A controvérsia quanto à nomenclatura GNU/Linux é uma disputa entre membros da comunidade de software livre e código aberto. É centrada em torno da denominação do núcleo de sistema chamado "Linux", e a vontade de utilizar esta nomenclatura como um termo genérico para tudo relacionado ao mesmo. O termo defendido pela Free Software Foundation (FSF), para relacionar o núcleo do sistema com as ferramentas desenvolvidas pela fundação GNU seria GNU/Linux, ficando o nome "Linux" para ser utilizado apenas quando se referindo ao núcleo Linux. O nome é por vezes pronunciado como "GNU com Linux".
https://pt.wikipedia.org/wiki/Controv%C3%A9rsia_quanto_%C3%A0_nomenclatura_GNU/Linux
Eu peguei esse trecho da wikipedia. Abrindo um pequeno comentário sobre o mesmo: a versão em português está bem diferente da versão em inglês e fica ao critério do leitor dar uma olhada em ambos e decidir qual está melhor. Voltando ao assunto, a guerra entre os termo Linux e GNU/Linux. A briga vem de longa data, basicamente quando Linux começou a crescer exponencialmente em popularidade e deixou o projeto GNU em sua sombra. O bom doutor, Richard Stallman, ficou famoso por suas longas interjeições sobre o assunto. E virou meme. Infinitos memes.
O sistema operacional era GNU no início, mas por conta do kernel na época não estar pronto, usaram Linux. Mas não imaginavam que a força de comunidade ao redor do Linux seria tão grande e tão marcante. Ao ponto do Linux ter sido somente um kernel no início, mas hoje ser uma fundação e com vários projetos abrigados, como o OpenTofu, Linux para setor automobilístico, CNCF (Cloud Native Computing Foundation), etc. Por simplicidade, muita gente chama o sistema operacional inteiro com Linux somente. E isso, claro, ganhou força por ser mais fácil e simples que dizer GNU/Linux ou GNU+Linux.
Dentro dessa discussão existe ainda o ponto que alguns levantam que dentro de um sistema operacional, geralmente aquilo que você usa de uma distro - distribuição de Linux, não depende só do GNU. Existem outros códigos, projetos e licenças ali. De MIT a Apache, de KDE a Gnome, e assim por diante. Então se fosse pra dar crédito a todos ali, deveria ser chamado MIT/Xorg/Apache/Git/GNU/Linux ou qualquer outra coisa tão bizarra ou até mais que isso.
Claro que grande parte das coisas ali não existiriam sem a contribuição do projeto GNU, principalmente com o GCC. Até mesmo os BSDs dependeram do GCC até a Apple botar dinheiro no llvm/clang - e por conta disso estavam todos parados no GCC 3.2 por causa da mudança pra licença GPLv3, então a Apple ajudou muito.
