
Essa é uma dica pra quem, como eu, cria vários bots por aí. Se você quer dar uma carinha bonita pro perfil do bot, existe esse site que gera uma imagem pra você: https://robohash.org/
Eu gerei uma aqui pro site pra ter uma ideia.

Eu não lembro quem passou a dica disso. Mas nunca mais parei de usar. Nada como ter um rosto no seu robô preferido.
Pra quem acompanha o https://linux-br.org deve ter percebido que o ritmo de postagem caiu bastante. Na verdade despencou em comparação com o ano passado.
E não, não foi mais um bug que eu introduzi.
Ao contrário. Eu diria que fiz os artigos mostrados serem mais seletos. Primeiramente usando um filtro melhor de palavras de interesse. Descobri que meu filtro anterior tinha um erro no regex (sempre ele) e não funcionava como eu queria. Na verdade não fazia nada e passava qualquer tipo de artigo. Esse tipo de coisa de regex quando a gente faz errado...
Corrigido o problema de filtrar as palavras chaves, durate a refatoração do código eu resolvi só adotar artigos que tinha feito upload de uma imagem com sucesso. E isso já restringiu ainda mais o volume de postagens pra modestos 1 ou 2 por dia. Às vezes nem mesmo isso. E espero que esse efeito ajude a mais pessoas a participarem do site, algo que está longe de acontecer pelos números de acessos diários.
2024 já com força total :)
Recentemente tem circulado no Mastodon as mensagens do site https://crieaporradeum.blog/ que é um tradução do https://startafuckingblog.com/ e um incentivo um tanto passivo-agressivo pras pessoas criarem seus próprios sites. Como eu.
Não sei bem se usando uma linguagem assim consiga realmente incentivar as pessoas a fazerem isso, mas eu ao menos vi algumas respostas positivas. O que me faz pensar que talvez eu deva começar a usar o mesmo tipo de linguagem passivo-agressiva pra convencer as pessoas a fazerem algo.
Enquanto isso deixo aqui uma imagem com o mesmo estilo que fiz numa outra vida agora. Espero que também sirva de incentivo pra quem está lendo aqui a fazer... sei lá. Faça qualquer coisa com isso desde que seja algo positivo. Ao menos eu espero que seja positivo.

E façam a porra de um blog!
Foi o que pensei que ia acontecer. Infelizmente as coisas não saíram como esperado.
E claro que já resolvi o problema, que foi relacionado com php8.2-mysql, do contrário não estaria lendo esse artigo. Mas podia ter acontecido lá depois de julho...
Recebi essa semana um resumo do google maps sobre o tanto que pedalei no ano passado.
Eu tenho duas contas, uma genérica e outra desse domínio, e cada uma veio com uma distância diferente mesmo sendo a mesma pessoa com o mesmo telefone e aplicativos. Não sei explicar o motivo.
Mas o fato é que pedalei bastante ano passado. Algo próximo de 2000 Km. E com certeza acima de 1800 Km.
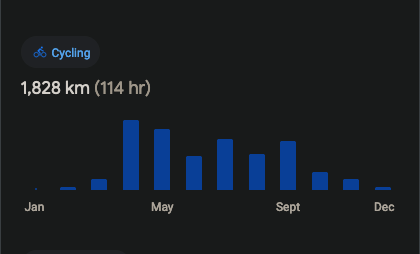
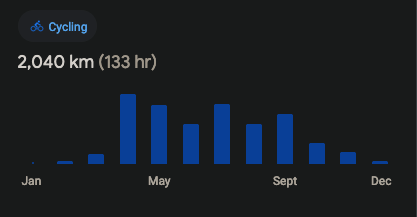
Só espero conseguir repetir o feito esse ano e talvez até passar dessa marca.

