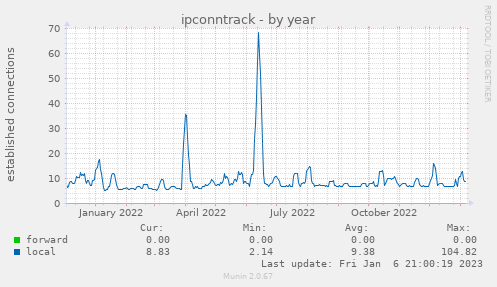
Hoje estava olhando pro gráficos anuais de performance da VM quando vi a imagem acima. Parece ataque. Tem cara de ataque mas... não achei nada que tivesse relacionado.
Tem algo na parte de firewall:
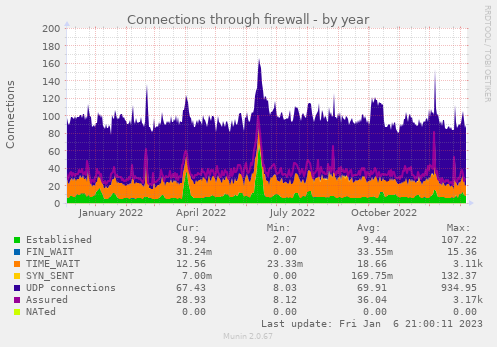
Mas é só isso.
Não tem tráfego no Apache:
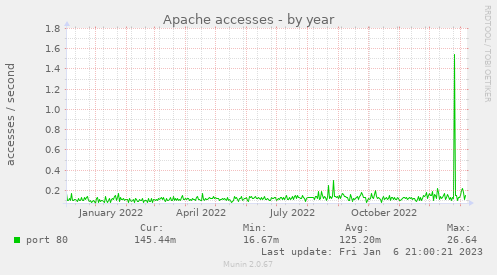
O pico no final do ano fui em fazendo upgrade. Mas só. Os outros gráficos de CPU, load average, etc não mostram nada.
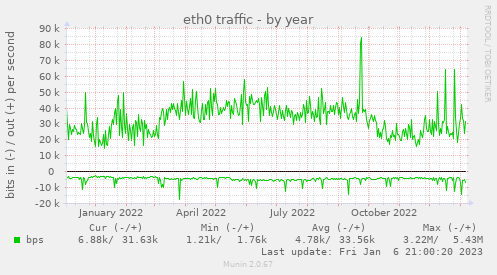
Não sei se isso me deixa feliz ou triste. Por um lado estou feliz de estar de pé sem precisar mexer em nada por outro lado... o que será que foi atacado?
No momento sigo chorrindo.

Nota: as configurações que seguram o site e tudo mais em pé são as descritas em O dia em que sofri um ataque de DDoS.
E como foi o tráfego por aqui em 2022?

Sem muitas surpresas eu diria. Um tráfego baixo e mais ou menos constante com o passar do tempo.
Qual sistema operacional?
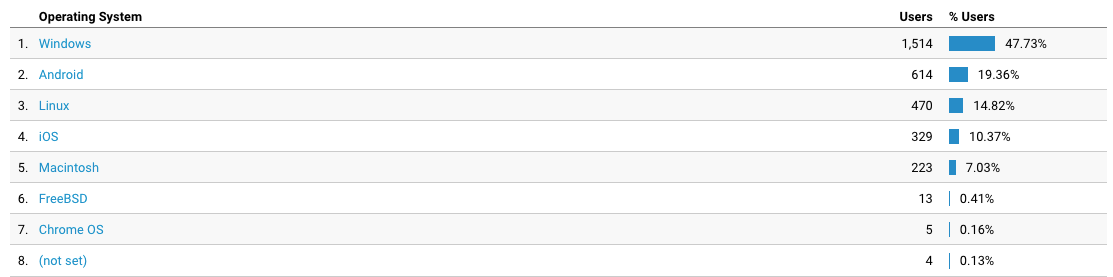
Windows continua sendo a maioria isolada. Mas os demais somados já são mais da metade. Então existe alguma esperança pra humanidade. Ainda que pouca.
E navegadores? Acho que essa vai sem grandes surpresas.