E existe ainda a discussão, bastante rasa, de alguns de que Linux não roda sem GNU. Isso já foi demonstrado tanto pelo Android que não é verdade. E agora existem tanto o Chimera Linux, sem absolutamente nada de GNU e usando algumas ferramentas escritas em rust, quanto o Alpine Linux, feito pra containers.
Mas o ponto que eu queria abordar aqui, pois essa discussão já existe faz décadas e nada mudou muito, foi um artigo que peguei no site do GNU. Eu particularmente achei maravilhoso.
https://www.gnu.org/distros/common-distros.en.html
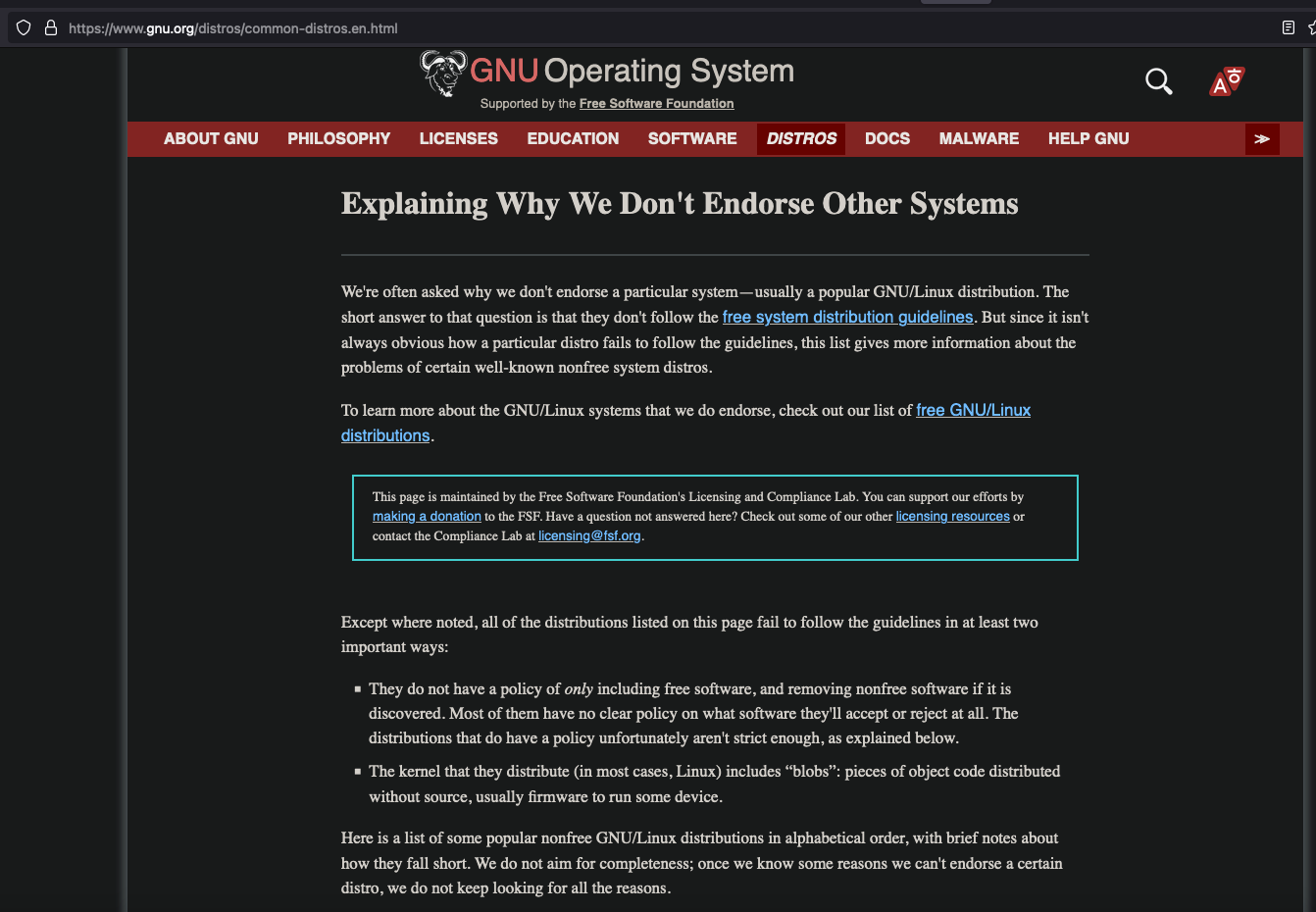
tl;dr: basicamente o que está escrito é que o projeto GNU não endossa as distribuições porque pra isso não pode distribuir nada que não seja software livre. Então quem usa firmwares binários, os blobs, não é endossado como GNU. Nem quem permite instalação de software proprietário. Sim, quem permite. Pois o OpenBSD não carrega firmwares binários por questões de segurança. Nem contém softwares proprietários no sistema operacional. Mas o sistema de ports, que são scripts e Makefiles de contribuidores e de usuários, esse instala softwares não livres. E isso é o suficiente pra GNU não endossar como... um sistema GNU??? Apesar da hipocrisia, acho que não seria o caso de nomear o OpenBSD como GNU de qualquer forma.
Mas o interessante é que ela acaba com a discussão. Se contém firmware ou é possível instalar software proprietários (steam, google chrome, etc) então não é GNU. Muito bem. Então nem é mais preciso a discussão sobre o nome. O nome é Linux e pronto :)
Interessante que referem-se às distros como GNU/Linux, como no caso do Arch GNU/Linux, enquanto o próprio Arch está como Arch Linux.
Pra terminar, deixo aqui vocês com os melhores memes desse tema.

















Se você nunca ouviu falar de DoH além do Homer reclamando que fez alguma bobagem, então não está na Internet tempo o suficiente. E talvez não esteja protegendo sua privacidade como poderia.
DNS, de Domain Name Service (serviço de nomes de domíno), é o que traduz um nome de domínio como helio.loureiro.eng.br pra um endereço IP. No caso de helio.loureiro.eng.br o nome é resolvido tanto pra IPv4 quanto pra IPv6.
Por mais inocente que seja essa tradução, esse dado não tem criptografia ou qualquer outro tipo de proteção. Pode e provavelmente é usado por seu provedor de Internet pra conhecer seus hábitos de navegação e até vender esse dado pra alguém.
