
Vira e mexe aparece esse assunto em algum grupo de discussão, seja no Facebook ou seja no Telegram. São vários os relatos de instalação de sistemas de 32 bits em máquinas mais modestas, em geral com até 2 GB de RAM, e que ficaram mais rápidas.
Então resolvi passar um tempo fazendo a prova, inclusive da quantidade de memória.
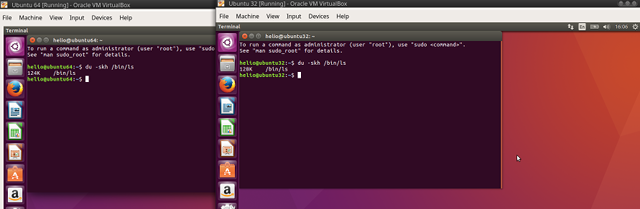
Pra validar, instalei em VMs (VirtualBox) dois sistemas Ubuntu baseados no 16.04, Xenial. Ambos configurados como CPUs de 64 bits, 2 GB de RAM, 128 MB de vídeo com aceleração 3D e 20 GB de disco.
Pra consumir memória, deixei ambos com o navegador firefox rodando no tweetdeck, aplicativo que mostra o fluxo de mensagens do twitter. Como o mesmo é feito em javascript, vai consumindo a memória conforme o tempo passa. Ambos começaram com frugais 300 MB de RAM e ao terminar de escrever, depois de mais de 24 horas rodandos, ambos consumiam mais de 1.5 GB da RAM.
Não fiz testes de desempenho pelo motivo óbvio: fiz com meu laptop e ele não é exatamente um tipo de ambiente dos mais robustos pra esse tipo de coisa. Mas pra finalidade de verificação de tamanho de binários em máquinas virtuais, serve bem.

