
Eu tenho rodado um tipo de sistema que faz DynDNS pra minhas máquinas que estão atrás de um serviço de DHCP como meu desktop que fica aqui em minha mesa, em casa.
O princípio é que essa máquina acessa uma certa URL a cada 5 minutos. Então a cada 5 minutos eu olho pro log do servidor web que roda nessa porta e pego os dados. Pego o IPv4 e o IPv6. Na verdade pego o que vier e vejo se é IPv4 ou IPv6. Depois olho no mapa de DNS se o valor mudou. Se mudou, altero o serial do map e mando um restart no serviço.
A lógica é simples. Mas eu fiz isso uns 15 anos atrás. Pra python2.Alguma-Coisa. Portei pra python3 no melhor estilo #XGH. O resultado? Problemas aqui e ali.
Vamos dar uma olhada no script anterior.
#! /usr/bin/python3 -u
# -*- encoding: utf-8 -*-
"""
DNS updater. It checks if hostname and IP are updated
on maps. If not, update accordingly and reload bind.
"""
# grep "\/\?update_dyndns=" /var/log/apache2/dyndns-access.log | sed "s/ HTTP.*//" | awk '{print $1, $NF}'
import re
import time
import os
import subprocess
import sys
LOG = "/var/log/apache2/dyndns-access.log"
DNSCONF = "/etc/bind/master/dyndns.truta.org"
DNSDATE = "/etc/bind/master/db.truta.org"
DNSFILES = [ DNSDATE, "/etc/bind/master/db.linux-br.org" ]
TRANSLATE = {
"goosfraba" : "helio",
"raspberrypi-masoso" : "rpi0",
"raspberrypi1" : "rpi1",
"raspberrypi2" : "rpi2",
"raspberrypi3" : "rpi3"
}
def debug(*msg):
if "DEBUG" in os.environ:
print("DEBUG:", *msg)
def get_latest_ips():
"""
Dictionary in format:
Domain/node : [ ipv4, ipv6]
"""
debug("get_latest_ips()")
NODE_IP = {}
with open(LOG) as logfile:
for line in logfile.readlines():
if not re.search("\/\?update_dyndns=", line):
continue
line = re.sub(" HTTP.*", "", line)
param = line.split()
ip = param[0]
nodename = re.sub("\/\?update_dyndns=", "", param[-1])
if not nodename in NODE_IP:
NODE_IP[nodename] = [ None, None ]
# ipv4?
if re.search("([0-9].*)\.([0-9].*)\.([0-9].*)\.([0-9].*)", ip):
NODE_IP[nodename][0] = ip
debug(f"{nodename} (ipv4): {ip}")
else:
NODE_IP[nodename][1] = ip
debug(f"{nodename} (ipv6): {ip}")
return NODE_IP
def apply_translate(DIC):
debug("apply_translate()")
# DIC = { translatedName : [ipv4, ipv6] }
debug("apply_translate(): DIC:\n", DIC)
tempDIC = {}
for nodename in DIC:
debug(f"apply_translate(): searching {nodename}")
if not nodename in TRANSLATE:
debug(f"{nodename} not in TRANSLATE table")
continue
dnsName = TRANSLATE[nodename]
if dnsName is None:
debug(f"{nodename} translates to None")
continue
nodeValue = DIC[nodename]
debug(f"apply_translate(): adding {dnsName} as {nodeValue}")
tempDIC[dnsName] = nodeValue
debug("apply_translate(): returning tempDIC:\n", tempDIC)
return tempDIC
def check_for_update(DIC):
debug("check_for_update()")
isupdated = False
buf = ""
debug("check_for_update(): current DNS entries")
with open(DNSCONF) as fh:
for line in fh.readlines():
if line.startswith(";") or line.startswith("#"):
buf += line
continue
line = line.rstrip()
param = line.split()
if len(param) != 3:
buf += f"{line}\n"
continue
subname, subtype, subip = param
print(f"DNS current entry: {subname}, Type: {subtype}, IP: {subip}")
if not subname in DIC:
debug(f"check_for_update(): {subname} is not into the DIC")
buf += f"{line}\n"
continue
ipv4, ipv6 = DIC[subname]
print(f"Found {subname} for update")
# ipv4
if subtype == "A":
print("Checking IPv4")
if ipv4 != subip and len(ipv4) > 0:
print(f" * Updating {subname} from {subip} to {ipv4}")
isupdated = True
buf += f"{subname}\t\t\t{subtype}\t{ipv4}\n"
continue
# ipv6
if subtype == "AAAA":
print("Checking IPv6")
if ipv6 != subip and len(ipv6) > 0:
print(f" * Updating {subname} from {subip} to {ipv6}")
isupdated = True
buf += f"{subname}\t\t\t{subtype}\t{ipv6}\n"
continue
buf += f"{line}\n"
if isupdated:
print(f"Updating file {DNSCONF}")
debug("check_for_update(): buf:", buf)
with open(DNSCONF, 'w') as fh:
fh.write(buf)
return isupdated
def get_dns_map_serial(dns_file: str) -> str:
with open(dns_file) as fh:
for line in fh.readlines():
if not re.search(" ; serial", line):
continue
timestamp = line.split()[0]
return timestamp
raise Exception(f"Failed to read serial from dns file: {dns_file}")
def get_serial_date_update(timestamp: str) -> list:
if len(timestamp) != 10 :
raise Exception(f"Wrong timestamp size (not 10): {timestamp}")
dateformat = timestamp[:8]
serial = timestamp[8:]
return (serial)
def update_serial_in_file(old_serial: str, new_serial: str, filename: str) -> None:
with open(filename) as fh:
buf = fh.read()
buf = re.sub(old_serial, new_serial, buf)
with open(filename, 'w') as fw:
fw.write(buf)
def update_timestamp(dryrun=False):
debug("update_timestamp()")
buf = ""
today = time.strftime("%Y%m%d", time.localtime())
timestamp = get_dns_map_serial(DNSDATE)
(last_update, last_serial) = get_serial_date_update(timestamp)
print("Timestamp:", timestamp)
print("Last update:", last_update)
print("Last serial:", last_serial)
original_timestamp = ""
if int(today) > int(last_update):
timestamp = f"{today}00"
else:
serial = int(last_serial) + 1
if serial < 100:
timestamp = "%s%02d" % (today, serial)
else:
timestamp = "%08d00" % (int(today) + 1)
print("New timestamp:", timestamp)
print("Updating file", DNSDATE)
debug(f"update_timestamp(): timestamp={timestamp}")
if dryrun is False:
update_serial_in_file(original_timestamp, timestamp, DNSDATE)
else:
print("-= dry-run mode =-")
print(f"Here file {DNSDATE} would be updated.")
print("Content:\n", buf)
def bind_restart(dryrun=False):
#cmd = "systemctl restart named.service"
## reload is enough
cmd = "systemctl reload named.service"
if dryrun is False:
subprocess.call(cmd.split())
else:
print("-= dry-run mode =-")
print(f"Here command would be called: {cmd}")
def main():
now = time.ctime(time.time())
print(f"Starting: {now}")
DNS = get_latest_ips()
DNS = apply_translate(DNS)
debug(DNS)
status = check_for_update(DNS)
if status:
if len(sys.argv) > 1 and sys.argv[-1] == "--help":
print(f"Use: {sys.argv[0]} [--help|--dry-run]")
sys.exit(0)
if len(sys.argv) > 1 and sys.argv[-1] == "--dry-run":
doDryRun = True
else:
doDryRun = False
update_timestamp(dryrun=doDryRun)
bind_restart(dryrun=doDryRun)
if __name__ == '__main__':
main()
O código está gigante e uma zona. E estava dando crash. Vamos então olhar por partes.
LOG = "/var/log/apache2/dyndns-access.log"
DNSCONF = "/etc/bind/master/dyndns.truta.org"
DNSDATE = ""
DNSFILES = [ DNSDATE, "/etc/bind/master/db.linux-br.org" ]
LOG é onde eu tenho de ler pra buscar o padrão de acesso.
DNSCONF é onde ficam as definições de "IP TIPO NOME" como "1.2.3.4 A helio" pro caso de IPv4.
DNSDATE é onde ficavam as atualizações pro domínio truta.org.
Eu percebi que dava pra fazer a mesma coisa com outros domínios, então depois
eu inseri junto o DNSFILES pra ter também o linux-br.org.
No final esses aquivos só precisam ser abertos pra alterar o serial.
O mapa de dns, pra entender o que é, é esse aqui pro truta.org:
❯ cat /etc/bind/master/db.truta.org
$TTL 180 ; # three minute
@ IN SOA ns1.truta.org. helio.loureiro.eng.br. (
2025080800 ; serial
43200 ; refresh (12 hours)
3600 ; retry (1 hour)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
@ NS ns1.truta.org.
@ NS ns2.afraid.org.
@ NS ns1.first-ns.de.
@ NS robotns2.second-ns.de.
@ NS robotns3.second-ns.com.
@ A 95.216.213.181
@ MX 5 mail.truta.org.