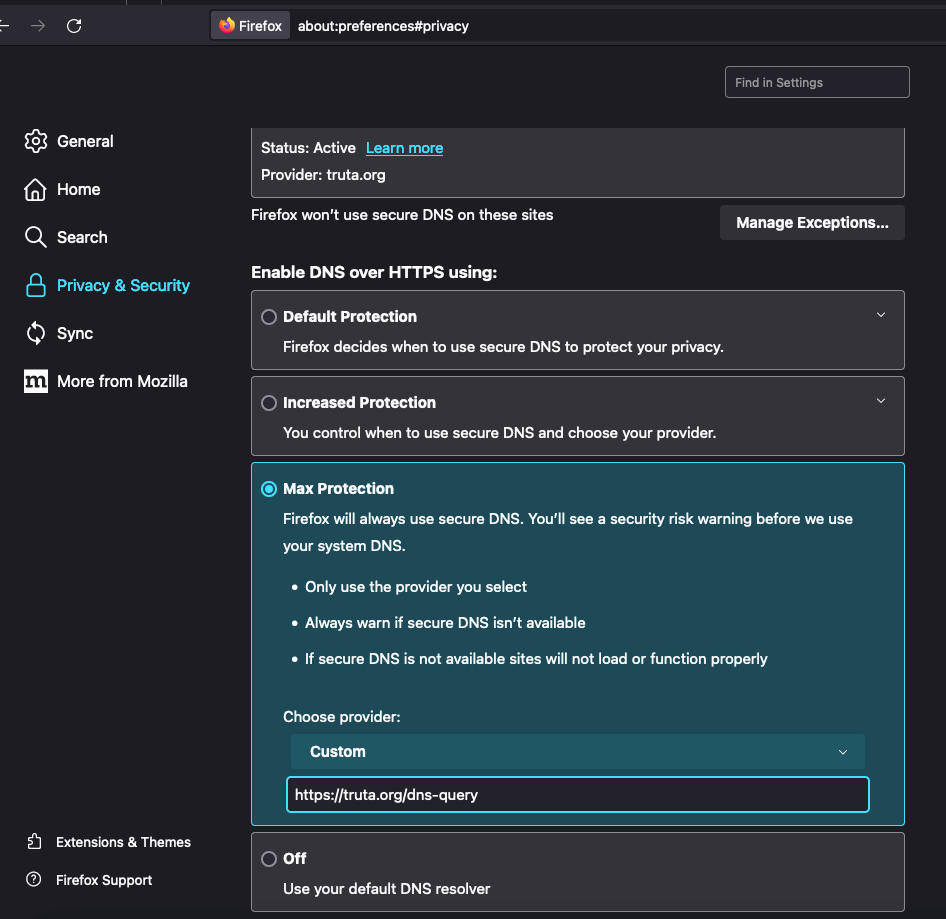
Pra coibir tal uso de sua informação pessoal foi criado o protocolo DoH, ou DNS over HTTPS, que é a requisição de DNS enviada por HTTPS. A vantagem desse método é que ninguém consegue diferenciar seu tráfego HTTPS como sendo uma requisição DNS ou acesso a uma página web, que é protegida por uma camada de SSL de criptografia. O firefox permite a configuração de forma bastante fácil.
Mas claro que em alguns lugares o acesso pode ser barrado pra dificultar seu acesso ao DoH e forçar o uso de um serviço de DNS local. Por padrão o firefox permite usar o serviço do Cloudflare ou do NextDNS. O que fazem alguns provedores é bloquear requisições pra esses destinos. Mesmo o serviço de DoH do OpenDNS é bloqueado.
Pra previnir isso eu habilitei um DoH relay que recebe as requisições e envia para https://doh.opendns.com/dns-query pra resolver. Então para usar o serviço, basta configurar como fiz acima no Firefox e usar o destino:
E claro que esse artigo não é só pra dizer que esse serviço está habilitado. É pra mostrar como montar o seu.
Eu usei o binário de um doh-relay escrito em Go e disponível no github aqui:
https://github.com/tinkernels/doh-relay
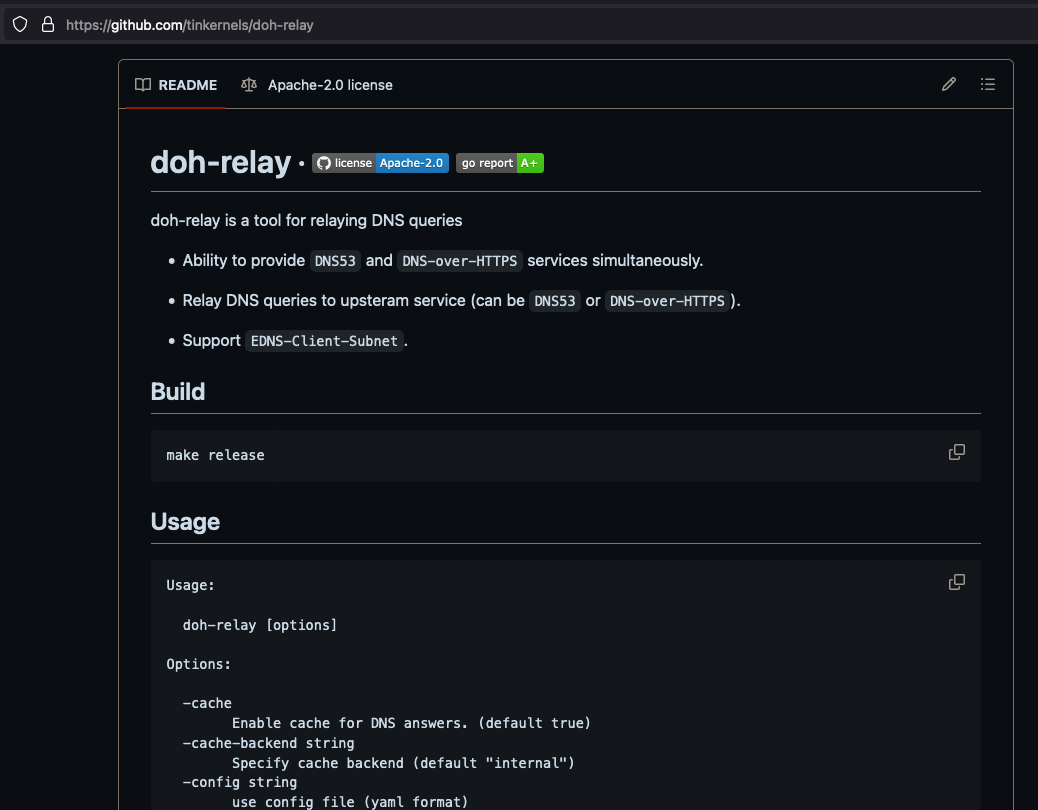
A compilação foi um simples comando, assumindo que tenha o Go pra fazer a compilação:
macOS in ~
✦ ❯ cd /tmp
macOS in /tmp
✦ ❯ git clone https://github.com/tinkernels/doh-relay.git
Cloning into 'doh-relay'...
