
E o progresso do Linux no desktop continua. Mais e mais canais no YouTube passaram a usar Linux pra uma ou outra coisa.
Se antes Linux era a coisa de nerd e geeks, agora virou mainstream.
Não que pudesse ser diferente. Basta ver o que é Android hoje em dia. Não é nicho. É mainstream.
Eu já comentei do canal do PewDiePie.
Passei a acompanhar também outro canal, o Switch and Click. Está uma delícia acompanhar as aventuras dela com Linux. De Mint ela já passou pra arch. E agora Omarchy.
E pra finalizar, o canal do Leon e da Nice. Esses, Windowzeros raizes. Mas vou dizer que a grande ajuda foi terem já migrado pro macOS. Isso "azeitou" a mudança ou uso em paralelo do Linux.
E por último, um último canal recomendado recentement no grupo Linux Brasil do Telegram. O cara instala Linux numa máquina super limitada e... funciona. Não que isso seja surpresa.
Numa discussão no fediverso falamos sobre habilitar as métricas do GoToSo, também conhecido como GoToSocial. Fiz algumas mudanças e consegui expor essas métricas.
O compose.yaml do GoToSo:
services:
gotosocial:
image: docker.io/superseriousbusiness/gotosocial:latest
container_name: gotosocial
user: 1000:1000
networks:
- gotosocial
environment:
GTS_HOST: bolha.linux-br.org
GTS_DB_TYPE: postgres
GTS_CONFIG_PATH: /gotosocial/config.yaml
[...]
OTEL_METRICS_PRODUCERS: prometheus
OTEL_METRICS_EXPORTER: prometheus
OTEL_EXPORTER_PROMETHEUS_HOST: 0.0.0.0
OTEL_EXPORTER_PROMETHEUS_PORT: 9090
[...]
ports:
- "8080:8080"
- "9090:9090"
[...]
A config.yaml também do GoToSo:
[...]
media-emoji-local-max-size: 250KiB
media-emoji-remote-max-size: 250KiB
advanced-rate-limit-requests: 0
metrics-enabled: true
Uma vez que isso estava habilitado e o container reiniciado, foi só verificar a porta 9090.
❯ curl -s localhost:9090/metrics | head -10
# HELP go_config_gogc_percent Heap size target percentage configured by the user, otherwise 100.
# TYPE go_config_gogc_percent gauge
go_config_gogc_percent{otel_scope_name="go.opentelemetry.io/contrib/instrumentation/runtime",otel_scope_schema_url="",otel_scope_version="0.63.0"} 100
# HELP go_goroutine_count Count of live goroutines.
# TYPE go_goroutine_count gauge
go_goroutine_count{otel_scope_name="go.opentelemetry.io/contrib/instrumentation/runtime",otel_scope_schema_url="",otel_scope_version="0.63.0"} 167
# HELP go_memory_allocated_bytes_total Memory allocated to the heap by the application.
# TYPE go_memory_allocated_bytes_total counter
go_memory_allocated_bytes_total{otel_scope_name="go.opentelemetry.io/contrib/instrumentation/runtime",otel_scope_schema_url="",otel_scope_version="0.63.0"} 1.6433066284e+11
# HELP go_memory_allocations_total Count of allocations to the heap by the application.
Em seguida subi um container, também com podman, pra coletar esses dados. Junto com um prometheus-exporter pra coletar dados da máquina.
compose.yaml:
services:
prometheus:
image: quay.io/prometheus/prometheus
container_name: prometheus
environment:
TZ: Europe/Stockholm
ports:
- "9000:9090"
volumes:
- data:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
restart: unless-stopped
extra_hosts:
- localserver:192.168.1.2
volumes:
data:
prometheus.yml:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets:
- "localhost:9090"
labels:
app: "prometheus"
- job_name: "mimir"
static_configs:
- targets:
- "localserver:9100"
labels:
app: "mimir"
- job_name: "gotoso"
static_configs:
- targets:
- "localserver:9090"
labels:
app: "gotoso"
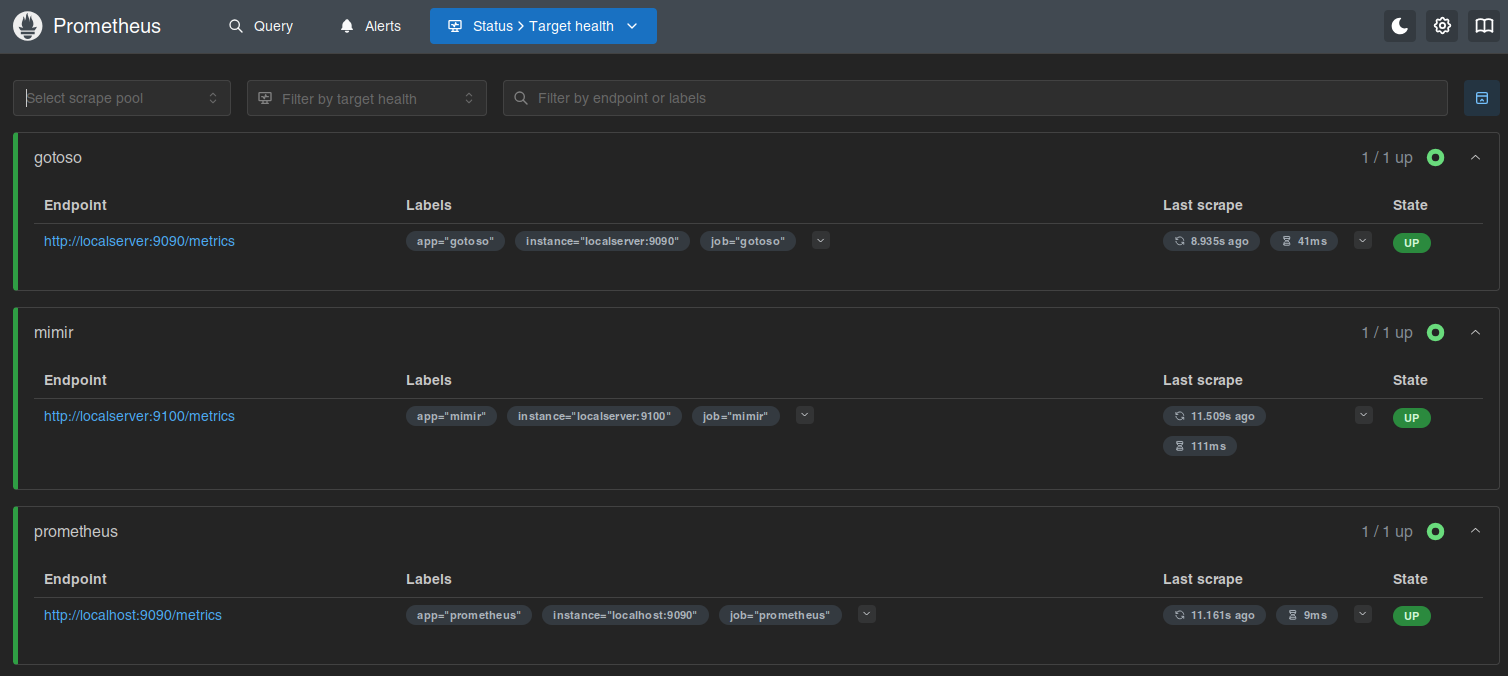
Isso já faz subir e você pode olhar no target health.
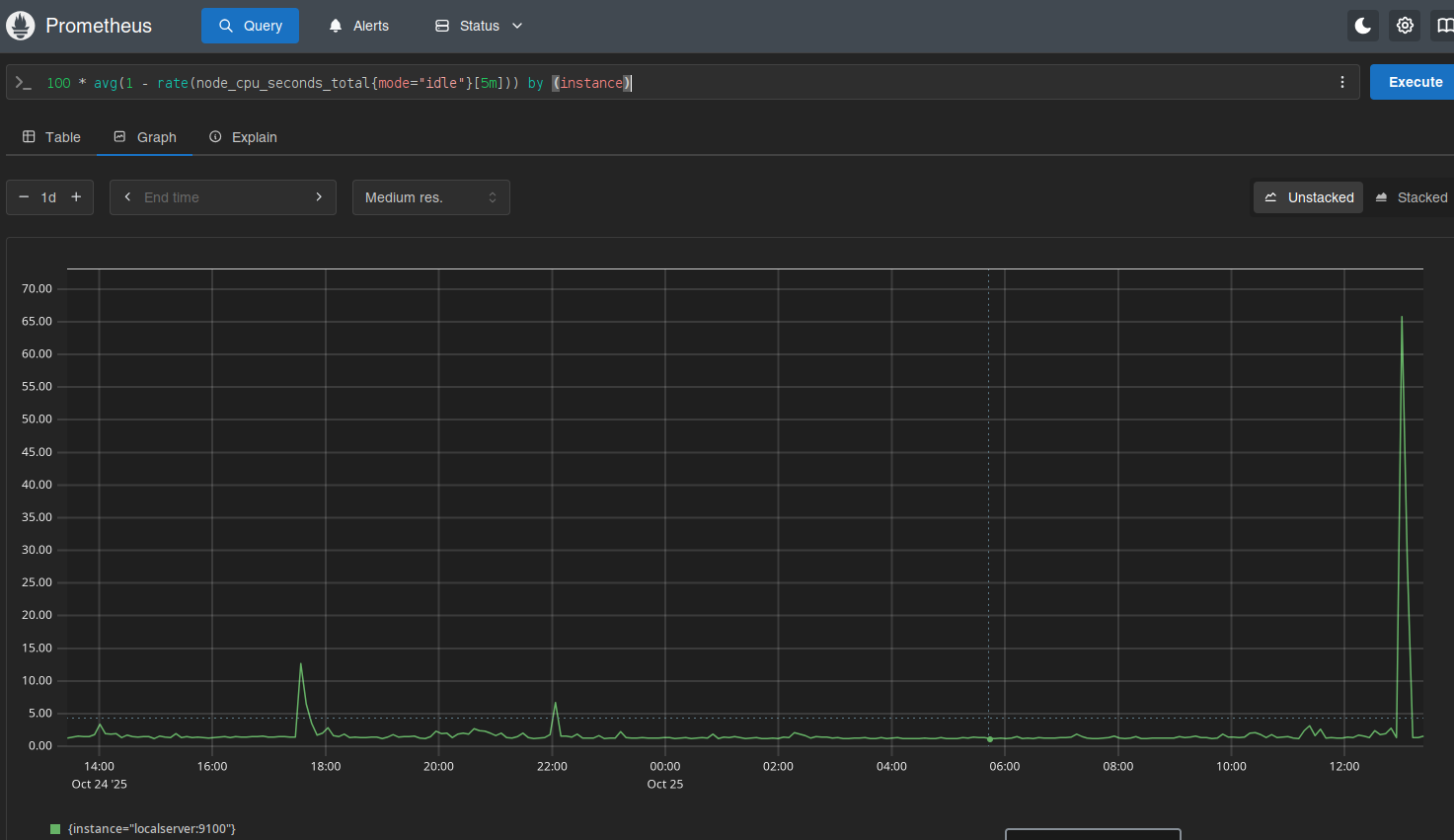
Daí é deixar o Prometheus coletar os dados e depois olhar os gráficos.

