
Na firma estamos com um projeto de autenticar clientes usando OpenBAO. OpenBAO, pro não iniciados, é um fork do Vault da Hashicorp que por sua vez é uma forma de você gerar sua própria CA, Certificate Authority, e criar seus próprios certificados. E com isso temos um caso novo que são os computadores com TPM, Trusted Platform Module, que é um hardware que gera e armazena suas chaves criptográficas.
Na forma antiga, você recebe um token da rede e usa esse token pra pedir pro OpenBAO pra gerar tanto certificado quanto a chave privada. Com TPM, que gera sua própria chave privada e armazena localmente, você precisa gerar uma chave privada localmente e depois armazenar criar uma CSR, Certificate Signing Request, pra solicitar que seja gerado um certificado.
É preciso instalar o pacote "tpm2-tools", que vai baixar o que é preciso pra falar com o TPM. Também é preciso adicionar seu usuário no grupo "tss", do contrário somente como "root" vai conseguir acessar os devices do TPM.
Os comandos pra gerar a chave privada via TPM e o CSR são esses abaixo:
tpm2_createek -G ecc -c ek_ecc.ctx || echo "TPM already initialized"
tpm2_createak -C ek_ecc.ctx -G ecc -g sha256 -s ecdsa -c ak_ecc.ctx || echo "TPM already initialized"
tpm2_evictcontrol -c ak_ecc.ctx 0x81000000 || echo "TPM already initialized and it is persistent"
openssl req \
-provider tpm2 \
-provider default \
-propquery '?provider=tpm2' \
-new \
-subj "/CN=client.loureiro.eng.br/" \
-key handle:0x81000000 \
-out client.csr
Depois disso é enviar ao OpenBAO, que no caso está rodando via container pra testes na porta 8200 e sem TLS habilitado. O truque do "data" é colocar o certificado inteiro em uma linha só, por isso o "sed" e "tr".
curl \
-s \
-o client_data.json \
--cacert openbao_ca.crt \
--header "X-Vault-Token: $TOKEN" \
--header "Content-Type: application/json" \
--data "{\"csr\": \"$(
cat $CLIENT_CSR | sed "s/\$/@@@/g" | tr -d "\n" | sed "s/@@@/\\\n/g"
)\",\"common_name\": \"client\",\"alt_names\": \"client.loureiro.eng.br\",\"ttl\": \"90d\"}" \
"http://openbao:8200/v1/pki/sign/client-loureiro"
Feito isso, os certificados ficam disponíveis no client_data.json. Basta extrair e usar.
jq -re .data.certificate > client.csr
export OPENSSL_CONF=$PWD/openssl.cnf
export OPENSSL_MODULES=/usr/lib/x86_64-linux-gnu/ossl-modules
curl \
--cert client.csr \
--cacert openbao_ca.crt \
--key handle:0x81000000 \
--key-type PROV \
--engine tpm2 \
-H "Content-Type: application/json" \
-d '{"agent_id":"0001","message":"testing"}' \
https://api.loureiro.eng.br/v1/getdata
Na falta de uma imagem melhor ou relacionada, deixei essa do meu peruzão que comi durante o Sweden Rock.
Só um comando que uso bastante e provavelmente tem gente que nem sabe que existe.
OpenSSL tem várias funcionalidades, entre elas gerar senhas. O comando que uso é o seguinte:
❯ openssl rand -base64 32 | cut -c 1-43
O resultado é algo como isso aqui (que a cada comando resulta em algo aleatório):
❯ openssl rand -base64 32 | cut -c 1-43
EHjsiO2IIuaBzGmugiVDZgfmj83v/LqZ/nevZ5itzV0
Já faz um tempo que eu venho querendo apagar tudo o que postei no Twitter, ou X, Xwitter. Não só pelo fato da empresa ter entrado com tudo na era da merdificação, mas porque gosto de pensar que ajudei alguém a virar um milionário. Ainda mais se esse alguém era antes um bilionário.