@ AAAA 2a01:4f9:c012:f3c4::1
@ TXT "v=spf1 a mx ip4:95.216.213.181 ip6:2a01:4f9:c012:f3c4::1 include:_spf.google.com -all"
mail._domainkey IN TXT "v=DKIM1; k=rsa; t=y; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCpp/HlB1QAHjp6jHGCj9kfcZSjY3ipbGuU/enVjEeptlNgw2qTxRRJ6puPiW5DWCOaPEg2nC//wRazFgMuLZ3C89vF2TT57upngmNuCcLtbwNxo6G1JFo5GD92UbQgstYC+cjfrRlw56XfwzWVtojR4ZCB8PCQCguwhwunwRhJEwIDAQAB" ; ----- DKIM key mail for truta.org
; As e AAAAs
; CNAMES
www AAAA 2a01:4f9:c012:f3c4::1
www A 95.216.213.181
ns1 A 95.216.213.181
AAAA 2a01:4f9:c012:f3c4::1
mail A 95.216.213.181
AAAA 2a01:4f9:c012:f3c4::1
; DYNAMIC TRUTAS
$INCLUDE "/etc/bind/master/dyndns.truta.org";
A linha que precisa ser alterada é a que tem 2025080800 ; serial.
A parte que faz a mágica de ler os novos endereços IPs é $INCLUDE "/etc/bind/master/dyndns.truta.org";.
E se não está familiarizado com mapas de dns, o que tem depois do ";" é ignorado.
Então o bind lê somente o 2025080800.
O ; serial é um comentário pra humanos entenderem o que é aquilo.
O serial é um número inteiro.
Você pode usar qualquer número.
Só precisa incrementar quando faz alguma alteração no mapa pra poder notificar que houve mudança pro seus secundários.
A boa prática é usar YYYYMMDDXX onde:
Então se o mapa é atualizado no mesmo dia, você incrementa o XX. Claro que isso te limita à 100 alterações por dia, de 0 a 99. Mas não é algo como ficar atualizando tanto o mapa. A menos que você seja um provedor de cloud. Daí as coisas funcionam de jeito beeeeem diferente. Mas vamos ficar no feijão com arroz.
Vamos voltar ao script. Como está escrito com funções, fica mais fácil de olhar pra cada uma independentemente. Eu vou colocar fora de ordem pra ficar mais claro o que faz o quê. Ou o que deveria fazer o quê.
def debug(*msg):
if "DEBUG" in os.environ:
print("DEBUG:", *msg)
Isso é claramente uma gambiarra. XGH em sua melhor forma. Só pra eu ter um "debug" pra olhar dentro do programa.
def main():
now = time.ctime(time.time())
print(f"Starting: {now}")
DNS = get_latest_ips()
DNS = apply_translate(DNS)
debug(DNS)
status = check_for_update(DNS)
if status:
if len(sys.argv) > 1 and sys.argv[-1] == "--help":
print(f"Use: {sys.argv[0]} [--help|--dry-run]")
sys.exit(0)
if len(sys.argv) > 1 and sys.argv[-1] == "--dry-run":
doDryRun = True
else:
doDryRun = False
update_timestamp(dryrun=doDryRun)
bind_restart(dryrun=doDryRun)
if __name__ == '__main__':
main()
A função main é o que chama tudo.
Algumas coisas de tempo pra saber quando começa.
E efetivamente a primeira chamada aqui: DNS = get_latest_ips().
Soa razoável olhar pra esse get_latest_ips() e imaginar que volta os últimos ips.
Mas ip de quem?
Com certeza tem de voltar algo como um dicionário pra você saber qual hostname tem qual ip.
E esse DNS?
Tinha de ser em maiúsculo?
Definitivamente não.
Variáveis em maiúsculo a gente deixa pra constantes como LOG.
Mas seguimos...
Agora temos um DNS = apply_translate(DNS).
Esse é um filtro que usa o TRANSLATE lá em cima:
TRANSLATE = {
"goosfraba" : "helio",
"raspberrypi-masoso" : "rpi0",
"raspberrypi1" : "rpi1",
"raspberrypi2" : "rpi2",
"raspberrypi3" : "rpi3"
}
E isso é usado porque meu desktop, por exemplo, tem hostname "goosfraba". Mas eu quero que ele seja no fqdn como "helio.truta.org". Então eu uso essa "tradução" de hostname recebido pro que eu quero no dns.
status = check_for_update(DNS) eu provavelmente comparo com o que está em DNSCONF.
E se houve alteração, salvo em status.
Definitivamente um boolean.
Em seguinda essa parte aqui:
if status:
if len(sys.argv) > 1 and sys.argv[-1] == "--help":
print(f"Use: {sys.argv[0]} [--help|--dry-run]")
sys.exit(0)
if len(sys.argv) > 1 and sys.argv[-1] == "--dry-run":
doDryRun = True
else:
doDryRun = False
Esse é um outro XGH. Tudo pra ver se existe o parâmetro "--help". Ou se é passado "--dry-run". "dry-run" é como é chamado um "test pra ver se vai" sem realmente fazer nada. Eu provavelmente fiz isso porque a primeira implementação era em shell script. Mas mesmo em shell script isso seria XGH.
update_timestamp(dryrun=doDryRun) faz aquele update de serial nos mapas de dns se algo mudou.
A menos que o parâmetro de "dry-run" esteja lá.
E finalmente bind_restart(dryrun=doDryRun) reinicia o serviço via systemd ser não for um "dry-run".
Olhamos a lógica do que deveria fazer.
Agora vamos ver o que foi feito.
Vamos começar com o get_latest_ips( ).
def get_latest_ips():
"""
Dictionary in format:
Domain/node : [ ipv4, ipv6]
"""
debug("get_latest_ips()")
NODE_IP = {}
with open(LOG) as logfile:
for line in logfile.readlines():
if not re.search("\/\?update_dyndns=", line):
continue
line = re.sub(" HTTP.*", "", line)
param = line.split()
ip = param[0]
nodename = re.sub("\/\?update_dyndns=", "", param[-1])
if not nodename in NODE_IP:
NODE_IP[nodename] = [ None, None ]
# ipv4?
if re.search("([0-9].*)\.([0-9].*)\.([0-9].*)\.([0-9].*)", ip):
NODE_IP[nodename][0] = ip
debug(f"{nodename} (ipv4): {ip}")
else:
NODE_IP[nodename][1] = ip
debug(f"{nodename} (ipv6): {ip}")
return NODE_IP
Aparentemente a estrutura NODE_IP = {} vai ser um dicionário do tipo
hostname: [IPv4][IPv6].
with open(LOG) as logfile:
for line in logfile.readlines():
if not re.search("\/\?update_dyndns=", line):
continue
Aqui é ler o aquivo LOG.
Se a linha não tiver o padrão "/?update_dynds=", vai pra próxima linha.
line = re.sub(" HTTP.*", "", line)
param = line.split()
ip = param[0]
nodename = re.sub("\/\?update_dyndns=", "", param[-1])
A alinha recebida é algo assim:
83.233.219.150 - - [11/Aug/2025:08:54:57 +0000] "GET /?update_dyndns=goosfraba HTTP/1.1" 200 87144 "-" "curl/8.15.0"
Então o regex em line = re.sub(" HTTP.*", "", line) remove tudo depois de " HTTP", including essa parte junto.
A linha então fica algo assim:
83.233.219.150 - - [11/Aug/2025:08:54:57 +0000] "GET /?update_dyndns=goosfraba
A linha param = line.split() cria a variável param (parâmetros) com a linha separada por espaços simples.
ip = param[0] pega o primeiro parâmetro.
No exemplo seria "83.233.219.150".
nodename = re.sub("\/\?update_dyndns=", "", param[-1]) pega o último parâmetro, que no exemplo seria
"/?update_dyndns=goosfraba" e remove a parte "/?update_dyndns=".
Vai sobrar o hostname, "goosfraba".
if not nodename in NODE_IP:
NODE_IP[nodename] = [ None, None ]
Aqui olha se o dicionário NODE_IP tem a chave que é o nodename.
Eu comentei acima hostname, mas no código chamei de nodename.
Tenha em mente que eram a mesma coisa.
E se a chave não existe, eu crio com uma lista vazia.
if re.search("([0-9].*)\.([0-9].*)\.([0-9].*)\.([0-9].*)", ip):
NODE_IP[nodename][0] = ip
debug(f"{nodename} (ipv4): {ip}")
else:
NODE_IP[nodename][1] = ip
debug(f"{nodename} (ipv6): {ip}")
Finalmente eu comparo o ip se bate com o padrão ([0-9].*)\.([0-9].*)\.([0-9].*)\.([0-9].*) que
é basicamente qualquer número de 0 à 9 seguido de ponto.
Então se eu recebesse um IP inválido, como 999.9999999.999999999999.99999999, validaria.
Mas pro script XGH, foi suficiente.
Daí eu sei se é um IPv4.
Se não for, é IPv6.
Como vou lendo o arquivo LOG de cima pra baixo,
esses valores de hostname e ip é atualizado várias vezes.
Com os mesmos valores.
E como o servidor web atualiza também de cima pra baixo, a última linha deve ser a mais atual.
Não muito eficiente, mas dá certo.
XGH raiz.
O apply_translate( ) eu não vou comentar.
Já expliquei acima o que ele faz, que é traduzir hostname pra entrada no dns.
Não adiciona muita coisa.
Então vamos pro próximo.
O próximo é um XGH raiz.
Função grande.
