*Nota: esse artigo foi originalmente escrito pra Revista Espírito Livre, mas como a edição não saiu estou postando aqui.

Olá leitores da Revista Espírito Livre. Eu venho do futuro pra falar sobre os 30 anos de Linux. Futuro muitos anos à frente? Sinto mas estou apenas algumas horas adiantado devido ao timezone em que vivo. Mas tenho um certo prazer em dizer que celebrei a chegada do ano novo antes que todo mundo no Brasil, e avisando o que os aguarda do futuro (geralmente nada). E vamos ser sinceros: no mundo de hoje com tanta gente acreditando em terra plana, rejeitando vacinas e tomando cloroquina, dizer que venho do futuro é até uma licença poética aceitável.
Mas vamos voltar ao assunto do artigo: Linux. E seus 30 anos de vida. Foi uma comemoração bem moderada, sem grandes festas, sem bolo pra comemorar, e nenhuma meetup organizada. Ao menos por aqui. Talvez a culpa fosse da pandemia. Talvez fosse porque Linux já é tão comum e seu uso é diário, o que não nos faz mais sentir que seu aniversário é uma data especial. Mas são 30 anos desde que um estudante finlandês tentou escrever um minix melhor que o minix, um sistema operacional Unix para estudantes, e achou que nunca seria tão grande quanto o projeto GNU.
Não, não vou entrar na polêmica de quem é maior que quem entre GNU e Linux. Ambos têm seus méritos e são gigantes. E não estaríamos onde estamos sem eles. O projeto GNU já completou 38 anos também no dia 27 de setembro, mas o artigo é sobre Linux. Então deixo meus parabéns ao projeto GNU mas tenho de dizer que mesmo o sistema operacional mais comum que usamos pelas distros sendo um GNU/Linux, é Linux que o chamamos. Isso começou desde muito tempo atrás e duvido que mude algum dia. Alguns podem insistir em chamar de GNU/Linux, mas se até mesmo o Debian mudou de Debian GNU/Linux pra simplesmente Debian, que diremos de Linux além, é claro, de apenas Linux? Nomes curtos têm tendência a ficar melhores e as pessoas relacionam-se com isso mais facilmente.
Parte dessa tradição de denominação veio como herança de como eram os sistemas Unix nos princípios dos tempos, ou anos 70 em Unix time. Primeiro existiu o Unix da AT&T, em seguida surgiu uma melhoria desse que ficou conhecida como BSD, de Berkeley. E assim foi por quase 10 anos. O Unix BSD era basicamente o mesmo Unix, mas com drivers, ferramentas, scripts e até sistema de boot de Berkeley. E era o sistema operacional completo, com kernel, bibliotecas, editores, shell, etc. Mesmo os sistemas que surgiram da compra da licença do Unix da AT&T, como SunOS da Sun – atual Oracle, eram sistemas operacionais completos mas com nomes curtos como SunOS, HP-UX, SCO, Xenix, etc.
Quando o bom doutor, Richard Stallman, teve a epifania de criar um sistema operacional totalmente livre, o sistema operacional GNU – pra poder dizer que GNU não era Unix (GNU is Not Unix), nunca pensou em criar tudo de forma coesa. Ele começou da forma simples e em partes. Primeiro as ferramentas: editor (se bem que emacs é mais uma religião que editor mas isso é assunto pra outro artigo bem mais longo que esse), compilador, shell, etc. Mas tudo era separado em seu repositório e era necessário baixar os fontes e compilar sua versão usável. Então nunca houve uma identidade de sistema operacional GNU. Era a biblioteca sunsite com ferramentas GNU. Até surgir o Linux e permitir criar um sistema operacional completo. Claro que pra isso foram necessários os surgimentos das distros, um encurtamento para distribuições, que empacotavam o Linux com GNU e distribuíam como sistema operacional.

E Linux nasceu como um kernel, como já descrevi antes no “um minix melhor que o minix”, mesmo que Tannenbaum discordasse disso, e cresceu tanto em linhas quanto em contribuidores e até mesmo em ecossistema. Hoje em dia Linux é um projeto, uma fundação. E abrange de redes à containers com OCI, Open Container Iniciative. E apesar de ter nascido pra rodar software da GNU como bash e ser compilado com GCC, hoje em dia já roda em sistemas sem nada da GNU como Alpine e Android. E compila com o llvm. Não totalmente como com GCC, mas é um trabalho em andamento e deve em algum momento tornar o Linux compilável com qualquer compilador C. Isso sem comentar o suporte à linguagem rust, que poderá talvez nos próximo 10 anos virar boa parte do código do kernel. Talvez até a maior parte dele. Quem sabe?
Desses 30 anos eu já comentei sobre os surgimento das distros. Falta escrever sobre o desaparecimento delas. Atualmente o site distrowatch, famoso por enumerar as distros que surgiam, parece mais um obituário. A grande maioria das distros que surgiram também sumiram. Não que alguém vá sentir falta da Bieber Linux ou da Hanna Montana Linux, mas sei de gente que até hoje chora a perda do – um momento pra respirar e segurar a náusea – kurumin. A maioria dessas distros recebeu a alcunha carinhosa no Brasil de REFISEFUQUIs. Aqui peço a ajuda ao amigo Fábio Benedito pra descrever o que são:

As REFISEQUIs mostraram um lado interessante sobre a liberdade do software livre: cada um podia e ainda pode fazer um fork de alguma distro e criar a sua própria. Ao contrário das distros que contavam com legiões de voluntários ou funcionários, dependendo se fossem empresas ou projetos voluntários como Fedora e Debian, as REFISEFUQUIs eram batalhas de um soldado só. Talvez dois. Mas não muito mais que isso. Conseguiam fazer o primeiro release, o segundo, então o... o... o... acabava o gás. Talvez algumas tenham ido um pouco mais longe que isso, mas ninguém sobrevive ao tempo sem organização e principalmente mãos pra ajudar a manter tudo funcionando. Talvez o propósito fosse somente ter seu sistema listado na distrowatch. Nesse caso tenho de admitir que a missão foi cumprida. Amigos, amigos, negócios à parte.
E o que dizer das empresas? Nesses 30 anos muitas delas surgiram pra levar o Linux pra todos como principal sistema operacional do desktop. Inclusive com a versão tupiniquim com a Conectiva. E eram muitas. Infelizmente o cenário atual conta com apenas algumas delas. As que não faliram sofreram um processo de compra ou fusão. E eventualmente faliram. Talvez a venda de software gratuito não fosse tão bom negócio assim? A venda da Red Hat pra IBM por mais de 34 bilhões de dólares dizem o contrário. O que faltou então? Talvez menos geeks programadores e mais pessoas de negócios gerenciando a empresa? Talvez. A verdade é que muita coisa foi feita sem muito planejamento e só imaginando bastasse o software ter licença GPL ou qualquer outra livre e seria o suficiente pra empresa sobreviver. Infelizmente a realidade mostrou que não era bem isso.

E não só de dramas empresariais viveu o Linux nesses 30 anos. Teve também o caso da vira-casaca Caldera Open Linux, que comprou o que sobrou da SCO e aplicou um processo por roubo de propriedade intelectual contra o Linux. O caso ficou anos num tribunal e finalmente teve um fim. Os gestores da massa falida da empresa, que por motivos óbvios não conseguiu sobreviver no negócio, fechou um acordo muito bom de mais de 14 milhões de dólares com a... IBM!? Não me perguntem o porquê da IBM ter sido envolvida em suposto roubo de propriedade intelectual do Linux, mas no fim ela comprou o que sobrou de patentes e propriedade intelectual e encerrou o assunto.
Outro caso de tribunal nesses 30 anos de Linux que ficou muito famoso foi a prisão de Hans Reiser, criador do filesystem reiserfs, um dos primeiros filesystems com journaling no Linux e que eu pessoalmente cheguei a usar, acusado de assassinato. Não que sua prisão tenha alguma relação com Linux. Pelo contrário. Mas foi algo que impactou a direção dos filesystems em Linux, que estavam em suas infâncias no mundo journalling. Depois de sua prisão eu fui movido por, digamos, forças superiores a usar o XFS que foi doado pela SGI ao Linux. E até hoje é meu filesystem predileto, junto com LVM.
Outro drama vivido na lista do kernel durante esses 30 anos foi o eventual sumisso do próprio Linus Torvalds seguido da introdução de um código de conduta,vonde ele mesmo aceitava que tinha um comportamento tóxico e que precisa fazer terapia para endereçar seus problemas de uma melhor maneira. Não faltou gritaria em relação ao código de conduta com ataques dizendo que o mesmo iria coibir a participação das pessoas no desenvolvimento do kernel. Atualmente ninguém questiona o quão benéfico foi esse código de conduta, assim como quão tarde veio a ser adotado. E, claro, ainda há quem diga que ele motivou muita gente a não participar mais do desenvolvimento. Quantos? Esse será um dado que nunca veremos.
E ao longo desses 30 anos do Linux vimos também a grande batalha dos sistemas de inits, onde systemd saiu como vencedor e upstart virou lembrança. De todos os males ditos sobre o systemd na época, poucos realmente aconteceram, se é que aconteceram. E justiça seja feita: systemd é muito, mas muito mais que um mero sistema de init.
Claro que algumas distros seguem longe do systemd, como se isso fosse algum certificado de pureza. Mas nada que abale a realidade de que systemd funciona, vai muito bem obrigado, e trouxe flexibilidade e robustez ao Linux. Se antes precisávamos de gambiarras pra monitorar se um daemon não tinha dado crash e fechado inesperadamente, agora apenas temos o systemd lá monitorando e garantindo tudo funcionando. Ou quase. Claro que aparecem uns problemas aqui e ali, mas nada que negue o fato de que systemd melhorou muito a forma de como Linux tem seus daemons rodando.
crond? Coisa do passado. systemd tem agendamento de tarefas e substitui completamente o crond, que por sua vez poderia ter um crash e simplesmente parar de funcionar. E não para por aí o canivete suíço de funcionalidades do systemd.
E nesses anos vimos como Linux chegou ao mundo dos games. Primeiramente de forma modesta com jogos portados pela Loki games. Depois de um tempo de silêncio e de abandono, uma voltou triunfante com o suporte da Steam, a gigante de jogos digitais.
Mas mesmo a Steam passou por maus bocados. Sua estratégia de abraçar o Linux foi para fugir dos braços da Microsoft, que na época mudava sua visão sobre jogos com o Windows 8, tentando forçar os jogadores a usarem sua própria loja de jogos. Então pra ter massa de manobra e poder negociar, a Steam abraçou o Linux. E lançou seu próprio sistema operacional chamado SteamOS, baseado no Debian. E foi um sucesso. Ou quase isso.
A quantidade de jogadores em sistemas Linux chegou a dobrar de 1 para 2%. Mas não mais que isso. Apesar de todo o suporte, o uso nunca cresceu como esperado.
Mas foi o suficiente pra dar o que a Steam precisava: algo pra negociar e tempo. E com o tempo o CEO da Microsoft foi trocado, e por um que tanto declarou amar Linux, e abraçou definitivamente dentro da empresa, assim como provavelmente chegou num acordo com a Steam. E ficamos sem muitas novidades.
Isso até pouco tempo atrás, quando a Steam anunciou novamente algo bastante interessante: Steam deck. Basicamente um PC portátil com tela e controle conectados que permite jogar em qualquer lugar seu catálogo de jogos e... rufem os tambores... rodando Linux. Dessa vez a escolha foi o Arch Linux, a nova distro do pedaço que todo mundo ama. Eu incluso.
Essa nova estratégia da Steam muda seu foco de apenas ser uma plataforma digital de jogos pra vender console de jogos, competindo com Playstation, Xbox e Nintendo Switch. Por outro lado a maioria dos jogos continuaram não sendo nativos pra Linux, mas rodando através de um wine melhorado da própria Steam, o proton. Se chegou agora e não conhece o wine, esse é um software que faz uma tradução das chamadas de programas Windows para Linux. O resultado disso é a possibilidade de rodar programas feitos para Windows diretamente em Linux. E nisso acho que a mudança da Steam vai dar uma piorada pra jogos nativos em Linux. Que estúdio gastará tempo e pessoal pra fazer um jogo que rode em Linux quando pode fazer em Windows, o que provavelmente já fazem, e apenas trabalhar pra rodar bem em proton? Então é uma vitória com um certo gosto amargo de derrota.