Buscando no GitHub, encontrei algumas soluções. Uma que pareceu dar mais certa foi a tweetXer, que você abre o console no Twitter e cola código pra fazer a coisa acontecer. O risco é ser banido pelo Twitter, mas acho que nesse ponto é até lucro.
Antes de começar é preciso solicitar a criação de um backup de sua conta. Um dos arquivos js que virão é o que alimentará o script pra ir apagando. Depois é sentar e esperar.
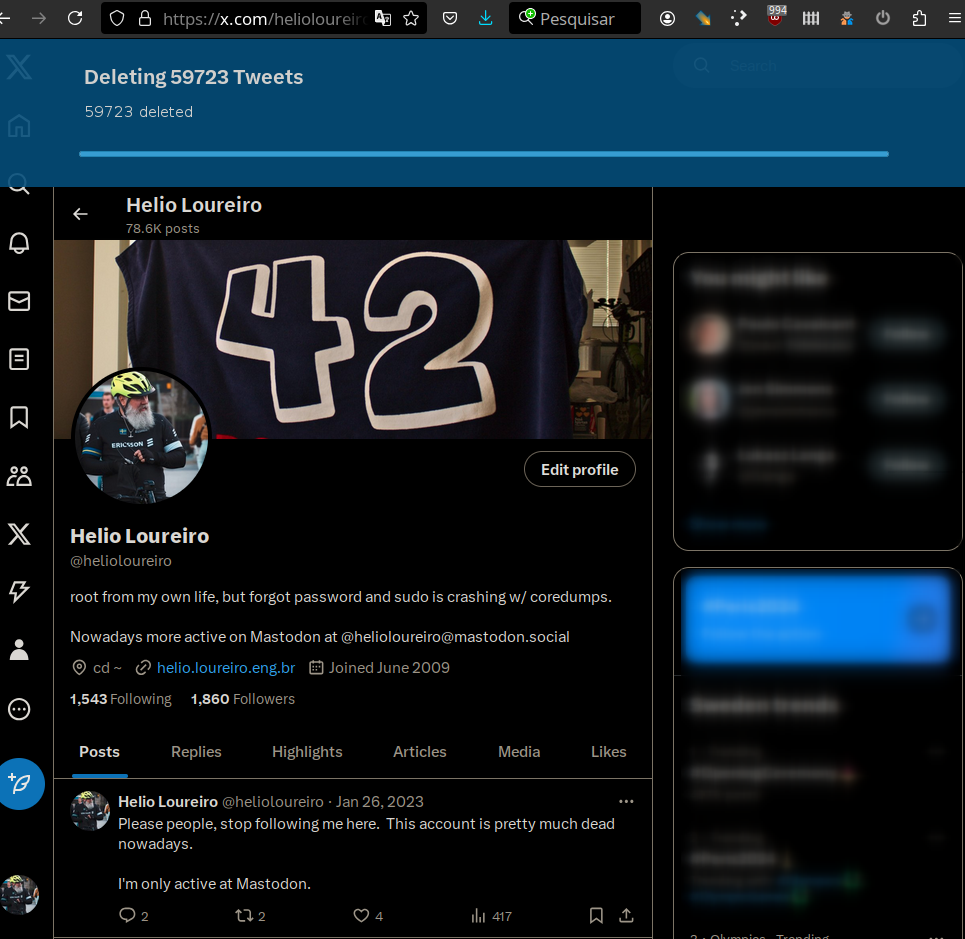
Como é possível ver na imagem acima, o treco mandou bala em 59.723 tweets meus. Haja tweets!