É a check_for_update( ).
Vamos por partes.
def check_for_update(DIC):
debug("check_for_update()")
isupdated = False
buf = ""
debug("check_for_update(): current DNS entries")
with open(DNSCONF) as fh:
for line in fh.readlines():
if line.startswith(";") or line.startswith("#"):
buf += line
continue
line = line.rstrip()
param = line.split()
if len(param) != 3:
buf += f"{line}\n"
continue
Aqui é lido o arquivo DNSCONF, que é onde está o mapa "ip tipo nome" como "1.2.3.4 A helio".
Essa primeira parte descarta as linhas que começam ou com ";" ou com "#".
Na verdade copia a linha como está em buf.
A parte de baixo prepara a linha pra ser lida se tiver o padrão de ter ao menos 3 parâmetros quando separada por espaços.
Se não for, copie pro buffer e vá pra próxima linha.
subname, subtype, subip = param
print(f"DNS current entry: {subname}, Type: {subtype}, IP: {subip}")
if not subname in DIC:
debug(f"check_for_update(): {subname} is not into the DIC")
buf += f"{line}\n"
continue
Aqui já pega os 3 parâmetros que serão subname, subtype, subip.
O subname é o hostname.
Ou nodename.
Consistência não é meu forte.
Ou não era.
E se esse hostname não estiver no dicionário, salva a linha como ela era no buffer e vai pra próxima linha.
ipv4, ipv6 = DIC[subname]
print(f"Found {subname} for update")
# ipv4
if subtype == "A":
print("Checking IPv4")
if ipv4 != subip and len(ipv4) > 0:
print(f" * Updating {subname} from {subip} to {ipv4}")
isupdated = True
buf += f"{subname}\t\t\t{subtype}\t{ipv4}\n"
continue
# ipv6
if subtype == "AAAA":
print("Checking IPv6")
if ipv6 != subip and len(ipv6) > 0:
print(f" * Updating {subname} from {subip} to {ipv6}")
isupdated = True
buf += f"{subname}\t\t\t{subtype}\t{ipv6}\n"
continue
buf += f"{line}\n"
Aqui os endereços IPv4 e IPv6 são recuperados do dicionário em ipv4, ipv6 = DIC[subname].
Se o subtipo for "A", eu olho se o endereço IPv4 mudou.
Se for "AAAA", olho o IPv6.
Se alterar, eu altero isupdated pra verdadeiro.
if isupdated:
print(f"Updating file {DNSCONF}")
debug("check_for_update(): buf:", buf)
with open(DNSCONF, 'w') as fh:
fh.write(buf)
return isupdated
E finalmente, se o código foi alterado, escrevo em cima do arquivo antigo o conteúdo novo.
Até aqui tudo bem.
O código está meio rebuscado e com alguns pontos de XGH mas parece funcional.
Vamos então olhar a próxima parte, que é atualizar os mapas caso tenha tido alguma mudança.
Olhando pra update_timestamp( ) vamos ver que esse depende de outras funções, que ficam pra cima no código.
E aqui já entra um pequeno mal estar.
Eu gosto dos conselhos do Uncle Bob sobre clean code.
E prefiro ler um código de cima pra baixo.
Usou uma função ou método?
Coloque abaixo.
Na ordem em que foi chamado.
Mas com python com funções isso não funciona.
Você tem de colocar acima as funções que serão chamadas abaixo.
Então vamos lá.
def update_timestamp(dryrun=False):
debug("update_timestamp()")
buf = ""
today = time.strftime("%Y%m%d", time.localtime())
timestamp = get_dns_map_serial(DNSDATE)
Bem básico.
Pega o dia de hoje no formato "YYYMMDD".
Em seguida olha qual o serial do arquivo com get_dns_map_serial( ).
Ao contrário do que fiz até agora, eu vou parar de analizar essa função e seguir o código que ela chamou.
def get_dns_map_serial(dns_file: str) -> str:
with open(dns_file) as fh:
for line in fh.readlines():
if not re.search(" ; serial", line):
continue
timestamp = line.split()[0]
return timestamp
raise Exception(f"Failed to read serial from dns file: {dns_file}")
Esse trecho de código é claramente mais recente. Usando f-strings e mais type hints pra saber o que seria ali. E variáveis em minúsculas! E bem simples: abre o arquivo passado (um mapa de dns) e busca pela linha com "; serial". Quebra a linha em espaços e retorna o primeiro parâmetro encontrado. Não tem verificação se realmente voltou uma string, mas parece ser isso. E se não achar nada, lança uma exceção e para a execução toda. Um pouco demais, mas pelo menos não retorna algo errado e deixa destruir o mapa de dns.
Vamos então voltar a olhar a função chamadora, update_timestamp( ).
(last_update, last_serial) = get_serial_date_update(timestamp)
Novamente um código mais enxuto.
Ao invés de manter no corpo da função, chamar outra função auto-explicativa.
Então vamos olhar a get_serial_date_update( ).
def get_serial_date_update(timestamp: str) -> list:
if len(timestamp) != 10 :
raise Exception(f"Wrong timestamp size (not 10): {timestamp}")
dateformat = timestamp[:8]
serial = timestamp[8:]
return (serial)
Aqui ele verifica se o serial tem 10 caractéres, ou 10 dígitos com if len(timestamp) != 10.
Ou gera uma exceção e encerra a execução.
Pega os primeiro 8 caractéres e coloca em dateformat.
Em seguida pega os caractéres restantes e coloca em serial.
E retorna o serial.
Perceberam os problemas?
Já começa que a função chama-se get_serial_date_update( ).
Qual o update?
E deveria retornar uma lista.
Até volta, mas com um valor só, o serial.
A função que chamava esperava o quê?
Esperava isso aqui: (last_update, last_serial) = get_serial_date_update(timestamp).
Então recebe last_update mas não last_serial.
Achamos um 🪲.
Vamos então continuar em update_timestamp( ).
print("Timestamp:", timestamp)
print("Last update:", last_update)
print("Last serial:", last_serial)
original_timestamp = ""
if int(today) > int(last_update):
timestamp = f"{today}00"
else:
serial = int(last_serial) + 1
if serial < 100:
timestamp = "%s%02d" % (today, serial)
else:
timestamp = "%08d00" % (int(today) + 1)
print("New timestamp:", timestamp)
Aqui a data today é transformada em int (integer, inteiro) e comparada com last_update, que também é transformado em int.
Se for maior, mais atual, então inicializa com "00".
Se não for mais atual, então incrementa o número serial em 1.
E olha se for maior que 100, incializa o dia seguinte e começa com 00 de novo.
E finalmente:
if dryrun is False:
update_serial_in_file(original_timestamp, timestamp, DNSDATE)
Se não está rodando em dry-run, rodar esse update_serial_in_file( ).
Pelo nome é possível deduzer que seja trocar o serial antigo do arquivo pelo novo.
Mas vamos olhar o código.
def update_serial_in_file(old_serial: str, new_serial: str, filename: str) -> None:
with open(filename) as fh:
buf = fh.read()
buf = re.sub(old_serial, new_serial, buf)
with open(filename, 'w') as fw:
fw.write(buf)
E sim, é basicamente isso mesmo. Ler o arquivo todo, trocar a string antiga pela nova, e salvar.
E com isso chegamos na parte final do script:
bind_restart(dryrun=doDryRun)
É bem descritivo e faz exatamente o que diz: reinicia o serviço de dns via systemd.
def bind_restart(dryrun=False):
#cmd = "systemctl restart named.service"
## reload is enough
cmd = "systemctl reload named.service"
if dryrun is False:
subprocess.call(cmd.split())
else:
print("-= dry-run mode =-")
print(f"Here command would be called: {cmd}")
Se teve paciência de ler até aqui, espero que tenha gostado e aprendido que esse código estava bem ruim. E o que seria um código bom? Com certeza um que seja legível de cima pra baixo. Até certo ponto porque python não é tão flexível assim. Sem delongas, vou mostrar o código novo. Depois vou explicando.
#! /usr/bin/python3 -u
# -*- encoding: utf-8 -*-
"""
DNS updater. It checks if hostname and IP are updated
on maps. If not, update accordingly and reload bind.
"""
# grep "\/\?node=" /var/log/apache2/dyndns-access.log | sed "s/ HTTP.*//" | awk '{print $1, $NF}'
import re
import time
import os
import subprocess
import sys
import argparse
import logging
logger = logging.getLogger(__file__)
consoleOutputHandler = logging.StreamHandler()
logger.addHandler(consoleOutputHandler)
logger.setLevel(logging.INFO)
TRANSLATE = {
"goosfraba" : "helio",
"raspberrypi-masoso" : "rpi0",
"raspberrypi1" : "rpi1",
"raspberrypi2" : "rpi2",
"raspberrypi3" : "rpi3"
}
class DnsIPUpdate:
'''
A class that reads httpd logs for patterns in order to find a host IP,
update dns file accordingly if needed and restart dns service if updated.
