Renovando meus votos pra 2023.
*Nota: esse artigo foi originalmente escrito pra Revista Espírito Livre, mas como a edição não saiu estou postando aqui.

Olá leitores da Revista Espírito Livre. Eu venho do futuro pra falar sobre os 30 anos de Linux. Futuro muitos anos à frente? Sinto mas estou apenas algumas horas adiantado devido ao timezone em que vivo. Mas tenho um certo prazer em dizer que celebrei a chegada do ano novo antes que todo mundo no Brasil, e avisando o que os aguarda do futuro (geralmente nada). E vamos ser sinceros: no mundo de hoje com tanta gente acreditando em terra plana, rejeitando vacinas e tomando cloroquina, dizer que venho do futuro é até uma licença poética aceitável.
Mas vamos voltar ao assunto do artigo: Linux. E seus 30 anos de vida. Foi uma comemoração bem moderada, sem grandes festas, sem bolo pra comemorar, e nenhuma meetup organizada. Ao menos por aqui. Talvez a culpa fosse da pandemia. Talvez fosse porque Linux já é tão comum e seu uso é diário, o que não nos faz mais sentir que seu aniversário é uma data especial. Mas são 30 anos desde que um estudante finlandês tentou escrever um minix melhor que o minix, um sistema operacional Unix para estudantes, e achou que nunca seria tão grande quanto o projeto GNU.
Não, não vou entrar na polêmica de quem é maior que quem entre GNU e Linux. Ambos têm seus méritos e são gigantes. E não estaríamos onde estamos sem eles. O projeto GNU já completou 38 anos também no dia 27 de setembro, mas o artigo é sobre Linux. Então deixo meus parabéns ao projeto GNU mas tenho de dizer que mesmo o sistema operacional mais comum que usamos pelas distros sendo um GNU/Linux, é Linux que o chamamos. Isso começou desde muito tempo atrás e duvido que mude algum dia. Alguns podem insistir em chamar de GNU/Linux, mas se até mesmo o Debian mudou de Debian GNU/Linux pra simplesmente Debian, que diremos de Linux além, é claro, de apenas Linux? Nomes curtos têm tendência a ficar melhores e as pessoas relacionam-se com isso mais facilmente.
Parte dessa tradição de denominação veio como herança de como eram os sistemas Unix nos princípios dos tempos, ou anos 70 em Unix time. Primeiro existiu o Unix da AT&T, em seguida surgiu uma melhoria desse que ficou conhecida como BSD, de Berkeley. E assim foi por quase 10 anos. O Unix BSD era basicamente o mesmo Unix, mas com drivers, ferramentas, scripts e até sistema de boot de Berkeley. E era o sistema operacional completo, com kernel, bibliotecas, editores, shell, etc. Mesmo os sistemas que surgiram da compra da licença do Unix da AT&T, como SunOS da Sun – atual Oracle, eram sistemas operacionais completos mas com nomes curtos como SunOS, HP-UX, SCO, Xenix, etc.
Quando o bom doutor, Richard Stallman, teve a epifania de criar um sistema operacional totalmente livre, o sistema operacional GNU – pra poder dizer que GNU não era Unix (GNU is Not Unix), nunca pensou em criar tudo de forma coesa. Ele começou da forma simples e em partes. Primeiro as ferramentas: editor (se bem que emacs é mais uma religião que editor mas isso é assunto pra outro artigo bem mais longo que esse), compilador, shell, etc. Mas tudo era separado em seu repositório e era necessário baixar os fontes e compilar sua versão usável. Então nunca houve uma identidade de sistema operacional GNU. Era a biblioteca sunsite com ferramentas GNU. Até surgir o Linux e permitir criar um sistema operacional completo. Claro que pra isso foram necessários os surgimentos das distros, um encurtamento para distribuições, que empacotavam o Linux com GNU e distribuíam como sistema operacional.

E Linux nasceu como um kernel, como já descrevi antes no “um minix melhor que o minix”, mesmo que Tannenbaum discordasse disso, e cresceu tanto em linhas quanto em contribuidores e até mesmo em ecossistema. Hoje em dia Linux é um projeto, uma fundação. E abrange de redes à containers com OCI, Open Container Iniciative. E apesar de ter nascido pra rodar software da GNU como bash e ser compilado com GCC, hoje em dia já roda em sistemas sem nada da GNU como Alpine e Android. E compila com o llvm. Não totalmente como com GCC, mas é um trabalho em andamento e deve em algum momento tornar o Linux compilável com qualquer compilador C. Isso sem comentar o suporte à linguagem rust, que poderá talvez nos próximo 10 anos virar boa parte do código do kernel. Talvez até a maior parte dele. Quem sabe?
Desses 30 anos eu já comentei sobre os surgimento das distros. Falta escrever sobre o desaparecimento delas. Atualmente o site distrowatch, famoso por enumerar as distros que surgiam, parece mais um obituário. A grande maioria das distros que surgiram também sumiram. Não que alguém vá sentir falta da Bieber Linux ou da Hanna Montana Linux, mas sei de gente que até hoje chora a perda do – um momento pra respirar e segurar a náusea – kurumin. A maioria dessas distros recebeu a alcunha carinhosa no Brasil de REFISEFUQUIs. Aqui peço a ajuda ao amigo Fábio Benedito pra descrever o que são:

As REFISEQUIs mostraram um lado interessante sobre a liberdade do software livre: cada um podia e ainda pode fazer um fork de alguma distro e criar a sua própria. Ao contrário das distros que contavam com legiões de voluntários ou funcionários, dependendo se fossem empresas ou projetos voluntários como Fedora e Debian, as REFISEFUQUIs eram batalhas de um soldado só. Talvez dois. Mas não muito mais que isso. Conseguiam fazer o primeiro release, o segundo, então o... o... o... acabava o gás. Talvez algumas tenham ido um pouco mais longe que isso, mas ninguém sobrevive ao tempo sem organização e principalmente mãos pra ajudar a manter tudo funcionando. Talvez o propósito fosse somente ter seu sistema listado na distrowatch. Nesse caso tenho de admitir que a missão foi cumprida. Amigos, amigos, negócios à parte.
E o que dizer das empresas? Nesses 30 anos muitas delas surgiram pra levar o Linux pra todos como principal sistema operacional do desktop. Inclusive com a versão tupiniquim com a Conectiva. E eram muitas. Infelizmente o cenário atual conta com apenas algumas delas. As que não faliram sofreram um processo de compra ou fusão. E eventualmente faliram. Talvez a venda de software gratuito não fosse tão bom negócio assim? A venda da Red Hat pra IBM por mais de 34 bilhões de dólares dizem o contrário. O que faltou então? Talvez menos geeks programadores e mais pessoas de negócios gerenciando a empresa? Talvez. A verdade é que muita coisa foi feita sem muito planejamento e só imaginando bastasse o software ter licença GPL ou qualquer outra livre e seria o suficiente pra empresa sobreviver. Infelizmente a realidade mostrou que não era bem isso.