Cada VM recebeu o nome de "UbuntuXX" onde XX é a arquitetura do software, 32 ou 64 bits.
Logo de início o sistema com 32 bits mostra mais memória que realmente disponível. Ambas as VMs com 2 GB de RAM, mas com 32 bits ele mostra um pouco mais de 2048 MB. Bug? Não sei.
root@ubuntu64:~# head -5 /proc/meminfo MemTotal: 2048524 kB MemFree: 102900 kB MemAvailable: 859980 kB Buffers: 132452 kB Cached: 541576 kB
root@ubuntu32:~# head -5 /proc/meminfo MemTotal: 2060988 kB MemFree: 380360 kB MemAvailable: 507600 kB Buffers: 58812 kB Cached: 272512 kB
E na configuração das VMS...
helio@XPS13:VirtualBox VMs$ grep RAMSize Ubuntu\ {32,64}/Ubuntu\ {32,64}.vbox
Ubuntu 32/Ubuntu 32.vbox: <Memory RAMSize="2048"/>
Ubuntu 32/Ubuntu 32.vbox: <Display VRAMSize="128" accelerate3D="true"/>
Ubuntu 64/Ubuntu 64.vbox: <Memory RAMSize="2048"/>
Ubuntu 64/Ubuntu 64.vbox: <Display VRAMSize="128" accelerate3D="true"/>
Uma olhada no sistema usando top.
root@ubuntu64:~# top -b -n 1 | head -5 top - 18:42:55 up 2:38, 2 users, load average: 0,01, 0,02, 0,05 Tasks: 178 total, 1 running, 177 sleeping, 0 stopped, 0 zombie %Cpu(s): 5,0 us, 0,8 sy, 0,1 ni, 93,8 id, 0,1 wa, 0,0 hi, 0,1 si, 0,0 st KiB Mem : 2048524 total, 47004 free, 1157408 used, 844112 buff/cache KiB Swap: 2095100 total, 2082632 free, 12468 used. 842436 avail Mem
root@ubuntu32:~# top -b -n 1 | head -5 top - 18:42:45 up 2:38, 2 users, load average: 0,00, 0,00, 0,00 Tasks: 171 total, 1 running, 170 sleeping, 0 stopped, 0 zombie %Cpu(s): 9,3 us, 3,2 sy, 0,1 ni, 87,1 id, 0,1 wa, 0,0 hi, 0,2 si, 0,0 st KiB Mem : 2060988 total, 256196 free, 1112400 used, 692392 buff/cache KiB Swap: 2095100 total, 2089776 free, 5324 used. 681120 avail Mem
Como pode ser visto, o sistema de 32 bits mostra mais memória livre, 256 MB contra 47 MB, menos uso de swap, 5 MB contra 12 MB, mas tem menor memória disponível, 681 MB contra 842 MB.
Outro ponto interessante é que são 177 processos rodando em 64 bits contra 170 em 32. E antes de perguntarem, não investiguei o motivo e não acho que realmente importe muito. Mas percebi que por algum motivo acabei com versões de kernel diferentes.
root@ubuntu64:~# uname -a Linux ubuntu64 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
root@ubuntu32:~# uname -a Linux ubuntu32 4.8.0-45-generic #48~16.04.1-Ubuntu SMP Fri Mar 24 12:47:29 UTC 2017 i686 i686 i686 GNU/Linux
Isso tem importância na forma em que o kernel reserva a memória mas não usa. Fora isso, o resto é o mesmo.
É bastante comum a verificação de memória utilizada pelo comando top, htop ou mesmo ps. É possívei ver uma saída mais ou menos como essa com o top.
top - 12:58:22 up 20:54, 2 users, load average: 1,08, 0,43, 0,19
Tasks: 184 total, 1 running, 183 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3,5 us, 0,5 sy, 0,1 ni, 95,6 id, 0,1 wa, 0,0 hi, 0,1 si, 0,0 st
KiB Mem : 2048524 total, 106008 free, 1134092 used, 808424 buff/cache
KiB Swap: 2095100 total, 2017780 free, 77320 used. 860776 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1241 helio 20 0 1254076 160784 10380 S 50,0 7,8 30:33.19 compiz
767 root 20 0 480156 88992 8388 S 25,0 4,3 15:18.11 Xorg
2272 helio 20 0 1539028 451060 50504 S 6,2 22,0 42:32.37 firefox
1 root 20 0 185720 5708 3340 S 0,0 0,3 0:03.14 systemd
2 root 20 0 0 0 0 S 0,0 0,0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0,0 0,0 0:01.38 ksoftirqd/0
5 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0,0 0,0 0:01.65 rcu_sched
8 root 20 0 0 0 0 S 0,0 0,0 0:00.00 rcu_bh
9 root rt 0 0 0 0 S 0,0 0,0 0:00.00 migration/0
10 root rt 0 0 0 0 S 0,0 0,0 0:00.38 watchdog/0
11 root 20 0 0 0 0 S 0,0 0,0 0:00.00 kdevtmpfs
O comando top mostra o consumo de memória em VIRT, RES e SHR. É possível ver o firefox consumindo 1.54 GB de memória VIRT, 451 MB de memória RES e 50 MB de memória SHR. Mas o que são?
Atualmente é muito difícil um programa tão grande quanto firefox ter todas as bibliotecas incluídas em seu binário. Esse formato é chamado estático se usado. Isso faria com que o executável ficasse gigantesco. Fora isso, cada executável traria dentro de si a mesma biblioteca com os mesmos conteúdos. E a cada atualização dessas bibliotecas, seria necessário alterar o executável também.
Pra melhorar a eficiência, binários criados no formato ELF, Executable and Linkable Format, tem uma parte do cabeçalho que informa onde buscar essas bibliotecas de funções, que são os arquivos .so. São chamadas as bibliotecas dinâmicas, que podem ser atualizadas com o executável rodando. Quando um binário ELF é executado, o kernel carrega seu código na memória e de suas bibliotecas de funções. Se outro binário que aponta pra mesma biblioteca é executado, o kernel não carrega novamente a biblioteca, mas aponta pro endereçamento de memória onde essa já existe.
Então a memória VIRT, de virtual, mostra o total que um binário carregou na memória, inclusive com as bibliotecas dinâmicas que são compartilhadas. Esse tamanho então não é exatamente o que aquele programa sozinho carrega.
A memória RES mostra o quanto de memória está na RAM e não no SWAP. Mas ela mostra o total, incluindo das bibliotecas dinâmicas que são compartilhadas com outros programas.
A memória SHR é da compartilhada, de quanto de memória é compartilhado com bibliotecas dinâmicas.
O resultado é que pra saber o quanto um programa está consumindo por si só, seria algo como VIRT menos a SHR. Dai seria possível ver quanto o executável ocupa de memória, mais os stack de dados. Só que fica a pergunta: e a parte compartilhada? Não conta?
Conta! É memória consumida. É RAM que não pode usar. Mas como fazer isso? Se o firefox e o unity, como exemplo, compartilharem uma biblioteca de renderização 3D, então a gente diz que cada um consumiu metade dessa memória alocada? E se tiver mais um terceiro, ou quarto ou muito mais programas compartilhando essa mesma biblioteca? A resposta é tão complicada que é esse o motivo que o programa top não tenta resolver isso e mostra o total alocado, mesmo sabendo que boa parte daquilo é compartilhado.
Algumas formas de ver o quanto cada programa ocupa em stack de memória sem as bibliotecas compartilhadas são os comandos pmap e readelf, que serão usados mais adiante.
Vamos começar pelo tamanho dos binários. O binário de 32 bits é muito menor que o de 64 bits?
root@ubuntu64:~# ls -l /usr/lib/firefox/firefox -rwxr-xr-x 1 root root 125152 mar 29 18:25 /usr/lib/firefox/firefox
root@ubuntu32:~# ls -l /usr/lib/firefox/firefox -rwxr-xr-x 1 root root 136664 mar 29 18:50 /usr/lib/firefox/firefox
E já de cara as coisas começam a ficar mais interessantes. O binário do firefox em 32 bits é maior que o de 64 bits. Usando o comando readelf -S é possível olhar o conteúdo de ambos e quanto de memória ocupa cada parte. Mas vou evitar colocar aqui o resultado inteiro pois é muito longo e não será fácil visualizar as diferenças. Então mostro apenas as partes diferentes de ambos. Os valores estão em hexadecimal.
| 32 bits | 64 bits | |
| .gnu.hash | 04d4 | 04c4 |
| .dynsym | 0ea0 | 1578 |
| .dynstr | 184f | 17c8 |
| .gnu.version | 01d4 | 01ca |
| .gnu.version_r | 01a0 | 0160 |
| .rel.dyn | 0468 | 0cd8 |
| init | 0023 | 001a |
| .plt.got | 02b0 | 02a0 |
| .text | 013b34 | 0123ff |
Não completei a tablet toda, mas já dá pra perceber que os valores em 64 bits são menores em geral. Antes de uma pergunta sobre o motivo, isso eu não sei. Talvez algo em relação com compilador.
E quanto estão ocupando de memória rodando? Isso fica fácil verificar com o comando pmap.
root@ubuntu64:~# pmap 2272 | grep total total 1548796K
root@ubuntu32:~# pmap 2334 | grep total total 959916K
E o firefox ocupa 1.55 GB de RAM em 64 bits contra 956 MB em 32. Alguns já começam a se exaltar e gritar "viu! eu falei!" mas... e sempre tem um mas... em 32 bits, não sei a razão disso, o firefox usa um plugin-container junto. Ao matar esse plugin-container...
então ele tem de contar com o consumo de memória do firefox como um todo. Sendo assim.
root@ubuntu32:~# ps auxwww | grep -i firefox helio 2334 1.3 11.5 959920 238924 ? Sl apr01 17:44 /usr/lib/firefox/firefox helio 2490 3.6 19.6 1102860 404644 ? Sl apr01 47:30 /usr/lib/firefox/plugin-container -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 2334 true tab root 9461 0.0 0.0 6644 840 pts/4 S+ 13:42 0:00 grep --color=auto -i firefox root@ubuntu32:~# pmap 2334 | grep total total 959916K root@ubuntu32:~# pmap 2490 | grep total total 996360K
O total de uso de memória em 32 bits é na verdade 1956276K, 1.96 GB de RAM.
O consumo de memória é mais otimizado em 64 bits. O esperado resultado de 32 bits ocupar menos memória não passa de uma lenda urbana.
Mas podemos fazer algo mais interessante e olhar à fundo as difrenças de 32 bits e 64 bits em arquiteturas de 64 bits. Pra isso eu criei um pequeno programa em C que basicamente cria uma string com meu nome e copia pra outra variável. E fica fazendo isso. O motivo é apenas fazer análise de uso de memória com readelf e pmap.
testing.c
#include
#include
#include
char nome[] = "Helio Loureiro";
int main() {
char tmp[sizeof(nome)];
while(1) {
sleep(30);
strcpy(tmp, nome);
}
}
Compilando e verificando os tamanhos dos binários.
root@ubuntu64:~# vi testing.c root@ubuntu64:~# gcc -o testing testing.c root@ubuntu64:~# ls -l testing -rwxr-xr-x 1 root root 8696 apr 1 18:22 testing
root@ubuntu32:~# vi testing.c root@ubuntu32:~# gcc -o testing testing.c root@ubuntu32:~# ls -l testing -rwxr-xr-x 1 root root 7424 apr 1 18:22 testing
Nesse caso bem simples, com nenhuma biblioteca dinâmica em uso além da própria GNU libc, o executável em 32 bits ficou menor. Não metade do tamanho, mas 14% menor. E rodando?