'''
def __init__(self, args: argparse.Namespace):
self._logfile: str = args.logfile
self._bindfiles: list = args.bindfiles.split(",")
self._IPv4: dict = {}
self._IPv6: dict = {}
self._dryrun: bool = args.dryrun
self._dyndnsfile: str = args.dyndnsfile
self._fakesystemd: bool = args.fakesystemd
# for the serial on the dns files
self._year: str = time.strftime("%Y", time.localtime())
self._month: str = time.strftime("%m", time.localtime())
self._day: str = time.strftime("%d", time.localtime())
def update(self):
'run the update'
matched_lines: list = self.getEntriesFromLogs()
self._populateIPsData(matched_lines)
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
self._applyTranslation()
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
if not self._dryrun:
resp: bool = self._updateDNSFiles()
if resp is True:
self._restartService()
def getEntriesFromLogs(self) -> list:
'return the matching lines from logging file'
matches: list = []
with open(self._logfile) as fd:
for line in fd.readlines():
if not re.search(r"\/\?update_dyndns=", line):
continue
line = line.rstrip()
logger.debug(f"found line in log: {line}")
matches.append(line)
return matches
def _populateIPsData(self, matches):
'fill the IPv4 and IPv6 structures with IPs and hostnames'
for line in matches:
ip_addr, _, _, timestamp, timezone, method, uri, http_version, status_code, size, _, user_agent = line.split()
timestamp = timestamp[1:]
timezone = timezone[:-1]
method = method[1:]
http_version = http_version[:-1]
user_agent = user_agent[1:-1]
logger.debug(f"ip={ip_addr} timestamp={timestamp} timezone={timezone} method={method} uri={uri} proto={http_version} status_code={status_code} size={size} agent={user_agent}")
hostname = self._getHostName(uri)
if self._isIPv4(ip_addr):
self._IPv4[hostname] = ip_addr
else:
self._IPv6[hostname] = ip_addr
def _isIPv4(self, ip: str) -> bool:
'quickly finds out whether IPv4 or not - then IPv6'
if re.search("^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$", ip):
return True
return False
def _getHostName(self, uri: str) -> str:
'filter uri to return only the hostname'
hostname = re.sub(r",.*", "", uri)
hostname = re.sub(r".*update_dyndns=", "", hostname)
return hostname
def _applyTranslation(self) -> None:
'translate hostname according to table'
for old_name, new_name in TRANSLATE.items():
if old_name in self._IPv4:
logger.debug(f"Translating IPv4: from={old_name} to={new_name}")
self._IPv4[new_name] = self._IPv4[old_name]
del self._IPv4[old_name]
if old_name in self._IPv6:
logger.debug(f"Translating IPv6: from={old_name} to={new_name}")
self._IPv6[new_name] = self._IPv6[old_name]
del self._IPv6[old_name]
def _updateDNSFiles(self) -> bool:
'check and update DNS files if needed'
isUpdated = self._updateDynDNS()
if isUpdated is True:
self._updateSerialOnDNS()
return isUpdated
def _updateDynDNS(self) -> bool:
'check each entry into dyndns file and returns true if updated'
status = False # by default we don't update
output = []
with open(self._dyndnsfile) as fd:
buffer = fd.readlines()
for line in buffer:
line = line.rstrip() # remove new line
try:
hostname, _, _, dns_type, ip_addr = line.split("\t")
except ValueError:
output.append(f"{line}\n")
continue
match dns_type:
case "A":
# IPv4
if hostname in self._IPv4:
if self._IPv4[hostname] != ip_addr:
logger.info(f"updating IPv4 for {hostname}: old={ip_addr} new={self._IPv4[hostname]}")
line = f"{hostname}\t\t\tA\t{self._IPv4[hostname]}"
status = True
case "AAAA":
# IPv6
if hostname in self._IPv6:
if self._IPv6[hostname] != ip_addr:
logger.info(f"updating IPv6 for {hostname}: old={ip_addr} new={self._IPv6[hostname]}")
line = f"{hostname}\t\t\tAAAA\t{self._IPv6[hostname]}"
status = True
case _:
pass
output.append(f"{line}\n")
if status is True:
with open(self._dyndnsfile, 'w') as fw:
fw.write("".join(output))
return status
def _updateSerialOnDNS(self) -> None:
for filename in self._bindfiles:
buffer: list = []
logger.debug(f"updating serial on file: {filename}")
with open(filename) as fd:
for line in fd.readlines():
if not re.search("; serial", line):
buffer.append(line)
continue
line = line.rstrip()
logger.debug(f"line with serial number: {line}")
serial = self._sanitizeSerial(line)
logger.debug(f"serial={serial}")
new_serial = self._increaseSerial(serial)
logger.debug(f"new_serial={new_serial}")
line = f"\t\t\t\t{new_serial} ; serial\n"
logger.info(f"updating: filename={filename} old_serial={serial} new_serial={new_serial}")
buffer.append(line)
with open(filename, "w") as fw:
fw.write("".join(buffer))
def _sanitizeSerial(self, serial_nr: str) -> str:
'to remove the \t and spaces'
serial, _ = serial_nr.split(";")
serial = re.sub(r"\t", "", serial)
serial = re.sub(" ", "", serial)
return serial
def _increaseSerial(self, serial_nr: str):
'to identify and increase serial'
year = serial_nr[:4]
month = serial_nr[4:6]
day = serial_nr[6:8]
counter = serial_nr[8:]
today = f"{self._year}{self._month}{self._day}"
serial_date = f"{year}{month}{day}"
if today == serial_date:
new_counter = self._increaseString(counter)
return f"{today}{new_counter}"
else:
return f"{today}00"
def _increaseString(self, str_number: str) -> str:
'convert string to int, increase by one and return as string'
int_number: int = int(str_number)
int_number += 1
return f"{int_number}"
def _restartService(self) -> None:
'restart systemd service'
cmd = ["systemctl", "reload", "named.service"]
logger.info("restarting named.service")
if self._fakesystemd is True:
print(f"here service would be restarted: {cmd}")
else:
subprocess.call(cmd)
def getTimestamp():
return time.strftime("%Y%m%dT%H:%M:%S", time.localtime())
def main():
logger.info(f"starting: {getTimestamp()}")
parser = argparse.ArgumentParser(description='script to update DNS entries for dynamic clients found on httpd logs')
parser.add_argument("--logfile", required=True, help="the httpd log to be checked")
parser.add_argument("--loglevel", default="info", help="logging level for this script")
parser.add_argument("--bindfiles", required=True, help="files separated by \",\" to be updated to update serial")
parser.add_argument("--dyndnsfile", required=True, help="the dyndns map to update the IPs")
parser.add_argument("--dryrun", default=False, type=bool, help='run as dry-run or not (default=false)')
parser.add_argument("--fakesystemd", default=False, type=bool, help='run just a printout instead of systemd')
args = parser.parse_args()
if args.loglevel != "info":
logger.setLevel(args.loglevel.upper())
logger.debug(f"args: {args}")
dns = DnsIPUpdate(args)
dns.update()
logger.info(f"finished: {getTimestamp()}")
if __name__ == '__main__':
main()
A parte de baixo continua mais ou menos igual: chama uma função main( ) que faz tudo.
Mas agora a função main( ) usa argparse pra pegar os argumentos.
Então as constantes com os nomes dos arquivos sumiram e viraram agora argumentos.
Isso facilita escrever testes (o que não fiz ainda).
O que o código faz?
Faz isso aqui:
dns = DnsIPUpdate(args)
dns.update()
Cria um objeto DnsIPUpdate( ) e chama o método update( ).
Não mais funções mas métodos.
Parece mais simples de entender.
Espero.
Vamos então agora olhar a classe. Começando com sua inicialização.
def __init__(self, args: argparse.Namespace):
self._logfile: str = args.logfile
self._bindfiles: list = args.bindfiles.split(",")
self._IPv4: dict = {}
self._IPv6: dict = {}
self._dryrun: bool = args.dryrun
self._dyndnsfile: str = args.dyndnsfile
self._fakesystemd: bool = args.fakesystemd
# for the serial on the dns files
self._year: str = time.strftime("%Y", time.localtime())
self._month: str = time.strftime("%m", time.localtime())
self._day: str = time.strftime("%d", time.localtime())
As variáveis (atributos da classe) vêm do argparse. Todas com o "_" no início pra indicar que são internas. Não que isso importe muito uma vez que não é uma classe feita pra ser usada como biblioteca. E agora IPv4 e IPv6 são estruturas separadas. Do tipo dicionário. E pegamos ano, mês e dia separados.
Vamos então olhar o método chamado, o update( ):
def update(self):
'run the update'
matched_lines: list = self.getEntriesFromLogs()
self._populateIPsData(matched_lines)
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
self._applyTranslation()
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
if not self._dryrun:
resp: bool = self._updateDNSFiles()
if resp is True:
self._restartService()
Primeiramente que o método update( ) aparece logo abaixo da inicialização da classe.
Então você lê o código de cima pra baixo, o que é muito desejado.
E o código chama outro método em matched_lines: list = self.getEntriesFromLogs( ), que vai retornar uma lista.
Vamost então olhar o que faz getEntriesFromLogs( ).
def getEntriesFromLogs(self) -> list:
'return the matching lines from logging file'
matches: list = []
with open(self._logfile) as fd:
for line in fd.readlines():
if not re.search(r"\/\?update_dyndns=", line):
continue
line = line.rstrip()
logger.debug(f"found line in log: {line}")
matches.append(line)
return matches
Ele então abre o arquivo _logfile e guarda as linhas com o padrão "/?update_dyndns=".
