Já dizia Bezerra da Silva: malandro é malandro, mané é mané.
Na Internet não seria diferente. Eis que chega em casa um boleto de cobrança de um domínio *parecido* com um que administro. Achei um pouco estranho, pois em geral recebo notificação por mail, e do registro.br. Claro que é mais um empresário brasileiro tentando dar uma de malandro.

A empresa RegistraCom envia um boleto, com um domínio parecido com o seu existente, com os dados da empresa em que foi registrado (e que nunca divulguei) tentando ganhar um registro .com do seu domínio.
O texto dentro do boleto diz o seguinte (os negritos vêm do boleto):
Notificação de registro do domínio: helioloureiro.comSegue abaixo informações do Registro de domínio, por favor leia com atenção:Domínio: helioloureiro.comTitularidade: Empresa LTDACnpj/Cpf: 00001110000000Conforme nosso contato para atualização dos dados cadastrais, nossa área técnica identificou que o domínio helioloureiro.com (sob extensão .COM) encontra-se liberado para registro. Esta liberação pode ocorrer quando o pagamento não é realizado dentro do prazo, por disponibilidade efetiva de registro ou desinteresse na renovação.Como indentificamos que Empresa LTDA já possui o mesmo nome helioloureiro.com.br (sob extensão .com.br), é importante que registre imediatamente o domínio (sob extensão .COM) evitando que um terceiro venha registrá-lo.O valor do registro é de R$ 60,00 por um período de 1 ano.Após identificarmos o seu pagamento o registro será realizado em um prazo máximo de até 48hs, incluindo a configuração de redirecionamento, ou seja, quando acessado helioloureiro.com o visitante será redirecionado para o site helioloureiro.com.brCaso não haja interesse, o domínio helioloureiro.com continuará disponível e o mesmo poderá ser registrado por um terceiro a qualquer momento.
Se lido atentamente, é informado que o boleto é um "registro" do seu domínio .COM. Claro que a intenção é isentar de qualquer acusação, afinal, foi informado o que era. Mas é nítida a tentativa de golpe, tentando se passar por um registro de domínio legítimo.
Provavelmente quem registra seus próprios domínios, como eu, não cai nesse golpe. Mas e empresas médias e grandes? Em geral quem recebe tais boletos é o pessoal de controladoria/contabilidade. Alguém duvida que o contador da empresa vai perceber essa sutil diferença? Ou vai apenas pagar o valor, 60 reais, que é irrisório pra uma empresa média pra cima, e nem perceber quando o boleto verdadeiro chegar, e pagar novamente? Então é claro que o boleto é golpe.

A empresa "RegistraCom", que aparece no whois como pertencente à empresa "WebVisão", ambos registrados pela mesma pessoa, já tem queixas no reclamar. A resposta, claro, é a mais cara de pau possível.
Esse tipo de golpe já apareceu outras vezes na lista do GTER, da empresa RegistraBrasil. Mas como aqui é Brasil, terra da malandragem, eis que aparece outro gênio pra arrasar com os manés.
E depois reclamamos dos políticos. Esses são realmente apenas um reflexo de seu povo.
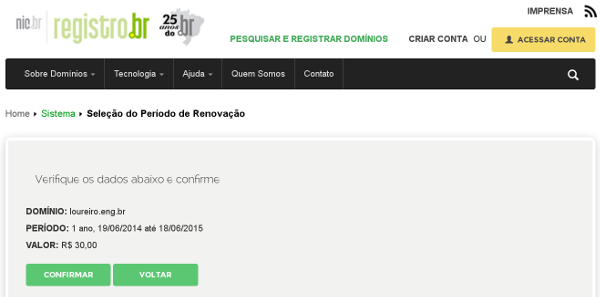
E esse é o sistema de geração de boleto do registro.br. Sem fraudes.