O resultado final foi esse aqui:
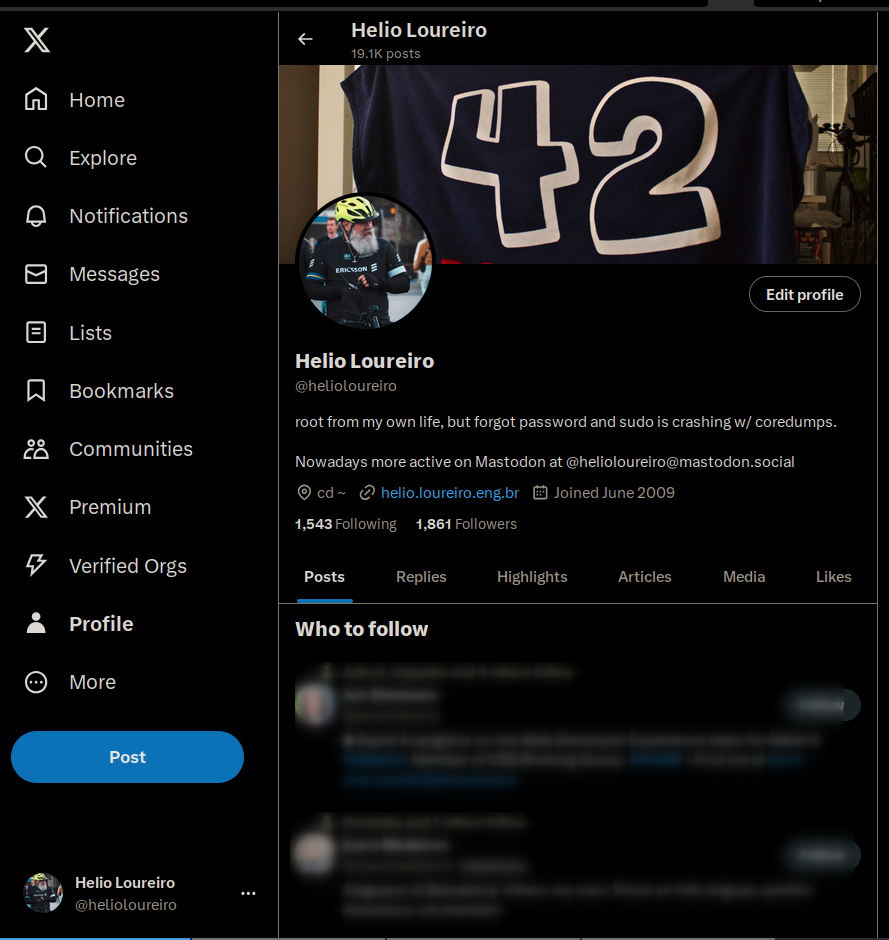
Tive de fazer o scroll em duas página pra mostrar que não sobrou nada. Nada. Foi bem eficiente. Mas...
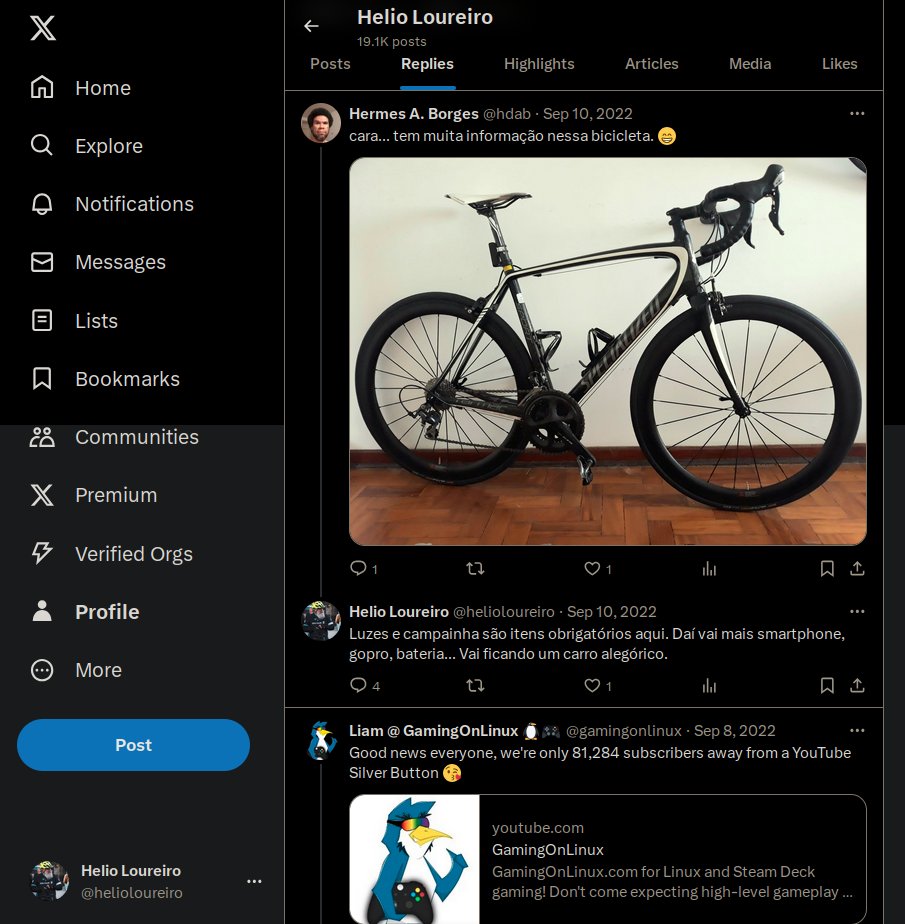
como pode ser visto aqui, meus replies ficaram pra trás.