E não só de dramas empresariais viveu o Linux nesses 30 anos. Teve também o caso da vira-casaca Caldera Open Linux, que comprou o que sobrou da SCO e aplicou um processo por roubo de propriedade intelectual contra o Linux. O caso ficou anos num tribunal e finalmente teve um fim. Os gestores da massa falida da empresa, que por motivos óbvios não conseguiu sobreviver no negócio, fechou um acordo muito bom de mais de 14 milhões de dólares com a... IBM!? Não me perguntem o porquê da IBM ter sido envolvida em suposto roubo de propriedade intelectual do Linux, mas no fim ela comprou o que sobrou de patentes e propriedade intelectual e encerrou o assunto.
Outro caso de tribunal nesses 30 anos de Linux que ficou muito famoso foi a prisão de Hans Reiser, criador do filesystem reiserfs, um dos primeiros filesystems com journaling no Linux e que eu pessoalmente cheguei a usar, acusado de assassinato. Não que sua prisão tenha alguma relação com Linux. Pelo contrário. Mas foi algo que impactou a direção dos filesystems em Linux, que estavam em suas infâncias no mundo journalling. Depois de sua prisão eu fui movido por, digamos, forças superiores a usar o XFS que foi doado pela SGI ao Linux. E até hoje é meu filesystem predileto, junto com LVM.
Outro drama vivido na lista do kernel durante esses 30 anos foi o eventual sumisso do próprio Linus Torvalds seguido da introdução de um código de conduta,vonde ele mesmo aceitava que tinha um comportamento tóxico e que precisa fazer terapia para endereçar seus problemas de uma melhor maneira. Não faltou gritaria em relação ao código de conduta com ataques dizendo que o mesmo iria coibir a participação das pessoas no desenvolvimento do kernel. Atualmente ninguém questiona o quão benéfico foi esse código de conduta, assim como quão tarde veio a ser adotado. E, claro, ainda há quem diga que ele motivou muita gente a não participar mais do desenvolvimento. Quantos? Esse será um dado que nunca veremos.
E ao longo desses 30 anos do Linux vimos também a grande batalha dos sistemas de inits, onde systemd saiu como vencedor e upstart virou lembrança. De todos os males ditos sobre o systemd na época, poucos realmente aconteceram, se é que aconteceram. E justiça seja feita: systemd é muito, mas muito mais que um mero sistema de init.
Claro que algumas distros seguem longe do systemd, como se isso fosse algum certificado de pureza. Mas nada que abale a realidade de que systemd funciona, vai muito bem obrigado, e trouxe flexibilidade e robustez ao Linux. Se antes precisávamos de gambiarras pra monitorar se um daemon não tinha dado crash e fechado inesperadamente, agora apenas temos o systemd lá monitorando e garantindo tudo funcionando. Ou quase. Claro que aparecem uns problemas aqui e ali, mas nada que negue o fato de que systemd melhorou muito a forma de como Linux tem seus daemons rodando.
crond? Coisa do passado. systemd tem agendamento de tarefas e substitui completamente o crond, que por sua vez poderia ter um crash e simplesmente parar de funcionar. E não para por aí o canivete suíço de funcionalidades do systemd.
E nesses anos vimos como Linux chegou ao mundo dos games. Primeiramente de forma modesta com jogos portados pela Loki games. Depois de um tempo de silêncio e de abandono, uma voltou triunfante com o suporte da Steam, a gigante de jogos digitais.
Mas mesmo a Steam passou por maus bocados. Sua estratégia de abraçar o Linux foi para fugir dos braços da Microsoft, que na época mudava sua visão sobre jogos com o Windows 8, tentando forçar os jogadores a usarem sua própria loja de jogos. Então pra ter massa de manobra e poder negociar, a Steam abraçou o Linux. E lançou seu próprio sistema operacional chamado SteamOS, baseado no Debian. E foi um sucesso. Ou quase isso.
A quantidade de jogadores em sistemas Linux chegou a dobrar de 1 para 2%. Mas não mais que isso. Apesar de todo o suporte, o uso nunca cresceu como esperado.
Mas foi o suficiente pra dar o que a Steam precisava: algo pra negociar e tempo. E com o tempo o CEO da Microsoft foi trocado, e por um que tanto declarou amar Linux, e abraçou definitivamente dentro da empresa, assim como provavelmente chegou num acordo com a Steam. E ficamos sem muitas novidades.
Isso até pouco tempo atrás, quando a Steam anunciou novamente algo bastante interessante: Steam deck. Basicamente um PC portátil com tela e controle conectados que permite jogar em qualquer lugar seu catálogo de jogos e... rufem os tambores... rodando Linux. Dessa vez a escolha foi o Arch Linux, a nova distro do pedaço que todo mundo ama. Eu incluso.
Essa nova estratégia da Steam muda seu foco de apenas ser uma plataforma digital de jogos pra vender console de jogos, competindo com Playstation, Xbox e Nintendo Switch. Por outro lado a maioria dos jogos continuaram não sendo nativos pra Linux, mas rodando através de um wine melhorado da própria Steam, o proton. Se chegou agora e não conhece o wine, esse é um software que faz uma tradução das chamadas de programas Windows para Linux. O resultado disso é a possibilidade de rodar programas feitos para Windows diretamente em Linux. E nisso acho que a mudança da Steam vai dar uma piorada pra jogos nativos em Linux. Que estúdio gastará tempo e pessoal pra fazer um jogo que rode em Linux quando pode fazer em Windows, o que provavelmente já fazem, e apenas trabalhar pra rodar bem em proton? Então é uma vitória com um certo gosto amargo de derrota.

Todo os anos eu além de dizer que estou no futuro na virada do ano, também digo que o próximo ano será o ano do Linux no desktop. E isso já faz uns... 15 anos? Talvez mais. Tanto que sempre uso a famosa imagem/meme do nerd dizendo isso (que aliás nem sei quem é pra dar os devidos créditos).
E esse ano nunca chegou. Não da forma que eu imaginava pelo menos. Atualmente o laptop chromebook é um dos mais vendidos para área de educação tanto nos EUA quanto na Europa. O Brasil não entra na conta por ainda viver um bom atraso tecnológico, mas aqui na Suécia minha filha tem seu chromebook na escola pra pesquisar e fazer os exercícios escolares. Na Suécia não houve um lockdown como em outros países durante a pandemia, mas alunos do colegial pra cima foram solicitados pra estudarem de casa. E cada um levou seu chromebook pra isso. E isso aconteceu em vários outros países, não somente aqui.
Sem contar que muitos desktops e laptops foram trocados por tablets e smartphones. Eu mesmo leio bastante em meu tablet Android e passo as manhãs lendo as notícias no meu smartphone (que diga-se de passagem tem a tela tão grande que praticamente precisei comprar uma calça nova e experimentar antes se ele cabia no bolso), também Android. Então a realidade de desktop que esperávamos não é mais aquela de 15 ou 20 anos atrás. Virou uma realidade de cloud, nas nuvens.
Mesmo que, pra desgosto de alguns, cloud rode no computador dos outros, atualmente é impossível fugir dele. Assim como tablets, smartphones, smartTVs, raspberrypis e muitos outros dispositivos, o cloud roda baseado em Linux. Linux virou o senhor supremo de todas as áreas. De geladeiras a super computadores, sendo presença prepobderante na lista dos 500 mais rápidos super computadores do mundo, sendo liderado atualmente pelo Fugaku do Japão com 7.630.848 núcleos de CPU e impressionantes 537.212 teraflops por segundo de desempenho de pico. Nesse é possível jogar minecraft sem lag.
Mas a discussão é no desktop, aquele ambiente dominado pela Microsoft. Sim, esse mesmo. Estamos em 2021 e ainda hoje as pessoas sofrem com vulnerabilidades e malwares enviados por mail no sistema de Redmond. Praticamente o mesmo problema desde que lançaram o Windows 95. E as pessoas continuam usando mesmo assim. Então eu duvido que Linux consiga entrar nesse mercado onde vírus e ransomware já são tidos como coisas absolutamente normais do dia a dia. Ele ficará naqueles que gostam de ter um sistema melhor, mais rápido e mais seguro.
E a liberdade? Sim, existem aqueles que usarão pela liberdade. E talvez por outros motivos. Mas isso não é importante, mesmo que pra eles sejam. O importante é que usem.
E aqui deixo escrito a mensagem que sempre passei e que sempre indignou muita gente: usem software livre. Não percam tempo com política, liberdade, filosofia, etc. Apenas usem se não for seu caso ainda. Isso abrirá portas para você.
Gostou? Então não fique só na instalação de uma distro. Ou de várias. Linux e outros software livres são baseados em... software. Então entre de cabeça. Aprenda a programar usando shell scripts. Depois vá pra linguagens como perl, python e nodejs. E não pare aí. Entre de cabeça.
Ajude um projeto pois tanto Linux quanto todo o ecossistema de software livre ainda dependem de voluntários, que estão ali pra ajudar e aprender. Então participe. Faça parte. Tenho certeza não se arrependerá.
Finalmente deixo aqui meu viva ao Linux e seus 30 anos.

Quando comecei a aprender Linux e Unix, no século passado, esses dois livros eram meus referenciais sobre ferramentas pra usar. Unix Power Tools e Unix System Administration Handbook. Foram e continuam excelentes livros, mas as ferramentas passaram a ser muito melhores. A grande maioria re-escrita em rust ou em Go! pra maior velocidade e até mesmo segurança.
Eu usava uma ferramenta aqui e outra ali até ler um artigo sobre o assunto e depois achar uma boa referência no GitHub. O artigo que li no começo eu já não lembro e não tenho o link, mas as ferramentas eu fui pegando por essa referência aqui:
https://github.com/ibraheemdev/modern-unix
Então vou listar as ferramentas que uso atualmente. Pegue a pipoca e sente bem confortavelmente que são várias. Não existe ordem de preferência e eu geralmente não adoto duas ferramentas pra mesma coisa. Mostro aqui o que é de uso no dia à dia de trabalho.
Eu estou colocando o link pra cada uma na imagem, mas a grande maioria funciona pelo sistema de pacotes das distros. Dê uma olhada nisso antes de baixar do site.
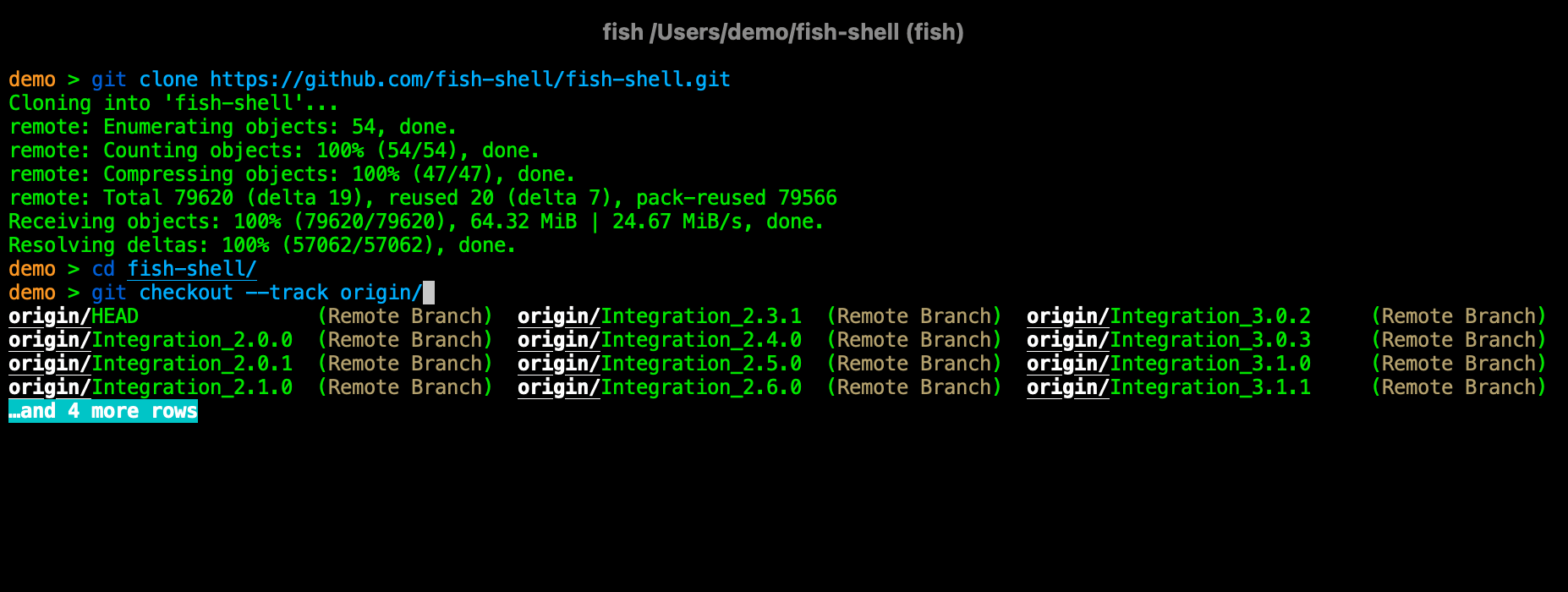
Eu sinta uma pena muito grande de ver quem fica preso ao bash nos dias de hoje. Não me entenda mal se você é uma dessas pessoas: bash é excelente. Mas existem alternativas muito superiores. Uma delas é o fish. Eu ouvi falar pela primeira vez do fish através do Kov na mesa do Debian numa das edições do FISL. E confesso que achei... aquilo não era pra mim. Eu estava confortável no meu bash. Eu não poderia estar mais enganado.
Na segunda tentativa, eu me forcei a usar o fish por no mínimo 6 meses. E o que aconteceu? Não consigo mais ficar sem ele. É o meu shell de linha de comando em todo lugar. Eu ainda uso o bash pra scripts, mas pra linha de comando, fish shell.