Com a recente mudança do DropBox, que permitiu a entrada da Condoleezza Rice em seu quadro de diretores, acho que realmente é hora de dizer adeus. O site Drop-DropBox deixa isso bem claro:
Apesar de toda gritaria em relação à privacidade, eu sempre fiz uso de armazenamento em nuvem. Seja do DropBox, seja do UbuntuOne, que também anunciou sua saída desse mercado. Em geral eu salvo coisas que não exigem privacidade ou sigilo como vídeos do celular, artigos, e revistas eletrônicas, como as revistas Espírito Livre e BSD Magazine, para poder ler depois no tablet. A única exceção de confidencialidade é que guardo meu chaveiro digital do KeePassX lá, pois preciso que o mesmo esteja disponível em todo lugar. E espero que a senha pra destravar o mesmo seja suficiente pra garantir minha segurança contra a NSA ou quem quer que seja...
Com esses requisitos na cabeça e um computador na mão, sai buscando alternativas tanto pro DropBox quanto pro UbuntuOne. Dei uma olhada, claro, no owncloud. O problema dele é ter o servidor disponível. Eu até poderia usar o desktop de casa pra isso, mas no momento ele está a mais de 10.000 Km longe de mim e meu link com ele é só via IPv6, o que não o torna muito viável pra acesso no meu smartphone e meu tablet. Então eu ainda preciso de um servidor de terceiros.
Foi quando achei uma recomendação de migração pro Box.Com, que oferece 10 GB de espaço. Isso seria o suficiente pra acomodar todos os meus arquivos tanto do DropBox quanto do UbuntuOne. Agora era o segundo desafio: como copiar os dados?
Tanto o DropBox quanto o UbuntuOne têm uma maneira muito simples de replicar os dados: basta instalar o aplicativo e copiar os dados nas pastas designadas pra ter a replicação. E pronto! E o Box.Com?
O Box.Com não tem aplicativo cliente pra Linux. Esse já era um ponto pra descartar, mas... encontrei uma solução até simples.
How to mount Box.com cloud storage on Linux
Com isso, segui os passos e instalei o pacote davfs2, criei uma entrada em ~/Box.Com e fui movendo meus arquivos dos diretórios do DropBox e do UbuntuOne pra ~/LocalBox.Com, em GoodByeDropBox e GoodByeUbuntuOne, pra ir sincronizando as nuvens de que os arquivos foram removidos. Por que não movi direto pra dentro do ~/Box.Com?
Pelo motivo que essa montagem de dispositivo realmente cria uma partição remota. Ao "desmontar" a mesma, os dados não ficam acessíveis. Então só monto a mesma pra sincronizar os arquivos. Mas existem problemas. De tempos em tempos aparecem erros no sincronismo, que uso "rsync" pra fazer:
helio@elx3030vlm-78:LocalBox.Com$ rsync -auc GoodByeDropBox ../Box.Com/ rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.DI-524_traffic.pl.51cQSZ" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.WGR614v7_traffic.pl.2VEgLG" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.admin-linux-br.pJj79O" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.adsl_check.py.fNvPNz" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.bin2iso.RbTw54" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.block_3GRouter.py.0KawJP" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.block_3GRouter.py~.6IOAnA" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.check-spam-clean.sh.iNFK1k" failed: Invalid argument (22) rsync: mkstemp "/home/helio/Box.Com/GoodByeDropBox/bin/.check_myip.sh.i1MZF5" failed: Invalid argument (22) rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1070) [sender=3.0.9]
E devia ter usado "tar" pra fazer o sincronismo, mas eu não queria ocupar toda banda, pois tenho somente um 1 Mbps de upstream. E esse é outro problema: não existe nenhum controle de banda pra download ou upload. Com isso, vez ou outra o link fica inutilizável e a partição simplesmente... morre! Não é possível nem ler, nem escrever. Nem "ls" funciona. E isso acaba exigindo um "kill" no mount pra fechar tudo e abrir novamente.
Por enquanto o sistema está muito, mas muito novo, e sem grandes comparações de melhoria. Mas há possibilidades. Com a liberação do código fonte do UbuntuOne, talvez seja possível criar um aplicativo cliente melhor, com possibilidade de verificação de mudança e atualização remota. Mas isso é apenas suposição. Nada de concreto até agora.
No momento, o que posso dizer é: adeus DropBox, longa vida ao Box.Com.


Hoje apareceu essa imagem no facebook (sim, uso facebook e muito) e me fez lembrar de uma situação que aconteceu durante meu período como consultor, quando vivia em Floripa. É praticamente um conto, mas acho que serve pra ilustrar que algumas coisas não se negociam e, entre elas, o seu valor pelo trabalho.
Como eu vivia em Florianópolis, era (e ainda é) fácil encontrar mão de obra por causa das universidades da região, seja da própria UFSC, seja da UDESC, ou até mesmo da federal de Joinville. Fácil e farta. Não faltava gente que não soubesse instalar Linux. Hoje deve ser mais fácil ainda, já que a instalação é algo trivial. Mas naquela época eu estava me especializando em fazer migração de servidores que rodavam o Unix SCO pra Linux ou FreeBSD. Meu predileto era FreeBSD, que era mais fácil de manter que Linux, já que não tinha Internet fácil ou rápida em todo lugar. E a compatibilidade binária pra rodar SCO era melhor, quer dizer, menos problemática.