E novamente renovo meus votos de que o próximo ano será o ano do Linux no desktop. Já é líder em cloud, servidores, telefone, televisores e tudo mais que pensar. Até a Microsoft usa Linux com WSL. Então não existe motivo de não usar Linux no desktop também.
E eu realmente adoro voltar ao meu archlinux aqui e usar ctrl+c e ctrl+v ou ctrl+shift+c e ctrl+shift+v ao contrário do command+c e command+v do Apple. O hardware é legal, o sistema operacional é um belo BSD, mas a interface gráfica é pobre se comparada a um KDE por exemplo.
Então que venha 2024 e junto com o ano novo o Linux em todos os desktops.
Feliz ano novo!
Por algum motivo estranho e bizarro eu simplesmente parei de gerar os vídeos da passagem do ano capturada pela câmera do raspberry pi 3.
Então esse fim de ano resolvi colocar tudo em dia. Ainda falta de 2023, que farei após o início do ano, mas os anos anteriores estão aqui. E com buracos. Não foi todo ano que consegui capturar as imagens diariamente por uma série de razões. De memory card corrompido à libcamera quebrada. E nem sempre percebi isso rapidamente.
Mas estão aí as imagens pra quem quiser ver e ficar um pouco mais de 5 minutos admirando a passagem do tempo. Dica: é hipnotizante.

Resolvi dar aquele tapa de fim de ano no raspberry pi que tenho, versão 3 e talvez B mas não tenho certeza. E fiz upgrade pro Bookworm, último release do Debian.
O site não recomenda fazer isso e sim reinstalar o sistema operacional. Mas eu sempre tento o upgrade primeiro e guardo a opção de reinstalar pro último caso.
Acabei perdendo acesso ao wifi durante o upgrade e precisei tirar ele da janela e mexer aqui na mesa. Nada demais e aparentemente deu certo.
Aparentemente...
Toda vez que eu tentava algum comando que mandasse muitos dados como "dmesg" ou "journalctl -b -1", a conexão travava. E como fica ali na janela, sem cabo de rede perto, eu nunca soube se era problema do ssh ou do wifi ou que simplesmente travava. Apenas sabia que depois que travava eu não conseguia mais conectar.
Junto a isso as fotos da janela começaram a sair muito ruins. Com muita exposição.

No fim acabei botando de novo aqui na mesa e mexendo pra ver se acertava a parte do ssh.

Achei uma dica em "https://discourse.osmc.tv/t/solved-ssh-connection-sometimes-hangs/76504" pra alterar o "/etc/ssh/sshd_config" e adicionar as seguintes linhas:
IPQoS cs0 cs0
E reiniciando o sshd. Realmente deu certo. A conexão passou a ficar estável. O segredo foi mudar o ToS pra best effort com cs0.
Eu também mudei o /etc/rc.local pra rodar e deixar o wifi sem power management e evitar qualquer problema de conexão que esse pudesse causar.
iwconfig wlan0 power off
A parte da câmera eu não consegui acertar aqui na mesa. Simplesmente não consegui abrir o programa gráfico pra isso. No fim fiz ajustes no programa que uso com rpicam-still, que parece ser o novo programa pra usar.
Eu ainda não olhei como ficou a exposição da manhã, mas a de noite está bacana.

E no fim arrumei com o parâmetro "--shutter".
Quem quiser olhar ou re-usar o script, está aqui no github:

Eu tenho postado pouco aqui. Mea culpa. Totalmente.
Mas é porque tenho trabalhado bastante em outras coisas. Uma delas é no https://linux-br.org, our melhor, em sua automação.
Hoje eu estava olhando a quantidade de posts no site. É um histórico bastante interessante.
2018 Abril: 12
2018 Maio: 42
2018 Junho: 33
2018 Julho: 19
2018 Agosto: 16
2018 Setembro: 18
2018 Outubro: 21
2018 Novembro: 8
2018 Dezembro: 2
2019 Janeiro: 0
2019 Fevereiro: 2
2019 Março: 1
2019 Abril: 1
2019 Maio: 0
2019 Junho: 0
2019 Julho: 0
2019 Agosto: 0
2019 Setembro: 0
2019 Outubro: 0
2019 Novembro: 0
2019 Dezembro: 0
2020 Janeiro: 14
2020 Fevereiro: 4
2020 Março: 0
2020 Abril: 6
2020 Maio: 0
2020 Junho: 1
2020 Julho: 0
2020 Agosto: 1
2020 Setembro: 1
2020 Outubro: 2
2020 Novembro: 0
2020 Dezembro: 0
2021 Janeiro: 0
2021 Fevereiro: 0
2021 Março: 0
2021 Abril: 1
2021 Maio: 0
2021 Junho: 0
2021 Julho: 0
2021 Agosto: 0
2021 Setembro: 0
2021 Outubro: 0
2021 Novembro: 0
2021 Dezembro: 0
2022 Janeiro: 1
2022 Fevereiro: 0
2022 Março: 0
2022 Abril: 1
2022 Maio: 0
2022 Junho: 1
2022 Julho: 0
2022 Agosto: 0
2022 Setembro: 0
2022 Outubro: 0
2022 Novembro: 1
2022 Dezembro: 0
2023 Janeiro: 1
2023 Fevereiro: 0
2023 Março: 0
2023 Abril: 1073
2023 Maio: 718
2023 Junho: 462
2023 Julho: 893
2023 Agosto: 832
2023 Setembro: 799
2023 Outubro: 202
2023 Novembro: 834
2023 Dezembro: 286
O site começou cheio de gás e contribuidores. Depois passou por momentos de abandono até que entram os posts automatizados. E pula de 0 pra mais de 1000 artigos. A média tem sido por volta de 800 e é possível ver quando houve algum problema, como no mês de outubro desse ano quando o upgrade do Debian quebrou parte dos pacotes Python usados.
Apesar do maior número posts, isso não contribuiu muito pra maior audiência do site. Ele continua com pouco ou nenhum acesso.
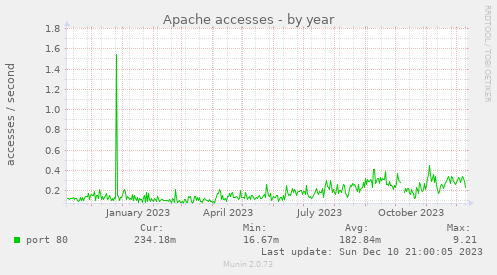
Esse dado de acesso ao servidor web não é só pro linux-br, é pra esse site aqui e mais alguns outros hospedados na mesma VPS.
Bom... ao menos temos um site de notícias funcionando. Quem sabe o restante virá com o tempo?

Estava ouvindo o último episódio do podcast dos programadores, o mesmo que já comentei em aprendendo a programar através de desafios com o site osprogramadores, e o entrevistado comentou sobre já ter visitados 11 países. Eu nunca tinha pensado no assunto, mas também passei dos 10 países que já visitei.
Claro que não passei muito tempo em cada um deles, mas trabalhar com o que trabalho já me possibilitou viajar bastante pelo mundo.
Os países que já visitei:
E isso que cancelei algumas viagens pra destinos como Holanda e Alemanha.
E claro que não passei muito tempo em cada país. Alguns eu passei e passo só o fim de semana, como é o caso da Bélgica onde vou pro FOSDEM.
Mas visitei :)
Pra quem tiver interesse em ouvir o episódio, é esse aqui:
.oO(nota mental: já não posso usar o número de países que visitei como token pra recuperar senhas)