Ninguém me segurou, mas também não instalei o Grafana.
Por enquanto...
Um pequeno vídeo juntando todas a fotos que o Google Photos mostrou com a busca por "selfie".

E a bolha está de pé. Ou quase isso.
A primeira semana em operação foi erro 502 o tempo todo. Achei que o problema era como estava funcionando pelo systemd. Então criei um serviço novo só pra ela.
# /etc/systemd/user/podman-compose@.service
[Unit]
Description=GoToSocial as container service
StartLimitIntervalSec=0
[Service]
Type=simple
User=helio
Group=helio
#WorkingDirectory=/home/helio/gotosocial
ExecStart=/home/helio/gotosocial/entrypoint.sh start
ExecStop=/home/helio/gotosocial/entrypoint.sh stop
Restart=always
RestartSec=30
[Install]
WantedBy=default.target
Depois achei que era o enviroment.
Comentei a parte de WorkingDirectory, como pode ser visto acima.
Também troquei o podman-compose up por esse script entrypoint.sh.
#! /usr/bin/env bash
GOTOSOCIAL_DIR="/home/helio/gotosocial"
start_gotosocial() {
echo "Starting gotosocial"
cd $GOTOSOCIAL_DIR
/usr/bin/podman pull docker.io/superseriousbusiness/gotosocial:latest
/usr/bin/podman pull docker.io/library/postgres:latest
/usr/bin/podman-compose down
sleep 5
/usr/bin/podman-compose up
}
stop_gotosocial() {
echo "Stopping GoToSocial"
cd $GOTOSOCIAL_DIR
/usr/bin/podman-compose down
}
case $1 in
start) start_gotosocial ;;
stop) stop_gotosocial ;;
restart) $0 stop
sleep 30
$0 start
;;
*) echo "Unknown option: $1"
exit 1
esac
Os podman pull estavam antes no serviço do systemd.
Joguei tudo pra dentro do script.
E o resultado foi: 502.
Então comecei a considerar que tinha feito algo errado no compose.yml.
services:
gotosocial:
image: docker.io/superseriousbusiness/gotosocial:latest
container_name: gotosocial
user: 1000:1000
networks:
- gotosocial
environment:
# Change this to your actual host value.
GTS_HOST: bolha.linux-br.org
GTS_DB_TYPE: postgres
GTS_CONFIG_PATH: /gotosocial/config.yaml
# Path in the GtS Docker container where the
# Wazero compilation cache will be stored.
GTS_WAZERO_COMPILATION_CACHE: /gotosocial/.cache
## For reverse proxy setups:
GTS_TRUSTED_PROXIES: "127.0.0.1,::1,172.18.0.0/16"
## Set the timezone of your server:
TZ: Europe/Stockholm
ports:
- "127.0.0.1:8080:8080"
volumes:
- data:/gotosocial/storage
- cache:/gotosocial/.cache
- ~/gotosocial/config.yaml:/gotosocial/config.yaml
restart: unless-stopped
healthcheck:
test: wget --no-vebose --tries=1 --spider http://localhost:8080/readyz
interval: 10s
retries: 5
start_period: 30s
depends:
- postgres
postgres:
image: docker.io/library/postgres:latest
container_name: postgres
networks:
- gotosocial
environment:
POSTGRES_PASSWORD: *****
POSTGRES_USER: gotosocial
POSTGRES_DB: gotosocial
restart: unless-stopped
volumes:
- ~/gotosocial/postgresql:/var/lib/postgresql
ports:
- "5432:5432"
healthcheck:
test: pg_isready
interval: 10s
timeout: 5s
retries: 5
start_period: 120s
networks:
gotosocial:
ipam:
driver: default
config:
- subnet: "172.18.0.0/16"
gateway: "172.18.0.1"
volumes:
data:
cache:
Nada de muito fantástico. Um postgres rodando junto com um gotosocial. Algumas configurações de proxy, que é o nginx da máquina, e é isso. E continuava o 502.
Mas se eu entrava na máquina, e rodava uma sessão de tmux e dentro dela chamava o podman-compose up,
daí tudo funcionava.
Dei então uma olhada no erro.
Oct 15 10:16:56 mimir entrypoint.sh[1895291]: podman-compose version: 1.0.6
Oct 15 10:16:56 mimir entrypoint.sh[1895291]: ['podman', '--version', '']
Oct 15 10:16:56 mimir entrypoint.sh[1895291]: using podman version: 4.9.3
Oct 15 10:16:56 mimir entrypoint.sh[1895291]: ** excluding: set()
Oct 15 10:16:56 mimir entrypoint.sh[1895291]: ['podman', 'ps', '--filter', 'label=io.podman.compose.project=gotosocial', '-a', '--format', '{{ index .Labels "io.podman.compose.config-hash"}}']
Oct 15 10:16:56 mimir entrypoint.sh[1895303]: time="2025-10-15T10:16:56+02:00" level=warning msg="RunRoot is pointing to a path (/run/user/1000/containers) which is not writable. Most likely podman will fail."
Oct 15 10:16:56 mimir entrypoint.sh[1895303]: Error: default OCI runtime "crun" not found: invalid argument
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: Traceback (most recent call last):
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/bin/podman-compose", line 33, in
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: sys.exit(load_entry_point('podman-compose==1.0.6', 'console_scripts', 'podman-compose')())
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3/dist-packages/podman_compose.py", line 2941, in main
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: podman_compose.run()
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3/dist-packages/podman_compose.py", line 1423, in run
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: cmd(self, args)
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3/dist-packages/podman_compose.py", line 1754, in wrapped
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: return func(*args, **kw)
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: ^^^^^^^^^^^^^^^^^
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3/dist-packages/podman_compose.py", line 2038, in compose_up
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: compose.podman.output(
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3/dist-packages/podman_compose.py", line 1098, in output
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: return subprocess.check_output(cmd_ls)
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3.12/subprocess.py", line 466, in check_output
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: File "/usr/lib/python3.12/subprocess.py", line 571, in run
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: raise CalledProcessError(retcode, process.args,
Oct 15 10:16:57 mimir entrypoint.sh[1895291]: subprocess.CalledProcessError: Command '['podman', 'ps', '--filter', 'label=io.podman.compose.project=gotosocial', '-a', '--format', '{{ index .Labels "io.podman.compose.config-hash"}}']' returned non-zero exit status 125.
Oct 15 10:16:57 mimir systemd[1]: gotosocial.service: Main process exited, code=exited, status=1/FAILURE
Oct 15 10:16:57 mimir systemd[1]: gotosocial.service: Failed with result 'exit-code'.
Oct 15 10:16:57 mimir systemd[1]: gotosocial.service: Consumed 1.481s CPU time.
Oct 15 10:17:27 mimir systemd[1]: gotosocial.service: Scheduled restart job, restart counter is at 1280.
Oct 15 10:17:27 mimir systemd[1]: Started gotosocial.service - GoToSocial as container service.
Oct 15 10:17:27 mimir entrypoint.sh[1895707]: Starting gotosocial
Oct 15 10:17:30 mimir entrypoint.sh[1895781]: podman-compose version: 1.0.6
Oct 15 10:17:30 mimir entrypoint.sh[1895781]: ['podman', '--version', '']
Oct 15 10:17:30 mimir entrypoint.sh[1895781]: using podman version: 4.9.3
Oct 15 10:17:30 mimir entrypoint.sh[1895781]: ** excluding: set()
Oct 15 10:17:30 mimir entrypoint.sh[1895781]: podman stop -t 10 postgres
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: exit code: 0
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: podman stop -t 10 gotosocial
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: exit code: 0
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: podman rm postgres
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: exit code: 0
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: podman rm gotosocial
Oct 15 10:17:31 mimir entrypoint.sh[1895781]: exit code: 0
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: podman-compose version: 1.0.6
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ['podman', '--version', '']
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: using podman version: 4.9.3
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ** excluding: set()
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ['podman', 'ps', '--filter', 'label=io.podman.compose.project=gotosocial', '-a', '--format', '{{ index .Labels "io.podman.compose.config-hash"}}']
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: podman volume inspect gotosocial_data || podman volume create gotosocial_data
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ['podman', 'volume', 'inspect', 'gotosocial_data']
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: podman volume inspect gotosocial_cache || podman volume create gotosocial_cache
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ['podman', 'volume', 'inspect', 'gotosocial_cache']
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: ['podman', 'network', 'exists', 'gotosocial_gotosocial']
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: podman create --name=gotosocial --label io.podman.compose.config-hash=4f4b10e0c67c04b7b4f2392784b378735d4378d9d411f1405cf3819c6207bd1a --label io.podman.compose.project=gotosocial --label io.podman.compose.version=1.0.6 --label PODMAN_SYSTEMD_UNIT=This email address is being protected from spambots. You need JavaScript enabled to view it. --label com.docker.compose.project=gotosocial --label com.docker.compose.project.working_dir=/home/helio/gotosocial --label com.docker.compose.project.config_files=compose.yaml --label com.docker.compose.container-number=1 --label com.docker.compose.service=gotosocial -e GTS_HOST=bolha.linux-br.org -e GTS_DB_TYPE=postgres -e GTS_CONFIG_PATH=/gotosocial/config.yaml -e GTS_WAZERO_COMPILATION_CACHE=/gotosocial/.cache -e GTS_TRUSTED_PROXIES=127.0.0.1,::1,172.18.0.0/16 -e TZ=Europe/Stockholm -v gotosocial_data:/gotosocial/storage -v gotosocial_cache:/gotosocial/.cache -v /home/helio/gotosocial/config.yaml:/gotosocial/config.yaml --net gotosocial_gotosocial --network-alias gotosocial -p 127.0.0.1:8080:8080 -u 1000:1000 --restart unless-stopped --healthcheck-command /bin/sh -c 'wget --no-vebose --tries=1 --spider http://localhost:8080/readyz' --healthcheck-interval 10s --healthcheck-start-period 30s --healthcheck-retries 5 docker.io/superseriousbusiness/gotosocial:latest
Oct 15 10:17:36 mimir entrypoint.sh[1895920]: exit code: 0
A parte final, com podman create, é o systemd reiniciando o serviço.
O problema está on início, onde há um crash de python:
subprocess.CalledProcessError: Command '['podman', 'ps', '--filter', 'label=io.podman.compose.project=gotosocial', '-a', '--format', '{{ index .Labels "io.podman.compose.config-hash"}}']' returned non-zero exit status 125.
Eu entrava na máquina e rodava o comando pra ver o resultado:
❯ podman ps --filter 'label=io.podman.compose.project=gotosocial' -a --format '{{ index .Labels "io.podman.compose.config-hash"}}'
4f4b10e0c67c04b7b4f2392784b378735d4378d9d411f1405cf3819c6207bd1a
4f4b10e0c67c04b7b4f2392784b378735d4378d9d411f1405cf3819c6207bd1a
E mostrava os containers rodando (porque tinha sido reiniciados pelo systemd). Eu ficava com aquela cara de "ué!?".
No início do erro, tem essa outra mensagem aqui:
Error: default OCI runtime "crun" not found: invalid argument
.
Então fui olhar se era algum problema nesse crun.
E está instalado (acho que veio como dependência do podman.
❯ which crun
/usr/bin/crun
❯ dpkg -S /usr/bin/crun
crun: /usr/bin/crun
Busquei sobre erros do GoToSocial mesmo. E nada.
Olhando pra todo lado tentando descobrir o que poderia ser, reparei em outro erro:
msg="RunRoot is pointing to a path (/run/user/1000/containers) which is not writable. Most likely podman will fail."
.
Isso soou promissor.
Então de repente o pointing path não estava disponível pra escrita.
Poderia ser... systemd?
Com isso eu comecei a buscar algo relacionado com timeout ou user logout.
Acabei encontrando o artigo abaixo:
Nesse artigo alguém comenta que pode ser uma opção de container linger.
Segui a referência que tinha sobre isso.
loginctl?
Faz até sentido isso.
Mas o podman não deveria descrever isso na documentação?
Então fui buscar e achei isso aqui:
Pra deixar bem ilustrado onde aparece a referência de linger na documentação:

Algo que é vital pra funcionar como serviço aparece como... exemplo??? Os caras tão de brincation uite me.

Mas no fim era isso mesmo.
Bastou um sudo logictl enable-user helio pra ter o container rodando depois que eu saio da sessão.
Se eu tivesse decido rodar com docker compose, eu provavelmente não teria o mesmo problema uma vez que roda com o privilégio de root.
Então fica mais essa lição aqui.
E mesmo tendo lendo a documentação, sempre aparecem alguns pontos que a porra da documentação só dá um peteleco em cima e dentro dos exemplos ainda por cima.
Mas está funcionando. Minha bolha, bolha minha.

Faz algum tempo que venho pensando e criar meu próprio servidor no fediverso. O Augusto Campos postou sobre como fez a mesma coisa com uns NUC, aqueles computadores compactos. Eu fiquei empolgado com a ideia e resolvi ir pra frente.
Minha primeira ideia foi de rodar tudo num raspberry pi 5. Mas daí veio primeiro dilema: preço.

Por 1.500 coroas suecas é um pouco demais pra algo sem disco. É divertido, mas está longe do que eu queria.
Então resolvi olhar se tinha algo refurbished, pra pagar barato e ajudar a natureza (será que ajuda mesmo?). E achei algo bem interessantes na Amazon mesmo.

1.600 coroas suecas por 16 GB de RAM, 512 GB de SSD? E ainda uma CPU Xeon? E mesmo placa de vídeo???
Bora lá!
Comprei a máquina. E ela chegou ontem.

Primeira coisa que fiz, logo depois que tirei da caixa, foi abrir pra ver como estava dentro. Tem bastante espaço sobrando dentro pra aumentar a RAM.

E até mesmo espaço pra mais discos. Já estou pensando em comprar um HDD de 8 TB pra colocar também como storage pra backups.

E ainda veio uma plaquinha de vídeo marota. Coisa linda.

E como extra ainda vieram juntos teclado e mouse. Tem cara de gamer mas olhando mais de perto o teclado...


Esperava um switch mecânico blue, mas no lugar esse switch esquisito aí. Tem cara de coisa barata. Mas tem luzinha colorida. Já vale como brinde gratuito. E falando de brindes...

Veio também esse dongle bluetooth. Eu tenho um parecido no desktop que uso aqui, que roda archlinux btw.
Com o brinquedo em mão, já fui pra instalação. Fui de Ubuntu mesmo. E com zfs como filesystem.


A máquina está instalada e decidi usar o hostname como mimir.
Não muito criativo, mas um símbolo nórdico de conhecimento.
Tá valendo.
Eu ainda estou vendo como vou fazer tudo. A máquina está ligada e conectada na rede. Está aqui no meu quarto, ao lado da impressora. Talvez eu depois mude pra outro lugar mas como está silenciosa, então não é problema por enquanto.
Dos desafios pra subir a máquina estão as limitações de um ambiente home based: não tenho backup de nada, não tem no-break e só conectividade por IPv6. Além de que não posso ter serviço de email configurado uma vez que a porta de SMTP (25) fica bloqueada.
Também não decidi ainda o que vou rodar. Estou pensando em Pixelfed pra uma forma de postar fotos. Mas nada decidido ainda. Continuo testando.
Mas logo devo anunciar minha própria rede social. Aguardem.

Essa semana recebi uma missão: permitir acesso aos logs de um container numa VM em que a pessoa não pode conectar.
Pense em algumas opções e a que me pareceu mais apropriada foi criar um pequeno serviço com python, fastapi e uvicorn. E deixar disponível como acesso http.
Então fiz um programa bem simples:
#! /usr/bin/env python3
import uvicorn
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse, StreamingResponse
import subprocess
# https://stackoverflow.com/questions/4417546/constantly-print-subprocess-output-while-process-is-running
def shellExec(command: list[str]):
popen = subprocess.Popen(command, stdout=subprocess.PIPE, universal_newlines=True)
for stdout_line in iter(popen.stdout.readline, ""):
yield stdout_line
popen.stdout.close()
return_code = popen.wait()
if return_code:
raise subprocess.CalledProcessError(return_code, command)
def getContainerLogs():
for line in shellExec(["docker", "logs", "ubuntu", "-f"]):
yield line
app = FastAPI()
@app.get("/logs", response_class=PlainTextResponse)
async def getLogs():
return StreamingResponse(getContainerLogs(), media_type="text/plain")
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080)
O programa então roda o comando docker logs ubuntu -f pra ficar lendo os logs vindo do container "ubuntu".
Nada muito fantástico.
E como deixar rodando?
Eu podia criar um container que pudesse acessar /var/run/docker.socket pra ler info dos containers rodando.
E os logs.
Mas fui pela simplicidade e só criei um serviço do systemd mesmo.
[Unit]
Description=Stream logs from ubuntu container
Wants=network-online.target
After=network-online.target docker.service
[Service]
User=helio
Group=hackerz
Restart=always
WorkingDirectory=/home/helio/bin
ExecStart=/home/helio/bin/stream-logs-container.py
# If running the Agent in scraping service mode, you will want to override this value with
# something larger to allow the Agent to gracefully leave the cluster. 4800s is recommend.
TimeoutStopSec=5s
[Install]
WantedBy=multi-user.target
Daí bastou ativar e partir pro abraço.
❯ sudo systemctl enable --now stream-logs-container.service
Password:
❯ curl localhost:8080/logs
mariadb 12:38:12.20 INFO ==>
mariadb 12:38:12.21 INFO ==> Welcome to the Bitnami mariadb container
mariadb 12:38:12.21 INFO ==> Subscribe to project updates by watching https://github.com/bitnami/containers
mariadb 12:38:12.21 INFO ==> Did you know there are enterprise versions of the Bitnami catalog? For enhanced secure software supply chain features, unlimited pulls from Docker, LTS support, or application customization, see Bitnami Premium or Tanzu Application Catalog. See https://www.arrow.com/globalecs/na/vendors/bitnami/ for more information.
mariadb 12:38:12.22 INFO ==>
mariadb 12:38:12.22 INFO ==> ** Starting MariaDB setup **
mariadb 12:38:12.25 INFO ==> Validating settings in MYSQL_*/MARIADB_* env vars
mariadb 12:38:12.26 INFO ==> Initializing mariadb database
mariadb 12:38:12.28 INFO ==> Updating 'my.cnf' with custom configuration
mariadb 12:38:12.29 INFO ==> Setting slow_query_log option
mariadb 12:38:12.35 INFO ==> Setting long_query_time option
mariadb 12:38:12.37 INFO ==> Installing database
mariadb 12:38:13.91 INFO ==> Starting mariadb in background
2025-10-02 12:38:13 0 [Note] Starting MariaDB 10.11.11-MariaDB source revision e69f8cae1a15e15b9e4f5e0f8497e1f17bdc81a4 server_uid RV0GswTTbCaNJgiFfL+XFbloFPM= as process 98
2025-10-02 12:38:13 0 [Note] InnoDB: Compressed tables use zlib 1.2.13
2025-10-02 12:38:13 0 [Note] InnoDB: Number of transaction pools: 1
2025-10-02 12:38:13 0 [Note] InnoDB: Using crc32 + pclmulqdq instructions
2025-10-02 12:38:14 0 [Note] InnoDB: Using Linux native AIO
2025-10-02 12:38:14 0 [Note] InnoDB: Initializing buffer pool, total size = 128.000MiB, chunk size = 2.000MiB
2025-10-02 12:38:14 0 [Note] InnoDB: Completed initialization of buffer pool
2025-10-02 12:38:14 0 [Note] InnoDB: Buffered log writes (block size=512 bytes)
2025-10-02 12:38:14 0 [Note] InnoDB: End of log at LSN=45502
2025-10-02 12:38:14 0 [Note] InnoDB: 128 rollback segments are active.
2025-10-02 12:38:14 0 [Note] InnoDB: Setting file './ibtmp1' size to 12.000MiB. Physically writing the file full; Please wait ...
2025-10-02 12:38:14 0 [Note] InnoDB: File './ibtmp1' size is now 12.000MiB.
^C
Como ele fica lendo sem parar os logs, é preciso um "ctrl+c" pra sair.