Chrome com larga marge à frente. Firefox e safari empatados. Edge mostrando que por enquanto continua longe de ser usado de verdade.
E vamos pro mobile.

Mesmo Android sendo uns 85% do mercado mobile, teve bastante gente em iOS acessando o site. Interessante.
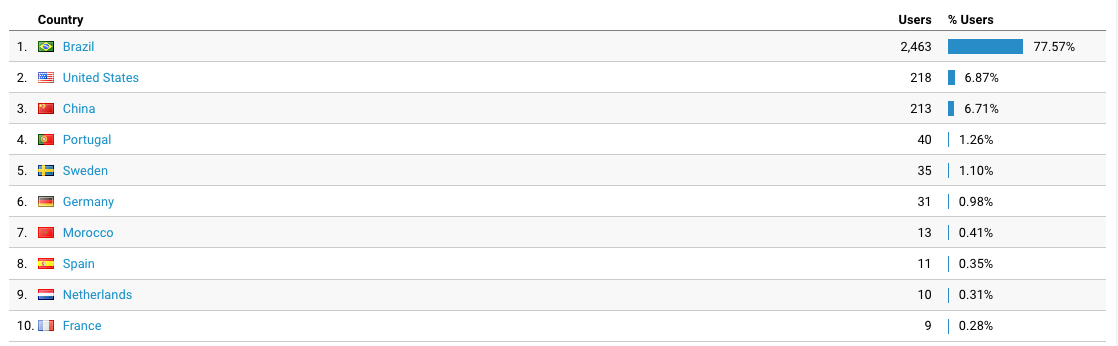
E sem surpresas pra origem dos acessos. Brazil é líder isolado. Seria estranho não ser uma vez que só escreve em português por aqui.
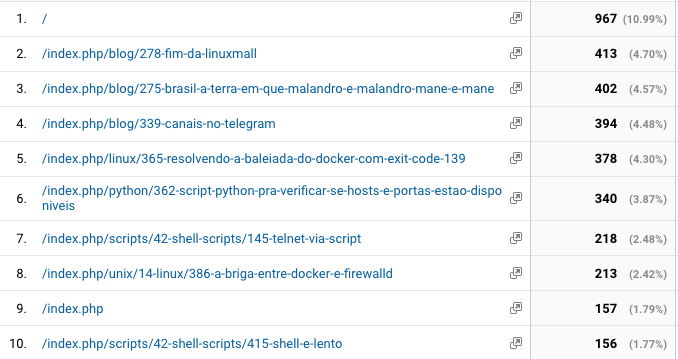
Das páginas mais lidas, a surpresa foram Fim da LinuxMall? e Brasil: a terra em que malandro é malandro, mané é mané. Provavelmente essa última foi por conta da mesma empresa estar novamente aplicando golpes.
E quem fez referências ao site?
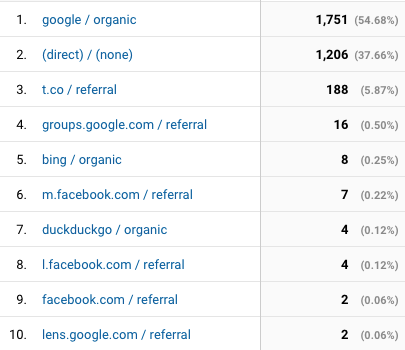
A maioria foi de busca direto pelo Google. Alguns via twiiter (o t.co) e alguns poucos de facebook e duckduckgo. Menção honrosa ao Bing.
E o que buscaram por aqui?
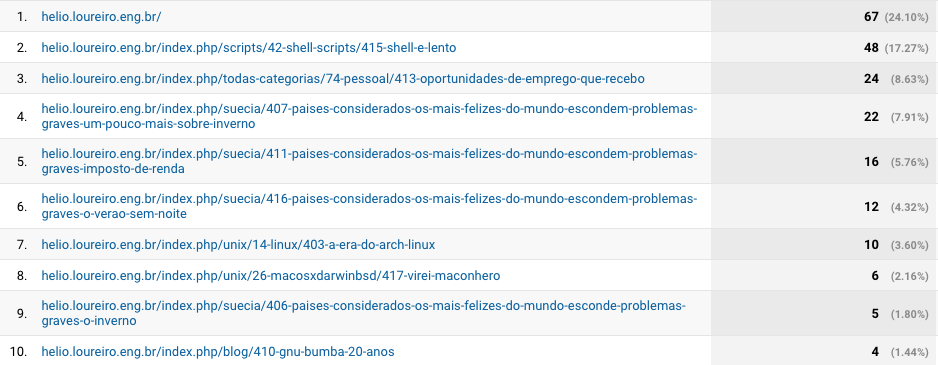
Alguns devem ter sido pela divulgação de links que fiz no Twitter, que agora abandonei pelo Mastodon.