Todo os anos eu além de dizer que estou no futuro na virada do ano, também digo que o próximo ano será o ano do Linux no desktop. E isso já faz uns... 15 anos? Talvez mais. Tanto que sempre uso a famosa imagem/meme do nerd dizendo isso (que aliás nem sei quem é pra dar os devidos créditos).
E esse ano nunca chegou. Não da forma que eu imaginava pelo menos. Atualmente o laptop chromebook é um dos mais vendidos para área de educação tanto nos EUA quanto na Europa. O Brasil não entra na conta por ainda viver um bom atraso tecnológico, mas aqui na Suécia minha filha tem seu chromebook na escola pra pesquisar e fazer os exercícios escolares. Na Suécia não houve um lockdown como em outros países durante a pandemia, mas alunos do colegial pra cima foram solicitados pra estudarem de casa. E cada um levou seu chromebook pra isso. E isso aconteceu em vários outros países, não somente aqui.
Sem contar que muitos desktops e laptops foram trocados por tablets e smartphones. Eu mesmo leio bastante em meu tablet Android e passo as manhãs lendo as notícias no meu smartphone (que diga-se de passagem tem a tela tão grande que praticamente precisei comprar uma calça nova e experimentar antes se ele cabia no bolso), também Android. Então a realidade de desktop que esperávamos não é mais aquela de 15 ou 20 anos atrás. Virou uma realidade de cloud, nas nuvens.
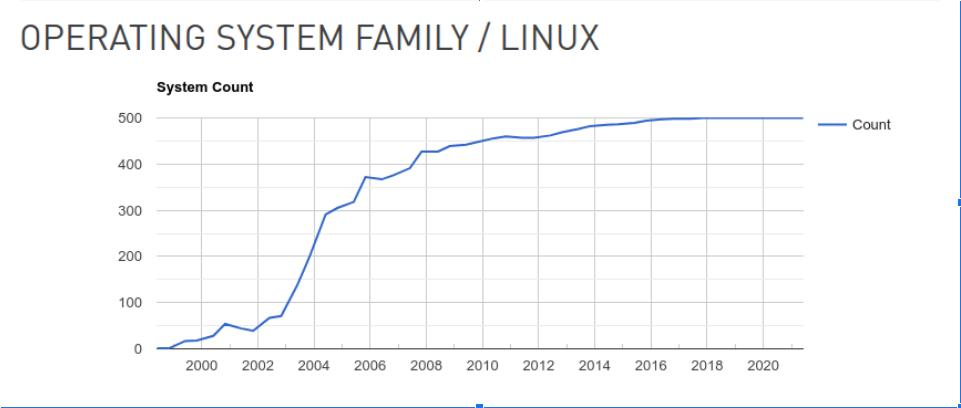
Mesmo que, pra desgosto de alguns, cloud rode no computador dos outros, atualmente é impossível fugir dele. Assim como tablets, smartphones, smartTVs, raspberrypis e muitos outros dispositivos, o cloud roda baseado em Linux. Linux virou o senhor supremo de todas as áreas. De geladeiras a super computadores, sendo presença prepobderante na lista dos 500 mais rápidos super computadores do mundo, sendo liderado atualmente pelo Fugaku do Japão com 7.630.848 núcleos de CPU e impressionantes 537.212 teraflops por segundo de desempenho de pico. Nesse é possível jogar minecraft sem lag.
Mas a discussão é no desktop, aquele ambiente dominado pela Microsoft. Sim, esse mesmo. Estamos em 2021 e ainda hoje as pessoas sofrem com vulnerabilidades e malwares enviados por mail no sistema de Redmond. Praticamente o mesmo problema desde que lançaram o Windows 95. E as pessoas continuam usando mesmo assim. Então eu duvido que Linux consiga entrar nesse mercado onde vírus e ransomware já são tidos como coisas absolutamente normais do dia a dia. Ele ficará naqueles que gostam de ter um sistema melhor, mais rápido e mais seguro.
E a liberdade? Sim, existem aqueles que usarão pela liberdade. E talvez por outros motivos. Mas isso não é importante, mesmo que pra eles sejam. O importante é que usem.
E aqui deixo escrito a mensagem que sempre passei e que sempre indignou muita gente: usem software livre. Não percam tempo com política, liberdade, filosofia, etc. Apenas usem se não for seu caso ainda. Isso abrirá portas para você.
Gostou? Então não fique só na instalação de uma distro. Ou de várias. Linux e outros software livres são baseados em... software. Então entre de cabeça. Aprenda a programar usando shell scripts. Depois vá pra linguagens como perl, python e nodejs. E não pare aí. Entre de cabeça.
Ajude um projeto pois tanto Linux quanto todo o ecossistema de software livre ainda dependem de voluntários, que estão ali pra ajudar e aprender. Então participe. Faça parte. Tenho certeza não se arrependerá.
Finalmente deixo aqui meu viva ao Linux e seus 30 anos.

Hoje é 20 de março e finalmente a temperatura atingiu um nível o suficiente pra abrir as janelas pela primeira vez no ano: 15°C. Peço desculpas pelas manchas de poeira acumalada pelo inverno, mas ainda não foi quente o suficiente pra passar um tempo limpando as janelas pelo lado de fora.
Se chegou aqui e ainda não leu os outros artigos, então pare e leia agora:
Aproveitando toda a emoção que a primavera traz, também recebemos nosso imposto de renda. O órgão que controla a cobrança de imposto é o mesmo que cuida do registro de pessoas, o skatteverket. Aqui na Suécia nós não fazemos o imposto de renda: ele já vem pronto. Então nos resta apenas confirmar os dados e aceitar. E pronto.

Como tudo é ligado com seu número pessoal aqui, fica fácil pro skatteverket saber qualquer receita que recebeu em sua conta no banco, assim como a gastou. Tudo aqui é registrado.
Você pode alterar o relatório de imposto que recebeu adicionando alguns dados a mais, como serviços de limpeza ou empregada, que emitem um recibo chamado RUT onde 50% do valor pago pelo serviço pode ser deduzido do imposto. Geralmente nem é preciso fazer isso pois o prestador de serviço que emite um RUT pra você já faz o registro junto ao skatteverket. Mas a opção de editar o relatório de imposto de renda existe. Só que qualquer alteração no mesmo já significa que está na malha fina. Emitir nota fiscal amiga? Aqui isso não é possível.
A declaração de imposto de renda pode chegar em forma de papel, como essa da imagem acima ou por formato digital se assim preferir, que é meu caso. Você pode responder que está ok pelo site diretamente, ou pelo correio ou até mesmo por SMS. Eu geralmente faço pela página web. Nenhum plugin adicional é necessário. Só entrar, conferir os dados e olhar se tem algo a pagar ou a receber e enviar.
Ouço isso o tempo todo. Então vamos ao números do meu imposto de renda desse ano. Então no ano passado ou paguei exatamente... rufem os tambores... 26.69%. Contando do que recebi o ano todo e de quanto imposto foi devido.
Aqui o imposto é cobrado por faixas salariais como no Brasil, mas tem o imposto progressivo: quanto maior o salário, maior o imposto a ser pago.
Eu não sei bem as faixas como estão hoje em dia, então estou usando a referência daqui: https://everythingsweden.com/tax-in-sweden/

Esse cáculo de 31% depende de onde mora. Se é numa zona com poucos serviços e precisa de desenvolvimento, esse imposto pode chegar à 36%. Como eu moro no subúrbio de Estocolmo, mas ainda parte de Estocolmo, o imposto é mais baixo. É a parte que vai pra manter escolas, dentistas e médicos na sua região diretamente. Então onde o imposto é mais alto o custo de vida é mais baixo, pois é uma região mais afastada. E quanto mais próximo do centro, mais baixo o imposto mas mais alto o custo de vida, incluindo aluguéis.
Algumas coisas que o imposto morde você com força aqui que escorre até uma lágrima quando recebe o salário: horas extras tem 50% de imposto direto em cima do valor pago, "benefícios" pagos pela empresa cobram 50% de imposto em cima, o que inclui até uso de lavanderia em viagem de trabalho e ticket alimentação.
Outro impostos estranhos que são pagos aqui: televisão pública (1300 sek/ano) e tem um imposto-velório, que você tem todo o serviço funerário disponível quando morrer sem precisar de ninguém pagar por nada. Você já pagou durante a vida. Eu não achei quanto é mas é um valor bem baixo.
Update: achei uma referência do imposto de funeral em https://www.scb.se/en/finding-statistics/statistics-by-subject-area/public-finances/local-government-finances/local-taxes/pong/statistical-news/municipal-taxes-2020/

são 25 centavos por mês.
Estão abertas as inscrições para a caravana GNU/Bumba, que levará os interessados, de São Paulo até Porto Alegre, onde ocorrerá o III
Fórum Internacional de Software Livre,nos dias 02, 03 e 04 de Maio. O ônibus (com ar-condicionado e leito) passará também por Curitiba e Florianópolis, para embarque dos companheiros desta região que desejarem
se juntar a caravana. A organização da caravana já reservou as vagas necessárias no Hotel Elevado, que fica próximo à PUC, local onde será realizado o Fórum. O Fórum, http://www.softwarelivre.rs.gov.br/forum/, evento anual que está em sua terceira edição, contará com a presenta de grandes
palestrantes, como Bob Chassell (FSF), Paul Everitt (Zope), Miguel de
Icaza (Ximian), Patrick Stakem (NASA); Shane Hathaway [Python], David
Sugar (GNU Bayonne), Ralf Noldem (kDevelop), Tim Ney (Gnome Foundation);
Andrei Zmievski (PHP-GTK), Peter Salus (Matrix), Larry Wall (Perl) e
Jon "maddog" Hall. Não perca esta oportunidade de ouvir grandes nomes do movimento Software Livre e de conhecer os amigos de todo Brasil que estarão reunindo-se neste evento imperdível! Valores Ônibus: R$ 100,00 (Ida e volta. O ônibus ficará a disposição para nos levar até a PUC todos os dias) Vale lembrar que, quanto mais pessoas, menor o valor. [:)] Hospedagem: As diárias do Hotel Elevado terão um custo de R$ 25,00 (quarto individual) ou R$ 18,00 (duplo). O pagamento do ônibus deverá ser realizado por depósito bancário Wendell Martins Borges
E assim, com essa singela mensagem, Wendell (mais conhecido como perlporter), juntou um bando de nerds numa das melhores e mais divertidas viagens até o FISL, o GNU/Bumba. Todo mundo junto, num ônibus de viagem, falando sobre Linux, FreeBSD, software livre, etc. Foram dias intensos com palestras e workshops, mas sobrevivemos pra estar aqui, 20 anos depois, e contar essa história.
Como toda viagem, começou lenta e sonolenta, pegando recém-chegados de outros estados ou mesmo países na rodoviária do Tietê na capital de São Paulo. E partiu rumo à Porto Alegre, com parada em Curitiba e Florianópolis. Pra animar o pessoal, uma parada pra comprar cerveja. E tudo mudou. Virou um carnaval sobre rodas.
Naquela época eu consegui pegar emprestada a máquina fotográfica do departamento, que usávamos pra fazer site survey. A fotos em resolução 640x480p salvas em disquete são as imagens vistas no vídeo abaixo (tá... eu passei num esquema com machine learning pra aumentar o tamanho das fotos). Grande época, com Larry Wall aparecendo no workshop de perl, pessoal do CIPSGA, Debian Brasil em formação (naquela época era tudo muito dividido por estados com Debian-SP, Debian-RS, etc), SamaBSD e muitos outros.
O SamaBSD foi uma empresa que surgiu pra vender o FreeBSD. E só existiu durante o FISL. Depois disso nunca mais ouvi falar da empresa e não tenho ideia do motivo de não ter ido pra frente.
E durante essa viagem eu já usava FreeBSD no meu laptop. Lembro que fizemos uma competição de quem dava boot mais rápido, eu com FreeBSD, e... acho que era o PH com Debian. Ganhei com larga margem. Na volta já tínhamos convertido boa parte do GNU/Bumba pra BSDBus :D
Das pessoas que aparecem nas fotos e que consegui reconhecer:
E muitos outros que agora não lembro o nome, afinal já se foram 20 anos.
Um grande agradecimento ao Perlporter por ter tido a coragem de organizar essa viagem. Foi realmente inesquecível e muito divertida. Um evento organizado por e-mail numa época em que não nos conhecíamos pessoalmente e sabíamos apenas os ids de cada um. Apesar de tudo, foi algo que mostrou como o software livre era baseado em comunidade.
Valeu tru!
![]()
Depois que publiquei o artigo sobre o firewall no openwrt em refatorando meu script de bloqueio de youtube no openwrt, eu ainda precisei dar umas boas mexidas no script pra melhorar. Inclusive comprei até um roteador novo pra poder usar o OpenWRT melhor e com mais facilidade, um Linksys WRT3200ACM que suporta nativamente o OpenWRT. Parece que seu firmware original é até baseado no OpenWRT, mas durou exatamente 5 minutos na minha mão. Só o tempo de conectar e carregar o OpenWRT nele.