Conformes as pedaladas foram ficando mais longas, eu comecei a ter um problema recorrente: câimbras.
Sempre depois de 60 Km e quando pedalando próximo de 20 Km/h (ou acima). E uma vez que a câimbra chega, não tem como fazer parar. Só resta pedalar bem mais devagar. E isso pode ser um problema numa pedalada planejada de 100 Km.
O que fiz? Não, não perguntei ao ChatGPT.
Mas busquei no Youtube.
E achei um vídeo falando do assunto.
Gosto bastante dos vídeos desse canal GCN. Dão várias dicas boas. E essa não foi exceção.
Eu passei a usar o que indicaram no vídeo: eletrólitos. Eu estou usando esse eletrólito aqui no momento:
Basicamente ele adiciona açúcar, pra dar energia, mantém hidratado porque é uma mistura com água, e tem um pouco de sal. E você pode até mesmo fazer em casa uma vez que a receita é a mesma que soro caseira.
E vou dizer que isso mudou muito a forma como pedalo hoje em dia. Antes eu tinha o receio de ter a câimbra no meio do caminho e ia mais leve. Agora eu estou me arrebentando de pedalar e sinto os músculos fadigados, mas nada de câimbra. E as pedaladas passaram de acima 60 Km pra mais de 100 Km.
Não sei se o eletrólito funciona da mesma forma pra todo mundo. Os motivos de câimbras podem ser diferentes pra cada pessoa. Mas acho que vale a tentativa de usar pra quem está sofrendo com isso.


Já faz algum tempo que venho trocando o hábito de comprar na Amazon pelo de comprar na Aliexpress. A vantagem é que geralmente é mais barato na Aliexpress. A desvantagem é que nem tudo dá pra trocar ou devolver. E demora mais pra chegar, se bem que os chineses estão fazendo um excelente trabalho nesse ponto. E tem o fator qualidade.
Então essas compras invariavelmente te levam a adquirir coisas que não duram muito ou estragam rapidamente.
Mas isso está mudando. E muito. Então vou listar aqui coisas que comprei ultimamente e estão sendo muito úteis e a qualidade é excelente. Vou botar os links mas... na Aliexpress os vendedores podem desaparecer do dia pra noite. Faz parte do "ethos" da Aliexpress. Vamos então às dicas.

Não é lá um produto que exigem muita coisa, mas é algo que ajuda bastante nos dias de chuva pra não deixar sua cabeça molhada. E custa pouco.

Essa bomba portátil ajudou a diminuir o peso e volume da bomba elétrica USB que eu carregava antes. Eu sempre levo uma outra bomba manual pro caso de ficar sem gás já que usou o cilindro uma vez, ele não segura o gás depois.

Eu tenho uma mochila maior que levo nas viagens mais longas. Mas uso essa pras pedaladas mais próximas. Como eu tenho bagageiro, prendo nele ao invés de prender no banco.

Conforme vamos pedalando, essa fita do guidão vai gastando. Troquei por essa da Aliexpress e não tenho reclamações. Fuciona bem e a opção de cores é maior.

Quando pedalamos no verão, depois de 2 ou 3 horas, a água das garrafas viram chá. Então eu comprei essa térmica pra experimentar. E funciona! Mantém o líquido gelado por mais de 12 horas. O problema foi tamanho: diâmetro maior que o que cabia no porta-garrafa da bike. Atualmente eu carrego ela como segunda garrafa na mochina traseira.

Eu não sei muito bem como descrever essas peças de roupa de ciclismo em português que em tradução literal ficariam como "aquecedores de pernas e braços", mas são extensões de roupas pra te manter quente. Talvez não muito necessário em climas quentes como do Brasil, mas essenciais aqui na Europa nórdica. E ocupam pouco espaço na mala.

Eu uso essa camiseta como primeira camada. Não tem outra funcionalidade além da de absorver suor e evitar aquela gotícula que escorre das costas e entra no seu rego e só vai parar quando chega no seu c*. Pra quem não usa bib pra pedalar, aquela roupa de ciclismo, ou usa essa roupa com roupas de baixo (calcinha ou cueca) - o que não deveriam fazer, não é algo tão necessário assim.

Essa é a fita que uso pra fazer o acabamento da outra fita, que descrevi acima, no guidão. Usei recentemente pra cobrir o cabo do power bank, que é laranja, e deixar quase todo preto.

Como a outra garrafa térmica que comprei primeiro tem o diâmetro muito grande, acabei comprando essa. Ela é hoje em dia minha garrafa principal e segura bem a temperatura. Talvez por até 10h ou mais. E com o diâmetro menor, encaixa sem problemas no porta-garrafas da bike.

A maioria dos porta-garrafas você tira por cima a garrafa. Como eu uso um porta trecos na parte de baixo do frame da bike, pra carregar o power bank, precisei comprar um que eu pudesse tirar e colocar a garrafa de lado. Esse permite garrafas com diâmetro maior mas eu achei que a garrafa térmica de 1l não fica firme nela e resolvi não arriscar.

Item obrigatório aqui, que chove bastante. A vantagem desses paralamas é que são presos por borrachas. Então é fácil colocar e tirar.

Deve ter nome melhor que "porta-trecos" mas essa mochila que é um porta-trecos tem o diferencial de poder parafusar no frame. E como minha bike, uma Trek, tem essa entrada pros parafusos, esse porta-treco funcionou maravilhosamente.

Eu fiz um review no Aliexpress sentando a lenha nesse power bank. Fui muito rápido no meu teste pra fazer tal review. O problema é que o cabo não entra muito bem e precisa encaixar certo. Feito isso corretamente, segura bem a carga. Alimenta a minha GoPro por 12h. Até mais. Tem a funcionalidade de lâmpada, mas eu não uso. E encaixa no conector de Garmin. A parte de cima, onde coloco o computador, não é muito firme e faz barulho. Mas não cai. Nem solta.

Não é bem relacionado com a bike, mas como uso um setup Garmin, digamos que até faz parte. Eu não gosto de usar a pulseira de borracha e prefiro essas de velcro.

Acho que nem preciso descrever muito aqui. Talvez só uma nota: meu amigo comprou uma semelhante pela Temu e a qualidade parece inferior.

Também acho que não preciso descrever muito aqui. Funciona bem pra absorver o suor.
Aqui capacete não é ítem obrigatório. Mas campainha é. E essa fica legal em drop bar de road e gravel bikes.

Se realmente protege contra raios UV, eu não sei. Mas tem funcionado. Tem uns vãos nas bordas que incomodam no início. Mas depois de algumas pedaladas você acostuma e não nota. Eu não costumo botar as alças laterais atrás da orelha porque vão machucando ao longo do caminho. Eu coloco ao lado e preciso que fique firme pra não cair (o capacete ajuda a segurar). E esses óculos funcionaram bem pra isso.

Esse espelho ajuda muito quando estamos na estrada. Posso ver se quem está atrás não está distante e ver se carros estão chegando. E quando fica fechado, não fica aparente que está ali no guidão.

Esse aqui não tem um uso muito prático. É só estético mesmo. Eu tenho a tampa das válvulas de alumínio azul também. Então combina e fica charmoso.

Quando ligo o power bank ou no telefone ou na GoPro, esse é o cabo que uso. Ele estica bastante e não fica solto.

Comprei só pra combinar com a cor da bike. Funcionam bem.

Eu passei a usar esse mount de Garmin pra segurar o telefone. Fica firme. E posso encaixar o computador também. E os power banks que tenho. Podia ter em azul pra combinar com a bike.

Mais fácil pra prender o tênis.

Eu preciso trocar os pedais a cada 6 meses. Talvez até em menos tempo. Esses são baratos e leves.

São engraçadas. Mas não absorvem bem o suor. Mas são engraçadas.

Essas luvas com alcochoamento mais grosso (6mm) ajudam bastante nas pedaladas mais longas.

Como eu tenho mount de Garmin na bike, uso esse case pra segurar o telefone. Fica firme e absorve bem a trepidação.
Um dos produtos desapareceu. Então vou deixar ele aqui pra caso apareça de novo. É um power bank com lâmpada. Tenho usado mais como lâmpada frontal.

A descrição era: ThinkRider Bicycle Light For Garmin Gopro Bike Headlight Type-C Usb Charging Bike Flashlight Bicycle Lamp Black, 100-300 Lumen.
Agora não tem mais desculpa pra nãp pedalar. Bugigangas legais é que não vão faltar.

Agora dando uma olhada na Aliexpress, eu achei o powerbank com lâmpada que mencionei. Mudou de loja/fabricante mas parece o mesmo produto.

Por motivos que não cabem aqui, temos alguns servidores instalados em uma sala na empresa. E essa sala tem um ar-condicionado pra manter a temperatura sob controle.
Um belo dia estou olhando os dados no Grafana e noto que essas máquinas não reportaram dados (não temos alertas enviados pelo Grafana, mas o porquê disso fica pra um outro dia). Entro na sala e a temperatura estava simplemente... 32°C. Era verão na Suécia, que é curto mas tem seus dias bem quentes. E o hardware das máquinas desligaram pra proteção.
Entre entrar em contato com técnico do ar-condicionado e deixar a sala aberta pra ventilar, ficamos com aquele gosto amargo de não ter nenhum dado sobre a temperatura.
A solução? raspberrypi!
Ele tem um sensor que é vendido na Internet.
O sensor já chegou mas não o raspberrypi. O motivo deve ser porque compramos um modelo que funciona como KVM e tem algumas coisas a mais.
Então aqui a descrição de como botar o serviço pra funcionar em Linux.
Existe um software descrito na página do produto que aponta pro seguinte repositório no GitHub:
Mas o repositório parece abandonado. Já faz 7 anos que ninguém manda nenhum commit. E o código não funciona com a versão mais moderna do sensor.
O que fazer? Patch!
Então corrigi o programa e criei um fork do repo original.
Então temos o software pronto pra funcionar. Ou quase.
Antes é preciso corrigir as permissões de leitura e escrita do dispositivo.
E pra isso eu criei uma pequena regra no udev em
/etc/udev/rules.d/90-temperature-sensor.rules
KERNEL=="hidraw[0-9]*", SUBSYSTEM=="hidraw", SUBSYSTEMS=="usb", ATTRS{idVendor}=="3553", ATTRS{idProduct}=="a001", MODE="0666", SYMLINK+="temper"
Pegando a saída do kernel:
# dmesg | grep -i temper
[ 5.152423] usb 1-10.4: Product: TEMPer2
[ 6.769788] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.0/0003:3553:A001.0005/input/input14
[ 6.826541] hid-generic 0003:3553:A001.0005: input,hidraw4: USB HID v1.11 Keyboard [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input0
[ 6.826720] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.1/0003:3553:A001.0006/input/input15
[ 6.827067] hid-generic 0003:3553:A001.0006: input,hidraw5: USB HID v1.10 Device [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input1
[ 939.507362] usb 1-10.4: Product: TEMPer2
[ 939.521617] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.0/0003:3553:A001.000B/input/input26
[ 939.580825] hid-generic 0003:3553:A001.000B: input,hidraw4: USB HID v1.11 Keyboard [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input0
[ 939.581808] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.1/0003:3553:A001.000C/input/input27
[ 939.582035] hid-generic 0003:3553:A001.000C: input,hidraw5: USB HID v1.10 Device [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input1
É possível ver que o dispositivo aparece como dois devices:
/dev/hidraw4
e
/dev/hidraw5.
Eu tentei usar a permissão 0644 primeiro, mas essa não funcionou pra ler os dados. Então tive de mudar pra 0666 mesmo sendo algo que só lê informação.
Feita essa etapa, ainda não estamos prontos pra rodar o programa temper.py.
Ainda é preciso instalar a dependência: serial.
Se seu sistema é baseado em debian/ubuntu:
> sudo apt install -y python3-serial
Se não for, talvez seja mais fácil fazer com virtualenv.
E pra isso eu atualmente uso o uv
> uv venv venv
> source venv/bin/activate
(venv)> uv pip install serial
Tendo tudo pronto, chegamos ao momento da verdade:
(venv)> ./temper.py
Bus 001 Dev 011 3553:a001 TEMPer2_V4.1 25.6C 78.0F - 22.8C 73.1F -
Pegando a saída como JSON permite ver melhor o que é cada um desses resultados.
(venv)> ./temper.py --json
[
{
"vendorid": 13651,
"productid": 40961,
"manufacturer": "PCsensor",
"product": "TEMPer2",
"busnum": 1,
"devnum": 11,
"devices": [
"hidraw4",
"hidraw5"
],
"firmware": "TEMPer2_V4.1",
"hex_firmware": "54454d506572325f56342e3100000000",
"hex_data": "808009f64e200000800108e94e200000",
"internal temperature": 25.5,
"external temperature": 22.81
}
]
Então a primeira temperatura lida, de /dev/hidraw4, é 25.5°C interna do dispositivo.
A segunda, /dev/hidraw5, é de 22.81°C e externa, do cabo.