E em formate de lista.
Depois retorna esses valores.
Não melhorou muito em termos de ler o arquivo todo e fazer o parsing de tudo.
Ficou só mais legível.
Voltando ao update( ) temos logo em seguida: self._populateIPsData(matched_lines).
Então vamos olhar o código de _populateIPsData( ).
def _populateIPsData(self, matches):
'fill the IPv4 and IPv6 structures with IPs and hostnames'
for line in matches:
ip_addr, _, _, timestamp, timezone, method, uri, http_version, status_code, size, _, user_agent = line.split()
timestamp = timestamp[1:]
timezone = timezone[:-1]
method = method[1:]
http_version = http_version[:-1]
user_agent = user_agent[1:-1]
logger.debug(f"ip={ip_addr} timestamp={timestamp} timezone={timezone} method={method} uri={uri} proto={http_version} status_code={status_code} size={size} agent={user_agent}")
hostname = self._getHostName(uri)
if self._isIPv4(ip_addr):
self._IPv4[hostname] = ip_addr
else:
self._IPv6[hostname] = ip_addr
Agora a linha é quebrada em espaços mas o dados são utilizados. O que é "_" significa que seja descartado. Então olhando a linha de exemplo novamente:
83.233.219.150 - - [11/Aug/2025:08:54:57 +0000] "GET /?update_dyndns=goosfraba HTTP/1.1" 200 200 "-" "curl/8.15.0"
Temos:
O que vem a seguir é somente pra limpar esses parâmetros.
Servem pra alguma coisa?
Não.
Só pra ficar bonitinho no debug.
O que realmente importa são os valores de ip_addr e uri.
Em seguida é chamado hostname = self._getHostName(uri).
Vamos olhar o código do _getHostName( ).
def _getHostName(self, uri: str) -> str:
'filter uri to return only the hostname'
hostname = re.sub(r",.*", "", uri)
hostname = re.sub(r".*update_dyndns=", "", hostname)
return hostname
É somente o mesmo sanitizador usado anteriormente. Vai remover o "/?update_dyndns=" e deixar somente o hostname.
Voltando ao _populateIPsData( ), temos a chamada if self._isIPv4(ip_addr):
pra verificar se é um endereço IPv4 ou não.
def _isIPv4(self, ip: str) -> bool:
'quickly finds out whether IPv4 or not - then IPv6'
if re.search("^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$", ip):
return True
return False
O código agora olha se é um número válido dentro do range de IPv4.
Então após essa verificação, ou o dicionário _IPv4 ou o _IPv6 é populado. E segue o formato "hostname: IP". Mas cada um em seu dicionário agora.
Voltando ao update( ) temos:
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
self._applyTranslation()
logger.debug(f'IPv4s: {self._IPv4}')
logger.debug(f'IPv6s: {self._IPv6}')
Que é a mesmo tradução feita anteriormente.
def _applyTranslation(self) -> None:
'translate hostname according to table'
for old_name, new_name in TRANSLATE.items():
if old_name in self._IPv4:
logger.debug(f"Translating IPv4: from={old_name} to={new_name}")
self._IPv4[new_name] = self._IPv4[old_name]
del self._IPv4[old_name]
if old_name in self._IPv6:
logger.debug(f"Translating IPv6: from={old_name} to={new_name}")
self._IPv6[new_name] = self._IPv6[old_name]
del self._IPv6[old_name]
Seguindo em frente no update( ) temos o seguinte:
if not self._dryrun:
resp: bool = self._updateDNSFiles()
Vamos olhar então _updateDNSFiles( ) que faz o update já visto anteriormente.
def _updateDNSFiles(self) -> bool:
'check and update DNS files if needed'
isUpdated = self._updateDynDNS()
if isUpdated is True:
self._updateSerialOnDNS()
return isUpdated
Ele chama _updateDynDNS( ).
Vamos então ao código.
def _updateDynDNS(self) -> bool:
'check each entry into dyndns file and returns true if updated'
status = False # by default we don't update
output = []
with open(self._dyndnsfile) as fd:
buffer = fd.readlines()
for line in buffer:
line = line.rstrip() # remove new line
try:
hostname, _, _, dns_type, ip_addr = line.split("\t")
except ValueError:
output.append(f"{line}\n")
continue
Então ele abre o arquivo e lê linha por linha.
Mas dessa vez tenta popular a estrutura: hostname, _, _, dns_type, ip_addr = line.split("\t").
Se der errado, joga a linha no que será escrito depois.
E segue pra próxima linha.
Continuando.
match dns_type:
case "A":
# IPv4
if hostname in self._IPv4:
if self._IPv4[hostname] != ip_addr:
logger.info(f"updating IPv4 for {hostname}: old={ip_addr} new={self._IPv4[hostname]}")
line = f"{hostname}\t\t\tA\t{self._IPv4[hostname]}"
status = True
case "AAAA":
# IPv6
if hostname in self._IPv6:
if self._IPv6[hostname] != ip_addr:
logger.info(f"updating IPv6 for {hostname}: old={ip_addr} new={self._IPv6[hostname]}")
line = f"{hostname}\t\t\tAAAA\t{self._IPv6[hostname]}"
status = True
case _:
pass
Usa match ao invés de um if.
Poderia usar if?
Sim.
Mas achei que o match deixou o código mais organizado.
Em seguida verifica se o hostname existe no dicionário de IP.
Se existir, compara se o IP está diferente ou não.
Se estiver, atualiza a flag status pra verdadeiro pra avisar que houveram mudanças.
output.append(f"{line}\n")
if status is True:
with open(self._dyndnsfile, 'w') as fw:
fw.write("".join(output))
return status
A parte final é salvar o arquivo caso tenha havido alguma alteração.
Voltando para _updateDNSFiles( ), temos:
if isUpdated is True:
self._updateSerialOnDNS()
return isUpdated
Vamos então olhar _updateSerialOnDNS( ):
def _updateSerialOnDNS(self) -> None:
for filename in self._bindfiles:
buffer: list = []
logger.debug(f"updating serial on file: {filename}")
with open(filename) as fd:
for line in fd.readlines():
if not re.search("; serial", line):
buffer.append(line)
continue
line = line.rstrip()
logger.debug(f"line with serial number: {line}")
serial = self._sanitizeSerial(line)
logger.debug(f"serial={serial}")
new_serial = self._increaseSerial(serial)
logger.debug(f"new_serial={new_serial}")
line = f"\t\t\t\t{new_serial} ; serial\n"
logger.info(f"updating: filename={filename} old_serial={serial} new_serial={new_serial}")
buffer.append(line)
with open(filename, "w") as fw:
fw.write("".join(buffer))
Aqui já virou feijão com arroz.
O que temos de olhar é _sanitizeSerial( ),
depois _increaseSerial( ).
def _sanitizeSerial(self, serial_nr: str) -> str:
'to remove the \t and spaces'
serial, _ = serial_nr.split(";")
serial = re.sub(r"\t", "", serial)
serial = re.sub(" ", "", serial)
return serial
Sem surpresas, só um regex pra voltar o número serial.
def _increaseSerial(self, serial_nr: str):
'to identify and increase serial'
year = serial_nr[:4]
month = serial_nr[4:6]
day = serial_nr[6:8]
counter = serial_nr[8:]
today = f"{self._year}{self._month}{self._day}"
serial_date = f"{year}{month}{day}"
if today == serial_date:
new_counter = self._increaseString(counter)
return f"{today}{new_counter}"
else:
return f"{today}00"
Aqui o código mudou.
Ao invés de comparar com números inteiros, faz uma comparação de string direto.
E chama _increaseString( ) pra aumentar o valor da string.
def _increaseString(self, str_number: str) -> str:
'convert string to int, increase by one and return as string'
int_number: int = int(str_number)
int_number += 1
return f"{int_number}"
Aqui sim a string é convertida pra inteiro. Esse é incrementado por 1. Mas retorna como string.
Chegamos então na parte final do update( ) que chama o método _restartService().
def _restartService(self) -> None:
'restart systemd service'
cmd = ["systemctl", "reload", "named.service"]
logger.info("restarting named.service")
if self._fakesystemd is True:
print(f"here service would be restarted: {cmd}")
else:
subprocess.call(cmd)
Sem muita novidade, é o código pra reiniciar o serviço de dns via systemd.
E aqui acabamos com o código novo. O que achou? Eu achei melhor de manter. E funcionando sem bugs.
O próximo passo será escrever testes unitários pra ele ☺️.
Esse é um update to artigo usando python pra capturar a webcam. E com o uso do obamawatched 2021. Eu atualizei recentemente o obamawatcher pra rodar com PySide6 e está aqui funcionando no meu laptop atual de trabalho. No meu pessoal também. Ao menos acho que está funcionando.
O resultado final já está no vídeo acima. Como são várias imagens, os comandos que listei antes já não funcionam muito bem. Eu precisei primeiro redimensionar as imagens pra 640x360 para ficar em widescreen (16:9). As fotos mais antigas saíram em formato quadrado porque era o que a Webcam suportava na época. Então precisei cortar pra ficarem no aspecto correto. E pra isso eu usei python com pillow.
