
Já faz algum tempo que quero escrever sobre meu uso de LVM, mas até agora a procrastinação venceu. No último artigo Trabalhando de home-office eu descrevei meu ambiente de home-office e um pouco do meu desktop. Ao entrar no desktop é que percebi que um dos HDDs simplemente parou de funcionar, esse Seagate Firecuda de 2 TB. Graças ao LVM eu não percebi nada, nem perdi dados. E vou descrever aqui o cenário e como fiz a troca e re-sincronismo dos dados.
Usando o comando lvm é possível ver o estado dos meu volumes:
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor-r- 750.00g 100.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
Minhas partições eram todas XFS mas descobri que alguns jogos da Steam simplesmente só rodam com EXT4. Então precisei criar uma partição EXT4 somente pros jogos. É o volume com nome de "steam" e que mostra um "100.00". Esse número representa a cópia no disco que falhou, que estava em RAID1.
Primeiro eu adicionei outro disco de 2 TB que tinha aqui (no passado eu usava 2 HDDs de 2 TB cada com LVM, comprei o HDD novo de 4 TB e removi 1 dos HDDs que estava em bom estado ainda), e particionei da mesma forma que o HDD de 4 TB, com uma partição EFI e outra de boot do mesmo tamanho. O restante pro LVM.
root@goosfraba:~# fdisk -l /dev/sdb
Disco /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 setores
Unidades: setor de 1 * 512 = 512 bytes
Tamanho de setor (lógico/físico): 512 bytes / 512 bytes
Tamanho E/S (mínimo/ótimo): 512 bytes / 512 bytes
Tipo de rótulo do disco: dos
Identificador do disco: 0x18a6e3b6
Dispositivo Inicializar Início Fim Setores Tamanho Id Tipo
/dev/sdb1 2048 1128447 1126400 550M ef EFI (FAT-12/16/32)
/dev/sdb2 1128448 5322751 4194304 2G 83 Linux
/dev/sdb3 5322752 3907029167 3901706416 1.8T 8e Linux LVM
Tendo a partição sdb3 disponível pro LVM, então o que faltava era adicionar o grupo de volumes que uso. Ao listar os discos físicos disponíveis, apareceu a informação ainda do disco antigo como "unknown".
root@goosfraba:~# pvdisplay
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name [unknown]
VG Name diskspace
PV Size <1.82 TiB / not usable <4.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476931
Free PE 284930
Allocated PE 192001
PV UUID N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t
"/dev/sdb3" is a new physical volume of "<1.82 TiB"
--- NEW Physical volume ---
PV Name /dev/sdb3
VG Name
PV Size <1.82 TiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
Isso acontenceu porque o metadado ainda estava lá apesar do disco ter sido removido da máquina. Enquanto isso a partição sdb3 aparece como "Allocatable NO" pois ainda não está disponível pra uso.
A primeira coisa é remover os dados incosistes do vg (volume group).
root@goosfraba:~# vgreduce diskspace --removemissing --force
WARNING: Device for PV N26Uhr-VM1o-ocfo-V7FR-26oS-BgFB-t1IA9t not found or rejected by a filter.
Wrote out consistent volume group diskspace.
E adicionar a nova partição ao vg.
root@goosfraba:~# vgextend diskspace /dev/sdb3
Volume group "diskspace" successfully extended
Com isso o a informação de pv mostra como usado.
root@goosfraba:~# pvdisplay
--- Physical volume ---
PV Name /dev/sda3
VG Name diskspace
PV Size <3.64 TiB / not usable <4.82 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 953211
Free PE 451450
Allocated PE 501761
PV UUID 9wmB4t-RyQP-uDc2-2hNO-wn7c-7wq8-GcQV8S
--- Physical volume ---
PV Name /dev/sdb3
VG Name diskspace
PV Size <1.82 TiB / not usable <2.09 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 476282
Free PE 476282
Allocated PE 0
PV UUID CvlXC4-LiEI-mr0c-vSky-oryk-Khrl-J1dyBa
E a informação de vg mostra com 6 TB disponíveis pra uso.
root@goosfraba:~# vgdisplay
--- Volume group ---
VG Name diskspace
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 217
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 8
Open LV 8
Max PV 0
Cur PV 2
Act PV 2
VG Size 5.45 TiB
PE Size 4.00 MiB
Total PE 1429493
Alloc PE / Size 501761 / 1.91 TiB
Free PE / Size 927732 / <3.54 TiB
VG UUID f2ufnI-c802-yt6f-2nMG-6BYl-8atu-wbR7vO
Agora a partição já faz parte do lvm. O que resta é a usar como RAID1 em mirror. Ou mesmo como uma partição qualquer se eu quisesse. Mas no caso uso como RAID1 pra ter um pouco mais de desempenho.
