E foi-se a Python Brasil 9, em Brasília. Evento muito legal e que reuniu a comunidade de desenvolvedores python tupiniquins.
Eu participei falando um pouco do meu trabalho em telecomunicações. Minha apresentação foi essa abaixo, "python in telecommunications", que contou um pouco da história do nono dígito. Claro que não dá pra entender muito, uma vez que tem mais imagens que informação, mas mostra bem como python ajudou a ter uma solução mais robusta e limpa em relação a anterior, que rodava em shell script.

Quais são a 4 liberdades do software livre, segundo o próprio Stallman?
As mesmas foram copiadas da página do projeto GNU, em "a definição do software livre". Ainda no mesmo é possível ler:
"Um programa é software livre se os usuários possuem todas essas liberdades. Portanto, você deve ser livre para redistribuir cópias, modificadas ou não, gratuitamente ou cobrando uma taxa pela distribuição, a qualquer um, em qualquer lugar. Ser livre para fazer tudo isso significa (entre outras coisas) que você não deve ter que pedir ou pagar pela permissão para fazê-lo."
Apesar da relutância de algumas pessoas, software livre não significa exatamente software gratuito. Quando alguém adota um licença livre, permite entre outras coisas que seu software seja vendido e outra pessoa ganhe com isso.
Sempre é fácil exaltar os benefícios do software livre, como compartilhamento e conhecimento. De ter uma comunidade em volta da mesma. Mas quando o assunto chega no bolso, na parte financeira, parece que dói na vaidade de algumas pessoas aceitar isso.
Observando outro dado importante sobre software livre, mais precisamente o kernel Linux (fonte: arstechnica):

Das contribuições ao kernel entre 2012 e setembro de 2013,somando os sem qualquer vínculo com os desconhecidos, os consultores e o acadêmicos, tem-se 19.5% de código gerado por eles contra 52,5% gerado por empresas, isso olhando apenas essa lista e não todas as contribuições. Ou seja, empresas que têm uma visão de negócios investem fortemente em software livre e são no momento a maioria do commits de código no kernel Linux.
O que estou tentando mostra aqui é que existe um interesse financeiro pra tal investimento das empresas. Existe um modelo de negócios com software livre, apesar de negado com todas as forças por muitas pessoas.
Quando se fala em software livre, todos lembram de usar um licença de acordo, seja GPL2, GPL3, BSD, Mozilla, Artistic ou qualquer outra livre, mas nunca pensa num ponto importante: como ganhar dinheiro com esse software? E isso não deveria ser combatido, mas fomentado, pois como apresentei no início, em momento algum Richard Stallman fala para não se fazer um modelo de negócios com software livre e que lucrar com isso seja errado.
Eu poderia então pegar uma distro como Debian, colocar numa embalagem bonita, adicionar manuais impressos, criar caixas com um logo novo, chamar de HeliOSTM, e vender ao preço de R$ 500,00 a caixa. Eu só precisaria incluir o código fonte disponível, até no site e separado das mídias, e incluir no manual dizendo que o sistema é baseado em Debian. Claro que isso por si só não bastaria. Seria preciso verificar quem seria meu mercado consumidor e iniciar uma campanha de marketing direcionada para comprovar como o HeliOSTM é um dos melhor sistemas para se usar num computador. E em nenhum momento eu estaria indo contra os 4 princípios do software livre. E nem precisaria realmente fazer o software: poderia continuar copiando do Debian.
Isso é apenas um exemplo pra ilustrar como é possível fazer negócios com software livre, gostando os desenvolvedores e comunidade ou não. E sempre é preciso pensar nisso: em qual parte da cadeia gostaria de estar? Em quem faz o negócio com o software livre, ou quem gera software pra outros comercializarem. O software livre permite que todos estejam do outro lado, que sejam seus próprios patrões. Mas pra isso é preciso estar preparado e não ter uma visão ingênua do software livre, de comunidade, mas um foco em como ter sua vida baseada nele.
Tentarei manter um ritmo de posts sobre o assunto e descrever como fazer o primeiro milhão de software livre (para quem ainda não o fez).