As redes sociais que apontaram pra mim tiveram Twitter como grande campeão, mas era onde eu fazia mais anúncios dos posts. Esse lugar deve ser tomado pelo Mastodon em 2023 uma vez que Twitter virou abandonware pra mim.
Isso irá impactar no acesso ao site? Acho que não. Muita gente vem por busca orgânica.
E mesmo com mudança de template, upgrade de joomla, eu consegui dessa vez não perder tráfego. Isso foi bom.
E que comece 2023!

Hoje, tentando baixar um substituto pro Disqus no Linux-BR, descobri que meus e-mails pra @hl.eng.br não estavam mais funcionando.
Então fui fuçar nos logs do postfix pra ver a razão.
Jan 3 13:22:02 truta postfix/smtp[1984]: B300F11F304: to=, orig_to=<***** AT hl.eng.br>, relay=aspmx.l.google.com[2607:f8b0:4001:c58::1b]:25, delay=13, delays=12/0.01/0.64/0.57, dsn=5.7.1, status=bounced (host aspmx.l.google.com[2607:f8b0:4001:c58::1b] said: 550-5.7.1 [2605:2700:0:17:a800:ff:fe3e:bc97] Our system has detected that this 550-5.7.1 message does not meet IPv6 sending guidelines regarding PTR records 550-5.7.1 and authentication. Please review 550-5.7.1 https://support.google.com/mail/?p=IPv6AuthError for more information 550 5.7.1 . z23-20020a056638001700b00358317a21c3si22106554jao.145 - gsmtp (in reply to end of DATA command))
tl;dr: Google passou a exigir configuração de SPF desde novembro de 2022. Então já desde essa época que nada funciona.
O motivo, claro, é que recebo tudo no servidor onde está o blog e envio pra minha conta loureiro.eng.br que fica no Google.
Nada como começar o ano olhando alguns logs.
E fui fazer o upgrade do linux-br.org pra joomla4 e... deu ruim.

Ainda estou tentando descobrir como corrigir antes de apelar pra reverter o backup.
Renovando meus votos pra 2023.
E finalmente tomei coragem pra passar o dia fazendo o upgrade do site pro Joomla 4. As coisas ainda não estão 100% redondas, mas estou corrigindo aos poucos.
O importante é que sai do joomla3, que está em pra parar de receber updates já no ano que vem.
Agora é caçar ou um tema escuro pra site ou modificar esse aqui mesmo pra ficar marotamente escuro. Dark mode rules!
Update: missão cumprida! Site atualizado com a extensão DarkMagic: https://github.com/nikosdion/DarkMagic/releases/tag/2.1.0