Temos as leituras e os dados. Como mandar isso pro Grafana?
Eu primeiramente tentei fazer em shell script e mandar o dados pro mimir, que é onde eu agrego as métricas.
Fracassei miseravelmente.
Não existe uma forma muito fácil de enviar um dados pro lá. O formato que o alloy usa é protobuf, que é um dado comprimido em snappy, etc.
Qual outra alternativa?
Expor o dado como open metric pro alloy pegar e enviar.
Pode parecer simples mas... precisamos de um servidor web pra isso.
Algo que temos fácil em python.
Então usando uvicorn e fastapi podemos ter tudo funcionando.
E é possível importar o temper.py como módulo.
E é preciso incrementar nosso virtualenv (ou pacotes) com esses pacotes:
> sudo apt install -y python3-uvicorn python3-fastapi
ou
(venv)> uv pip install uvicorn
(venv)> uv pip install fastapi
Sem mais delongas, eis aqui o código do monitor.py:
#! /usr/bin/env python3
import subprocess
import argparse
import logging
import threading
import time
try:
import temper
except ImportError as e:
print(f"Error importing temper module: {e}")
print("Make sure python3-serial is installed: sudo apt-get install python3-serial")
exit(1)
import uvicorn
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse
CELSIUS = "\u2103"
DEFAULT_PORT = 8000
TEMPERATURE_MAX = 25.0
logger = logging.getLogger(__file__)
consoleOutputHandler = logging.StreamHandler()
formatter = logging.Formatter(
fmt="[%(asctime)s] (%(levelname)s) %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
consoleOutputHandler.setFormatter(formatter)
logger.addHandler(consoleOutputHandler)
logger.setLevel(logging.INFO)
def shellExec(command: str) -> str:
'run a command and return its output'
try:
return subprocess.getoutput(command)
except Exception as e:
logger.error(f"Error executing shell command '{command}': {e}")
return f"Error: {e}"
app = FastAPI()
# Global temperature monitor instance (will be set in main)
temperature_monitor = None
@app.get("/metrics", response_class=PlainTextResponse)
async def metrics():
if temperature_monitor is None or temperature_monitor.temperature_current is None:
return ""
temperature_current = temperature_monitor.temperature_current
logger.info(f"/metrics: {temperature_current}{CELSIUS}")
data_lines = list()
data_lines.append("#HELP server_room_temperature_celsius the room with servers current temperature")
data_lines.append("#TYPE server_room_temperature_celsius gauge")
data_lines.append(f"server_room_temperature_celsius {temperature_current}")
data_lines.append("")
return "\n".join(data_lines)
class TemperatureMonitor:
'A class that handle the temperature monitoring'
port: int = DEFAULT_PORT
temperature_max: float = TEMPERATURE_MAX
temperature_current: float|None = None
alert_lock: bool = False
def __init__(self, port=None, temperature_max=None) -> None:
if port:
self.port = port
if temperature_max:
self.temperature_max = temperature_max
def monitor(self) -> None:
th = threading.Thread(target=self.webserver)
th.daemon = True # Make it a daemon thread
th.start()
try:
while True:
self.update()
time.sleep(15)
except KeyboardInterrupt:
logger.info("Monitoring stopped by user")
except Exception as e:
logger.error(f"Error in monitoring loop: {e}")
raise
def webserver(self) -> None:
uvicorn.run(app, host="127.0.0.1", port=self.port)
def update(self) -> None:
'Read the output from the command'
try:
tp = temper.Temper().read()
if not tp or len(tp) == 0:
logger.warning("No temperature devices found")
self.temperature_current = None
return
self.temperature_current = tp[0].get('external temperature')
if self.temperature_current is not None:
logger.info(f"🌡️ current temperature: {self.temperature_current}{CELSIUS}")
else:
logger.warning("External temperature reading is None")
except Exception as e:
logger.error(f"Error reading temperature sensor: {e}")
self.temperature_current = None
if __name__ == '__main__':
parse = argparse.ArgumentParser(description="script to monitor temperature")
parse.add_argument("--loglevel", default="info", help="the logging level (default=info)")
parse.add_argument("--tempmax", type=float, default=TEMPERATURE_MAX, help="maximum temperature before raising alert")
parse.add_argument("--port", type=int, default=DEFAULT_PORT, help="port to listen the service")
args = parse.parse_args()
# Validate log level
valid_log_levels = ['DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL']
if args.loglevel.upper() not in valid_log_levels:
print(f"Invalid log level: {args.loglevel}. Valid options: {', '.join(valid_log_levels)}")
exit(1)
if args.loglevel.upper() != "INFO":
logger.setLevel(args.loglevel.upper())
# Validate temperature threshold
if args.tempmax <= 0:
print("Temperature threshold must be greater than 0")
exit(1)
# Validate port number
if not (1 <= args.port <= 65535):
print("Port must be between 1 and 65535")
exit(1)
# Create temperature monitor instance
temperature_monitor = TemperatureMonitor(args.port, args.tempmax)
temperature_monitor.monitor()
Eu tenho integrado uma parte de alerta que usa outro sistema, mas removi pra deixar o código fazendo somente o que é preciso.
No alloy, adicionei as seguintes linhas:
discovery.relabel "temperature_sensor" {
targets = array.concat(
[{
__address__ = "localhost:8000",
}],
)
rule {
source_labels = ["__address__"]
target_label = "instance"
replacement = "temper"
}
}
prometheus.scrape "temperature_sensor" {
targets = discovery.relabel.temperature_sensor.output
forward_to = [prometheus.remote_write.prod.receiver]
job_name = "agent"
}
Tudo pronto.
Ou quase.
Falta rodar o monitor.py que mostrei acima como serviço.
E pra isso usamos o systemd.
Basta criar o arquivo /etc/systemd/system/temperature-monitor.service
e iniciar.
[Unit]
Description=Temperature monitoring service
After=network.target
[Service]
User=helio
Group=helio
WorkingDirectory=/home/helio/temperature-sensor
ExecStart=/home/helio/temperature-sensor/monitor.sh
Restart=always
[Install]
WantedBy=multi-user.target
O script monitor.sh é pra somente ler o virtualenv corretamente:
#! /usr/bin/env bash
die() {
echo "ERROR: $@" >&2
echo "[$(date)] exiting with error"
exit 1
}
program="$0"
root_dir=$(readlink -f $program)
root_dir=$(dirname $root_dir)
cd $root_dir
source venv/bin/activate || \
die "failed to read virtualenv"
exec ./monitor.py
E iniciando o serviço:
> sudo systemctl daemon-reload
> sudo systemctl enable --now temperature-monitor
O que resta é criar um gráfico pra métrica server_room_temperature_celsius
e partir pro abraço.
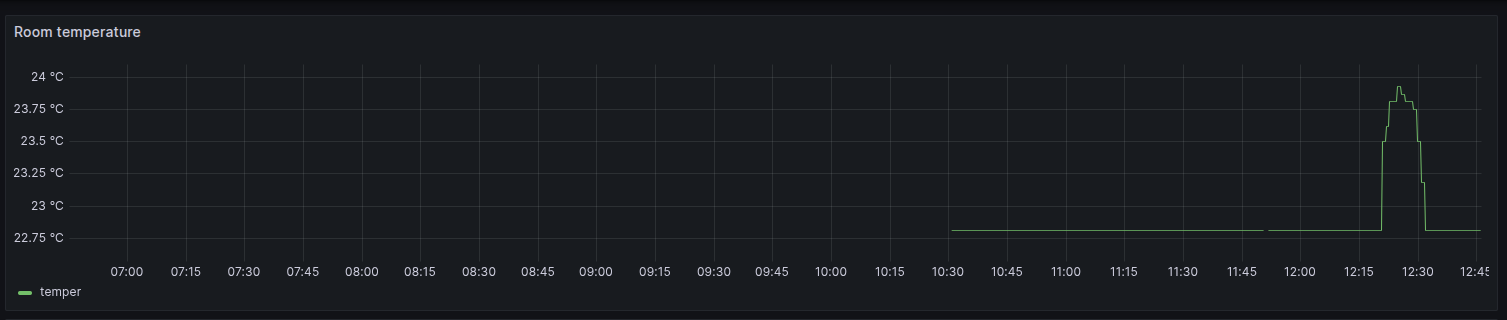
Update: [Fri Sep 12 05:30:00 PM CEST 2025] acabo de perceber que o repositório que fiz fork é na verdade um fork de outro, que parece ser bem mais completo.
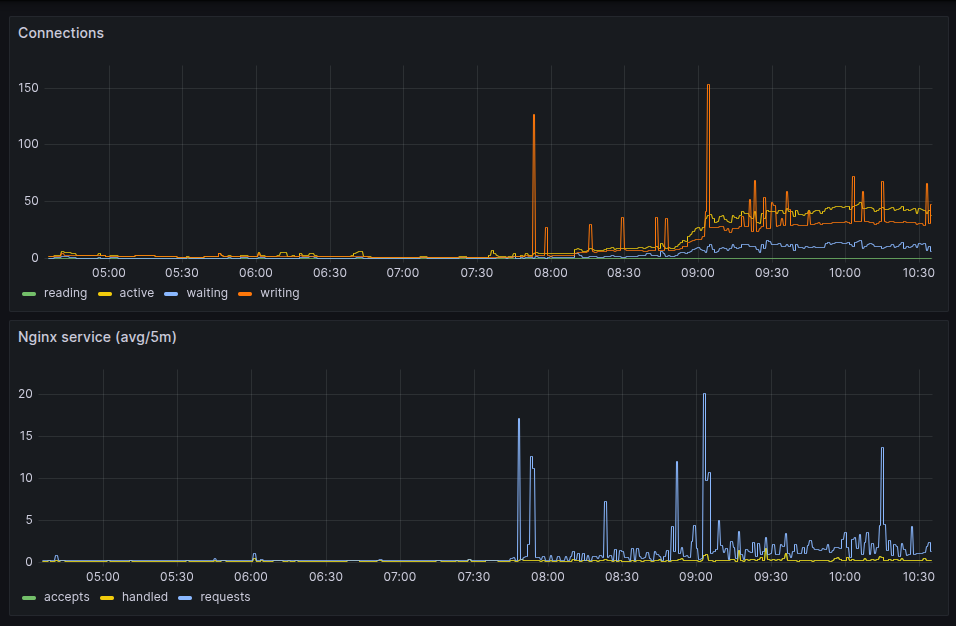
Seguindo o artigo expondo as métricas do nginx pro prometheus, aqui está o resultado olhado no grafana.
Como os valores
server_accepts_total,
server_handled_total e
server_requests_total
são do tipo counter,
eu usei um irate(__variável__[5m])
pra mostrar no gráfico da forma acima.
E como coletei esses dados? Eu já tinha comentado no artigo configurando o grafana alloy pra monitorar VMs que uso o alloy. Então foi adicionando uma entrada extra nele.
[...]
discovery.relabel "metrics_agent" {
targets = array.concat(
[{
__address__ = "localhost:9090",
}],
)
rule {
source_labels = ["__address__"]
target_label = "instance"
}
}
[...]
prometheus.scrape "nginx_metrics" {
targets = discovery.relabel.metrics_agent.output
forward_to = [prometheus.remote_write.prod.receiver]
}
Agora fica mais fácil entender o que acontece com as páginas servidas e se tem realmente alguma lentidão.