Interessante existirem poucos posts sobre isso, mas mailman3 é um desastre perto do que era mailman2.
Mailman2 era o gerenciado de email feito em cima da versão do python2. E tudo funcionava belo e bonito. Mas um dia surgiu uma grande ruptura que foi o python3, um cataclisma em forma de versão nova. Python3 quebrou chamadas e mudou a ponto de inutilizar tudo que foi feito em python2. Por si só isso já seria um aviso pra evitar Python de forma geral, mas todo mundo acabou migrando pro Python3 e assumindo que os problemas foram pra trazer uma melhoria geral no desempenho e uso da linguagem. Mas tente sugerir um Python4 pra ver o que acontesse...
E nesse tsunami causando desastre por onde passava chamado Python3, veio o upgrade do mailman2 pra mailman3 pra rodar com python3. Mas ao invés de manter o código que existia, decidiram quebrar em várias partes e até enfiar django no meio da coisa. Resultado: um desastre.
Uma das instalações que temos de mailman3 simplesmente não funciona. Outra que tínhamos, ficou fora do ar por 2 anos. Como não tinha muito tráfego, não foi tanto problema, mas eu não conseguia achar o problema do sistema não funcionar. Por sorte achei um site que deu uma letra de que poderia ser que um dos diretórios que são usados não estava com as permissões certas. E foi isso. Logs pra ajudar? Nada. Eu só via erro ao acessar o postifx. Então eu passei basicamente 2 anos tentando arrumar um problema que não existia entre o mailman3 e o postfix.
E agora chegou o momento de migrar as listas que temos num servidor interno na firma. O atual roda no Ubuntu 18.04 e estamos migrando pra uma VM nova rodando Ubuntu 22.04. E cadê o mailman3? Sim, ele não entrou no Ubunt 22.04. Simplesmente estava quebrado e não entrou. Até agora não existe um pacote usável do mesmo.
https://bugs.launchpad.net/ubuntu/+source/mailman3/+bug/1999197
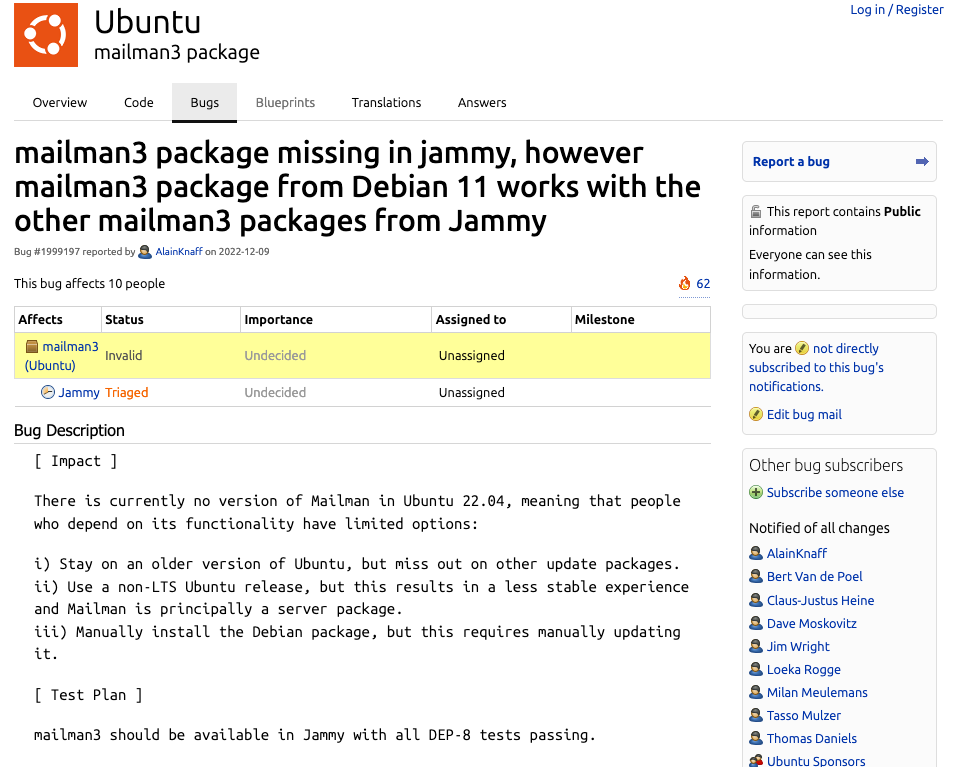
Então resta a opção de instalar manualmente pelos fontes, certo? Certo? Certo??? Pois é... tente entrar na página do mailman3 e seguir a... instalação. É um apanhado de coisas jogadas sem descrever como fazer funcionar de forma consistente.
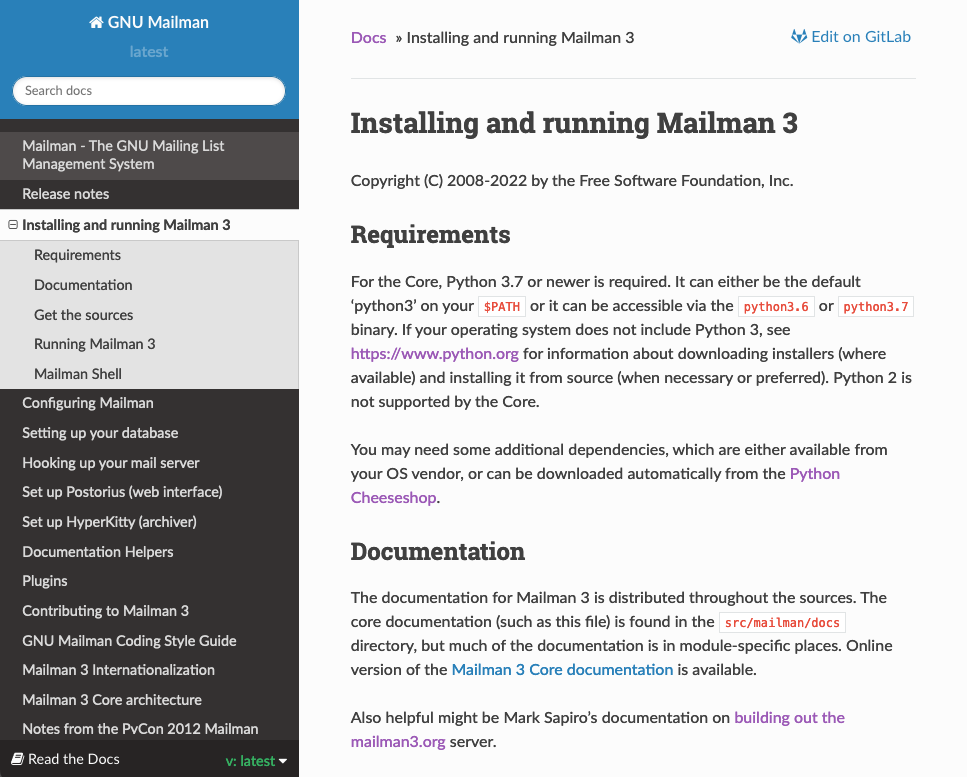