Tive de trabalhar nessa semana com um caso que me exigiu usar o pycurl no Python. O problema foi que escrevi um script que rodava baixando artefatos de build no Jenkins usando o módulo requests, e o mesmo não funcionava mais no Gitlab.
Depois de gastar um pouco de tempo no request, e usando o curl do exemplo do site do Gitlab, eu acabei desistindo e indo pra usar o pycurl no script. De cara descobri que não tinha pycurl instalado. E no MacOS não foi tão simples como poderia ter sido. A receita de bolo pra instalar o pycurl foi a seguinte sequência:
helio@MacOS> arch -arm64 brew install openssl curl helio@MacOS> export PATH=/opt/homebrew/opt/curl/bin:$PATH helio@MacOS> export LDFLAGS="-L/opt/homebrew/opt/curl/lib":$LDFLAGS helio@MacOS> export CPPFLAGS="-I/opt/homebrew/opt/curl/include":$CPPFLAGS helio@MacOS> arch -arm64 pip install --no-cache-dir --compile --ignore-installed --install-option="--with-openssl" --install-option="--openssl-dir=/opt/homebrew/Cellar/openssl@3/3.0.7" pycurl
Quando algo funciona em curl é fácil escrever o código em python. Basta rodar com o parâmetro --libcurl foo.c que ele joga o código em funcionou dentro do arquivo.c no formato pra linguagem C, mas é bem próximo do uso em python.
hnd = curl_easy_init(); curl_easy_setopt(hnd, CURLOPT_BUFFERSIZE, 102400L); curl_easy_setopt(hnd, CURLOPT_URL, "https://gitlab.[redacted]/api/v4/projects/[redacted]/jobs/[redacted]/artifacts"); curl_easy_setopt(hnd, CURLOPT_NOPROGRESS, 1L); curl_easy_setopt(hnd, CURLOPT_HTTPHEADER, slist1); curl_easy_setopt(hnd, CURLOPT_USERAGENT, "curl/7.86.0"); curl_easy_setopt(hnd, CURLOPT_FOLLOWLOCATION, 1L); curl_easy_setopt(hnd, CURLOPT_MAXREDIRS, 50L); curl_easy_setopt(hnd, CURLOPT_HTTP_VERSION, (long)CURL_HTTP_VERSION_2TLS); curl_easy_setopt(hnd, CURLOPT_FTP_SKIP_PASV_IP, 1L); curl_easy_setopt(hnd, CURLOPT_TCP_KEEPALIVE, 1L);
Em python:
url = "https://gitlab.[redacted]/api/v4/projects/[redacted]/jobs/[redacted]/artifacts"
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.BUFFERSIZE, 102400)
c.setopt(c.NOPROGRESS, 1)
if GITLAB_PRIVATE_TOKEN:
c.setopt(c.HTTPHEADER, [ "PRIVATE-TOKEN:" + GITLAB_PRIVATE_TOKEN ])
else:
c.setopt(c.HTTPHEADER, [ USERNAME + ":" + PASSWORD])
c.setopt(c.USERAGENT, "curl/7.84.0")
c.setopt(c.FOLLOWLOCATION, 1)
c.setopt(c.HTTP_VERSION, c.CURL_HTTP_VERSION_2TLS)
c.setopt(c.TCP_KEEPALIVE, 1)
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
E assim o código saiu funcionando.

Depois de mais de um ano recebendo avisos de que o PHP7.4 do Debian stable estava desatualizado e seu suporte iria terminar, eu finalmente segui uma receita de bolo pra atualizar pro PHP8.1.
https://computingforgeeks.com/how-to-install-php-on-debian-linux-2/
Eu achei que seria bem mais complicado.
Ele recomenda um repositório aleatório de um site https://packages.sury.org que achei um tanto... suspeito.
Mas dando uma olhada no site, é do próprio mantenedor dos pacotes PHP no Debian. E foi realmente um mamão com açúcar. Depois do apt update ele já reconheceu que haviam pacotes para atualizar e um apt dist-upgrade -y -m fez o resto. E saiu funcionando.
O restante foi selecionar o módulo no apache com a2enmod php8.1 e desabilitar o antigo com a2dismod php7.4 e finalmente reiniciar o próprio apache com systemctl restart apache2 e pronto.
Update 2022-12-09 (alguns minutos após postar esse artigo): cantei vitória cedo demais. O PHP8.1 derrubour primeiro o encurtador hl.eng.br. Tive de atualizar o yourls.org pra botar no ar novamente.
Em seguida...

