 Gosto do jogo UFOAI, de UFO Alien Invasion. É um jogo de estratégia que joguei pela primeira vez nos tempos do DOS e do "Windows 3.11 for Workgroups". Nessa época era um outro jogo, pago, e que se chamava X-Com Unknown Enemy, ou algo assim. Com o avanço dos sistemas, computadores, e jogos, obviamente ficou obsoleto e esquecido. Então alguns fãns resolveram fazer uma versão opensource do jogo, e claro, com esteróides.
Gosto do jogo UFOAI, de UFO Alien Invasion. É um jogo de estratégia que joguei pela primeira vez nos tempos do DOS e do "Windows 3.11 for Workgroups". Nessa época era um outro jogo, pago, e que se chamava X-Com Unknown Enemy, ou algo assim. Com o avanço dos sistemas, computadores, e jogos, obviamente ficou obsoleto e esquecido. Então alguns fãns resolveram fazer uma versão opensource do jogo, e claro, com esteróides.
O jogo exige OpenGL pra rodar, pois usa massivamente o "quake engine" pra renderizar os ambientes. E é fantástico, e difícil, pois tem uma inteligência artificial aprimorada, que faz com que seus soldados saiam correndo de medo no meio de algumas batalhas.
Fazia tempo que não jogava, mesmo porque jogo mais em console que no PC, mas essa semana resolvi brincar um pouco. Eis que descubro um problema de OpenGL no meu laptop:
helio@shibboleet:~$ ufo +set vid_ref sdl
---- filesystem initialization -----
Adding game dir: /usr/share/games/ufoai/base
Added packfile /usr/share/games/ufoai/base/0base.pk3 (9 files)
Added packfile /usr/share/games/ufoai/base/0maps.pk3 (544 files)
Added packfile /usr/share/games/ufoai/base/0materials.pk3 (45 files)
Added packfile /usr/share/games/ufoai/base/0media.pk3 (10 files)
Added packfile /usr/share/games/ufoai/base/0models.pk3 (2015 files)
Added packfile /usr/share/games/ufoai/base/0music.pk3 (49 files)
Added packfile /usr/share/games/ufoai/base/0pics.pk3 (2114 files)
Added packfile /usr/share/games/ufoai/base/0shaders.pk3 (26 files)
Added packfile /usr/share/games/ufoai/base/0snd.pk3 (266 files)
Added packfile /usr/share/games/ufoai/base/0ufos.pk3 (97 files)
Adding game dir: ./base
Added packfile ./base/0base.pk3 (9 files)
Added packfile ./base/0maps.pk3 (544 files)
Added packfile ./base/0materials.pk3 (45 files)
Added packfile ./base/0media.pk3 (10 files)
Added packfile ./base/0models.pk3 (2015 files)
Added packfile ./base/0music.pk3 (49 files)
Added packfile ./base/0pics.pk3 (2114 files)
Added packfile ./base/0shaders.pk3 (26 files)
Added packfile ./base/0snd.pk3 (266 files)
Added packfile ./base/0ufos.pk3 (97 files)
Adding game dir: /home/helio/.ufoai/2.3.1/base
using /home/helio/.ufoai/2.3.1/base for writing
executing default.cfg
couldn't execute config.cfg
----- network initialization -------
libcurl/7.21.6 OpenSSL/1.0.0e zlib/1.2.3.4 libidn/1.22 librtmp/2.3 initialized.
------ server initialization -------
added 7 maps to the mapcycle
----- console initialization -------
Console initialized.
------- video initialization -------
SDL version: 1.2.14
I: desktop depth: 32bpp
I: video memory: 0
I: Available resolutions: 1366x1792 1366x768 1360x768 1024x768 800x600 640x480 (6)
I: video driver: x11
I: setting mode -1
I: set swap control to 0
X Error of failed request: GLXUnsupportedPrivateRequest
Major opcode of failed request: 155 (GLX)
Minor opcode of failed request: 16 (X_GLXVendorPrivate)
Serial number of failed request: 25
Current serial number in output stream: 26
Tentei forçar o sistema a inicializar sem o uso de OpenGL, com o parâmetro "+set vid_ref sdl", mas nem isso resolveu. Como não existe nada mais sagrado ao homem que seus jogos eletrônicos, resolvi consertar o problema. Ou ao menos tentar.
