Estamos em maio de 2019 e até agora não escrevi nada por aqui. Um pouco por falta de tempo, mas a verdade é que a preguiça e procrastinação estão tomando conta de mim. Então resolvi fugir de assuntos mais técnicos e falar de dragões, de Skyrim.
Já jogou Skyrim? Não? Recomendo fortemente. É um jogo estilo RPG e longo, mas bem legal de jogar e não cansativo como Witcher 3 ou Fallout 3 e 4.
Antes de falar do jogo em si, vou descrever um pouco das plataformas. Plataformas? Sim! Adoro tanto o jogo que comprei pra consoles e pra PC.
Quem ganha? Não sei dize a resposta pois muito vai de gosto. Mas comparando alguns quesitos que sempre entram na discussão.
Esse foi o primeiro console que comprei o Skyrim. Em termos de custo foi o que paguei mais caro. Mas o motivo foi que comprei como 1 anos após o lançamento. O valor já era mais baixo que o preço de lançamento, mas foi muito mais caro que nas outras plataformas pelo fator de idade do jogo. Diferenças gráficas? Não percebi muita coisa. O jogo parece o mesmo. Mudança no roteiro do jogo? Não. Tudo segue do mesmo jeito, inclusive onde achar mais dinheiro ou relíquias. O único ponto que era chato no Xbox3 60 era a transição de telas quando entra ou sai de algum lugar como castelo ou caverna. O tempo era tão longo que eu podia checar o twitter, postar alguma coisa e a tela ainda não tinha carregado. Na época não me importei tanto mas hoje em dia é notável a lentidão pra carregar essas transições. E travamentos! Eventualmente o Xbox 360 dava uma travadinha pra nos lembrar que por mais que não fosse Windows, ainda era Microsoft.
Durante uma promoção de Black Friday acabei comprando um Playstation 4. Paguei 200 euros mas mesmo assim achei que foi caro demais pra um console que nada mais é que um upgrade do Playstation 3 (e sim, tenho também um Playstation 3, mas não tenho Skyrim nele). O que jogar? Sim! Skyrim. O valor já foi mais baixo que o que paguei pro Xbox 360 mas no pacote ainda vieram dois DLCs, o de Dawnguard que entram os vampiros no jogo e o Dragonborn que enfrenta outro como você, que absorve as almas dos dragões, mas tomou um rumo de vilão na vida (lado negro da força?).
Minha primeira decepção foram os gráficos. Esperava um baita upgrade em relação ao Xbox 360 mas no fim ficou a mesma coisa. Se sombreado ou efeito da água melhorou, eu realmente não percebi. A jogabilidade ficou exatamente a mesma, com baús, dinheiro e prêmios todos basicamente nos mesmos lugares. A transição de telas ficou bem mais rápida no Playstation 4 se comparado com Xbox 360.
Acabei fazendo um upgrade no meu PC e entre placa mãe nova, nova CPU, e mais memória, eu acabei adicionando um placa NVIDIA. Ao contrário dos consoles, PC é preciso passar a configuração pois cada um monta o que quiser. Minha configuração de PC é a seguinte:
Eu fiz o upgrade sem intenção de somente jogar mas de ter um PC pra fazer de tudo. A grande mudança que aconteceu foi o lançamento o Proton da Steam, que, baseado em Wine, permite rodar os jogos de Windows em Linux. Sobre o lançamento do Proton e estado atual da Steam sobre Linux com certeza não vou entrar em detalhes aqui, mas vale um outro artigo.


Agora descrevendo o Skyrim no PC. Com as configurações no máximo, ultra, tive problema de "stuttering", da imagem quebrando, sem fluidez. Mesmo diminuindo os efeitos pra médio não consegui resolver o problema. De longe a versão pra PC é a que tem mais bugs em relação aos outros. É bem comum atirar uma flecha em alguém na sua frente e... a flecha passar direto e acertar a parede. Fora erros de renderização de tela. Até agora não consigo entrar na água pois fica um borrão na tela e não vejo nada. Poderia dizer que são bugs do proton mas pela quantidade de gente reclamando em fóruns na Internet e rodando Windows, parece ser bug do jogo mesmo.
Agora ponto positivo: a imagem ficou melhor. Ah... ficou com um pouco mais de contraste, mas nada pra dizer que é muito melhor que console. Mas a transição de cenas... ficou um espetáculo. Entrar em um castelo leva coisa de 5 segundos. Isso sim foi algo a se elogiar.


Descrevi até o momento as plataformas mas não comentei nada do jogo. Talvez porque seja um jogo já antigo e dificilmente não se ouviu falar dele ou o jogou. Se esse é o seu caso, pode continuar lendo.
Skyrim é um jogo estilo RPG que lembra o modo de Fallout 3. Não é tão maçante quanto o Fallout 3 pra jogar, mas é um mundo aberto cheio de side quests que ajudam a melhorar seu desempenho no jogo. A história é que Skyrim repentimante se vê atacada por dragões. Ao ajudar a enfrentar um dos dragões, você se descobre herdeiro de um poder que absorve a alma do dragão abatido, um "Dragonborn" que será seu apelido durante o desenrolar do jogo. A estória toda é baseada em tentar vencer os dragões usando um "elder scroll" (velho pergaminho?). O jogo usa o sistema de gamefication, garantido bônus a cada etapa vencida, aumentando seu ranking, e dando possibilidade de desenvolver as habilidades que achar mais necessárias.
