Um vídeo curto com algumas fotos de como foi meu 2020. Por volta de 30 fotos por mês.
Spoiler alert: nada muito emocionante em tempos de COVID.

Um dos trabalhos que faço como voluntário é manter alguns serviços "alternativos" na empresa. Todos baseados em software livre.
Dos que são mantidos temos um mediawiki, um encurtador yourls e um etherpad-lite. E esse último foi o que precisei mexer pra transferir pra um servidor novo.
Muitas pessoas gostam do etherpad-lite e o usam, mas devo dizer que por trás é um lixo. Serviço porco. Ele usa uma só tabela no MySQL/MariaDB com dois campos:
mysql> show tables; +-----------------+ | Tables_in_paddb | +-----------------+ | store | +-----------------+ 1 row in set (0.00 sec) mysql> desc store; +-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | key | varchar(100) | NO | PRI | | | | value | longtext | YES | | NULL | | +-------+--------------+------+-----+---------+-------+ 2 rows in set (0.01 sec)
Sério. 2 campos. E só. Um é uma chave toscamente preparada pra ser chave primária e o resto... é valor. Então o uso do DB só cresce, sem chances de uma manutenção decente.
Enquanto o uso do etherpad-lite é um dor nas costelas, o assunto é mais da migração dos dados. Então continuando o assunto, o nosso DB chegou ao incrível valor de 13 GB. Daí como faz a migração? O básico é tirar um dump do DB antigo com mysqldump e carregar usando o comand mysql mesmo.
Algo como isso:
# mysql --host=remote-server.mysql.internal.com --port=1234 --user=sqluser --password=sqlpassword mydb < etherpad-migration-backup.sql
que pra todos efeitos funciona. O único problema foi que depois de passar 15 horas carregando o arquivo...
ERROR 2013 (HY000) at line 19057418: Lost connection to MySQL server during query
Dizem que não tem dor maior que a dor do parto. Tem sim e chama-se carregar um dump de 13 GB por 15 horas e falhar. Assim.
E o que restou fazer. Bom... eu sabia a linha onde estava o arquivo, mas já tinham sido 15 horas num arquivo serial, que faz linha por linha. Então decidi quebrar o dump em vários arquivos menores. Dei um rápido "wc -l" no dump e vi que tinham exatamente 28993313 linhas. Então era possível quebrar em 28 arquivos de 1 milhão de linhas cada. E foi o que fiz.
Assim eu sabia que podia continuar do arquivo 20 em diante. E depois resolvia como fazer com o que faltava.
# split -l 1000000 -d etherpad-migration-backup.sql etherpad-migration-backup.sql. # ls -1 pad-migration-backup.sql.?? etherpad-migration-backup.sql.00 etherpad-migration-backup.sql.01 etherpad-migration-backup.sql.02 etherpad-migration-backup.sql.03 etherpad-migration-backup.sql.04 etherpad-migration-backup.sql.05 etherpad-migration-backup.sql.06 etherpad-migration-backup.sql.07 etherpad-migration-backup.sql.08 etherpad-migration-backup.sql.09 etherpad-migration-backup.sql.10 etherpad-migration-backup.sql.11 etherpad-migration-backup.sql.12 etherpad-migration-backup.sql.13 etherpad-migration-backup.sql.14 etherpad-migration-backup.sql.15 etherpad-migration-backup.sql.16 etherpad-migration-backup.sql.17 etherpad-migration-backup.sql.18 etherpad-migration-backup.sql.19 etherpad-migration-backup.sql.20 etherpad-migration-backup.sql.21 etherpad-migration-backup.sql.22 etherpad-migration-backup.sql.23 etherpad-migration-backup.sql.24 etherpad-migration-backup.sql.25 etherpad-migration-backup.sql.26 etherpad-migration-backup.sql.27 etherpad-migration-backup.sql.28 etherpad-migration-backup.sql.29
Com isso eu tive vários arquivos que eu podia subir em paralelo. E foi o que fiz. O resultado? Não só um mas vários erros depois de algumas horas carregando. Eu queria chorar. No chuveiro. Em posição fetal. Só isso.
O maldito do comando mysql não te permite dar um replay descartando o que já existisse no DB, o que seria uma mão na roda nessas situações. Então fiz isso com python. Mas achei que seria lento demais manter serializado. Então era um bom momento pra testar o asyncio, que usei pouquíssimo até hoje. E valeu muito a pena. Esse é o script final:
#! /usr/bin/python3
import sys
import pymysql.cursors
import asyncio
connection = pymysql.connect(host="remote-server.mysql.internal.com",
port=1234,
user="sqluser",
password="sqlpassword",
db="mydb",
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
cursor = connection.cursor()
sema = asyncio.Semaphore(value=10)
async def commit_line(line):
await sema.acquire()
print(line)
try:
cursor.execute(line)
connection.commit()
except:
print("Line (", line[:10],") already inserted")
pass
sema.release()
with open(sys.argv[1]) as sqlfile:
loop = asyncio.get_event_loop()
for line in sqlfile.readlines():
loop.run_until_complete( commit_line(line) )
loop.close()
Não está dos mais polidos, e com senha dentro, mas era uma coisa rápida pra resolver meu problema. E resolveu.
Eu criei uma fila de 10 processos em paralelo pra rodar com: sema = asyncio.Semaphore(value=10)
o controle de acesso ao processo pra rodar é feito com sema.acquire() e sema.release(). Muito fácil. Nem precisei criar um objeto Queue.
Dentro do loop do commit_line() eu sabugue um "enfia essa linha lá ou então continua". Simples assim. E funcionou.
Eu já tinha deixado o tmux aberto com várias janelas, uma pra cada arquivo, então foi só rodar o mesmo em cada uma que falhou.
Levou mais umas 2 ou 3 horas mas carregou tudo.
Foi lindo, não foi?

Esses dias precisei fazer uma migração de uma mediawiki que usamos na empresa de uma máquina que rodava CentOS 6.8 pra um Ubuntu 18.04.
Para garantir seu funcionamento, primeiro eu queria testar os upgrades necessários em minha máquina. Nada melhor que copiar os arquivos e rodar a versão exata do site remoto com containers em docker.
Mas ao rodar o container... ele simplesmente saia com código de erro 139. Mais nada. Sem logs, sem describe, sem nada que pudesse ajudar.
~ > docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8ffcdf12d761 centos:6.8 "bash" 52 minutes ago Up 52 minutes 0.0.0.0:8080->80/tcp elated_ganguly 7bd9374248fd centos:6.8 "bash" 56 minutes ago Exited (139) 56 minutes ago dreamy_fermat 80ff07e9b84e centos:6.8 "bash" 10 hours ago Exited (139) 10 hours ago romantic_hertz 3db1d6c1f68b centos:6 "bash" 10 hours ago Exited (139) 10 hours ago bold_kilby
Olhando pela Internet, descobri em alguns sites pessoas relatando o mesmo problema. É algo relacionado com a versão da glibc do container com a versão do kernel que estou rodando, que é muito mais novo:
~ > uname -a Linux elxa7r5lmh2 5.9.0-rc5-helio #10 SMP Sat Sep 19 12:04:57 CEST 2020 x86_64 x86_64 x86_64 OSI/Linux
A solução é adicionar um parâmetro a mais no grub a opção "vsyscall=emulate":
~ > grep GRUB_CMDLINE_LINUX /etc/default/grub GRUB_CMDLINE_LINUX_DEFAULT="quiet splash" GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0 pcie_aspm=off pci=nomsi vsyscall=emulate"
e fazer um update no próprio grub.
~ > sudo update-grub2 && sudo reboot -f
Após um reboot os containers funcionaram sem problemas.
~ > docker run -it --rm=true centos:6.8 bash [root@224aecaba978 /]# hostname 224aecaba978 [root@224aecaba978 /]# exit exit ~ > docker ps -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ca68add255bd ubuntu:18.04 "bash" 2 hours ago Exited (1) 2 hours ago festive_galois ~ >
Eu tentei configurar diretamente no kernel através da interface em /sys, mas eu só consegui com isso gerar um kernel panic. O jeito mais fácil e seguro foi mesmo rebootando meu laptop.

Entre os vários grupos do Telegram, um que é muito bom é o de shell, o t.me/shellbr pros mais íntimos.
Um dia desses, entre discussões de como fazer um shell melhor e eu postando sticker pros falantes de língua inglesa de que o grupo é em língua portuguesa, apareceu algo que abriu minha visão em shell pra algo muito maravilhoso. Não é uma novidade de um comando mágico que faz algo completamente novo, mas a simplicidade da solução que esteve esse tempo todo na minha cara e eu nunca vi foi o que me fascinou.