Não vou escrever sobre vídeos de pornografia ou de pessoas xingando, nada disso. Vou falar de novo dos "padrões Microsoft". Não é de hoje que a Microsoft cria aplicativos não padronizados e que fazem questão de não funcionar em outros sistemas além do Windows.
Num desses dias me deparei com um danado de um arquivo de vídeo, WMV, que não funcionava de jeito nenhum.
helio@shibboleet:tmp$ mplayer sound_of_music.wmv
mplayer: Symbol `ff_codec_bmp_tags' has different size in shared object, consider re-linking
MPlayer SVN-r33713-4.6.1 (C) 2000-2011 MPlayer Team
mplayer: could not connect to socket
mplayer: No such file or directory
Failed to open LIRC support. You will not be able to use your remote control.
Playing sound_of_music.wmv.
ASF file format detected.
[asfheader] Video stream found, -vid 1
[asfheader] Audio stream found, -aid 2
VIDEO: [WMV3] 352x264 24bpp 1000.000 fps 336.0 kbps (41.0 kbyte/s)
Load subtitles in ./
open: No such file or directory
[MGA] Couldn't open: /dev/mga_vid
open: No such file or directory
[MGA] Couldn't open: /dev/mga_vid
[VO_TDFXFB] Can't open /dev/fb0: Permission denied.
[VO_3DFX] Unable to open /dev/3dfx.
NVIDIA: could not open the device file /dev/nvidiactl (No such file or directory).
[vdpau] Error when calling vdp_device_create_x11: 1
==========================================================================
Opening video decoder: [dmo] DMO video codecs
DMO dll supports VO Optimizations 0 1
DMO dll might use previous sample when requested
MPlayer interrupted by signal 11 in module: init_video_codec
Não é a primeira vez que pego desses arquivos WMV que morrem com essa mensagem "MPlayer interr'upted by signal 11 in module: init_video_codec". Aliás o sinal 11 de saída significa, de acordo com o /usr/include/asm-generic/errno-base.h":
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
#define ENXIO 6 /* No such device or address */
#define E2BIG 7 /* Argument list too long */
#define ENOEXEC 8 /* Exec format error */
#define EBADF 9 /* Bad file number */
#define ECHILD 10 /* No child processes */
#define EAGAIN 11 /* Try again */
#define ENOMEM 12 /* Out of memory */
#define EACCES 13 /* Permission denied */
#define EFAULT 14 /* Bad address */
o que não quer dizer nada para mim. Aliás quem criou esse código de erro de saída tava trollando, com certeza.
Mas voltando ao vídeo, que eu queria assistir de qualquer jeito, consegui resolver depois de um Googlada profunda. Foi difícil achar referências, mas encontrei um alternativa pra assistir o vídeo, lá no launchpad. Estava no bug descrito como "mplayer crashes opening wmv files encoded with DMO codec".
A solução foi usar o parâmetro "-vc ffwmv3". Com isso pude assistir ao vídeo que fizeram durante a Mobile World Congress, em Barcelona. Muito bonitinho por sinal.
helio@shibboleet:tmp$ mplayer -vc ffwmv3 sound_of_music.wmv
mplayer: Symbol `ff_codec_bmp_tags' has different size in shared object, consider re-linking
MPlayer SVN-r33713-4.6.1 (C) 2000-2011 MPlayer Team
mplayer: could not connect to socket
mplayer: No such file or directory
Failed to open LIRC support. You will not be able to use your remote control.
Playing sound_of_music.wmv.
ASF file format detected.
[asfheader] Video stream found, -vid 1
[asfheader] Audio stream found, -aid 2
VIDEO: [WMV3] 352x264 24bpp 1000.000 fps 336.0 kbps (41.0 kbyte/s)
Load subtitles in ./
open: No such file or directory
[MGA] Couldn't open: /dev/mga_vid
open: No such file or directory
[MGA] Couldn't open: /dev/mga_vid
[VO_TDFXFB] Can't open /dev/fb0: Permission denied.
[VO_3DFX] Unable to open /dev/3dfx.
NVIDIA: could not open the device file /dev/nvidiactl (No such file or directory).