Esse eu conheci mais recentemente por uma dica do Mastodon. Eu sinceramente não lembro quem recomendou, mas lembro de bastante gente elogiando. Testei e gostei. É um formatador de prompt. Ao invés de ficar configurando temas no shell, é só botar o starship pra carregar no login e tá pronto.
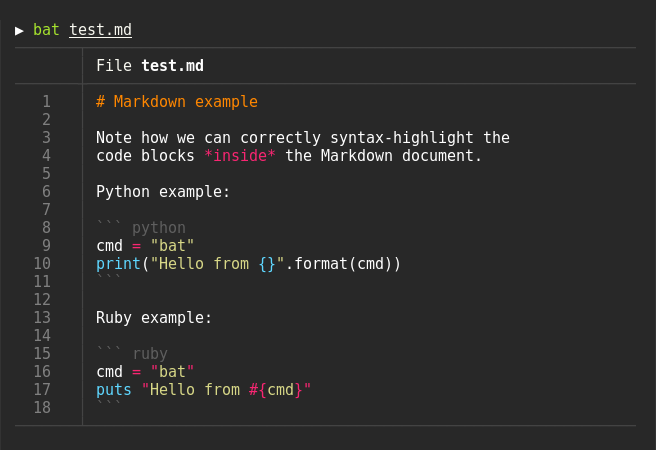
O bat é um substituto bem legal ao cat. É mais lento que o cat, mas traz ferramentas visuais com cores que facilitam olhar um arquivo. Isso te faz achar que a pequena lentidão pra ler o resultado vale o esforço, ou tempo.
Nota: por alguma motivo bizarro, no Ubuntu o binário instalado é batcat. Eu geralmente faço um link simbólico pra apenas bat.
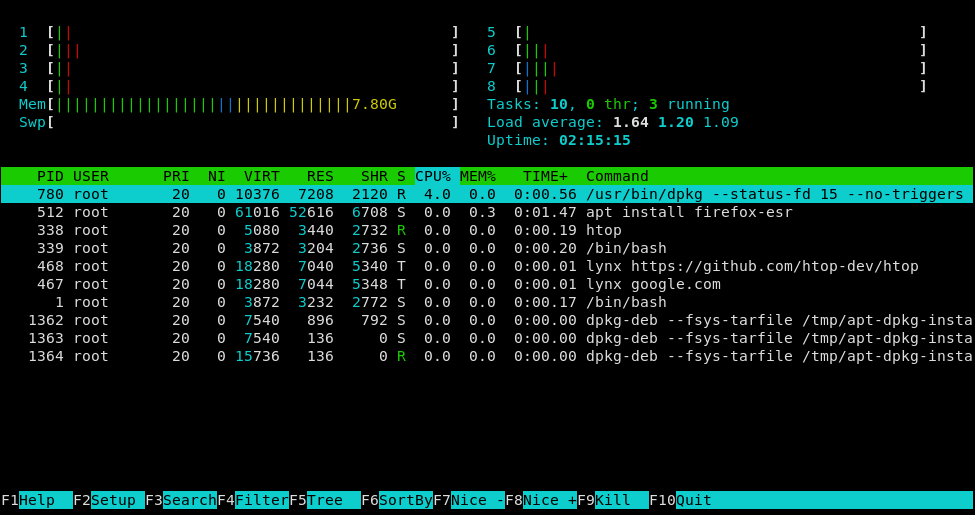
Esse é um excelente substituto ao "top". Bem mais gráfico e colorido. Eu nem considero algo tão moderno assim porque uso já faz mais de 10 anos. Mas recentemente descobri que tem gente que não sabe de sua existência. Então fica aqui na lista registrado.