root@ubuntu64:~# ./testing & [1] 19892 root@ubuntu64:~# pmap -x 19892 19892: ./testing Address Kbytes RSS Dirty Mode Mapping 0000000000400000 4 4 0 r-x-- testing 0000000000400000 0 0 0 r-x-- testing 0000000000600000 4 4 4 r---- testing 0000000000600000 0 0 0 r---- testing 0000000000601000 4 4 4 rw--- testing 0000000000601000 0 0 0 rw--- testing 00007f21a0044000 1788 816 0 r-x-- libc-2.23.so 00007f21a0044000 0 0 0 r-x-- libc-2.23.so 00007f21a0203000 2048 0 0 ----- libc-2.23.so 00007f21a0203000 0 0 0 ----- libc-2.23.so 00007f21a0403000 16 16 16 r---- libc-2.23.so 00007f21a0403000 0 0 0 r---- libc-2.23.so 00007f21a0407000 8 8 8 rw--- libc-2.23.so 00007f21a0407000 0 0 0 rw--- libc-2.23.so 00007f21a0409000 16 8 8 rw--- [ anon ] 00007f21a0409000 0 0 0 rw--- [ anon ] 00007f21a040d000 152 140 0 r-x-- ld-2.23.so 00007f21a040d000 0 0 0 r-x-- ld-2.23.so 00007f21a0615000 12 12 12 rw--- [ anon ] 00007f21a0615000 0 0 0 rw--- [ anon ] 00007f21a0630000 8 8 8 rw--- [ anon ] 00007f21a0630000 0 0 0 rw--- [ anon ] 00007f21a0632000 4 4 4 r---- ld-2.23.so 00007f21a0632000 0 0 0 r---- ld-2.23.so 00007f21a0633000 4 4 4 rw--- ld-2.23.so 00007f21a0633000 0 0 0 rw--- ld-2.23.so 00007f21a0634000 4 4 4 rw--- [ anon ] 00007f21a0634000 0 0 0 rw--- [ anon ] 00007ffd44054000 132 12 12 rw--- [ stack ] 00007ffd44054000 0 0 0 rw--- [ stack ] 00007ffd440e3000 8 0 0 r---- [ anon ] 00007ffd440e3000 0 0 0 r---- [ anon ] 00007ffd440e5000 8 4 0 r-x-- [ anon ] 00007ffd440e5000 0 0 0 r-x-- [ anon ] ffffffffff600000 4 0 0 r-x-- [ anon ] ffffffffff600000 0 0 0 r-x-- [ anon ] ---------------- ------- ------- ------- total kB 4224 1048 84
root@ubuntu32:~# ./testing & [1] 9589 root@ubuntu32:~# pmap -x 9589 9589: ./testing Address Kbytes RSS Dirty Mode Mapping 08048000 4 4 0 r-x-- testing 08048000 0 0 0 r-x-- testing 08049000 4 4 4 r---- testing 08049000 0 0 0 r---- testing 0804a000 4 4 4 rw--- testing 0804a000 0 0 0 rw--- testing b75d7000 1724 732 0 r-x-- libc-2.23.so b75d7000 0 0 0 r-x-- libc-2.23.so b7786000 4 0 0 ----- libc-2.23.so b7786000 0 0 0 ----- libc-2.23.so b7787000 8 8 8 r---- libc-2.23.so b7787000 0 0 0 r---- libc-2.23.so b7789000 4 4 4 rw--- libc-2.23.so b7789000 0 0 0 rw--- libc-2.23.so b778a000 12 8 8 rw--- [ anon ] b778a000 0 0 0 rw--- [ anon ] b77a5000 8 8 8 rw--- [ anon ] b77a5000 0 0 0 rw--- [ anon ] b77a7000 8 0 0 r---- [ anon ] b77a7000 0 0 0 r---- [ anon ] b77a9000 8 4 0 r-x-- [ anon ] b77a9000 0 0 0 r-x-- [ anon ] b77ab000 136 136 0 r-x-- ld-2.23.so b77ab000 0 0 0 r-x-- ld-2.23.so b77cd000 4 4 4 rw--- [ anon ] b77cd000 0 0 0 rw--- [ anon ] b77ce000 4 4 4 r---- ld-2.23.so b77ce000 0 0 0 r---- ld-2.23.so b77cf000 4 4 4 rw--- ld-2.23.so b77cf000 0 0 0 rw--- ld-2.23.so bfe72000 132 8 8 rw--- [ stack ] bfe72000 0 0 0 rw--- [ stack ] -------- ------- ------- ------- total kB 2068 932 56
É possível ver que em 64 bits o programa ocupa o dobro de memória em RAM que 32 bits. São 4224 KB contra 2068 KB. E é possível ver que é causado pela libc em 64 bits. Essa memória é totalmente usada pelo programa? Não uma vez que a libc é compartilhada. Mas em 64 bits ela faz duas chamadas para si. O restante, como stack, os valores são exatamente os mesmos.
Olhando com readelf pra investigar o tamanho de cada parte do binário.
root@ubuntu64:~# readelf -S -W testing There are 31 section headers, starting at offset 0x1a40: Section Headers: [Nr] Name Type Address Off Size ES Flg Lk Inf Al [ 0] NULL 0000000000000000 000000 000000 00 0 0 0 [ 1] .interp PROGBITS 0000000000400238 000238 00001c 00 A 0 0 1 [ 2] .note.ABI-tag NOTE 0000000000400254 000254 000020 00 A 0 0 4 [ 3] .note.gnu.build-id NOTE 0000000000400274 000274 000024 00 A 0 0 4 [ 4] .gnu.hash GNU_HASH 0000000000400298 000298 00001c 00 A 5 0 8 [ 5] .dynsym DYNSYM 00000000004002b8 0002b8 000078 18 A 6 1 8 [ 6] .dynstr STRTAB 0000000000400330 000330 000045 00 A 0 0 1 [ 7] .gnu.version VERSYM 0000000000400376 000376 00000a 02 A 5 0 2 [ 8] .gnu.version_r VERNEED 0000000000400380 000380 000020 00 A 6 1 8 [ 9] .rela.dyn RELA 00000000004003a0 0003a0 000018 18 A 5 0 8 [10] .rela.plt RELA 00000000004003b8 0003b8 000048 18 AI 5 24 8 [11] .init PROGBITS 0000000000400400 000400 00001a 00 AX 0 0 4 [12] .plt PROGBITS 0000000000400420 000420 000040 10 AX 0 0 16 [13] .plt.got PROGBITS 0000000000400460 000460 000008 00 AX 0 0 8 [14] .text PROGBITS 0000000000400470 000470 0001a2 00 AX 0 0 16 [15] .fini PROGBITS 0000000000400614 000614 000009 00 AX 0 0 4 [16] .rodata PROGBITS 0000000000400620 000620 000004 04 AM 0 0 4 [17] .eh_frame_hdr PROGBITS 0000000000400624 000624 000034 00 A 0 0 4 [18] .eh_frame PROGBITS 0000000000400658 000658 0000f4 00 A 0 0 8 [19] .init_array INIT_ARRAY 0000000000600e10 000e10 000008 00 WA 0 0 8 [20] .fini_array FINI_ARRAY 0000000000600e18 000e18 000008 00 WA 0 0 8 [21] .jcr PROGBITS 0000000000600e20 000e20 000008 00 WA 0 0 8 [22] .dynamic DYNAMIC 0000000000600e28 000e28 0001d0 10 WA 6 0 8 [23] .got PROGBITS 0000000000600ff8 000ff8 000008 08 WA 0 0 8 [24] .got.plt PROGBITS 0000000000601000 001000 000030 08 WA 0 0 8 [25] .data PROGBITS 0000000000601030 001030 00001f 00 WA 0 0 8 [26] .bss NOBITS 000000000060104f 00104f 000001 00 WA 0 0 1 [27] .comment PROGBITS 0000000000000000 00104f 000034 01 MS 0 0 1 [28] .shstrtab STRTAB 0000000000000000 001930 00010c 00 0 0 1 [29] .symtab SYMTAB 0000000000000000 001088 000678 18 30 47 8 [30] .strtab STRTAB 0000000000000000 001700 000230 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), l (large) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)
root@ubuntu32:~# readelf -S testing There are 31 section headers, starting at offset 0x1828: Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .interp PROGBITS 08048154 000154 000013 00 A 0 0 1 [ 2] .note.ABI-tag NOTE 08048168 000168 000020 00 A 0 0 4 [ 3] .note.gnu.build-i NOTE 08048188 000188 000024 00 A 0 0 4 [ 4] .gnu.hash GNU_HASH 080481ac 0001ac 000020 04 A 5 0 4 [ 5] .dynsym DYNSYM 080481cc 0001cc 000060 10 A 6 1 4 [ 6] .dynstr STRTAB 0804822c 00022c 000052 00 A 0 0 1 [ 7] .gnu.version VERSYM 0804827e 00027e 00000c 02 A 5 0 2 [ 8] .gnu.version_r VERNEED 0804828c 00028c 000020 00 A 6 1 4 [ 9] .rel.dyn REL 080482ac 0002ac 000008 08 A 5 0 4 [10] .rel.plt REL 080482b4 0002b4 000018 08 AI 5 24 4 [11] .init PROGBITS 080482cc 0002cc 000023 00 AX 0 0 4 [12] .plt PROGBITS 080482f0 0002f0 000040 04 AX 0 0 16 [13] .plt.got PROGBITS 08048330 000330 000008 00 AX 0 0 8 [14] .text PROGBITS 08048340 000340 0001a2 00 AX 0 0 16 [15] .fini PROGBITS 080484e4 0004e4 000014 00 AX 0 0 4 [16] .rodata PROGBITS 080484f8 0004f8 000008 00 A 0 0 4 [17] .eh_frame_hdr PROGBITS 08048500 000500 00002c 00 A 0 0 4 [18] .eh_frame PROGBITS 0804852c 00052c 0000c4 00 A 0 0 4 [19] .init_array INIT_ARRAY 08049f08 000f08 000004 00 WA 0 0 4 [20] .fini_array FINI_ARRAY 08049f0c 000f0c 000004 00 WA 0 0 4 [21] .jcr PROGBITS 08049f10 000f10 000004 00 WA 0 0 4 [22] .dynamic DYNAMIC 08049f14 000f14 0000e8 08 WA 6 0 4 [23] .got PROGBITS 08049ffc 000ffc 000004 04 WA 0 0 4 [24] .got.plt PROGBITS 0804a000 001000 000018 04 WA 0 0 4 [25] .data PROGBITS 0804a018 001018 000017 00 WA 0 0 4 [26] .bss NOBITS 0804a02f 00102f 000001 00 WA 0 0 1 [27] .comment PROGBITS 00000000 00102f 000034 01 MS 0 0 1 [28] .shstrtab STRTAB 00000000 00171b 00010a 00 0 0 1 [29] .symtab SYMTAB 00000000 001064 000470 10 30 47 4 [30] .strtab STRTAB 00000000 0014d4 000247 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)
Pra facilitar a análise, crie uma tabela com os valores em hexadecimal, em decimal e os valores de 64 bits menos os valores de 32 bits. Se 64 bits tiver valores maiores, o resultado é positivo. Do contrário, negativo. Isso mostra que a quantidade bytes alocados é maior ou menor em cada caso.
| Name | Type | Size 64 bits (hexa) | Size 32 bits (hexa) | 64 bits (dec) | 32 bits (dec) | Bigger? |
| NULL | 0 | 0 | 0 | 0 | 0 | 0 |
| .interp | PROGBITS | 00001c | 154 | 28 | 340 | -312 |
| .note.ABI-tag | NOTE | 20 | 168 | 32 | 360 | -328 |
| .note.gnu.build-id | NOTE | 24 | 188 | 36 | 392 | -356 |
| .gnu.hash | GNU_HASH | 00001c | 0001ac | 28 | 428 | -400 |
| .dynsym | DYNSYM | 78 | 0001cc | 120 | 460 | -340 |
| .dynstr | STRTAB | 45 | 00022c | 69 | 556 | -487 |
| .gnu.version | VERSYM | 00000a | 00027e | 10 | 638 | -628 |
| .gnu.version_r | VERNEED | 20 | 00028c | 32 | 652 | -620 |
| .rela.dyn | RELA | 18 | 0002ac | 24 | 684 | -660 |
| .rela.plt | RELA | 48 | 0002b4 | 72 | 692 | -620 |
| .init | PROGBITS | 00001a | 0002cc | 26 | 716 | -690 |
| .plt | PROGBITS | 40 | 0002f0 | 64 | 752 | -688 |
| .plt.got | PROGBITS | 8 | 330 | 8 | 816 | -808 |
| .text | PROGBITS | 0001a2 | 340 | 418 | 832 | -414 |
| .fini | PROGBITS | 9 | 4,00E+04 | 9 | 262144 | -262135 |
| .rodata | PROGBITS | 4 | 0004f8 | 4 | 1272 | -1268 |
| .eh_frame_hdr | PROGBITS | 34 | 500 | 52 | 1280 | -1228 |
| .eh_frame | PROGBITS | 0000f4 | 00052c | 244 | 1324 | -1080 |
| .init_array | INIT_ARRAY | 8 | 000f08 | 8 | 3848 | -3840 |
| .fini_array | FINI_ARRAY | 8 | 000f0c | 8 | 3852 | -3844 |
| .jcr | PROGBITS | 8 | 000f10 | 8 | 3856 | -3848 |
| .dynamic | DYNAMIC | 0001d0 | 000f14 | 464 | 3860 | -3396 |
| .got | PROGBITS | 8 | 000ffc | 8 | 4092 | -4084 |
| .got.plt | PROGBITS | 30 | 1000 | 48 | 4096 | -4048 |
| .data | PROGBITS | 00001f | 1018 | 31 | 4120 | -4089 |
| .bss | NOBITS | 1 | 00102f | 1 | 4143 | -4142 |
| .comment | PROGBITS | 34 | 00102f | 52 | 4143 | -4091 |
| .shstrtab | STRTAB | 00010c | 00171b | 268 | 5915 | -5647 |
| .symtab | SYMTAB | 678 | 1064 | 1656 | 4196 | -2540 |
| .strtab | STRTAB | 230 | 0014d4 | 560 | 5332 | -4772 |
Como pode ser visto na tabela, em todas as partes de cabeçalho ELF do executável, 64 bits é menor. O resultado é um binário com mais espaço na memória por alguma diferença na GNU libc, que não necessariamente significa que seu programa está ocupando mais memória em 64 bits. Pelo contrário. O stack pra dados alocados em geral é o mesmo que em 32 bits, mas o binário criado é mais eficiente com menor uso.
Espero com isso ter mostrado que 32 bits em arquitetura de 64 não traz um benefício real em dados. O motivo de pessoas dizerem que ficou mais rápido? Pode ser o resultado de algum outro problema de HD ou coisa do tipo, mas não pela arquitetura da CPU rodar melhor 32 bits em 64 bits, como alguns acham que é. No fim essa discussão de melhor ou pior fica num campo de sensações. Então é complicado argumentar contra alguém que acha que ficou mais rápido.
Minha sugestão final: se tem uma CPU que suporta 64 bits, use 64 bits.
E começou 2017. Pra celebrar o ano novo, resolvi entrar com tudo no Ubuntu 16.04, Xenial.