Pra dar um pouco mais de contexto, o que se referia isso: quem nunca precisou mandar um "ps auxwww | grep firefox" e pegou o próprio comando grep na saída?
~> ps auxwww | grep firefox helio 5719 15.5 2.9 3994484 475156 ? Rl 20:57 4:38 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.0 1.6 3021712 259472 ? Sl 20:58 1:47 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 1.0 1.2 2687192 201516 ? Sl 20:58 0:18 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 161856 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.8 2.0 3008700 325944 ? Rl 20:58 1:44 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 1.0 1.5 2875692 241532 ? Sl 21:08 0:12 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.5 1.1 2676620 179336 ? Rl 21:11 0:15 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120484 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13 helio 14368 0.0 0.0 18056 1052 pts/2 S+ 21:27 0:00 grep --color=auto firefox
Comecei com Linux em 1997, quando aprendi a usar as Sparc stations da universidade. Mais de 20 anos nessa indústria vital e eu sempre, sempre, usei desse jeito:
~ > ps auxwww | grep firefox | grep -v grep helio 5719 14.6 3.0 3991196 481364 ? Sl 20:57 4:56 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.2 1.7 3019784 279384 ? Sl 20:58 2:05 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 0.9 1.2 2687192 202532 ? Sl 20:58 0:19 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 164072 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.4 2.0 3008700 330532 ? Sl 20:58 1:49 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 0.9 1.5 2875692 241876 ? Sl 21:08 0:13 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.3 1.1 2676620 179336 ? Sl 21:11 0:16 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120588 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13
Com essa maravilhosa dica do Hélio Campos, basta fazer assim:
~ > ps auxwww | grep [f]irefox helio 5719 14.5 3.1 4005676 500088 ? Sl 20:57 5:01 /usr/lib/firefox/firefox --ProfileManger --no-remote helio 5815 6.7 1.8 3034264 293864 ? Rl 20:58 2:18 /usr/lib/firefox/firefox -contentproc -childID 1 helio 5876 0.9 1.2 2687192 203656 ? Sl 20:58 0:19 /usr/lib/firefox/firefox -contentproc -childID 2 helio 5916 0.5 1.0 2646492 164072 ? Sl 20:58 0:10 /usr/lib/firefox/firefox -contentproc -childID 3 helio 5939 5.3 2.0 3008700 331836 ? Sl 20:58 1:51 /usr/lib/firefox/firefox -contentproc -childID 4 helio 9210 0.9 1.5 2875692 241876 ? Sl 21:08 0:14 /usr/lib/firefox/firefox -contentproc -childID 9 helio 10161 1.3 1.1 2676620 179336 ? Sl 21:11 0:17 /usr/lib/firefox/firefox -contentproc -childID 10 helio 10394 0.2 0.7 2583360 120588 ? Sl 21:12 0:02 /usr/lib/firefox/firefox -contentproc -childID 11 helio 11818 0.0 0.4 2549948 77524 ? Sl 21:18 0:00 /usr/lib/firefox/firefox -contentproc -childID 13
Eu achei espetácular. Pode ser que eu esteja exagerando, mas achei mesmo. Uma dica muito simples e acabou com décadas usando um extra "grep" pra resolver as coisas.
Muito obrigado Hélio Campos e grupo shellbr!