Eu me sinto bastante solidário com as pessoas que investiram no TelexFree e acho muito injusto que saiam com tal prejuízo financeiro. Como fizeram um investimento em tecnologia sem o conhecimento necessário sobre a mesma, ou até sobre o retorno do investimento, acho que vale a pena sugerir alguns negócios melhores que TelexFree.
Com certeza que são tecnologias que abrirão muitas portas para todo esse pessoal esquecido do norte do país, principalmente do estado do Acre.
Se não investiu em TelexFree e mesmo assim quiser experimentar os serviços abaixo, garanto que não se decepcionará. São todos GRÁTIS! Totalmente grátis! Fácil assim. Apenas criar uma conta e usar. Não há investimento melhor.
Depois não digam que não ajudei.
![]()


Recentemente participei de um opencast do Ivan, Ubunterobr, sobre Debian.
O objetivo era explicar um pouco sobre o Debian, sua história, suas versões e, principalmente, como experimentar. E também um pouco sobre comunidade, que é a parte mais importante pra nós usuários comuns.
Maiores informações de Debian:

Depois de uma longa batalha pra atualizar meu PC, consegui deixar tudo redondo pra jogar L4D2 (Left for Dead 2) com o pessoal. E sobre o Ubuntu.
Um dos empecilhos era em relação às configurações de controle do jogo, que por padrão usa o mouse e o teclado. Eu até tentei usar no início, mas estou acostumado com os consoles, xbox360 e ps3, e com seus respectivos controles. Então era um sofrimento jogar.
Tentei utilizar os controles dos dois no Linux, mas vi na Internet que o melhor controle é o do xbox, mas não o wireless, o cabeado. Sem problemas. Sai caçando um e comprei na loja xing-ling de origem questionável mais próxima (na av. Paulista).
Quando fui jogar, nova decepção: não mapeava corretamente os movimentos. Mas uma alma caridosa conseguiu fazer o mapeamento usando um driver através do programa xboxdrv (tem pra Ubuntu).
Criei então os seguinte script pra mapear o controle e jogar com os amigos:
#! /bin/sh
# Name: xbox360controler_setup.sh
# Source http://ubuntuforums.org/showthread.php?t=2002622
case `whoami` in
root) echo "Running as root";;
*) echo "You must run it as root. Using sudo for that."
sudo $0
exit 0
esac
rmmod xpad
modprobe uinput
modprobe joydev
rmmod xpad
xboxdrv \
-s \
--type xbox360 \
--deadzone 9000 \
--dpad-as-button \
--trigger-as-button \
--ui-axismap "x2=REL_X:10,y2=REL_Y:10,x1=KEY_A:KEY_D,y1=KEY_W:KEY_S" \
--ui-buttonmap "tl=KEY_LEFTSHIFT,tr=KEY_LEFTCTRL" \
--ui-buttonmap "a=KEY_SPACE,b=KEY_C,x=KEY_1,y=KEY_R" \
--ui-buttonmap "lb=KEY_Q,rb=KEY_E" \
--ui-buttonmap "lt=BTN_RIGHT,rt=BTN_LEFT" \
--ui-buttonmap "dl=KEY_LEFT,dr=KEY_RIGHT,du=KEY_UP,dd=KEY_DOWN" \
--ui-buttonmap "back=KEY_ESC,start=KEY_ENTER"
Boa jogatina e lembre-se: se for jogar, pode me chamar. Não garanto lá um desempenho muito bom, mas a diversão é garantida.
Dia desses eu redescobri as imagens da minha webcam. Tirei vários screenshots usando o aplicativo cheese, desde que minha mais nova nasceu. E nem lembrava disso.
Consegui criar uma videozinho com elas, o que foi bem legal, mostrando o crescimento dela (e minha barba ficando cada vez mais branca).
A idéia inicial era gerar um gif animado, mas o mesmo ficou em 85 MB de tamanho. E sem som.
Então resolvi fazer 2 coisas:
A captura do screenshot, eu consegui fazer utilizando pygame. O módulo já inclui vários binding pra realizar ações como capturar da webcam e salvar a imagem. O script ficou assim:
#! /usr/bin/python -u
"""
Not only Obamas _is_ watching you...
Based in: http://stackoverflow.com/questions/15870619/python-webcam-http-streaming-and-image-capture
"""
SAVEDIR = "/home/helio/Pictures/Webcam"
import pygame, sys
import pygame.camera
import time, random
pygame.init()
pygame.camera.init()
cam = pygame.camera.Camera("/dev/video0", (640,480))
while True:
print "Taking a shot:",
cam.start()
image = cam.get_image()
cam.stop()
timestamp = time.strftime("%Y-%m-%d_%H%M%S", time.localtime())
filename = "%s/%s.jpg" % (SAVEDIR, timestamp)
print "saving into %s" % filename
pygame.image.save(image, filename)
time.sleep(random.randrange(10) * 60)
Chamei de obamawatch.py em homenagem à espionagem da NSA nas nossas vidas, e que o presidente Obama não fez esforço nenhum pra diminuir ou mesmo evitar. É um script super intrusivo, pois tira fotos de tempos em tempos, podendo pegar situações que... humm... não o faça se sentir muito orgulhoso. Então é bom rodar de vez em quando.
Pra juntar as imagens JPEG geradas em um GIF animado, usei o imagemagick com o mogrify. Com o mogrify, na verdade, eu diminui as imagens pra 320x240 pixels, pra diminuir o tamanho. Então usei o imagemagick pra gera o GIF.
mogrify -resize 320x240 *jpg
gm convert -delay 20 2013-09-07_1* animated-2013-09-07.gif
Com isso consegui o resultado abaixo. Bem divertido.