Da parte do clonar o repositório pra ter o comando mailman funcionando, como isso foi feito? Cadê o comando pra isso???
E é isso. A documentação, se melhorar muito, podemos chamar de lixo. Mas precisa melhorar, o que eu duvido muito.
Não só a instalação é lixo na forma de texto, como troubleshooting segue na mesma linha. Nenhuma informação que possa ajudar a resolver seus problemas.
E no mailman2 tudo estava rendondo, funcionando maravilhosamente. Não entende que ideia de Jerico que tiveram pra mudar completamente o produto em algo que precisa de muitas partes, desconexas pra funcionar.
E assim seguimos. Não sei se tento fazer uma instalação na mão do mailman3 on ubuntu 22.04, uma vez que não há explicação em como fazer isso, ou se jogo tudo pra cima e instalo outro servidor de lista como listproc. Acho que essa será a opção mais viável.
Continuando os posts sobre duas rodas, as últimas pedaladas que fizemos aqui em volta de Estocolmo.
O primeiro lugar chama-se Blå Lagun, que é Lagoa Azul. Lugar bem bonito mas bem remoto.
O segundo foi pra um bairro mais distante que tem a opção de voltar de trem, Bålsta.

Pediram algumas dicas sobre bicicletas no Mastodon, o que respondi prontamente. No final o histórico que contei pro lá acho que é algo que vale a pena guardar aqui, pra ficar salvo pra posteridade.
Eu não era uma pessoa que pedalava pra valer. Eu sempre gostei de andar de bicicleta, mas eram aquelas distâncias curtas de no máximo 15 Km. Muitas vezes bem menos que isso.
Então eu tinha uma Caloi Aluminum, uma mountain bike que me servia muito bem.

Ela tinha um bagageiro traseiro, que eu prendia a mochila, e algumas vezes ia trabalhar com ela. Mas naquela época era dureza. Não existiam ciclovias e eu tinha de lutar pelo meu lugar no asfalto com carros, ônibus, fretados e motoboys. E não foram poucas as vezes que até os motoboys me fecharam, pra eu cair mesmo. Até hoje não sei se tinham raiva por eu estar ali no trânsito pedalando ou se era apenas pra ver eu cair mesmo. Mas com isso minhas frequências de pedaladas não eram lá grande coisa.
Chegou o momento de mudar pra Suécia e empacotei a bicicleta pra vir pra cá. Veio no container, então chegou uns 3 meses depois que já estávamos instalados aqui numa casa em que alugamos em Sollentuna.
Mas como por aqui existem ciclovias pra todo lado (ou quase todo lado como fui descobrir mais recentemente), eu estava doido pra pedalar aqui e ir pro trabalho.