Mas eram épocas de Conectiva, que estava em destaque com seu 4.0. A caixa preta dava mesmo um visual de superioridade, de diferencial, de estilo de vida, de "sou maneiro, sou réquer", e as pessoas queriam usar Conectiva Linux em seus servidores. Se não fosse FreeBSD, eu preferia Debian, mas Debian nunca teve o appeal de marketing que uma Conectiva tinha na época. Eu usava Debian, mas era fã daquele visual do Conectiva. Era impossível não ser.
Então eu tinha esse cliente, que era uma concessionária de carros. A concessionária tinha a matriz, em Floripa, e várias filiais localizadas em outras cidades. Algumas distantes (acho que em Chapecó, extremo oeste de Santa Catarina). Depois de muito conversar, convencer, negociar, e testar, ele topou a migração de seu sistema de SCO pra Linux. Foi complicado, pois as filiais eram interligadas via LPCD, uma linha dedicada alugada da empresa de telefonia (TELESC na época) que funcionava via serial em velocidade de 9600 bps ou acima disso, mas não muito. E nem eram bits por segundo, eram bauds :-D
A configuração do aplicativo migrado do SCO foi bem fácil. O que me deu muito trabalho foi acertar as linhas seriais, que eram conectadas ao servidor via placa multiserial da Cyclades (alguém lembra disso?). Em cima da placa eu tinha as conexões ppp, que eram configuradas diferentemente, pois cada LPCD tinha uma característica. Não era o mais difícil, pois as linhas seriais eram assíncronas, abaixo de 64 kbps, mas não era fácil.
Na época não existia nada formal pra backup. Unidades de gravação de CD eram caras e, por isso, raras. Unidades de fita? Isso era coisa de empresa grande ou universidade. Então pra contornar o fato do cliente poder fazer alguma barbeiragem com o sistema instalado, eu fazia um backup das configurações do "/etc" usando RCS. Era tosco, mas funcionava e sempre me livrava do cliente que dizia "mas eu não mexi em nada". E me salvou inúmeras vezes.
Então veio o dia fatídico. E esses dias sempre acontecem numa sexta-feira, em geral perto das 5 da tarde. O cliente me ligou dizendo que tinha tido um "crash" no HD e precisa reinstalar tudo, pois, como eu já descrevi antes, não tinha backup. Hoje, olhando pra trás, eu sinto que éramos barnabés da informática, pois nem um pendrivezinho tinha pra fazer backup naquela época. Claro que tínhamos os disquetes de 1.44 MBytes, mas aquilo já ninguém usava. Pra complicar mais o meio de campo, o cliente ainda avisou que precisava rodar o faturamento na segunda-feira, que era fechamento do mês.
Como de cabeça já imaginei um fim de semana perdido, instalando servidor, reconfigurando e passando o domingo verificando conexão com as filiais, já pedi um valor alto. Não lembro quanto foi, mas diria que foi uns 3 mil reais. Como o valor era alto, muito mais que eu costumava cobrar pra esse tipo de atividade, ele me pediu pra pensar, pra comparar preços com outros consultores. Lembro de ter avisado que tudo bem, mas só ia esperar até perto das 7 da noite e, se fosse embora, não ia mais atender ele durante o fim de semana.
Perto do horário de deixar a empresa e ir pra casa, eis que ele me liga. Queria fechar comigo o serviço, mas estava muito caro. Seria possível negociar? Expliquei pra ele o quanto seria ruim para mim perder fim de semana por causa dele, pela urgência, e tudo mais. Mas então ele veio com o argumento que determinou a negociação:
- Mas tem um rapaz da faculdade que disse que faz por R$ 300,00. Não dá pra fazer pelo mesmo preço? Afinal é só instalar o Linux...
Fiquei calado por uns 10 segundos. A dúvida é se o mandava à merda, ou alguma outra forma de extravasar o desprezo que surgiu em mim. Mas respirei fundo e disse:
- Se ele pode fazer por 300, eu não consigo competir com esse preço. Por favor, faça o serviço com ele. Fico feliz que tenha encontrado alguém que possa atender melhor que eu, e com valores mais baixos.
E claro que fiquei muito, mas muito puto. Tanto que lembro da história até hoje. Mas fechei as coisas e fui pra casa.
Sábado foi um dia tranquilo, com direito à praia, camarão e cerveja. Domingo não foi muito diferente. Não muito? No fim do domingo comecei a receber as ligações do cliente. Como ele não tinha nenhum contrato comigo, não atendi.
Segunda-feira começou cedo. Por volta das 7 da manhã ele já me ligava. Imaginei que estava desesperado, e que algo tinha dado errado, mas muito errado. Tomei calmamente meu café, enquanto o celular se retorcia em cima da mesa, com o toque em modo vibração somente.
Por volta das 9 da manhã atendi o cliente. Era catástrofe pura. Tudo tinha dado errado, o sistema não tinha funcionado, o del não dava del, o windows não fazia windows, o enter não dava enter, e assim por diante. Perguntou carinhosamente se eu poderia atendê-lo ainda. Respondi positivamente:
- Claro, mas agora o valor é R$ 5.000,00.
- Mas você tinha dito 3000????
- É que agora eu preciso arrumar a bagunça que ficou aí. Mas se não quiser, pode procurar outra pessoal.
Eu gostaria de terminar a história com "e ganhei todo esse dinheiro e fiquei super feliz", mas eu realmente não lembro o final. Eu acho que ele não topou. Só lembro que nunca mais entrou em contato depois disso.
E eu? Eu realmente não sinto, até hoje, a menor falta de ter ganhado esse dinheiro. Mesmo. Só o fato de ter recebido a ligação na segunda-feira valeu mais que qualquer outra coisa.