Sim, o site inteiro caiu. Como o linux-br ficou em pé eu desconfiei que era algum plugin. Fui desabilitando um por um e nada. Até que troquei o tema. E era isso. Por isso a página está com essa cara pálida. Estou mexendo pra tentar colocar um tema mais escuro.
(e sim, sou daqueles que faz troubleshooting em produção)

Após um almoço no restaurante próximo da firma, na raras visitas que faço por lá, enquanto comiamos a famosa panqueca de quinta-feira, uma colega começou a conversar sobre o novo chat bot de OpenAI que tomou corações e posts do Mastodon, ChatGPT.
Hoje ela me enviou uma canção gerada pelo bot.
Helio, Helio, the Linux lover He knows Kubernetes like no other Prometheus, Design Rules, he's got them down Windows? He'd rather not mess around
With his skills in Python and Linux, too Helio can make any project come true He's a developer with a passion for all things open source And when it comes to coding, he's always on the right course
So here's to you, Helio, the Linux and Python king You make the world of technology sing Keep up the great work, and never lose your love for all things open We're grateful for all the code you're sharing, and the knowledge you're hopen!"
Eu adorei, claro. Muito obrigado Teja!

Por algum motivo bizarro, a Apple inclui essa tecla esquisita no teclado de seus notebooks. Tenho no MacBook Pro que uso, mas já vi que é a mesma coisa em outro modelos como o MacBook Air. Como eu uso boa parte do tempo em casa, onde tenho um teclado mecânico, quase nunca percebo o problema dessa tecla alienígena instalada. Mas basta eu trabalhar só no laptop em hackathons e outros eventos pra começarem os problemas. Principalmente quando vou mexer no shell e passar o "~" pra usar como abreviação do HOME.
Hoje, um dos raros dias que faço isso, resolvi mexer no laptop na sala pra assistir à copa do mundo e acertar algumas coisas no raspberrypi. Além de escrever pro blog aqui. Eis que o raio da tecla "~" faz falta. Mas dessa vez resolvi buscar alguma solução na Internet. E achei!
https://apple.stackexchange.com/questions/281405/easy-way-to-remap-non-modifier-keys-on-mac
Basicamente é rodar o seguinte comando:
MacOS@helio> hidutil property --set '{"UserKeyMapping":
[{"HIDKeyboardModifierMappingSrc":0x700000035,
"HIDKeyboardModifierMappingDst":0x700000064},
{"HIDKeyboardModifierMappingSrc":0x700000064,
"HIDKeyboardModifierMappingDst":0x700000035}]
}'
Isso já configura a tecla corretamente. E pra iniciar durante o boot, criar o arquivo ~/Library/LaunchAgents/com.user.loginscript.plist com o seguinte conteúdo:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.loginscript</string>
<key>ProgramArguments</key>
<array>
<string>/usr/bin/hidutil</string>
<string>property</string>
<string>--set</string>
<string>{"UserKeyMapping":[{"HIDKeyboardModifierMappingSrc":0x700000035, "HIDKeyboardModifierMappingDst":0x700000064}, {"HIDKeyboardModifierMappingSrc":0x700000064, "HIDKeyboardModifierMappingDst":0x700000035}]}</string>
</array>
<key>RunAtLoad</key>
<true/>
</dict>
</plist>
E chamar na inicialização assim:
MacOS@helio> launchctl load ~/Library/LaunchAgents/com.user.loginscript.plist
E pronto! Tecla funcional. Agradeço de coração quem deu essa resposta maravilhosa no stack exchange.
UPDATE: Sun Nov 27 19:27:29 CET 2022
Quando fui usar o laptop conectado no teclado externo, tive a triste verificação de que os comandos acima troca uma tecla pela outra, o que é altamente indesejado. O que eu quero é mesmo sumir com a tecla do "±" que não uso.
Pra isso eu precisei modificar o comando anterior para:
MacOS@helio> hidutil property --set '{"UserKeyMapping":
[{"HIDKeyboardModifierMappingSrc":0x700000064,
"HIDKeyboardModifierMappingDst":0x700000035}]
}'
E o mesmo pra ~/Library/LaunchAgents/com.user.loginscript.plist:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.loginscript</string>
<key>ProgramArguments</key>
<array>
<string>/usr/bin/hidutil</string>
<string>property</string>
<string>--set</string>
<string>{"UserKeyMapping":[{"HIDKeyboardModifierMappingSrc":0x700000064, "HIDKeyboardModifierMappingDst":0x700000035}]}</string>
</array>
<key>RunAtLoad</key>
<true/>
</dict>
</plist>
E agora tenho a tecla "~" em ambos os teclados. Precisei dar um "reload" no launchctl pro caso do teclado:
MacOS@helio> launchctl unload ~/Library/LaunchAgents/com.user.loginscript.plist MacOS@helio> launchctl load ~/Library/LaunchAgents/com.user.loginscript.plist