Um programa que subtitui o "df" pra ver o tamanho e uso de partições.
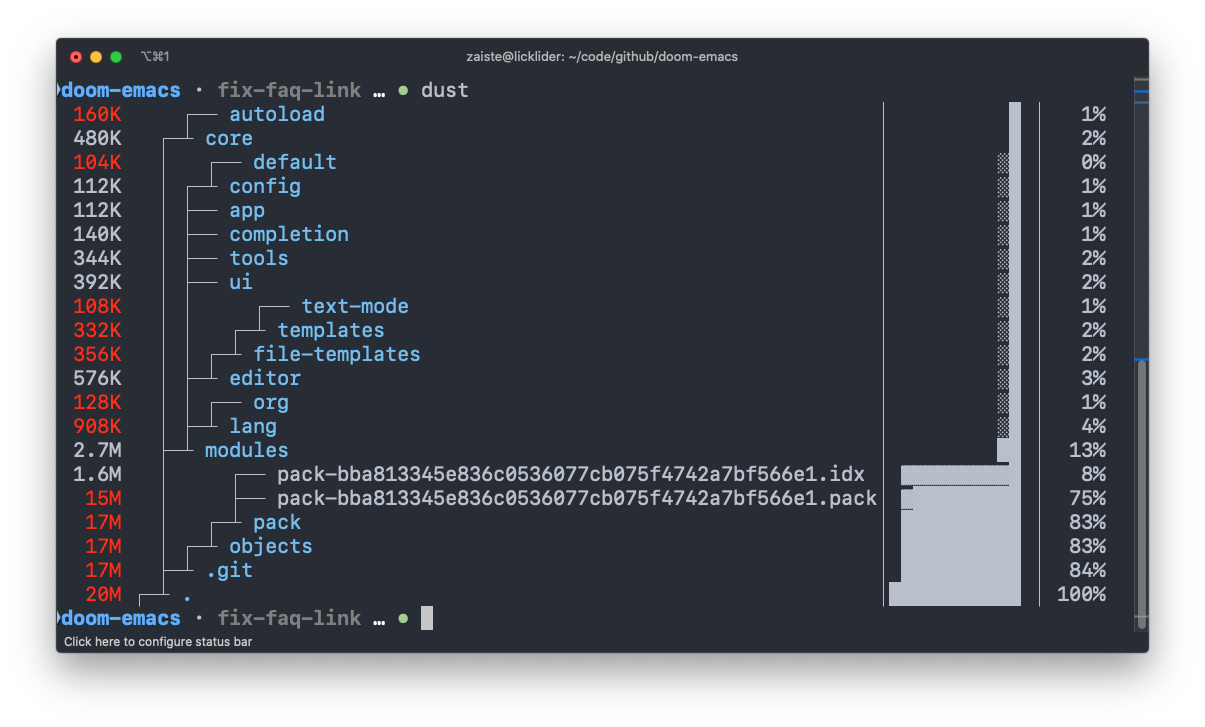
Usa o "du" pra ver qual o tamanho de arquivos e/o ou diretórios? Pois chegou sua evolução.
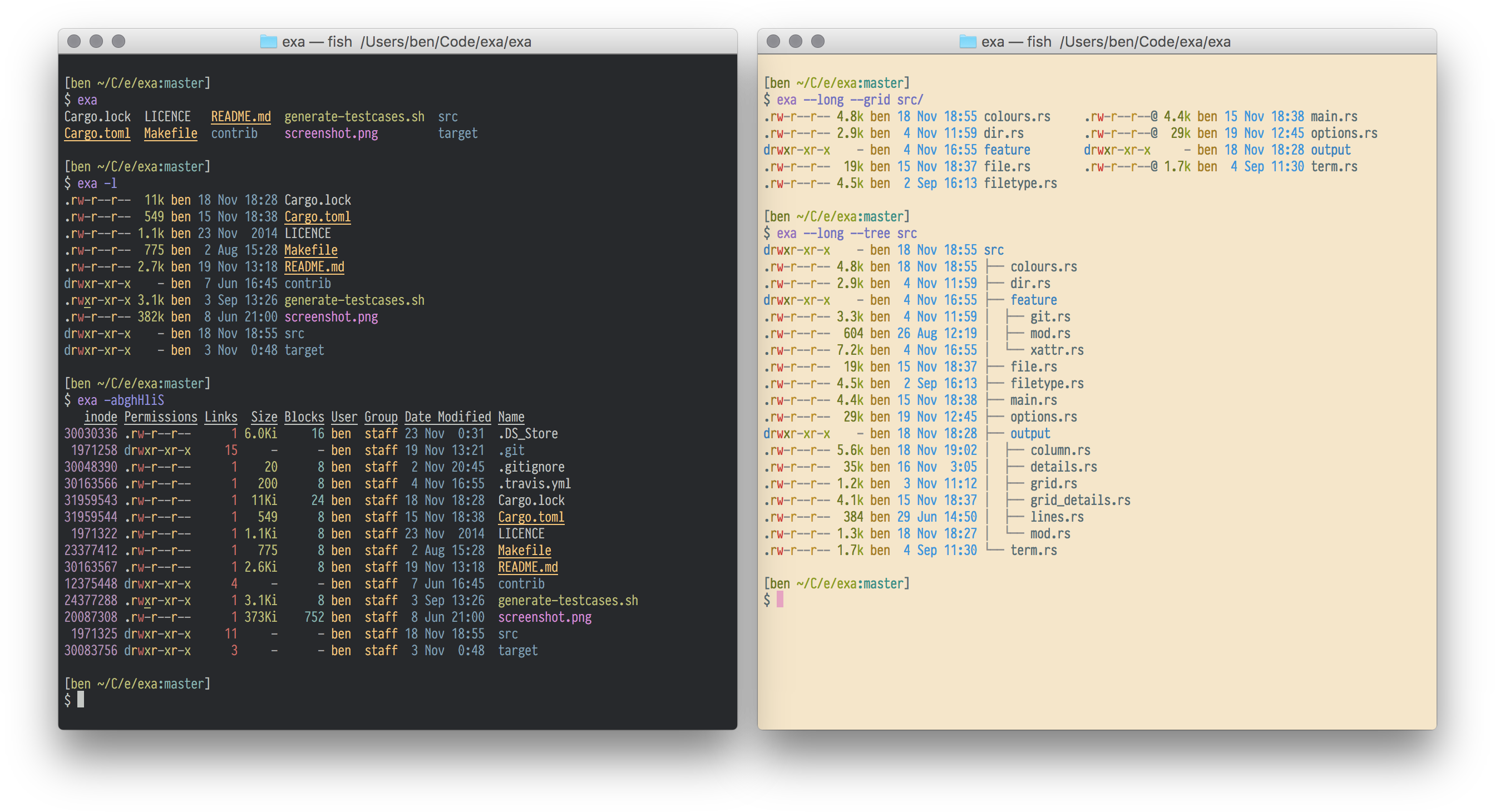
Esses são substitutos ao "ls". A sintaxe não é 100% compatível. Por exemplo "-tr" não funciona neles, mas você pode usar algo mais simples como "--sort=created". O programa começou como exa, que tem disponível no Ubuntu 24.04, mas no Archlinux passaram pra eza. Imagino que foi um fork porque o primeiro deve ter parado o desenvolvimento.
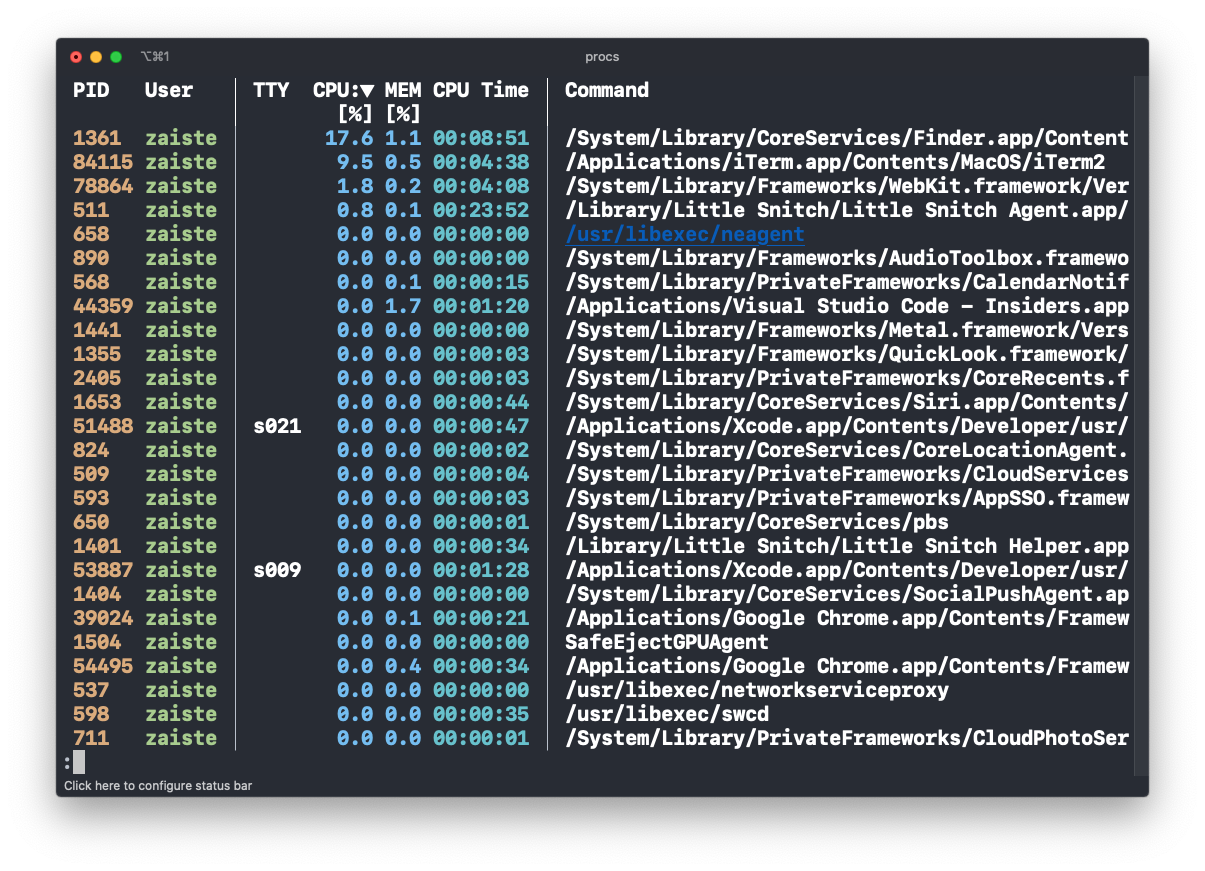
Ainda usa "ps" pra listar processos? E fica bolado que quando manda um "grep", o mesmo aparece na listagem? Pois o procs resolve esse problema.
O ripgrep, que apesar do nome tem como binário apenas "rg", é um excelente substituto do grep pra procurar em arquivos de determinado diretório. Ou diretórios. E bem mais rápido.
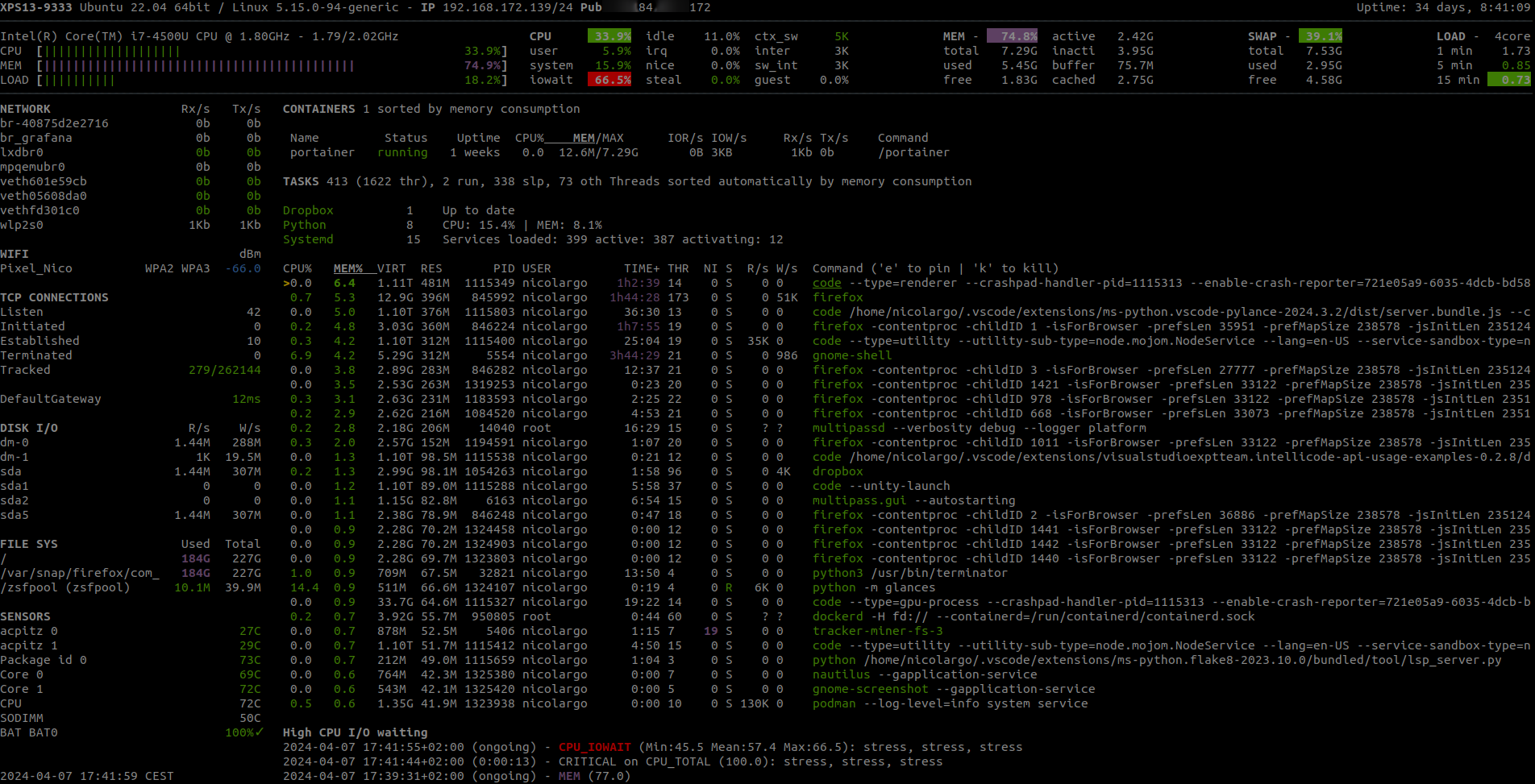
O glances é escrito em python. Legal, mas isso o torna lento pra iniciar. Mas depois que inicia, funciona bem. Ele é um melhoramento do "htop" com mais informação.
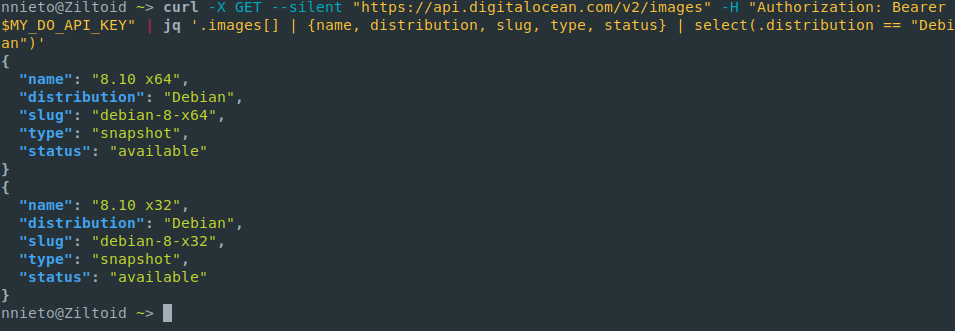
Se você mexe com kubernetes ou com arquivos json, jq é a ferramenta. Ajuda a filtrar e dá o resultado num formato colorido, o que ajuda a visualizar. E você pode construir filtros pros resultados. Existe uma outra ferramenta que é mais rápida, mas eu acabo usando o jq por causa da saída colorida (que ajuda demais).
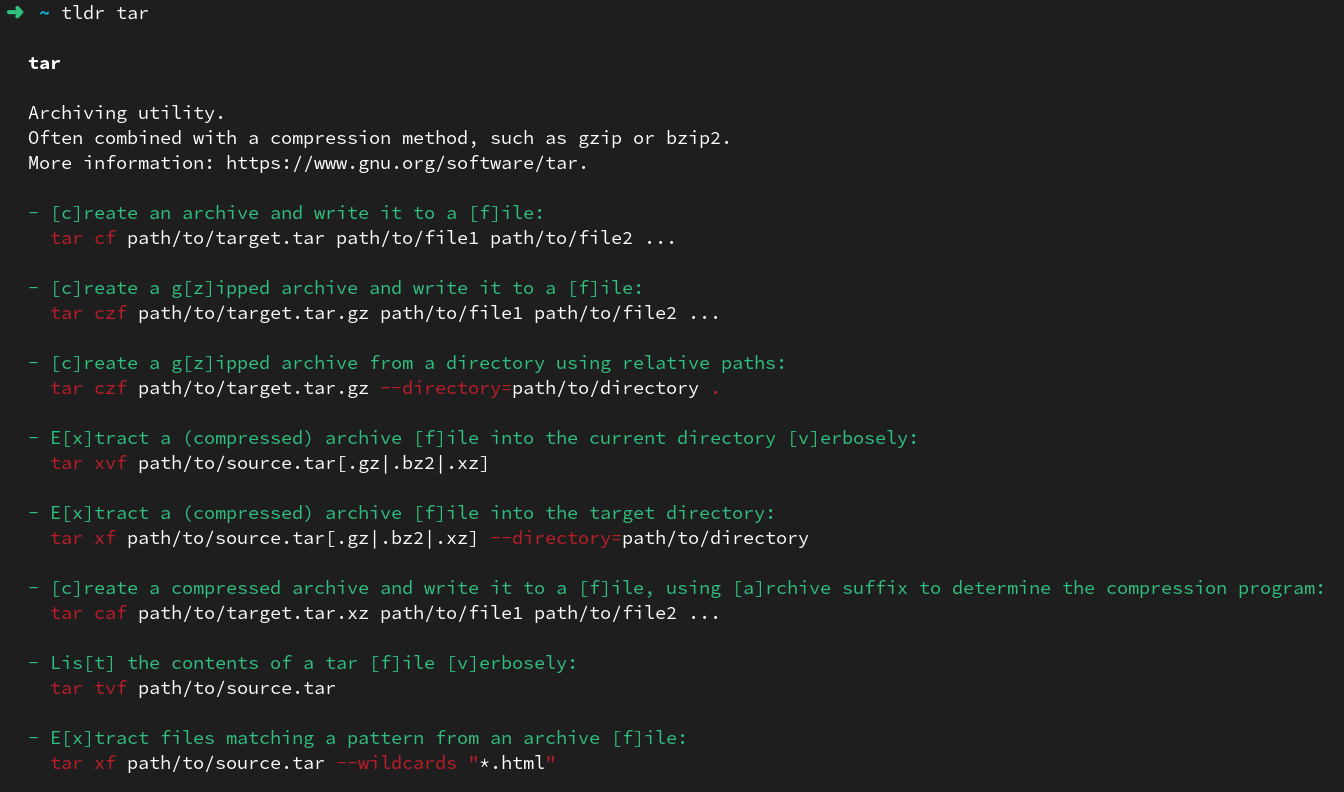
Sabe aquele problema de ler manpage e não ter exemplos? O tldr resolve essa parte. Baixa exemplos do comando que quiser usar.