[vdpau] Error when calling vdp_device_create_x11: 1
==========================================================================
Forced video codec: ffwmv3
Opening video decoder: [ffmpeg] FFmpeg's libavcodec codec family
Unsupported PixelFormat 61
Unsupported PixelFormat 53
Unsupported PixelFormat 61
Unsupported PixelFormat 53
[wmv3 @ 0xb657c180]Extra data: 8 bits left, value: 0
Selected video codec: [ffwmv3] vfm: ffmpeg (FFmpeg WMV3/WMV9)
==========================================================================
==========================================================================
Opening audio decoder: [ffmpeg] FFmpeg/libavcodec audio decoders
AUDIO: 44100 Hz, 2 ch, s16le, 64.0 kbit/4.54% (ratio: 8003->176400)
Selected audio codec: [ffwmav2] afm: ffmpeg (DivX audio v2 (FFmpeg))
==========================================================================
AO: [pulse] 44100Hz 2ch s16le (2 bytes per sample)
Starting playback...
Movie-Aspect is undefined - no prescaling applied.
VO: [xv] 352x264 => 352x264 Planar YV12
A: 7.2 V: 7.2 A-V: -0.000 ct: -0.046 108/108 9% 1% 0.3% 4 0

Nota: Antes que perguntem, não posso publicar o vídeo. Não é nada de tão sério ou secreto, mas uma vez que envolve a marca da empresa e foi feito por outras pessoas, eu preciso que elas primeiro publiquem no Youtube, ou algum outro site, pra depois publicar aqui. E não vou pagar nada pro ECAD.
 Já tinha feito referência anteriormente sobre o sistema de monitoração MUNIN principalmente quando escrevi sobre o ataque DDoS que sofri, mostrando os gráficos gerados por ele, mas até agora não tinha escrito nada sobre o mesmo. Então é hora de tentar me redimir sobre isso.
Já tinha feito referência anteriormente sobre o sistema de monitoração MUNIN principalmente quando escrevi sobre o ataque DDoS que sofri, mostrando os gráficos gerados por ele, mas até agora não tinha escrito nada sobre o mesmo. Então é hora de tentar me redimir sobre isso.
Descobri o MUNIN por acaso. Eu não sou muito fã de sistemas de monitoração pois toda vez que ouço a palavra "monitoração" já penso logo em Nagios ou algo do gênero, que tem um belo apelo visual e poder de monitoração, mas que é complicado para configurar e colocar em produção pela primeira vez, com arquivos de configuração baseados em um XML ou algo próximo disso. Sem falar no consumo de CPU. Eu buscava algum sistema de monitoração de mail enviados pelo mailman, para apenas visualizar a quantidade de mensagens enviadas numa lista de mail que participo e ajudo a administrar.
Buscando algum sistema que apenas apresentasse os dados de uso do mailman em forma fácil como um CSV, para importar em algum outro sistema como MRTG ou RDDTool, encontrei um link na lista de desenvolvimento desse sobre o MUNIN. Primeiramente olhei um screenshot do mesmo e fiquei surpreso pelo belo gráfico gerado, mas não achei que o mesmo criava tudo sozinho e auto-magicamente.
A página do projeto diz que o nome Munin vem das lendas nórdicas: Munin e Hugin são os corvos que ficam nos ombros de Odin (pai de Thor) e vão de tempos em tempos à Midgard, o nosso mundo, para visualizar e lembrar de fatos, e depois reportar os mesmos à Odin. Segundo a página do projeto o nome Munin também significa memória, , provavelmente em línguas nórdicas (leia-se vikings).

E novamente as redes sociais mostram sua força. Após a série de protestos no dia 18, onde até mesmo esse site ficou fora do ar, contra o SOPA, os políticos norte americanos resolveram voltar atrás e não mais apoiar a lei que iria acabar com a liberdade da Internet.
De minha parte, foi uma experiência de abstinência de Internet. Passei o dia sem acessar mail, twitter, facebook, e quase qualquer dispositivo de rede. Mas não fiquei sem mexer no computador, pois aproveitei pra fechar uns trabalhos pendentes (trabalho de casa de contabilidade, do MBA) e minha mãe pediu ajuda pra comprar umas passagens pra uma viagem de ônibus até o Rio de Janeiro, via site da empresa de ônibus. E pedido de mãe a gente não nega. Então minha abstinência foi mais em relação às redes sociais.
A imagem abaixo, que apareceu no FaceBook, ilustra bem a mudança de posicionamento dos políticos após o dia 18 de janeiro de 2012.

Tudo seria vitória, linda e maravilhosa, se não fosse o caso do Megaupload. Megaupload é, ou era, um famoso site onde se hospedava dados para download. Apesar da política do site, de não permitir pirataria, era comum encontrar links de filmes, músicas, vídeos e jogos que apontavam para esse site. O truque era simples: quebrar o conteúdo em vários arquivos protegidos por senha. Mas mesmo sendo contra pirataria, e atuando contra essa uma vez que detectada, o site foi fechado pelo FBI. E o mais absurdo: seus donos foram presos na Nova Zelândia.