Como um tsunami, Elon Musk assumiu o Twitter e literalmente varreu como uma onde destruidora a empresa. De cara mandou metade pra rua, depois pediu code review pra cada um que ficou e deu prazo para irem trabalhar fisicamente na empresa ou automaticamente estariam demitidos. Claro que as coisas não foram muito bem. E no momento atual continuam indo por água abaixo.
Enquanto isso redes alternativas ganharam tração, entre elas a Mastodon. Ao contrário do Twitter, Mastodon não é uma empresa ou uma rede: é um conjunto de servidores conversando o mesmo protocolo e que se comunicam entre si. Eu já tinha uma conta na instância mastodon.social, onde tudo surgiu. Mas desde que foi criada, em 2015, eu tinha postado 2 mensagens. E só. Nunca teve muita gente ali pra conversar pra tornar a rede minimamente interessante.
Mas com a ascensão do Elon ao Twitter isso tudo mudou. E pra melhor. Muita gente interessante migrou pra rede Mastodon, ao ponto de atingir o efeito rede e manter um crescimento sustentando em termos de usuários e posts. Se os servidores vão aguentar esse tráfego, daí já são outros 500.
No Twitter eu automatizava muita coisa. Então pra mim era essencial ter as mesmas coisas no Mastodon. Eu primeiramente descobri o programa "toot", em Python. Com ele é possível criar posts usando shell script (e na verdade foi o que fiz de início).
Não sei se tem pacotes pra instalar o toot, mas eu usei o pip do próprio python pra instalar.
helio@MacOS> pip3 install toot
Com isso o programa "too" vai parar em ~/.local/bin, que eu já tenho na minha variável PATH, então funciona no shell. Mas é preciso corrigir o PATH se for usar num script via crontab (como eu fiz depois).
