client
remote-cert-tls server
resolv-retry infinite
nobind
persist-key
persist-tun
float
route-delay 30
ca /etc/openvpn/keys/ca.crt
cert /etc/openvpn/keys/dd-wrt.crt
key /etc/openvpn/keys/dd-wrt.key
comp-lzo
No caso basta apenas trocar a linha "remote 52.30.152.15" pra da VPS no AWS. Como no servidor, copie as chaves para dentro do diretório "/etc/openvpn/keys" para facilitar a configuração.
Para iniciar o túnel, basta chamar openvpn como root ou via sudo:
sudo openvpn --config dd-wrt-client-conf
e testar se a conexão está estabelecida corretamente.
No DD-WRT, basta ir na aba de "services/VPN" e habilitar o "OpenVPN". A configuração é a seguinte:
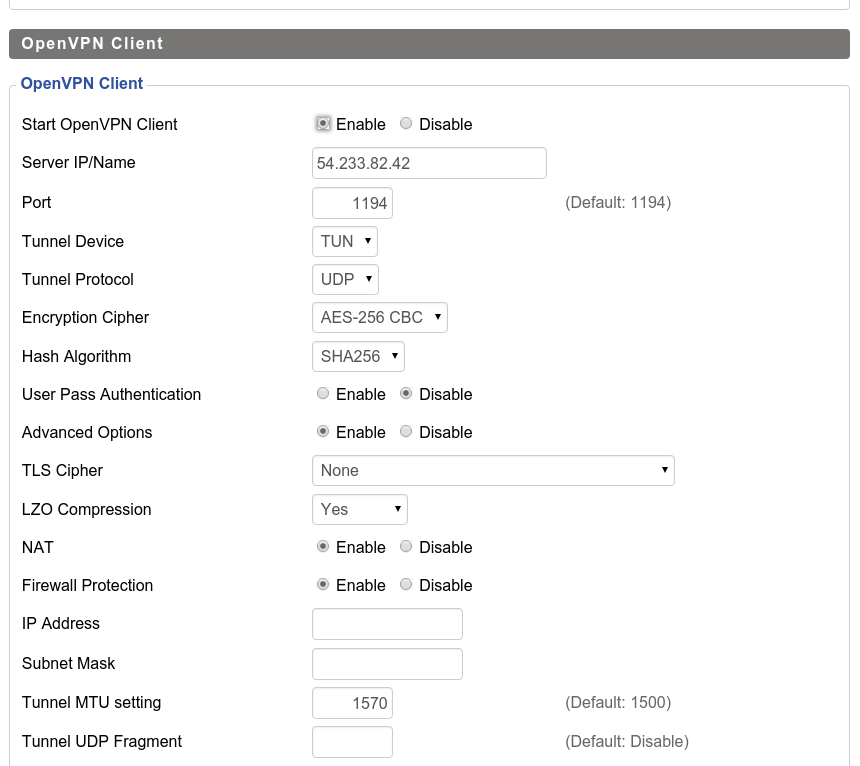

Em "Server IP/Name", basta colocar o IP da instância da AWS. Em CA Cert, o certificado da entidade certificadora, basta copiar e colar o conteúdo de "keys/ca.crt". Em "Public Client Cert" é copiado o conteúdo de "keys/dd-wrt.crt" inteiro, inclusive os dados que estão no início (e que parecem não ser necessários, mas são). Por último em "Private Client Key" vão os dados de "keys/dd-wrt.key", que é a chave privada.
Terminada a configuração, basta salvar e aplicar pra ter seu túnel OpenVPN iniciado diretamente do roteador.
E deu certo no final?
Não. Eu mudei minha conta pra UK pra ter conteúdo em inglês. Então preciso mudar de novo pro Brasil, mudança permitida somente a cada 3 meses, pra ativar os jogos. Não é à toa que Bill Gates é o homem mais rico do mundo.
De agora em diante, só jogos em mídia digital pro playstation e steam.

Ano passado durante uma arrumação das coisas em casa, pra encaixotar e mudar, encontrei um CD do Direto GNU. Desde então tenho essa idéia de escrever sobre a história do mesmo, mas sempre tinha alguma coisa a mais pra escrever e acabava esquecendo. Hoje apareceu a oportunidade.
Antes de continuar devo dizer que tudo que escrevo aqui não é fato comprovado. É algo do tipo "ouvi do porteiro do amigo da cunhada de um sogro de um amigo meu". Quem quiser saber se o fato é verídico ou não, o melhor é buscar por si mesmo as fontes pois não sou jornalista investigativo buscando um Pulitzer e isso aqui não é um blog que busca pela veracidade de notícias e fatos (não que tudo postado aqui seja mentira).
O que era ou é esse tal de Direto GNU?