Esses dias eu peguei um problema no servidor web, nginx. Não nele especificamente. Mas um usuário estava reclamando que estava super lento pra carregar as páginas.
A questão então é como ver como e quanto está o nginx. Infelizmente a versão open source não fornece muita coisa. Só uma versão texto de estatísticas.
Não é grande coisa mas pelo menos já é ALGUMA COISA.
Agora como monitorar isso no Grafana?
A resposta são open metrics. E isso não tem.
Não tinha.
Fiz um programa em Go que converte essas estatísticas em open metrics e expõe na porta 9090 no endpoint /metrics.
Pra ter isso funcionando, é preciso primeiro subir a configuração de estatísticas no nginx.
server {
listen 127.0.0.1:8080;
location /api {
stub_status;
allow 127.0.0.1;
deny all;
}
}
Eu salvei no arquivo statistics.conf e coloquei em /etc/nginx/conf.d.
E bastou um reload pra ter funcionado.
❯ curl localhost:8080/api
Active connections: 2
server accepts handled requests
21 21 322
Reading: 0 Writing: 1 Waiting: 1
Agora é rodar o programa e apontar pra esse endpoint.
❯ ./nginx-openmetrics/nginx-openmetrics --service=http://localhost:8080/api
[2025-08-22T14:11:45] (INFO): 🚚 fetching data from:http://localhost:8080/api
[2025-08-22T14:11:45] (INFO): 🎬 starting service at port:9090
E a porta fica exposta pras métricas serem coletadas pelo prometheus ou grafana alloy. Ou qualquer outro programa que faça scrape de dados no padrão open metrics.
❯ curl localhost:9090/metrics
# HELP active_connections The number of active connections
# TYPE active_connections gauge
active_connections 1
# HELP reading_connections The number of active reading connections
# TYPE reading_connections gauge
reading_connections 0
# HELP server_accepts_total The total number of server accepted connections
# TYPE server_accepts_total counter
server_accepts_total 22
# HELP server_handled_total The total number of server handled connections
# TYPE server_handled_total counter
server_handled_total 22
# HELP server_requests_total The total number of server requests
# TYPE server_requests_total counter
server_requests_total 333
# HELP waiting_connections The number of waiting connections
# TYPE waiting_connections gauge
waiting_connections 0
# HELP writing_connections The number of active writing connections
# TYPE writing_connections gauge
writing_connections 1
E fica exposto em todas as interfaces.
❯ netstat -nat | grep 9090 | grep -i listen
tcp6 0 0 :::9090 :::* LISTEN
O programa faz o update dos dados a cada 15 segundos. Pra não sobrecarregar.
E ainda falta dar uma melhorada com a entrada como serviço do systemd. Devo fazer isso hoje.
Próximo passo será gerar um pacote debian dele pra instalar fácil.
Update: Fri Aug 22 04:23:45 PM CEST 2025
Tá lá o arquivo pro systemd.
E está funcionando no sistema que estou testando.
root@server:/# systemctl status nginx-openmetrics.service
● nginx-openmetrics.service - nginx open metrics service
Loaded: loaded (/etc/systemd/system/nginx-openmetrics.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2025-08-22 14:08:17 UTC; 16min ago
Main PID: 314061 (nginx-openmetri)
Tasks: 7 (limit: 19076)
Memory: 4.0M
CPU: 47ms
CGroup: /system.slice/nginx-openmetrics.service
└─314061 /usr/sbin/nginx-openmetrics --service=http://localhost:8080/api
Aug 22 14:08:17 internal systemd[1]: Started nginx open metrics service.
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78433] (INFO): nginx-open-metrics-service (1.0-9)
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78441] (INFO): 🚚 fetching data from:http://localhost:8080/api
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78442] (INFO): 🎬 starting service at port:9090
Confesso que pra escrever o script pra lers os logs do servidor web, aquele que mostrei em acessos de robôs nos logs web, foi algo próximo do vudu. Tudo porque o formato gerado não é lá muito amigável.
Idem pras máquinas do trabalho. Então hoje eu resolvi dar uma olhada se tinha como escrever esses mesmos logs em json.
E tem.
O primeiro que olhei foi no nginx. E é bem fácil de fazer.
log_format logger-json escape=json '{"source": "nginx", "time": "$time_iso8601", "resp_body_size": $body_bytes_sent, "host": "$http_host", "address": "$remote_addr", "request_length": $request_length, "method": "$request_method", "uri": "$request_uri", "status": $status, "user_agent": "$http_user_agent", "resp_time": $request_time, "upstream_addr": "$upstream_addr"}';
[...]
server {
listen 443 ssl;
server_name api.company.com;
...
access_log /var/log/nginx/access.log logger-json;
...
}
Eu segui a receita desses dois links aqui:
https://www.velebit.ai/blog/nginx-json-logging/
https://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
Pro Apache não tem um módulo que já gera tudo meio mastigado como no nginx. Mas você pode criar o formato do log como quiser.
LogFormat "{ \"time\":\"%{%Y-%m-%d}tT%{%T}t.%{msec_frac}tZ\", \"process\":\"%D\", \"filename\":\"%f\", \"remoteIP\":\"%a\", \"host\":\"%V\", \"request\":\"%U\", \"query\":\"%q\", \"method\":\"%m\", \"status\":\"%>s\", \"userAgent\":\"%{User-agent}i\", \"referer\":\"%{Referer}i\" }" combined
ErrorLogFormat "{ \"time\":\"%{%Y-%m-%d}tT%{%T}t.%{msec_frac}tZ\", \"function\" : \"[%-m:%l]\" , \"process\" : \"[pid %P:tid %T]\" , \"message\" : \"%M\" ,\ \"referer\"\ : \"%{Referer}i\" }"
E esse veio de dica do stack-overflow:
Eu não segui os mesmos parâmetros entre apache e nginx. Por enquanto estou só testando e estar com os campos bem definidos já é o suficiente pra mim.
> tail -1 /var/log/apache2/linux-br-access.log | jq .
{
"time": "2025-08-20T09:38:59.369Z",
"process": "241797",
"filename": "/var/www/linux-br.org/index.php",
"remoteIP": "54.36.149.72",
"host": "linux-br.org",
"request": "/date/2024/03/page/3/",
"query": "",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
Agora ficou fácil de filtrar e pegar só os campos que interessam. E usando "jq".
> tail -1 /var/log/apache2/linux-br-access.log | jq ".userAgent"
"Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)"
> tail -3 /var/log/apache2/linux-br-access.log | jq ".userAgent"
"Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)"
"Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)"
"Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)"