Apesar de ser 2017 e o Ubuntu 16.04 ter sido lançado em abril de 2016, a versão que uso é corporativa, o que significa homologada pela empresa. Então leva um tempo até estar certificado pra uso (o que significam várias adaptações na Intranet também). O anúncio de sua disponibilidade foi quase no fim de dezembro de 2016 e fiquei feliz de começar 2017 já com um sistema novo.
Eu tinha já atualizado meu desktop pro 16.04, mas eu praticamente nunca o uso. Está lá o steam instalado, mas eu dificilmente ligo. Quem me adicionou pra jogar saber disso (spoiler: eu também jogo mal pra caramba).
Mas a instalação no meu laptop seria um passo muito maior, com uso diário e desenfreado do sistema, puxando ao limite.

Nem preciso dizer que até rolou uma lágrima quando rebootei meu Ubuntu 14.04 com 241 dias de uptime pra fazer upgrade. Foram quase 8 meses de longevidade. Mas eu precisava desse upgrade. Um sistema de 2014 estava pra lá de desatualizado.
A instalação foi tranquila e terminou depois de aproximadamente meia hora. Mesmo sendo um laptop com SSD, o que demorou mesmo foi a recuperação dos dados do meu /home. E sim, foi preciso reinstalar. Recomendação da Canonical.
Mas como alguém forjado no fogo do Unix através de décadas, certeza que fiz backup. Inclusive perdi um certo tempo salvando meus containers preciosos de docker. E... esqueci de fazer backup do diretório onde salvei os containers. Mas meu /home foi recuperado. .oO(nota mental: salvar os containers num diretório que eu realmente faça backup)
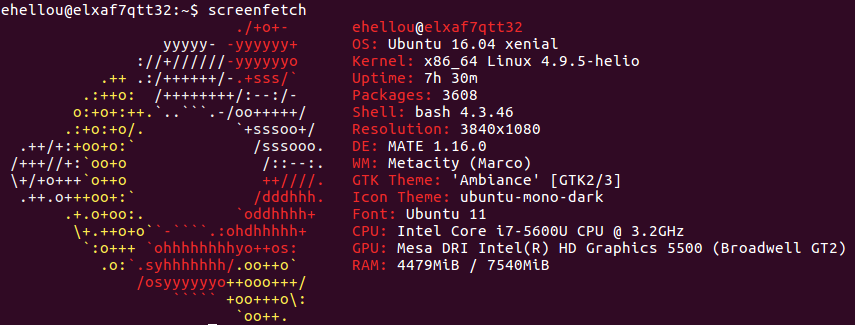
O Ubuntu 16.04 já sai pedido atualizações pra virar 16.04.1. Sinal do tempo que levou pra ser homologado. O kernel padrão é o 4.4.x, então não perdi tempo e, enquanto sincronizava o /home, já fui dando git clone no repositório do kernel. Tentei o kernel 4.9 mas encontrei problemas no suspend e na parte gráfica. Tentei o 4.10-rcx e também encontrei instabilidade. Voltei pro 4.7.x. Fiquei com ele até ontem, quando problemas na placa gráfica da Intel começaram a aparecer (os videos, como efeito colateral, ficavam sempre atrasados em relação ao som). Então compilei o 4.9.5 que teve release faz 2 dias. E aparentemente está tudo funcionando melhor.
Linux elxaf7qtt32 4.9.5-helio #7 SMP PREEMPT Sat Jan 21 23:35:49 CET 2017 x86_64 x86_64 x86_64 GNU/Linux
Mesmo rodando systemd, minha decepção ficou por conta do KDE5. Vários coredumps, travadas em geral, mudança na proteção de tela, que agora é uma insossa tela estática com imagem ao invés de xscreensaver, mundança na UI de configuração e, o que foi o pior, mudança na API de systray do Xprotocol. Isso significou que programas como pidgin e keepassx simplesmente não voltam mais se são minimizados. A coisa desandou tanto que tive de sair do KDE5. Experimentei alguns outros WMs e no fim terminei com o mate. Não sou fã do Gnome, mas o mate deve servir até eu recompilar o KDE4 inteiro pro Xenial. Essa é a solução que vi no momento. Eu estava tão excitado com plasma... decepção... decepção...
Mas fora o KDE5, o sistema roda redondo. Já gravei 2 webcasts esse ano no Unix Load On e o gerenciamento de dispositivos funcionou lindamente (pavucontrol na veia). Também já fiz um vídeo com o Kdenlive que se mostrou melhor e até mais rápido que a versão que usava no 14.04.
No geral estou feliz com a versão mais nova do Ubuntu, mas triste em ver que o KDE permitiu um release tão podre da sua versão 5. E antes que mencionem ser uma versão mais velha e com muitos bugs, eu sincronizei com o ppa do kubuntu pra pegar os releases e updates mais recentes. Alguns bugs resolvidos mas... coredump em quase tudo.
E vamos ver se chego novamente nos 241 dias de uptime. Só faltam 240 dias e 6 horas pra chegar lá.
A convite do pessoal do SecurityCast, participei de um webcast pra desmistificar sobre ataques em redes de telefonia, mais especificamente no core da rede, nos enlaces de sinalização SS7.
Não sei se consegui deixar muito claro os pontos, pois o tempo é curto pra entrar em detalhes, mas espero ter respondido a maioria das dúvidas sobre essa rede e sua segurança.
As redes de sinalização de telefonia não tem criptografia ou algo do tipo, mas estão cercadas por um ambiente seguro. A segurança do perímetro é responsável por garantir o sigilo, confidencialidade e integridade da informação, não a rede em si.
Faz anos que escrevi sobre um uptime de 100 dias, em guerra dos 100 dias, e agora finalmente bati esse uptime.
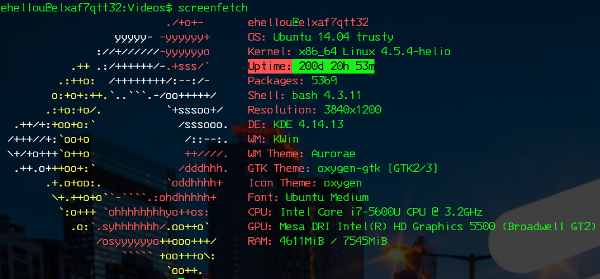
No momento o uptime é um pouco maior:
17:42:23 up 212 days, 3:29, 31 users, load average: 1.54, 1.25, 1.27
mas já vale pra ilustrar o quanto o Linux evoluiu em estabilidade. Não só ele, mas toda a distro, que no meu caso é Ubuntu.
Anteriormente a maioria de problemas que exigiam o desligamento eram sempre relacionados com driver de vídeo Intel (na época do uptime de 100 dias). Recentemente eu experimentei alguns congelamentos por falta de memória e até mesmo alguns crashes ao mudar de monitor (altero com bastante frequência entre só a tela do laptop, laptop e um monitor, e laptop e projetor). Também tive problemas com entrada e saída de áudio com pulseaudio.
Por esse motivo eu sempre tentei compilar uma kernel mais recente e experimentar. No caso estou 4.5.4. Nem era dos mais estáveis e ainda está com bug de segurança pra acesso local, como o Dirty COW. Uma vez que a invasão exige acesso local, estou relativamente seguro (se acessarem meu laptop, provavelmente será mais pelo valor do equipamento que pelos dados).
Mas uso diariamente meu laptop e de forma bastante extensiva. Uso com docker, compilação de programas em C e C++, VMs com virtualbox e libvirt, edição de vídeo e de fotografia, etc. É o famoso "pau pra toda obra". E sem demais problemas.
Encontrei alguns? Com certeza. Tive alguns crashes do Xorg. Mas como tenho habilitado o <ctr>+<alt>+<backspace> pra fechar o X inteiro e forçar um restart, não perdi nada além alguns segundos.
Fico feliz em usar Linux de uma maneira tão útil e que permite ser produtivo, tendo meu desktop pronto somente abrindo a tampa.
E por falar de desktop, fiz recentemente um vídeo pra mostrar o porquê de eu usar KDE, que adoro.
E agora tentar chegar em 365 dias. Ou mais.

Software livre pode ser uma vantagem estratégica pra empresas, seja como forma de manter os custos baixos com uso da gratuidade dos programas ou seja como forma de inovação tecnológica pela forma simples e aberta de integrar os software. Mas e no lado pessoal? Como seguir uma carreira com software livre?
Contarei como foi no meu caso, mas... não recomendo seguir os mesmos passos. Eu tive sorte de uma questão de momento, que abriu uma enorme oportunidade pra mim. Atualmente essa mesma condição não existe mais. Então tente ver a questão de oportunidade aproveitada e só isso. Como o texto ficou muito longo, resolvi quebrar em partes pra abordar o início, e como se desenvolveu em seguida.
[AVISO: O RESTANTE DO TEXTO É LONGO E CONTÉM MUITA, MUITA, MAS MUITA NOSTALGIA]
Eu comecei com software livre na faculdade, UFSC, em 97. Eu tinha um computador que havia sido sucateado pela família, um 486, mas que era perfeito pros meus trabalhos na faculdade. Por um acaso muito grande, um raio caiu na rede elétrica e fritou a placa mãe. O que foi um grande azar na época acabou por se tornar um catalisador do restante da minha vida profissional nos 19 anos seguintes (e contando).
Sem muita opção eu acabei arrumando uma placa mãe de um 386 com 8MB de RAM com um amigo (valeu kibão!). Sem coprocessador numérico. A máquina era uma carroça e o tal do Windows 95 travava o tempo todo. Naquela época a vida era um inferno.
E nesse inferno por coincidência eu iniciei uma matéria optativa: Unix. Achei muito legal o sistema e descobri que tinha uma variação dele que rodava no meu cambaleante 386: era um RedHat. Acho que 4. Dois CDs de instalação da Cheap&Bytes.