remote: Enumerating objects: 461, done.
remote: Counting objects: 100% (192/192), done.
remote: Compressing objects: 100% (136/136), done.
remote: Total 461 (delta 127), reused 117 (delta 56), pack-reused 269
Receiving objects: 100% (461/461), 180.87 KiB | 3.17 MiB/s, done.
Resolving deltas: 100% (307/307), done.
macOS in /tmp
✦ ❯ cd doh-relay
macOS in doh-relay on master via 🐹 v1.22.0
✦ ❯ make linux-amd64
mkdir -p release
GOOS=linux GOARCH=amd64 go build -ldflags "-extldflags=-static -w -s" -o release/doh-relay_linux-amd64 .
go: downloading github.com/ReneKroon/ttlcache v1.7.0
go: downloading github.com/miekg/dns v1.1.54
go: downloading github.com/buraksezer/connpool v0.6.0
go: downloading github.com/gin-gonic/gin v1.9.0
go: downloading github.com/oschwald/geoip2-golang v1.8.0
go: downloading github.com/sirupsen/logrus v1.9.1
go: downloading gopkg.in/yaml.v3 v3.0.1
go: downloading golang.org/x/sys v0.8.0
go: downloading golang.org/x/net v0.10.0
go: downloading github.com/gin-contrib/sse v0.1.0
go: downloading github.com/mattn/go-isatty v0.0.18
go: downloading github.com/go-playground/validator/v10 v10.13.0
go: downloading github.com/ugorji/go/codec v1.2.11
go: downloading github.com/pelletier/go-toml/v2 v2.0.7
go: downloading github.com/oschwald/maxminddb-golang v1.10.0
go: downloading github.com/leodido/go-urn v1.2.4
go: downloading golang.org/x/crypto v0.9.0
go: downloading github.com/go-playground/universal-translator v0.18.1
go: downloading golang.org/x/text v0.9.0
go: downloading github.com/go-playground/locales v0.14.1
macOS in doh-relay on master via 🐹 v1.22.0 took 9s
✦ ❯ mv release/doh-relay_linux-amd64 release/doh-relay
No servidor truta.org, copiei o binário pra /usr/local/bin. E criei grupo e usuário.
root@truta /u/l/bin# addgroup --system doh-relay
Adding group `doh-relay' (GID 135) ...
Done.
root@truta /u/l/bin# adduser --system --gid 135 doh-relay
Adding system user `doh-relay' (UID 129) ...
Adding new user `doh-relay' (UID 129) with group `doh-relay' ...
Not creating `/nonexistent'.
Em seguida adicionei um serviço ao systemd e habilitei.
root@truta /# cd /etc/systemd/system
root@truta /e/s/system# vim doh-relay.service
root@truta /e/s/system# cat doh-relay.service
[Unit]
Description=Dns-over-HTTPS relay
After=syslog.target network.target
[Service]
User=doh-relay
Group=doh-relay
WorkingDirectory=/tmp
ExecStart=/usr/local/bin/doh-relay --cache=true --doh -doh-upstream=https://doh.opendns.com/dns-query
Type=simple
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
root@truta /e/s/system# systemctl daemon-reload
root@truta /e/s/system# systemctl enable --now doh-relay.service
Created symlink /etc/systemd/system/default.target.wants/doh-relay.service → /etc/systemd/system/doh-relay.service.
root@truta /e/s/system# systemctl status doh-relay
● doh-relay.service - Dns-over-HTTPS relay
Loaded: loaded (/etc/systemd/system/doh-relay.service; enabled; preset: enabled)
Active: active (running) since Thu 2024-03-07 09:47:09 -03; 5s ago
Main PID: 819347 (doh-relay)
Tasks: 6 (limit: 3535)
Memory: 4.0M
CPU: 15ms
CGroup: /system.slice/doh-relay.service
└─819347 /usr/local/bin/doh-relay --cache=true --doh -doh-upstream=https://doh.opendns.com/dns-query
Mar 07 09:47:09 truta.org systemd[1]: Started doh-relay.service - Dns-over-HTTPS relay.