Eu tenho um laptop pessoal que é um Thinkpad T480. Escrevi sobre o mesmo aqui: entrei pra moda do laptop refurbished. Como não estou usando ele pra muita coisa e tenho também um Thinkpad pro trabalho, deixo o meu pra rodar o último Ubuntu.
E estava com o oneiric, 24.10, quando tentei fazer upgrade pro plucky, 25.04. E tive um belo dum crash no zfs.
------------[ cut here ]------------
WARNING: CPU: 0 PID: 227 at drivers/usb/typec/ucsi/ucsi.c:1390 ucsi_reset_ppm+0x1ad/0x1c0 [typec_ucsi]
Modules linked in: zfs(PO) spl(O) dm_crypt hid_multitouch hid_generic cdc_ncm cdc_ether usbnet uas mii usbhid hid usb_storage crct10dif_pclmul crc32_pclmul polyval_clmulni polyval_generic nvme ghash_clmulni_intel snd sha256_ssse3 soundcore sha1_ssse3 nvme_core e1000e video thunderbolt ucsi_acpi psmouse nvme_auth xhci_pci typec_ucsi typec xhci_pci_renesas sparse_keymap platform_profile wmi aesni_intel crypto_simd cryptd
CPU: 0 UID: 0 PID: 227 Comm: kworker/0:2 Tainted: P O 6.11.0-25-generic #25-Ubuntu
Tainted: [P]=PROPRIETARY_MODULE, [O]=OOT_MODULE
Hardware name: LENOVO 20L6S4G700/20L6S4G700, BIOS N24ET76W (1.51 ) 02/27/2024
Workqueue: events_long ucsi_init_work [typec_ucsi]
RIP: 0010:ucsi_reset_ppm+0x1ad/0x1c0 [typec_ucsi]
Code: ff 8b 55 bc 81 e2 00 00 00 08 0f 85 33 ff ff ff 4c 89 75 c8 48 8b 05 72 9d 4a cb 49 39 c5 79 94 b8 92 ff ff ff e9 19 ff ff ff <0f> 0b e9 57 ff ff ff e8 17 1b 17 ca 0f 1f 80 00 00 00 00 90 90 90
RSP: 0018:ffffba53c03a3d80 EFLAGS: 00010206
RAX: 0000000008000000 RBX: ffff9d0102192800 RCX: 0000000000000000
RDX: 00000000fffb83c0 RSI: 0000000000000000 RDI: 0000000000000000
RBP: ffffba53c03a3dd0 R08: 0000000000000000 R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000000 R12: ffffba53c03a3d8c
R13: 00000000fffb83be R14: ffff9d0101a4fc00 R15: ffff9d01021928c0
FS: 0000000000000000(0000) GS:ffff9d0666200000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
CR2: 00005799b59ce675 CR3: 00000003afe3e004 CR4: 00000000003706f0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
Call Trace:
<TASK>
? show_trace_log_lvl+0x1be/0x310
? show_trace_log_lvl+0x1be/0x310
? ucsi_init+0x32/0x310 [typec_ucsi]
? show_regs.part.0+0x22/0x30
? show_regs.cold+0x8/0x10
? ucsi_reset_ppm+0x1ad/0x1c0 [typec_ucsi]
? __warn.cold+0xa7/0x101
? ucsi_reset_ppm+0x1ad/0x1c0 [typec_ucsi]
? report_bug+0x114/0x160
? handle_bug+0x6e/0xb0
? exc_invalid_op+0x18/0x80
? asm_exc_invalid_op+0x1b/0x20
? ucsi_reset_ppm+0x1ad/0x1c0 [typec_ucsi]
ucsi_init+0x32/0x310 [typec_ucsi]
ucsi_init_work+0x18/0x90 [typec_ucsi]
process_one_work+0x174/0x350
worker_thread+0x31a/0x450
? _raw_spin_lock_irqsave+0xe/0x20
? __pfx_worker_thread+0x10/0x10
kthread+0xe1/0x110
? __pfx_kthread+0x10/0x10
ret_from_fork+0x44/0x70
? __pfx_kthread+0x10/0x10
ret_from_fork_asm+0x1a/0x30
</TASK>
---[ endtrace 0000000000000000 ]---
WARNING: CPU: 0 PID: 978 at /build/linux-Ajk80v/linux-6.11.0/debian/build/build-generic/____________________________________________________________________________dkms/build/zfs/2.2.6/build/module/zfs/zfs_log.c:817 zfs_log_setsaxattr+0x140/0x150 [zfs]
Modules linked in: msr(+) parport_pc ppdev lp parport efi_pstore nfnetlink dmi_sysfs ip_tables x_tables autofs4 typec_displayport zfs(PO) spl(O) dm_crypt hid_multitouch hid_generic cdc_ncm cdc_ether usbnet uas mii usbhid hid usb_storage crct10dif_pclmul crc32_pclmul polyval_clmulni polyval_generic nvme ghash_clmulni_intel snd sha256_ssse3 soundcore sha1_ssse3 nvme_core e1000e video thunderbolt ucsi_acpi psmouse nvme_auth xhci_pci typec_ucsi typec xhci_pci_renesas sparse_keymap platform_profile wmi aesni_intel crypto_simd cryptd
CPU: 0 UID: 0 PID: 978 Comm: systemd-random- Tainted: P W O 6.11.0-25-generic #25-Ubuntu
Tainted: [P]=PROPRIETARY_MODULE, [W]=WARN, [O]=OOT_MODULE
Hardware name: LENOVO 20L6S4G700/20L6S4G700, BIOS N24ET76W (1.51 ) 02/27/2024
RIP: 0010:zfs_log_setsaxattr+0x140/0x150 [zfs]
Code: ff ff ff 31 c9 48 c7 c2 c0 94 e5 c0 4c 89 f6 4c 89 55 c0 48 c7 c7 68 8e e5 c0 4c 89 4d d0 c6 05 4a 50 13 00 01 e8 a0 c3 a9 c8 <0f> 0b 4c 8b 55 c0 4c 8b 4d d0 e9 30 ff ff ff 90 90 90 90 90 90 90
RSP: 0018:ffffba53c192f748 EFLAGS: 00010246
RAX: 0000000000000000 RBX: ffff9d0107f7bdb0 RCX: 0000000000000000
RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
RBP: ffffba53c192f790 R08: 0000000000000000 R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000000 R12: ffff9d011613e800
R13: ffff9d010b3499c0 R14: 000000000000001c R15: 0000000000000000
FS: 00007a57caef8980(0000) GS:ffff9d0666200000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
CR2: 00007a57cbf071e0 CR3: 000000010a016003 CR4: 00000000003706f0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
Call Trace:
<TASK>
? show_trace_log_lvl+0x1be/0x310
? show_trace_log_lvl+0x1be/0x310
? zfs_sa_set_xattr+0x34a/0x3b0 [zfs]
? show_regs.part.0+0x22/0x30
? show_regs.cold+0x8/0x10
? zfs_log_setsaxattr+0x140/0x150 [zfs]
? __warn.cold+0xa7/0x101
? zfs_log_setsaxattr+0x140/0x150 [zfs]
? report_bug+0x114/0x160
? handle_bug+0x6e/0xb0
? exc_invalid_op+0x18/0x80
? asm_exc_invalid_op+0x1b/0x20
? zfs_log_setsaxattr+0x140/0x150 [zfs]
? zfs_log_setsaxattr+0x140/0x150 [zfs]
zfs_sa_set_xattr+0x34a/0x3b0 [zfs]
zpl_xattr_set_sa+0x102/0x200 [zfs]
zpl_xattr_set+0x21c/0x290 [zfs]
__zpl_xattr_user_set+0x128/0x170 [zfs]
zpl_xattr_user_set+0x22/0x40 [zfs]
__vfs_removexattr+0x81/0xd0
__vfs_removexattr_locked+0xe5/0x1a0
? touch_atime+0xbe/0x120
vfs_removexattr+0x59/0x110
__do_sys_fremovexattr+0x130/0x1c0
__x64_sys_fremovexattr+0x15/0x20
x64_sys_call+0x1fc7/0x22b0
do_syscall_64+0x7e/0x170
? filemap_map_pages+0x34f/0x570
? xa_load+0x73/0xb0
? do_read_fault+0xfd/0x200
? do_fault+0x183/0x210
? generic_file_llseek+0x24/0x40
? zpl_llseek+0x32/0xd0 [zfs]
? ksys_lseek+0x7d/0xd0
? syscall_exit_to_user_mode+0x4e/0x250
? do_syscall_64+0x8a/0x170
? __count_memcg_events+0x86/0x160
? count_memcg_events.constprop.0+0x2a/0x50
? handle_mm_fault+0x1bb/0x2d0
? do_user_addr_fault+0x5e9/0x7e0
? irqentry_exit_to_user_mode+0x43/0x250
? irqentry_exit+0x43/0x50
? exc_page_fault+0x96/0x1c0
entry_SYSCALL_64_after_hwframe+0x76/0x7e
RIP: 0033:0x7a57cba5d4eb
Code: 73 01 c3 48 8b 0d 0d 79 0e 00 f7 d8 64 89 01 48 83 c8 ff c3 66 2e 0f 1f 84 00 00 00 00 00 90 f3 0f 1e fa b8 c7 00 00 00 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d dd 78 0e 00 f7 d8 64 89 01 48
RSP: 002b:00007ffe118d0498 EFLAGS: 00000246 ORIG_RAX: 00000000000000c7
RAX: ffffffffffffffda RBX: 0000000000000004 RCX: 00007a57cba5d4eb
RDX: 000000000000001a RSI: 00006015c386c08b RDI: 0000000000000005
RBP: 00007ffe118d05d0 R08: 00007a57cbb45b20 R09: 00000000000000c0
R10: 0000601603619fc0 R11: 0000000000000246 R12: 0000000000000005
R13: 0000000000000001 R14: 0000000000000000 R15: 0000000000000001
</TASK>
E ficava nisso.
Tinha de mandar um zfs rollback nos volumes pra conseguir voltar a usar.
E tentar o upgrade novamente.
Depois de muito tentar, resolvi abrir um bug report no launchpad. Meu bug foi marcado como duplicado e passei então a interagir no bug onde o problema foi reportado primeiramente.
tl;dr: o bug era do zfs no kernel padrão que o plucky instala. A correção exige upgrade tanto do zfs quanto do kernel antes de ir pro upgrade do plucky.
Da primeira vez eu errei esse upgrade. E precisei recuperar o zfs pra voltar o snapshot.
E mais um problema já que não existe um procedimento bem descritivo de como fazer isso. Ou tem?
Sim tem. E mais de um.
Tive de recuperar algumas vezes o sistema. Então fiquei meio que craque em fazer isso. O esquema está abaixo:
root@ubuntu:~# lsblk -f
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
loop0 squashfs 4.0 0 100% /rofs
loop1 squashfs 4.0