Primeiramente removendo as informações de RAID1 que ainda existindo.
root@goosfraba:~# lvconvert -m 0 /dev/diskspace/steam
Are you sure you want to convert raid1 LV diskspace/steam to type linear losing all resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace -wi-ao---- 750.00g
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
O parâmetro "-m 0" diz que a partição será em RAID0.
Em seguida basta mudar a partição novamente pra RAID1 e o sincronismo iniciará.
root@goosfraba:~# lvconvert -m 1 /dev/diskspace/steam /dev/sdb3
Are you sure you want to convert linear LV diskspace/steam to raid1 with 2 images enhancing resilience? [y/n]: y
Logical volume diskspace/steam successfully converted.
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 0.00
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
root@goosfraba:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home diskspace -wi-ao---- 450.00g
root diskspace -wi-ao---- 5.00g
steam diskspace rwi-aor--- 750.00g 34.56
swap diskspace -wi-ao---- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-ao---- 40.00g
E é isso. Simples e rápido graças ao LVM.
Eu tenha plena certeza que um dos círculos do inferno de Dante é feito em GTK e roda Gnome. Certeza pura. Estou pra conhecer um widget mais porcaria que GTK. Não tem jeito de eu gostar dele, nem Gnome.
Eu já tinha escrito aqui sobre o problema com fontes em Fontes de aplicativos em GTK no KDE e também o problema com a mesma barra de rolagem em Corrigindo as teclas de rolagem em GTK. Mas descobri recentemente que o infeliz do leitor de mails evolution, feito em GTK, tem a maravilhosa barra de rolagem que desaparece.
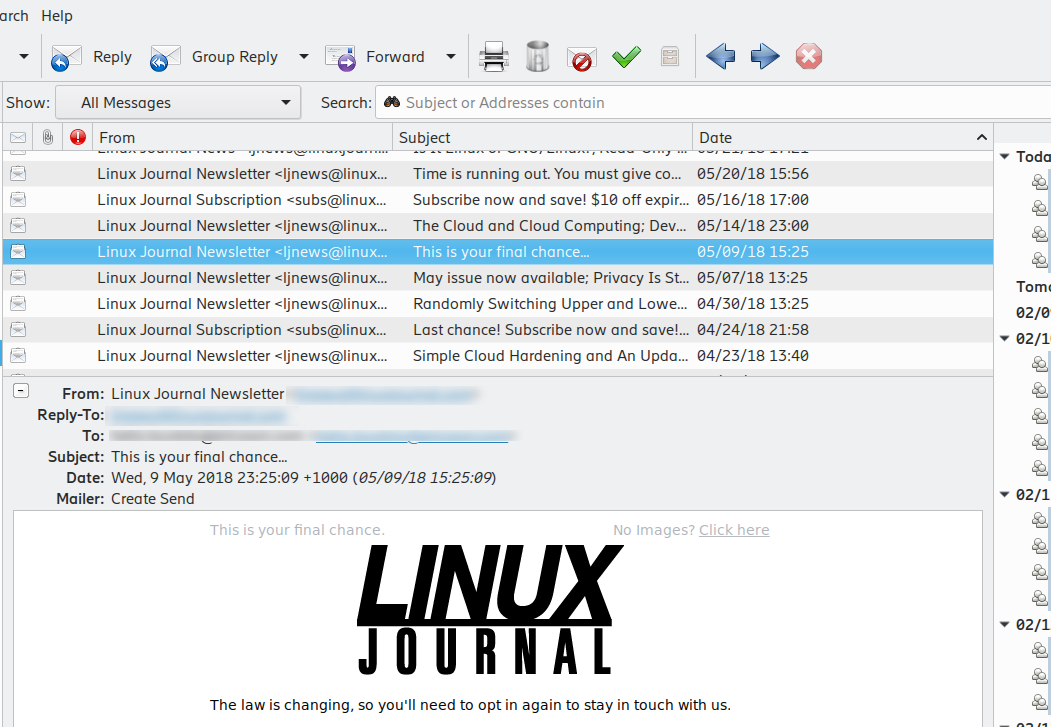
Antes de qualquer manifestação a respeito, sim estou mostrando as partes de mail da Linux Journal, que infelizmente fechou as portas definitivamente. E por isso as datas de 2018. Mas é só olhar a image que nota-se a falta das barras de rolagem, tanto pro texto quanto pras mensagens.