No início do jogo é preciso escolher um nome e um rosto para seu personagem. Eu já joguei com todos nomes possíveis e imagináveis: Stallman, Systemd, Milkshake, Jessica Jones, Querida, Ada, etc. E sim, joguei tanto com personagens do sexo masculino quanto feminino.
Há diferença entres os personagens ou sexo? Personagens do sexo feminino sofrem ataques constantes de chauvinismo. Escolha uma loira nordica de olhos azuis e todo guarda de todo lugar vai tentar te passar uma cantada, que não influencia em nada no jogo. Escolha uma Ork e todos dirão que sua cara está horrível. Do sexo masculino os comentários costumam ser mais genéricos. Mas entre as raças disponíveis, Ork, nórdico, bretão, khajiit (felinos), argoniano (lagartos), e elfos o resultado é praticamente o mesmo. Então seja feliz em montar alguém com a cara que gostar, inclusive com cicatrizes e pinturas de guerra, e comece a jogar sem preocupação no impacto que isso terá na estória do jogo.
Nota: boa parte do jogo você estará usando um capacete ou mesmo máscara, então não se preocupe muito em botar um cabelo muito maneiro ou um pintura fantástica.

Durante o desenrolar do jogo, é possível visualizar seu personagem em terceira pessoa ou em primeira pessoa, estilo FPS. Isso ajuda bastante na jogabilidade.

Entre as várias habilidades que pode evoluir ao longo do jogo, eu acabei sempre optando por "sneak" e "archery". Com ambas desenvolvidas, fica muito mais fácil esgueirar-se dentro de castelos ou cavernas e matar os inimigos com o mínimo de sangue derramado, principalmente o seu sangue. Já tentei ir com uma raça mais forte, como Ork, e entrar de peito aberto em lutas e melhorar a habilidade de armas de uma mão ou de ambas as mãos, mas o resultado é que você acaba morrendo a maior parte das vezes.
Outro detalhe: ao evoluir o uso do arco, você desenvolve o poder de dar um zoom no alvo e até mesmo ter um efeito de slow motion pra acertar. Então é um atributo bastante prático.
Entrar sorrateiramente é chave pro jogo todo. E um dos side quests que te ajuda nisso é a dos "thiefs guild".
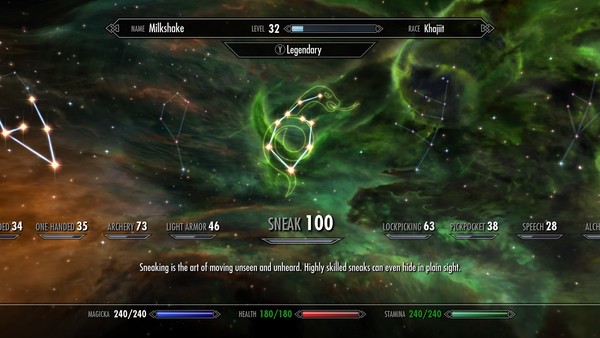

Outra habilidade que também gosto de desenvolver é de mágicas, principalmente a de "conjuration". No meio de uma luta chamar um "astronarch" sempre ajuda, seja pra te defender ou seja pra roubar o foco do inimigo enquanto você ataca por trás.
Depois de jogar tanto eu já sempre sigo o mesmo roteiro. Aliás recentemente descobri que é possível fechar quase todos os side quests sem nem mesmo ativar o poder de Dragonborn, o que significa não visitar Whiterun e ir direto pras outras cidades pra iniciar os side quests.
O primeiro que sempre faço é da escola de magia em Winterhold. É um side quest com poucas missões e rapidamente é possível adquirir poderes mágicos. Ao terminar o side quest, você está na posição de archmage da escola, então ganha um quarto (o principal) onde fica fácil guardar tudo quanto for cacareco que for recolhendo ao longo do jogo.
Em seguida eu em geral sigo ou o side quest dos "thiefs guild" em Riften ou "dark brotherhood". Se for seguir a de ladrões, é preciso adquirir o poder de Dragonborn pra seguir até o fim.
O quest do "thiefs guild" termina por te conceder um roupa de nightingale, que é ótima pra jogar o restante no modo stealth.
O quest do "dark brotherhood" você assassina o imperador de Tamriel e permite desenvolver o ataque por trás com uma adaga. Vira um modo eficiente de eliminar qualquer inimigo, por mais forte que seja. No início do quest, é possível virar-se contra os "dark brotherhood" e daí o quest vira pra eliminar todos eles. Mas é muito mais legal virar um assassino. Não é todo jogo que a gente mata o imperador.
Esses com esses side quests terminados, seu poder de "sneak" já estará em 100%. Com isso todo o restante do jogo ficará bem mais fácil e simples.
Existem outros side quests relevantes? Existem vários side quests, mas relevantes mesmo são só esses 3. Outros te darão uma arma ou uma peça de roupa (capacete, armadura, etc), mas nenhum é tão completo como esses 3.
E a guerra? A estória desenvolve-se em meio a uma guerra entre império e rebeldes, liderados por Ulfric Stormcloack. É possível inclusive não escolher lado nenhum e seguir o jogo. Em determinado ponto um acordo de paz será feito na escola dos Greybeards pra enfrentar os dragões.
Minha opção? Eu acabei gostando mais de ajudar os rebeldes. As missões são mais interessantes. O lado legal é que a maioria dos Jarls, prefeitos das cidades, são trocados ao vencer a guerra. Mesmo o Jarl de Whiterun é deposto.