O inconveniente é que mexer remotamente em regras de firewall invariavelmente leva a... ficar com a conexão bloqueada. Algumas vezes basta reiniciar mas em outras é preciso rebootar no botão.
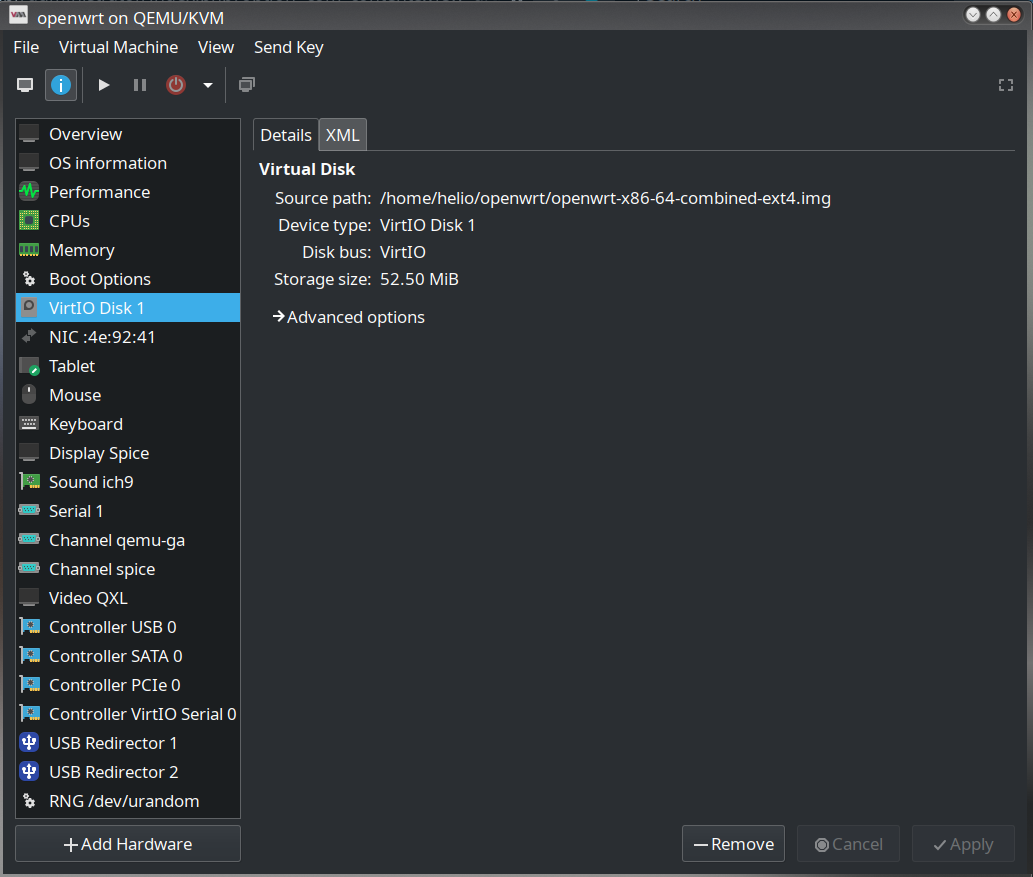
Então procurando alguma forma de melhorar meu workflow ao invés de usar o bom e velho XGH, eu acabei achando uma image de VM do openwrt. E instalei aqui usando o libvirt. As imagens ficam aqui:
https://archive.openwrt.org/snapshots/trunk/x86/64/
É um repositório pra x86_64. Eu usei a image openwrt-x86-64-combined-ext4.img.gz, que bastou mapear no virt-manager e usar. Deixei com 2 cpus e 512 MB de RAM, que é a mesma memória disponível no Linksys WRT3200. E isso facilitou bastante mexer com o script. Resolvi um bug que as conexões ficavam ativas quando deveriam estar desabilitadas. Então se for usar meu script, pegue do github pra ter a versão mais atualizada.
E esse foi então o resultado do uso do obamawatcher que descrevi em Obama está observando você durante o ano de 2021.
É possível ver a barba crescendo :)

Se chegou aqui e ainda não leu os outros artigos, então pare e leia agora:
Peço desculpas pelo último artigo sobre o inverno. Mas depois de alguns anos vivendo no frio, gelo e escuridão, eu já estou parecido com o argentino no Canadá. Exceto que não cai pra quebrar nenhum osso ainda, nem bati carro na neve e muito menos penso em voltar pro Brasil.
Eu larguei meu rant sobre o inverno e não comentei de algumas coisas loucas que já fiz aqui nessa época do ano. Teve uma vez que caiu uma tempestade de neve que era prevista ser a pior da última década. Era tipo uma confluência de tempestades de neve juntas com mais uma frente fria chegando e tudo mais. Era algo como o dia que até o inferno congelaria. Chamaram carinhosamente de "a besta do leste", the beast of East.
Sabendo das notícias, eu e meus colegas combinamos de trabalhar no tal dia remotamente. E o que aconteceu? Nada. Não nevou. Ficou tudo ok. Então durante aquele dia decidimos todos ir pra empresa no dia seguinte.
E eu fui de bicicleta.
Só que a tal mega tempestade de neve pegou algum congestionamento na Alemanha e chegou no dia seguinte. E com força. Eu por acaso consegui registrar muita coisa.
Foi até engraçado, mas o ruim foi que nevou muito. Demais. Carros foram soterrados na neve. Quem estava na empresa saiu por volta das 10 horas da manhã porque os carros estavam desaparecendo na neve. E quem saiu nesse horário ficou preso num mega congestionamento, porque estava intransitável. E eu com a minha magrela.
O esforço de pedalar na neve é parecido com o de pedalar em areia fofa (chuto que seja porque nunca tentei andar de bicicleta na praia, mas andando é a mesma sensação, então deve ser também parecido). Cansa. Cada 2 ou 3 pedaladas que eu dava, andava meia pedalada. Mas eu sobrevivi. Fui e voltei ao trabalho numa das piores tempestades de neve dos últimos tempos.
Só que de noite, enquanto eu dormia, simplesmente tive câimbras nas duas batatas das pernas. Eu lá, dormindo e babando, e de repente eu pulo (e caio) da cama gritando de dor com as duas pernas travadas. Dizem que maratonistas novatos têm esse tipo de reação depois do esforço extremo da corrida. Eu precisei trabalhar o restante da semana de casa porque nem andar eu conseguia direito.
Foi louco, mas eu fiz. Acho que maratonistas também sentem a mesma coisa. Tanto de adrenalina e sentido de superação quanto as câimbras. Não sei se faria novamente. Mas como estamos todos em casa por conta da pandemia, então não preciso pensar muito nisso.
E agora um fato que aconteceu esses dias e tirei uma foto pra registrar.

É a mesma foto que abri esse artigo, digo, o mesmo lugar, mas repare nas crianças na plataforma.
Eu esqueci de dizer nos artigos anteriores que as escolas levam as crianças pra excursão usando o transporte público. A pessoa mais na frente é a professora ou professor. E de manhã é bem comum ver um monte de alunos na plataforma do metrô. Em alguns casos eles vão à biblioteca do bairro, que fica a uma estação dessa, em outras vão visitar museus. Sim, museus. Os museus aqui na Suécia, e principalmente em Estocolmo que tem muitos, é um lugar de diversão pras crianças. Eles têm geralmente um parque indoor temático, relacionado à exposição do museu, onde as crianças podem brincar e aprender.
As fotos a seguir são das partes pras crianças brincarem no tekniska museet, museu de tecnologia. O mesmo onde está o primeiro servidor do piratebay.



E enquanto as crianças estão entrando ou saindo do trem do metrô, o maquinista espera. A última pessoa a entrar e sair é o professor. Quando a turma é muito nova, como jardim da infância, eles vão em 2 professores ou então duas turmas de crianças com 4 professores. E sempre tem um que sai ou entra por último e faz sinal pro maquinista que está ok pra ir. E só então o trem fecha as portas e segue. É algo tão, mas tão, mas tão comum aqui que eu esqueci de escrever sobre isso antes.
E agora algo sobre mulheres e maquiagem.

Essa revista chegou hoje. Essa é a típica mulher sueca aqui. Não só pelos olhos azuis e cabelo loiro, mas pela pouca maquiagem. E não existem nenhuma sensualização dela na foto. E apenas ela sendo ela. E confesso que depois de um tempo aqui, passando por essa desintoxicação quanto ao marketing brasileiro e objetificação feminina, eu já acho hoje em dia as propagandas que vejo do Brasil com algo bem vulgar.
E é isso. Guardar energia pra escrever mais na semana que vem. Que com certeza terá mais frio, mas já menos escuridão.
Já é possível ver como melhorou muito o tempo aqui. Peço perdão pelo sarcasmo.
UPDATE 2022-01-22: algumas fotos de como realmente fica tudo em volta durante o inverno, sem o romantismo das bolas de neves. Parte da sujeira é por causa da areia, mostrada numa das fotos, que serve pra dar um pouco de atrito no gelo e tentar ajudar a não escorregar tanto. Mas boa parte do que se vê são os "icepacks", pacotes de gelo. Neve que derreteu e congelou de novo. Tirei as fotos hoje durante minha ida ao restaurante próximo pra comprar o almoço.











Se ainda não leu os artigos anteriores:
Como bons brasileiros, nós não conhecemos neve. Talvez alguns dias frios durante o inverno, um pouco de gelo pra quem viaja pra São Joaquim em Santa Catarina, ou férias de inverno em Bariloche pros mais abastados. Então é uma visão romântica da neve e do inverno.
Inverno é duro aqui. Muito duro. Começa a ficar frio por volta de meados de setembro e só volta a melhorar em meados de abril. Mas em alguns anos isso só aconteceu em julho (e também teve anos em que março estava bom). Então vivemos com as janelas fechadas por 5 ou 6 meses por ano. Janelas com vidro duplo, pra isolar o ambiente. Dentro de casa vivemos em confortáveis 21°-25° C dependendo dos radiadores e da casa. Em geral perto de 21° C.
Não bastasse o frio, uma das piores coisas aqui na europa nórdica é a escuridão. A foto acima do sol pondo-se foi feita por volta das 3 horas da tarde. Nessa época do ano o sol nasce depois das 8 da manhã. Hoje, dia 15 de janeiro, o sol nasce às 8:30 e põe-se às 3:24 da tarde. O ápice a escuridão é dia 21 de dezembro, e depois disso vai aumentando as horas de sol. 1 minuto mais ou menos por dia (em certo momento é bem mais, mas não vou entrar nesse assunto).