2014 começou muito bom para mim e com mudanças importantes. Nesse ano estou deixando de trabalhar com integração, o que significava mais instalação e adaptação de sistemas, pra trabalhar em desenvolvimento puro. Isso pra falar só da parte básica da mudança, pois ela também inclui uma mudança de país, com toda a carga de alterações que a envolvem: família, língua, o que fazer com o que ficou pra trás, vender, alugar, etc.
Mas tirando a parte do stress normal que é relativo a qualquer mudança, e por pior que possa parecer é sempre positivo, a mudança no ambiente de trabalho me colocou diretamente em projetos de software livre. E não somente livre, mas software de alta disponibilidade.
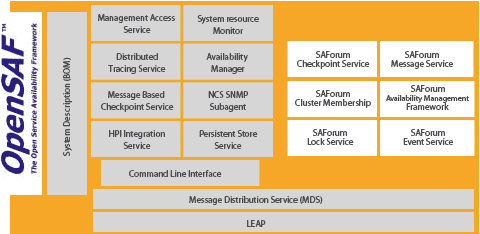
![]() Estarei trabalhando junto com o framework do OpenSAF. Antes de perguntarem mais sobre o mesmo, eu não sei muito. Estou aprendendo, e aprendendo devagar, pois é um assunto muito extenso.
Estarei trabalhando junto com o framework do OpenSAF. Antes de perguntarem mais sobre o mesmo, eu não sei muito. Estou aprendendo, e aprendendo devagar, pois é um assunto muito extenso.
OpenSAF, ao contrários de outras soluções, é mais voltado para alta disponibilidade de aplicação, não de sistema operacional. A base, claro, é totalmente em Linux, e qualquer Linux (distro, quis dizer distro). Mas até onde vi, ele é mais voltado para Suse e RedHat, pois boa parte de seus pacotes está em RPM.
Falando em RPM, esse agora passou a fazer parte do meu dia à dia. Trabalho muito mais com criação de .SPEC para geração dos mesmos que pacotes .DEB. Mas faço isso em cima de um sistema Ubuntu :-)
Tenho aprendido bastante sobre LSB e como gerar um sistema dentro dos requisitos da mesma, o que não é fácil. Muito pacotes de software livre simplesmente dão crash por falta de alguma biblioteca mais atualizada ou mais genérica. Isso pra não falar dos #ifdef dos headers .h em C.
Eu já dei uma procurada sobre aplicativos ou sites que façam uso do OpenSAF, pra poder entender um pouco mais e verificar seu uso fora do ambiente de telecomunicações, e acabei descobrindo que a mediawiki faz uso.
https://www.mediawiki.org/wiki/User_Guideline_for_Trace_and_Log
Eu gostaria de achar mais exemplos de uso, já que é uma ferramenta de software livre e extremamente poderosa, mas infelizmente é difícil encontrar. Aparentemente não fui só eu que achei complexa a configuração dele. Apesar disso, o framework suporta código em java, C, C++, Python e Erlang, entre outros. Não que não tenha mais coisa, mas não apareceu ninguém pra fazer o port. Eu tenho trabalhado mais na parte de python do sistema, mas não o suficiente pra fazer um commit oficial. Não ainda. Mas espero em breve conseguir fazer isso. Espero...

Pra agitar um pouco mais as coisas na empresa, e trazer um pouco de inovação no modo de pensar e trabalhar, preparei um coding dojo.
Os desafios, peguei de dojopuzzles.com, que é um .com mas o conteúdo é totalmente em português, mas nada que um google translator não resolvesse pra usar em inglês.
Faltava um contador e um semáforo pra ver o estado do código. Procurei pelos relógios/cronômetros de pomodoro, mas não achei um que realmente me agradasse. Existem várias soluções, mas muitas são pequenas demais pra apresentar numa tela projetada.
O semáforo, encontrei depois a solução do Danilo Bellini, o dose, que é escrito em python com wxwindows. É uma boa solução, mas ainda faltava o cronômetro.
Foi então que resolvi botar a mão na massa e criar meu próprio sistema. Usei PyQT pra desenhar a janela principal. Claro que não fiz tudo na mão: eu usei o qt4-designer pra agilizar tudo e deixar quase pronto, deixando o python pra somente pegar os valores e interagir o mínimo possível.

O sistema ainda precisa de umas melhorias, com certeza. Ele é burro ao ponto de ficar em loop rodando com python a cada 5s todo arquivo que estiver lá. Então eu preciso melhorar pra poder usar outras linguagens além de python. Nisso eu vi que a solução do Danilo é mais inteligente, pois usa um "watchdog()" pra verificar se houve mudança no arquivo antes de rodar. Então já inclui no "roadmap" tentar implementar isso. Também achei que faz falta um som ou alarme pra avisar do tempo. Vou ver se consigo incluir um do tipo do NBA, que vai tocando quando o tempo está acabando (a partir de 10s). Isso vai dar mais "visibilidade" durante os dojos.
Quem quiser participar, ou só dar uma olhada, o código está no github: codingdojocontrol