#! /usr/bin/env python3
import os
import re
import argparse
try:
from PIL import Image
except ModuleNotFoundError as e:
raise Exception("missing pillow - run: pip install Pillow") from e
golden_rate = 1280/720
default_size_x = 640
default_size_y = 360
parse = argparse.ArgumentParser(description="Script to resize pictures from a specific directory to the same size")
parse.add_argument("--directory", required=True, help="directory with images jpg")
args = parse.parse_args()
for filename in sorted(os.listdir(args.directory)):
if not re.search("jpg", filename):
continue
with Image.open(args.directory + "/" + filename) as image:
width, height = image.size
rate = float(width)/float(height)
is_golden = rate == golden_rate
is_correted = False
rate_from_default = width / default_size_x
if rate_from_default == 1:
pass
elif rate_from_default > 1:
image = image.resize((default_size_x, int(height/rate_from_default)))
is_correted = True
else:
image = image.resize((default_size_x, int(height/rate_from_default)), Image.Resampling.LANCZOS)
is_correted = True
if not is_golden:
image = image.crop((0, 0, default_size_x, default_size_y))
image.save(filename)
print(f"{filename}: {width}x{height}, golden: {is_golden}, corrected: {is_correted}")
print(f"Golden rate: {golden_rate}")
Tendo as imagens no mesmo formato, basta ordernar e usar ffmpeg pra montar o vídeo.
#! /usr/bin/env bash
die() {
echo "$1" >&2
exit 1
}
counter=0
for img in [0-9]*.jpg
do
serial=$(printf "%06d" $counter)
new_name="G${serial}.JPG"
counter=$(expr $counter + 1)
if [ -f "$new_name" ]; then
echo "$new_name already exists"
continue
fi
echo "$img => $new_name"
mv $img $new_name
done
case $(uname -s) in
Linux)
echo "Merging images into single video file: output.mp4"
ffmpeg -r 8 -i G%06d.JPG -c:v h264 -b:v 5M output.mp4 || \
die "Failed to render output.mp4"
;;
Darwin)
echo "Merging images into single video file: output.mp4"
ffmpeg -hwaccel auto -r 8 -i G%06d.JPG -c:v h264_videotoolbox -b:v 5M output.mp4 || \
die "Failed to render output.mp4"
esac
Eu não testei o código de macOS, então pode ser que não funcione. Meu PC atual, um Lenovo Thinkpad, é processador e GPU Intel. Eu tentei usar -hwaccel vaapi mas as cores saiam erradas, no estilo negativo de filme. Então deixei rodar no processador mesmo.
E pra comparar o resultado em mpeg comparado com o mesmo em gif:
░▒▓ …/tmp/imagens-webcam/Webcam2 via v3.12.3 (venv) 15:33
❯ gm convert -delay 20 *JPG output.gif
░▒▓ …/tmp/imagens-webcam/Webcam2 via v3.12.3 (venv) 15:38
❯ ls -l output.*
.rw-rw-r-- 209M helio 27 Nov 15:38 output.gif
.rw-rw-r-- 103M helio 27 Nov 13:54 output.mp4
A geração do gif demorou uma eternidade, 5 minutos. O ffmpeg foram só alguns segundos. O tamanho foi o dobro no gif. Pra ver a imagem, teria de carregar tudo e só depois ver o resultando. Como mpeg, vai enviando o vídeo aos poucos.
Eu finalizei o vídeo no kdenlive, fazendo o merge com o vídeo anterior e adicionando a música. Ficou uma nostalgia gostosa.
E com certeza atualizarei daqui alguns anos.

Eu resolvi melhorar a previsão e o modelo pra tal sobre o Linux no desktop, uma realidade inegável. Então escrevi algo em python pra fazer isso pra mim o trabalho e usar de algum modelo já pronto.
(venv) helio@goosfraba ~/D/linux-desktop-dominance-forecast (main)> ./forecasting.py
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2009-01-01 95.42 3.68 0.17 0.64 0.0 0.0 0.0
2009-02-01 95.39 3.76 0.14 0.62 0.0 0.0 0.0
2009-03-01 95.22 3.87 0.16 0.65 0.0 0.0 0.0
2009-04-01 95.13 3.92 0.17 0.66 0.0 0.0 0.0
2009-05-01 95.25 3.75 0.24 0.65 0.0 0.0 0.0
Playstation Other
Date
2009-01-01 0.08 0.02
2009-02-01 0.07 0.02
2009-03-01 0.08 0.02
2009-04-01 0.10 0.02
2009-05-01 0.09 0.02
Windows OS X Unknown Linux Chrome OS iOS Android \
Date
2024-01-01 73.00 16.11 5.33 3.77 1.78 0.0 0.0
2024-02-01 72.17 15.42 6.10 4.03 2.27 0.0 0.0
2024-03-01 72.47 14.68 6.52 4.05 2.27 0.0 0.0
2024-04-01 73.50 14.70 5.34 3.88 2.56 0.0 0.0
2024-05-01 73.91 14.90 4.87 3.77 2.54 0.0 0.0
2024-06-01 72.81 14.97 6.23 4.05 1.93 0.0 0.0
2024-07-01 72.10 14.92 7.13 4.44 1.41 0.0 0.0
Playstation Other
Date
2024-01-01 0.0 0.01
2024-02-01 0.0 0.01
2024-03-01 0.0 0.01
2024-04-01 0.0 0.01
2024-05-01 0.0 0.01
2024-06-01 0.0 0.01
2024-07-01 0.0 0.01
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/tsa/statespace/sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 11 M = 10
This problem is unconstrained.
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.00575D-01 |proj g|= 1.24633D+00
At iterate 5 f= -1.49635D-01 |proj g|= 1.77236D-01
At iterate 10 f= -3.64537D-01 |proj g|= 1.24837D-01
At iterate 15 f= -3.84843D-01 |proj g|= 1.22570D-01
At iterate 20 f= -4.20877D-01 |proj g|= 9.71167D-02
At iterate 25 f= -4.29351D-01 |proj g|= 1.13565D-01
At iterate 30 f= -4.33425D-01 |proj g|= 9.06436D-02
At iterate 35 f= -4.34142D-01 |proj g|= 3.98871D-02
At iterate 40 f= -4.36192D-01 |proj g|= 4.26757D-01
At iterate 45 f= -4.37801D-01 |proj g|= 6.82859D-02
At iterate 50 f= -4.37938D-01 |proj g|= 1.67285D-02
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
11 50 55 1 0 0 1.673D-02 -4.379D-01
F = -0.43793754789434586
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
/home/helio/DEVEL/linux-desktop-dominance-forecast/venv/lib/python3.12/site-packages/statsmodels/base/model.py:607:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
The year of Linux on the Desktop: 2036-11-30 00:00:00

Se ignorarmos os pequenos erros e avisos que aparecem, coisa pouca e irrelevante como valor divergir demais, podemos ver claramente quando o ano do Linux no desktop acontece: 2036-11-30
Então a previsão revisada é que logo estaremos em todos os lugares. Aguardem-nos!
E claro que publiquei isso tudo no GitHub:
E usei o seguinte artigo como referência (e código, diga-se de passagem):
Bom ano do Linux no desktop pra todos vocês.

Esses dias estava analisando um código que era parecido com shell script. Sua função era monitorar as interfaces de rede para, no caso de alteração (nova interface surgindo ou desaparecendo), registrar a mudança de objetos no sistema de dados do opensaf (objetos no IMM pra quem conhece).
Mas o código fazia algo parecido com um shell que a todo healthcheck do AMF (framework do opensaf que é muito semelhante ao systemd e roda determinado programa ou script de tempos em tempos) fazia uma busca com o comando "ip link addr list" e comparava com o que estava armazenado no IMM. Algo como:
def healthcheckCallback(self, invocation, compName, healthcheckKey): saAmfResponse(self.check_macs, invocation, eSaAisErrorT.SA_AIS_OK)
def check_macs(self):
macs = []
for line in self.get_link_list().split("\n"):
if not re.search("link/ether", line): continue
# [ 'link/ether', '52:54:00:c3:5d:88', 'brd', 'ff:ff:ff:ff:ff:ff']
mac.append(line.split()[1])
imm_obj = self.get_from_imm()
if imm_obj != macs:
self.update_imm(mac)
def get_link_list(self):
linux_command = "ip link list"
return self.run_shell(linux_command)
Essa é uma forma bastante simplificada pra tentar visualizar como tudo funciona. Eu propositalmente tirei comentários extras e deixei mais limpo apenas para poder comentar aqui.
Como a chamada pra buscar os dados junto ao IMM no OpenSAF tem muitas linhas, eu só deixei um get_from_imm() que retornará um array de mac registrados anteriormente. Se esse valor for diferente do coletado, então é chamado o método update_imm() com os macs que devem estar lá.
Funciona? Sim, funciona. Mas... se não houve nenhuma mudança nas interfaces de rede (como a subida de uma interface de VIP ou mesmo um container em docker), por quê eu preciso rodar o get_link_list()?
Entendeu qual foi meu ponto?
O código em si consiste em rodar o monitoramente separado numa thread. Toda vez que o código detecta uma mudança (na verdade o kernel sinaliza isso), ele altera uma variável que o programa lê durante o healthcheck. Algo como:
def check_macs(self):
if self.network_changed is False: return
Assim bem simples. Teve mudança? network_changed vira um True.