Garimpando na Internet achei dois artigos sobre o mesmo problema e como o corrigir:
https://forum.endeavouros.com/t/disable-scrollbar-fading/1488/4
https://techne.alaya.net/?p=19006
Basicamente uma solução sugere que em /etc/environment seja adicionado a variável "GTK_OVERLAY_SCROLLING=0". É possível já testar pelo terminal essa opção, o que não adiantou nada pra mim. Mesmo forçando o uso da variável com o comando:
helio@xps13ubuntu:~$ gdbus call \
--session --dest org.freedesktop.DBus \
--object-path /org/freedesktop/DBus \
--method org.freedesktop.DBus.UpdateActivationEnvironment '{"GTK_OVERLAY_SCROLLING": "0"}'A outra solução sugerida é adicionar em ~/.config/gtk-3.0/settings.ini:
[Settings]
gtk-primary-button-warps-slider=falseHá outros relatos dizendo pra usar "gtk-primary-button-warps-slider=0" mas também não deu muito certo para mim.
E essa é a parte horrorosa do GTK e Gnome. Não existe uma configuração simples de fazer. Tudo são comandos e configurações enfiadas em cantos escuros do sistema.
Como alguém consegue criar algo assim e achar bom? Eu realmente não entendo. E continuo procurando uma solução pro evolution, que é o cliente de mail padrão da empresa e não posso trocar por outro (mesmo porque se fosse em thunderbird, também é em GTK).
Por enquanto eu consegui amenizar o uso da barra de rolagem que aparece com o mouse passando sobre ele com uam configuração de estilo no GTK.
helio@xps13ubuntu:~$ cat ~/.config/gtk-3.0/gtk.css
scrollbar, scrollbar button, scrollbar slider {
-GtkScrollbar-has-backward-stepper: true;
-GtkScrollbar-has-forward-stepper: true;
min-width: 15px;
min-height: 15px;
border-radius: 0;
}Não está bonito, mas funciona melhor que a versão anterior.
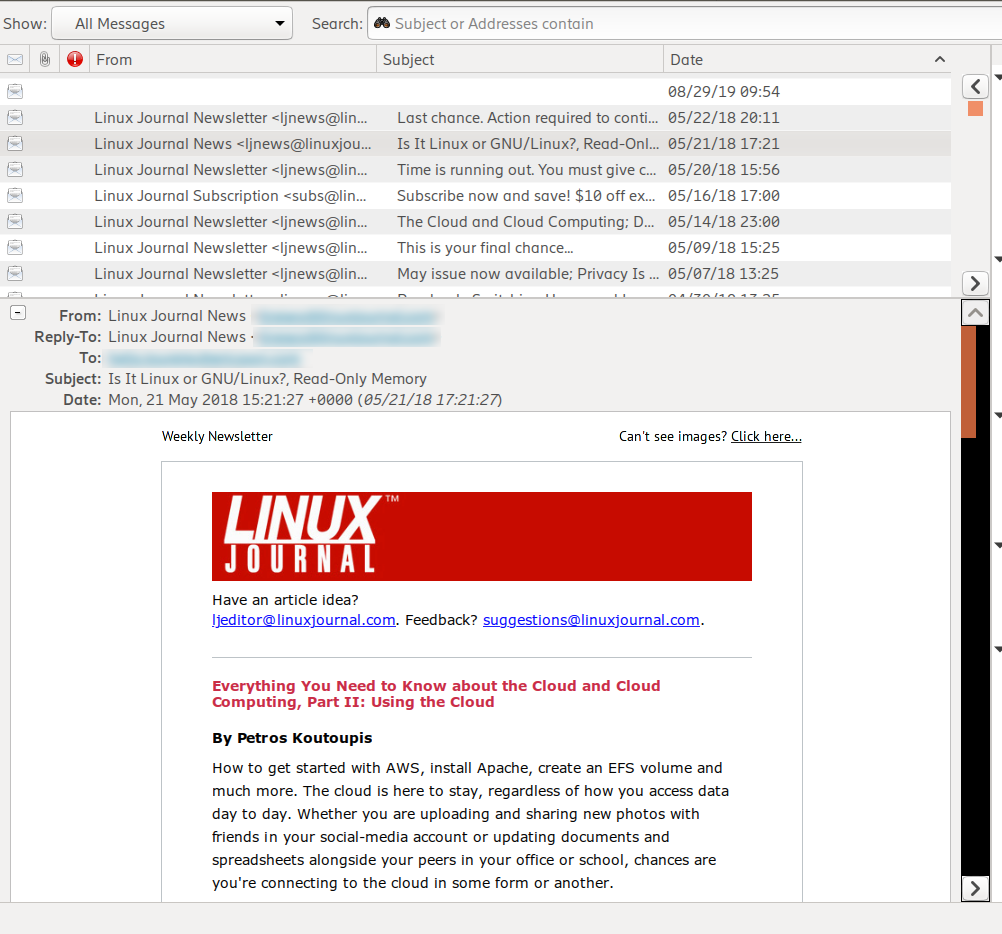
E após um reboot indesejado, aparentemente o GTK_OVERLAY_SCROLLING deu certo e as barras apareceram definitivamente.
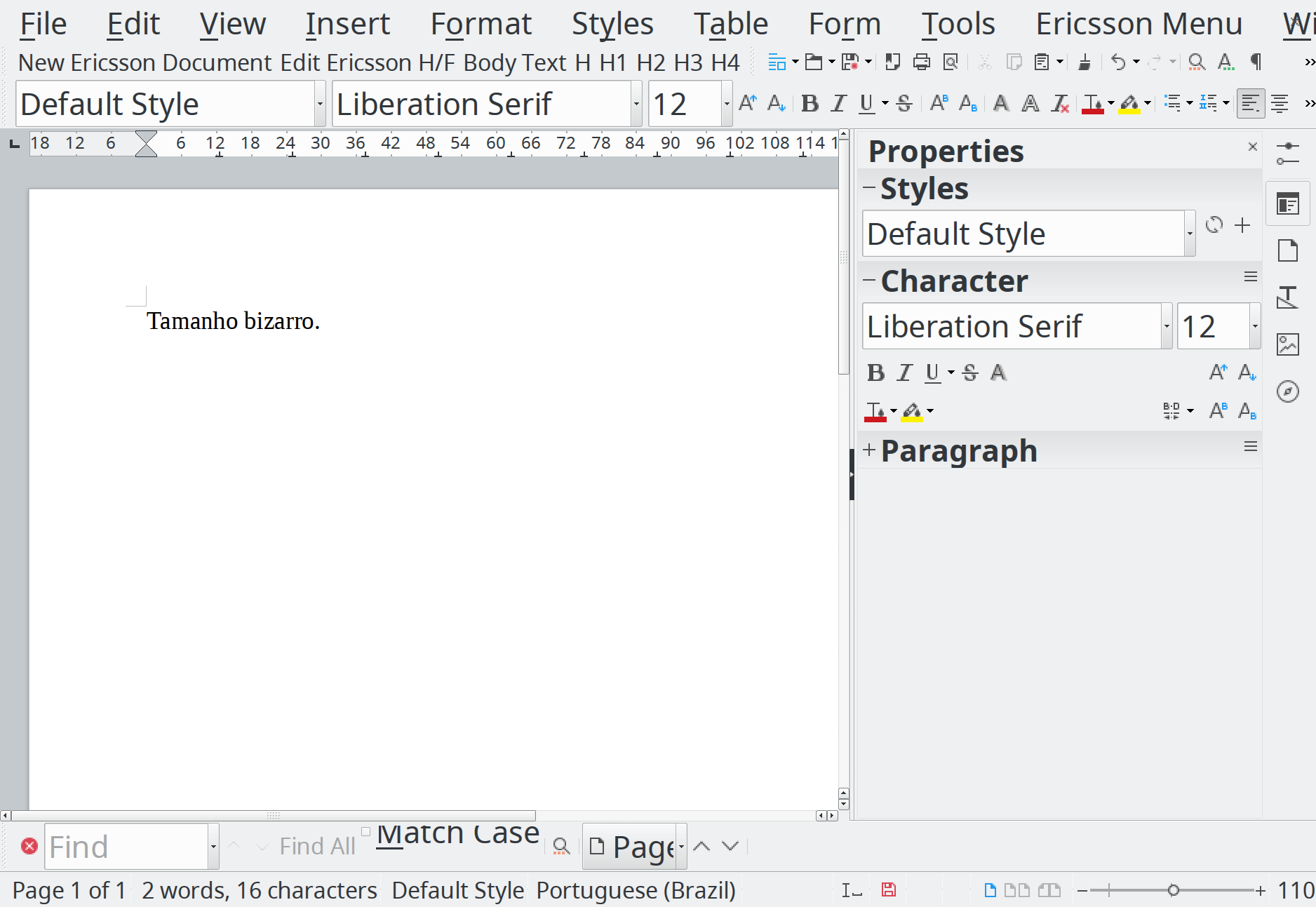
Se existe algo que é um inferno em Linux é fonte. Como uso KDE como desktop padrão com HiDPI em 196 pontos, os aplicativos em GTK teimam em usar outras fontes e com tamanhos diferentes. É tipo uma maldição de Montezuma. Um dia seu ambiente gráfico está tudo certo, e de repente fica tudo com cara de que você tem problemas de visão.