Às vezes eu escrevo programas. Entre esse programas, alguns são daemons.
Além da confusão com demônios, o que são daemons?
Daemons são os programas que rodam em background no sistema, não precisando de um terminal (console) anexado. E qualquer tipo de programa pode ser um daemon, pra qualquer finalidade.
Em geral daemons seguem as seguintes regras pra se tornarem daemons:
O segundo fork() é feito para garantir que o programa, através do segundo processo filho, seja "herdado" pelo processo init do sistema.
Em Python, sempre incluo uma função como essa:
def Daemonize(self):
"""
Fork to became a daemon.
"""
if not self.isDaemon:
try:
self.run()
except KeyboardInterrupt:
sys.exit(0)
return
os.chdir("/")
pid = os.fork()
if (pid > 0):
sys.exit(os.EX_OK)
else:
pid = os.fork()
if (pid > 0):
sys.exit(os.EX_OK)
else:
self.run()
Esse é parte de um método, mas poderia ser uma função. A idéia é usar o getopt() para verificar as opções passadas e entrar no modo de daemon ou não, dependendo da opção passada, que modifica a variável booleana self.isDaemon.
Mas um dos meus programs começou a apresentar o seguinte erro:
helio@goosfraba:~$ connect_TSP.py ccn
IP already setup... skipping root access
Running as daemon
daemonized...
close failed in file object destructor:
IOError: [Errno 10] No child processes
Error in sys.excepthook:
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/apport_python_hook.py", line 66, in apport_excepthook
from apport.fileutils import likely_packaged, get_recent_crashes
RuntimeError: sys.meta_path must be a list of import hooks
Original exception was:
IOError: [Errno 10] No child processes
Inicialmente achei que era problema no "apport" com meu programa, que usa python-expect. Mesmo com tal erro, o programa funcionava perfeitamente em background, como daemon. Várias fontes na Internet, principalmente no Launchpad, o sistema de bug report do Ubuntu, várias pessoas reclamavam de tal erro como sendo problema do apport.
Após muito buscar a origem do problema, não no Ubuntu, mas no python, descobri que alguns file descriptors estavam causando esse erro, por continuarem abertos quando ocorria o fork(). Corrigi da seguinte forma:
def Daemonize(self):
"""
Fork to became a daemon.
"""
if not self.isDaemon:
try:
self.run()
except KeyboardInterrupt:
sys.exit(0)
return
os.chdir("/")
pid = os.fork()
if (pid > 0):
os.close(sys.stdin.fileno())
os.close(sys.stout.fileno())
os.close(sys.stderr.fileno())
sys.exit(os.EX_OK)
else:
pid = os.fork()
if (pid > 0):
os.close(sys.stdin.fileno())
os.close(sys.stdout.fileno())
os.close(sys.stderr.fileno())
sys.exit(os.EX_OK)
else:
self.run()
então bastou fechar os descritores de arquivo do STDIN, STDOU e STDERR pra ter certeza que o daemon não sairia com o erro acima.
Happy hacking :-)

Acaba de ser publicada a edição número 52 da revista Espírito Livre. Uma edição totalmente dedicada ao FISL 14 e... com um artigo meu!!!
Nada muito estravagante, apenas uma descrição de como foi o FISL para mim. E com as fotos que tirei durante todo o evento.
Infelizmente o servidor da revista Espírito Livre parece estar sofrendo o tráfego intenso, então está bastante difícil acessar a revista e baixar. Mas aos que conseguirem (e com certeza uma hora ou outra conseguirão), espero que gostem.