Linux tem mecanismos pra detectar uma mudanças na interfaces de rede. Por quê não usar? E foi o que fiz.
Criei um método chamado monitor_link() que é iniciado junto com programa no método initialize(), que é parte de como o AMF faz as chamadas de callback:
self.thread = threading.Thread(target=self.monitor_link, args=())
self.thread.start()
E como funciona o monitor_link()? Aqui tenho de pedir desculpas antecipadamente que enquanto o código utiliza menos CPU e memória que chamar um shell script, o tamanho e complexidade é bastante grande. No fim troquei 2 linhas de código por umas 35 linhas. Na verdade eu praticamente escrevi o código por trás do "ip link". Mas o resultado ficou independente desse comando e mesmo de utilizar um shell externo pra buscar o resultado.
A primeira coisa é criar um socket do tipo AF_NETLINK. Em seguida fazer um bind() num ID aleatório e monitorar com RTMGRP_LINK.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
pra gerar o código aleatório que é um inteiro, usei os.getpid() pra usar o PID do próprio programa.
Em seguida é iniciado um loop com select() em cima do descritor do socket pra leitura. Quando aparecer algum dado, daí sim a informação é lida.
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
O que vem a seguir são quebras da sequência de bits até chegar no ponto é possível ver o tipo de mensagem que chegou do select(). Se o tipo de mensagem for NOOP de algo nulo, apenas continue monitorando no select(). Se vier algum ERROR, pare o programa. Se vier mensagem e não for do tipo NEWLINK pra um link novo ou mudança de MAC, também continue aguardando no select().
if msg_type == NLMSG_NOOP: continue elif msg_type == NLMSG_ERROR: break elif msg_type != RTM_NEWLINK: continue
Por fim uma iteração nos dados pra buscar o tipo. Se o dado for do tipo IFLA_IFNAME, que é uma nova interface ou mudança de nome, ou IFLA_ADDRESS, que é MAC e endereço IP, muda a flag de network_changed pra True.
rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
E é isso. O código completo segue abaixo.
def monitor_link(self):
# Create the netlink socket and bind to RTMGRP_LINK,
s = socket.socket(socket.AF_NETLINK, socket.SOCK_RAW, socket.NETLINK_ROUTE)
s.bind((os.getpid(), RTMGRP_LINK))
while self.terminating is False:
rlist, wlist, xlist = select.select([s.fileno()], [], [], 1)
if self.network_changed is True: continue
if self.terminating is True: return
try:
data = os.read(rlist[0], 65535)
except:
continue
msg_len, msg_type, flags, seq, pid = struct.unpack("=LHHLL", data[:16])
if msg_type == NLMSG_NOOP: continue
elif msg_type == NLMSG_ERROR: break
elif msg_type != RTM_NEWLINK: continue
data = data[16:]
family, _, if_type, index, flags, change = struct.unpack("=BBHiII", data[:16])
remaining = msg_len - 32
data = data[16:]
while remaining:
rta_len, rta_type = struct.unpack("=HH", data[:4])
if rta_len < 4: break
rta_data = data[4:rta_len]
increment = (rta_len + 4 - 1) & ~(4 - 1)
data = data[increment:]
remaining -= increment
if rta_type == IFLA_IFNAME or rta_type == IFLA_ADDRESS:
self.network_changed = True
Encontrei essa implementação no Stack Overflow buscando informação do código em C. Foi uma grande ajuda e deixou meu programa muito mais coerente com o que eu realmente queria.
Ficou muito maior? Ficou. Mas também ficou muito mais 1337 :)
Mais:
[1] Exemplo de uso de python com AMF no OpenSAF: https://sourceforge.net/p/opensaf/staging/ci/default/tree/python/samples/amf_demo
[2] Projeto OpenSAF: https://sourceforge.net/projects/opensaf/
[3] Implementação original desse código: https://stackoverflow.com/questions/44299342/netlink-interface-listener-in-python

Tive de trabalhar nessa semana com um caso que me exigiu usar o pycurl no Python. O problema foi que escrevi um script que rodava baixando artefatos de build no Jenkins usando o módulo requests, e o mesmo não funcionava mais no Gitlab.
Depois de gastar um pouco de tempo no request, e usando o curl do exemplo do site do Gitlab, eu acabei desistindo e indo pra usar o pycurl no script. De cara descobri que não tinha pycurl instalado. E no MacOS não foi tão simples como poderia ter sido. A receita de bolo pra instalar o pycurl foi a seguinte sequência:
helio@MacOS> arch -arm64 brew install openssl curl helio@MacOS> export PATH=/opt/homebrew/opt/curl/bin:$PATH helio@MacOS> export LDFLAGS="-L/opt/homebrew/opt/curl/lib":$LDFLAGS helio@MacOS> export CPPFLAGS="-I/opt/homebrew/opt/curl/include":$CPPFLAGS helio@MacOS> arch -arm64 pip install --no-cache-dir --compile --ignore-installed --install-option="--with-openssl" --install-option="--openssl-dir=/opt/homebrew/Cellar/openssl@3/3.0.7" pycurl
Quando algo funciona em curl é fácil escrever o código em python. Basta rodar com o parâmetro --libcurl foo.c que ele joga o código em funcionou dentro do arquivo.c no formato pra linguagem C, mas é bem próximo do uso em python.
hnd = curl_easy_init(); curl_easy_setopt(hnd, CURLOPT_BUFFERSIZE, 102400L); curl_easy_setopt(hnd, CURLOPT_URL, "https://gitlab.[redacted]/api/v4/projects/[redacted]/jobs/[redacted]/artifacts"); curl_easy_setopt(hnd, CURLOPT_NOPROGRESS, 1L); curl_easy_setopt(hnd, CURLOPT_HTTPHEADER, slist1); curl_easy_setopt(hnd, CURLOPT_USERAGENT, "curl/7.86.0"); curl_easy_setopt(hnd, CURLOPT_FOLLOWLOCATION, 1L); curl_easy_setopt(hnd, CURLOPT_MAXREDIRS, 50L); curl_easy_setopt(hnd, CURLOPT_HTTP_VERSION, (long)CURL_HTTP_VERSION_2TLS); curl_easy_setopt(hnd, CURLOPT_FTP_SKIP_PASV_IP, 1L); curl_easy_setopt(hnd, CURLOPT_TCP_KEEPALIVE, 1L);
Em python:
url = "https://gitlab.[redacted]/api/v4/projects/[redacted]/jobs/[redacted]/artifacts"
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.BUFFERSIZE, 102400)
c.setopt(c.NOPROGRESS, 1)
if GITLAB_PRIVATE_TOKEN:
c.setopt(c.HTTPHEADER, [ "PRIVATE-TOKEN:" + GITLAB_PRIVATE_TOKEN ])
else:
c.setopt(c.HTTPHEADER, [ USERNAME + ":" + PASSWORD])
c.setopt(c.USERAGENT, "curl/7.84.0")
c.setopt(c.FOLLOWLOCATION, 1)
c.setopt(c.HTTP_VERSION, c.CURL_HTTP_VERSION_2TLS)
c.setopt(c.TCP_KEEPALIVE, 1)
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
E assim o código saiu funcionando.
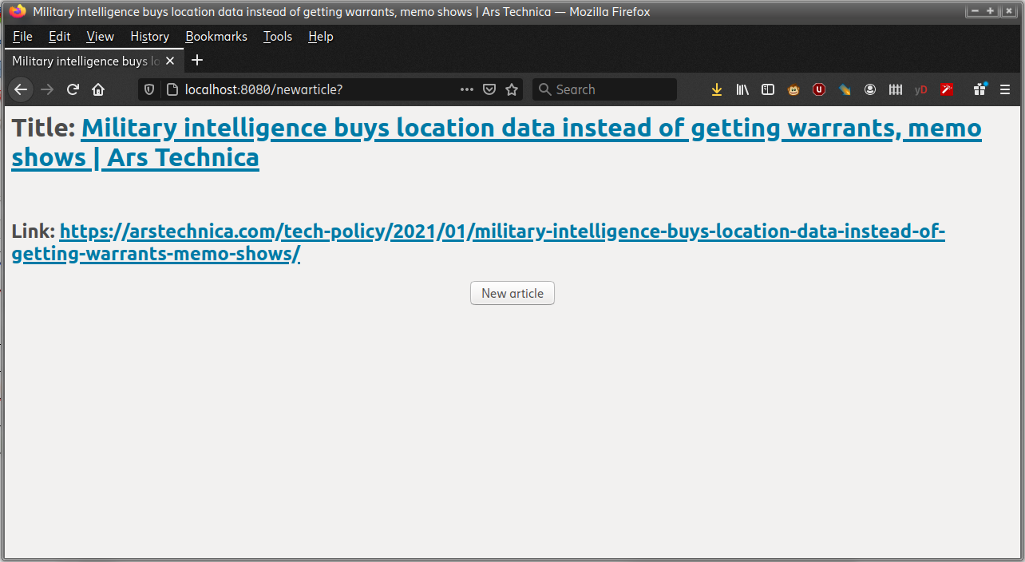
Toda vez que gravamos o Unix Load On (Canal Unix Load On), eu acabo fazendo uma seleção tosca do que vamos falar. Isso sempre me deu uma coceira de resolver. E nada melhor que o bom e velho Python.