Esses dias eu dei uma boa arrumada na minha estante e encontrei um laptop que estava parado desde 2014. Quando liguei, estava ainda com o Ubuntu 14.04 instalado e rodando. Pensei no mesmo momento que seria perfeito pra verificar o estado da proteção que as distros ditas livres e que são baseadas no GNU Linux Libre possuem.
Eu entrei na página da FSF eu fui seguindo as distros recomendadas como 100% livres. Peguei pra testar as seguintes: Trisquel, Parabola e Guix. Eu ia tentar também a Gnewsense mas a página principal mostra que depois de anos parada seu desenvolvimento foi simplesmente abandonado. Mas ainda está listada na página da FSF.
(Foto By Rafael Bonifaz - Alexandre Oliva, CC BY-SA 2.0,https://commons.wikimedia.org/w/index.php?curid=8939097)
Pra ter alguma comparação eu também testei Debian puro, sem nada a parte de firmwares, e também um Ubuntu. Vou descrever cada um em separado.
Esse morreu na praia pra mim. Como essas distribuições não usam firmwares, não consigo ativar o wifi do laptop. O Guix exige que a instalação siga por rede pra terminar. Eu deixei o laptop numa mesa longe da rede cabeada. Entre mexer o laptop pra minha mesa ou puxar um cabo até o outro quarto eu preferi simplesmente deixar de lado. Tentei procurar por um livecd ou algo do gênero mas não encontrei.
O Trisquel teve a instalação relativamente tranquila. Uma voz robotizada ficava falando tudo o que eu teclava mas deu tudo certo. Como esperado não funcionou com o wifi mas teve o touchpad do laptop funcionado desde a instalação.
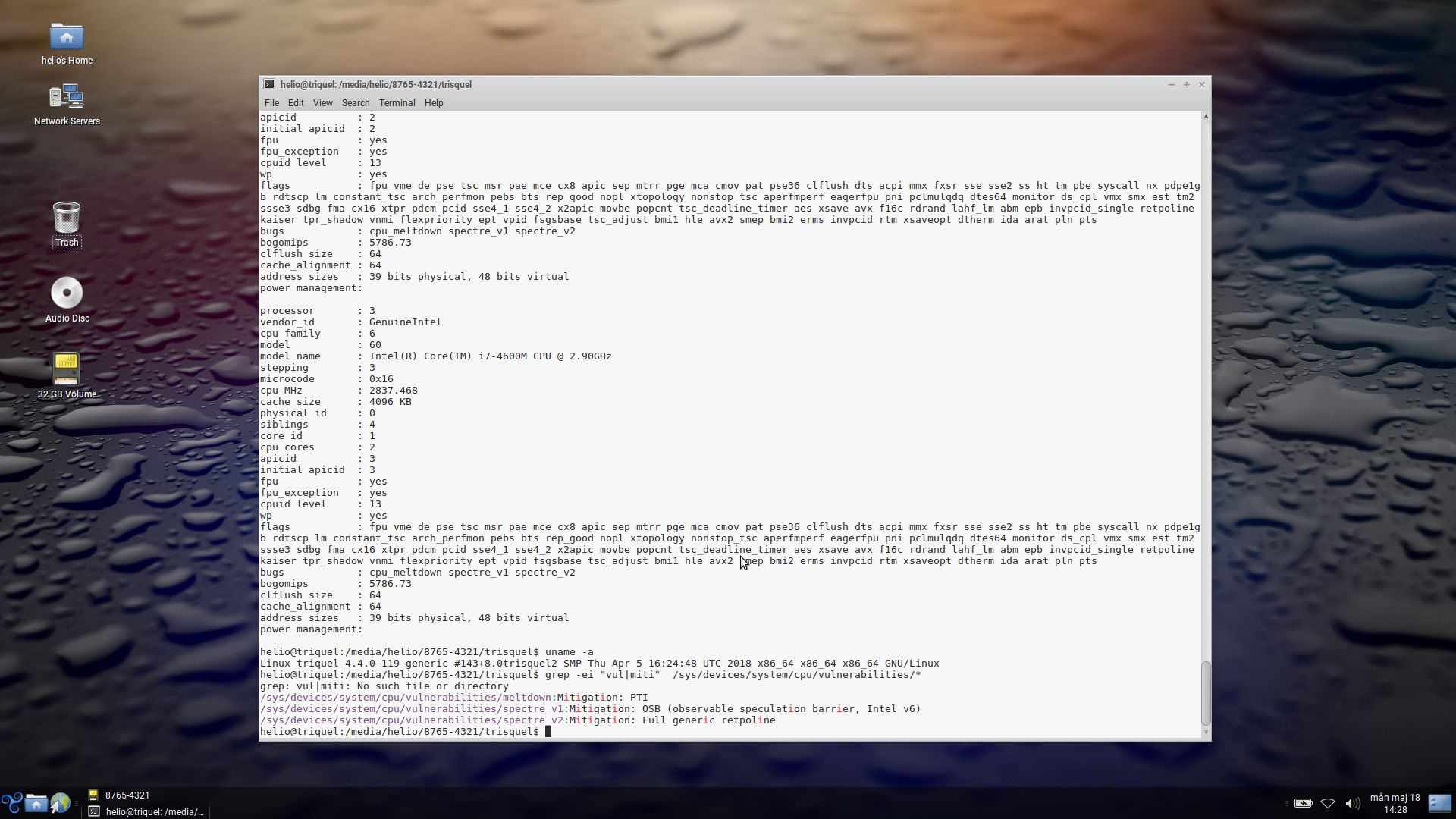
uname:
Linux triquel 4.4.0-119-generic #143+8.0trisquel2 SMP Thu Apr 5 16:24:48 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 2222.578 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movb e popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb invpcid_single retpoline kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 e rms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 bogomips : 5786.73 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: OSB (observable speculation barrier, Intel v6) /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline
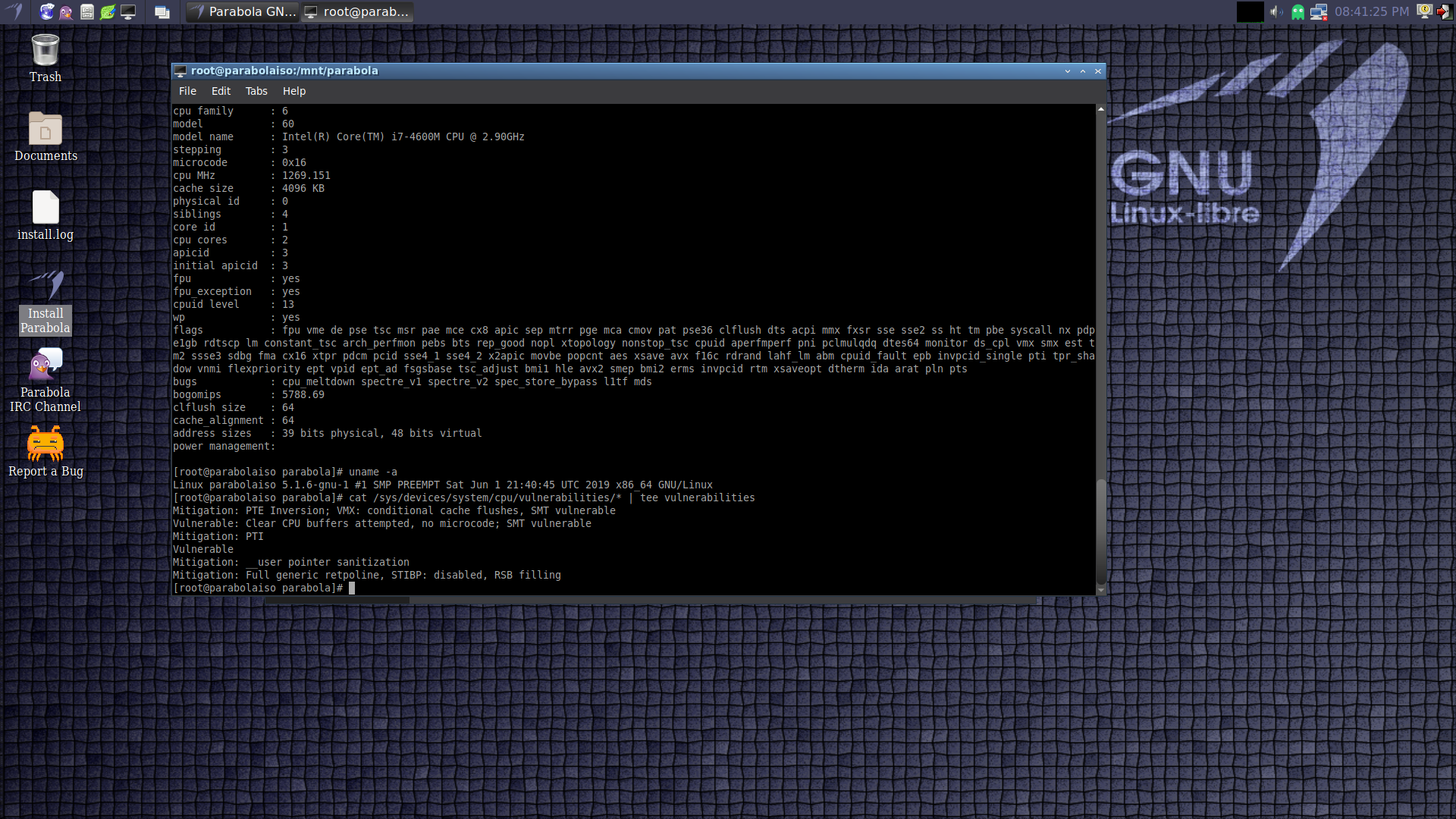
uname:
Linux parabolaiso 5.1.6-gnu-1 #1 SMP PREEMPT Sat Jun 1 21:40:45 UTC 2019 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 1069.269 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds bogomips : 5788.69 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/l1tf:Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable /sys/devices/system/cpu/vulnerabilities/mds:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable /sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline, STIBP: disabled, RSB filling
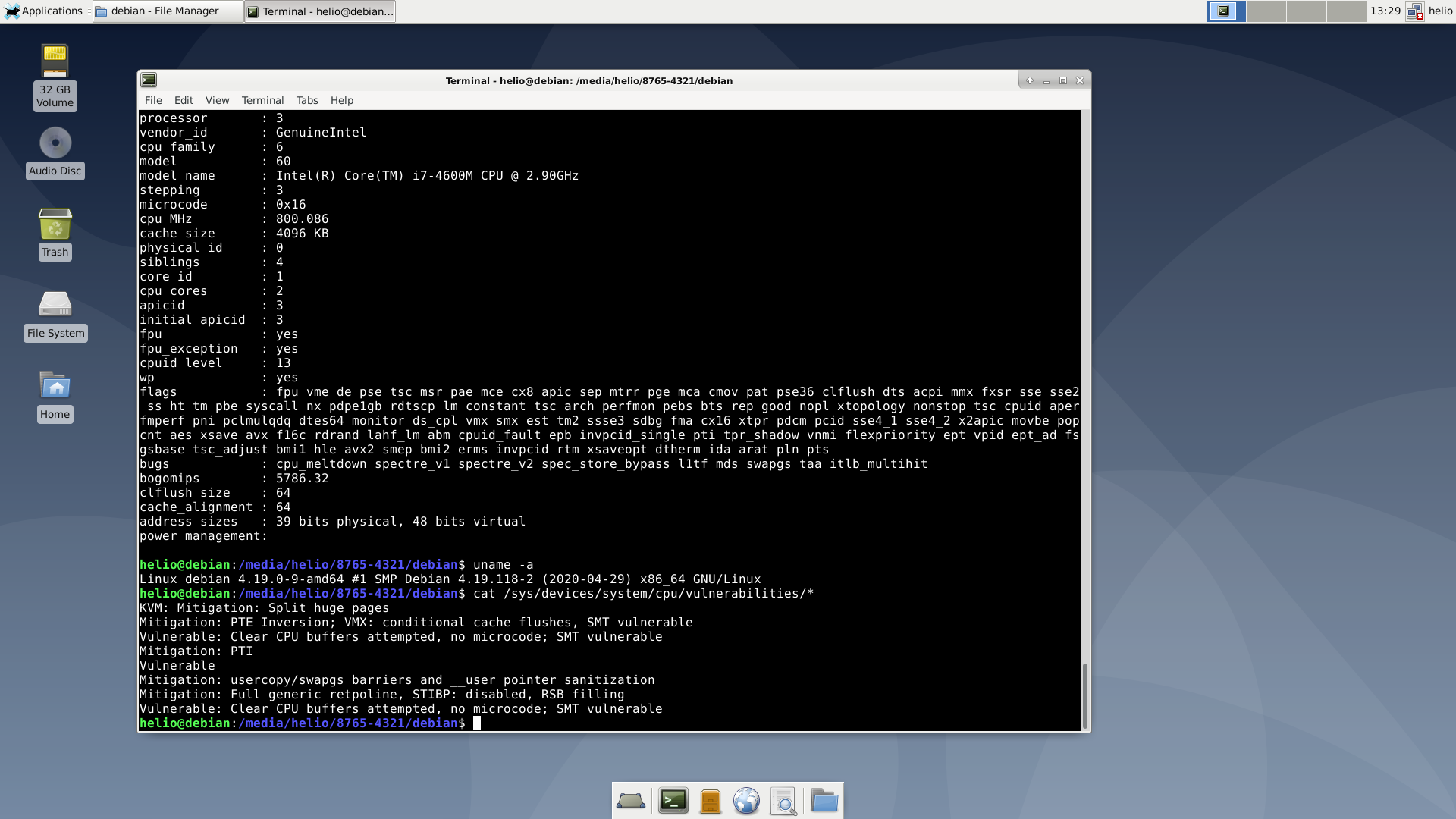
uname:
Linux debian 4.19.0-9-amd64 #1 SMP Debian 4.19.118-2 (2020-04-29) x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 1903.637 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit bogomips : 5786.32 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/itlb_multihit:KVM: Mitigation: Split huge pages /sys/devices/system/cpu/vulnerabilities/l1tf:Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable /sys/devices/system/cpu/vulnerabilities/mds:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable /sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: usercopy/swapgs barriers and __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline, STIBP: disabled, RSB filling /sys/devices/system/cpu/vulnerabilities/tsx_async_abort:Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable
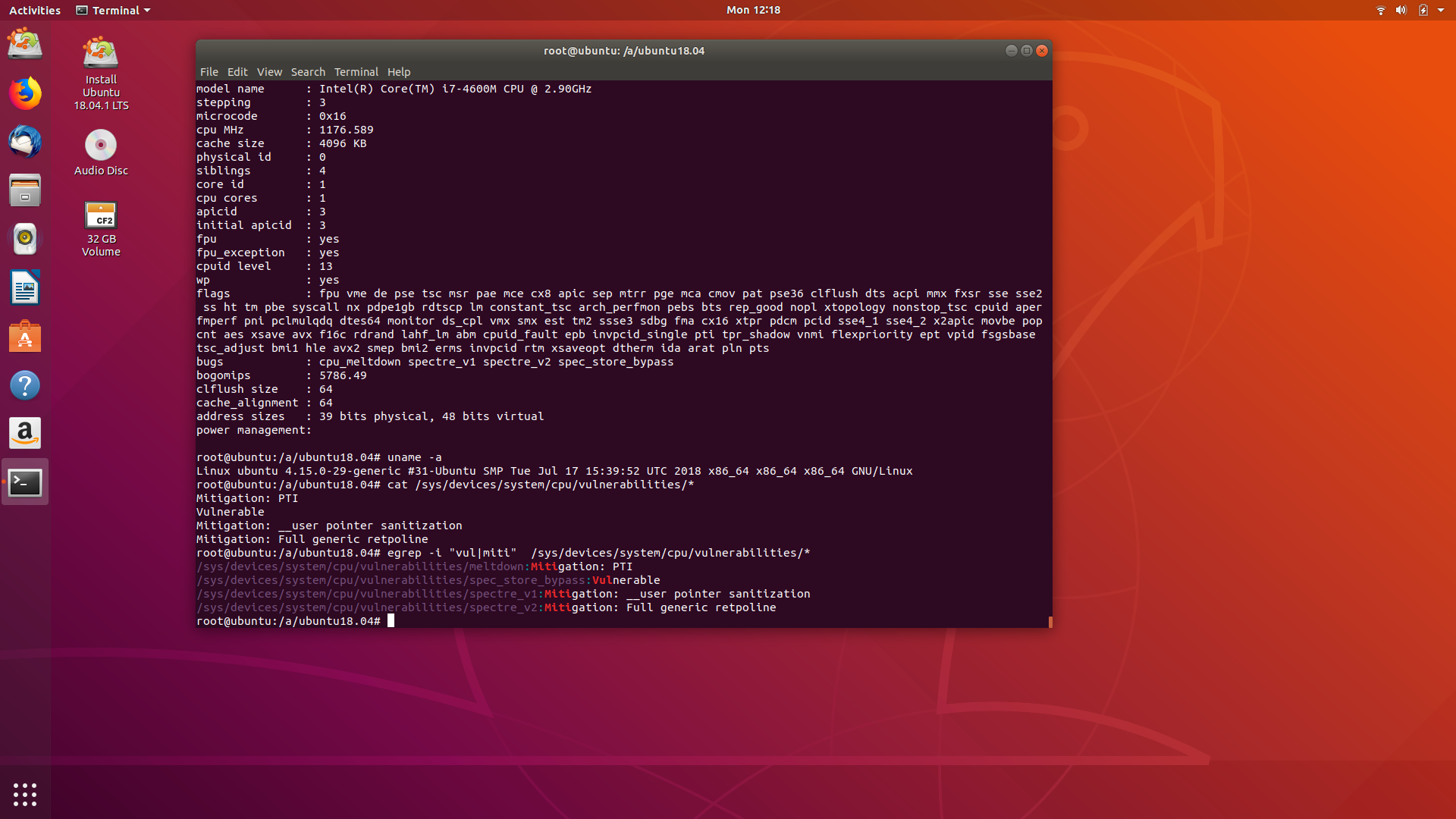
uname:
Linux ubuntu 4.15.0-29-generic #31-Ubuntu SMP Tue Jul 17 15:39:52 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4600M CPU @ 2.90GHz stepping : 3 microcode : 0x16 cpu MHz : 2047.970 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_ perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe p opcnt aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveop t dtherm ida arat pln pts bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass bogomips : 5786.49 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
vulnerabilidades:
/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI /sys/devices/system/cpu/vulnerabilities/spec_store_bypass:Vulnerable /sys/devices/system/cpu/vulnerabilities/spectre_v1:Mitigation: __user pointer sanitization /sys/devices/system/cpu/vulnerabilities/spectre_v2:Mitigation: Full generic retpoline
A comparação é difícil porque cada um dos sistemas operacionais roda com uma versão de kernel diferente. Todas baseadas em Linux.
Todas mostram em cpuinfo que detectam as falhas de spectre_v[1,2] e meltdown, além das demais.
Como mostrado pelas distros com kernels mais recentes, várias vulnerabilidades estão ainda abertas. O sistema continua vulnerável aos ataques de especulação mas não aos spectre v1 e v2, nem meltdown. Realmente sobre essas duas vulnerabilidades o Oliva está certo. Só errou que o restante continua vulnerável e inseguro sem as correções de firmware.
Não imagino que possam ser corrigidas em versões mais recentes pois precisam do firmware da Intel pra mudar o microcode direto na CPU.
Quem continuar utilizando algumas dessas distros é interessante ficar de olho qual bug de CPU foi corrigido e qual ainda está pendente. E ter cuidado ao usar o computador, pois o mesmo continua vulnerável a ataques de especulação mesmo rodando somente software livre.