Então em teoria ganhamos contra o SOPA, que foi arquivado, mas na prática o mesmo já está sendo aplicado, sendo votado ou não. É a mesma história da invasão americana no Iraque. Quem não se lembra de que os EUA acusaram o Iraque de possuir armas de destruição em massa, e mesmo sendo votado contra qualquer intervenção naquele País, o EUA tomou a dianteira e o invadiu, sem nunca prestar contas nem encontrar nada de armas de destruição e massa? E agora vemos a mesma manipulação maniqueísta americana em relação à Internet. Para quem não percebeu ainda: estamos em perigo.
![]()
|
Para quem ainda não sabe, amanhã, dia 18 de janeiro, é o dia em que a Internet vai parar. Não vai parar por qualquer motivo, mas para chamar atenção quanto a aprovação da chamada SOPA, Stop Online Piracy Act. Para quem ainda não sabe o significado do SOPA, recomendo a leitura desse artigo: Como estou aderindo aos protestos, amanhã o site também estará em modo "off-line", apresentando o logo do SOPA. |
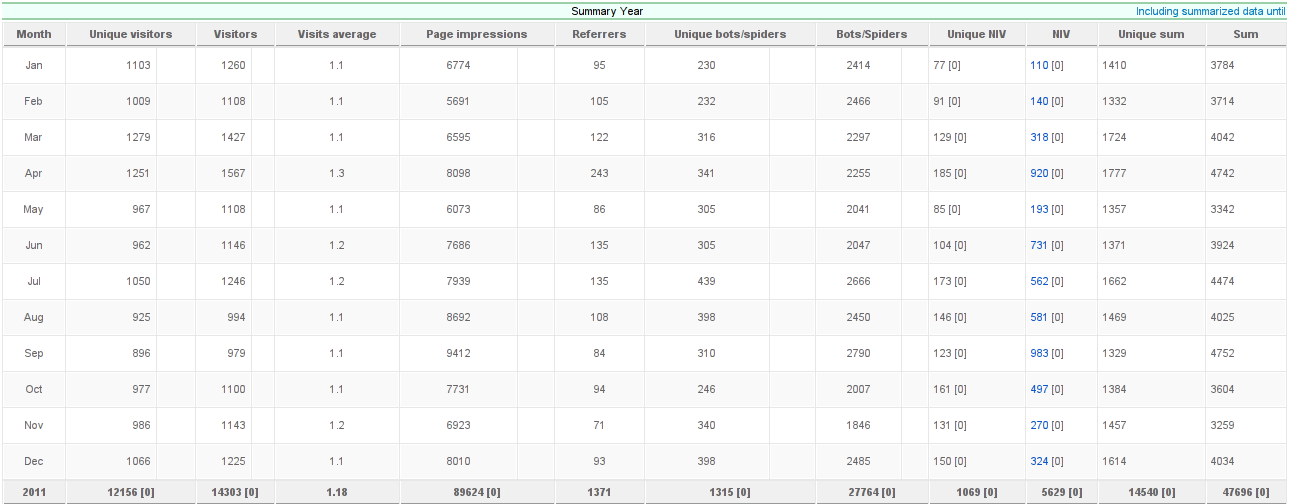
Um pouco atrasado em relação à mídia em geral, que ansiosamente lança esse tipo de reflexão logo na última semana do ano, ou no máximo nos primeiros dias do ano que recém chega, aqui estou eu falando do ano que se foi, 2011. E no dia 11 de janeiro! Não tenho mesmo aquele "timing" jornalístico.
Deixando de lado a discussão sobre certo ou errado em relação a tais publicações, estou escrevendo aqui como foi o ano de 2011 aqui nesse site. Com a ajuda do JoomlaStats ficou bem fácil de ver a quantidade de acessos, páginas mais acessadas, sistemas operacionais, navegadores, etc. Então vamos lá!
Com uma média de aproximadamente 1000 visitas por mês, não tenho do que reclamar em relação à quantidade. Foram mais ou menos 33 visitantes por dia. Uma boa média para quem não tem um grande acervo de material, nem marketing direcionado. Achava que eu só atraia os spammers, mas vejo que tenho algo a mais que um endereço de e-mail valioso (pros spammers).