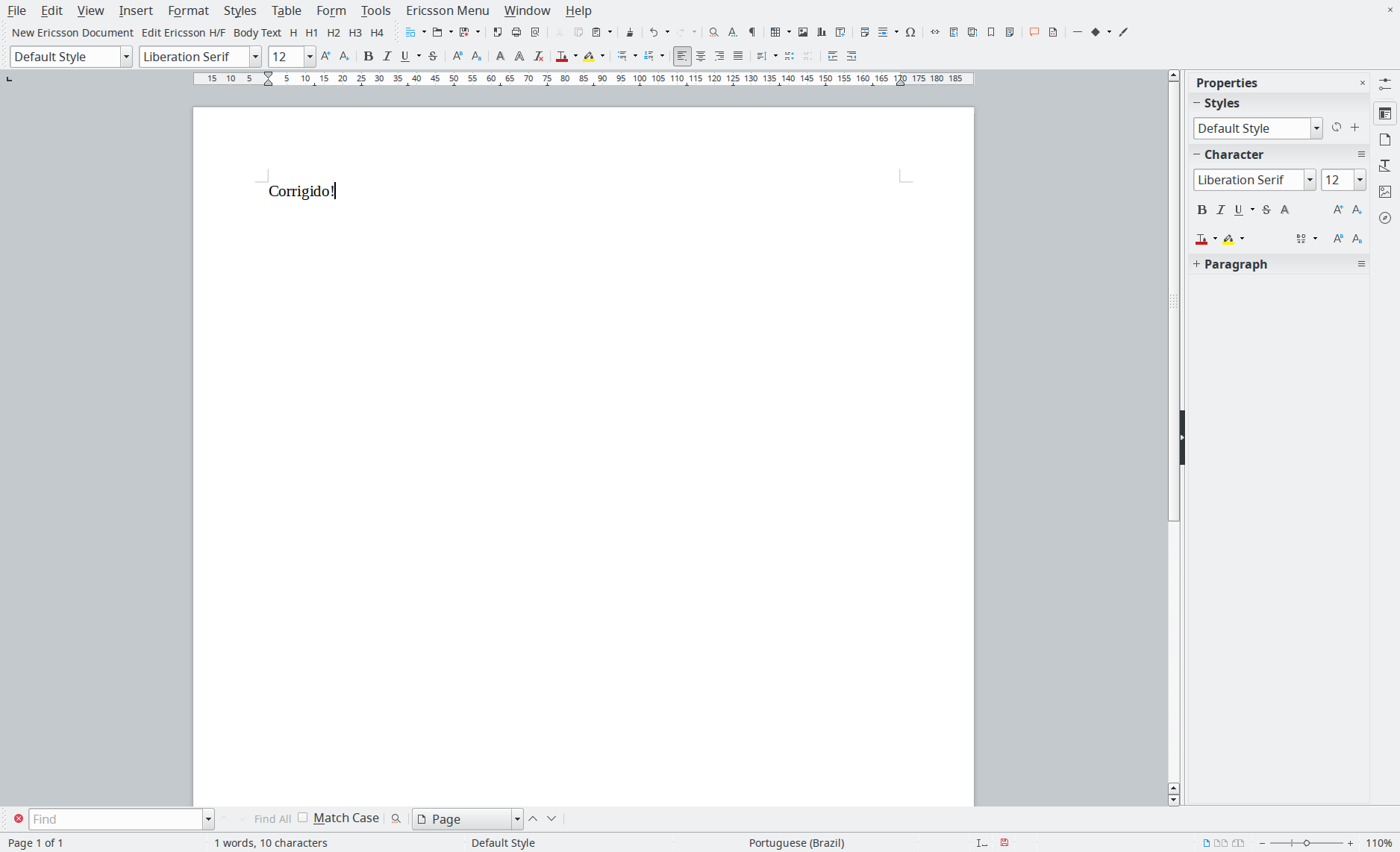
E pior que os aplicativos escritos em GTK não respeitam o tamanho de fonte colocado no KDE. Uma das maneiras que encontrei foi usando comandos diretamente vi gsettings pra verificar o que os aplicativos em GTK têm configurados:
helio@xps13:~$ gsettings get org.gnome.desktop.interface text-scaling-factor helio@xps13:~$ gsettings get org.gnome.desktop.interface monospace-font-name helio@xps13:~$ gsettings get org.gnome.desktop.interface document-font-name helio@xps13:~$ gsettings get org.gnome.desktop.interface font-name helio@xps13:~$ gsettings get org.gnome.desktop.wm.preferences titlebar-font
e depois trocar pra padrões mais confortáveis.
helio@xps13:~$ gsettings set org.gnome.desktop.interface text-scaling-factor 0.5 helio@xps13:~$ gsettings set org.gnome.desktop.interface monospace-font-name 'Ubuntu Mono 10' helio@xps13:~$ gsettings set org.gnome.desktop.interface document-font-name 'Ubuntu 10' helio@xps13:~$ gsettings set org.gnome.desktop.interface font-name 'Ubuntu 10' helio@xps13:~$ gsettings set org.gnome.desktop.wm.preferences titlebar-font 'Ubuntu Bold 10'
E às vezes ainda preciso forçar um re-cache das fontes usadas com o comando:
helio@xps13:~$ sudo fc-cache -f -v
mas o resultado final é satisfatório (em geral basta fechar e abrir os programas pra encontrar a interface com as fontes corrigidas).
Quem tem filho sabe que não é fácil impor limites. Especialmente quanto uso de tablets ou smartphones ou até mesmo da TV. Eu tenho em casa um problema com YouTube que acaba virando a atração principal com um conteúdo bem longe de ser didático. Tentei até onde podia limitar no "YouTube é das 18 às 20" mas tenho fracassado miseravelmente.
Então resolvi apelar aos meus conhecimento computacionais e ao roteador por onde passa todo o tráfego da casa, e que roda open-wrt.
Criei um sistema básico em shell script que bloqueia tudo que é relacionado com YouTube em horários pré-determinados. Não ficou bonito, mas funciona.