Mar 07 09:47:09 truta.org doh-relay[819347]: *** Starting ***
Mar 07 09:47:09 truta.org doh-relay[819347]: time="2024-03-07T09:47:09" level=info msg="open : no such file or directory" file="geoip.go:41"
Mar 07 09:47:09 truta.org doh-relay[819347]: time="2024-03-07T09:47:09" level=info msg="resolver: [https://doh.opendns.com/dns-query], fallback: []" file="main.go:339"
O último passo foi adicionar a configuração ao apache com proxy interno conectando com a porta 15353 onde roda o doh-relay.
root@truta /e/a/conf-enabled# cat /etc/apache2/conf-enabled/doh-enabled.conf
<IfModule mod_proxy.c>
ProxyVia On
ProxyRequests Off
ProxyPass /dns-query http://localhost:15353/dns-query retry=0 timeout=10
ProxyPassReverse /dns-query http://localhost:15353/dns-query
ProxyPreserveHost on
<Proxy *>
Options FollowSymLinks MultiViews
AllowOverride All
Order allow,deny
allow from all
</Proxy>
</IfModule>
root@truta /e/a/conf-enabled# a2enmod proxy
Module proxy already enabled
root@truta /e/a/conf-enabled# a2enmod proxy_html
Considering dependency proxy for proxy_html:
Module proxy already enabled
Considering dependency xml2enc for proxy_html:
Enabling module xml2enc.
Enabling module proxy_html.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# a2enmod proxy_http
Considering dependency proxy for proxy_http:
Module proxy already enabled
Enabling module proxy_http.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# a2enmod proxy_http2
Considering dependency proxy for proxy_http2:
Module proxy already enabled
Considering dependency http2 for proxy_http2:
Enabling module http2.
Enabling module proxy_http2.
To activate the new configuration, you need to run:
systemctl restart apache2
root@truta /e/a/conf-enabled# apachectl configtest
Syntax OK
root@truta /e/a/conf-enabled# apachectl restart
E pronto. Um relay de DoH pronto pra servir.
06-05-2025: deu algum ziriguidum no serviço e no momento não está funcionando. Se alguém, além de mim, usava pra alguma coisa, sinto muito. Atualizo aqui quando voltar.

Essa é uma dica pra quem, como eu, cria vários bots por aí. Se você quer dar uma carinha bonita pro perfil do bot, existe esse site que gera uma imagem pra você: https://robohash.org/
Eu gerei uma aqui pro site pra ter uma ideia.

Eu não lembro quem passou a dica disso. Mas nunca mais parei de usar. Nada como ter um rosto no seu robô preferido.
Pra quem acompanha o https://linux-br.org deve ter percebido que o ritmo de postagem caiu bastante. Na verdade despencou em comparação com o ano passado.
E não, não foi mais um bug que eu introduzi.
Ao contrário. Eu diria que fiz os artigos mostrados serem mais seletos. Primeiramente usando um filtro melhor de palavras de interesse. Descobri que meu filtro anterior tinha um erro no regex (sempre ele) e não funcionava como eu queria. Na verdade não fazia nada e passava qualquer tipo de artigo. Esse tipo de coisa de regex quando a gente faz errado...
Corrigido o problema de filtrar as palavras chaves, durate a refatoração do código eu resolvi só adotar artigos que tinha feito upload de uma imagem com sucesso. E isso já restringiu ainda mais o volume de postagens pra modestos 1 ou 2 por dia. Às vezes nem mesmo isso. E espero que esse efeito ajude a mais pessoas a participarem do site, algo que está longe de acontecer pelos números de acessos diários.
2024 já com força total :)
Recentemente tem circulado no Mastodon as mensagens do site https://crieaporradeum.blog/ que é um tradução do https://startafuckingblog.com/ e um incentivo um tanto passivo-agressivo pras pessoas criarem seus próprios sites. Como eu.
Não sei bem se usando uma linguagem assim consiga realmente incentivar as pessoas a fazerem isso, mas eu ao menos vi algumas respostas positivas. O que me faz pensar que talvez eu deva começar a usar o mesmo tipo de linguagem passivo-agressiva pra convencer as pessoas a fazerem algo.
Enquanto isso deixo aqui uma imagem com o mesmo estilo que fiz numa outra vida agora. Espero que também sirva de incentivo pra quem está lendo aqui a fazer... sei lá. Faça qualquer coisa com isso desde que seja algo positivo. Ao menos eu espero que seja positivo.

E façam a porra de um blog!
Foi o que pensei que ia acontecer. Infelizmente as coisas não saíram como esperado.
E claro que já resolvi o problema, que foi relacionado com php8.2-mysql, do contrário não estaria lendo esse artigo. Mas podia ter acontecido lá depois de julho...
Recebi essa semana um resumo do google maps sobre o tanto que pedalei no ano passado.
Eu tenho duas contas, uma genérica e outra desse domínio, e cada uma veio com uma distância diferente mesmo sendo a mesma pessoa com o mesmo telefone e aplicativos. Não sei explicar o motivo.
Mas o fato é que pedalei bastante ano passado. Algo próximo de 2000 Km. E com certeza acima de 1800 Km.
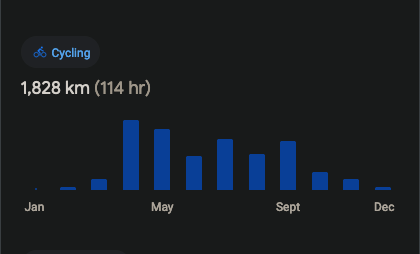
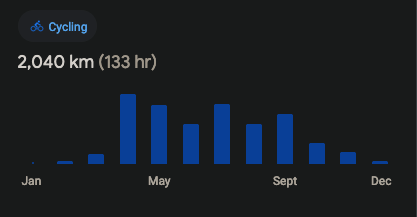
Só espero conseguir repetir o feito esse ano e talvez até passar dessa marca.