Não sou grande fã de padrinhos mágicos. Não que o seriado seja ruim, mas não tenho assistido muito televisão. Mas esse vídeo foi apresentado durante a aula de Marketing do MBA, com o professor Peruzzo, que por si só já é um show à parte.
É um vídeo interessantes pois mostra o Flappy Bob, um cara de uma família de palhaços, que se perdeu dos pais e foi criado pelos duendes, verdadeiros burocratas.
Notem como o vídeo é a própria realidade de nossas vidas, onde se não escolhemos o que queremos, as escolhas são feitas por nós. E nós as engolimos sem nem mesmo contestar. Vídeo forte.
A letra:
Timmy: Ei, Flappy Bob olha que situação
Você foi usado apenas como peão
As suas roupas de palhaço
Eles tiraram sem razão
Cai na real isso não é diversão
Desde pequeno manipularam você
Escolhiam seu carro e o que devia comer
Sei que é difícil enxergar
Que é tudo um plano pra te enganar
É hora de parar antes de se arrepender
DC e Sanderson:Ei Flappy Bob, o que é que tá havendo?
Você tá escutando mentiras sem sentido
Pra encher o teu ouvido
Te botando contra nós
Abafando a nossa voz
É, mas vê se não esquece
Foi você, Flappy Bob!
É, foi só você!
Que protegemos, respeitamos!
Como um filho especial.
E agora o que é que temos?
Seja grato pelo menos!
Assinando esse contrato
Tudo vai ficar legal!
Timmy: Cadê a diversão?
Flappy Bob: Em quem acredito?
Duendes: Cadê a diversão?
Flappy Bob: Estou em conflito!
Timmy: Quem vai dizer o que na verdade é diversão?
Timmy: Cadê a diversão?
Flappy Bob: Faz uma pausa!
Duendes: Ele é o vilão!
Flappy Bob: Por sua causa
Quase perdi tudo que eu sempre achei diversão.
Timmy: Ei, Flappy Bob! Ouça o seu coração!
Não é nada disso a sua verdadeira missão!
Eu sei que agora eu tô numa fria
Mas os seus pais, o que diriam
Sobre o caminho que você escolheu sem razão?
Timmy: Cadê a diversão?
Flappy Bob: Em quem acredito?
Duendes: Cadê a diversão?
Flappy Bob: Estou em conflito!
Timmy: Quem vai dizer o que na verdade é diversão?
Timmy: Cadê a diversão?
Flappy Bob: Eu tô confuso!
Duendes: Mas ele é o vilão!
Flappy Bob: É só um intruso!
Duendes: Não merece atenção!
Flappy Bob: Vou agora assinar é minha decisão!
Timmy: Não!
Flappy Bob: Pode até ser um erro que cometi
Duendes: Ha! Ha! Ha! Ha!
Flappy Bob: Mas tudo mudar é muito arriscado pra mim
As coisas que eu usei são do passado eu já deixei!
Eu quero meu mundo como eu me acostumei!
Com toda proteção
Duendes: O perdedor vai pro chão!
Timmy: Ah!
Flappy Bob: Valeu pela caneta!
Não dá mais pra ignorar os dispositivos móveis. Não é somente na televisão, Internet e no dia à dia que vemos os smartphones e tables. Na estatística de acesso ao site eles também estão aparecendo, e de forma crescente.
Eu mesmo tenho usado bastante meu celular Nexus S para navegar na web (principalmente quando estou na cama) e nada me irrita mais que acessar um site não preparado para ele, que fica mais de 1 minuto para carregar as páginas. Mas não adianta nada reclamar dos outros se nem mesmo eu tava prestando a devida atenção a isso.
Então instalei o módulo Mobilebot do Joomla para modificara formatação do site para dispositivos móveis.
Como ainda está em fase de testes, não prometo uma grande melhoria o resolução imediata dos problemas, mas já é um começo.

Finalmente cheguei à conclusão do motivo das falhas de SSH. Eu não tinha me dado conta, mas o problema surgiu depois do upgrade do Ubuntu que estou usando no laptop, para a versão 11.10 (Oneiric).