Esse enviei 2 apresentações pra Python Brasil. Uma falando sobre python-twitter (e como faço pra enviar os #FF de sexta-feira) e outra pra falar sobre python em telecomunicações.
Não tenho nada escrito ainda, e vou aguardar a confirmação do trabalho pra começar. Se der certo, estarei em Brasília no início de outubro :-)

Finalmente resolvi adicionar meu próprio PPA, Personal Package Archive - ou Arquivo de pacote pessoal, no Launchpad do Ubuntu. Isso vai me permitir distribuir facilmente os pacotes que crio. São para uso meu, baseado num Ubuntu LTS 12.04, mas podem ajudar mais pessoas.
Pra começar, fiz um upload do backport do python-twitter 1.0.1, que funciona com a API v1.1.
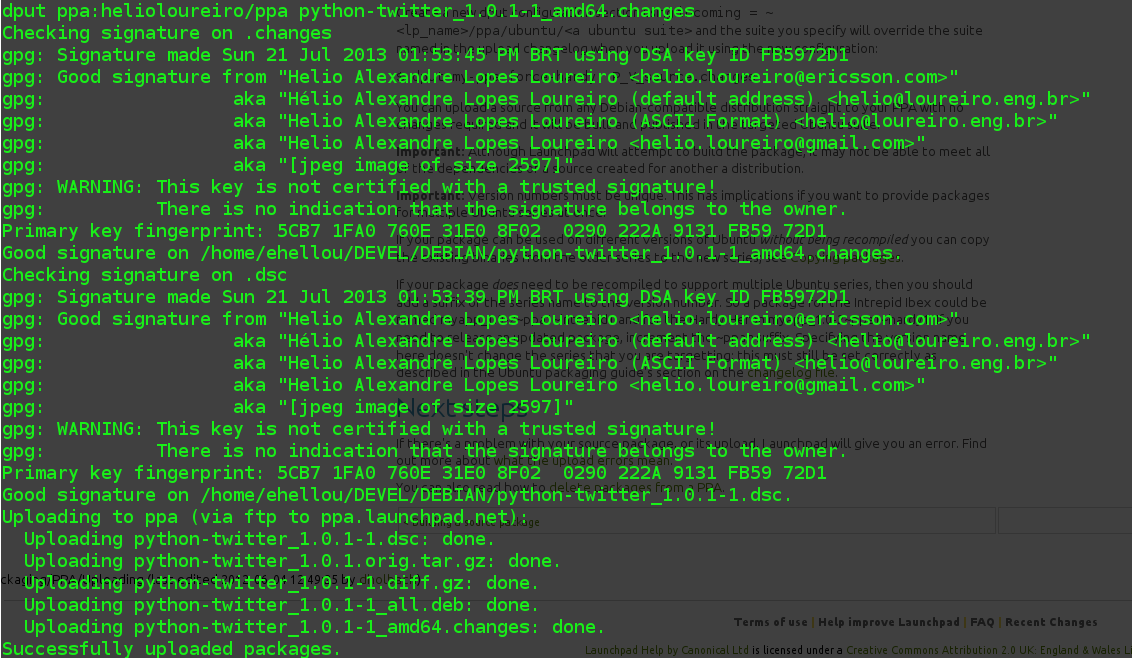
Para quem desejar usar meu repositório, deve bastar adicionar o PPA.
| sudo add-apt-repository ppa:helioloureiro |
Minha chave PGP ainda não foi adicionada, mas isso deve ser corrigido em algum commit do sistema, o que talvez demore 1 dia. Até lá, meu pacote python-twitter não aparecerá como disponível.
Meu próximo upload deve ser dos pf-kernel. Já tenho compilado as versões 3.9.5 e 3.10.0.
Mais uma vez consegui peregrinar e me juntar ao grupo de ativistas e programadores que se reúnem uma vez ao ano em Porto Alegre, RS, para o FISL, Fórum Internacional de Software Livre.
Como sempre, foi um evento agradável e cheio de reencontros. Amigos que não via a mais de 10 anos!
Esse ano escolhi uma participação um pouco mais ativa, e fiz 2 oficinas de criação de pacotes. Na verdade a idéia era fazer uma iniciação na criação de pacotes durante a primeira oficina, e continuar com uma hackaton na segunda, mas o público da segunda oficina foi... completamente diferente da primeira! Devo supor que a primeira oficina foi um completo desastre e as pessoas desistiram de vez de fazer pacotes. E tive de re-fazer a parte didática durante a segunda, o que não permitiu corrigir nenhuma pacote oficial. Mas não deixou de ser divertido (ao menos para mim).
Além do encontro especial com os amigos, tive o prazer de participar de um churrasco numa cervejaria artesanal. Helles, ipa, weiss, red ale, pilsen... realmente um evento que deu um *gostinho* a mais ao FISL. E que gostinho bom.
Não bastasse o sabor ímpar das cervejas, descobri que quem tinha organizado a festança era a caravana de Florianópolis, da UFSC! Foi um encontro etílico do "old school" com o "new school". E tinha até o Maddog por lá.
Enfim o FISL foi mais uma vez um espetáculo. Espero ter condições para poder estar por lá no ano que vem novamente.