Eu aindei com ela algumas vezes até perceber que o garfo estava ao contrário. Mas foi o começo e passei a pedalar um trecho que o Google dizia levar 20 minutos pra eu completar. Eu levava 50 minutos. E chegava morrendo na empresa.


Eu era um barnabé sobre duas rodas. Usava um capacete bem ordinário que ganhei de um colega do trabalho e um par de luvas que comprei na loja de materiais de construção. Era basicamente um "luva de pedreiro" do pedal. E continuava amarrando minha mochila no bagageiro traseiro, que rendeu algumas quedas no meio do caminho.
Logo chegou o inverno e eu decidi continuar pedalando.


E aí os problemas começaram. Pra derreter o gelo, jogam uma areia com sal. Bastante sal. Então primeiro foi a catraca que travou e ficou rodando sem travar a roda. Tive de comprar um solvente pra derreter o sal que estava dentro pra pode voltar a usar.
Em seguida foi um dos pedais. Deu folga onde é parafusado e caiu. Simplesmente caiu. Eu tinha um par extra, mas descobri que a rosca, que era alumínio, no crankset corroeu com o sal. Então colei o pedal com superbonder e segui pedalando. Ela ainda rodava, e assim eu passei o inverno. E mudei pra onde moro até hoje.
Por aqui existe um bicicletário onde você coloca uma das rodas e deixa a bicicleta lá travada. E esse foi o problema.

O vento empurrou a bicicleta de lado e entortou a roda. Então eu tinha uma roda torta, um crankset colado e um pedal perdido. Cotei os preços pra trocar e era o preço de uma bicicleta nova. Aliás com a mão de obra saia até mais caro. Foi aí que passei pra minha primeira bicicleta local.
Nessa época eu morava no que o Google dizia levar 30 minutos pedalando e eu fazia em 45.
Essa bicicleta é um misto de mountain bike com quadro e garfo rígidos. É muito boa pra pedalar em asfalto e é possível arriscar algumas trilhas com ela. Coloquei um assento traseiro pra levar a filhota pra escolinha e depois minha mochila, mesmo no inverno, e assim parti pro pedal. No inverno sempre com pneu de inverno pra não escorregar e lamber o asfalto (o que fiz algumas vezes mesmo usando esse tipo de pneu).


Conforme a filhota cresceu e não precisou mais da cadeirinha, eu passei a usar uma cesta na traseira pra carregar as coisas. Nessa época eu já tinha comprado a roupa mais adequada pra pedalar tanto no verão quanto no inverno. Mas o inverno sempre sendo mais difícil que o verão em termos de roupa. Precisei ir ajustando os modelitos pra aguentar o tranco.


Como eu usava a bicicleta pra tudo, inclusive fazer compras, que exigia uma certa logística já que não existia um supermercado perto de casa, eu acabei trocando a cesta na traseira por uma caixa. Isso facilitava carregar compras e coisas maiores pra cima e pra baixo. Mas confesso que não era algo... visualmente bonito. Era funcional, com certeza.


E foi nessa época que também comprei esse suporte pra dar manutenção em bicicletas. Era mais barato que pagar mão-de-obra pra fazer o que eu precisava, que era majoritariamente trocar o pneu pro de inverno.

Nessa época eu consegui manter os 30 minutos de pedalada pra firma no verão. No inverno o tempo varia com qualidade da limpeza da rua, levando entre 45 minutos até 1 hora.

Se você perguntar qual a razão de eu ter comprado uma outra bicicleta, uma mountain bike, se a híbrida já me servia bem, eu vou responder que não sei, só sei que foi assim. Eu vi a bicicleta em exposição na loja e achei a cor incrível. Linda. E a suspensão ajudaria durante o inverno. E o vendedor deu um belo desconto no valor. Acho que foi 15% (mas faz bastante tempo então posso estar enganado). E comprei. Precisava? Eu não precisava. Mas eu queria. Estava passando pelo divórcio, então eu queria me dar esse presente.