No Ubuntu o pacote chama-se fd-find. E instala o binário como fdfind. Eu renomeio pra fd, tal qual é no archlinux e no macOS. É um melhoramento do find. Mais rápido e mais fácil de usar.
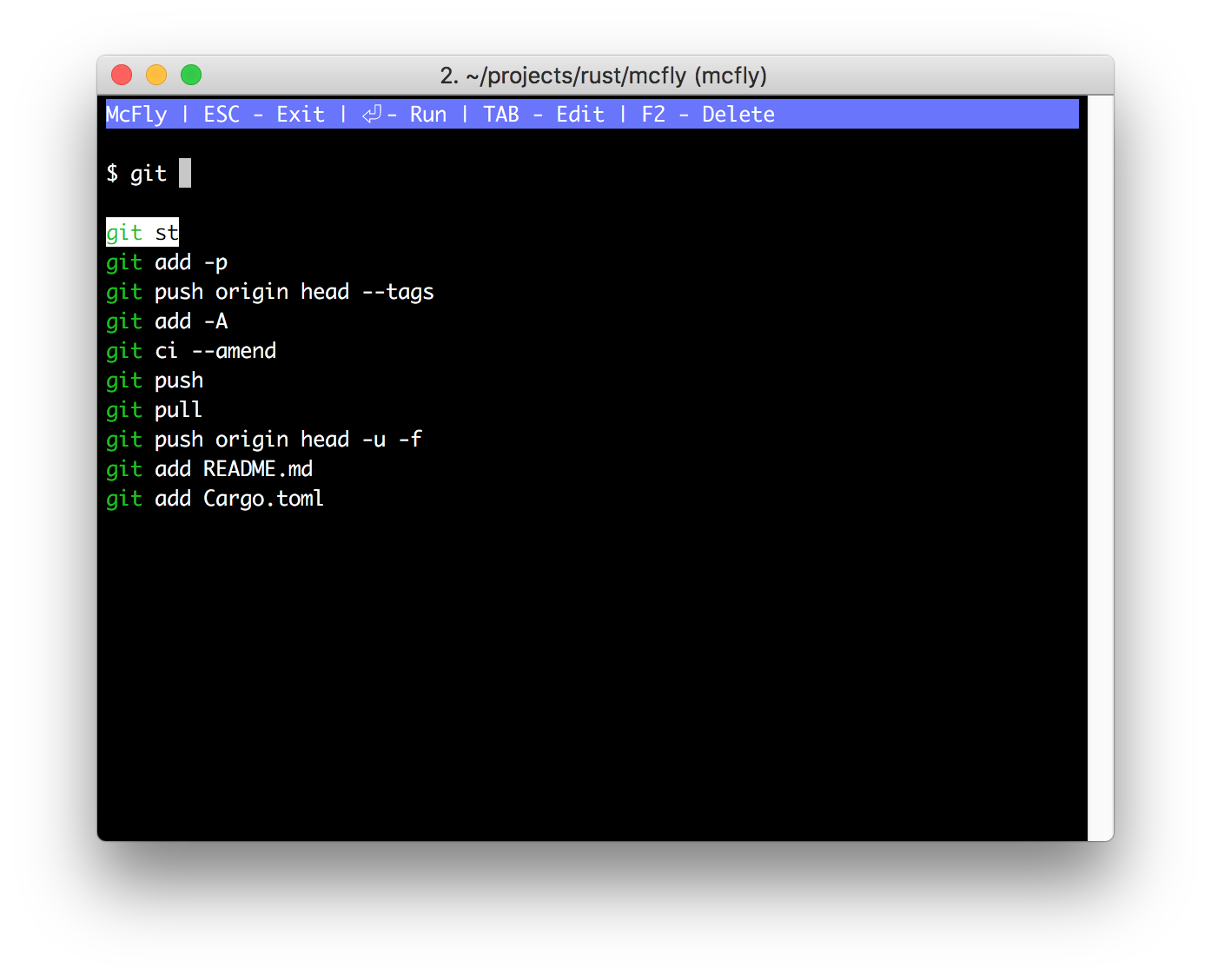
Esse entra aqui como uma menção quase que honrosa porque atualmente eu já não uso mais. Ele é prático se você usar outro shell que não seja o fish, como bash ou zsh. Ele faz a busca no histórico ser de uma forma bem mais simples. Tal como já é por padrão no fish.
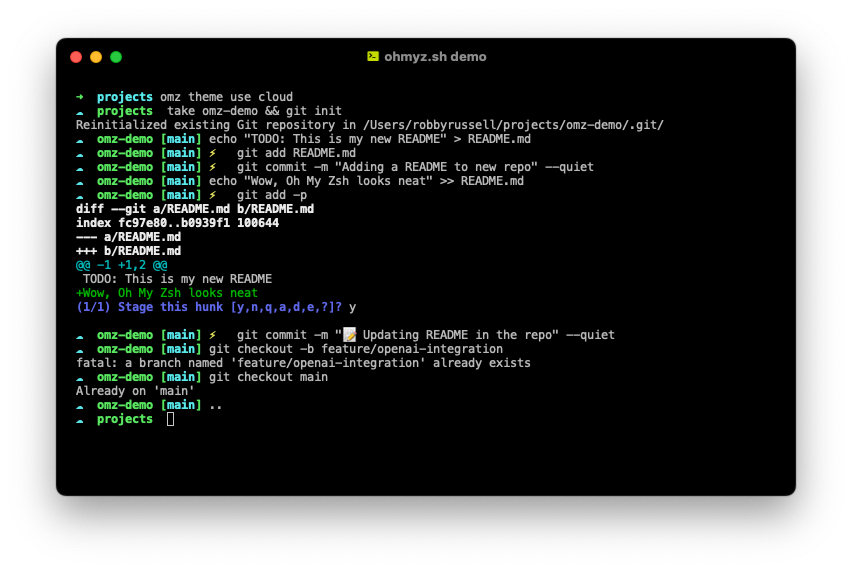
A imagem é do oh-my-zsh, que deixa o terminal mais bonitinho. O zsh mesmo não tem imagem na página do projeto. Se é que é um projeto.
O zsh é o padrão no macOS e eu resolvi experimentar por 6 meses na máquina que peguei no refresh da Ericsson. A vantagem do zsh é que é a mesma sintaxe do bash, então você reaproveita muita coisa. Agora sobre trocar zsh por bash... no final eu achei bem parecido. Existem algumas vantagens do zsh, mas no uso do dia à dia, pra mim pelo menos, não fez tanta diferença assim.
O Patola lembrou bem que existem comportamentos distintos entre bash e zsh.
Em bash:
patola@risadinha:/dados$ echo a | read b ; echo $b
patola@risadinha:/dados$
Em zsh:
[19:03] [9665] [patola@risadinha /dados]% echo a | read b ; echo $b
a
[19:03] [9666] [patola@risadinha /dados]%O resultado é diferente porque a sintaxe é diferente. O bash tem right-side fork, o zsh tem left-side fork. Isso não é controverso. É uma diferença de sintaxe conhecida, explicada e verificável.
-- Patola
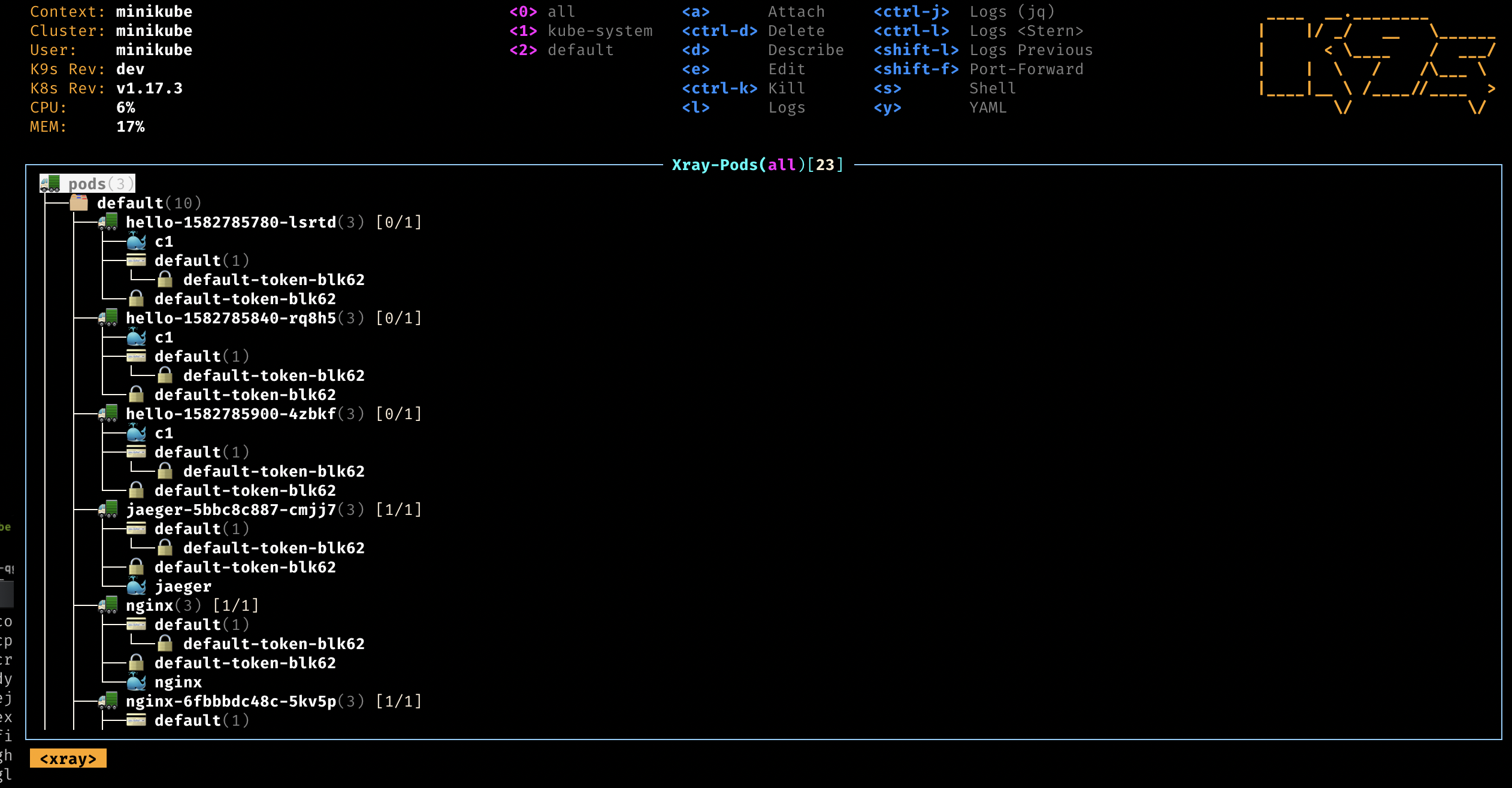
Essa não é bem uma dica pra quem mexe com kubernetes. Ao invés de ficar mandando "kubectl" pra tudo quanto é lado, o melhor é usar o k9s. Ele mostra de forma visual o seu cluster e namespace. E todos os atributos que consegue ver pelo "kubectl".
E assim terminamos o artigo. Se eu lembrar de mais alguma coisa que uso e esqueci, acrescento aqui.