O começo é criar um login na instância que for usar. Eu por exemplo comecei com
helio@MacOS> toot loginThis email address is being protected from spambots. You need JavaScript enabled to view it. helio@MacOS> toot login -iThis email address is being protected from spambots. You need JavaScript enabled to view it.
As configurações ficam armazenadas num arquivo for json em ~/.config/toot/config.json, o que depois facilitou minha vida pra criar scripts em python (mas que vou descrever em outro artigo).
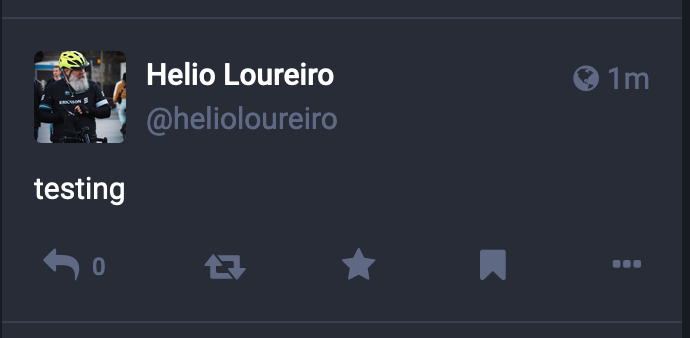
Daí você pode começar a mandar mensagens usando a conta padrão ou usando o "-i" pra qual instância quer mandar.
helio@MacOS> toot post "testing"
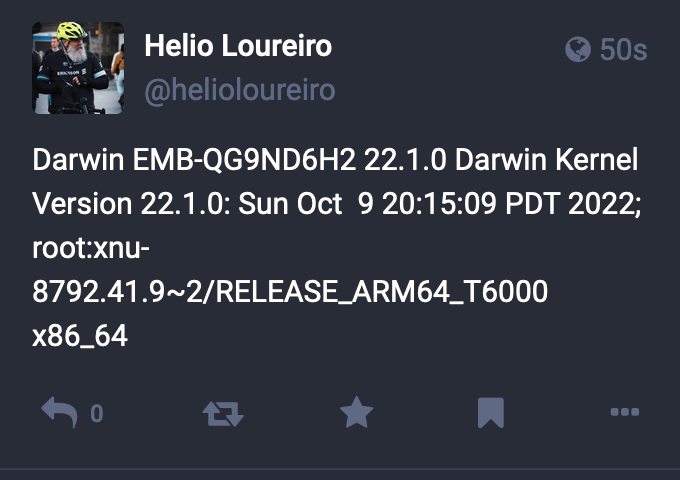
E o toot aceita mesmo passar conteúdo via pipe:
helio@MacOS> uname -a | toot post
Pra subir imagens e usando minha instância que posto em português:
helio@MacOS> toot activate helioloureiroBR@This email address is being protected from spambots. You need JavaScript enabled to view it.
✓ User helioloureiroBR@This email address is being protected from spambots. You need JavaScript enabled to view it. active
helio@MacOS> toot post "só li verdades" --media=$HOME/Pictures/chicobuarque-mastodon.jpg
Uploading media: /Users/ehellou/Pictures/chicobuarque-mastodon.jpg
Toot posted: https://mastodon.social/@helioloureiroBR/109410489057504335
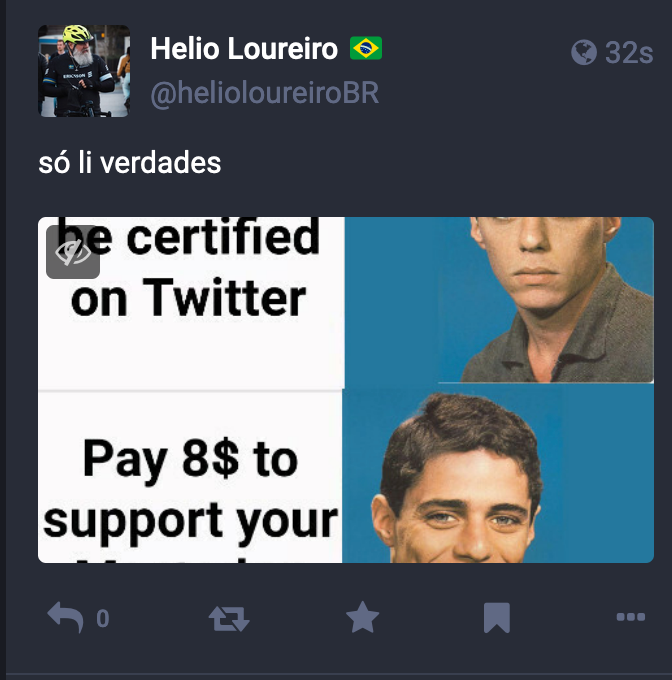
Então é possível ver as possibilidades infinitas de scripts em shell com o uso de toot.
Pra terminar o artigo, deixo aqui a imagem muito significativa que enviei no teste. Afinal não existe prazer maior na vida que ajudar um bilionário a ficar milionário.