Como fui conectar em um outro servidor e tive o mesmo erro, vi que não era problema do Solaris, mas sim do cliente ssh. Então tentei uma conexão em modo de debug:
helio@shibboleet:~$ ssh -C -v slowlaris
OpenSSH_4.2p1 Debian-4.sesarge.2, OpenSSL 0.9.7m 23 Feb 2007
debug1: Reading configuration data /home/helio/.ssh/config
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: Applying options for *
debug1: Connecting to slowlaris [1.2.3.103] port 22.
debug1: Connection established.
debug1: identity file /home/helio/.ssh/identity type 0
debug1: identity file /home/helio/.ssh/id_rsa type 1
debug1: identity file /home/helio/.ssh/id_dsa type 2
debug1: Remote protocol version 2.0, remote software version Sun_SSH_1.1.3
debug1: no match: Sun_SSH_1.1.3
debug1: Enabling compatibility mode for protocol 2.0
debug1: Local version string SSH-2.0-OpenSSH_4.2p1 Debian-4.sesarge.2
debug1: Unspecified GSS failure. Minor code may provide more information
Credentials cache file '/tmp/krb5cc_1000' not found
debug1: Unspecified GSS failure. Minor code may provide more information
Credentials cache file '/tmp/krb5cc_1000' not found
debug1: Unspecified GSS failure. Minor code may provide more information
debug1: Unspecified GSS failure. Minor code may provide more information
debug1: Unspecified GSS failure. Minor code may provide more information
SPNEGO cannot find mechanisms to negotiate
debug1: Offering GSSAPI proposal: (null)
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: server->client aes128-cbc hmac-md5 zlib
debug1: kex: client->server aes128-cbc hmac-md5 zlib
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP
debug1: SSH2_MSG_KEX_DH_GEX_INIT sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_REPLY
debug1: Host 'slowlaris' is known and matches the RSA host key.
debug1: Found key in /home/helio/.ssh/known_hosts:4
debug1: ssh_rsa_verify: signature correct
debug1: Enabling compression at level 6.
debug1: SSH2_MSG_NEWKEYS sent
debug1: expecting SSH2_MSG_NEWKEYS
debug1: SSH2_MSG_NEWKEYS received
debug1: SSH2_MSG_SERVICE_REQUEST sent
debug1: SSH2_MSG_SERVICE_ACCEPT received
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Next authentication method: gssapi-with-mic
debug1: Unspecified GSS failure. Minor code may provide more information
Credentials cache file '/tmp/krb5cc_1000' not found
debug1: Trying to start again
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Next authentication method: publickey
debug1: Offering public key: /home/helio/.ssh/id_rsa
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Offering public key: /home/helio/.ssh/id_dsa
Received disconnect from 1.2.3.103: 2: Too many authentication failures for minsat
Dessa vez olhei com mais atenção a saída do comando. Notei vários erros com a mensagem "Unspecified GSS failure. Minor code may provide more information" e uma referência aos tipos de autenticação "gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive". Então busquei pelos erros de ssh com gssapi na Internet e... BINGO! Achei uma opção simples para desativar o mesmo, que deve ter mudado com o upgrade do openssl. Basta passar o parâmetro "-o GSSAPIAuthentication=no".
helio@shibboleet:~$ ssh -C -v -o GSSAPIAuthentication=no slowlaris
OpenSSH_4.2p1 Debian-4.sesarge.2, OpenSSL 0.9.7m 23 Feb 2007
debug1: Reading configuration data /home/helio/.ssh/config
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: Applying options for *
debug1: Connecting to slowlaris [1.2.3.103] port 22.
debug1: Connection established.
debug1: identity file /home/helio/.ssh/identity type 0
debug1: identity file /home/helio/.ssh/id_rsa type 1
debug1: identity file /home/helio/.ssh/id_dsa type 2
debug1: Remote protocol version 2.0, remote software version Sun_SSH_1.1.3
debug1: no match: Sun_SSH_1.1.3
debug1: Enabling compatibility mode for protocol 2.0
debug1: Local version string SSH-2.0-OpenSSH_4.2p1 Debian-4.sesarge.2
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: server->client aes128-cbc hmac-md5 zlib
debug1: kex: client->server aes128-cbc hmac-md5 zlib
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP
debug1: SSH2_MSG_KEX_DH_GEX_INIT sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_REPLY
debug1: Host 'slowlaris' is known and matches the RSA host key.
debug1: Found key in /home/helio/.ssh/known_hosts:4
debug1: ssh_rsa_verify: signature correct
debug1: Enabling compression at level 6.