Acho o que tinha de descrever do jogo é isso. Espero que tenha animado a experimentar quem nunca jogou e tentar conquistar toda Skyrim. Boa diversão!

Uma das grandes barreiras que encontramos ao iniciar o aprendizado de uma linguagem de programação é a falta de exercícios mais próximos da realidade. Talvez nem todo mundo veja essa dificuldade, mas pra mim sempre foi assim. Se não vejo uma forma de aplicar o que estou aprendendo, não consigo evoluir na linguangem.
Pegando como exemplo o livro da linguagem C escrito por Kerninghan e Ritchie: os exemplos são tão específicios que fica difícil abstrair as ideias e aprender como usar ponteiros de forma eficiente.
Para tentar superar essa barreira e ajudar a quem quiser aprender a programar sair da inércia e praticar surgiu o site "os programadores" ou http://osprogramadores.com. É um site criado e mantido pelos programadores Bernardino Campos, Marcelo Pinheiro, Marco Paganini e Sergio Correia pra ajudar iniciantes com desafios que são enviados através de "pull requests" no GitHub, ou seja, além de programar ainda existe a oportunidade de aprender controle de versão com git.
Não existe exigência de regularidade: é possível enviar seu código quando estiver disponível pra escrever. Também não existe uma linguagem só. Os desafios podem ser resolvidos em qualquer linguagem, de C à nodejs. E atualmente existe um sistema de scores pra ver quem está com maior pontuação de participação.
Eu só resolvi até agora os desafios 01 (que é criação e fork do repositório no github), 02 e 03 mas estou devendo de enviar meus pull requests. Fiz em python, go e C mas ainda quero escrever também em perl.
E tem mais uma parte interessante: grupo no telegram! Não bastando ter apenas o site, o grupo está lá pra ajudar com perguntas e respostas sobre os desafios e assuntos às vezes nem tão ligados à programação assim como por exemplo lubrificante pra ventoinha da cpu. O link é esse: https://t.me/osprogramadores
Então se tem interesse em aprender a programar ou aprender uma nova linguagem, não deixe pra depois e participe. É bem divertido e interessante.
Se existe algo que é um inferno em Linux é fonte. Como uso KDE como desktop padrão com HiDPI em 196 pontos, os aplicativos em GTK teimam em usar outras fontes e com tamanhos diferentes. É tipo uma maldição de Montezuma. Um dia seu ambiente gráfico está tudo certo, e de repente fica tudo com cara de que você tem problemas de visão.
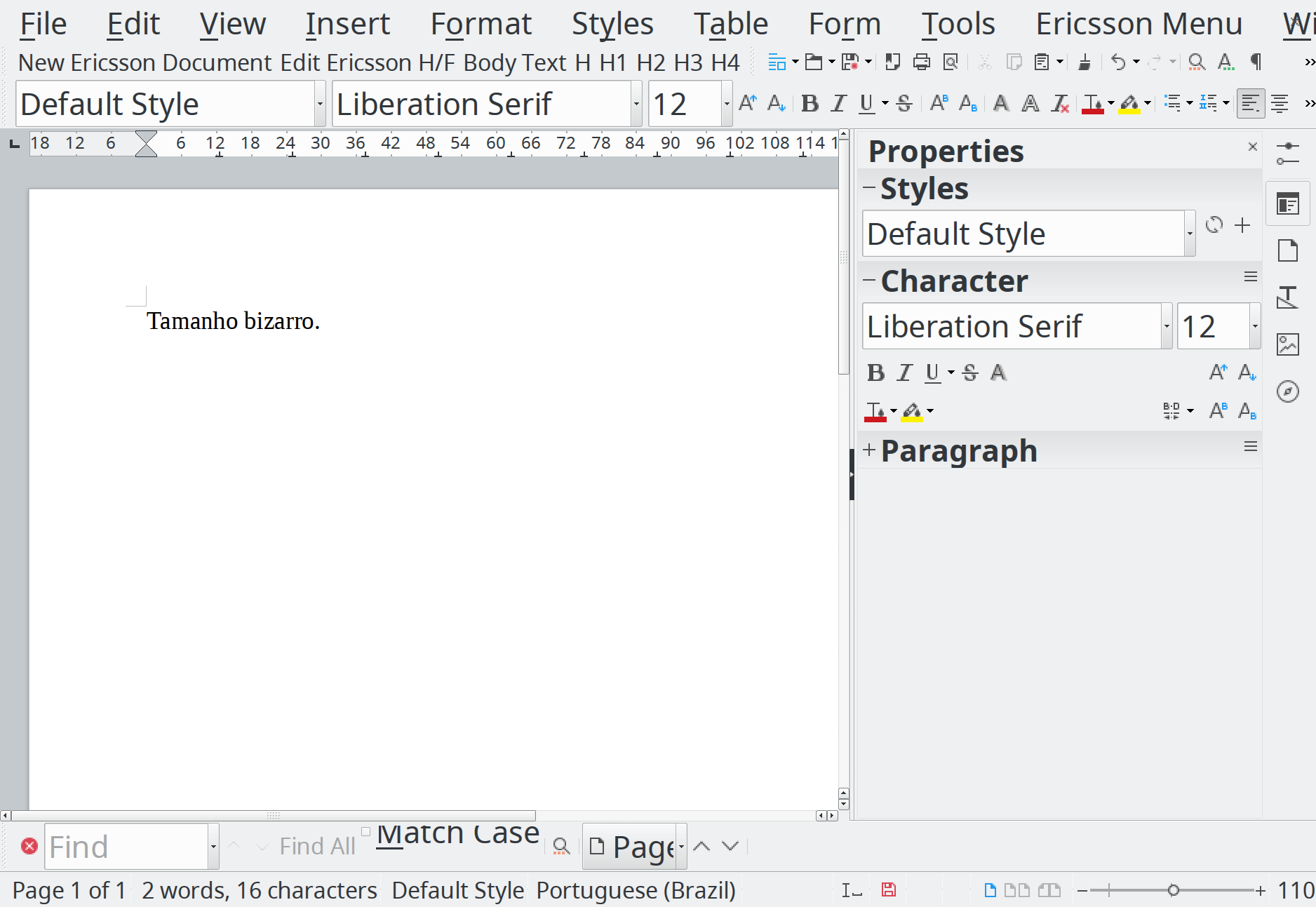
E pior que os aplicativos escritos em GTK não respeitam o tamanho de fonte colocado no KDE. Uma das maneiras que encontrei foi usando comandos diretamente vi gsettings pra verificar o que os aplicativos em GTK têm configurados:
helio@xps13:~$ gsettings get org.gnome.desktop.interface text-scaling-factor helio@xps13:~$ gsettings get org.gnome.desktop.interface monospace-font-name helio@xps13:~$ gsettings get org.gnome.desktop.interface document-font-name helio@xps13:~$ gsettings get org.gnome.desktop.interface font-name helio@xps13:~$ gsettings get org.gnome.desktop.wm.preferences titlebar-font
e depois trocar pra padrões mais confortáveis.