O Debian Jessie, última versão estável do sistema operacional universal Debian, foi lançado a quase 1 ano. Somente agora criei coragem de fazer o upgrade. Estava rodando Wheezy, a versão anterior que entrou em LTS (Long Term Support ou suporte estendido), que atendia bem o site mas, sempre existe um mas, descobri alguns problemas de limitação do kernel com o greyd.
Alguns sites não estavam sendo marcados corretamente com ipset. Como o greyd foi criado pra versões mais recentes de kernel (Wheezy rodava com um linux-3.2), a opção era desativar o greyd ou atualizar o sistema. Então vamos atualizar!
Sem ajuda dos trus La_Sombra e Rootsh nada disso seria possível. Foi um trabalho de garimpo no passado pra achar como conectar na VM e quem ainda tinha a chave de conexão. Culpa disso pela estabilidade do sistema. Obrigado Debian!
Eu já tinha feito o upgrade do Ubuntu LTS, de 14.04 pro 16.04, e esperava alguns problemas que seriam corrigidos com reboot e uns "apt-get -f install", então o acesso ao console era essencial. Parte dessa espectativa era também o motivo pra ter postergado esse upgrade. systemd é algo que ainda me dói no alma.
Pra fazer o upgrade? Do bom e velho jeito do Debian: primeiramente deixando atualizado na versão corrente, Wheezy
# cd /etc/apt # apt-get update && apt-get upgrade
Em seguida mover a versão pra Jessie e continuar com upgrade.
# cp sources.list sources.list.wheezy # cat sources.list.wheezy | sed "s/wheezy/jessie/" > sources.list # apt-get update # apt-get dist-upgrade
Pronto. É isso. Fácil assim.
Foram uns 500 MB de download, uma vez que é um servidor e roda só o necessário, um reboot e... saiu funcionando de primeira! Eu achando que o systemd ia encrencar com alguma coisa e... nada! Claro que nem tudo foi tão bem assim. Precisei arrumar algumas configurações do servidor web, assim como do mail, mas muita coisa saiu funcionando sem mexer. Ainda estou com problemas com o dovecot, mas nada que force uma volta ao Wheezy pra corrigir.
Parabéns à equipe do Debian por um sistema tão afinado e redondo assim. Continua sendo minha distro preferida.
Por uma coincidência incrível, daquelas que ocorrem a cada alinhamento de planetas ou algo do gênero, assisti ontem a palestra do John Maddog Hall na campus party 7 cujo nome é esse do texto: fique rico com software livre. É o tipo de assunto que gosto de accompanhar, mas eu tinha baixado a palestra pra assistir e tinha esquecido completamente. Eis que o wifi estava ruim ontem, Netflix não funcionando, Internet intermitente e... sim, resolvi vasculhar o HD pra ver se tinha algo que eu pudesse ler ou assistir. Incrível o poder de abandonar coisas interessantes conforme a capacidade do HD aumenta...
Em várias listas e grupos que participo existe uma noção errada, e até um pouco ingênua, de que software livre é o que basta pro negócio dar certo. Que com software livre já existe uma vantagem competitiva. Nessa apresentação do Maddog, que está em inglês, ele toca nesse ponto. Eu peguei algumas partes pra comentar.