Não costumo entrar em política por aqui, nem mesmo muito fora daqui, mas o caso do marco civil da Internet pede um certo envolvimento. Conforme os limites do digital e do real ficam menos tênues, é impossível não comentar de ambos, mesmo que isso envolva política, mulher, religião ou futebol, os pilares que sustentam a nossa sociedade.
Mas não vou comentar sobre os aspectos do marco civil. Já existem muitos sites falando sobre o mesmo. Claro que existem os que falam contra, como sempre, mas o melhor é se informar sobre o assunto. Eu pessoalmente recomendo o post do Sakamoto:
Marco Civil: se disserem que a lei é para censurar e espionar, não acredite
Mas o que queria abordar aqui é uma outra parte do marco civil, em relação ao artigo 16, que fala da guarda de logs.
O que me levou a escrever sobre isso foi um post do Paulo Rená sobre esse tema:
Snowden pede criptografia, mas art. 16 seria tiro pela culatra
A parte do artigo 16 do código civil, como até é comentado no artigo, diz:
O provedor de aplicações de Internet constituído na forma de pessoa jurídica, que exerça essa atividade de forma organizada, profissionalmente e com fins econômicos,deverá manter os respectivos registros de acesso a aplicações de internet, sob sigilo, em ambiente controlado e de segurança, pelo prazo de seis meses, nos termos do regulamento.
E está feita a confusão. Então vou tentar explicar de forma técnica, e não vou entrar no mérito do direito, pois nem tenho conhecimento pra tal. É apenas o que existe e o que isso significa, e o motivo de estar no marco civil.
Todo serviço que envolve bits, TODO, tem um serviço de registro, ou como chamamos, log. TODO. Quer dizer então que quando me conecto ao provedor e recebo um endereço IP, isso fica num log. Quando envio um mail, isso fica num log. Quando entro aqui no meu site, pra escrever esse post, isso fica num log.
Como exemplo, um registro de mails que tenho num servidor que ajudo a manter:
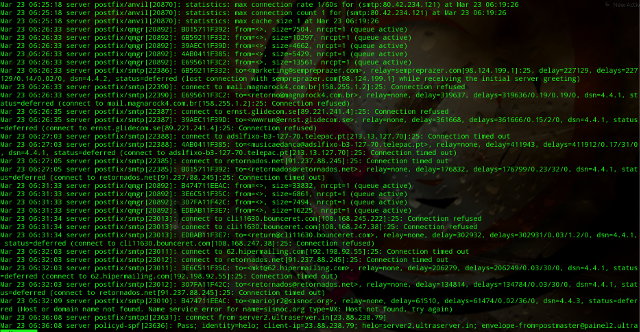
Os IPs são reais, assim como os domínios que se apresentam aqui (a maioria mails falsos de SPAM). Ao contrário do que se comenta por aí, não existe uma monitoração do conteúdo. Mas se eu tenho acesso ao servidor, eu posso muito bem olhar o conteúdo de tais mails, por mais que minha conexão seja criptografada com o mundo exterior. Mas isso já é tema pra um outro post.
E servidor de web? Sim, tem log. E não muito diferente dos logs do servidor de mail.
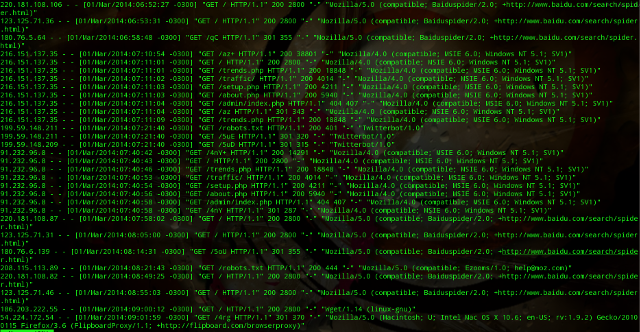
Como se pode ver, não existe muita informação além de IP de origem, página que se tentou acessar, se deu certou ou não, e o tipo de navegador usado. Esses dados são importantes pra se verificar páginas erradas, falhas em navegadores, e audiência.
E claro, ataques! Foi esse um dos princípios pros quais os logs surgiram. Quando se sofre um ataque, a primeira coisa que se procura, é nos logs. Sempre.
E essa é a questão do marco civil Até quando guardar esses logs? Infinitamente? 6 meses? 2 anos? 5 anos? 10 anos? Quem pode acessar? Como? Pode ser usado pra vender um produto e/ou serviço?
Então quando se fala das questões de logs, não é sobre o governo monitorar todos, mas sobre os registros que já existem, sobre como vamos lidar com eles. E a menos que se opte for ferramentas para garantir sua privacidade como TOR, não existe conexão anônima. Nunca.
E sim, eu violei o sigilos do meus logs. Espero que os cidadãos afetados não me processem, pois foi pra fins didáticos.

Eu tenho dito e repetido que as discussões passaram das lista de mail pras redes sociais. Infelizmente as melhores discussões, aliás, os melhores grupos estão no FaceBook. Acho que faz parte do amadurecimento das tecnologias em torno das redes sociais. Nada mais de mail, nada mais de irc, o lance do momento é rede social.
Numa das discussões do grupo Debian Brasil surgiu uma questão sobre o logo do Debian: é o logo baseado no queixo do Buzzlightyear ou o queixo do Buzz que é baseado no logo? Essa pergunta me fez garimpar o site do Debian e acabei encontrando umas informações bem interessantes, pra não dizer divertidas, sobre o logo.
Já faz mais de 10 anos que conhecemos o Debian com seu logo atual, uma espiral. Mas quando o novo logo do projeto foi escolhido, pra trocar o anterior que era um pinguim estilizado, entre os concorrentes existiam símbolos como uma formiga. uma foca e até mesmo uma... galinha?
Na época, 1999, o Debian já contava com 509 desenvolvedores, mas apenas 184 votaram, dos quais 143 não contabilizados por problemas nas chaves PGP, 3 com conflito por votos duplicados, e somente 143 votos válidos. Então temos o logo que existe hoje no Debian por 143 votos!
Entre os logos concorrentes, em ordem de votação:
1º Espiral: ![]()
2° DB: ![]()
3º Logo anterior: ![]()
4° Espiral modificada: simplesmente uma modificação sobre o logo da Espiral, sem a garrafa (que se tornou na verdade o símbolo mesmo).
5° Galinha: ![]()
6° Mais discussões sobre modificações na formiga ou na foca.
7° Formigas: ![]()
8º Foca: ![]()
O sistema de votação permite a escolha, mas também sugestões de melhorias, como pode ser visto nas colocações 4º e 6º respectivamente. Mas o que achei mais engraçado é que no fim, o logo que todos conhecemos, acabou sendo decido por 143 pessoas somente. Como diria Frank Underwood, da série House of Cards do NetFlix: democracy is so overrated (democracia é tão superestimada).
Hoje o Debian conta com 957 desenvolvedores (estatísticas de julho de 2013), praticamente o dobro da época em que foi feito a votação do logotipo novo. Será que o resultado seria diferente? Aliás, será que teríamos somente esses logos como opção?
Sobre o queixo do Buzz e o logo do Debian, possivelmente não tem relação. O filme Toy Story foi lançado em 1995. O logo, em 1999.
[1] Grupo Debian Brasil no FaceBook
[2] Grupo Software Livre Brasil no FaceBook