Hoje chegou um mail pedindo pra testar uma mudança de máquinas que saíram da empresa pra irem habitar o cloud. A tarefa era testar máquina e porta. Algumas máquinas com uma porta somente, outras com várias. E todas TCP.
Pra fazer isso rapidamente eu escrevi um script em python3 que basicamente estabelece uma conexão TCP e mostra OK se conectar ou FAIL se não conseguir. Bem básico, mas resolveu meu problema muito mais rápido que se eu fosse testar máquina por máquina, porta por porta provavelmente com o comando telnet.
#! /usr/bin/python3
import socket
servers = [
"helio.loureiro.eng.br:443",
"helio.loureiro.eng.br:389",
"helio.loureiro.eng.br:8081",
"helio.loureiro.eng.br:80",
"helio.loureiro.eng.br:22"
]
for server in servers:
try:
host, port = server.split(":")
port = int(port)
socket.create_connection((host, port), 3)
print(server, "OK")
except:
print(server, "FAIL")
O resultado:
helio.loureiro.eng.br:443 OK helio.loureiro.eng.br:389 FAIL helio.loureiro.eng.br:8081 FAIL helio.loureiro.eng.br:80 OK helio.loureiro.eng.br:22 OK
Boa diversão!
Tenho feito muitos testes para utilizar TLS e mTLS. TLS é uma camada de criptografia assimétrica para garantir a comunicação segura entre dois pontos.
Em geral temos o model parecido com os sites web onde o servidor tem uma conexão segura assinada por uma autoridade certificadora e nos conectamos a ele. No caso de mTLS, mutual TLS, é preciso validar quem conecta também.
Pra gerar os testes que venho fazendo, gero um certificado de 1 dia usando openssl da seguinte forma:
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 1 -nodes \
-subj "/C=SE/ST=Stockholm/L=STHLM/O=Company/OU=ADP/CN=localhost
Esse comando gera para mim a chave do servidor (key.pem) e a chave da autoridade certificadora, que assina a chave.
Em geral carrego isso no meu programa que utiliza TLS.
Pra testar (assumindo que seu serviço seja http e esteja usando a porta 9091):
curl --cacert cert.pem --key key.pem --cert cert.pem "https://localhost:9091/
Eu poderia gerar um chave pro client, que no caso é o comando curl, mas como é pra ambiente de testes, re-uso o mesmo.
Boa diversão!