De início não funcionava. Eu não conseguia instalar, mas o tal de Slackware, em disquetes funcionava. Levei 1 mês pra desvendar o problema que era o cdrom conectado na placa de som e que exigia um parâmetro extra no RedHat após o boot. Mas esse mês de insistência me ajudou a aprender o caminho unix de se fazer as coisas: leia as manpages!
Eu passava horas e horas nos laboratórios da faculdade lendo howtos e manpages na Internet. Documentação existia, mas não era fácil mandar um "como faz isso aqui" pra alguém responder. Existia a lista de discussão linux-br, mas perguntar algo que estava facilmente disponível em documentação era pedir pra ser chicoteado em praça pública. A caminhada da vergonha de Sersei em game of thrones é muito menos humilhante pra ter idéia de como era. Mas nesse ambiente hostil, onde só os mais fortes sobreviviam, eu consegui permanecer. E instalar o tal RedHat.
Era um prazer imensurável ter aquele ambiente OpenWin igual do Solaris da faculdade rodando em casa. E tinha spice (um programa de simulação de circuitos elétricos - coisa de quem faz engenharia elétrica)! Não exatamente aquele todo gráfico e bonitinho da faculdade, mas um todo em texto. O importante era que funcionava. E depois de ter aprendido a usar o editor vi, entre muitas lágrimas de revolta e me perguntando como alguém poderia ter criado aquilo, o spice era moleza.
Mas não tinha editor de textos WYSIWYG (What You See Is What You Get - o que você vê é o que você quer). Não tão simples quanto o Microsoft word. Essa limitação me levou rapidamente a aprender e usar latex. Textos muito mais elegantes num "vi" de distância de você. A bem da verdade eu usava emacs pra isso.
Não demorou muito e tudo aquilo virou minha paixão. Escolhi uma distro pra viver a minha vida com o mesmo amor com que se escolhe um time de futebol. Era torcida pura e simples. Flameware de formatos de pacotes, escrever textos e documentação sobre tudo o que fazia e participar de encontros. Foi assim que acabei indo pro primeiro FISL e conhecendo essas figuras que depois fizeram e até hoje fazem parte da minha vida profissional e até mesmo pessoal.

Nessa época meu sonho era ser sysadmin. Mas não sysadmin de Linux. Eu queria ser daqueles sysadmins que eram mitos. Um quase Denis Ritchie. Só não podia ser trabalho com Windows. No máximo uma configuração de servidor samba.
Então nesse pique quase que obssessivo por me torna um sysadmin, eu comecei a fazer consultorias em Unix. Alguns eram implementação de firewall, que eu já dominava com certa facilidade, outras eram pra instalar uma solução completa de servidor web, mail e dns. Fiz vários updates de servidores SCO pra Linux ou FreeBSD, que virou minha outra paixão nessa época (um TRUE Unix se comparado com Linux, que vinha do Minix - meu pensamento na época).
Toda essa introdução de como comecei com Linux é somente pra ilustrar de como eu não tinha a menor idéia do que estava fazendo. Não sei se outros da mesma geração como Eduardo Maçan, Nelson Murilo e Klaus Stedding-Jenssen sabiam. Sem modéstia nenhuma, esses caras eram monstros em Unix. Eu achava divertido, mas não entendia nada de Unix, programação, redes de computadores ou mesmo segurança. Só me achava o máximo por rodar um Unix em casa igual ao da faculdade. Lutar pela liberdade? A luta era sair do Windows. Essa era a luta pra mim. E ter um computador funcional num 386 de 8 MB de RAM sem coprocessador numérico. Essa era liberdade que eu queria.
Com o caminho de sysadmin escolhido, mergulhei em livros e estudei muito. Quase abandonei a faculdade de engenharia elétrica pra tentar seguir só como sysadmin. Nesse ponto o fato de morar em Florianópolis ajudou bastante pois era difícil encontrar emprego na área. Então acabei levando a faculdade até o fim. Do contrário teria tomado a decisão errada de parar os estudos.
Ao terminar a faculdade, e tentando viver como sysadmin, consegui alguns trabalhos em provedores locais que usavam Linux. Tive inclusive a oportunidade de trabalhar com máquinas FreeBSD. Mas a quantidade de trabalho não era tão grande assim, nem pagava tão bem. Então eu mantinha uma bolsa de trabalho na faculdade também.
Com os "freelas" aparecendo, consegui uma oportunidade pra cobrir um colega numa empresa de treinamentos. Esse foi meu início como instrutor de cursos de Linux, segurança e logo depois de cabeamento estruturado. Eu entendia de Linux, mas segurança e cabeamento... então tive de buscar apostilas e livros e estudar. Pra cabeamento estruturado até mesmo uma certificação Furukawa eu tive de fazer.

Mas esse estudo e empenho trouxeram frutos. Logo começaram a aparecer projetos maiores e mais interessantes, com empresas grandes. Eu me associei à empresa de treinamentos e conseguimos uma parceria pra representar a Conectiva, empresa brasileira de sistema GNU/Linux, no estado de Santa Catarina. Com a boa quantidade de trabalho, acabei abandonando a bolsa da faculdade pra me dedicar ao que eu gostava, que era ser um sysadmin profissional, instalando e configurando servidores, firewalls, IDSs, etc.
Mas logo eu comecei a sentir as limitações regionais. Muitos dos trabalhos exigiam não somente meu mundinho sysadmin, mas uma integração total de sistemas em rede, ou seja, conhecer melhor roteadores e switches. As opções de aprendizado eram complicadas pela falta de equipamento, que na época era muito cara. Com isso eu tomei a decisão de buscar emprego numa empresa maior, onde eu pudesse ter contato com esse tipo de equipamento e tecnologia.
E assim eu consegui um trabalho em São Paulo, na empresa onde trabalho até hoje. Essa parte em diante, deixo pra contar no próximo post :)
Abrimos uma pesquisa pra saber se as pessoas gostariam de um hangout falando sobre free software e open source, história, movimentos e polêmicas. O "sim" ganhou uma larga margem, então fizemos o último programa do canal "Unix Load On" sobre isso.
Não sei se foi abordado tudo o que deveria ser falado, mas tenho certeza que a discussão longa, interminável e improdutiva sobre o asssunto também continuará. Infelizmente.
Então aproveitem.
Estive trabalhando nos últimos tempos em publicar as palestras do FISL no Youtube. Por que fazer isso? Bom... primeiramente pra atender um interesse próprio que é assistir os vídeos na minha SmartTV, que é Smart, roda Linux, mas não suporta o formato OGV disponibilizado no site do FISL (software livre é sobre coçar sua coceira, lembram?). Publicando o conteúdo no Youtube continua OGV por trás, mas daí a TV aceita o format HMTL5 pra envio do stream do vídeo.
Mas isso não é tudo. Publicando no Youtube um público que não sabe da existência do FISL vai ter acesso aos vídeos. Tenho notado vários acessos de gente no exterior ao conteúdo em inglês.
E tudo é feito de forma automatizada. Como cada FISL usou uma forma distinta de publicação, tenho usando um mesmo script modificado a cada edição do evento. Eles estão armazenados na minha conta de Github.
https://github.com/helioloureiro/homemadescripts
No momento estão carregados os vídeos da última e penúltima edição do FISL, mas pretendo carregar o máximo possível dos eventos anteriores.
O outro motivo, além da disponibilização dos vídeos em outra plataforma (mesmo não sendo software livre), é ter um acesso permanente aos vídeos. No momento estão hospedados nas máquinas da ASL assim como um dia tivemos nossas listas de mails nos servidores da CIPSGA (Comitê de Incentivo à Produção de Software Gratuito e Alternativo). Não sei se a ASL está no mesmo nível da CIPSGA, que usava máquinas na SERPRO se não estou enganado, e por uma falha de disco perderam todos os dados, mas por precaução melhor fazer a maior quantidade de cópias possíveis dos vídeos.
Essa é a idéia no momento.
Nota: eu vi que alguns vídeos estão sem alguns caractéres. É alguma conversão de utf-8 que deu errado :(