Eu falo e escrevo muito sobre modelos de competitividade de software livre, sobre negócios, sobre como fazer do software livre um modelo de negócios sustentável. Mas confesso que isso eu não tinha percebido, sobre o systemd.
Assim como quase todo mundo da área de Linux que conheço, o assunto da adoção do systemd por parte do Ubuntu passou por mim mais como decisão técnica que qualquer coisa. Participei de discussões sobre funcionalidades e, o que era o principal para mim, sobre os benefícios do mesmo. Como quase todo mundo, fiquei feliz pelo Ubuntu seguir o Debian e ainda, declaradamente, se dizer fazendo parte do ecossistema do mesmo.
Mas eu estava errado. Redondamente errado. Milhões de dólares errado. Ou seriam bilhões?
Por um acaso muito grande, acaso mesmo pois eu já tinha lido e re-lido vários artigos e posts sobre Ubuntu e systemd, eu topei com um artigo do Steven J. Vaughan-Nichols na ZDNet:
After Linux civil war, Ubuntu to adopt systemd
Boa parte dele descreve sobre Ubuntu adotar o systemd, benefícios e o quanto isso teria de impacto em relação ao upstart. Nada de novidade aí. A maioria dos outros artigos trata em geral da mesma coisa, alguns mais profundamente, outros com traduções bem toscas. Mas todos basicamente falando o mesmo.
Então Steven escreve a pérola do artigo:
This conflict is part of a greater fight between Canonical and Red Hat over the future of Linux. Another argument, still ongoing, is whether the X Window System -- the foundation of Unix and Linux's graphics system -- should be replaced by Ubuntu's Mir or Red Hat/Fedora's Wayland.
Senti aquela epifania típica de uma grande revelação.
Era óbvio. Sempre foi. Canonical está numa luta acirrada com a Red Hat pelo futuro do Linux. Ambas tentando dominar a tecnologia que estará nos desktops e servidores das próximas gerações. O código, sempre aberto, é apenas uma parte de um todo. Existe toda uma estratégia pra se abocanhar uma fatia de mercado.
Nós, meros usuários, não somos o alvo, mas sim o mercado de cloud e de servidores. A Canonical tenta ganhar o gosto dos usuários (e sysadmins) com uma interface semelhante através de vários dispositivos, o unity. Hoje falamos de computadores e laptops, mas amanhã possivelmente será sobre tablets, smartTVs e smartphones.
RedHat, por sua vez, tenta impor sua dominação tecnológica pra manter seu mercado de servidores corporativos e do recém chegado mercado de cloud. Sua vantagem competitiva está na marca de ser uma empresa tipicamente "open source" e que contribui pra comunidade. Claro que os benefícios do retorno desse investimento se fazem claros por sua fatia de mercado e pelo relatório financeiro do último ano, que mostra um lucro líquido na casa de milhões de dólares.
Então quando pensar em systemd x upstart, ou wayland x mir, não pense em comunidade, não pense em código aberto, pense onde está o dinheiro. Quem vencer, terá toda uma comunidade pra suportar.

Na última edição da newsletter do site Netcraft, vi uma estatística sobre o uso do Apache webserver que me deu um frio na barriga. Assim como o clássico americano "o último dos moicanos", parece que estamos vivendo tempos de extinção também de projetos open sources.
Não, o projeto Apache não está acabando.

De acordo com as estatísticas de servidores web no ar, coletada mensalmente pela Netcraft desde quando eu soube o que era Internet (na verdade desde que eu soube o que era Linux), mostra que o uso do Apache nunca esteve num patamar tão baixo de uso. Os dados se comparam com os de 1995! Ou seja, depois de quase 20 anos reinando como o melhor webserver de todos, desbancando até os servidores proprietários da época como o da NCSA (era o Netscape?) e da própria Sun, agora o Apache vê seu rival IIS pronto pra tirar seu pódio e se tornar o mais usado servidor web.
Parte da culpa disso, é claro, vem da adoção do cloud da Microsoft, o Azure. Tem também a parcela de crescimento do "new kid on the block" do pedaço, o nginx. Mas parece ser inevitável uma mudança no comportamento de uso dos servidores web, trocando o open source pelo proprietário.
As consequências podem ser as piores possíveis, indo da diminuição de contribuições ao projeto Apache, o que talvez leve a um total abandono de seu uso, até o risco da Microsoft enfiar algum serviço proprietário web, como um protocolo fechado, que só funcione em servidores IIS/Azure com browser Internet Explorer (vide protocolo do Exchange Server com o Outlook, o MAPI). Esse risco sempre existe quando se trata de Microsoft, que não pensa duas vezes em criar barreiras de uso pra aprisionar ainda mais seus usuários.
Por outro lado mostra também que a grande maioria dos desenvolvedores estão migrando pra web. E infelizmente trazendo as péssimas práticas que aprenderam nas escolas, aquelas que têm todo um parque de ferramentas e máquinas doados pela Microsoft.
É triste de ver...
Quem passou por aqui nesses últimos dias com certeza notou que o site tava uma zona. Tava sem formatação, sem logo, às vezes sem nada. Como se diz "em casa de ferreiro, o espeto é de pau", por aqui não é diferente e resolvi aplicar uma atualização no Joomla sem fazer backup. Metodologia #XGH está no sangue, não dá pra evitar. O upgrade simplesmente acabou com o funcionamento do template que estava o site. Fiquei essa semana toda tentando arrumar o template, e ao mesmo tempo experimentando alguns outros. Mas buscar "template free joomla" na Internet é quase uma busca pelo santo Graal. Quase tudo é pago, feito de "windows users" para "windows users" e pouco coisa sai da forma que se deseja. A menos que pague por um serviço de consultoria.
Mas sou brasileiro, no exterior é verdade, então não desisto nunca. Achei um template legal e fui acertando, arrumando os pontos, as posições e agora está com uma cara aceitável. Pelo trabalhão que deu, espero não precisar ter de fazer isso novamente tão cedo.
Ou talvez aprender mais como fazer um design bonitinho de site pra não ter de depender de outros. Afinal não uso mesmo tanta coisa assim.