Já faz algum tempo que quero escrever sobre meu uso de LVM, mas até agora a procrastinação venceu. No último artigo Trabalhando de home-office eu descrevei meu ambiente de home-office e um pouco do meu desktop. Ao entrar no desktop é que percebi que um dos HDDs simplemente parou de funcionar, esse Seagate Firecuda de 2 TB. Graças ao LVM eu não percebi nada, nem perdi dados. E vou descrever aqui o cenário e como fiz a troca e re-sincronismo dos dados.
Usando o comando lvm é possível ver o estado dos meu volumes:
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor-r- 750.00g 100.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
Minhas partições eram todas XFS mas descobri que alguns jogos da Steam simplesmente só rodam com EXT4. Então precisei criar uma partição EXT4 somente pros jogos. É o volume com nome de "steam" e que mostra um "100.00". Esse número representa a cópia no disco que falhou, que estava em RAID1.
Primeiro eu adicionei outro disco de 2 TB que tinha aqui (no passado eu usava 2 HDDs de 2 TB cada com LVM, comprei o HDD novo de 4 TB e removi 1 dos HDDs que estava em bom estado ainda), e particionei da mesma forma que o HDD de 4 TB, com uma partição EFI e outra de boot do mesmo tamanho. O restante pro LVM.
root@goosfraba:~# fdisk -l /dev/sdb
Disco /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 setores
Unidades: setor de 1 * 512 = 512 bytes
Tamanho de setor (lógico/físico): 512 bytes / 512 bytes
Tamanho E/S (mínimo/ótimo): 512 bytes / 512 bytes
Tipo de rótulo do disco: dos
Identificador do disco: 0x18a6e3b6
Dispositivo Inicializar Início Fim Setores Tamanho Id Tipo
/dev/sdb1 2048 1128447 1126400 550M ef EFI (FAT-12/16/32)
/dev/sdb2 1128448 5322751 4194304 2G 83 Linux
/dev/sdb3 5322752 3907029167 3901706416 1.8T 8e Linux LVM
Tendo a partição sdb3 disponível pro LVM, então o que faltava era adicionar o grupo de volumes que uso. Ao listar os discos físicos disponíveis, apareceu a informação ainda do disco antigo como "unknown".
root@goosfraba:~# pvdisplay
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name [unknown]
VG Name diskspace
PV Size <1.82 TiB / not usable <4.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476931
Free PE 284930
Allocated PE 192001
PV UUID N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t
"/dev/sdb3" is a new physical volume of "<1.82 TiB"
--- NEW Physical volume ---
PV Name /dev/sdb3
VG Name
PV Size <1.82 TiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
Isso acontenceu porque o metadado ainda estava lá apesar do disco ter sido removido da máquina. Enquanto isso a partição sdb3 aparece como "Allocatable NO" pois ainda não está disponível pra uso.
A primeira coisa é remover os dados incosistes do vg (volume group).
root@goosfraba:~# vgreduce diskspace --removemissing --force
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
Wrote out consistent volume group diskspace.
E adicionar a nova partição ao vg.
root@goosfraba:~# vgextend diskspace /dev/sdb3
Volume group "diskspace" successfully extended
Com isso o a informação de pv mostra como usado.
root@goosfraba:~# pvdisplay
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name /dev/sdb3
VG Name diskspace
PV Size <1.82 TiB / not usable <2.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476282
Free PE 476282
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
E a informação de vg mostra com 6 TB disponíveis pra uso.
root@goosfraba:~# vgdisplay
--- Volume group ---
VG Name diskspace
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 217
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 8
Open LV 8
Max PV 0
Cur PV 2
Act PV 2
VG Size 5.45 TiB
PE Size 4.00 MiB
Total PE 1429493
Alloc PE / Size 501761 / 1.91 TiB
Free PE / Size 927732 / <3.54 TiB
VG UUID f2ufnI-c802-yt6f-2nMG-6BYl-8atu-wbR7vO
Agora a partição já faz parte do lvm. O que resta é a usar como RAID1 em mirror. Ou mesmo como uma partição qualquer se eu quisesse. Mas no caso uso como RAID1 pra ter um pouco mais de desempenho.
Primeiramente removendo as informações de RAID1 que ainda existindo.
root@goosfraba:~# lvconvert -m 0 /dev/diskspace/steam
Are you sure you want to convert raid1 LV diskspace/steam to type linear losing all resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace -wi-ao---- 750.00g
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
O parâmetro "-m 0" diz que a partição será em RAID0.
Em seguida basta mudar a partição novamente pra RAID1 e o sincronismo iniciará.
root@goosfraba:~# lvconvert -m 1 /dev/diskspace/steam /dev/sdb3
Are you sure you want to convert linear LV diskspace/steam to raid1 with 2 images enhancing resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 0.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 34.56
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
E é isso. Simples e rápido graças ao LVM.

Com o mundo inteiro parado em compasso de espera ou em quarentena por causa do COVID-19, resolvi me juntar aos que mostram um pouco de seu ambiente de home-office pra auxiliar os que estão iniciando nesse mundo de pijamas e pantufas. Já peço desculpas antecipadamente pela pouca limpeza do ambiente. Eu até passei um aspirador de pó pra parecer menos decadente, mas infelizmente não deu pra esconder muito não. Como é um ambiente que uso muito já que trabalho remotamente com bastante frequência, a limpeza deixa muito a desejar. Sem contar com a estante orientada à bagunça que tenho do lado direito. É um verdadeiro porta-trecos gigante que faço bom uso pra guardar... trecos.
Primeiramente uma descrição do ambiente:é meu quarto. A mesa fica ao lado da minha cama e tenho um espacinho apertado onde cabe a cadeira. Não permite muitas acrobacias mas é bastante funcional como ambiente de trabalho em casa. E tem a vantagem que posso ficar dentro do quarto fechado enquanto trabalho ao invés de ficar na sala ou na cozinha.
Agora vamos aos pequenos detalhes importantes e com links caso queiram olhar as especificações e/ou comprar algo igual. Lembrem-se de que não fui ao supermercado (ou Amazon no caso) e comprei tudo de uma vez. Fui adquirindo tudo ao longo de vários anos.

TP-LINK TL-SG108 8-Port Metal Gigabit Ethernet Switch
Trabalho cabeado. Nada de rede wi-fi com suas interferências. Tenho um switch de mesa não gerenciável da tp-link com portas 1Gbps. Como meu apartamento tem cabeamento estruturado, um desses cabos vai direto pro roteador de saída. De lá é uma conexão fibra ótica de 100 Mbps. Eu gostaria de ter uma conexão maior, mas aqui na Suécia custa muito caro. E os 100 Mbps têm me atendido bem. Trabalho sem engasgos na rede, ouvindo música no Spotify e ainda a filhota assiste YouTube ou NetFlix sem problemas. Não rodo nada de traffic shape no meu roteador de saída, que é um tp-link também rodando open-wrt. Tenho nesse link tanto IPv4 quanto IPv6.
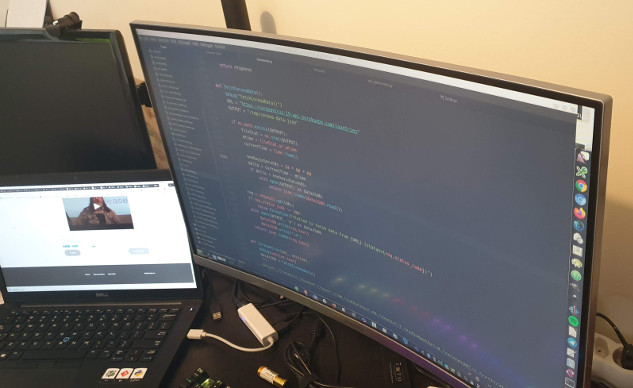
Samsung C27F581F 68.6 cm (27 Inch) Monitor (LCD/TFT/Curved)
USB 2.0 Multi-functional LAN Adapter - White
Invision® TV & PC VESA Adapter Kits
HumanCentric VESA Adaptor Holder for Samsung CF591 Curved Monitor 27 Inch LC27F591FDNXZA
Tenho uma tela principal que é curvada: . É algo maravilhoso. A curvatura realmente ajuda os olhos a não ficarem tão cansados ao fim do dia. Atrás das telas eu tenho um braço mecânico que as sustenta. Quando estou trabalhando eu uso o laptop como segunda tela e empurro a tela extra pra trás. Quando uso meu desktop, que já comento mais abaixo, eu movo essa segunda tela mais próxima de mim, mas meio que de lado. Apesar de ter duas telas, a que uso mesmo é a frontal, o display curvado. Além do cômodo formato curvo tem também filtro de luz azul e som embutido. Então posso usar pra assistir vídeos e até mesmo jogar, o que faço com meu desktop pessoal.