Hoje eu coloquei as mangas de fora e fiz funcionar. No bom e velho modo script: rodo num shell, e pego o resultado. Mas cheguei no ponto em que gostaria de que isso estivesse disponível em modo web, pra eu poder mostrar durante o programa diretamente no browser.
O Python fornece o módulo SimpleHTTPServer, que aliás parece que no Python3 virou uma classe de http.serve. Mas tem. Ele mostra o filesystem via interface http a partir de onde você chama o módulo. Não deveria ser complicado fazer o output do meu script ir pra uma interface http. E realmente foi o que fiz.
def start():
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header("Content-type", "text/html")
self.end_headers()
client_ip, client_port = self.client_address
reqpath = self.path.rstrip()
print(f"request from {client_ip}:{client_port} for {reqpath}")
article = get_final_article()
title = get_title(article)
link = get_link(article)
response = f"""
<h1>Title: <a href="/{link}">{title}
<h2>Link: <a href="/{link}">{link}</a></h2>
"""
content = bytes(response.encode("utf-8"))
self.wfile.write(content)
Se leu com atenção vai ver que a linha do artigo eu pego em "article = get_final_article()". Isso retorna algo como:
* [Linux developers get ready to wield the secateurs against elderly microprocessors • The Register](https://www.theregister.com/2021/01/11/linux_olld_cpus/)
Dai o restante é sanitizar cada um pra mostrar corretamente.
O script todo pode ser visto aqui: https://github.com/helioloureiro/homemadescripts/blob/master/random_article.py
O resultado no console é algo parecido com isso aqui:
./random_article.py
127.0.0.1 - - [26/Mar/2021 21:31:27] "GET /newarticle? HTTP/1.1" 200 -
request from 127.0.0.1:46060 for /newarticle?
= Articles =
* /helioloureiro/canalunixloadon/blob/master/pautas/2016030.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016040.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016041.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016050.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016051.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016090.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016100.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016110.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2016120.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017010.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017020.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017030.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017040.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017060.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017061.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017070.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017080.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2017110.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2018030.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2018050.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2018060.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2018080.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2018100.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2019020.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2019040.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2019070.md
* /helioloureiro/canalunixloadon/blob/master/pautas/2019110.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20200717.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20200807.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20201001.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20201015.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20201029.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20201115.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20201204.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210121.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210205.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210215.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210312.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210325.md
* /helioloureiro/canalunixloadon/blob/master/pautas/20210410.md
Latest: /helioloureiro/canalunixloadon/blob/master/pautas/20210410.md
https://raw.githubusercontent.com/helioloureiro/canalunixloadon/blob/master/pautas/20210410.md
Article selected: * [Linux developers get ready to wield the secateurs against elderly microprocessors • The Register](https://www.theregister.com/2021/01/11/linux_olld_cpus/)
title: Linux developers get ready to wield the secateurs against elderly microprocessors • The Register
article: * [Linux developers get ready to wield the secateurs against elderly microprocessors • The Register](https://www.theregister.com/2021/01/11/linux_olld_cpus/)

Eu não sei bem o motivo, mas esse fim de ano o Google não mandou mais os dados totalizados de meios de transporte. E não tem mais como pegar os valores pelo browser. Só pelo app.
Eu queria saber quanto pedalei no total durante 2024. Então precisei fazer manualmente uma tabela e cálculo. Chato, mas nada de absurdo.
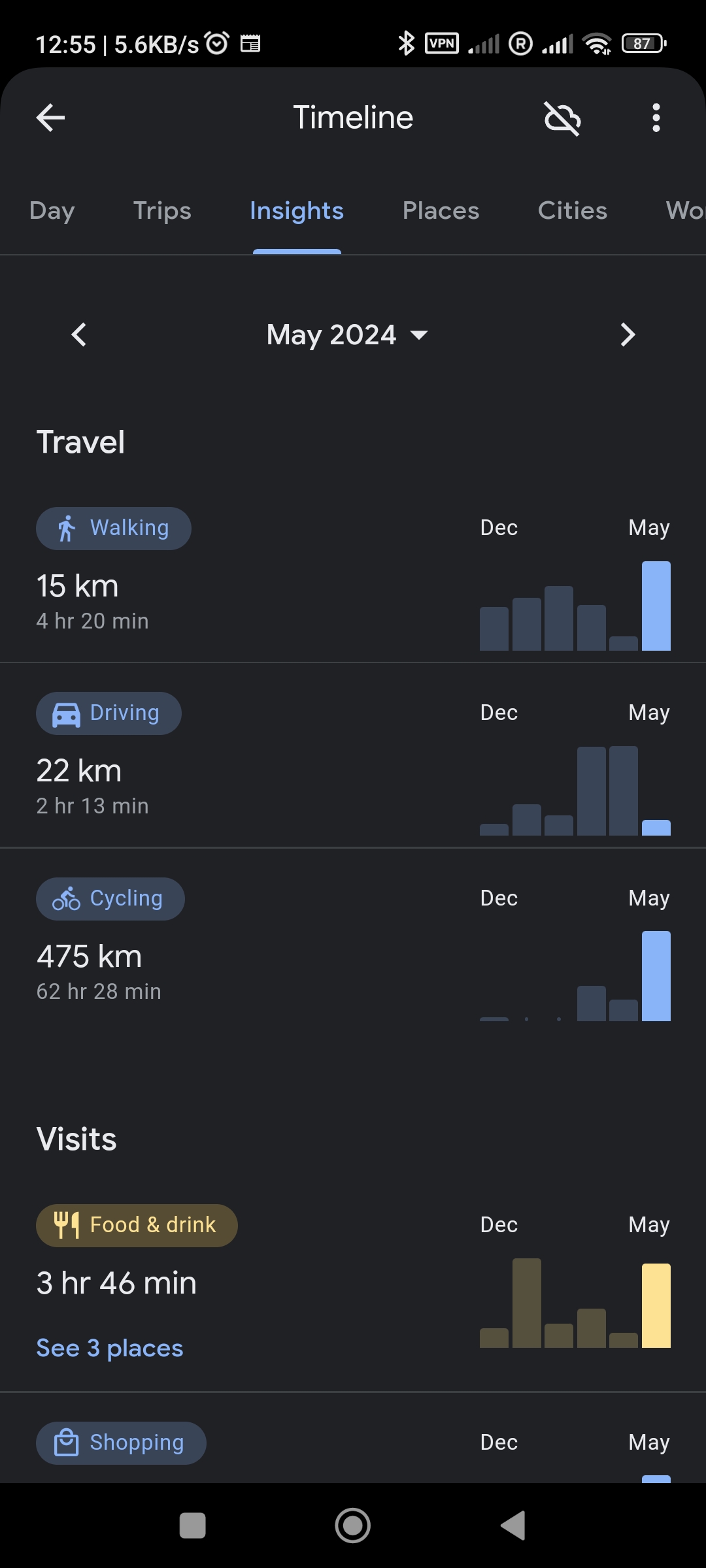
Os resultados foram os seguintes (dados em Km):
| Mês | Carro | Bicicleta | Transporte público | Avião | Motocicleta | Andando |
| Janeiro | 43 | - | 71 | - | 11 | 9 |
| Fevereiro | 28 | - | 182 | 2577 | - | 11 |
| Março | 124 | 187 | - | - | - | 7 |
| Abril | 125 | 113 | 33 | - | - | 2 |
| Maio | 22 | 475 | - | - | - | 15 |
| Junho | 1153 | 244 | 33 | - | - | 15 |
| Julho | 591 | 157 | 47 | - | - | 30 |
| Agosto | 220 | 254 | 31 | - | - | 7 |
| Setembro | 46 | 157 | 99 | 2173 | - | 25 |
| Outubro | 166 | 135 | 25 | - | - | 6 |
| Novembro | 173 | 130 | 116 | - | - | 14 |
| Dezembro | 512 | 113 | 20 | 10935 | - | 6 |
E fiz um programa em python, dentro do ipython, pra gerar os resultados (e também pra fazer depois essa tabela aqui em html):
In [48]: def soma_coluna(coluna):
...: soma = 0
...: for line in lines:
...: p = line.split("|")
...: try:
...: soma += int(p[coluna])
...: except TypeError:
...: pass
...: except ValueError:
...: pass
...: return soma
O resultados totais:
Confesso que fiquei decepcionado. Com 475 Km pedalados em maio, eu achei que ia bater os 3000 Km em 2024. Nem 2500 Km eu cheguei.
No artigo pedal forte de 2023 em dados do Google, é possível ver que também pedalei em torno de 2000 Km. Existe alguma divergência nos dados do Google, porque tenho 2 contas (uma free tier e outra paga), mas não acho que mudaria muita coisa. E não tive paciência de ficar catando dado mês-a-mês da outra conta.
Alguns dados parecem incorretos. Eu por exemplo não andei de moto em janeiro. Esse é o mês em que está tudo de baixo de neve na Suécia. Mas usei a moto pra ir trabalhar em outubro. Então pode ser que o dado da moto seja uma bicicleta na verdade (bem provável), mas e os dados da motocicleta devem ter ido parar na do carro em outubro. Não faria muita diferença nos dados totais.