Esse primeiro slide é bem interessante. Ele comenta sobre as liberdades que definem um software como livre. E coloca bem claro na parte de baixo: ninguém disse que não devia fazer dinheiro escrevendo software livre. Sim, software livre pode ser vendido. Pode-se ganhar dinheiro com ele. Já comentei algumas vezes em sobre a 5a liberdade que criaram - mais acirramente no Brasil - onde transformar software livre em dinheiro virou algum tipo de pecado. Não é.

Business as usual. Software livre significou uma quebra de paradigma na forma de fazer software, mas não na de fazer negócios. Para ganhar dinheiro com software livre é preciso conhecer seu mercado, seus concorrentes, seu produto, seus consumidores, enfim tratar como outro negócio qualquer. Não existe mágica com software livre. Software é software e negócios são negócios.

O por qual motivo as pessoas escrevem software livre? São inumeradas as razões, que diferem em muito do software proprietário, onde somente um modelo de negócios existe. Mas não acredite que software livre é feito somente por hobbistas. Grandes empresas já fazem ou contribuem com a maioria dos projetos de software livre. Em termos de negócios, abrir seu software como livre pode não trazer um benefício direto. Pode ajudar na correção de bugs e adição de melhorias, mas não necessariamente no negócio em si (software livre não é vantagem competitiva, lembra?).

E alguém pagaria pra ter um software livre? Sim! Maddog inumera alguma das razões. A maior dela é usar o software livre pra atender mais rapidamente alguma necessidade da empresa. Então essa empresa com certeza pagaria o desenvolvedor, ou que se quiser manter o software, pra adicionar uma melhoria. Ou mesmo criar um fork.
São consideradas outras facetas do software livre como negócio, mas não vou comentar uma por uma pois o melhor é assistir a palestra por inteiro. Apenas lembre-se que é possível ganhar dinheiro com software livre, mas isso não significa que software livre seja uma vantagem competitiva pro negócio.

Eu resolvi melhorar a previsão e o modelo pra tal sobre o Linux no desktop, uma realidade inegável. Então escrevi algo em python pra fazer isso pra mim o trabalho e usar de algum modelo já pronto.
(venv) helio@goosfraba ~/D/linux-desktop-dominance-forecast (main)> ./forecasting.py
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2009-01-01 95.42 3.68 0.17 0.64 0.0 0.0 0.0
2009-02-01 95.39 3.76 0.14 0.62 0.0 0.0 0.0
2009-03-01 95.22 3.87 0.16 0.65 0.0 0.0 0.0
2009-04-01 95.13 3.92 0.17 0.66 0.0 0.0 0.0
2009-05-01 95.25 3.75 0.24 0.65 0.0 0.0 0.0
Playstation Other
Date
2009-01-01 0.08 0.02
2009-02-01 0.07 0.02
2009-03-01 0.08 0.02
2009-04-01 0.10 0.02
2009-05-01 0.09 0.02
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2024-01-01 73.00 16.11 5.33 3.77 1.78 0.0 0.0
2024-02-01 72.17 15.42 6.10 4.03 2.27 0.0 0.0
2024-03-01 72.47 14.68 6.52 4.05 2.27 0.0 0.0
2024-04-01 73.50 14.70 5.34 3.88 2.56 0.0 0.0
2024-05-01 73.91 14.90 4.87 3.77 2.54 0.0 0.0
2024-06-01 72.81 14.97 6.23 4.05 1.93 0.0 0.0
2024-07-01 72.10 14.92 7.13 4.44 1.41 0.0 0.0
Playstation Other
Date
2024-01-01 0.0 0.01
2024-02-01 0.0 0.01
2024-03-01 0.0 0.01
2024-04-01 0.0 0.01
2024-05-01 0.0 0.01
2024-06-01 0.0 0.01
2024-07-01 0.0 0.01
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/statespace/sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 11 M = 10
This problem is unconstrained.
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.00575D-01 |proj g|= 1.24633D+00
At iterate 5 f= -1.49635D-01 |proj g|= 1.77236D-01
At iterate 10 f= -3.64537D-01 |proj g|= 1.24837D-01
At iterate 15 f= -3.84843D-01 |proj g|= 1.22570D-01
At iterate 20 f= -4.20877D-01 |proj g|= 9.71167D-02
At iterate 25 f= -4.29351D-01 |proj g|= 1.13565D-01
At iterate 30 f= -4.33425D-01 |proj g|= 9.06436D-02
At iterate 35 f= -4.34142D-01 |proj g|= 3.98871D-02
At iterate 40 f= -4.36192D-01 |proj g|= 4.26757D-01
At iterate 45 f= -4.37801D-01 |proj g|= 6.82859D-02
At iterate 50 f= -4.37938D-01 |proj g|= 1.67285D-02
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
11 50 55 1 0 0 1.673D-02 -4.379D-01
F = -0.43793754789434586
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/base/model.py:607:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
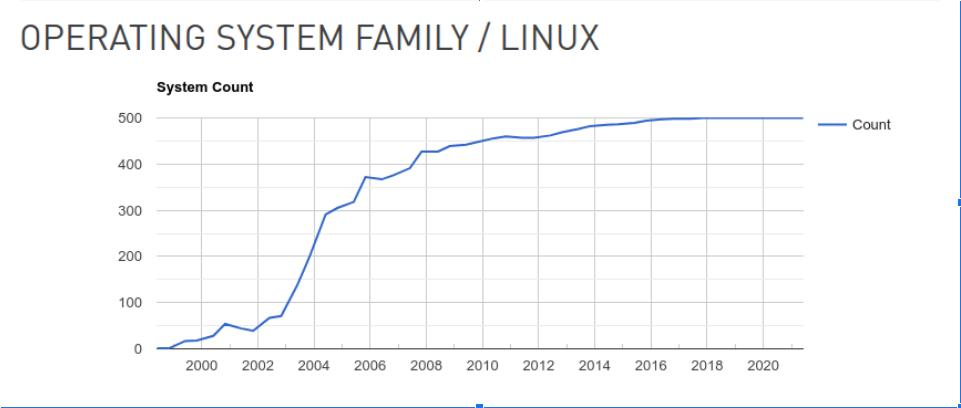
The year of Linux on the Desktop: 2036-11-30 00:00:00

Se ignorarmos os pequenos erros e avisos que aparecem, coisa pouca e irrelevante como valor divergir demais, podemos ver claramente quando o ano do Linux no desktop acontece: 2036-11-30
Então a previsão revisada é que logo estaremos em todos os lugares. Aguardem-nos!
E claro que publiquei isso tudo no GitHub:
E usei o seguinte artigo como referência (e código, diga-se de passagem):
Bom ano do Linux no desktop pra todos vocês.
![]()
Mais uma vez participei da BSD Day. Sempre um prazer estar no evento e equanto é possível.
Esse ano seria presencial, mas por causa da greve de funcionários o evento teve de ser online. Sorte minha.
Dessa vez contei a história do Unix. Depois que assisti eu achei que ficou meio confuso. Eu devia ter separado mais por linha de tempo pros eventos ficarem mais interessantes. Fica pra próxima.
Infelizmente minha webcam ficou travando. Ainda não sei bem se o problema foi no sistema, no archlinux, ou na banda (500 Mbps fibra ótica), ou no browser (Google Chrome) ou no Streamyard. Ou mesmo uma combinação de tudo.