USB 2.0 Multi-functional LAN Adapter - White
Eu uso esse adaptador USB pra juntar teclado, mouse e a saída pra rede cabeada. O conector USB eu comprei no GearBest. É USB 2.0 mas funciona muito bem pra seu propósito e torna o uso compartilhado entre trabalho/casa mais maleável.

AmazonBasics USB 3.0 A Male to A Female Extension Cable - Black 2 m
Tenho também um outro hub USB 3.0 (só notar as portas com cor azul pra saber que é padrão 3.0) que conecta por um cabo mais longo na traseira do desktop. Quando vou mudar do laptop, que é da empresa, pro desktop eu só mudo o conector USB que descrevi anteriormente nesse hub. No monitor há um botão pra mudar a origem de vídeo.

O mouse eu não tenho a descrição porque comprei numa loja física. Mas é um à laser bem simples e wireless. Funciona o suficiente pra o que é preciso. Tem esse botão de "dpi" que nunca apertei. Sei lá se explode então não vou fazer isso agora.

AMD FX 8300 AM3 + 3.3/4.2 GHz, 16MB Cache, 95 W, Box, FD8300WMHK 16MB Cache, 95 W, Box)
ARCTIC Freezer 7 Pro Rev 2 - 150 Watt Multicompatible Low Noise CPU Cooler for AMD and Intel Sockets
Ace 700 W BR PSU with 12 cm Red Fan and PFC – Black
JBL Charge 3 Waterproof Portable Bluetooth Speaker with 6000 mAh Power Bank and Hands-Free Function
AmazonBasics - Controller für die Xbox One, kabelgebunden, Weiß
Crucial Ballistix Sport LT White 16GB (2x8GB) / 2666Hz / DDR4 / CL16
Pra fechar apenas o conjunto da obra aqui está o desktop. Ele roda um Ubuntu 18.04, tem 32 GB de RAM, 6 TB de HDD (1 de 4 TB e outro de 2 TB com LVM), e cpu AMD FX. Eu comprei a primeira versão dele no Ponto Frio e rodava Linux. Era originalmente um Semp Toshiba. Hoje em dia só sobrou a carcaça. O gravador de DVD está desligado, assim como o leitor de cartões na parte da frente. De resto, nem os parafusos sobraram. Nele eu rodo jogos e eventualmente uso pra gravar o webcast por ter mais potência que meu laptop.
Acima do desktop é possível ver uma caixa de som JBL. Além de fazer o rock'n roll rolar solto nos churrascos por aqui (e expurgar todo pagode que tentar chegar perto), eu em geral uso o smartphone conectado ao Spotify pra ouvir música e jogar o áudio na caixa de som. A vantagem é que evito usar o tráfego da VPN da empresa pra ouvir música pelo laptop.
E pra gaming, que não é bem o motivo desse artigo, eu uso um controle de Xbox cabeado. Não parece legítimo, mas serve pra jogar e custou barato.

Motospeed Inflictor CK104 NKRO Gaming Mechanical Keyboard - Red Blue Switch
Esse teclado eu adoro. Amo de paixão. É um teclado do tipo blue key. Não é extremamente barulhento mas faz um sonzinho que é gostoso pra mim (as pessoas em volta não devem achar tão gostoso assim). Faz eu lembrar dos teclados IBMs da faculdade, dos RS6000. Esse teclado é tão bom que comprei logo 3. Um eu uso em casa, o outro no trabalho. O último eu dei de presente. E pela quantidade de sujeira (momento de vergonha) podem ver que uso muito esse teclado. Além do som, o fato de usar teclas que tem uma mola mais forte ajudam a não ter aquela dor nos dedos de reumatismo. Então como um bom samurai tem sua espada e cuida dela pois dela depende sua vida, o mesmo aplica-se pra quem trabalhar com TI: invista num bom teclado e de preferência mecânico. Seus dedos o agradecerão. Esse por acaso eu comprei numa promoção durante o Black Friday chinês (10 de novembro?).

TecTake Bürostuhl Drehstuhl Racing Schalensitz - Diverse Farben -
Outro item de suma importância é uma boa cadeira. Essas cadeiras gamers são as melhores e não custam tão caro. Eu não pude comprar uma melhor por falta de espaço pra colocar mas tenha uma boa cadeira já que passará muito tempo sentado. Na empresa eu tenho uma cadeira muito melhor que essa e com ajustes que a fazem parecer uma espaçonave. É tão complicada que tivemos uma pessoa vindo dar curso em como ajustar a mesma. Essa minha é mais simples mas aguenta bem o tranco e permite eu ter uma posição de trabalho onde a lombar não fica cansada depois do dia. Evitem trabalhar na cama ou no sofá. Por mais que pareça legal no começo, sua coluna sentirá depois pois estará muito tempo trabalhando assim. Imagine se precisar ficar mais de 2 meses trabalhando de casa então?

Minha impressora está aí de enfeite. A tenho caso precise mas a tinta já secou faz anos. Uso em geral o scanner pra documentos. Deixo a foto do bolo de aniversário de 25 anos do Debian pra mostrar que um dia ela realmente imprimiu alguma coisa. Se seu trabalho exige impressão, recomendo comprar uma multifuncional dessas. Eu sempre compro Lexmark pois tem suporte out-of-the-box pra Linux. Vem até o Tux na caixa pra mostrar que tem suporte. E realmente funciona bem. Essa impressora tem também fax, mas assim como o botão do mouse, nunca usei e acho que se tentar agora deve explodir tudo.



Sobre a decoração... bom... não tenho muito o que dizer. Deixe o ambiente como quiser pois afinal é sua casa. Gosto da imagem do Tux próximo ao Kratos. Parece que ele está dizendo ao seu ouvido "relaxa, você vai conseguir sobreviver a essa quarentena desse vírus".
E acho que é isso. Se tiverem alguma dúvida que eu possa ajudar, só me contactar no twitter ou mesmo no telegram. No telegram peço somente que o façam pelo grupo https://t.me/linux_brasil pra me facilitar responder.
E por último, minha dica pra fechar bem o artigo:

Bebam chá! Não é brincadeira. O café aumenta a ansiedade e nesses tempos de isolamento o melhor é tentar manter a paz interior. No começo é difícil trocar o café por chá, mas com o tempo isso vai mudando. O chá me ajudou tanto que até o remédio pra controlar ansiedade eu consegui parar de tomar. E hidrata! Então, keep calm, bebam chá e bom home-office.