Nos primeiros anos recebemos isso como novidade e até adoramos. Afinal é novidade. Mas conforme o tempo vai passando, e isso vira sua rotina, começa a afetar você. Em geral levando à depressão. E esse é um dos maiores motivos de uso de antidepressivos aqui, do qual também sou usuário: regular o corpo com os ciclos de pouco sol no inverno e muito sol no verão. É bem comum encontrar pessoas que passam pelo problema de insônia, que é um dos efeitos disso. Durante o inverno, o isolamento em casa também vira uma norma. E isso traz ainda o que é conhecido como S.A.D., Seasonal Affective Disorder, que é uma forma de depressão.
Esse ano a cervejaria BrewDog fez uma campanha de cerveja pra ajudar as pessoas que sofrem de S.A.D. de tão grave e comum que isso é na europa como um todo (talvez não tanto na parte sul como Grécia, Itália e Portugal). Os lucros arrecadados serão destinados ao tratamento dessa desordem e doenças mentais.

https://www.brewdog.com/uk/iamwhole
A primeira coisa que temos que fazer pra combater o S.A.D. é aumentar a dose de vitamina D, aquela que conseguimos pelo sol. Aqui é item obrigatório entre meados de setembro até meados de março ou até mesmo abril. Adultos e crianças. Mas mesmo não tendo S.A.D., os efeitos do pouco sol fazem-se sentir logo mesmo com a vitamina D extra: cabelos caindo e unhas quebrando. Mesmo os animais de estimação perdem bastante pelos durante o inverno, a ponto de eu achar que consegueria montar um gato a mais por mês com tanto pelo que o roomba coletava (roomba, o robôzinho que varre o chão).
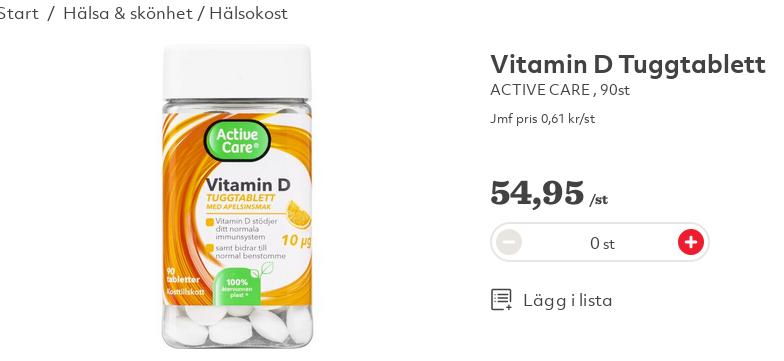
Além do pouco sol, insônia, cabelos caindo, unhas quebrando ainda existe um outro problema com o inverno que é a pele. A pele sofre e muito com o clima frio, que é muito seco. Então uma das coisas que temos de abandonar aqui até certo ponto é banho. É comum ouvir falar de gente que foi ao médico ver uma irritação na pele que estava ficando vermelha, meio esfolada, e o médico perguntar "está tomando banho todo dia?". A água aqui tem muito calcário, tanto que deixa umas manchas brancas por onde seca. Essa mesma água usada diariamente vai deixando a pele cada vez mais seca. Ao ponto de exigir usar cremes hidratantes.
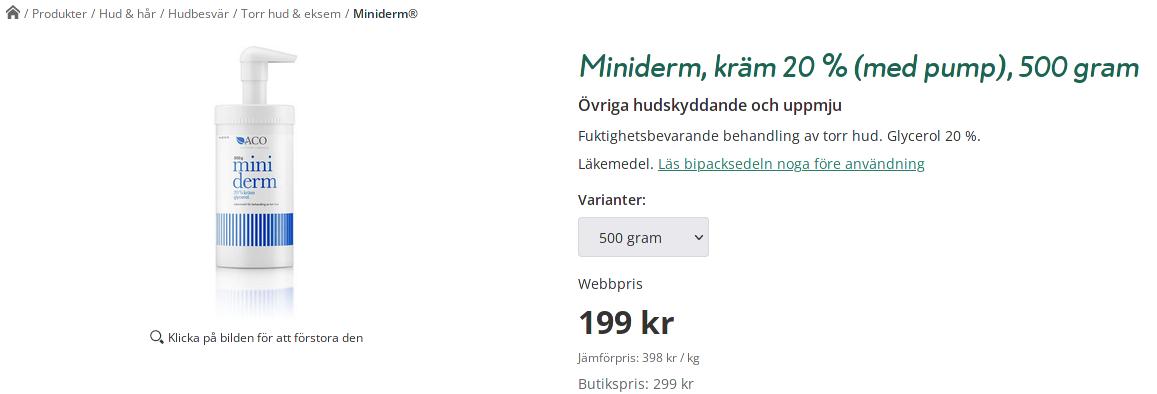
Eu costumo ou usar esse creme, que não tem cheiro e é bom pra quem é alérgico a quase tudo como eu, ou uso um Dove cream shower após tomar banho. E tem quem tome até dois banhos por dia e não tenha esses problemas de pele. Mas quem não cuida e insiste pode desenvolver o que é conhecido como "alergia ao inverno", que é o pior ponto onde pode-se chegar. Essa alergia é uma eczema da pele que fica irritada com qualquer coisa sintética. Então imagine como é terrível enfrentar de 5 a 6 meses de inverno sem poder usar uma jaqueta. E o uso de roupas de algodão, que é a única coisa possível de usar quando se está com a pele assim, têm o incoveniente de perder muito calor. Ao suar, a roupa de algodão fica molhada e não seca, tanto que não é recomendado seu uso.
Então parte do ritual de enfrentar um inverno tão longo é acostumar a usar roupas que permitam que sue, mas o suor fique isolado fora do corpo e ainda assim te mantenham aquecido. Por conta disso as roupas de inverno não cheiram lá muito bem pra narizes recém chegados. Claro que com o tempo a gente acostuma.
Só uma curiosidade sobre os próprios suecos. Como eu costumava ir trabalhar de bicicleta mesmo durante o inverno, claro que dividi vestiário com vários colegas e pude notar seus hábitos quanto ao banho. Existiam alguns que só se enxugavam o suor e colocavam a roupa de trabalho (porque aqui tem de usar uma roupa própria pra pedalar durante o inverno), mas a grande maioria tomava o "banho sueco" que é basicamente entrar no chuveiro e só passar um água rápida. Menos de 5 minutos. Sem sabão. Sim, deixar a pele oleosa. Isso ajuda a pele a sobreviver à rotina do inverno.

Eu comentei acima que dentro de casa as temperaturas são de 21 à 25°C. Recomendam então usar pouca ou nenhuma roupa dentro de casa pra justamente a pele respirar. Por isso é tão comum ver gente andando pelada nos apartamentos no centro da cidade. No começo você acha engraçado e fica um pouco envergonhado com isso, mas depois de um tempo você vira mais um dos pelados andando pela casa.
Mas e a parte legal, de esquiar, patinar no gelo, bonecos de neve, etc?

Claro que isso existe. E é bem divertido. Mas em geral só é possível um ou dois dias depois que nevou, ou em alguns parques enquanto a temperatura ficar abaixo de zero e não tiver muito sol, o que é comum durante o inverno. Nos locais de muita circulação a neve vira uma lama que suja tudo por onde se anda (e daí o hábito na Suécia de não se usar sapatos dentro de casa, nem as visitas).


Esquiar já é algo diferente. Eu nunca fiz, mas as estações de esqui ficam em sua maioria em locais onde a neve cai o ano inteiro. Então é mais ou menos ter vontade de ir lá fazer. Eu até hoje não fui, mas algum dia tento. Quero experimentar o snowboard.
A neve dá uma alegrada na escuridão nórdica, mas por outro lado cria o problema de que escorrega. E muito. O sol bate na neve, que reflete a luz e aumenta a troca de calor. A parte de cima da neve esquenta e derrete. Mas assim que o sol se vai, essa parte de cima congela novamente e vira gelo. Uma área gigantesca de gelo. E no escuro. Os carros e mesmo as bicicletas aqui usam pneus de inverno, que em geral têm cravos de metal pra segurar nesse gelo. Mas não os sapatos. Aliás até tem umas garras que podem adaptar nos sapatos pra andar no gelo, mas é complicado andar com aquilo por aí. Se for ao mercado por exemplo, na rua estará super seguro de escorregar no gelo mas ao entrar no mercado o piso liso vai fazer você escorregar. Então não é algo muito prático pra se usar durante todo o inverno. Talvez pra uma caminhada nos bosques. Então durante o inverno é comum as pessoas caírem e quebrarem braços, pernas, pulsos, etc. Imagine você ter caído num inverno e quebrado a perna? E imagine o medo de acontecer de novo. E ter 6 meses de inverno todo ano.
Em lugares mais urbanos como o centro da cidade é comum passar um tratorzinho nas calçadas limpando a neve e o gelo. O mesmo acontece nas ruas e vias de bicicletas. Claro que eles não limpam o tempo todo. Vez ou outra, numa tempestade forte de neve, fica tudo coberto de neve, que é onde fica o perigo de escorregar e cair. Outro perigo é a neve ou gelo acumulado nos telhados de prédios. Existe o risco de um pedaço grande cair na sua cabeça, assim como aqueles pingentes de gelo que ficam nas beiradas. A recomendação é não andar perto das paredes pra evitar isso. Mas todo ano morrem pessoas assim.

E a roupa de inverno? Todos os lugares onde frequentamos têm aquecimento, e por isso não usamos tanta roupa pra segurar o frio como no Brasil. Geralmente uma boa jaqueta basta. Só que essa jaqueta será seu melhor companheiro por 6 meses por ano. Bom... talvez nem tanto. Frio mesmo faz normalmente em janeiro e em fevereiro. Então digamos de 2 a 3 meses. Mas nos outros meses está frio, abaixo de 10°C. Enquanto uma boa jaqueta dá conta do recado, a maioria tem jaquetas de meia estação, que é também meu caso. São jaquetas que aguentam bem até uns -1 ou -2 °C. Abaixo disso, daí sim a jaqueta de inverno. E não dá pra lavar essa jaqueta a cada uso porque ainda mais no inverno não vai secar tão rápido e sair com jaqueta úmida por dentro não é lá uma boa ideia. Lembram que comentei do cheiro da roupa aqui? Pois é...

Aqui é comum ter muitas promoções boas de roupa de inverno no começo da primavera, por volta de março e abril. Foi quando comprei essa jaqueta da foto. Meu único arrependimento dessa jaqueta foi ter escolhido o branco. Agora ela está toda encardida e não tem jeito de tirar.
Quando cheguei do Brasil eu sentia muito frio em temperaturas de 5°C pra baixo. Eu usava uma camada a mais de roupa, a tal segunda pele ou camada básica. Essa é uma malha a mais de algodão ou sintética, que ao contrário da roupa pra exercício pode ser de algodão (desde que não sue muito nela). Depois de alguns anos morando aqui eu já não uso tanto até temperaturas até -5°C. Só a calça jeans já tá bom o suficiente. Mas isso também depende de quanto tempo estarei fora de casa. Se for pra como por exemplo andar até à praia, onde tirei a foto do início do artigo, com certeza uso sim. São uns bons 30 a 40 minutos de caminhada na neve até chegar lá. E a calça jeans só não segura o frio assim por tanto tempo. Pra ir pro trabalho de transporte público? Só a calça jeans mesmo.
Vendo essa perspectiva de como funciona a vida no inverno aqui, acho que fica claro o motivo do Linus Torvalds ter criado um kernel. É o que se tem pra fazer aqui durante o inverno. Eu tento passar o tempo fazendo pizzas, pães, e cerveja. Jogando PlayStation com os amigos e atualizando aqui o blog. Mas mesmo assim... o inverno é longo. Não acho que consigo criar um kernel, mas tenho feito muitas outras coisa. E dá pra entender o porquê do R. R. Martin usar a Suécia como referência em seus livro do game of thrones. Aqui a gente sempre sabe que o inverno está chegando...