Não fiz muita propaganda por aqui (e devia ter feito), mas participei do FISL 14, em Porto Alegre, RS, com uma oficina de criação de pacotes DEB. Tentei criar uma sinergia de Debian com Ubuntu, sem focar em nenhum dos dois, e mostrando com pacotes pode ser criados para ambos.
Aqui está a apresentação, em prezi, que usei durante o evento.
Finalmente chegou o momento em que me rendi novamente ao appeal corporativo e voltei a utilizar um equipamento da empresa, e não mais um laptop meu e pessoal.
Optei por um equipamento que fosse homologado internamente para rodar Linux, e então recebi um considerado "high end laptop": um notebook HP EliteBook 8570w.

A instalação foi bem tranquila. Bastou inserir o pendrive e seguir com os passos de instalação do Ubuntu via rede.
Sem mexer em nada, o sistema já saiu funcionando: webcam, wifi, som, etc. A única coisa que ficou faltando, mas que foi corretamente notificada pelo Ubuntu, foi a placa de vídeo nvidia, e para instalar os drivers proprietários. E que bela placa de vídeo: NVIDIA GPU Quadro K1000M (GK107GL) com 2 GB de memória dedicada. Alguns sites não recomendam essa placa para jogos, mas com certeza esse não é o meu objetivo com esse equipamento.
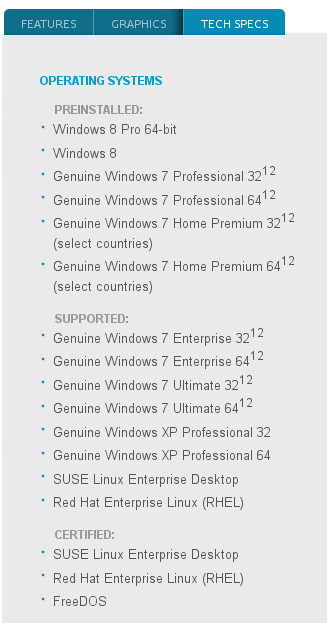
Mas vamos ver um pouco mais do hardware:
Ainda tem uma porção de coisas que não consegui identificar. Existe no hardware, mas não vejo nas saídas de lspci e lsusb, ou mesmo lshw. Um bom exemplo é uma porta de modem que tem na parte de trás do laptop.

Minha primeira impressão sobre o laptop é... ele é um monstrobook. É enorme e pesado. Pesa 3 Kg pela descrição técnica, mas parece que são uns 15 Kg. É um hardware grande e confortável para digitar, mas tão grande que tem até teclado numérico junto. E deixa isso claro pela informação na traseira, onde se descreve como "Workstation", não um notebook ou laptop. Para quem estava acostumado com um laptop fofucho de 13 polegadas, é uma mudança muito grande.


Tem ainda uma série de botões para uso ou do touchpad ou do pointer que fica no meio do teclado, algo desnecessário. As teclas são confortáveis, mas poderia ter ao menos iluminação.
Os botões para habilitar/desabilitar wireless e som, que ficam no topo à direita, funcionam sem problemas. Os outros dois botões que ficam por lá também, para acesso rápido à Internet e para uma... calculadora? Esses não funcionam para nada. O de acesso à Internet dá um refresh na página web que se está lendo.
Sobre o botão de bloqueio de som, esse não funcionou _exatamente_ de primeira. Ele mostrava o bloqueio do som, mas sem efeito concreto disso. O motivo foi que pulseaudio apontava pra saída do DisplayPort como principal. Bastou utilizar o aplicativo pavucontrol e modificar o padrão pra saída de som normal que o botão funcionou corretamente.


O site da HP dá bastantes detalhes sobre o equipamento e seu uso em potencial.
o que chama a atenção é que esse é um hardware certificado para usar Linux. Acho que nunca tinha usado um laptop que tivesse isso. Não é certificado para Ubuntu, mas se funcionou com uma distribuição de Linux, funciona com todas.
E a HP chegou mesmo a fazer até um vídeo sobre o laptop. (vídeo foi removido)
É um equipamento legal, parrudo, mas pesado. O carcaça é de aço escovado, o que dá um certo charme ao conjunto. Faz falta também uma saída HDMI ao invés de DisplayPort. E a autonomia da bateria é baixa, entre 2 e 3 horas apenas. Estou gostando dele e espero que minhas costas se acostumem logo com o peso. E espero que a próxima geração de laptops homologados pela empresa seja de ultrabooks...
Page 24 of 39