loop2 squashfs 4.0
loop3 squashfs 4.0 0 100% /snap/bare/5
loop4 squashfs 4.0 0 100% /snap/core22/1748
loop5 squashfs 4.0 0 100% /snap/firefox/5751
loop6 squashfs 4.0 0 100% /snap/firmware-updater/167
loop7 squashfs 4.0 0 100% /snap/gnome-42-2204/202
loop8 squashfs 4.0 0 100% /snap/gtk-common-themes/1535
loop9 squashfs 4.0 0 100% /snap/snap-store/1248
loop10 squashfs 4.0 0 100% /snap/thunderbird/644
loop11 squashfs 4.0 0 100% /snap/ubuntu-desktop-bootstrap/315
loop12 squashfs 4.0 0 100% /snap/snapd-desktop-integration/253
loop13 squashfs 4.0 0 100% /snap/snapd/23545
sda iso9660 Joliet Extension Ubuntu 24.04.2 LTS amd64 2025-02-15-09-15-26-00
├─sda1 iso9660 Joliet Extension Ubuntu 24.04.2 LTS amd64 2025-02-15-09-15-26-00 0 100% /cdrom
├─sda2 vfat FAT12 ESP B5A5-8010
├─sda3
└─sda4 ext4 1.0 writable 5729a291-83ad-4b15-91b1-09a17bfc9504 1.3G 4% /var/crash
/var/log
sdb
nvme0n1
├─nvme0n1p1 vfat FAT32 C399-15AF
├─nvme0n1p2 zfs_member 5000 bpool 4626876014803904226
├─nvme0n1p3
└─nvme0n1p4 zfs_member 5000 rpool 15334588309526604034
root@ubuntu:~# zpool import -f rpool
root@ubuntu:~# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
rpool 936G 365G 571G - - 6% 39% 1.00x ONLINE -
root@ubuntu:~# cryptsetup open /dev/zvol/rpool/keystore rpool-keystore
Enter passphrase for /dev/zvol/rpool/keystore:
root@ubuntu:~# mkdir /mnt-keystore
root@ubuntu:~# mount /dev/mapper/rpool-keystore /mnt-keystore
root@ubuntu:~# ls /mnt-keystore
lost+found system.key
root@ubuntu:~# cat /mnt-keystore/system.key | zfs load-key -L prompt rpool
root@ubuntu:~# umount /mnt-keystore
root@ubuntu:~# cryptsetup close rpool-keystore
root@ubuntu:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 365G 542G 192K /
rpool/ROOT 106G 542G 192K none
rpool/ROOT/ubuntu_ni6nkv 106G 542G 11.5G /mnt
rpool/ROOT/ubuntu_ni6nkv/srv 352K 542G 192K /mnt/srv
rpool/ROOT/ubuntu_ni6nkv/usr 7.96M 542G 192K /mnt/usr
rpool/ROOT/ubuntu_ni6nkv/usr/local 7.77M 542G 6.02M /mnt/usr/local
rpool/ROOT/ubuntu_ni6nkv/var 64.4G 542G 192K /mnt/var
rpool/ROOT/ubuntu_ni6nkv/var/games 272K 542G 192K /mnt/var/games
rpool/ROOT/ubuntu_ni6nkv/var/lib 60.0G 542G 24.2G /mnt/var/lib
rpool/ROOT/ubuntu_ni6nkv/var/lib/AccountsService 1.07M 542G 212K /mnt/var/lib/AccountsService
rpool/ROOT/ubuntu_ni6nkv/var/lib/NetworkManager 7.59M 542G 580K /mnt/var/lib/NetworkManager
rpool/ROOT/ubuntu_ni6nkv/var/lib/apt 388M 542G 103M /mnt/var/lib/apt
rpool/ROOT/ubuntu_ni6nkv/var/lib/dpkg 1.14G 542G 169M /mnt/var/lib/dpkg
rpool/ROOT/ubuntu_ni6nkv/var/log 261M 542G 92.7M /mnt/var/log
rpool/ROOT/ubuntu_ni6nkv/var/mail 272K 542G 192K /mnt/var/mail
rpool/ROOT/ubuntu_ni6nkv/var/snap 4.11G 542G 4.03G /mnt/var/snap
rpool/ROOT/ubuntu_ni6nkv/var/spool 10.6M 542G 468K /mnt/var/spool
rpool/ROOT/ubuntu_ni6nkv/var/www 55.3M 542G 55.1M /mnt/var/www
rpool/USERDATA 258G 542G 192K none
rpool/USERDATA/home_39e1h7 258G 542G 242G /home
rpool/USERDATA/root_39e1h7 58.8M 542G 28.4M /root
rpool/keystore 39.8M 542G 16.5M -
rpool/var 739M 542G 192K /var
rpool/var/lib 739M 542G 192K /var/lib
rpool/var/lib/docker 738M 542G 729M /var/lib/docker
root@ubuntu:~# zfs set mountpoint=/mnt rpool/ROOT/ubuntu_ni6nkv
root@ubuntu:~# zfs mount rpool/ROOT/ubuntu_ni6nkv
root@ubuntu:~# ls /mnt
bin boot cdrom dev etc home lib lib32 lib64 media mnt opt proc root run sbin snap srv sys tmp usr var
root@ubuntu:~# zpool import -N -R /mnt bpool
root@ubuntu:~# zfs mount bpool/BOOT/ubuntu_ni6nkv
root@ubuntu:~# ls /mnt/boot/
System.map-6.11.0-21-generic config-6.11.0-21-generic efi initrd.img-6.11.0-21-generic initrd.img.old memtest86+x64.bin vmlinuz-6.11.0-21-generic vmlinuz.old
System.map-6.11.0-24-generic config-6.11.0-24-generic grub initrd.img-6.11.0-24-generic memtest86+ia32.bin memtest86+x64.efi vmlinuz-6.11.0-24-generic
System.map-6.14.0-15-generic config-6.14.0-15-generic initrd.img initrd.img-6.14.0-15-generic memtest86+ia32.efi vmlinuz vmlinuz-6.14.0-15-generic
root@ubuntu:~# mount /dev/nvme0n1p1 /mnt/boot/efi/
root@ubuntu:~# ls /mnt/boot/efi/
EFI
root@ubuntu:~# for i in proc dev sys dev/pts; do mount -v --bind /$i /mnt/$i; done
mount: /proc bound on /mnt/proc.
mount: /dev bound on /mnt/dev.
mount: /sys bound on /mnt/sys.
mount: /dev/pts bound on /mnt/dev/pts.
root@ubuntu:~# zfs set mountpoint=/ rpool/ROOT/ubuntu_ni6nkv
Broadcast message from systemd-journald@ubuntu (Sat 2025-04-19 15:35:17 UTC):
systemd[1]: Caught , from our own process.
root@ubuntu:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
bpool 838M 953M 96K /mnt/boot
bpool/BOOT 833M 953M 96K none
bpool/BOOT/ubuntu_ni6nkv 833M 953M 295M /mnt/boot
rpool 365G 542G 192K /
rpool/ROOT 106G 542G 192K none
rpool/ROOT/ubuntu_ni6nkv 106G 542G 11.5G /
rpool/ROOT/ubuntu_ni6nkv/srv 352K 542G 192K /srv
rpool/ROOT/ubuntu_ni6nkv/usr 7.96M 542G 192K /usr
rpool/ROOT/ubuntu_ni6nkv/usr/local 7.77M 542G 6.02M /usr/local
rpool/ROOT/ubuntu_ni6nkv/var 64.4G 542G 192K /var
rpool/ROOT/ubuntu_ni6nkv/var/games 272K 542G 192K /var/games
rpool/ROOT/ubuntu_ni6nkv/var/lib 60.0G 542G 24.2G /var/lib
rpool/ROOT/ubuntu_ni6nkv/var/lib/AccountsService 1.07M 542G 212K /var/lib/AccountsService
rpool/ROOT/ubuntu_ni6nkv/var/lib/NetworkManager 7.59M 542G 580K /var/lib/NetworkManager
rpool/ROOT/ubuntu_ni6nkv/var/lib/apt 388M 542G 103M /var/lib/apt
rpool/ROOT/ubuntu_ni6nkv/var/lib/dpkg 1.14G 542G 169M /var/lib/dpkg
rpool/ROOT/ubuntu_ni6nkv/var/log 261M 542G 92.7M /var/log
rpool/ROOT/ubuntu_ni6nkv/var/mail 272K 542G 192K /var/mail
rpool/ROOT/ubuntu_ni6nkv/var/snap 4.11G 542G 4.03G /var/snap
rpool/ROOT/ubuntu_ni6nkv/var/spool 10.6M 542G 468K /var/spool
rpool/ROOT/ubuntu_ni6nkv/var/www 55.3M 542G 55.1M /var/www
rpool/USERDATA 258G 542G 192K none
rpool/USERDATA/home_39e1h7 258G 542G 242G /home
rpool/USERDATA/root_39e1h7 58.8M 542G 28.4M /root
rpool/keystore 39.8M 542G 16.5M -
rpool/var 739M 542G 192K /var
rpool/var/lib 739M 542G 192K /var/lib
rpool/var/lib/docker 738M 542G 729M /var/lib/docker
root@ubuntu:~# zfs set mountpoint=/boot bpool
root@ubuntu:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
bpool 838M 953M 96K /mnt/boot
bpool/BOOT 833M 953M 96K none
bpool/BOOT/ubuntu_ni6nkv 833M 953M 295M /mnt/boot
rpool 365G 542G 192K /
rpool/ROOT 106G 542G 192K none
rpool/ROOT/ubuntu_ni6nkv 106G 542G 11.5G /
rpool/ROOT/ubuntu_ni6nkv/srv 352K 542G 192K /srv
rpool/ROOT/ubuntu_ni6nkv/usr 7.96M 542G 192K /usr
rpool/ROOT/ubuntu_ni6nkv/usr/local 7.77M 542G 6.02M /usr/local
rpool/ROOT/ubuntu_ni6nkv/var 64.4G 542G 192K /var
rpool/ROOT/ubuntu_ni6nkv/var/games 272K 542G 192K /var/games
rpool/ROOT/ubuntu_ni6nkv/var/lib 60.0G 542G 24.2G /var/lib
rpool/ROOT/ubuntu_ni6nkv/var/lib/AccountsService 1.07M 542G 212K /var/lib/AccountsService
rpool/ROOT/ubuntu_ni6nkv/var/lib/NetworkManager 7.59M 542G 580K /var/lib/NetworkManager
rpool/ROOT/ubuntu_ni6nkv/var/lib/apt 388M 542G 103M /var/lib/apt
rpool/ROOT/ubuntu_ni6nkv/var/lib/dpkg 1.14G 542G 169M /var/lib/dpkg
rpool/ROOT/ubuntu_ni6nkv/var/log 261M 542G 92.7M /var/log
rpool/ROOT/ubuntu_ni6nkv/var/mail 272K 542G 192K /var/mail
rpool/ROOT/ubuntu_ni6nkv/var/snap 4.11G 542G 4.03G /var/snap
rpool/ROOT/ubuntu_ni6nkv/var/spool 10.6M 542G 468K /var/spool
rpool/ROOT/ubuntu_ni6nkv/var/www 55.3M 542G 55.1M /var/www
rpool/USERDATA 258G 542G 192K none
rpool/USERDATA/home_39e1h7 258G 542G 242G /home
rpool/USERDATA/root_39e1h7 58.8M 542G 28.4M /root
rpool/keystore 39.8M 542G 16.5M -
rpool/var 739M 542G 192K /var
rpool/var/lib 739M 542G 192K /var/lib
rpool/var/lib/docker 738M 542G 729M /var/lib/docker
No fim deu certo e consegui fazer upgrade pro plucky. Mas o problema ainda existe. Não sei se será um problema quando chegar a época de upgrade do 24.04.
Espero que não.
Page 1 of 37