Esse ano eu consegui montar uma retrospectiva logo no ínicio do ano.
Infelizmente foi um final de ano difícil pra mim com a morte do nosso gato de estimação bem no final do ano. Mas... a vida segue.
Eu tinha colocado uma meta de escrever semanalmente aqui no site. Não cheguei a alcançar a meta semanal mas definitivamente escrevi muito mais que nos anos anteriores. É sempre bom adicionar conteúdo.
Montando o vídeo de retrospectiva eu percebi o quão pouco tirei fotos ou fiz vídeos durante 2021. Não sei bem explicar o motivo, mas eu mesmo não lá muito de fazer selfies. E mesmo minha conta no Instagram é mais pra postar fotos em uso a câmera e dou um tratamento melhor que as imagens feitas pelo telefone.
Eu não coloquei uma meta pra participar de eventos com palestras, mas acabei até que fazendo bastante. Foram 4 palestras em 3 eventos:
E ainda fui parte da organização da PyCon Suécia. Não fiz nenhuma palestra lá, mas organizar o evento tomou bastante meu tempo e dedicação. Apareceu uma foto minha nos créditos finais, o que já é suficiente.
Não bastasse isso ainda fui organizador da hackathon global de outono na empresa. Em geral temos 2 por ano. E como é algo interno, eu não fiz muita propaganda fora da empresa. Mas foi mais uma coisa pra eu ter de trabalhar.
Eu acho que desse lado pessoal foi um ano muito bom. Espero conseguir fazer as mesmas coisas agora em 2022. Um pouco menos dessa vez porque quase tudo caiu junto entre meados de outubro e meados de novembro. Inclusive escrevi até um artigo pra REL (Revista Espírito Livre) que não foi publicado. Eu provavelmente vou publicar aqui em algum momento.
Agora vamos às estatísticas do site. Pra começar uma bela surpresa que só vejo quando faço essa restrospectiva:
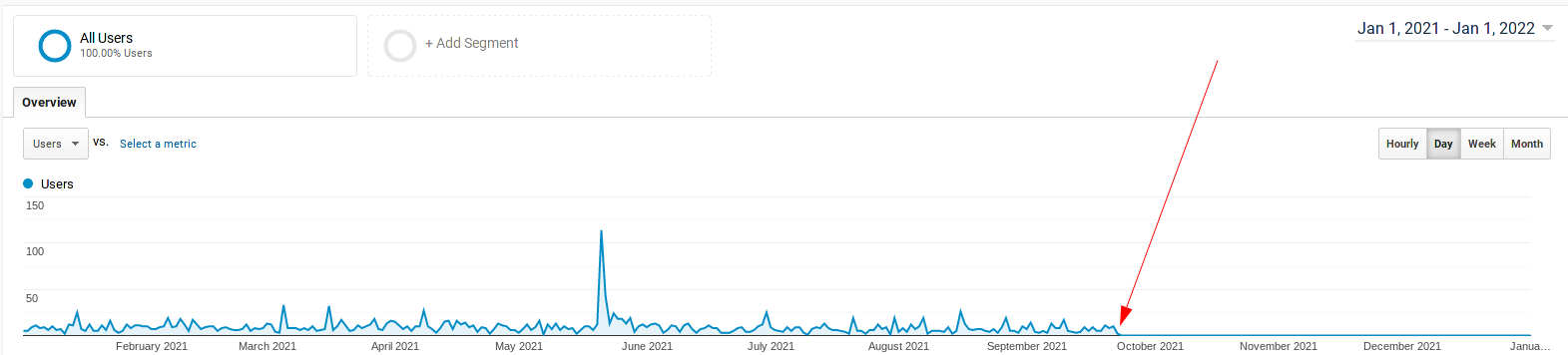
Eu fiz alguma besteira no site e o Google analytic parou de funcionar no início de outubro. E não tenho ideia do que possa ter sido. Mas quando acabar de escrever aqui eu já vou dar uma olhada. Sendo estatísticas, vamos chutar que é uma amostra grande o suficiente pra estimar o restante em termos de porcentagens.
Em relação aos navegadores que mais acessaram:
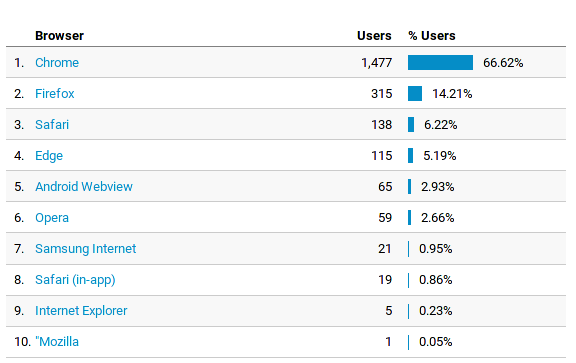
Chrome já na frente de longe com Firefox em segundo. Eu fiquei feliz de ver o Firefox ainda relevante por aqui.
E relação aos países que mais acessaram:
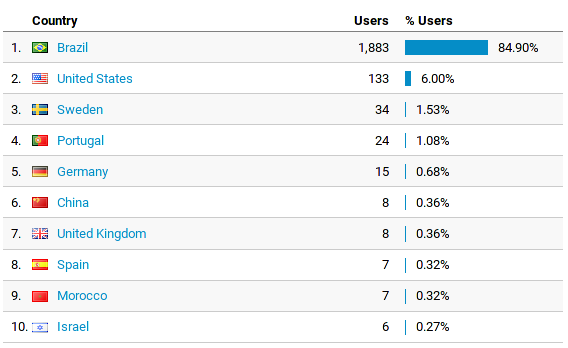
Posso assumir que os 1.34% de acesso a partir da Suécia seja eu mesmo.
Em relação aos sistemas operacionais de computadores (porque tem uma categoria separada para mobile):
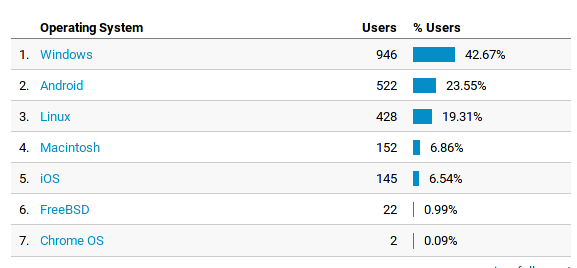
Novamente Windows em primeirão. Acho que pela primeira vez abaixo dos 50%, com android e Linux chegando à uns 42%, que já deixa equilibrado em Linux em Windows. Não me perguntem o porquê do Analytics mostrar separado.
E finalmente os sistemas operacionais mobile:
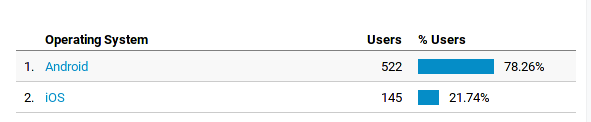
Quase mesma estatísticas mundial de 85% de equipamentos Android (telefones e tablets). Não muita surpresa aqui. E nada de Windows phone felizmente. Pelo menos na área mobile o povo aprendeu.
E esse foi o resumo do meu 2021. Vou tentar manter o ritmo de 1 artigo ou mais por semana esse ano também. Afinal escrever tem de ser uma rotina ou do contrário as redes sociais roubam todo o meu tempo livre.
Feliz 2022!

No artigo a era do Arch Linux eu esqueci de comentar, mas segue aqui a menção honrosa ao cartão pendrive da FSF que funcionou maravilhosamente pra instalar o Arch. Uma pena que eles não mencionem o suporte ao Arch, assim como não o fazem pro Debian, em usa página de Free distros. O Arch não instala nada pra você. Nem sugere. Mas já faz anos que a FSF adotou uma postura anti-liberdade, onde o bloqueio de uso de firmwares têm de ser forçado goela abaixo do usuário pra ser aprovada. Espero que isso mude em 2022 na FSF.
![]()
Já faz um certo tempo que venho acompanhando o Archlinux de perto. Já tinha uma VM rodando pra testes. Mas com a decisão da Steam de lançar o device de games steam deck baseado no Arch, eu realmente fiquei tentado a experimentar mais a fundo, como meu sistema principal no desktop.
Antes de mais nada vou deixar claro que como desktop eu não tenho somente um computador. Tenho um gabinete desktop mesmo, que já descrevi anos atrás no artigo goosfraba, e tenho também o laptop de trabalho. Eu geralmente passo mais tempo no laptop, que roda Ubuntu. O meu desktop estava também com Ubuntu, mas rodando o 21.10. E não tinha reclamações a respeito. Mas faz um tempo que desejo sair do mundo Debian/Ubuntu por vários motivos. De comunidade a questão de forma de participação.
Então aproveitando as férias que peguei nesse fim de ano, resolvi partir pra cima da instalação do Arch. Peço antecipadamente desculpas por ser muita coisa em imagens, mas eu fiz registros dos passos e dificuldades de instalação atráves de imagens em posts no Twitter pra justamente descrever aqui.
Como o computador já roda Ubuntu com LVM, não precisei fazer muita coisa além de criar mais partições que seriam próprias do Arch. Então simplesmente as criei assim:
lvcreate diskspace -L 10G -n archlinux-root
lvcreate diskspace -L 50G -n archlinux-usr
lvcreate diskspace -L 10G -n archlinux-var
E em teoria isso deveria ser o suficiente. Parti pra instalação e o primeiro problema foi encontrar o pendrive pra dar boot na instalação do Arch. Eu tinha criado o pendrive com o comando dd mas eu resolvi seguir à risca a instalação do Arch e refiz o pendrive novamente.