Então essa foi minha segunda bicicleta aqui. E nela eu comecei a querer pedalar muito mais. Fiquei bem audacioso. E tentei algumas distâncias mais longas como 40 Km, que me deixaram exausto. o problema era o peso da bicicleta e a velocidade máxima (e a média também). Mountain bikes são ótimas pra trechos curtos, mas são muito pesadas. Eu conseguia uma velocidade máxima de 20 Km/h e uma média de 12 Km/h. Uma pedalada pra um local distante 20 Km eram praticamente 4 horas em cima da bicicleta.

Nessa época eu aderi ao uso da roupa de lycra apertada. Descobri que ela protegia muito mais do frio por estar colada ao corpo. E comprei meu primeiro kit de ciclismo com a marca da firma.


Meu tempo de pedalada pra firma não mudou muito. Continuei com o tempo de 30 minutos no verão e uns 45 no inverno.
Como eu queria pedalar longas distâncias, arrisquei e comprei uma bicicleta road da Sava. Toda de fibra carbono. A bicicleta toda pesa acho que o mesmo que a trava que eu uso na mountain bike. Bricandeira, não é tão leve assim, mas é leve. Acho que 9 Kg.

Meu primeiro problema com a road foi a falta de bagageiro traseiro. Ela veio sem a furação pra poder colocar um. Então tive de botar um que era preso ao quadro só por pressão.
Mas de resto a bicicleta era uma maravilha. Tem o passo de adaptar a usar o guidão no estilo drop-bar, mas depois de umas 5 andadas nelas, eu já conseguia me virar bem (e não cair). E consegui atingir o objetivo de pedalar numa velocidade média acima de 25 Km/h, o que viabilizava pedaladas mais distantes como eu queria. O fato de ser mais aerodinâmica também distribuiu bem o peso. Ao invés de ficar o tempo todo sentado em cima da lombar, como no caso da mountain bike, eu conseguia distribuir o peso entre os braços e as costas.
O ponto negativo era que eu ficava com dor e cansado no pescoço, nas costas e nos braços depois de uma pedalada não muito longa. Mas nada que o treino não melhorasse.
Mas no fim eu optei por comprar um braço móvel pro guidão e subir um pouco mais pra ter mais conforto nas pedaladas mais longas.




Com a Sava eu comecei a quebrar meus recordes. O mais rápido que consegui pedalar pra firma foram 22 minutos. Mas eu nunca a usei no inverno. Aliás até tomei um capote nela já no outono em cima das folhas como descrevi em Países considerados os mais felizes do mundo escondem problemas graves - levei um tombo de bicicleta. Eu continuo usando a mountain bike durante o inverno.

E por fim chegamos na última, ou a mais recente das bicicletas, a Trek Al Domane 3. O que me levou a comprar outra bicicleta se eu tinha achado meu ethos na road? Primeiro que eu estava sempre com aquele receio do bagageiro adaptado. Como forçava o quadro de forma diferente da que foi projetado, eu sempre tive a preocupação de que aquilo iria causar fadiga no carbono. O segundo ponto foi... as estradas.

Na viagem que fizemos até Upsalla, 80 Km, tivemos a infelicidade de um dos pneus furar. Mas estávamos preparados com câmaras extras, bomba de ar, etc. Mas o problema é o tipo de terreno. Em volta de Estocolmo existem ciclovias. Mas basta sair um pouco fora que invariavelmente precisamos pedalar em gravel. E uma bicicleta road o pneu é muito fino. Muito. Ela é feita pra asfalto somente.

Daí entra o investimento numa gravel. Ela tem pneu adequado, quadro mais forte, etc. E já veio com as furações pro bagageiro traseiro, além de permitir um frontal se eu quiser. Além disso a distância entre o banco e o guidão é menor, o que dá mais conforto em pedaladas mais distantes. E não precisei nem usar meu adaptador regulável. Ponto negativo? Ela é mais pesada que a road. Bem mais. Mas nela eu tenho certeza de poder usar a bicicleta pra realmente viajar e até mesmo acampar sem medo de ficar com problemas no caminho.
Eu ainda não medi meu tempo nessa gravel pra ir pra firma porque eu estou fazendo um caminho mais longo pra ir pedalando junto com um amigo. Mas imagino que eu faça abaixo de 30 minutos pelo caminho antigo, que aliás está em obras e exige um contorno bem longo que adiciona quase que 1 Km a mais.
Agora qual será a minha próxima bicicleta?

Page 9 of 39