E novamente renovo meus votos de que o próximo ano será o ano do Linux no desktop. Já é líder em cloud, servidores, telefone, televisores e tudo mais que pensar. Até a Microsoft usa Linux com WSL. Então não existe motivo de não usar Linux no desktop também.
E eu realmente adoro voltar ao meu archlinux aqui e usar ctrl+c e ctrl+v ou ctrl+shift+c e ctrl+shift+v ao contrário do command+c e command+v do Apple. O hardware é legal, o sistema operacional é um belo BSD, mas a interface gráfica é pobre se comparada a um KDE por exemplo.
Então que venha 2024 e junto com o ano novo o Linux em todos os desktops.
Feliz ano novo!
Por algum motivo estranho e bizarro eu simplesmente parei de gerar os vídeos da passagem do ano capturada pela câmera do raspberry pi 3.
Então esse fim de ano resolvi colocar tudo em dia. Ainda falta de 2023, que farei após o início do ano, mas os anos anteriores estão aqui. E com buracos. Não foi todo ano que consegui capturar as imagens diariamente por uma série de razões. De memory card corrompido à libcamera quebrada. E nem sempre percebi isso rapidamente.
Mas estão aí as imagens pra quem quiser ver e ficar um pouco mais de 5 minutos admirando a passagem do tempo. Dica: é hipnotizante.

Resolvi dar aquele tapa de fim de ano no raspberry pi que tenho, versão 3 e talvez B mas não tenho certeza. E fiz upgrade pro Bookworm, último release do Debian.
O site não recomenda fazer isso e sim reinstalar o sistema operacional. Mas eu sempre tento o upgrade primeiro e guardo a opção de reinstalar pro último caso.
Acabei perdendo acesso ao wifi durante o upgrade e precisei tirar ele da janela e mexer aqui na mesa. Nada demais e aparentemente deu certo.
Aparentemente...
Toda vez que eu tentava algum comando que mandasse muitos dados como "dmesg" ou "journalctl -b -1", a conexão travava. E como fica ali na janela, sem cabo de rede perto, eu nunca soube se era problema do ssh ou do wifi ou que simplesmente travava. Apenas sabia que depois que travava eu não conseguia mais conectar.
Junto a isso as fotos da janela começaram a sair muito ruins. Com muita exposição.

No fim acabei botando de novo aqui na mesa e mexendo pra ver se acertava a parte do ssh.

Achei uma dica em "https://discourse.osmc.tv/t/solved-ssh-connection-sometimes-hangs/76504" pra alterar o "/etc/ssh/sshd_config" e adicionar as seguintes linhas:
IPQoS cs0 cs0
E reiniciando o sshd. Realmente deu certo. A conexão passou a ficar estável. O segredo foi mudar o ToS pra best effort com cs0.
Eu também mudei o /etc/rc.local pra rodar e deixar o wifi sem power management e evitar qualquer problema de conexão que esse pudesse causar.
iwconfig wlan0 power off
A parte da câmera eu não consegui acertar aqui na mesa. Simplesmente não consegui abrir o programa gráfico pra isso. No fim fiz ajustes no programa que uso com rpicam-still, que parece ser o novo programa pra usar.
Eu ainda não olhei como ficou a exposição da manhã, mas a de noite está bacana.

E no fim arrumei com o parâmetro "--shutter".
Quem quiser olhar ou re-usar o script, está aqui no github:

Eu tenho postado pouco aqui. Mea culpa. Totalmente.
Mas é porque tenho trabalhado bastante em outras coisas. Uma delas é no https://linux-br.org, our melhor, em sua automação.
Hoje eu estava olhando a quantidade de posts no site. É um histórico bastante interessante.
2018 Abril: 12
2018 Maio: 42
2018 Junho: 33
2018 Julho: 19
2018 Agosto: 16
2018 Setembro: 18
2018 Outubro: 21
2018 Novembro: 8
2018 Dezembro: 2
2019 Janeiro: 0
2019 Fevereiro: 2
2019 Março: 1
2019 Abril: 1
2019 Maio: 0
2019 Junho: 0
2019 Julho: 0
2019 Agosto: 0
2019 Setembro: 0
2019 Outubro: 0
2019 Novembro: 0
2019 Dezembro: 0
2020 Janeiro: 14
2020 Fevereiro: 4
2020 Março: 0
2020 Abril: 6
2020 Maio: 0
2020 Junho: 1
2020 Julho: 0
2020 Agosto: 1
2020 Setembro: 1
2020 Outubro: 2
2020 Novembro: 0
2020 Dezembro: 0
2021 Janeiro: 0
2021 Fevereiro: 0
2021 Março: 0
2021 Abril: 1
2021 Maio: 0
2021 Junho: 0
2021 Julho: 0
2021 Agosto: 0
2021 Setembro: 0
2021 Outubro: 0
2021 Novembro: 0
2021 Dezembro: 0
2022 Janeiro: 1
2022 Fevereiro: 0
2022 Março: 0
2022 Abril: 1
2022 Maio: 0
2022 Junho: 1
2022 Julho: 0
2022 Agosto: 0
2022 Setembro: 0
2022 Outubro: 0
2022 Novembro: 1
2022 Dezembro: 0
2023 Janeiro: 1
2023 Fevereiro: 0
2023 Março: 0
2023 Abril: 1073
2023 Maio: 718
2023 Junho: 462
2023 Julho: 893
2023 Agosto: 832
2023 Setembro: 799
2023 Outubro: 202
2023 Novembro: 834
2023 Dezembro: 286
O site começou cheio de gás e contribuidores. Depois passou por momentos de abandono até que entram os posts automatizados. E pula de 0 pra mais de 1000 artigos. A média tem sido por volta de 800 e é possível ver quando houve algum problema, como no mês de outubro desse ano quando o upgrade do Debian quebrou parte dos pacotes Python usados.