helio@xps13:~$ gsettings set org.gnome.desktop.interface text-scaling-factor 0.5 helio@xps13:~$ gsettings set org.gnome.desktop.interface monospace-font-name 'Ubuntu Mono 10' helio@xps13:~$ gsettings set org.gnome.desktop.interface document-font-name 'Ubuntu 10' helio@xps13:~$ gsettings set org.gnome.desktop.interface font-name 'Ubuntu 10' helio@xps13:~$ gsettings set org.gnome.desktop.wm.preferences titlebar-font 'Ubuntu Bold 10'
E às vezes ainda preciso forçar um re-cache das fontes usadas com o comando:
helio@xps13:~$ sudo fc-cache -f -v
mas o resultado final é satisfatório (em geral basta fechar e abrir os programas pra encontrar a interface com as fontes corrigidas).
Quem tem filho sabe que não é fácil impor limites. Especialmente quanto uso de tablets ou smartphones ou até mesmo da TV. Eu tenho em casa um problema com YouTube que acaba virando a atração principal com um conteúdo bem longe de ser didático. Tentei até onde podia limitar no "YouTube é das 18 às 20" mas tenho fracassado miseravelmente.
Então resolvi apelar aos meus conhecimento computacionais e ao roteador por onde passa todo o tráfego da casa, e que roda open-wrt.
Criei um sistema básico em shell script que bloqueia tudo que é relacionado com YouTube em horários pré-determinados. Não ficou bonito, mas funciona.
#! /bin/sh
# save it into /usr/lib/scripts/firewall.sh
# and add into scheduled tasks as
# */5 * * * * /usr/lib/scripts/firewall.sh
hour=`date +%H`
minute=`date +%M`
echo "hour=$hour"
echo "minute=$minute"
status_file=/tmp/firewall_status
blocked_pattern="youtubei.googleapis.com googlevideo.com ytimg-edge-static.l.google.com i.ytimg.com youtube-ui.l.google.com www.youtube.com googleapis.l.google.com youtubei.googleapis.com video-stats.l.google.com ytimg-edge-static.l.google.com"
enable_firewall() {
echo "Enabling firewall"
for chain in INPUT FORWARD OUTPUT
do
count=1
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
count=`expr $count + 1`
done
done
echo iptables -I $chain $count -p udp --sport 443 -j DROP
iptables -I $chain $count -p udp --sport 443 -j DROP
count=`expr $count + 1`
echo iptables -I $chain $count -p udp --dport 443 -j DROP
iptables -I $chain $count -p udp --dport 443 -j DROP
count=`expr $count + 1`
done
}
disable_firewall() {
echo "Disabling firewall"
for chain in INPUT FORWARD OUTPUT
do
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
done
done
echo iptables -D $chain -p udp --sport 443 -j DROP
iptables -D $chain -p udp --sport 443 -j DROP