Não que tivesse mudado muita coisa. Eu precisei mexer nos parâmetros de boot da BIOS pra aceitar o pendrive. Depois de algumas configurações extras que mais foram mais próximas ao vodoo, eis que consegui o tão almejado boot.
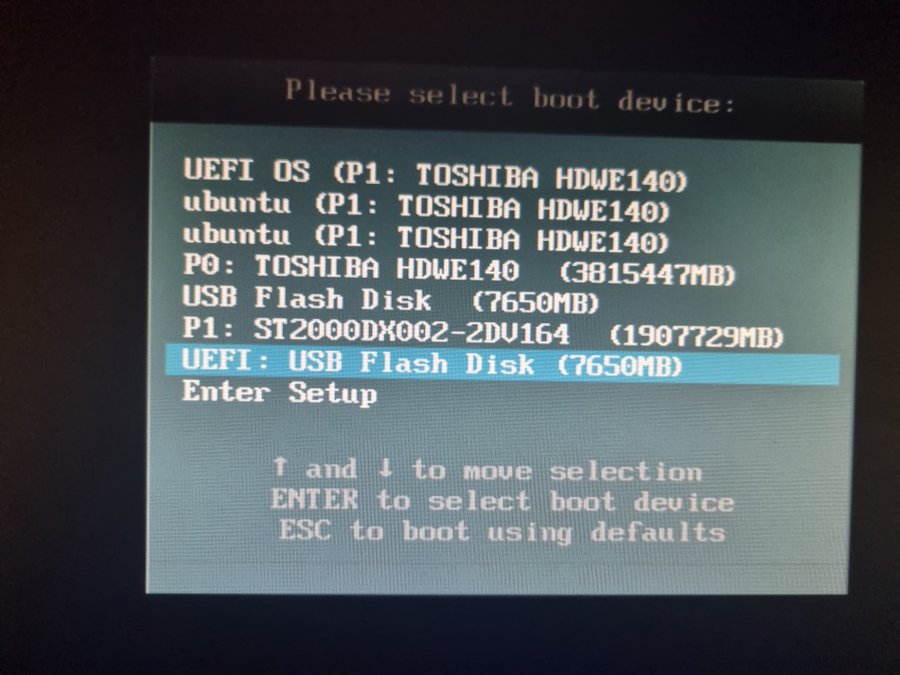
O boot do Arch foi um passeio no parque. Como ele não faz nada automático e você faz tudo manualmente bastou apenas formatar e montar as partições que eu já tinha criado pra seguir com a instalação.
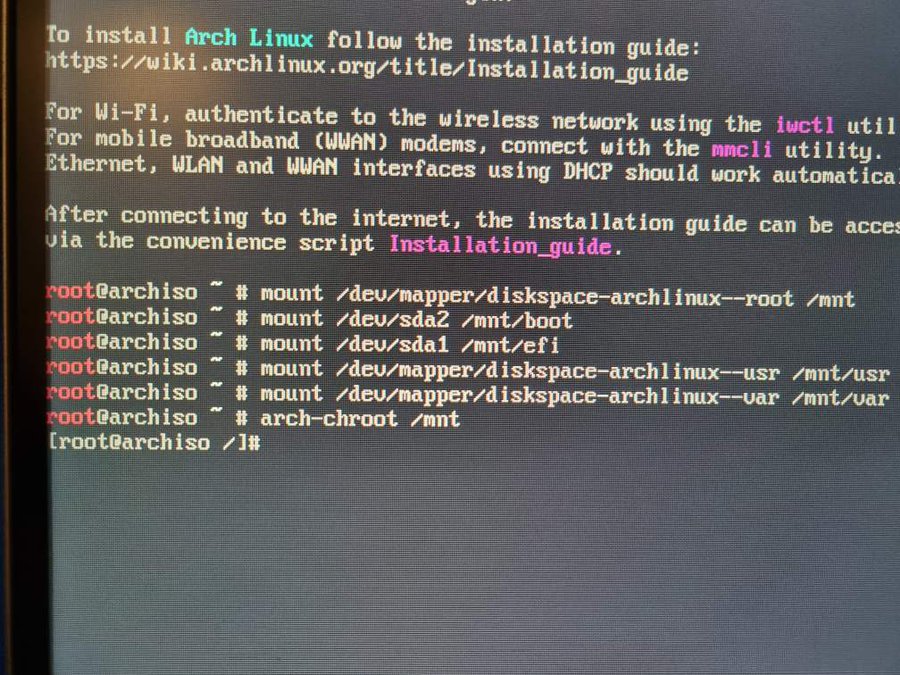
Nos passos de instalação do grub e meio que empaquei. Eu já tinha o grub instalado na partição UEFI e funcionando no Ubuntu. Seria o caso de apenas adicionar uma nova entrada no grub.cfg? E foi
menuentry 'Arch Linux' --class archlinux --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-16a93a2f-e4a6-4ab3-8eee-b33403509ed4' {
recordfail
load_video
gfxmode $linux_gfx_mode
insmod gzio
if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi
insmod part_gpt
insmod ext2
set root='hd0,gpt2'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,gpt2 --hint-efi=hd0,gpt2 --hint-baremetal=ahci0,gpt2 --hint='hd0,gpt2' bfc3c17e-d451-4c35-8c4a-f93b17436783
else
search --no-floppy --fs-uuid --set=root bfc3c17e-d451-4c35-8c4a-f93b17436783
fi
linux /vmlinuz-linux root=/dev/mapper/diskspace-archlinux--root init=/usr/lib/systemd/systemd ro net.ifnames=0 biosdevname=0 iommu=pt showopts noquiet nosplash verbose
initrd /initramfs-linux.img
}Com isso eu consegui deixar a opção de boot do Arch disponível. Existe aí um pequeno problema, o tal elefante na sala: o que acontece quando o Ubuntu atualizar. Eventualmente eu devo dar boot no Ubuntu e rodar algum upgrade de kernel. Ao rodar o mkinitram, com certeza vai sobreescrever essa entrada. Ainda não resolvi esse problema, mas por enquanto sigo usando somente Arch.
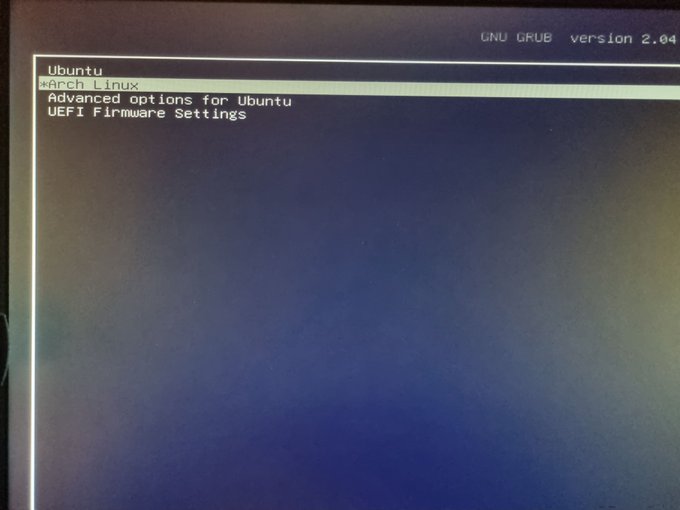
Então a coisa foi mesmo fácil e bastou apenas apertar o <Enter>...
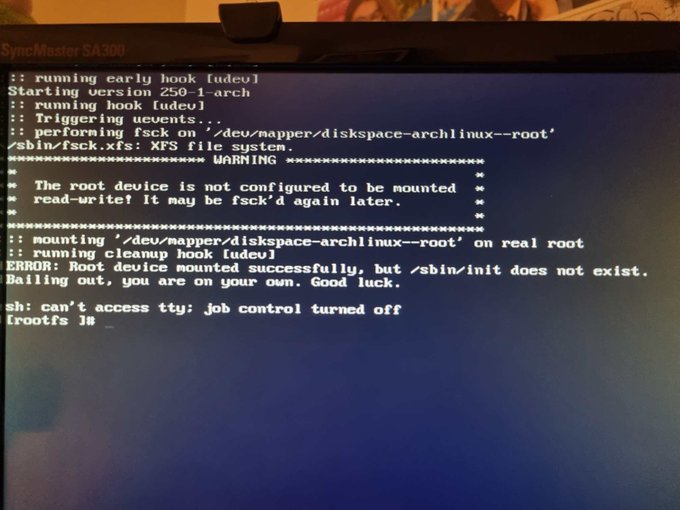
O que deu errado? E aqui eu comecei a entender um pouco mais do Arch além da superfície. E essa era meu objetivo desde o início. Pra entender o problema é preciso olhar como são os diretórios dentro do Arch primeiro.
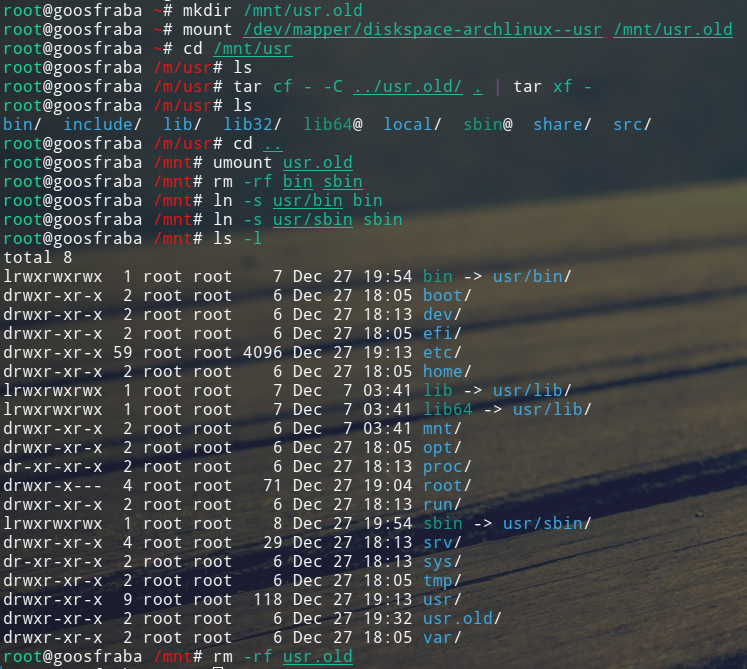
root@goosfraba /u/bin# ls -l /
total 28
lrwxrwxrwx 1 root root 7 Dec 7 03:41 bin -> usr/bin
drwxr-xr-x 5 root root 4096 Dec 27 21:51 boot
drwxr-xr-x 23 root root 4600 Dec 29 00:12 dev
drwxr-xr-x 3 root root 4096 Jan 1 1970 efi
drwxr-xr-x 90 root root 8192 Dec 29 13:48 etc
drwxr-xr-x 35 root root 4096 Jun 9 2020 home
lrwxrwxrwx 1 root root 7 Dec 7 03:41 lib -> usr/lib
lrwxrwxrwx 1 root root 7 Dec 7 03:41 lib64 -> usr/lib
drwxr-xr-x 2 root root 6 Dec 7 03:41 mnt
drwxr-xr-x 11 root root 154 Dec 29 13:48 opt
dr-xr-xr-x 437 root root 0 Dec 27 21:59 proc
drwxr-x--- 14 root root 239 Dec 29 13:27 root
drwxr-xr-x 26 root root 740 Dec 29 00:45 run
lrwxrwxrwx 1 root root 7 Dec 7 03:41 sbin -> usr/bin
drwxr-xr-x 4 root root 29 Dec 27 21:17 srv
dr-xr-xr-x 13 root root 0 Dec 27 21:59 sys
drwxrwxrwt 24 root root 4096 Dec 29 13:48 tmp
drwxr-xr-x 23 root root 332 Jun 19 2018 ubuntu
drwxr-xr-x 9 root root 118 Dec 29 13:48 usr
drwxr-xr-x 14 root root 201 Dec 29 12:58 var
O Arch não tem /bin, /sbin, /lib e /lib64. Ele joga todos os executáveis em /usr/bin e todas as libs em /usr/lib. Isso talvez facilite algum tipo de manutenção, mas quebra o princípio de que pra dar boot todo o necessário deveria estar em /bin pra executáveis de usuário e /sbin pra executáveis de root. Assim como a libc em /lib. O problema foi que eu tinha criado uma partição /dev/devicemapper/diskspace-arch--usr e montado no /usr, que não é passada no boot, que pede somente a partição root.
Então tive de replanejar minha instalação aumentando a partição raiz e removendo a partição que abrigava o /usr.
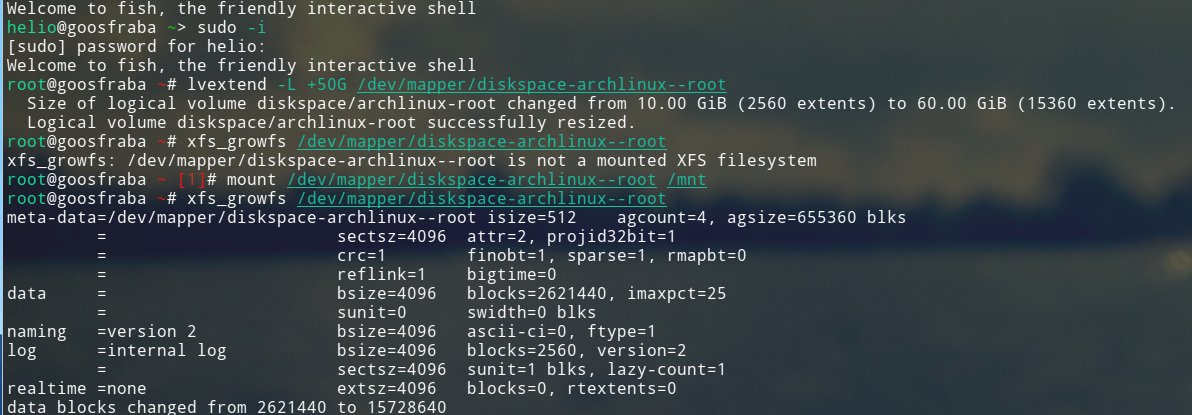
E finalmente copiar os dados do que era /usr.
E finalmente remover a partição criada pra abrigar originalmente o /usr.