Depois da festança, sempre vem a ressaca. Sempre. O governo brasileiro sente com força esse pós-festa que se reflete em toda economia e deve durar ainda alguns bons anos pra se recuperar (haja engov). Tudo causado por um certo "abuso" nos gastos que junto com um certo "otimismo demais" e uma não leitura da realidade resultou nisso.
E o governo brasileiro não está sozinho. Eike Batista sofreu do mesmo mal com suas empresas X. Vendidas como o modelo de empresas que se deveriam seguir no Brasil, com o típico empresário de sucesso, a bonança terminou antes que qualquer projeto fosse finalizado e empresas gerassem algo mais que prejuízo. Como resultado a ressaca foi brava. Quem acreditou, perdeu muito dinheiro. Não, o Eike não perdeu dinheiro.
Em software livre existe algo parecido. A festança foi a celebração da luta contra "as redes devassas", contra a "monitoração da NSA". Como a canção de Gilberto Gil, todos gritavam "vamos fugir, desse lugar, babe" e apontavam a solução pra redes como Diaspora, Quitter, OpenMailBox, RiseUp, etc. Quando escrevi o artigo as empresas nefastas e redes devassas, já apontava um problema de sustentabilidade: como uma alternativa dessa se mantem viável? Quem paga essa conta?
Mas era época de festança. Quem liga pra quem paga a conta enquanto tem cerveja? E gratuita! Todo brasileiro que se dizia ativista corria em euforia pra nova rede gratuita, gritando que errados eram os outros. Éramos vendidos. Não sabíamos o preço de nossa liberdade.
Mas chegou a ressaca. Hoje ao entrar na rede do Diáspora, que faço pelo joindiaspora.com, que consegui participar por convite do Eduardo (BoiMate), encontrei um botão de doação. Pra se manter vivo, o serviço precisa de máquina, acesso Internet, eletricidade, etc. De forma voluntária é mantido o software e sistema, mas isso não basta: precisa de dinheiro.
Da mesma forma, com praticamente nenhum uso, tenho uma conta no OpenMailBox. Das mensagens que recebo, o mesmo tipo de pedido: precisamos de dinheiro pra continuar existindo!
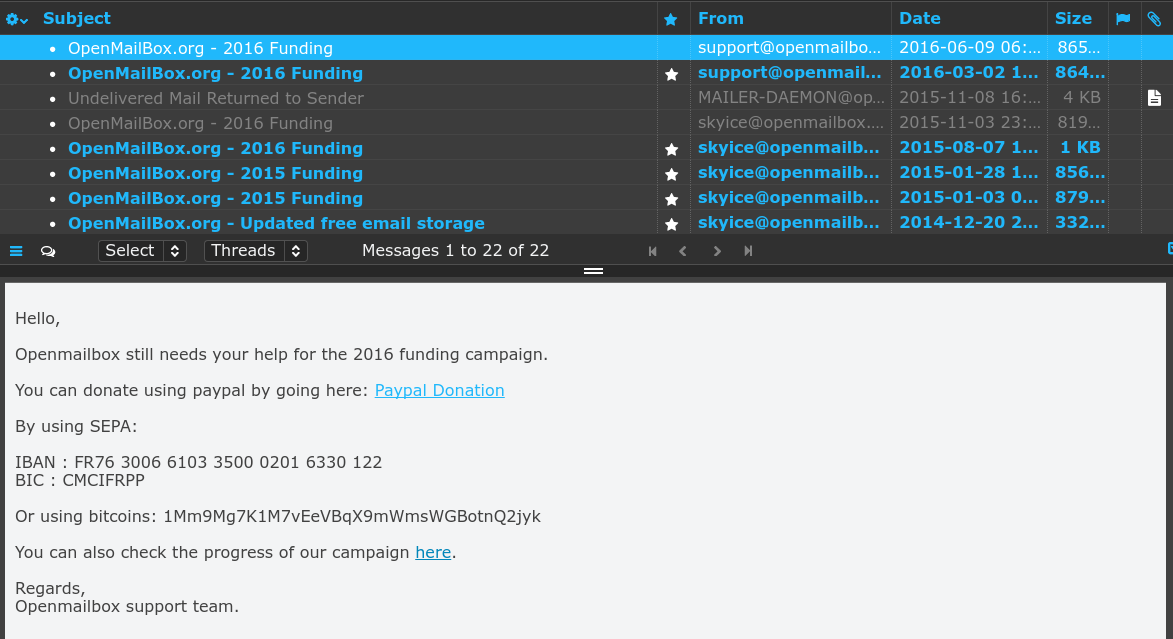
É algo terrível ou anti-ético? Pelo contrário. Se o modelo de financiamento não é por monetização com propaganda, nem vendendo nossos meta-dados, nada mais transparente que pedir dinheiro. Querem usar o serviço? Ajudem a manter! A ASL pediu doações pra realizar o FISL e teve, segundo relatos, um dos melhores FISLs dos últimos anos. Vários serviços buscam financiamento pra se manter, inclusive a FSF.
De minha parte eu contribuo para:
Não é um valor alto, na verdade algo como 20 reais por mês em cada (exceção da FSF que cobra beeeeem mais caro), mas já deve ajudar.
E você que usa software livre, pra qual projeto faz doação em dinheiro? Não acha que vale à pena ajudar algum projeto que goste? Pense bem nisso antes da ressaca bater forte.
Em janeiro eu escrevi sobre a palestra de Richard Stallman na universidade de Estocolmo, cujo assunto era privacidade. Algumas pessoas contestaram o que foi escrito por mim pela falta de provas documentais como vídeos ou gravação de áudio. Infelizmente no início da palestra, que era sobre privacidade, ele pediu para que todos desligassem seus celulares e não postassem nada sobre ele lá, muito menos com tag, pra evitar a geolocalização. Não só eu mas todos que pude ver guardaram seus celulares que estavam prontos pra gravar a palestra. E ninguém levou uma câmera como alternativa :(
Eu também nunca gastei muito tempo pra responder os questionamentos sobre o que escrevi, que foi arduamente defendido pelo Patola (valeu Patola!), pelo simples fato que são 2 ou 3 que semprem dizem esse tipo de coisa e não acrescentam muita coisa numa discussão de software livre. Eu prefiro não gastar energia com esse tipo de polêmica vazia.
Mas felizmente Stallman repete bastante as palestras. Não são exatamente iguais pois por aqui ele adicionou quase 1 hora a mais sobre privacidade e Snowden, mas na parte sobre software livre é a mesma coisa nas que eu vi.
Depois de Estocolmo ele fez uma palestra em Zurique na Suiça.
e agora apareceu uma outra palestra em espanhól no congresso de soberania tenológica em Barcelona.
Tem de assistir ambas? Se quiser discutir os pontos que coloquei antes, sim. Do contrário a palestra de Zurique está melhor pra ver os slides, mas está em inglês. A de Barcelona é mais fácil de entender, mas não aparecem os slides. O mundo não é mesmo perfeito...

O Debian Jessie, última versão estável do sistema operacional universal Debian, foi lançado a quase 1 ano. Somente agora criei coragem de fazer o upgrade. Estava rodando Wheezy, a versão anterior que entrou em LTS (Long Term Support ou suporte estendido), que atendia bem o site mas, sempre existe um mas, descobri alguns problemas de limitação do kernel com o greyd.
Alguns sites não estavam sendo marcados corretamente com ipset. Como o greyd foi criado pra versões mais recentes de kernel (Wheezy rodava com um linux-3.2), a opção era desativar o greyd ou atualizar o sistema. Então vamos atualizar!
Sem ajuda dos trus La_Sombra e Rootsh nada disso seria possível. Foi um trabalho de garimpo no passado pra achar como conectar na VM e quem ainda tinha a chave de conexão. Culpa disso pela estabilidade do sistema. Obrigado Debian!
Eu já tinha feito o upgrade do Ubuntu LTS, de 14.04 pro 16.04, e esperava alguns problemas que seriam corrigidos com reboot e uns "apt-get -f install", então o acesso ao console era essencial. Parte dessa espectativa era também o motivo pra ter postergado esse upgrade. systemd é algo que ainda me dói no alma.
Pra fazer o upgrade? Do bom e velho jeito do Debian: primeiramente deixando atualizado na versão corrente, Wheezy
# cd /etc/apt # apt-get update && apt-get upgrade
Em seguida mover a versão pra Jessie e continuar com upgrade.
# cp sources.list sources.list.wheezy # cat sources.list.wheezy | sed "s/wheezy/jessie/" > sources.list # apt-get update # apt-get dist-upgrade
Pronto. É isso. Fácil assim.
Foram uns 500 MB de download, uma vez que é um servidor e roda só o necessário, um reboot e... saiu funcionando de primeira! Eu achando que o systemd ia encrencar com alguma coisa e... nada! Claro que nem tudo foi tão bem assim. Precisei arrumar algumas configurações do servidor web, assim como do mail, mas muita coisa saiu funcionando sem mexer. Ainda estou com problemas com o dovecot, mas nada que force uma volta ao Wheezy pra corrigir.
Parabéns à equipe do Debian por um sistema tão afinado e redondo assim. Continua sendo minha distro preferida.