echo iptables -D $chain -p udp --dport 443 -j DROP
iptables -D $chain -p udp --dport 443 -j DROP
done
}
case $1 in
start) enable_firewall
echo -n "enabled" > $status_file
exit 0;;
stop) disable_firewall
echo -n "disabled" > $status_file
exit 0;;
esac
# possible status
# enabled|disabled
# start
# from 7:55-09:59
time_status=disabled
if [[ $hour -ge 7 && $hour -lt 10 ]]; then
time_status=enabled
if [[ $hour -eq 7 ]]; then
if [[ $minute -lt 55 ]]; then
time_status=disabled
else
time_status=enabled
fi
fi
fi
# from 12:00-17:59
if [[ $hour -ge 12 && $hour -lt 18 ]]; then
time_status=enabled
fi
# from 20:00-21:59
if [[ $hour -ge 20 && $hour -lt 22 ]]; then
time_status=enabled
fi
echo "time_status=$time_status"
current_status=
if [[ -f "$status_file" ]]; then
current_status=`cat $status_file`
fi
if [[ $current_status = $time_status ]]; then
echo "nothing to do"
else
if [[ $time_status = "enabled" ]];then
echo "loading firewall rules"
enable_firewall
fi
if [[ $time_status = "disabled" ]];then
echo "removing firewall rules"
disable_firewall
fi
echo -n $time_status > $status_file
fi
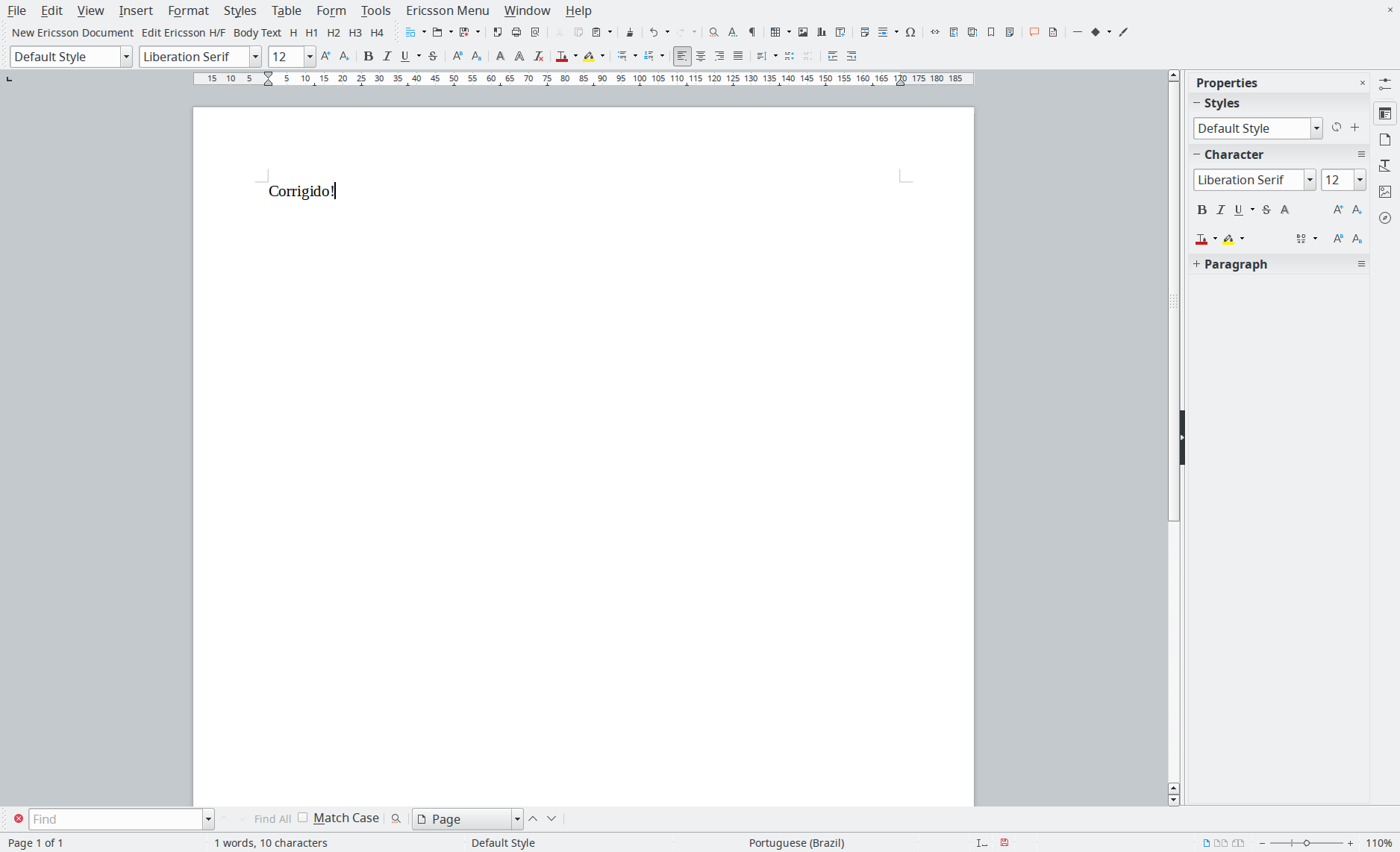
Basta salvar o arquivo em /usr/lib/scripts/firewall.sh e adicionar à crontab do open-wrt.
O código fonte está também publicado no github: https://github.com/helioloureiro/homemadescripts/blob/master/openwrt-firewall-block-youtube.sh
Toda história tem um começo, meio e fim. E esse momento chegou pro encurtador que criei em 14 de novembro de 2010. Inspirado no miud.in criado pelo Eduardo Maçan e baseado no yourls.org, criei o encurtador pra desafiar o "status quo" da empresa e mostrar que as coisas podiam funcionar de forma fácil e simples. A vida do encurtador foi legal com vários pontos altos mas ultimamente pude ver que eu era o único usuário costumaz do sistema. De resto eram só SPAMs e mais SPAMs. E custo.
O verdadeiro matador do encurtador foi custo. De algo em torno de 10 dólares em 2010, o custo bateu 70 dólares agora pra renovar. Alto demais pro pouco uso. Então decidi juntar o eri.cx ao panteão dos heróis e mitos da Internet e encerrar seu uso.
Foi divertido enquanto durou.
Mas tem um outro lado positivo. Registrei outro domínio dentro do .br com valor muuuuuito mais acessível: http://hl.eng.br
É basicamente o eri.cx só que com outro domínio. Então todas os links encurtados do passado funcionarão no novo. E com um adicional: CAPTCHA! Sim, menos SPAMs e mais links encurtados. E que dure 8 anos do eri.cx ou até mais. Longa vida ao http://hl.eng.br !