Apesar do maior número posts, isso não contribuiu muito pra maior audiência do site. Ele continua com pouco ou nenhum acesso.
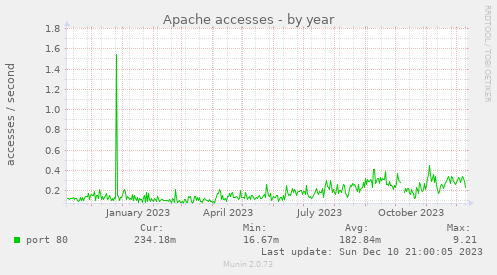
Esse dado de acesso ao servidor web não é só pro linux-br, é pra esse site aqui e mais alguns outros hospedados na mesma VPS.
Bom... ao menos temos um site de notícias funcionando. Quem sabe o restante virá com o tempo?

Estava ouvindo o último episódio do podcast dos programadores, o mesmo que já comentei em aprendendo a programar através de desafios com o site osprogramadores, e o entrevistado comentou sobre já ter visitados 11 países. Eu nunca tinha pensado no assunto, mas também passei dos 10 países que já visitei.
Claro que não passei muito tempo em cada um deles, mas trabalhar com o que trabalho já me possibilitou viajar bastante pelo mundo.
Os países que já visitei:
E isso que cancelei algumas viagens pra destinos como Holanda e Alemanha.
E claro que não passei muito tempo em cada país. Alguns eu passei e passo só o fim de semana, como é o caso da Bélgica onde vou pro FOSDEM.
Mas visitei :)
Pra quem tiver interesse em ouvir o episódio, é esse aqui:
.oO(nota mental: já não posso usar o número de países que visitei como token pra recuperar senhas)

Interessante existirem poucos posts sobre isso, mas mailman3 é um desastre perto do que era mailman2.
Mailman2 era o gerenciado de email feito em cima da versão do python2. E tudo funcionava belo e bonito. Mas um dia surgiu uma grande ruptura que foi o python3, um cataclisma em forma de versão nova. Python3 quebrou chamadas e mudou a ponto de inutilizar tudo que foi feito em python2. Por si só isso já seria um aviso pra evitar Python de forma geral, mas todo mundo acabou migrando pro Python3 e assumindo que os problemas foram pra trazer uma melhoria geral no desempenho e uso da linguagem. Mas tente sugerir um Python4 pra ver o que acontesse...
E nesse tsunami causando desastre por onde passava chamado Python3, veio o upgrade do mailman2 pra mailman3 pra rodar com python3. Mas ao invés de manter o código que existia, decidiram quebrar em várias partes e até enfiar django no meio da coisa. Resultado: um desastre.
Uma das instalações que temos de mailman3 simplesmente não funciona. Outra que tínhamos, ficou fora do ar por 2 anos. Como não tinha muito tráfego, não foi tanto problema, mas eu não conseguia achar o problema do sistema não funcionar. Por sorte achei um site que deu uma letra de que poderia ser que um dos diretórios que são usados não estava com as permissões certas. E foi isso. Logs pra ajudar? Nada. Eu só via erro ao acessar o postifx. Então eu passei basicamente 2 anos tentando arrumar um problema que não existia entre o mailman3 e o postfix.
E agora chegou o momento de migrar as listas que temos num servidor interno na firma. O atual roda no Ubuntu 18.04 e estamos migrando pra uma VM nova rodando Ubuntu 22.04. E cadê o mailman3? Sim, ele não entrou no Ubunt 22.04. Simplesmente estava quebrado e não entrou. Até agora não existe um pacote usável do mesmo.