debug1: SSH2_MSG_NEWKEYS sent
debug1: expecting SSH2_MSG_NEWKEYS
debug1: SSH2_MSG_NEWKEYS received
debug1: SSH2_MSG_SERVICE_REQUEST sent
debug1: SSH2_MSG_SERVICE_ACCEPT received
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Next authentication method: publickey
debug1: Offering public key: /home/helio/.ssh/id_rsa
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Offering public key: /home/helio/.ssh/id_dsa
debug1: Authentications that can continue: gssapi-keyex,gssapi-with-mic,publickey,password,keyboard-interactive
debug1: Next authentication method: keyboard-interactive
Password:
debug1: Authentication succeeded (keyboard-interactive).
debug1: channel 0: new [client-session]
debug1: Entering interactive session.
debug1: Sending environment.
debug1: Sending env LANG = en_US.UTF-8
debug1: Remote: Channel 0 set: LANG=en_US.UTF-8
Last login: Tue Dec 6 11:30:56 2011 from 1.2.3.7
Oracle Corporation SunOS 5.10 Generic Patch January 2005
You have new mail.
[helio@slowlaris ~]>
Para evitar digitar essa opção em todas as conexões, simplesmente adicionei o parâmetro em ".ssh/config". E fim dos problemas.
Fonte: http://www.walkernews.net/2009/04/06/how-to-fix-scp-and-ssh-login-prompt-is-very-slow-in-linux/
 Hoje fui brindado com essa mensagem ao tentar acessar por ssh uma workstation Sun Ultra 10 que tenho por aqui. Simplesmente não conseguia conectar por ssh.
Hoje fui brindado com essa mensagem ao tentar acessar por ssh uma workstation Sun Ultra 10 que tenho por aqui. Simplesmente não conseguia conectar por ssh.
helio@shibboleet:~$ ssh ultra10
Received disconnect from 1.2.3.241: 2: Too many authentication failures for helio
Felizmente o acesso por telnet estava disponível. Não encontrei nada relacionado à ssh que pudesse estar bloqueando meu acesso. Mas como estava rodando um programa que testava acesso via ssh para outra máquina, que abria várias threads, imaginei que isso tivesse matado todo os meus max_files_open disponíveis.
Mas mesmo matando todos os processos ssh, continuei com esse problema.
ultra10{root} #: ps -ef | grep -i ssh | awk '{print $2}' | xargs kill -9
Tentei parar o serviço e abrir o ssh em modo de debug:
ultra10{root} #: svcadm disable ssh
ultra10{root} #: /usr/lib/ssh/sshd -f -dd
Mas também sem nenhuma ajuda claro. Olhando na Internet achei que era possível arrumar isso alterando o parâmetro " MaxAuthTries". Editei então o arquivo "/etc/ssh/sshd_config" e deixei as entrada da seguinte forma:
MaxAuthTries 60
MaxAuthTriesLog 30
O ssh voltou a funcionar. Resta agora descobrir como meu programa com expect e threads causou isso.
 Recentemente foi liberado o Joomla 1.5.25 em http://www.joomla.org com várias correções sérias de exploração de falha por XSS.
Recentemente foi liberado o Joomla 1.5.25 em http://www.joomla.org com várias correções sérias de exploração de falha por XSS.
A série 1.5.x refere-se à versão estável. Para as versões de desenvolvimento, atualização para 1.7.3 corrige essa falha.
Se você é usuário de Joomla, não perca tempo e atualize logo seu CMS.
Faz um pouco mais de uma ano desde a aquisição do netbook Dexnet N280 através da loja online da Saraiva. Na época em que escrevi sobre o mesmo por aqui, algumas pessoas me alertaram sobre o problema com as dobradiças da tela. Após pouco mais de 1 ano utilizando o netbook, e esses problemas começaram a dar as caras.







Não resta muito o que fazer uma vez que o problema parece ser por desgaste do material (não pelo uso contínuo, mas pela baixa qualidade), então estou procurando a nota fiscal para notificar o fabricante e solicitar reparo do equipamento. Eu só não lembro se a garantia era de mais de 1 ano. Se não for, só me resta chorar...
Tudo tem um início. Para fazer o restante dos artigos inteligíveis, é preciso explicar um pouco de telefonia, mais precisamente da transmissão da telefonia em forma de dados. Ou na verdade como a voz vira dados.
Na figura abaixo é mostrado um exemplo, bem simplificado e limitado, de chamadas telefônicas em sistemas que chamamos de "rede fixa". Antes da chegada dos celulares, era o que conheciamos como telefonia.