SPAM é uma batalha sem fim. Cria-se uma forma de mitigar ou diminuir e são apenas algumas semanas de sossego. Logo eles acham uma forma de burlar as barreiras que criamos. Como faz tempo que não trabalho com mail de larga escala e controlo apenas a da VM do servidor desse domínio aqui, eu não tenho nem idéia do tamanho do problema que grandes empresas como Google têm. A quantidade de SPAM que tenho de lidar já é mais que suficiente pra eu me aborrecer.
Eu já implementei SPF pra verificação de origem dos mails, mailassassin, white e black list e... o volume continua alto.
Mailassassin era um dos mais promissores mas consome muita CPU a cada verificação. Além disso ele é um software muito burro (desculpem ao autores e fãs) pois ele recebe o mail pra fazer análise. Porque não fazer logo na conexão alguma verificação e descartar logo? No fim gastou banda, CPU e memória pra ver algo óbvio. Quando recebo um mail vindo de algo como "helio-a414c-loureiro.eng.
 Pois o projeto OpenBSD resolveu cuidar disso. Eles criaram um daemon que enferniza a vida de spammers. É um verdadeiro saci pererê dos e-mails. O spamd recebe o mail e funciona de uma forma muuuuuuito lenta, com a conexão bem degradada. Após terminar a tentativa de envio do mail, ele simplesmente fecha a conexão e pede que tente novamente. Se o servidor tentar novamente, muito provavelmente não é uma máquina de SPAM. Como essa tentativa seguida faz parte do protocolo SMTP, servidores legítimos continuaram tentando enquanto spammers vão pra outra pobre vítima.
Pois o projeto OpenBSD resolveu cuidar disso. Eles criaram um daemon que enferniza a vida de spammers. É um verdadeiro saci pererê dos e-mails. O spamd recebe o mail e funciona de uma forma muuuuuuito lenta, com a conexão bem degradada. Após terminar a tentativa de envio do mail, ele simplesmente fecha a conexão e pede que tente novamente. Se o servidor tentar novamente, muito provavelmente não é uma máquina de SPAM. Como essa tentativa seguida faz parte do protocolo SMTP, servidores legítimos continuaram tentando enquanto spammers vão pra outra pobre vítima.
No último hackathon que participei eu tentei fazer um port desse daemon pro Linux. Encontrei um port já em andamento chamado obspamd no github, que estava com o build quebrado, e consegui arrumar o que estava com problemas. Minha idéia era fazer um daemon funcional e completo portado pra Linux, com autoconf e configure. E foi num dos bug reports que eu estava respondendo que alguém mandou outra mensagem avisando que existia um port já bem funcional do mesmo, o greyd.
Fiquei surpreso ao descobrir que até site oficial já tinha, o http://greyd.org, pois eu nunca tinha ouvido falar. Até onde vi não existem pacotes para ele em Debian ou em Ubuntu. Então boa parte da instalação foi feita manualmente.
O que eu gostaria de fazer com o obspamd, de criar um sistema de build com autoconfigure, já está pronto no greyd. Além disso ele já implementa as chamadas de kernel pra adicionar as regras de firewall necessárias pro funcionamento do greyd.
Por quê do firewall? Tanto o original, spamd, quanto o greyd funcionam ouvindo na porta 8025. Então todo pacote que não foi classificado, baseado em IP de origem, ao tentar conectar na porta 25, padrão de mail, é redirecionado à porta 8025. O greyd segue com a conexão e marca esse tipo de pacote como provável whitelist (lista branca). Na segunda tentativa de conexão esse pacote já vai direto pro servidor de mail, que no meu caso é um postfix. Esse controle é feito através do firewall iptables com regras no PREROUTING e ipset do kernel, marcando tipos de pacote com IP de origem. E precisa do módulo conntrack do kernel.
Como é um programa bem recente, não existem pacotes pra ele. Ao menos em Debian/Ubuntu. Então ele ainda exige a compilação e instalação manual.
Para baixar o greyd diretamente do github:
# git clone https://github.com/mikey-austin/greyd.git
Pra compilação, eu escolhi usar sqlite3 como formato de arquivo de whitelist, então precisei incluir os cabeçalhos e bibliotecas referentes.
# apt-get install libsqlite3-dev libnetfilter-log-dev libnetfilter-conntrack-dev \
libpcap0.8 libspf2-dev # cd greyd # autoreconf -vi # ./configure \ --with-sqlite \ --with-netfilter \ --with-spf \ --bindir=/usr/bin \ --sbindir=/usr/sbin \ --sysconfdir=/etc \ --docdir=/usr/share \ --libdir=/usr/lib \ --localstatedir=/var \ GREYD_PIDFILE=/var/run/greyd.pid \ GREYLOGD_PIDFILE=/var/run/greylogd.pid \ DEFAULT_CONFIG=/etc/default/greyd.conf # make
O greyd também precisa que sejam criados 2 usuários: greyd e greydb, que controlam daemon e base de dados da lista. No seu repositório existe um diretório que ajuda a criar pacotes. Nele é possível ver os comandos pra realizar essa tarefa manualmente em greyd/packages/debian/postinst:
# adduser --quiet --system --home /var/run/greyd --group \
--uid 601 --gecos "greyd" --shell /bin/false --disabled-login greyd
# adduser --quiet --system --home /var/lib/greyd --group
--uid 602 --gecos "greydb" --shell /bin/false --disabled-login greydb
Em seguida é preciso criar o diretório onde a base de dados em squlite3 ou bsddb será escrita.
# mkdir -p /var/greydb # chown -R greydb:greydb /var/greydb
Com a configuração de compilação, as configuração serão armazenadas em /etc/default/greyd.conf. O spamd do OpenBSD por padrão roda em um ambiente chroot() pra proteção do sistema. Eu não consegui fazer o mesmo com o greyd. As configurações que estou usando no momento são (usando diff pra comparar):
# diff -u ./etc/greyd.conf /etc/default/greyd.conf
--- ./etc/greyd.conf 2016-07-07 13:47:43.000000000 -0300
+++ /etc/default/greyd.conf 2016-07-08 09:49:28.000000000 -0300
@@ -5,8 +5,8 @@
#
# Debugging options and more verbose logs.
#
-debug = 0
-verbose = 0
+debug = 1
+verbose = 1
daemonize = 1
#
@@ -17,7 +17,7 @@
#
# Address to listen on.
#
-bind_address = "127.0.0.1"
+bind_address = "200.123.234.321"
#
# Main greyd port.
@@ -32,7 +32,7 @@
#
# Enable listening on IPv6 socket.
#
-enable_ipv6 = 0
+enable_ipv6 = 1
bind_address_ipv6 = "::1"
#
@@ -60,7 +60,7 @@
#
# Chroot enable & location for main daemon.
#
-chroot = 1
+chroot = 0
chroot_dir = "/var/empty/greyd"
#
@@ -82,11 +82,13 @@
# Specify the maximum number of connections.
#
# max_cons = 800
+max_cons = 30
#
# Specify the maximum number of blacklisted connections to tarpit.
#
# max_cons_black = 800
+max_cons_black = 30
#
# The firewall configuration.
@@ -114,8 +116,8 @@
#
section database {
#driver = "/usr/lib/greyd/greyd_bdb_sql.so"
- #driver = "/usr/lib/greyd/greyd_sqlite.so"
- driver = "/usr/lib/greyd/greyd_bdb.so"
+ driver = "/usr/lib/greyd/greyd_sqlite.so"
+ #driver = "/usr/lib/greyd/greyd_bdb.so"
path = "/var/greyd"
db_name = "greyd.db"
Em geral ele funciona apenas na interface de loopback, mas por usar um Debian mais velho, o Wheezy, precisei ajustar pra ouvir na interface pública, a eth0.
Feito isso, basta iniciar o daemon e o daemon de controle de log:
# /etc/init.d/greylogd start # /etc/init.d/greyd start
Para quem já usa sistemas com systemd:
# systemctl start greylogd # systemctl start greyd
O próprio systemd cuidará de adicionar e habilitar esses serviços.
Mas ainda falta o firewall. São necessárias algumas regras na inicialização:
# ipset create greyd-whitelist hash:ip family inet hashsize 1024 maxelem 65536 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j LOG --log-prefix "[GREYD WHITED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j NFLOG --nflog-group 155 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j ACCEPT # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD 25 DNAT]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j DNAT \
--to-destination 200.123.234.321:8025 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD 25 REDIRECTED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j REDIRECT \
--to-ports 8025 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD FAILED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 8025 -j LOG \
--log-prefix "[GREYD 8025 JAILED]" # iptables -t filter -A INPUT -p tcp --dport smtp -j ACCEPT # iptables -t filter -A INPUT -p tcp --dport 8025 -j ACCEPT
Eu adicionei mais logs pra poder também acompanhar os pacotes, pra ver se estão sendo marcados ou não de acordo.
De início eu fiquei na dúvida se eu estava recebendo algum e-mail ou não, mas logo percebi que estava funcionando de acordo.
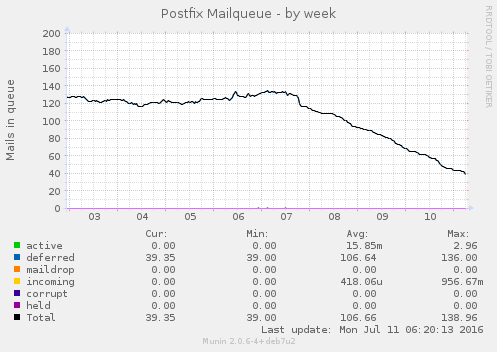
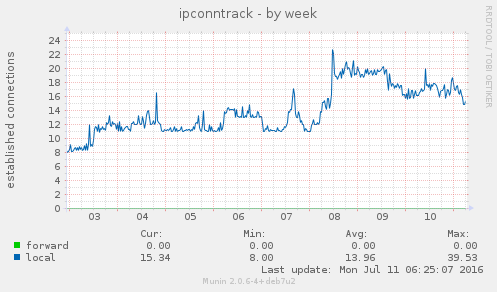
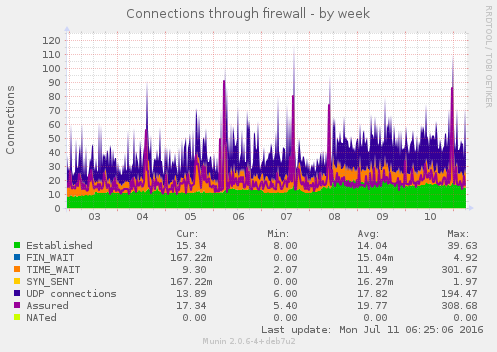
A fila de mails indesejados, que ficavam travados por não ter endereço de retorno, praticamente zeraram. O uso de memória aumento um pouco, assim como o conntrack no kernel. Por enquanto nada absurdo. E parece estar funcionando bem até agora. Se não respondi algum mail seu, já sabe o motivo.
Acabaram os SPAMs? Não! Spam é spam. Enquanto houver mail, existirá spammers. É fácil de implementar e barato. Mas eles diminuíram. E ao saber que estou gastando a conexão deles fazendo nada já me alegra o suficiente.
Meu próximo passo será gerar um pacote no meu ppa no launchpad: https://launchpad.net/~helioloureiro
Pra saber mais como lutar contra spam: http://antispam.br/

Reusando o código que escrevi pra tirar snapshots durante a PyConSe e publicar automaticamente no Twitter, escrevi um pequeno aplicativo pra raspberypi com Python pra pegar o mesmo tipo de imagem, mas da minha janela, e ir acompanhando a evolução do tempo ao longo do dia e do ano. Essa é a imagem que ilustra o início do post.
Acho que será legal fazer uma animação das imagens mostrando o sol que brilha até quase 11 da noite, o inverno que escurece às 2 da tarde, e a neve chegando. E tudo postando no Twitter.
As ferramentas são as mais simples possível: um raspberrypi conectado com um dongle wifi e uma webcam USB creative (que aliás uso pra participar dos hangouts). E sempre Python pra fazer tudo.