https://bugs.launchpad.net/ubuntu/+source/mailman3/+bug/1999197
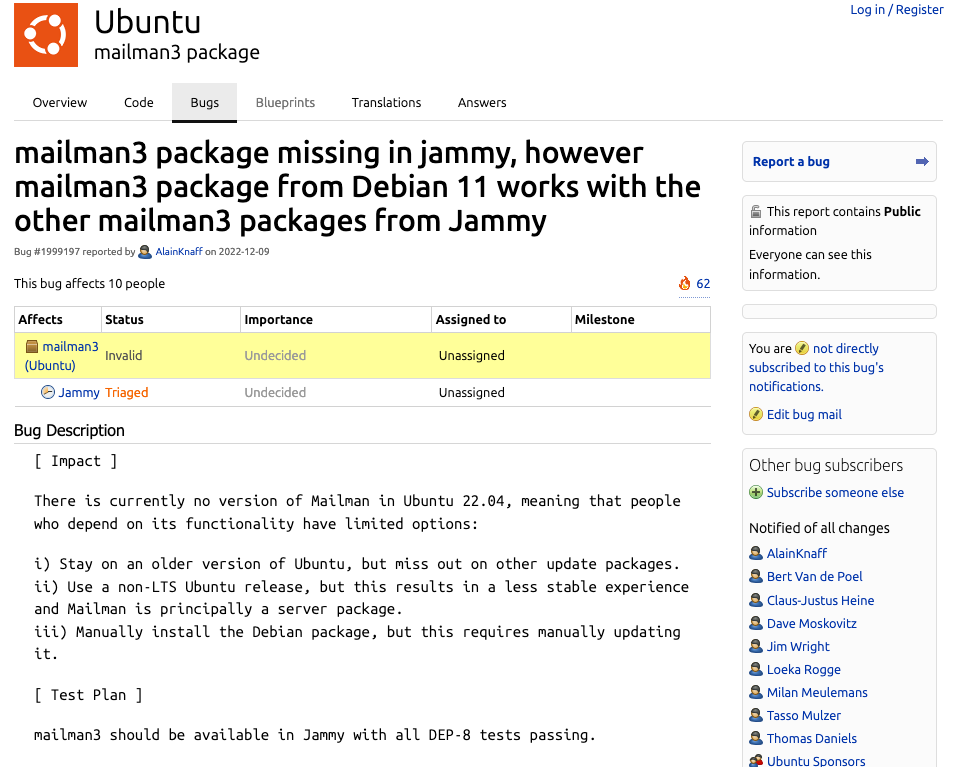
Então resta a opção de instalar manualmente pelos fontes, certo? Certo? Certo??? Pois é... tente entrar na página do mailman3 e seguir a... instalação. É um apanhado de coisas jogadas sem descrever como fazer funcionar de forma consistente.
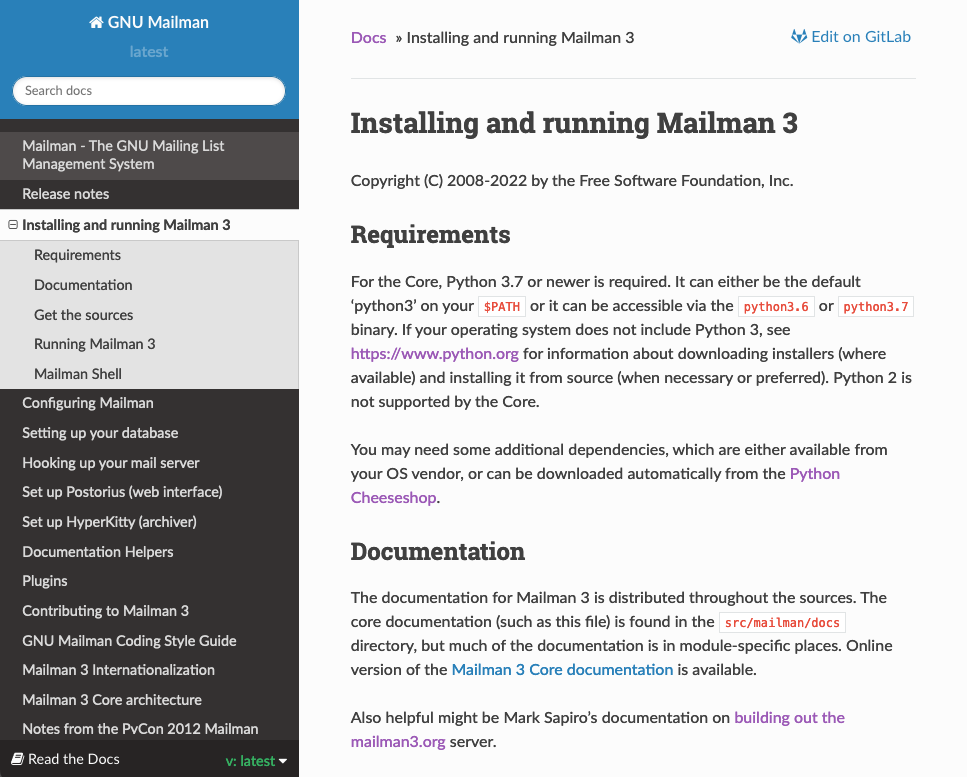



Da parte do clonar o repositório pra ter o comando mailman funcionando, como isso foi feito? Cadê o comando pra isso???
E é isso. A documentação, se melhorar muito, podemos chamar de lixo. Mas precisa melhorar, o que eu duvido muito.
Não só a instalação é lixo na forma de texto, como troubleshooting segue na mesma linha. Nenhuma informação que possa ajudar a resolver seus problemas.
E no mailman2 tudo estava rendondo, funcionando maravilhosamente. Não entende que ideia de Jerico que tiveram pra mudar completamente o produto em algo que precisa de muitas partes, desconexas pra funcionar.
E assim seguimos. Não sei se tento fazer uma instalação na mão do mailman3 on ubuntu 22.04, uma vez que não há explicação em como fazer isso, ou se jogo tudo pra cima e instalo outro servidor de lista como listproc. Acho que essa será a opção mais viável.
Page 9 of 40