E sim, passo o dia inteiro de pijama. Camiseta de pijama sponsered by Nginx®.
Update: atualização do artigo em trabalhando de casa - atualização de 2021.
Update em 03-03-2023: adicionei o link pra monitor Samsung.
Resolvi aproveitar o início de ano (já não tão início assim) pra renovar a cara do site. Resolvi experimentar o gantry, que já tinha usado anteriormente.
Ainda estou ajustando as coisas mas aparentemente ficou com um aspecto melhor. Tirando o logo que ficou em tamanho homeopático.
Ao menos a renderização em diferentes tipos de tela deve melhorar (o google viva me reclamando sobre isso).
Ah... e o nome do tema é... Helium. Pra combinar com o restante.
Eu tenha plena certeza que um dos círculos do inferno de Dante é feito em GTK e roda Gnome. Certeza pura. Estou pra conhecer um widget mais porcaria que GTK. Não tem jeito de eu gostar dele, nem Gnome.
Eu já tinha escrito aqui sobre o problema com fontes em Fontes de aplicativos em GTK no KDE e também o problema com a mesma barra de rolagem em Corrigindo as teclas de rolagem em GTK. Mas descobri recentemente que o infeliz do leitor de mails evolution, feito em GTK, tem a maravilhosa barra de rolagem que desaparece.
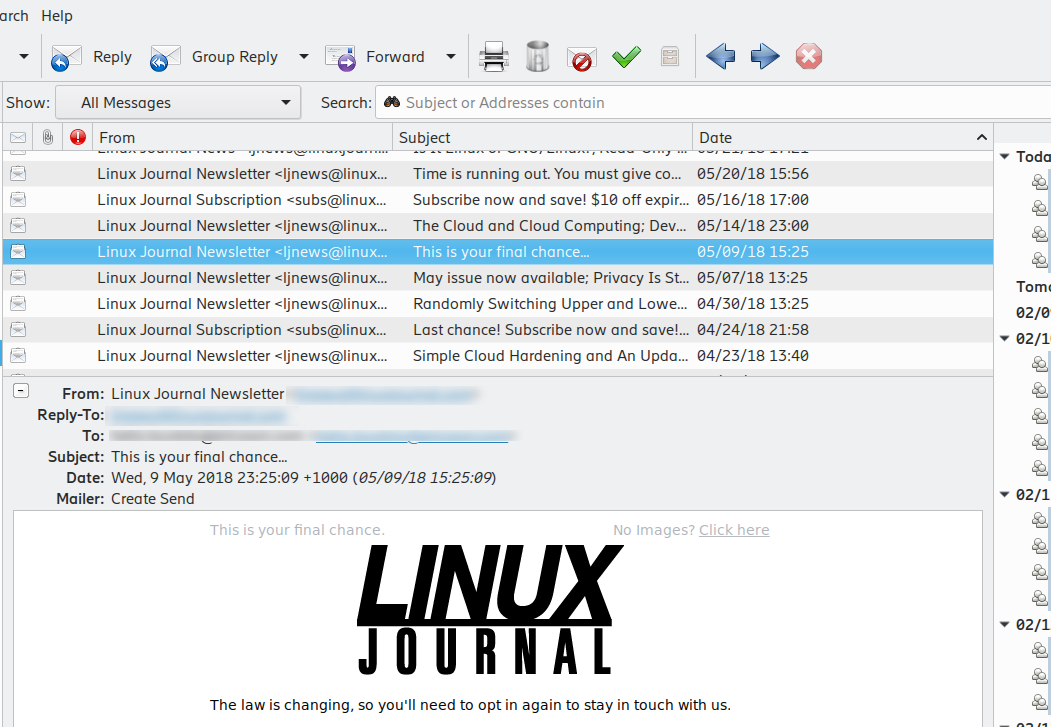
Antes de qualquer manifestação a respeito, sim estou mostrando as partes de mail da Linux Journal, que infelizmente fechou as portas definitivamente. E por isso as datas de 2018. Mas é só olhar a image que nota-se a falta das barras de rolagem, tanto pro texto quanto pras mensagens.
Garimpando na Internet achei dois artigos sobre o mesmo problema e como o corrigir:
https://forum.endeavouros.com/t/disable-scrollbar-fading/1488/4
https://techne.alaya.net/?p=19006
Basicamente uma solução sugere que em /etc/environment seja adicionado a variável "GTK_OVERLAY_SCROLLING=0". É possível já testar pelo terminal essa opção, o que não adiantou nada pra mim. Mesmo forçando o uso da variável com o comando:
helio@xps13ubuntu:~$ gdbus call \
--session --dest org.freedesktop.DBus \
--object-path /org/freedesktop/DBus \
--method org.freedesktop.DBus.UpdateActivationEnvironment '{"GTK_OVERLAY_SCROLLING": "0"}'A outra solução sugerida é adicionar em ~/.config/gtk-3.0/settings.ini:
[Settings]
gtk-primary-button-warps-slider=falseHá outros relatos dizendo pra usar "gtk-primary-button-warps-slider=0" mas também não deu muito certo para mim.
E essa é a parte horrorosa do GTK e Gnome. Não existe uma configuração simples de fazer. Tudo são comandos e configurações enfiadas em cantos escuros do sistema.
Como alguém consegue criar algo assim e achar bom? Eu realmente não entendo. E continuo procurando uma solução pro evolution, que é o cliente de mail padrão da empresa e não posso trocar por outro (mesmo porque se fosse em thunderbird, também é em GTK).
Por enquanto eu consegui amenizar o uso da barra de rolagem que aparece com o mouse passando sobre ele com uam configuração de estilo no GTK.
helio@xps13ubuntu:~$ cat ~/.config/gtk-3.0/gtk.css
scrollbar, scrollbar button, scrollbar slider {
-GtkScrollbar-has-backward-stepper: true;
-GtkScrollbar-has-forward-stepper: true;
min-width: 15px;
min-height: 15px;
border-radius: 0;
}Não está bonito, mas funciona melhor que a versão anterior.
E após um reboot indesejado, aparentemente o GTK_OVERLAY_SCROLLING deu certo e as barras apareceram definitivamente.

Foi um ano bastante parado aqui no site em relação a postagens. O único post que escrevi foi sobre Skyrim (e no momento estou tirando férias de fim de ano e estou jogando novamente).
Verdade seja dita que outras mídias sociais acabam roubando a atenção pela facilidade uso e de publicação (um dedo de distância por um app). Mas eu podia ter feito melhor, com certeza.
Ainda estou me recuperando de um burnout que tive em 2018 mas isso por si só não justifica essa lacuna aqui.
Por outro lado eu consegui aumentar minha participação em outros eventos, principalmente online. Aqui estão meus 2 vídeos durante a última PyCon Sweden:
Pode não parecer mas além de ter trabalhado na organização da conferência eu também fiz essa abertura marota no vídeos (que toca a musiquinha). Ficou bacana, não ficou?
Também tive a oportunidade de participar num evento 100% online sobre python chamado pyjamas (https://pyjamas.live). Como participo da organização da PyCon na Suécia eu realmente dedico pouco tempo pra eu mesmo apresentar alguma coisa. Mas dessa vez eu fiz um live coding de um bot pra telegram. Foi muito legal a experiência. E divertida.
Então basicamente isso é um resumo mais técnico do que foi meu ano de 2019.
Eu quase não publiquei nada aqui mas também comecei a mexer mais com go, que é uma linguagem bem legal de aprender e usar. É compilada e te dá bastante desempenho ao usar, mas tem um estilo de código mais fácil pra se escrever um programa que java por exemplo. A única coisa que às vezes me dá um nó na cabeça é que go usa a definição de tipo depois do nome da variável. E funciona de forma semelhante ao criar funções. Mas com o tempo a gente acaba acostumando (e depois apanha pra escrever algo em C, C++ ou mesmo Java).
Bom... é isso. E esse ano já coloquei como meta publicar mais por aqui.
Até o próximo post (e que não seja em 2021).
Estamos em maio de 2019 e até agora não escrevi nada por aqui. Um pouco por falta de tempo, mas a verdade é que a preguiça e procrastinação estão tomando conta de mim. Então resolvi fugir de assuntos mais técnicos e falar de dragões, de Skyrim.
Já jogou Skyrim? Não? Recomendo fortemente. É um jogo estilo RPG e longo, mas bem legal de jogar e não cansativo como Witcher 3 ou Fallout 3 e 4.
Antes de falar do jogo em si, vou descrever um pouco das plataformas. Plataformas? Sim! Adoro tanto o jogo que comprei pra consoles e pra PC.
Quem ganha? Não sei dize a resposta pois muito vai de gosto. Mas comparando alguns quesitos que sempre entram na discussão.
Esse foi o primeiro console que comprei o Skyrim. Em termos de custo foi o que paguei mais caro. Mas o motivo foi que comprei como 1 anos após o lançamento. O valor já era mais baixo que o preço de lançamento, mas foi muito mais caro que nas outras plataformas pelo fator de idade do jogo. Diferenças gráficas? Não percebi muita coisa. O jogo parece o mesmo. Mudança no roteiro do jogo? Não. Tudo segue do mesmo jeito, inclusive onde achar mais dinheiro ou relíquias. O único ponto que era chato no Xbox3 60 era a transição de telas quando entra ou sai de algum lugar como castelo ou caverna. O tempo era tão longo que eu podia checar o twitter, postar alguma coisa e a tela ainda não tinha carregado. Na época não me importei tanto mas hoje em dia é notável a lentidão pra carregar essas transições. E travamentos! Eventualmente o Xbox 360 dava uma travadinha pra nos lembrar que por mais que não fosse Windows, ainda era Microsoft.
Durante uma promoção de Black Friday acabei comprando um Playstation 4. Paguei 200 euros mas mesmo assim achei que foi caro demais pra um console que nada mais é que um upgrade do Playstation 3 (e sim, tenho também um Playstation 3, mas não tenho Skyrim nele). O que jogar? Sim! Skyrim. O valor já foi mais baixo que o que paguei pro Xbox 360 mas no pacote ainda vieram dois DLCs, o de Dawnguard que entram os vampiros no jogo e o Dragonborn que enfrenta outro como você, que absorve as almas dos dragões, mas tomou um rumo de vilão na vida (lado negro da força?).
Minha primeira decepção foram os gráficos. Esperava um baita upgrade em relação ao Xbox 360 mas no fim ficou a mesma coisa. Se sombreado ou efeito da água melhorou, eu realmente não percebi. A jogabilidade ficou exatamente a mesma, com baús, dinheiro e prêmios todos basicamente nos mesmos lugares. A transição de telas ficou bem mais rápida no Playstation 4 se comparado com Xbox 360.
Acabei fazendo um upgrade no meu PC e entre placa mãe nova, nova CPU, e mais memória, eu acabei adicionando um placa NVIDIA. Ao contrário dos consoles, PC é preciso passar a configuração pois cada um monta o que quiser. Minha configuração de PC é a seguinte:
Eu fiz o upgrade sem intenção de somente jogar mas de ter um PC pra fazer de tudo. A grande mudança que aconteceu foi o lançamento o Proton da Steam, que, baseado em Wine, permite rodar os jogos de Windows em Linux. Sobre o lançamento do Proton e estado atual da Steam sobre Linux com certeza não vou entrar em detalhes aqui, mas vale um outro artigo.