Mesmo assim é uma ótima ferramenta pra quem quer apagar o que postou ao longo do tempo no Twitter e migrar pro Mastodon.
https://github.com/lucahammer/tweetXer
Eu entrei numa thread com a pergunta sobre o que fazer pra apagar tudo que sobrou. Até o momento segue sem reposta.
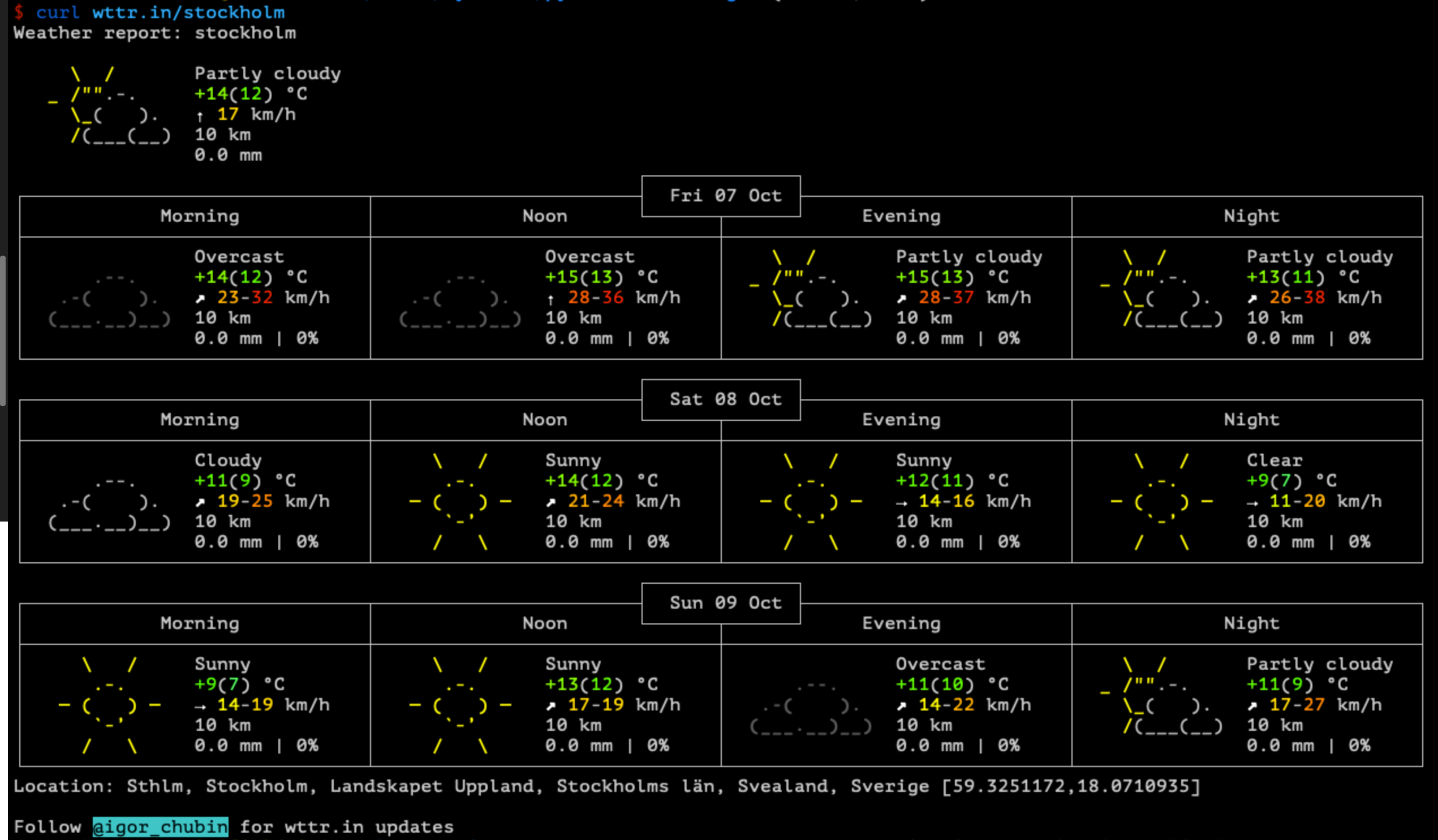
Hoje mandaram essa dica legal na firma. Você pode puxar a previsão do tempo no shell usando curl e apontando pra wttr.in/<cidade>.
Bem legal a ideia e prática.
E o código fonte está no github: https://github.com/chubin/wttr.in

Eu estou no momento trabalhando num troubleshooting de uma rede 5G. Qual a novidade? Seria o 5G? Bom... não. A diferença é que pra acessar o ambiente cloud eu preciso fazer login numa máquina e depois fazer login em outra máquina.
Nada muito glamouroso, mas não é algo que eu possa escolher não fazer. Então a forma pra ajudar a ter isso feito da forma mais rápida possível foi através dos uso de expect.
Primeiramente uma visão da rede:
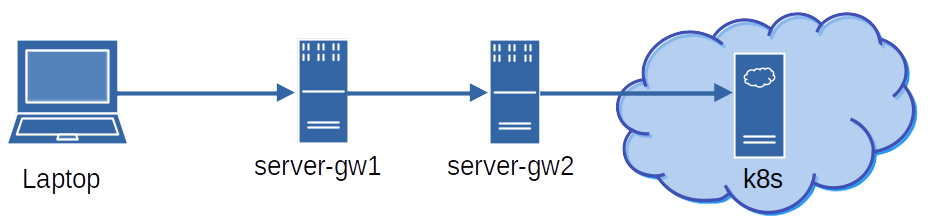