Com isso eu pude finalmente dar boot no Arch e subir o KDE plasma.
Mas foi só isso. Não consegui mexer em mais nada. O que deu errado? Primeiramente foi a escolha de KDE que fiz durante a etapa do pacstrap. Eu escolhi o plasma-desktop e o mesmo não vem completo, o certo era plasma-meta. Não tinha um shell pra eu abrir como o gnome-terminal nem konsole. E como habilitei o sddm, então não conseguia voltar pro console virtual usando <ctrl>+<alt>+<F1>. Fiquei empacado. E precisei novamente dar boot pelo pendrive pra corrigir isso.
E consegui subir meu ambiente da mesma forma que antes. Apenas re-criei meu usuário com mesmo UID e GID e montei a mesma partição /home que era do Ubuntu. Transparentemente.
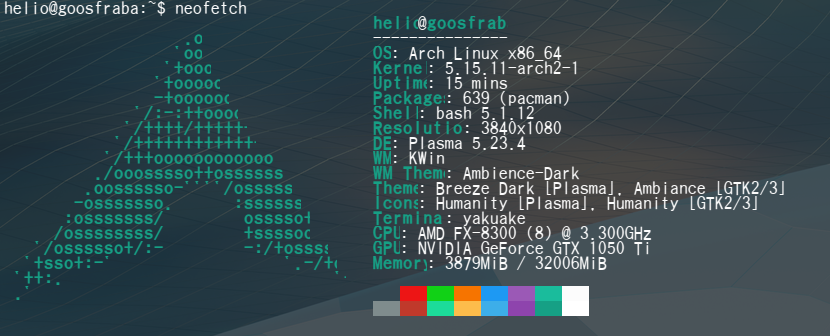
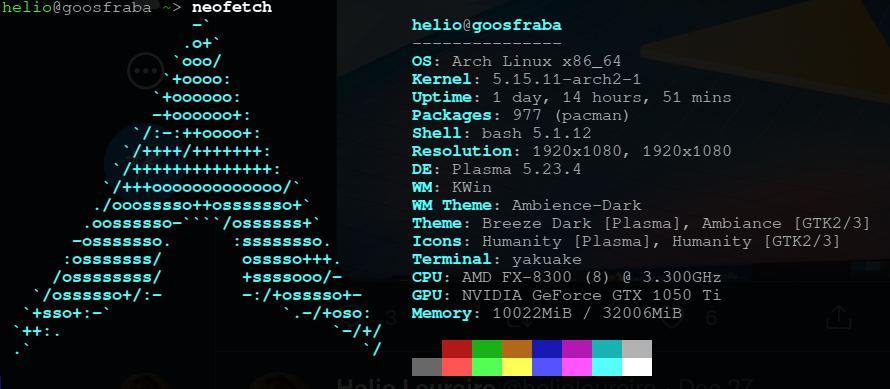
É nítida a diferença do primeiro screenshot do neofetch pro segundo, em como as fontes melhoraram. Aos poucos vou instalando e habilitando aquilo que preciso no Arch.
Eu de cara já sai com alguns extras funcionando sem mexer, como o Google Chrome, que aparece na imagem do desktop. Como estava na partição /opt, eu simplesmente montei e re-usei. Instalei o programa yay pra baixar pacotes faltando como steam e spotify. Ambos já instalados. E aos poucos vou arrumando a casa.
Um dos problemas que encontrei foi que minha partição de jogos da steam não aparecia disponível. Mas estava lá no comando lvs:
root@goosfraba /u/bin# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
archlinux-root diskspace -wi-ao---- 60.00g
archlinux-var diskspace -wi-ao---- 10.00g
debian diskspace -wi-a----- 10.00g
docker diskspace -wi-ao---- 30.00g
home diskspace -wi-ao---- 500.00g
linux-arch diskspace -wi-a----- 20.00g
opt diskspace -wi-ao---- 4.00g
root diskspace -wi-ao---- 10.00g
steam diskspace rwi-aor--- 750.00g 100.00
swap diskspace -wi-a----- 15.00g
tmp diskspace -wi-ao---- 5.00g
usr diskspace -wi-ao---- 95.00g
usrlocal diskspace -wi-ao---- 600.00g
var diskspace -wi-a----- 50.00g
O problema era que precisava ativar a partição, que faz mirroring entre os dois HDs que tenho. Bastou fazer o comando:
lvchange -a y /dev/diskspace/steamE meu steam passou a funcionar de novo.
E como eu já deixei o docker em um partição só sua, bastou montar pra ter novamente os containers que uso disponíveis no Arch.
root@goosfraba /u/bin# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
debian 11.0 6c97952ad9c0 6 days ago 626MB
theiaide/theia-full latest de7823cee314 2 months ago 11.5GB
debian <none> a178460bae57 3 months ago 124MB
theiaide/theia-full <none> 9c178198e255 3 months ago 8.86GB
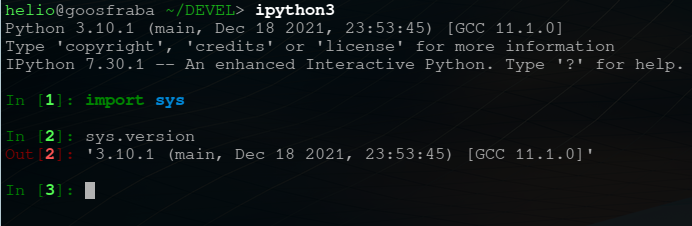
No arch já sai com o python 3.10 funcionando.
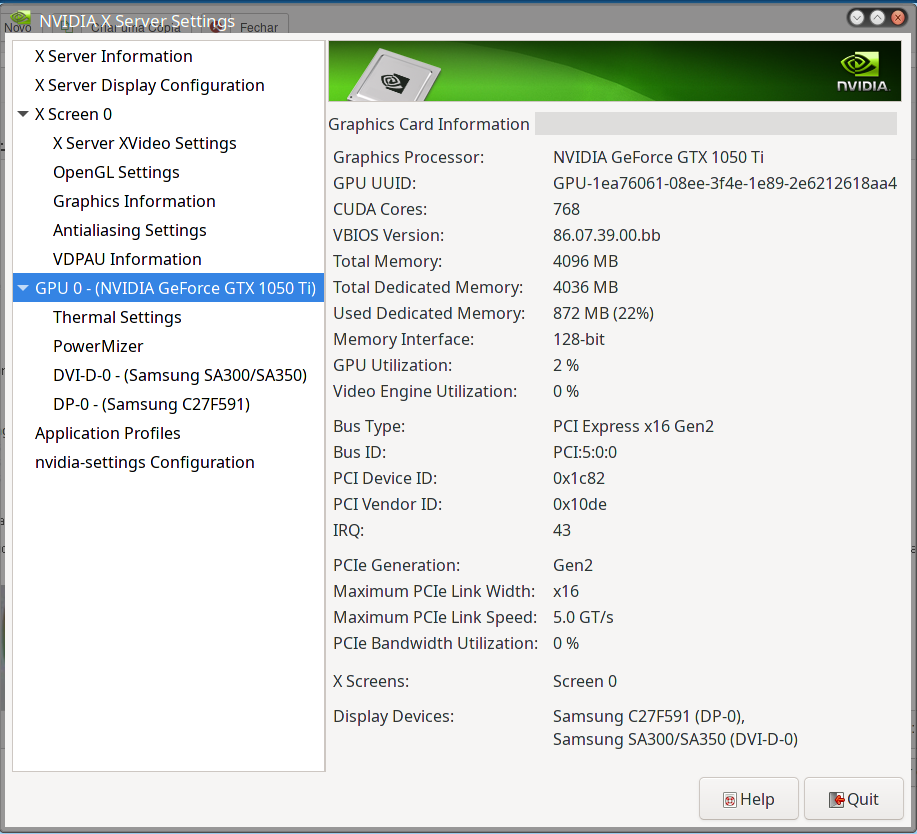
E pra minha surpresa a instalação do suporte à NVIDIA foi fácil e tranquilo. Mais que no Ubuntu.
Como foi possível ver é bem divertido o uso do Arch e resgata um pouco daquele espírito hacker de fuçar no seu sistema operacional pra ter tudo funcionando. Eu estou gostando da experiência por equanto. Acho que agora já posso fazer como o Kretcheu, se bem que Debian eu já não uso faz alguns anos.

Caso não tenha lido os artigos anteriores:
Como bom brasileiros, nascidos na burocracia, estamos acostumados a ter vários números pra diferentes finalidades. CPF pra coisas relacionadas com imposto, RG pra identidade, certificado de reservista, cartão eleitoral, etc. E cada um com um número qualquer que temos em geral de memorizar.
Na Suécia sua vida toda é ligada ao que é chamado de "personnummer", ou "personal number" em inglês, ou número pessoal na boa e velha língua tupiniquim. Ele é composto de <ano em que nasceu><mês em que nasceu><dia em que nasceu>-<4 dígitos aleatórios>. Algo como YYYYMMDD-ABCD. Simples assim.
O ano de nascimento pode ser usado tanto o formato YY como YYYY. Nos documentos aparecem no formato YY, mas quando recebe seu número, via carta, ele vem no formato do ano completo com 4 dígitos, YYYY.
E com esse número baseado no seu aniversário você faz tudo: vota, tira carteira de motorista, faz o imposto de renda, vai ao médico, contrata serviços pelo telefone, etc.
De posse do número, você pode tirar a sua carteira de identidade de estrangeiro residente.

A moçoila bonita da foto nasceu em 12 de junho de 1970 de acordo com seu "personnummer". Existe um número gigantesco no topo à esquerda, o "kortnummer", que é "número do cartão", mas esse não é usado pra nada.
O mesmo formato aplica-se pra identidade de quem é cidadão sueco.

A diferença dessas identidades é que a primeira é emitida pelo skatteverket, órgão responsável por cobrar os impostos e também de registro civil, e o segundo, pela polícia. O cartão emitido pelo skatteverket tem mais a aparência e formato de um cartão de crédito comum, enquanto que a carteira emitida pela polícia é um papel plastificado num plástico rígido.
Existe também a carteira de motorista, emitida pelo trafiksverket, órgão responsável controle e regulamentação de tráfego.