25 anos de alegrias e tristezas. Felizmente mais alegrias :)
Desses 25 anos, estamos juntos 20 anos. Acho. Talvez mais.

O herói de antigamente, quando eu comecei com Linux e BSD, era o sysadmin. Um lobo solitário que cuidava de um ou mais servidores com vários scripts de automação.
Essa figura desapareceu e cedeu lugar à padronização e máquinas virtuais. E as máquinas virtuais estão cada vez mais dando lugar aos containers.
Então a "arte" de fazer scripts está praticamente morrendo com poucos sysadmins ainda estudando perl, python, awk, etc. Mas mesmo na criação de containers é possível colocar scripts em prática e de forma proveitosa. Seriam o sysadmins 3.0.
Nesse sentido precisei criar um container pra rodar alguns programas em Java. Criei o container baseado no Ubuntu 16.04, que é a versão que tenho no laptop de trabalho e com Maven e Java. Maven é uma ferramenta de construção de Java parecida com pip no Python, CPAN no Perl, npm no node.js e rebar3 no Erlang. Ele baixa as dependências nas versões desejadas e compila tudo pra gerar seu arquivo jar. E também pode ser usado pra criar regras como de unittest.
Mas minha razão pra escrever esse post não é o Maven, que tem muitos outros artigos específicos muito bem escritos. É sobre o Java. Eu preciso rodar os meus programas com o JDK da Oracle. E como automatizar? Esse é o ponto dos scripts que comentei acima e razão desse artigo, de como usar ainda hoje em dia. Como o download do JDK da Oracle exige aceitação dos termos de uso, é preciso fazer isso dentro do script (através de cookies). O resto, é container puro.
O arquivo Dockerfile que criei é esse aqui:
FROM ubuntu:16latest
ENV container docker
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get install -y \
build-essential \
lsb-release \
tar \
wget \
unzip \
sudo \
git \
curl \
createrepo \
java-package \
fakeroot \
maven
RUN apt-get install -y \
libgtk-3-0 \
libcairo-gobject2
RUN JAVA_URL=$(curl -sS http://www.oracle.com/technetwork/java/javase/downloads/index.html | \
grep -i href | \
grep "Download JDK" | \
head -1 | \
tr " " "\n" | \
grep href | \
sed "s|.*href=\"\([^\"].*[^\"]\)\".*|\1|" ); \
JDK_URL=$(curl -sS http://www.oracle.com$JAVA_URL | \
grep -i "^downloads.*linux.*tar.gz.*" | \
tr " ," "\n" | \
grep http | \
sed "s/.*\(http\)/\1/;s/\"//g" ); \
curl \
-SLkO \
--header "Cookie: oraclelicense=accept-securebackup-cookie" \
-# \
$JDK_URL ; \
linux_java=$(basename $JDK_URL) ; \
version=$(echo $linux_java | sed "s/.*-\([0-9][^_]*\)_.*/\1/" | cut -d "." -f 1) ; \
new_name=jdk-${version}-linux-x64.tar.gz ; \
deb_name=oracle-java${version}-jdk_${version}_amd64.deb; \
mv $linux_java /home/$new_name
# uid=2000(jenkins) gid=2000(jenkins) groups=2000(jenkins),999(ssh-allowed),130(libvirtd),131(kvm),998(docker)
RUN groupadd -g 2000 jenkins
RUN useradd -g 2000 -u 2000 -m jenkins
RUN su - jenkins -c "yes Y | fakeroot make-jpkg /home/jdk-*-linux-x64.tar.gz"
RUN dpkg -i /home/jenkins/oracle-java*deb
RUN JAVA_HOME=$(update-java-alternatives -l | grep oracle | tail -1 | awk '{print $NF}') ; \
JAVA_VERSION=$(update-java-alternatives -l | grep oracle | tail -1 | awk '{print $1}') ; \
cd $JAVA_HOME; \
ln -s jre .; \
update-java-alternatives -s $JAVA_VERSION; \
update-alternatives --install /usr/bin/java java $JAVA_HOME/bin/java 1; \
update-alternatives --set java $JAVA_HOME/bin/java
Eu tenho um outro container chamado ubuntu:16latest que é um Ubuntu 16.04 com apt dist-upgrade pra ter a versão mais recente. Eu geralmente adiciono o usuários jenkins pra poder rodar os containers dentro do jenkins.
Uma vez feita a configuração, basta construir o container. Como tenho vários arquivos pra fazer essas construções, eu geralmente salvo como Dockerfile.<distro>_<aplicativo>. Nesse caso específico salvei num arquivo Dockerfile.ubuntu_java. Para construir o container então:
docker build -t ubuntu:java -f Dockerfile.ubuntu_java .
Feito o container e salvo com a tag ubuntu:java, basta somente chamar o container pra rodar seus programas em java ou compilar.
helio@linux:~/DockerBuilds$ docker run -it ubuntu:java java -version java version "10.0.1" 2018-04-17 Java(TM) SE Runtime Environment 18.3 (build 10.0.1+10) Java HotSpot(TM) 64-Bit Server VM 18.3 (build 10.0.1+10, mixed mode)
Daí pra frente é usar o Java como se estivesse instalado localmente.