Em tempo: eu não apaguei minhas contas no Twitter. Estão lá mas inativas.
Acabei de lançar um sistema fácil pra fazer loteria de participantes na PyCon Suécia.
Ia fazer web, mas depois mudei de idéia e passei pra console com dialog.
./simple-lottery-eventbrite.py --csvfile=/Users/ehellou/Downloads/PyconSweden2022-Attendee_Summary_Report_91481040875_20221027_1516.csv --dialog
Ele abrirá e perguntará quantos rounds quer rodar (ou quantos vencedores ganharão).
Em seguida ele permite confirmar o ganhador o cancelar, no caso da pessoa não estar na sala.
E por fim salva um log dos ganhadores, com o email correto.
O repositório está no github.
Se não leu ainda os outros posts, pare e leia pra entender um pouco mais sober a Suécia.

Ao invés de descrever como funciona a Suécia ou descrever como levei meu último tombo de bicicleta aqui. Claro que não foi o primeiro. Já cai algumas vezes andando na neve e no gelo. Mas esse foi o primeiro em que deslizei nas folhas do outono.
Nessa época do ano já fica escuro por volta das 5 horas da tarde. Então luzes nas bicicletas são ítens obrigatórios. E no sentido literal mesmo. A lei de trânsito na região de Estocolmo exige luzes (frontal e traseira) e campainha pra circular com bicicletas. Capacete não é obrigatório (apenas pra crianças e jovens até 15 anos - e é responsabilidade dos pais assegurarem que a criança/jovem o esteja usando). Eu sai mais tarde da empresa pois participava da nossa hackathon bi-anual que aconteceu a primeira edição na primavera e a segunda agora no outono. Mas se tivesse saído às 5 estaria escuro do mesmo jeito. Não choveu, mas o chão está úmido da chuva dos dias anteriores (e talvez durante a madrugada). Ao fazer a minha primeira curva... lá vou eu rolando com bicicleta, laptop, etc. Os freios e marchas da bicicleta ficaram tortos com o tombo. A roda também. Mas eu levo um kit básico de ferramentas e arrumei tudo por lá mesmo pra poder chegar em casa.
Não me machuquei muito uma vez que escorreguei com a bicicleta nas folhas que ficam no chão. Só um arranhão básico.

No dia seguinte descobri mais algumas coisas que ficaram danificadas pela queda.


A fonte eu consegui dar um desentortada na mão mesmo. E está aqui funcionando como se nada tivesse acontecido. O mesmo posso dizer do laptop.
Já no dia seguinte ligou como se nunca tivesse caído no chão. Na verdade eu não sei dizer o quanto ele bateu no chão uma vez que a bicicleta cai por cima de mim (e por isso arranhou a minha perna). Mas fiquei feliz de ver que o laptop da Apple é duro na queda. Ele realmente parece ser bem sólido.
Agora vamos ao ponto do motivo pelo qual eu cai. Primeiro que a culpa é minha. Somente minha. Nessa época do ano eu já não deveria estar usando minha bicicleta road, que tem um pneu slick pra asfalto. Eu tenho uma mountain bike e deveria ter ido com ela mesmo. E o problema dessa época do ano são as folhas e a chuva. Chove bastante, como que pra anunciar que o inverno está chegando e as folhas criam uma camada pastosa escorregadia. Até mesmo de carro é preciso tomar cuidado quando passa por onde tem muitas folhas no chão. Imaginem então de bicicleta?




Eu não cai em nenhum desses lugares em que tirei a foto. Foi num lugar com bem menos folhas. A diferença foi que eu estava rápido demais, no escuro e dando chances demais pro azar. Com esse pneuzinho aí abaixo.

Não estava chovendo no momento da foto, mas é possível perceber o quanto o pneu fica molhado por passar pelas folhas úmidas. E um pneu liso, pra asfalto...

Então imagino que essa tenha sido a última pedalada que dei com minha bicicleta road nesse ano. Vou passar a usar a mountain bike, que logo logo precisarei trocar os pneus atuais pelos pneus de inverno. E talvez no ano que vem considerar trocar por uma gravel, que tem o pneu mais largo e com ranhuras.
Mas enquanto isso, podem olhar os vídeos que fiz com a bike road esse ano. O primeiro foi uma pedalada básica até um local próximo, Upplands Väsby, 67 Km ida e volta, depois Uppsala, 82 Km (voltamos de trem) e finalmente Nynäsham, 73 Km, de onde também voltamos de trem.
Page 11 of 39