O Direto GNU foi uma das primeiras experimentações de software público com software livre. Como no início dos anos 2000 o software livre no Brasil tinha sua meca no FISL, em Porto Alegre, nada a se estranhar que o órgão de TI do governo estadual, a PROCERGS, estivesse tocando algo assim.
O Direto GNU era uma suite de aplicativos de mail pra escritórios. Em termos gerais, era um substituto livre do Exchange server da Microsoft. Fazia as partes de servidor de mail, webmail e agenda integrados. Talvez tivesse algo além disso, mas nunca nem olhei. Ganhei o CD da PROCERGS num dos FISLs e guardei.
Meu interesse nunca foi muito além disso pois eu não trabalhava com nada que precisasse do Direto GNU (não era mais sysadmin) e o sistema era feito em Java. Até hoje eu olho com cara de quem chupou limão galego quando alguém fala em software livre e código em Java. Aliás, como tenho trabalhando bastante com python e Java, eu atualmente olho pra quem programa em Java com uma certa dó, pela falta de conhecimento de algo melhor.
Software livre, nome até com GNU, Copyleft PROCERGS, Java, FISL... até aí estava tudo bem. Tudo se encaixava nos moldes de software livre no Brasil. Então... cadê o Direto GNU? Onde ele foi parar? Será que foi abandonado pra em pról do uso de Jegue Panel? É aí que entram as partes que são... rumores. Ou quase...
Era software livre? Boa pergunta. Eu achava que era. O CD ao menos mostrava um "Copyleft PROCERGS". Mas eu resolvi dar uma boa olhada de perto e...
helio@laptop:DiretoGNU$ ls direto-instalacao direto-instalacao.tar.gz Direto.pdf Fontes Fontes.zip Manual Instalacao.pdf Manual_Instalacao_Pdf.zip Manual_Usuario_Pdf.zip helio@laptop:DiretoGNU$ cd Fontes/ helio@laptop:Fontes$ ls Agenda AutorizaPresentation.java Catalogo DiretoProperties.java ImapAdminInterface.java ObjectPool.java Usuario.java Applet Editor BusinessInterface.java Correio diretorio ImapAdmin.java parseHash.java Util.java Autoriza.java ByteArrayDataSource.java Direto.java Hoje JDBCConnectionPool.java PresentationInterface.java helio@laptop:Fontes$ rgrep -i gpl * helio@laptop:Fontes$ rgrep -i copyright * Agenda/Evento.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/Reminder.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/Agenda.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/AgendaBusiness.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/EventoExport.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/ReminderThread.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Agenda/AgendaPresentation.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Catalogo/OptionsInterface.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Catalogo/CatalogoBusiness.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Catalogo/CatalogoPresentation.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Catalogo/DiretoOptions.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Catalogo/Catalogo.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados Correio/FollowUp.java:* Copyright (c) 2000 PROCREGS Projeto Direto. Todos os direitos reservados Correio/Correio.java: * Copyright (c) 2000 PROCREGS Projeto Direto. Todos os direitos reservados Correio/MailUserData.java: * Copyright (c) 1998 The Java Apache Project. All rights reserved. Correio/MailUserData.java: * 1. Redistributions of source code must retain the above copyright Correio/MailUserData.java: * 2. Redistributions in binary form must reproduce the above copyright Correio/FollowUpServer.java:* Copyright (c) 2000 PROCREGS Projeto Direto. Todos os direitos reservados Correio/CorreioProgramado.java: * Copyright (c) 2000 PROCREGS Projeto Direto. Todos os direitos reservados Direto.java:* Copyright (c) 2000 PROCERGS Projeto Direto. Todos os direitos reservados
Com exceção do software da Apache, o resto era tudo propriedade da PROCERGS.
Qual foi a consequência disso? Volto a frisar que é um rumor que ouvi do amigo, do amigo, do porteiro do vizinho. Mas ao trocar o governo, com a eventual verificação de caixa - que sempre está baixo pro seguinte - o governador em exercício teve uma idéia brilhante: fechar os fontes e cobrar pelo uso do software.
Na época em que fomentavam o Direto GNU o governador do Rio Grande do Sul era Olívio Dutra do PT. Um dos primeiros políticos que realmente abraçou o uso do software livre em sua administração. E não somente pra baixar custos, mas pra criar uma vantagem competitiva à região. E conseguiu, com muito sucesso. Então todos os órgãos de administração pública do estado adotaram o software. Empresas de energia elétrica, água, transporte, etc... tudo e todos.
Infelizmente a mudança de governo, que sempre acontece de tempos em tempos, fez uma curva de 180º nas diretivas de software livre indo totalmente na contra-mão do que existia. E o novo governador teve uma brilhante idéia pra reforçar a arrecadação da máquina estatal: cobrar pelo software. E pra cobrar era preciso... fechar o software!
Como a maioria das empresas estaduais já usavam o software, por exigência da administração anterior, virou quase um caso de ser tornar refém de seu uso. Como o software não existia em repositório, foi fácil mudar tudo pra uma licença proprietária fechada e cobrar pelo uso. Simples assim.
Foi assim que o DiretoGNU virou um direto na boca do estômago de todo mundo.
Atualmente o governo federal tem um software na mesma linha, o Demoisele, mas o aprendizado do Direto GNU os levou a ter certeza de ter a licença LGPL e de que o software está publicado num repositório externo. Depois veio também o Expresso, que fica próximo ao Direto GNU em termos de funcionalidade. Também publicado sob GPL e em repositórios públicos.
Essa foi a lição aprendida em termos governamentais sobre a gestão de conteúdo de software livre. Mas o seu uso pode ser totalmente abolido caso um novo governo assuma, o que eventualmente deve acontecer, e o mesmo quiser apagar o "legado" do governo anterior. Por isso é tào importante ter software livre como uma estratégia de crescimento pro país, e não de um partido.
O software livre não é de direta, nem de esquerda, nem de centro. É software, e disponível para todos, assim como os algoritmos de matemática.
Page 20 of 40