Fontes:
1. https://wiki.debian.org/JavaPackage
2. https://www.debian.org/doc/manuals/debian-java-faq/ch5.html

Tive a oportunidade de participar de um curso profissional de containers oferecido dentro da empresa. Já tive oportunidade de participar de outro curso ministrado pela mesma escola sobre OpenStack numa outra vez. Material de primeira, laboratório completo e explicações concisas. Resolvi escrever um pouco pra quem busca algo nesse sentido pra saber se realmente vale a pena.
Meu conhecimento anterior de Dockers veio todo de documentos gerados por comunidade de usuários e pelo próprio site do Docker. Eu já uso Docker faz alguns anos e com bastante desenvoltura. Muita coisa que preciso fazer já é em containers. Durante o curso percebi que realmente não tinha muita novidade. O uso básico de docker com "run", "images", "tag", etc é exatamente o mesmo.
Uma diferença notável que eu não conhecia foi a referência quanto à OCI, Open Container Iniciative, que tem agora um binário "runc" que substituirá o comando "docker" pra criar uma abstração genérica no manuseio de containers. Os argumentos são exatamente os mesmo que do "docker". Então um "docker run -it ubuntu:latest bash" funciona com um "runc run -it ubuntu:latest bash". Parte disso é pra facilitar o uso com kubernetes.
Agora sobre kubernetes, eu não conhecia tão a fundo. Sempre usei um básico do básico do básico com minikube na maioria das vezes. Já tinha mexido com Jagger pra alguma monitoração de tempo em containers, mas nada como vi no curso. O laboratório funcionando perfeitamente e com vários exercícios. Mas várias vezes consultamos a documentação online do kubernetes, ou seja, a documentação já disponível é riquíssima. Mesmo em alguns pontos o material didático estava bem atrás dos comandos disponíveis no último release de kubernetes.
E o material do curso? Sinto mas é um material copyrighted que não pode ser distribuído. E deixaram isso bem claro. Mas eu pessoalmente acho que a documentação com tutoriais disponíveis cobrem muito bem tudo que estava descrito ali.
Vale então fazer um curso pago de containers? Eu diria que depende. Se tem tempo, é possível aprender tudo sozinho em seu próprio computador. Mas se tiver uma necessidade mais imediata de resultados, sim cursos serão um bom acelerador nessa direção.
Qualquer que seja sua decisão, keep calm and runc -it run.

Escrevi um artigo pro blog "ChurrOps on DevOps" sobre raspresenterpy aṕos uma conversa sobre o assunto no canal do Telegram do grupo "papo de sysadmin".
Eu achava que já tinha escrito sobre isso aqui mesmo, mas fiquei surpreso por não ter encontrado nenhuma referência.
raspresenterpy é um programa de display que alterna links pra ser usado pra mostrar mensagens ou telas de monitoramento como do Jenkins. Fiz até uma apresentação sobre o mesmo numa PyConSE. O texto que escrevi detalha sobre repositório e como usar o mesmo.
Ele encontra-se com suporte ao raspbian Jessie e python-qt4. Testei com python-qt5 e já verifiquei que não funciona. Então deixei no meu backlog pra corrigir e lançar uma versão mais recente.
https://churrops.io/2018/06/08/usando-python-e-raspberrypi-pra-mostrar-varias-telas/

Feliz dia da toalha (ou dia do orgulho nerd). Pegue sua toalha e... não entre em pânico.


Já teve problemas com a barra de rolagens (ou scrolls)? Não? Pois eu tive por muito tempo.
Como uso KDE, aplicativos baseados em GTK teimam em ignorar os padrões que seleciono e fazem as coisas da forma que querem. Talvez por isso eu não use Gnome.
Mas esse problema vem me atormentando desde que foi lançado o GTK3. Faz o quê? Uns 5 anos? As teclas de rolagem estavam com um padrão de que apareciam somente quando o mouse passava por cima. Irritante. Não sei quem teve essa ideia, mas eu nunca gostei. Só que não conseguia mudar. E eu não dei muita importância ao fato já que no fim conseguia fazer o que precisava e isso era algo pequeno.
E hoje finalmente eu cheguei no ponto de me incomodar e procurar um solução, pois no inkscape é onde esse treco incomoda mais. Os botões de rolagem ficam se sobrepondo entre o da imagem e da paleta de cores. Às vezes queria mover, fazia no outro.

E até que não foi algo tão complicado quanto eu esperava. Como já imaginava, era algo configurável via interface gráfica no caso de estar usando Gnome ou Unity. Mas pra quem não os têm, via linha de comando basta usar o seguinte:
gsettings set com.canonical.desktop.interface scrollbar-mode normal
Não gostou e quer voltar ao padrão antigo (por mais que eu não entenda esse tipo de decisão)?
gsettings set com.canonical.desktop.interface scrollbar-mode overlay-auto
É bem simples. Sofri à toa por besteira.

Esses dias estava analisando um código que era parecido com shell script. Sua função era monitorar as interfaces de rede para, no caso de alteração (nova interface surgindo ou desaparecendo), registrar a mudança de objetos no sistema de dados do opensaf (objetos no IMM pra quem conhece).
Mas o código fazia algo parecido com um shell que a todo healthcheck do AMF (framework do opensaf que é muito semelhante ao systemd e roda determinado programa ou script de tempos em tempos) fazia uma busca com o comando "ip link addr list" e comparava com o que estava armazenado no IMM. Algo como:
def healthcheckCallback(self, invocation, compName, healthcheckKey): saAmfResponse(self.check_macs, invocation, eSaAisErrorT.SA_AIS_OK)
def check_macs(self):
macs = []
for line in self.get_link_list().split("\n"):
if not re.search("link/ether", line): continue
# [ 'link/ether', '52:54:00:c3:5d:88', 'brd', 'ff:ff:ff:ff:ff:ff']
mac.append(line.split()[1])
imm_obj = self.get_from_imm()
if imm_obj != macs:
self.update_imm(mac)
def get_link_list(self):
linux_command = "ip link list"
return self.run_shell(linux_command)
Essa é uma forma bastante simplificada pra tentar visualizar como tudo funciona. Eu propositalmente tirei comentários extras e deixei mais limpo apenas para poder comentar aqui.