Nada como começar 2014 com um post sobre nvidia. Não que 2014 tenha começado agora, mas não tive muito assunto pra escrever até o momento (na verdade tive, mas a inércia de 2013 foi mais forte).
Estou trabalhando num ambiente que usa pesadamente linux containers, os lxc, que é uma forma de virtualização. Pra minha triste surpresa, muitas funcionalidades não ficam ativas no lxc com o kernel-pf. Então resolvi voltar pro bom e velho kernel Linux padrão, baixado diretamente de https://www.kernel.org
Compilação feita, com parâmetros pra funcionamento dos linux containers (é preciso ativar cgroups em toda sua funcionalidade) e, antes do boot, aparece um upgrade dos drivers da nvidia. Já que ia fazer um reboot, resolvi fazer tudo de uma vez.
O boot do kernel linux-3.13.0-helio.3 (3ª versão, as outras duas ou eu esqueci algo, ou falhou em algum parâmetro que deixei fora) foi tranquilo mas o Xorg... esse subiu com noveau, bem inferior ao drive da nvidia. Ao tentar carregar o módulo da nvidia manualmente, pra descobrir qual o problema, surgiu a seguinte mensagem:
[ 89.005614] nvidia: Unknown symbol acpi_os_wait_events_complete (err 0)
[ 386.837191] nvidia: Unknown symbol acpi_os_wait_events_complete (err 0)
Procurando pela Internet, descobri que justamente o pacote novo da nvidia, nvidia-331 (ou nvidia-331_331.38-0ubuntu0.0.1~xedgers~precise2_amd64.deb), tem esse erro com kernels 3.13, pois a função EXPORT_SYMBOL(acpi_os_wait_events_complete) foi removida do mesmo.
A correção não é muito complexa. Basta aplicar a seguinte correção dentro de "/usr/src/nvidia-331-331.38", que foi criado durante a instalação do pacote:
--- nvidia-331-331.38/nv-acpi.c.orig 2014-01-21 11:44:59.485055493 +0100
+++ nvidia-331-331.38/nv-acpi.c 2014-01-21 11:44:22.664056579 +0100
@@ -301,13 +301,13 @@
"NVRM: nv_acpi_remove: failed to disable display switch events (%d)!\n", status);
}
- if (pNvAcpiObject->notify_handler_installed)
+ /* if (pNvAcpiObject->notify_handler_installed)
{
NV_ACPI_OS_WAIT_EVENTS_COMPLETE();
// remove event notifier
status = acpi_remove_notify_handler(device->handle, ACPI_DEVICE_NOTIFY, nv_acpi_event);
- }
+ }*/
if (pNvAcpiObject->notify_handler_installed &&
ACPI_FAILURE(status))
É um comentário em toda a parte de código que usa a função problemática. Uma vez que a chamada de kernel não existe mais, não deve causar grandes impactos. Então basta atualizar o dkms, que no meu caso fiz com o kernel de nome linux-3.13.0.helio-3.
dkms remove -m nvidia-331 -v 331.38 -k 3.13.0.helio-3
dkms build -m nvidia-331 -v 331.38 -k 3.13.0.helio-3
dkms install -m nvidia-331 -v 331.38 -k 3.13.0.helio-3
Com isso o módulo novo, com o patch acima, é construído. Então basta rebootar pra ter o kernel novo rodando e correr pro abraço :-)