Um diagrama feito no libreoffice draw. Também nada glamouroso, mas deve dar conta do recado. Eu rodo o script, que pede somente minha senha de rede uma vez que é o mesmo usuário no server-gw1. E conecta via ssh. No server-gw2 é o mesmo usuário e senha, o que facilita as coisa. Dali pra rede k8s não tem mais nada porque eu acesso com um kube.conf e comand kubectl.
O script é esse aqui:
#! /usr/bin/expect
stty -echo
send_user -- "Entre a senha: "
expect_user -re "(.*)\n"
send_user "\n"
stty echo
set PASS $expect_out(1,string)
spawn ssh server-gw1
while {1} {
expect {
"ssword:" { send "$PASS\n" }
"(yes/no)?" { send "yes\n" }
"\$ " {break}
}
}
send "ssh server-gw2; exit\n"
while {1} {
expect {
"ssword:" { send "$PASS\n" }
"(yes/no)?" { send "yes\n" }
"\$ " {break}
}
}
interact
Note que é possível trocar pra receber o username como input ou como argumento do script. Na chamada pro segundo servidor existe um 'send "ssh server-gw2; exit\n"'. O motivo disso é pra quando eu digitar "exit" do servidor server-gw2 não precisar digitar novamente no server-gw1. Então ele faz o ssh pro server-gw2 e o próximo comando esperando já é um exit.
Espero que ajude e happy coding!