Como a chamada pra buscar os dados junto ao IMM no OpenSAF tem muitas linhas, eu só deixei um get_from_imm() que retornará um array de mac registrados anteriormente. Se esse valor for diferente do coletado, então é chamado o método update_imm() com os macs que devem estar lá.
Funciona? Sim, funciona. Mas... se não houve nenhuma mudança nas interfaces de rede (como a subida de uma interface de VIP ou mesmo um container em docker), por quê eu preciso rodar o get_link_list()?
Entendeu qual foi meu ponto?
O código em si consiste em rodar o monitoramente separado numa thread. Toda vez que o código detecta uma mudança (na verdade o kernel sinaliza isso), ele altera uma variável que o programa lê durante o healthcheck. Algo como:
def check_macs(self):
if self.network_changed is False: return
Assim bem simples. Teve mudança? network_changed vira um True.
Linux tem mecanismos pra detectar uma mudanças na interfaces de rede. Por quê não usar? E foi o que fiz.
Criei um método chamado monitor_link() que é iniciado junto com programa no método initialize(), que é parte de como o AMF faz as chamadas de callback:
self.thread = threading.Thread(target=self.monitor_link, args=())
self.thread.start()
E como funciona o monitor_link()? Aqui tenho de pedir desculpas antecipadamente que enquanto o código utiliza menos CPU e memória que chamar um shell script, o tamanho e complexidade é bastante grande. No fim troquei 2 linhas de código por umas 35 linhas. Na verdade eu praticamente escrevi o código por trás do "ip link". Mas o resultado ficou independente desse comando e mesmo de utilizar um shell externo pra buscar o resultado.
A primeira coisa é criar um socket do tipo AF_NETLINK. Em seguida fazer um bind() num ID aleatório e monitorar com RTMGRP_LINK.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
pra gerar o código aleatório que é um inteiro, usei os.getpid() pra usar o PID do próprio programa.
Em seguida é iniciado um loop com select() em cima do descritor do socket pra leitura. Quando aparecer algum dado, daí sim a informação é lida.
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
O que vem a seguir são quebras da sequência de bits até chegar no ponto é possível ver o tipo de mensagem que chegou do select(). Se o tipo de mensagem for NOOP de algo nulo, apenas continue monitorando no select(). Se vier algum ERROR, pare o programa. Se vier mensagem e não for do tipo NEWLINK pra um link novo ou mudança de MAC, também continue aguardando no select().
if msg_type == NLMSG_NOOP: continue elif msg_type == NLMSG_ERROR: break elif msg_type != RTM_NEWLINK: continue
Por fim uma iteração nos dados pra buscar o tipo. Se o dado for do tipo IFLA_IFNAME, que é uma nova interface ou mudança de nome, ou IFLA_ADDRESS, que é MAC e endereço IP, muda a flag de network_changed pra True.
rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
E é isso. O código completo segue abaixo.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
while self.terminating is False:
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
if self.network_changed is True: continue
if self.terminating is True: return
try:
data = os.read(rlist[0], 65535)
except:
continue
msg_len, msg_type, flags, seq, pid = struct.unpack("=LHHLL", data[:16])
if msg_type == NLMSG_NOOP: continue
elif msg_type == NLMSG_ERROR: break
elif msg_type != RTM_NEWLINK: continue
data = data[16:]
family, _, if_type, index, flags, change = struct.unpack("=BBHiII", data[:16])
remaining = msg_len - 32
data = data[16:]
while remaining:
rta_len, rta_type = struct.unpack("=HH", data[:4])
if rta_len < 4: break
rta_data = data[4:rta_len]
increment = (rta_len + 4 - 1) & ~(4 - 1)
data = data[increment:]
remaining -= increment
if rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
self.network_changed = True
Encontrei essa implementação no Stack Overflow buscando informação do código em C. Foi uma grande ajuda e deixou meu programa muito mais coerente com o que eu realmente queria.
Ficou muito maior? Ficou. Mas também ficou muito mais 1337 :)
Mais:
[1] Exemplo de uso de python com AMF no OpenSAF: https://sourceforge.net/p/opensaf/staging/ci/default/tree/python/samples/amf_demo
[2] Projeto OpenSAF: https://sourceforge.net/projects/opensaf/
[3] Implementação original desse código: https://stackoverflow.com/questions/44299342/netlink-interface-listener-in-python
Tenho escrito pouco aqui, e já passei do prazo de fazer uma retrospectiva de 2017. Mas antes tarde do que nunca.
Ao invés de escrever, resolvi aderir ao momento multimídia do mundo e fazer em vídeo. O primeiro é um vídeo de fotos e vídeos meus que peguei direto no Google, no storage onde estão conectados meu smartphone e meu tablet.
O segundo é da coleção de snapshots que o raspberrypi tira a cada 15 minutos da janela de casa. Dá pra ver que no começo e no fim fica bem escuro, enquanto que no meio é mais claro (dias mais curtos no inverno e mais longos no verão).
Page 14 of 36