Agora descrevendo o Skyrim no PC. Com as configurações no máximo, ultra, tive problema de "stuttering", da imagem quebrando, sem fluidez. Mesmo diminuindo os efeitos pra médio não consegui resolver o problema. De longe a versão pra PC é a que tem mais bugs em relação aos outros. É bem comum atirar uma flecha em alguém na sua frente e... a flecha passar direto e acertar a parede. Fora erros de renderização de tela. Até agora não consigo entrar na água pois fica um borrão na tela e não vejo nada. Poderia dizer que são bugs do proton mas pela quantidade de gente reclamando em fóruns na Internet e rodando Windows, parece ser bug do jogo mesmo.
Agora ponto positivo: a imagem ficou melhor. Ah... ficou com um pouco mais de contraste, mas nada pra dizer que é muito melhor que console. Mas a transição de cenas... ficou um espetáculo. Entrar em um castelo leva coisa de 5 segundos. Isso sim foi algo a se elogiar.


Descrevi até o momento as plataformas mas não comentei nada do jogo. Talvez porque seja um jogo já antigo e dificilmente não se ouviu falar dele ou o jogou. Se esse é o seu caso, pode continuar lendo.
Skyrim é um jogo estilo RPG que lembra o modo de Fallout 3. Não é tão maçante quanto o Fallout 3 pra jogar, mas é um mundo aberto cheio de side quests que ajudam a melhorar seu desempenho no jogo. A história é que Skyrim repentimante se vê atacada por dragões. Ao ajudar a enfrentar um dos dragões, você se descobre herdeiro de um poder que absorve a alma do dragão abatido, um "Dragonborn" que será seu apelido durante o desenrolar do jogo. A estória toda é baseada em tentar vencer os dragões usando um "elder scroll" (velho pergaminho?). O jogo usa o sistema de gamefication, garantido bônus a cada etapa vencida, aumentando seu ranking, e dando possibilidade de desenvolver as habilidades que achar mais necessárias.
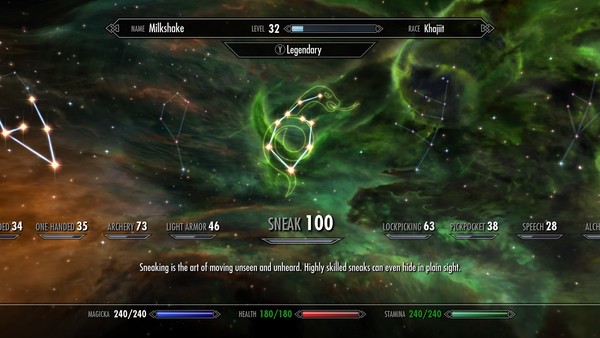
No início do jogo é preciso escolher um nome e um rosto para seu personagem. Eu já joguei com todos nomes possíveis e imagináveis: Stallman, Systemd, Milkshake, Jessica Jones, Querida, Ada, etc. E sim, joguei tanto com personagens do sexo masculino quanto feminino.
Há diferença entres os personagens ou sexo? Personagens do sexo feminino sofrem ataques constantes de chauvinismo. Escolha uma loira nordica de olhos azuis e todo guarda de todo lugar vai tentar te passar uma cantada, que não influencia em nada no jogo. Escolha uma Ork e todos dirão que sua cara está horrível. Do sexo masculino os comentários costumam ser mais genéricos. Mas entre as raças disponíveis, Ork, nórdico, bretão, khajiit (felinos), argoniano (lagartos), e elfos o resultado é praticamente o mesmo. Então seja feliz em montar alguém com a cara que gostar, inclusive com cicatrizes e pinturas de guerra, e comece a jogar sem preocupação no impacto que isso terá na estória do jogo.
Nota: boa parte do jogo você estará usando um capacete ou mesmo máscara, então não se preocupe muito em botar um cabelo muito maneiro ou um pintura fantástica.

Durante o desenrolar do jogo, é possível visualizar seu personagem em terceira pessoa ou em primeira pessoa, estilo FPS. Isso ajuda bastante na jogabilidade.

Entre as várias habilidades que pode evoluir ao longo do jogo, eu acabei sempre optando por "sneak" e "archery". Com ambas desenvolvidas, fica muito mais fácil esgueirar-se dentro de castelos ou cavernas e matar os inimigos com o mínimo de sangue derramado, principalmente o seu sangue. Já tentei ir com uma raça mais forte, como Ork, e entrar de peito aberto em lutas e melhorar a habilidade de armas de uma mão ou de ambas as mãos, mas o resultado é que você acaba morrendo a maior parte das vezes.
Outro detalhe: ao evoluir o uso do arco, você desenvolve o poder de dar um zoom no alvo e até mesmo ter um efeito de slow motion pra acertar. Então é um atributo bastante prático.
Entrar sorrateiramente é chave pro jogo todo. E um dos side quests que te ajuda nisso é a dos "thiefs guild".

Outra habilidade que também gosto de desenvolver é de mágicas, principalmente a de "conjuration". No meio de uma luta chamar um "astronarch" sempre ajuda, seja pra te defender ou seja pra roubar o foco do inimigo enquanto você ataca por trás.
Depois de jogar tanto eu já sempre sigo o mesmo roteiro. Aliás recentemente descobri que é possível fechar quase todos os side quests sem nem mesmo ativar o poder de Dragonborn, o que significa não visitar Whiterun e ir direto pras outras cidades pra iniciar os side quests.
O primeiro que sempre faço é da escola de magia em Winterhold. É um side quest com poucas missões e rapidamente é possível adquirir poderes mágicos. Ao terminar o side quest, você está na posição de archmage da escola, então ganha um quarto (o principal) onde fica fácil guardar tudo quanto for cacareco que for recolhendo ao longo do jogo.
Em seguida eu em geral sigo ou o side quest dos "thiefs guild" em Riften ou "dark brotherhood". Se for seguir a de ladrões, é preciso adquirir o poder de Dragonborn pra seguir até o fim.
O quest do "thiefs guild" termina por te conceder um roupa de nightingale, que é ótima pra jogar o restante no modo stealth.
O quest do "dark brotherhood" você assassina o imperador de Tamriel e permite desenvolver o ataque por trás com uma adaga. Vira um modo eficiente de eliminar qualquer inimigo, por mais forte que seja. No início do quest, é possível virar-se contra os "dark brotherhood" e daí o quest vira pra eliminar todos eles. Mas é muito mais legal virar um assassino. Não é todo jogo que a gente mata o imperador.
Esses com esses side quests terminados, seu poder de "sneak" já estará em 100%. Com isso todo o restante do jogo ficará bem mais fácil e simples.
Existem outros side quests relevantes? Existem vários side quests, mas relevantes mesmo são só esses 3. Outros te darão uma arma ou uma peça de roupa (capacete, armadura, etc), mas nenhum é tão completo como esses 3.
E a guerra? A estória desenvolve-se em meio a uma guerra entre império e rebeldes, liderados por Ulfric Stormcloack. É possível inclusive não escolher lado nenhum e seguir o jogo. Em determinado ponto um acordo de paz será feito na escola dos Greybeards pra enfrentar os dragões.
Minha opção? Eu acabei gostando mais de ajudar os rebeldes. As missões são mais interessantes. O lado legal é que a maioria dos Jarls, prefeitos das cidades, são trocados ao vencer a guerra. Mesmo o Jarl de Whiterun é deposto.
Acho o que tinha de descrever do jogo é isso. Espero que tenha animado a experimentar quem nunca jogou e tentar conquistar toda Skyrim. Boa diversão!
Page 16 of 39