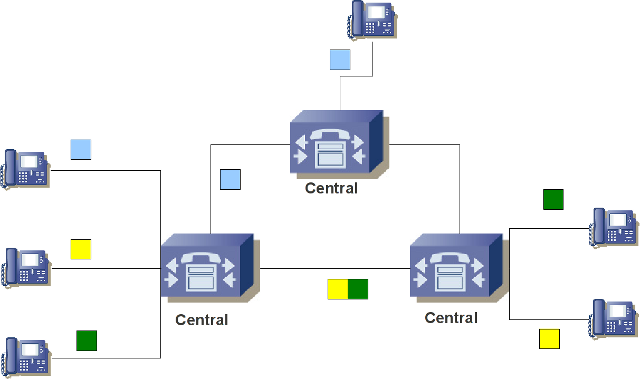
O telefones se comunicam com as "centrais telefônicas", ou "centrais de comutação", que pegam o conteúdo de voz do assinante e enviam para o destino. As centrais telefônicas fazem também o roteamento para o telefone de destino.
Não entrando muito sobre os detalhes do antigo sistema de telefonia, mas comentando da parte que realmente interessa, basta saber que a comunicação entre os telefones e a central telefônica se faz de forma analógica. Uma vez a voz chegando na mesma, essa é digitalizada e trocada entre as outras centrais totalmente digital. Ao chegar na central do telefone destino, essa voz digitalizada é convertida em formato analógico novamente.
Os primeiros celulares usavam algo muito parecido, inclusive enviado o conteúdo da chamada (voz) em forma analógica, o que permitia a "escuta" da mesma. Apesar da tecnlogia CDMA naquela época já permitir chamadas digitais, no Brasil adotou-se o formato analógico provavelmente pelo alto custo dos aparelhos celulares digitais. Já no GSM, a comunicação é completamente digital. Qualquer tecnologia a partir do GSM tem-se a chamada telefônica completamente digital. O responsável pela digitalização é o próprio celular.
Não importando muito para explicar a rede de telefonia pré-paga, mas como curiosidade, existem dois modos de digitalização de voz: a lei-A e a lei-µ (lei-mi). Nos EUA é usada a lei-A e aqui no Brasil, a lei-µ.
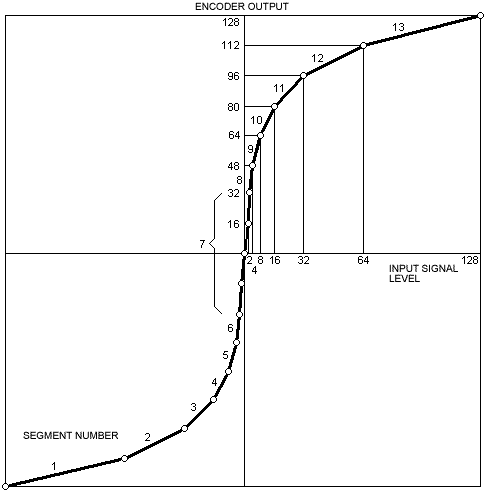
Ambas as leis designam com quantos bits será digitalizada a voz. Não em relação à quantidade, mas em relação à inclinação da curva de frequência da voz. Falando de forma mais simplificada, quando a voz é mais grave, usa-se menos bits, quando é mais aguda, mais bits. Onde e quando usar esses bits é o que é mapeado pelas tais leis. Em geral ao se trocar os codecs de voz e misturar as leis, de um lado se ouve a tal "voz de pato", e do outro, a voz do Darth Vader.
Como o nosso espectro de voz, ou faixa de frequência da voz, varia entre 300 Hz e 4KHz, usa-se uma amostragem de 8 KHz para ser digitalizada. Essa digitalização é feita por meio de pulsos, os chamados PCM, Pulse Coded Modulation, que "medem" a intensidade da voz e a digitalizam.
Essa voz digitalizada é transmitida entre as centrais telefônicas dentro de um link de 2 Mbps no Brasil (os chamados links E1) e 1.5 Mbps nos EUA (links T1). Vários links E1 são agregados em links maiores, como links STM-1 (155 Mbps) ou até como STM-4 ( 622 Mbps). Apesar do mundo IP já adotar redes de maior velocidade, com links de 10 Gbps, as redes de telefonia em geral ficam dentro do 622 Mbps.
Essa comunicação entre centrais com esses links é o que veremos nos próximos artigos.
Page 26 of 38