Software livre me faz lembrar pizza em vários aspectos: gosto de pizza como de software livre, é prática de fazer e comer, poucas pessoas não gostam (só as que não experimentaram na verdade), todos sabem como fazer (quais os ingredientes usados) e posso conseguir de vários lugares diferentes, as pizzarias, experimentando uma pizza de um sabor novo em cada lugar. Além de que cada região tem uma personalidade própria em sua pizza.
Quando se tem uma empresa de software livre, em certos aspectos de negócios não se difere muito de uma pizzaria. Em geral pizza não é um segredo e suas receitas são abertas (conhecidas). Qualquer pessoa pode iniciar uma pizzaria. Mas no mundo dos negócios, seja em pizzas ou seja em software livre, as coisas nem sempre vão bem. É possível notar pela quantidade de pizzarias que abrem e fecham logo em seguida. O mesmo com empresas e profissionais de software livre.
Se pizzas são gostosas e todos comem, e não se paga nada por suas receitas (o código fonte), então por qual motivo as pizzarias não dão todas certo?
Com certeza não são as pessoas, os usuários de pizza (soa meio como tráfico de drogas, mas vamos deixar assim por enquanto), os culpados. O que realmente atrapalha as pizzarias são... elas próprias e as outras pizzarias.
Essa disputa entre pizzarias pelo gosto dos usuários é chamado de competição no mundo dos negócios. Como se pode notar pelas pizzas, nem sempre uma pizzaria é ganhadora do gosto de todos o tempo todos. Todo mundo experimenta pizzas de vários lugares e nem sempre isso significa a falência das outras pizzarias. Então a competição nos negócios não é o extermínio dos outros competidores, mas a alternância desses para ganhar a decisão do cliente. O problema é quando nossa empresa nunca acaba sendo escolhida por nenhum cliente e por muito tempo.
Um dos fatores que leva tanto as pizzarias quanto as empresas de software livre a sair do mercado é a falta de clareza em como elas se estabelecem pra competir pelo gosto do usuário. Quando digo aqui empresas, digo também profissionais, afinal não é pequena a quantidade de pessoas que começam a trabalhar com software livre mas em certo ponto de suas carreiras profissionais abandonam tudo pra usarem Windows e outros softwares proprietários. De acordo com um dos papas na área de gestão estratégica de empresas, Michael Porter, um professor de Harvard, existem 2 formas de competição: por diferenciação ou por custos. O melhor é escolher uma dessas estratégias de competição e atuar somente nela, não misturado com a outra. Não que isso seja impossível, mas é preciso ter muito cuidado pra não misturar ambas e acabar por arruinar seu negócio.
Red Hat Inc., um dos maiores nomes no mundo de software livre, responsável pela distribuição empresarial de mesmo nome e mantenedora do projeto Fedora, fechou o ano fiscal de 2012 com vendas no valor de 1,33 bilhões de dólares. Lucro líquido de 209 milhões de dólares. Essa é uma empresa que demonstra como participa de sua competição utilizando a estratégia da diferenciação.
Red Hat Inc. vende um Linux como outro qualquer: baseado em código aberto. Tanto que a distribuição CentOS nada mais é que a compilação dos fontes do produto Red Hat Enterprise Linux, a versão empresarial de Linux da Red Hat. Então como uma empresa que vende algo gratuito e aberto consegue tanto dinheiro? Pelo seu diferencial de serviço. A Red Hat Inc. agrega um serviço preferencial de suporte. Empresas compram o Red Hat Enterprise Linux não somente por se tratar de Linux, mas por vir com a gama de serviços que a Red Hat presta, como atendimento 24x7, suporte on-site, atendimento telefônico, etc.
Entre tantas empresas de Linux, e mesmo distribuições, a Red Hat Inc. soube mostrar um diferencial a mais para cativar o público corporativo. E de uma forma bem lucrativa, mas sempre mantendo o espírito do software livre.
Quase todos que mexem alguma coisa com software livre conhecem o sistema de hospedagem da Amazon. E conhecem por ser... barato! A Amazon Inc. utiliza uma estratégia de baixo custo pra competir na área de cloud computing. Isso significa que muitos mais usuários utilizarão a plataforma e, a cada novo usuário, ela conseguirá baixar ainda mais seus preços. Essa é a competição por custos: mantendo o menor custo possível de operação e com o maior número de clientes possível.
Com esses dois modelos de competição em mente, já é possível entender o motivo pelo qual nem toda pizzaria se mantém aberta. É difícil ter uma pizzaria com área de recreação, som ambiente, manobrista na porta e cobrar um preço baixo pela pizza. Opta-se por um ou pelo outro para se ter sucesso.
Em software livre, eu acredito que deveria ser o mesmo. Em geral eu visualizo que a maioria dos empreendimentos de software livre utilizam a estratégia da diferenciação, por entregar um "algo a mais". Mas e quando alguém faz o mesmo?
Sim, estratégia é uma parte, importante, mas só uma parte.
Desde que o twitter liberou o histórico dos tweets antigos em formato CSV, procurei uma ferramenta para poder um tagcloud das minha palavras. Como o arquivo era muito grande (mais de 3 MB), as ferramentas online simplesmente travavam.
Procurando por alternativas, encontrei o pouco citado pytagcloud.
Então fiz o seguinte programa pra gerar o tagcloud dos meus tweets:
#! /usr/bin/pyhon
# -*- coding: utf-8 -*-
import re, csv
from pytagcloud import create_tag_image, make_tags
from pytagcloud.lang.counter import get_tag_counts
TWEETS = "tweets.csv"
buffer = ""
tws = csv.reader(open(TWEETS), delimiter=',', quotechar='"')
for rows in tws:
buffer += rows[5] + "\n"
output = "clound_large.png"
tags = make_tags(get_tag_counts(buffer), maxsize=120)
create_tag_image(tags,
output,
size=(800, 600),
fontname='Lobster')
Foi exatamente a cópia do programa documentado pelo próprio pytagcloud. Pra minha supresa, não funciona e sai o seguinte erro:
Traceback (most recent call last): File "generate_cloud.py", line 53, in File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 344, in create_tag_image File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 275, in _draw_cloud File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 62, in __init__ IOError: unable to read font filename Error in sys.excepthook: Traceback (most recent call last): File "/usr/lib/python2.7/dist-packages/apport_python_hook.py", line 66, in apport_excepthook ImportError: No module named fileutils Original exception was: Traceback (most recent call last): File "generate_cloud.py", line 53, in File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 344, in create_tag_image File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 275, in _draw_cloud File "/usr/local/lib/python2.7/dist-packages/pytagcloud/__init__.py", line 62, in __init__ IOError: unable to read font filename
Após muito mexer, pois o código exemplo, com texto menor, funciona perfeitamente, descobri que esse erro é gerado pela quantidade de palavras no arquivo de tweets. Consegui corrigir isso colocando um limite no tamanho dos tags, que é um array.
Page 23 of 39