Descobri que o Forecast.IO fornece uma API com JSON pra buscar a previsão do tempo atual e até 10 dias, com permissão de 1000 queries por dia de forma gratuita. Perfeito pro meu pequeno projeto. O mais difícil foi fazer a conversão da temperatura de Farenheit pra Celsius (meus dias de vestibulando já se foram faz muito tempo), mas pedi ajuda à Internet pra isso. Fiz uma pequena função que retorna os dados que quero em forma de um array.
import requests
import json
import time
"""
Um monte de código por aqui
[...]
""""
def get_content():
timestamp = time.strftime("Date: %Y-%m-%d %H:%M", time.localtime())
msg = []
msg.append("Stockholm")
msg.append(timestamp)
url = "https://api.forecast.io/forecast/%s/%s" % (wth_key, wth_loc)
req = requests.get(url)
jdata = json.loads(req.text)
summary = jdata["currently"]["summary"]
temp = jdata["currently"]["temperature"]
temp = Far2Celsius(temp)
msg.append(u"Temperature: %s°C" % temp)
msg.append("Summary: %s" %summary)
return msg
A primeira coisa que precisei alterar foi a adição de textos à imagem. Tendo a informação vinda do Forecast.IO, eu precisava modificar a imagem pra que ela aparecesse. No início eu usei uma fonte de cor branca, mas logo percebi que preto ficava com um contraste melhor. Mas quando chegar o inverno, época em que os dias são realmente muito curtos por aqui, vou precisar pensar numa forma pra trocar para branco. Mas no momento usei as bibliotecas do PIL que manipulam imagem em Python.
import Image
import ImageFont, ImageDraw, ImageOps
IMGSIZE = (1280, 720)
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
"""
Um monte de código por aqui
[...]
""""
def WeatherScreenshot():
msg = get_content()
if not msg:
msg = "Just another shot at %s" % \
time.strftime("%H:%M", time.localtime())
if msg:
msg_body = "\n".join(msg[1:])
im = Image.open(filename)
# just get truetype fonts on package ttf-mscorefonts-installer
try:
f_top = ImageFont.truetype(font="Arial", size=60)
except TypeError:
# older versions hasn't font and require full path
arialpath = "/usr/share/fonts/truetype/msttcorefonts/Arial.ttf"
f_top = ImageFont.truetype(arialpath, size=60)
try:
f_body = ImageFont.truetype(font="Arial", size=20)
except TypeError:
# older versions hasn't font and require full path
arialpath = "/usr/share/fonts/truetype/msttcorefonts/Arial.ttf"
f_body = ImageFont.truetype(arialpath, size=20)
txt = Image.new('L', IMGSIZE)
d = ImageDraw.Draw(txt)
d.text( (10, 10), msg[0], font=f_top, fill=255)
position = 80
for m in msg[1:]:
d.text( (10, position), m, font=f_body, fill=255)
position += 20
w = txt.rotate(0, expand=1)
im.paste(ImageOps.colorize(w, BLACK, BLACK), (0,0), w)
im.save(filename)
descobri que a versão de raspbian que estou usando, baseado em Debian Wheezy, tem uma API um pouco diferente e pode precisar que a fonte com o path completo seja passada no argumento.
Outra alteração foi mudar a chamada pra webcam capturar a imagem que era uma função mas modifiquei pra uma thread. Assim o tempo fica consistente. Do contrário ao invés de mostrar 12:00 apareceria algo como 12:03 (o tempo pra adquirir a imagem).
import threading
def WeatherScreenshot():
th = threading.Thread(target=GetPhoto)
th.start()
msg = get_content()
th.join()
E já que mencionei a imagem, esse foi o maior problema até agora. Descobri que não existe uma forma muito confiável de inicializar a webcam. Às vezes ela adquiri a imagem de forma bonitinha, às vezes fica super exposta, outras vezes sub.

E não tem nada que dê um feedback sobre a qualidade. Li vários artigos com dicas de uso com pygame, que é a forma que uso, e com opencv também, mas todas com o mesmo princípio. Basicamente fazem um start() no framework da webcam, que inicializa a webcam, adquirem um número de imagens aleatórios (alguns dizem 30) e esperam pelo melhor ao capturar a imagem. Nada que retorne um indicador de qualidade. Nada.
DISCARDFRAMES = 2 * 30
def GetPhoto():
filename = None
pygame.init()
pygame.camera.init()
elif os.path.exists("/dev/video0"):
device = "/dev/video0"
if not device:
print "Not webcam found. Aborting..."
sys.exit(1)
# you can get your camera resolution by command "uvcdynctrl -f"
cam = pygame.camera.Camera(device, IMGSIZE)
cam.start()
time.sleep(3)
counter = 10
while counter:
if cam.query_image():
break
time.sleep(1)
counter -= 1
# idea from https://codeplasma.com/2012/12/03/getting-webcam-images-with-python-and-opencv-2-for-real-this-time/
# get a set of pictures to be discarded and adjust camera
for x in xrange(DISCARDFRAMES):
while not cam.query_image():
time.sleep(1)
image = cam.get_image()
image = cam.get_image()
Basicamente um método de tentativa e erro. Por isso que iniciei a chamada à webcam como thread. Como as webcams USB tem CPU própria, não tem - até onde pesquisei - uma API confiável pra verificar se o balanço de branco normalizou antes de capturar a imagem. Só retornam a própria imagem. Tosco.
Então resolvi fazer um outro script como módulo, que basicamente mapeia toda a imagem em seu tamanho e cria um dicionário do tipo "COR: quantas vezes". Descobri que valores RGB (pega o valor de R + G + B, soma e divide por 3 pra ter a média) acima de 235 já indicam super exposição. Não só isso. Como eu conto a quantidade que aquele valor RGB aparece, sempre que um valor sobressai acima de 15% do total, já indica uma imagem ruim. Não é um dos melhores métodos científicos, mas tem funcionando bem (verifiquei nas imagens já adquiridas e salvas). Os tempos de aquisição de imagem mudaram de até 1 minuto pra em torno de 10 minutos. Mas por enquanto com qualidade muito melhor.
import Image
def brightness(filename):
"""
source: http://stackoverflow.com/questions/6442118/python-measuring-pixel-brightness
"""
img = Image.open(filename)
#Convert the image te RGB if it is a .gif for example
img = img.convert ('RGB')
RANK = {}
#coordinates of the pixel
X_i,Y_i = 0,0
(X_f, Y_f) = img.size
#Get RGB
for i in xrange(X_i, X_f):
for j in xrange(Y_i, Y_f):
#print "i:", i,",j:", j
pixelRGB = img.getpixel((i,j))
R,G,B = pixelRGB
br = sum([R,G,B])/ 3 ## 0 is dark (black) and 255 is bright (white)
if RANK.has_key(br):
RANK[br] += 1
else:
RANK[br] = 1
color_order = []
pic_size = X_f * Y_f
print "Picture size:", pic_size
for k in sorted(RANK, key=RANK.get, reverse=True):
amount = RANK[k]
# if low than 15%, ignore
if amount < (.15 * pic_size):
continue
print k, "=>", RANK[k]
color_order.append(k)
if color_order:
print color_order
return -1
return 0
O código todo está disponível no meu github.
https://github.com/helioloureiro/snapshot-twitter
E provavelmente devo lançar um gif animado posteriormente com o decorrer do clima ao longo do ano.
Tenho alguns problemas como concorrência no caso de tentar adquirir uma imagem ao mesmo tempo que a crontab tentar fazer isso (implementei uma API em REST pra isso, mas não é algo pra publicar :). Devo implementar algum tipo de lock usando /tmp, mas algo simples.
E agora no verão, com sol até quase 11 horas da noite, tenho também um pequeno problema de negação de serviço que às vezes acontece.


Ainda não descobri um módulo em Python pra mitigar isso :)

Eu nunca escrevi sobre séries ou filmes por aqui, mas essa série da HBO vale como uma exceção.
É uma comédia que satiriza o ambiente de startups do vale do silício, nos EUA. Pra quem está pensando em abrir um negócio no modelo de startup, com software livre principalmente, vale a pena assitir. Vai ter algo especifico de software livre? Vai ter GNU vs Linux? Não, não é uma série sobre tecnologia nesse nível. É sobre o ambiente de competição de startups. É mais sobre a área de negócios, mas não faltam referências a servidores, cloud, etc.
Como qualquer comédia que se espera, tem um grupo disfuncional que trabalha na startup que é tema da série. Geeks anti-sociais no bom estilo que precisam trabalhar em grupo mesmo não sabendo nem conversar entre si. E por aí segue a série, com uma ótima visão de problemas de startup, como o uso de SCRUM por um time que não acredita em agile, mandar tudo pra nuvem sem nem ao menos saber o que é nuvem, prometer algo que não tem prazo pra entregar, e por aí. E a pressão! A pressão pra virar uma startup rentável enquanto é dito o mantra "dinheiro não é importante, o importante é ter valor" e não ter dinheiro pra pagar os funcionários.
Mesmo com o tom de comédia traz uma ótima reflexão sobre o insano mundo de startups e a forma bizarra que se tornou tocar o negócio, desde a captação de investidores anjos (não tão anjos assim) quanto a perda de controle da empresa para esses novos donos.
Eu assisti apenas as 2 primeiras temporadas, mas recomendo. É uma aula de MBA em forma de comédia.
Page 17 of 38