#! /bin/sh
# save it into /usr/lib/scripts/firewall.sh
# and add into scheduled tasks as
# */5 * * * * /usr/lib/scripts/firewall.sh
hour=`date +%H`
minute=`date +%M`
echo "hour=$hour"
echo "minute=$minute"
status_file=/tmp/firewall_status
blocked_pattern="youtubei.googleapis.com googlevideo.com ytimg-edge-static.l.google.com i.ytimg.com youtube-ui.l.google.com www.youtube.com googleapis.l.google.com youtubei.googleapis.com video-stats.l.google.com ytimg-edge-static.l.google.com"
enable_firewall() {
echo "Enabling firewall"
for chain in INPUT FORWARD OUTPUT
do
count=1
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
count=`expr $count + 1`
done
done
echo iptables -I $chain $count -p udp --sport 443 -j DROP
iptables -I $chain $count -p udp --sport 443 -j DROP
count=`expr $count + 1`
echo iptables -I $chain $count -p udp --dport 443 -j DROP
iptables -I $chain $count -p udp --dport 443 -j DROP
count=`expr $count + 1`
done
}
disable_firewall() {
echo "Disabling firewall"
for chain in INPUT FORWARD OUTPUT
do
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
done
done
echo iptables -D $chain -p udp --sport 443 -j DROP
iptables -D $chain -p udp --sport 443 -j DROP
echo iptables -D $chain -p udp --dport 443 -j DROP
iptables -D $chain -p udp --dport 443 -j DROP
done
}
case $1 in
start) enable_firewall
echo -n "enabled" > $status_file
exit 0;;
stop) disable_firewall
echo -n "disabled" > $status_file
exit 0;;
esac
# possible status
# enabled|disabled
# start
# from 7:55-09:59
time_status=disabled
if [[ $hour -ge 7 && $hour -lt 10 ]]; then
time_status=enabled
if [[ $hour -eq 7 ]]; then
if [[ $minute -lt 55 ]]; then
time_status=disabled
else
time_status=enabled
fi
fi
fi
# from 12:00-17:59
if [[ $hour -ge 12 && $hour -lt 18 ]]; then
time_status=enabled
fi
# from 20:00-21:59
if [[ $hour -ge 20 && $hour -lt 22 ]]; then
time_status=enabled
fi
echo "time_status=$time_status"
current_status=
if [[ -f "$status_file" ]]; then
current_status=`cat $status_file`
fi
if [[ $current_status = $time_status ]]; then
echo "nothing to do"
else
if [[ $time_status = "enabled" ]];then
echo "loading firewall rules"
enable_firewall
fi
if [[ $time_status = "disabled" ]];then
echo "removing firewall rules"
disable_firewall
fi
echo -n $time_status > $status_file
fi
Basta salvar o arquivo em /usr/lib/scripts/firewall.sh e adicionar à crontab do open-wrt.
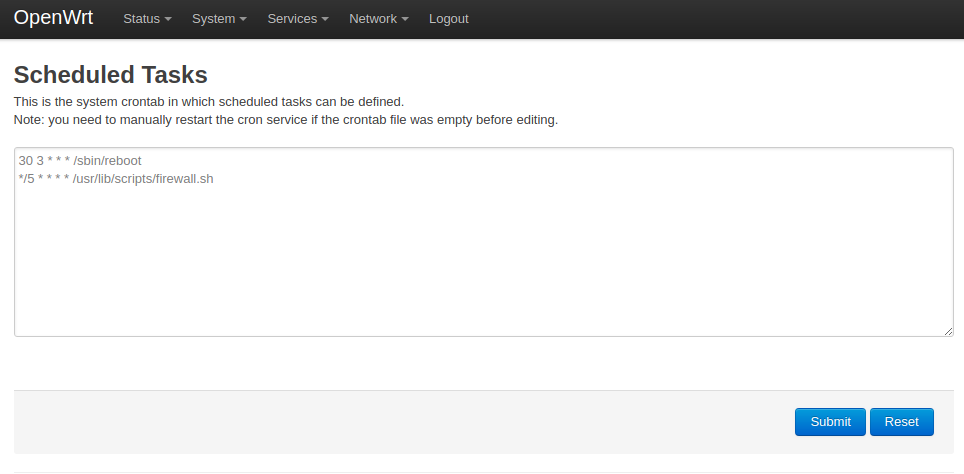
O código fonte está também publicado no github: https://github.com/helioloureiro/homemadescripts/blob/master/openwrt-firewall-block-youtube.sh

25 anos de alegrias e tristezas. Felizmente mais alegrias :)
Desses 25 anos, estamos juntos 20 anos. Acho. Talvez mais.