A carteria de motorista, körkort em sueco (kör - dirigir, kort - cartão), tem a data de nascimento no campo 3 e o número pessoal no campo 5, que mostra a mesma data em formato invertido e mais os 4 últimos dígitos aleatórios/verificadores (parece que os 2 últimos são os verificadores). Aqui dentro da Suécia a carteira de motorista serve como identidade. Tanto que só ando com ela na carteira.
Nas viagens que fiz aqui pela europa, a maioria dos aeroportos aceitou só a carteira de motorista pra embarcar. Exceção foi o aeroporto internacional de Lisboa, que exigiu meu passaporte.
O ponto interessante aqui é que seu nome não diz muita coisa. Quem o define é seu número pessoal. Então qualquer pessoa pode ir ao skatteverket, onde está o registro civil, e mudar seu nome quando quiser, quantas vezes quiser e pro que quiser. Parece simples, não? E realmente é.
Claro que alguns podem argumentar que um sistema simples desse pode levar a um maior monitoramento de sua vida e atividades privadas. Eu diria que sim. Mas acho que benefício de ter um só número significativo pra tudo na sua vida compensa isso. A menos que você seja um despachante.
Filho aborrecente é... aborrecente. E infelizmente tenho de tempos em tempos de usar a artimanha de bloquear o YouTube pra conseguir sua atenção e fazer as suas tarefas.
Hoje eu estava revendo o script que criei em bloqueando Youtube no OpenWRT, criado em 2018. Dei uma melhorada no código e fiz o cáculo do horário de uma forma melhor.
Precisei carregar os módulos "bc" e "iptables-mod-filter" no openwrt pra funcionar como desejado.
#! /bin/sh
# save it into /usr/lib/scripts/firewall.sh
# and add into scheduled tasks as
# */5 * * * * /usr/lib/scripts/firewall.sh timetable
NOW=$(date +"%H:%M")
TIMETABLE="07:55,10:00 12:00,18:00 20:30,22:00"
status_file=/tmp/firewall_status
blocked_pattern="youtubei.googleapis.com"
blocked_pattern="$blocked_pattern googlevideo.com"
blocked_pattern="$blocked_pattern ytimg-edge-static.l.google.com"
blocked_pattern="$blocked_pattern i.ytimg.com"
blocked_pattern="$blocked_pattern youtube-ui.l.google.com"
blocked_pattern="$blocked_pattern www.youtube.com"
blocked_pattern="$blocked_pattern googleapis.l.google.com"
blocked_pattern="$blocked_pattern youtubei.googleapis.com"
blocked_pattern="$blocked_pattern video-stats.l.google.com"
blocked_pattern="$blocked_pattern ytimg-edge-static.l.google.com"
enable_firewall() {
echo "Enabling firewall"
for chain in INPUT FORWARD OUTPUT
do
count=1
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -I $chain $count -p $proto -m string --algo bm --string "$blocked" -j DROP
count=`expr $count + 1`
done
done
echo iptables -I $chain $count -p udp --sport 443 -j DROP
iptables -I $chain $count -p udp --sport 443 -j DROP
count=`expr $count + 1`
echo iptables -I $chain $count -p udp --dport 443 -j DROP
iptables -I $chain $count -p udp --dport 443 -j DROP
count=`expr $count + 1`
done
echo -n "enabled" > $status_file
}
disable_firewall() {
echo "Disabling firewall"
for chain in INPUT FORWARD OUTPUT
do
for proto in tcp udp
do
for blocked in $blocked_pattern
do
echo iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
iptables -D $chain -p $proto -m string --algo bm --string "$blocked" -j DROP
done
done
echo iptables -D $chain -p udp --sport 443 -j DROP
iptables -D $chain -p udp --sport 443 -j DROP
echo iptables -D $chain -p udp --dport 443 -j DROP
iptables -D $chain -p udp --dport 443 -j DROP
done
echo -n "disabled" > $status_file
}
_get_time_as_integer() {
time=$1
hour=$(echo $time | cut -d: -f 1)
minute=$(echo $time | cut -d: -f 2)
echo "$hour * 100 + $minute" | bc
}
_get_start_time(){
# expected format: 07:00,10:00
time_str=$1
time_start=$(echo $time_str | cut -d, -f 1)
_get_time_as_integer $time_start
}
_get_stop_time() {
#expected format: 07:00,10:00
time_str=$1
time_stop=$(echo $time_str | cut -d, -f 2)
_get_time_as_integer $time_stop
}
get_timetable() {
do_activate=0
for value in $TIMETABLE
do
start=$(_get_start_time $value)
stop=$(_get_stop_time $value)
cur_time=$(_get_time_as_integer $NOW)
if [ $start -lt $cur_time ]; then
if [ $cur_time -lt $stop ]; then
do_activate=1
fi
fi
done
cur_status=$(cat $status_file)
if [ $do_activate ]; then
if [ "$cur_status" = "enabled" ]; then
echo "firewall already activated"
else
echo "activating firewall"
enable_firewall
fi
else
if [ "$cur_status" = "enabled" ]; then
echo "deactivating firewall"
disable_firewall
else
echo "firewall already deactivated"
fi
fi
}
case $1 in
start) enable_firewall
exit 0;;
stop) disable_firewall
exit 0;;
timetable) get_timetable
exit 0;;
status) echo "firewall rules are $(cat $status_file)";;
*) echo "Use: $0 [start|stop|timetable|status]"
exit 0
esac
exit 0
Agora os horário de bloqueio ficam na variável TIMETABLE e no format "<horário início HH:MM>,<horário fim HH:MM>". O firewall permite um direto "start" e "stop" pra ativar, assim como um "status". Crie alguma funções com o "_" no início, pra seguir um pouco o padrão do python de funções internas/privadas.
Seu funcionamento agora ficou muito bom e fácil, pra desespero dos aborrecentes.
root@OpenWrt:/usr/lib/scripts# ls
firewall.sh
root@OpenWrt:/usr/lib/scripts# ./firewall.sh status
firewall rules are disabled
root@OpenWrt:/usr/lib/scripts# ./firewall.sh timetable
activating firewall
Enabling firewall
iptables -I INPUT 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I INPUT 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I INPUT 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I INPUT 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I INPUT 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I INPUT 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I INPUT 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I INPUT 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I INPUT 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I INPUT 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I INPUT 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I INPUT 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I INPUT 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I INPUT 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I INPUT 21 -p udp --sport 443 -j DROP
iptables -I INPUT 22 -p udp --dport 443 -j DROP
iptables -I FORWARD 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I FORWARD 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I FORWARD 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I FORWARD 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I FORWARD 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I FORWARD 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I FORWARD 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I FORWARD 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I FORWARD 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I FORWARD 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I FORWARD 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I FORWARD 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I FORWARD 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I FORWARD 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I FORWARD 21 -p udp --sport 443 -j DROP
iptables -I FORWARD 22 -p udp --dport 443 -j DROP
iptables -I OUTPUT 1 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 2 -p tcp -m string --algo bm --string googlevideo.com -j DROP
iptables -I OUTPUT 3 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 4 -p tcp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I OUTPUT 5 -p tcp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I OUTPUT 6 -p tcp -m string --algo bm --string www.youtube.com -j DROP
iptables -I OUTPUT 7 -p tcp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I OUTPUT 8 -p tcp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 9 -p tcp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I OUTPUT 10 -p tcp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 11 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 12 -p udp -m string --algo bm --string googlevideo.com -j DROP
iptables -I OUTPUT 13 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 14 -p udp -m string --algo bm --string i.ytimg.com -j DROP
iptables -I OUTPUT 15 -p udp -m string --algo bm --string youtube-ui.l.google.com -j DROP
iptables -I OUTPUT 16 -p udp -m string --algo bm --string www.youtube.com -j DROP
iptables -I OUTPUT 17 -p udp -m string --algo bm --string googleapis.l.google.com -j DROP
iptables -I OUTPUT 18 -p udp -m string --algo bm --string youtubei.googleapis.com -j DROP
iptables -I OUTPUT 19 -p udp -m string --algo bm --string video-stats.l.google.com -j DROP
iptables -I OUTPUT 20 -p udp -m string --algo bm --string ytimg-edge-static.l.google.com -j DROP
iptables -I OUTPUT 21 -p udp --sport 443 -j DROP
iptables -I OUTPUT 22 -p udp --dport 443 -j DROP
root@OpenWrt:/usr/lib/scripts# ./firewall.sh timetable
firewall already activated
root@OpenWrt:/usr/lib/scripts# ./firewall.sh status
firewall rules are enabled
root@OpenWrt:/usr/lib/scripts# date
Sun Dec 19 13:51:32 CET 2021
Boa diversão. Ou não caso seja o aborrescente lendo esse artigo pra descobrir o porquê seu YouTube parou de funcionar.
No roadmap: incluir TikTok e Instagram.
UPDATE: eu por fim criei um repositório no github pra ficar mais fácil a manutenção: https://github.com/helioloureiro/opewrt-youtube-blocker
Não é sempre que preciso fazer dessas coisas, mas recentemente precisei mexer num disco de livecd do Ubuntu que estava em formato iso pra alterar algumas coisa.
Então aqui fica receita de como fazer isso (dependendo do que deseja fazer, claro).
Primeiro eu tenho dois diretórios que uso pra montagem dos filesystems. Os /cdrom e /mnt. Como já uso desse forma faz anos, não sei se são criados por padrão no Ubuntu ou outro sistemas. Então se for copiar o que descrevo aqui, tenha certeza que esses diretórios existem. Outro ponto importante é que rodo todos os comandos como root.
Então o começo de tudo é montar a imagem do Ubuntu no diretório desejado.
root@goosfraba /# mount -t iso9660 -o loop ubuntu-20.04.03-desktop-amd64.iso /cdrom
Esse conteúdo precisa ser copiado pra um diretório temporário.
root@goosfraba /# mkdir /tmp/temp-cdrom
root@goosfraba /# cd /tmp/temp-cdrom
root@goosfraba /t/temp-cdrom# tar cvf - -C /cdrom . | tar xvf -
Existe o arquivo casper/filesystem.squashfs que é o filesystem do livecd. Você pode montar esse disco com o seguinte comando (e aqui entra o /mnt que comentei antes):
root@goosfraba /t/temp-cdrom# mount -t squashfs -o loop /tmp/temp-cdrom/casper/filesystem.squashfs /mnt
mas esse disco é apenas read-only. Pra modificar é preciso usar a ferramenta unsquashfs que faz parte do pacote squashfs-tools.
root@goosfraba /t/temp-cdrom# mkdir /tmp/squashfs
root@goosfraba /t/temp-cdrom# cd /tmp/squashfs
root@goosfraba /t/squashfs# unsquashfs /tmp/temp-cdrom/casper/filesystem.squashfs
Parallel unsquashfs: Using 8 processors
185020 inodes (205968 blocks) to write
[=================================================================================================================================================================/] 205968/205968 100%
created 155722 files
created 19319 directories
created 29184 symlinks
created 8 devices
created 0 fifos
root@goosfraba /t/squashfs# ls squashfs-root/
bin@ boot/ dev/ etc/ home/ lib@ lib32@ lib64@ libx32@ media/ mnt/ opt/ proc/ root/ run/ sbin@ snap/ srv/ sys/ tmp/ usr/ var/
Daí sim fazer as modificações desejadas.
Ao terminar é preciso gerar a imagem no formato squashfs novamente, agora usando o mksquashfs. Prepare-se pra ir fazer um café ou assistir um filme pois o processo demora bastante nesse passo.
root@goosfraba /t/squashfs# mksquashfs squashfs-root /tmp/temp-cdrom/casper/filesystem.squashfs -b 1024k -comp xz -Xbcj x86 -e boot
Parallel mksquashfs: Using 8 processors
Creating 4.0 filesystem on /tmp/temp-cdrom/casper/filesystem.squashfs, block size 1048576. [=================================================================================================================================================================/] 149629/149629 100%
Exportable Squashfs 4.0 filesystem, xz compressed, data block size 1048576
compressed data, compressed metadata, compressed fragments,
compressed xattrs, compressed ids
duplicates are removed
Filesystem size 1695376.64 Kbytes (1655.64 Mbytes)
32.81% of uncompressed filesystem size (5167137.40 Kbytes)
Inode table size 1550743 bytes (1514.40 Kbytes)
20.75% of uncompressed inode table size (7473067 bytes)
Directory table size 1819524 bytes (1776.88 Kbytes)
36.53% of uncompressed directory table size (4981005 bytes)
Xattr table size 98 bytes (0.10 Kbytes)
81.67% of uncompressed xattr table size (120 bytes)
Number of duplicate files found 18577
Number of inodes 204220
Number of files 155715
Number of fragments 2275
Number of symbolic links 29180
Number of device nodes 8
Number of fifo nodes 0
Number of socket nodes 0
Number of directories 19317
Number of ids (unique uids + gids) 37
Number of uids 15
root (0)
ntp (126)
dnsmasq (112)
saned (119)
speech-dispatcher (114)
systemd-timesync (100)
_apt (105)
rtkit (118)
messagebus (106)
man (6)
postfix (125)
whoopsie (109)
sshd (121)
sddm (122)
syslog (104)
Number of gids 28
root (0)
dip (30)
shadow (42)
lpadmin (113)
rtkit (126)
mysql (131)
nogroup (65534)
lp (7)
audio (29)
systemd-timesync (102)
utmp (43)
tty (5)
geoclue (105)
_ssh (118)
input (106)
mail (8)
staff (50)
avahi (120)
man (12)
pulse-access (125)
whoopsie (116)
munin (130)
saned (127)
pulse (124)
uuidd (111)
systemd-journal (101)
adm (4)
messagebus (110)
E o último passo é gerar o disco bootável. Pra isso eu usei o genisoimage:
root@goosfraba /tmp# genisoimage -b isolinux/isolinux.bin -c isolinux/boot.cat -no-emul-boot -boot-load-size 4 -boot-info-table -r -J -o /tmp/ubuntu-20.04.03-modificado-desktop-amd64.iso /tmp/temp-cdrom
Com isso a image iso ubuntu-20.04.03-modificado-desktop-amd64.iso é gerada.
Page 13 of 40