Esses dias estava analisando um código que era parecido com shell script. Sua função era monitorar as interfaces de rede para, no caso de alteração (nova interface surgindo ou desaparecendo), registrar a mudança de objetos no sistema de dados do opensaf (objetos no IMM pra quem conhece).
Mas o código fazia algo parecido com um shell que a todo healthcheck do AMF (framework do opensaf que é muito semelhante ao systemd e roda determinado programa ou script de tempos em tempos) fazia uma busca com o comando "ip link addr list" e comparava com o que estava armazenado no IMM. Algo como:
def healthcheckCallback(self, invocation, compName, healthcheckKey): saAmfResponse(self.check_macs, invocation, eSaAisErrorT.SA_AIS_OK)
def check_macs(self):
macs = []
for line in self.get_link_list().split("\n"):
if not re.search("link/ether", line): continue
# [ 'link/ether', '52:54:00:c3:5d:88', 'brd', 'ff:ff:ff:ff:ff:ff']
mac.append(line.split()[1])
imm_obj = self.get_from_imm()
if imm_obj != macs:
self.update_imm(mac)
def get_link_list(self):
linux_command = "ip link list"
return self.run_shell(linux_command)
Essa é uma forma bastante simplificada pra tentar visualizar como tudo funciona. Eu propositalmente tirei comentários extras e deixei mais limpo apenas para poder comentar aqui.
Como a chamada pra buscar os dados junto ao IMM no OpenSAF tem muitas linhas, eu só deixei um get_from_imm() que retornará um array de mac registrados anteriormente. Se esse valor for diferente do coletado, então é chamado o método update_imm() com os macs que devem estar lá.
Funciona? Sim, funciona. Mas... se não houve nenhuma mudança nas interfaces de rede (como a subida de uma interface de VIP ou mesmo um container em docker), por quê eu preciso rodar o get_link_list()?
Entendeu qual foi meu ponto?
O código em si consiste em rodar o monitoramente separado numa thread. Toda vez que o código detecta uma mudança (na verdade o kernel sinaliza isso), ele altera uma variável que o programa lê durante o healthcheck. Algo como:
def check_macs(self):
if self.network_changed is False: return
Assim bem simples. Teve mudança? network_changed vira um True.
Linux tem mecanismos pra detectar uma mudanças na interfaces de rede. Por quê não usar? E foi o que fiz.
Criei um método chamado monitor_link() que é iniciado junto com programa no método initialize(), que é parte de como o AMF faz as chamadas de callback:
self.thread = threading.Thread(target=self.monitor_link, args=())
self.thread.start()
E como funciona o monitor_link()? Aqui tenho de pedir desculpas antecipadamente que enquanto o código utiliza menos CPU e memória que chamar um shell script, o tamanho e complexidade é bastante grande. No fim troquei 2 linhas de código por umas 35 linhas. Na verdade eu praticamente escrevi o código por trás do "ip link". Mas o resultado ficou independente desse comando e mesmo de utilizar um shell externo pra buscar o resultado.
A primeira coisa é criar um socket do tipo AF_NETLINK. Em seguida fazer um bind() num ID aleatório e monitorar com RTMGRP_LINK.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
pra gerar o código aleatório que é um inteiro, usei os.getpid() pra usar o PID do próprio programa.
Em seguida é iniciado um loop com select() em cima do descritor do socket pra leitura. Quando aparecer algum dado, daí sim a informação é lida.
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
O que vem a seguir são quebras da sequência de bits até chegar no ponto é possível ver o tipo de mensagem que chegou do select(). Se o tipo de mensagem for NOOP de algo nulo, apenas continue monitorando no select(). Se vier algum ERROR, pare o programa. Se vier mensagem e não for do tipo NEWLINK pra um link novo ou mudança de MAC, também continue aguardando no select().
if msg_type == NLMSG_NOOP: continue elif msg_type == NLMSG_ERROR: break elif msg_type != RTM_NEWLINK: continue
Por fim uma iteração nos dados pra buscar o tipo. Se o dado for do tipo IFLA_IFNAME, que é uma nova interface ou mudança de nome, ou IFLA_ADDRESS, que é MAC e endereço IP, muda a flag de network_changed pra True.
rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
E é isso. O código completo segue abaixo.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
while self.terminating is False:
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
if self.network_changed is True: continue
if self.terminating is True: return
try:
data = os.read(rlist[0], 65535)
except:
continue
msg_len, msg_type, flags, seq, pid = struct.unpack("=LHHLL", data[:16])
if msg_type == NLMSG_NOOP: continue
elif msg_type == NLMSG_ERROR: break
elif msg_type != RTM_NEWLINK: continue
data = data[16:]
family, _, if_type, index, flags, change = struct.unpack("=BBHiII", data[:16])
remaining = msg_len - 32
data = data[16:]
while remaining:
rta_len, rta_type = struct.unpack("=HH", data[:4])
if rta_len < 4: break
rta_data = data[4:rta_len]
increment = (rta_len + 4 - 1) & ~(4 - 1)
data = data[increment:]
remaining -= increment
if rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
self.network_changed = True
Encontrei essa implementação no Stack Overflow buscando informação do código em C. Foi uma grande ajuda e deixou meu programa muito mais coerente com o que eu realmente queria.
Ficou muito maior? Ficou. Mas também ficou muito mais 1337 :)
Mais:
[1] Exemplo de uso de python com AMF no OpenSAF: https://sourceforge.net/p/opensaf/staging/ci/default/tree/python/samples/amf_demo
[2] Projeto OpenSAF: https://sourceforge.net/projects/opensaf/
[3] Implementação original desse código: https://stackoverflow.com/questions/44299342/netlink-interface-listener-in-python

Recebi a missão de montar uma máquina que será usada pra AI na firma. Na foto ainda está o esqueleto dela, que também montei. E com somente uma fonte.
Era o teste pra ver se ligava. E ligou.
Ontem fui instalar o sistema operacional, que será Ubuntu, e... cadê o nvme? Passei algum tempo pesquisando até que achei que é algo com a mother board, a ASUS Pro WS WRX80E-SAGE SE WIFI. O artigo que ajudou foi esse aqui:
tl;dr: é preciso passar o parâmetro pci=nommconf no boot pro kernel achar o nvme.
Quando estiver montada, provavelmente com metade das placas nvidia porque só recebemos 2 das 4 compradas, faço outro post com a foto e mais alguns dados.

Já faz algum tempo que quero escrever sobre meu uso de LVM, mas até agora a procrastinação venceu. No último artigo Trabalhando de home-office eu descrevei meu ambiente de home-office e um pouco do meu desktop. Ao entrar no desktop é que percebi que um dos HDDs simplemente parou de funcionar, esse Seagate Firecuda de 2 TB. Graças ao LVM eu não percebi nada, nem perdi dados. E vou descrever aqui o cenário e como fiz a troca e re-sincronismo dos dados.
Usando o comando lvm é possível ver o estado dos meu volumes:
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor-r- 750.00g 100.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
Minhas partições eram todas XFS mas descobri que alguns jogos da Steam simplesmente só rodam com EXT4. Então precisei criar uma partição EXT4 somente pros jogos. É o volume com nome de "steam" e que mostra um "100.00". Esse número representa a cópia no disco que falhou, que estava em RAID1.
Primeiro eu adicionei outro disco de 2 TB que tinha aqui (no passado eu usava 2 HDDs de 2 TB cada com LVM, comprei o HDD novo de 4 TB e removi 1 dos HDDs que estava em bom estado ainda), e particionei da mesma forma que o HDD de 4 TB, com uma partição EFI e outra de boot do mesmo tamanho. O restante pro LVM.
root@goosfraba:~# fdisk -l /dev/sdb
Disco /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 setores
Unidades: setor de 1 * 512 = 512 bytes
Tamanho de setor (lógico/físico): 512 bytes / 512 bytes
Tamanho E/S (mínimo/ótimo): 512 bytes / 512 bytes
Tipo de rótulo do disco: dos
Identificador do disco: 0x18a6e3b6
Dispositivo Inicializar Início Fim Setores Tamanho Id Tipo
/dev/sdb1 2048 1128447 1126400 550M ef EFI (FAT-12/16/32)
/dev/sdb2 1128448 5322751 4194304 2G 83 Linux
/dev/sdb3 5322752 3907029167 3901706416 1.8T 8e Linux LVM
Tendo a partição sdb3 disponível pro LVM, então o que faltava era adicionar o grupo de volumes que uso. Ao listar os discos físicos disponíveis, apareceu a informação ainda do disco antigo como "unknown".
root@goosfraba:~# pvdisplay
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name [unknown]
VG Name diskspace
PV Size <1.82 TiB / not usable <4.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476931
Free PE 284930
Allocated PE 192001
PV UUID N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t
"/dev/sdb3" is a new physical volume of "<1.82 TiB"
--- NEW Physical volume ---
PV Name /dev/sdb3
VG Name
PV Size <1.82 TiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
Isso acontenceu porque o metadado ainda estava lá apesar do disco ter sido removido da máquina. Enquanto isso a partição sdb3 aparece como "Allocatable NO" pois ainda não está disponível pra uso.
A primeira coisa é remover os dados incosistes do vg (volume group).
root@goosfraba:~# vgreduce diskspace --removemissing --force
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
Wrote out consistent volume group diskspace.
E adicionar a nova partição ao vg.
root@goosfraba:~# vgextend diskspace /dev/sdb3
Volume group "diskspace" successfully extended
Com isso o a informação de pv mostra como usado.
root@goosfraba:~# pvdisplay
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name /dev/sdb3
VG Name diskspace
PV Size <1.82 TiB / not usable <2.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476282
Free PE 476282
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
E a informação de vg mostra com 6 TB disponíveis pra uso.
root@goosfraba:~# vgdisplay
--- Volume group ---
VG Name diskspace
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 217
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 8
Open LV 8
Max PV 0
Cur PV 2
Act PV 2
VG Size 5.45 TiB
PE Size 4.00 MiB
Total PE 1429493
Alloc PE / Size 501761 / 1.91 TiB
Free PE / Size 927732 / <3.54 TiB
VG UUID f2ufnI-c802-yt6f-2nMG-6BYl-8atu-wbR7vO
Agora a partição já faz parte do lvm. O que resta é a usar como RAID1 em mirror. Ou mesmo como uma partição qualquer se eu quisesse. Mas no caso uso como RAID1 pra ter um pouco mais de desempenho.
Primeiramente removendo as informações de RAID1 que ainda existindo.
root@goosfraba:~# lvconvert -m 0 /dev/diskspace/steam
Are you sure you want to convert raid1 LV diskspace/steam to type linear losing all resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace -wi-ao---- 750.00g
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
O parâmetro "-m 0" diz que a partição será em RAID0.
Em seguida basta mudar a partição novamente pra RAID1 e o sincronismo iniciará.
root@goosfraba:~# lvconvert -m 1 /dev/diskspace/steam /dev/sdb3
Are you sure you want to convert linear LV diskspace/steam to raid1 with 2 images enhancing resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 0.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 34.56
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
E é isso. Simples e rápido graças ao LVM.
