
SPAM é uma batalha sem fim. Cria-se uma forma de mitigar ou diminuir e são apenas algumas semanas de sossego. Logo eles acham uma forma de burlar as barreiras que criamos. Como faz tempo que não trabalho com mail de larga escala e controlo apenas a da VM do servidor desse domínio aqui, eu não tenho nem idéia do tamanho do problema que grandes empresas como Google têm. A quantidade de SPAM que tenho de lidar já é mais que suficiente pra eu me aborrecer.
Eu já implementei SPF pra verificação de origem dos mails, mailassassin, white e black list e... o volume continua alto.
Mailassassin era um dos mais promissores mas consome muita CPU a cada verificação. Além disso ele é um software muito burro (desculpem ao autores e fãs) pois ele recebe o mail pra fazer análise. Porque não fazer logo na conexão alguma verificação e descartar logo? No fim gastou banda, CPU e memória pra ver algo óbvio. Quando recebo um mail vindo de algo como "helio-a414c-loureiro.eng.
 Pois o projeto OpenBSD resolveu cuidar disso. Eles criaram um daemon que enferniza a vida de spammers. É um verdadeiro saci pererê dos e-mails. O spamd recebe o mail e funciona de uma forma muuuuuuito lenta, com a conexão bem degradada. Após terminar a tentativa de envio do mail, ele simplesmente fecha a conexão e pede que tente novamente. Se o servidor tentar novamente, muito provavelmente não é uma máquina de SPAM. Como essa tentativa seguida faz parte do protocolo SMTP, servidores legítimos continuaram tentando enquanto spammers vão pra outra pobre vítima.
Pois o projeto OpenBSD resolveu cuidar disso. Eles criaram um daemon que enferniza a vida de spammers. É um verdadeiro saci pererê dos e-mails. O spamd recebe o mail e funciona de uma forma muuuuuuito lenta, com a conexão bem degradada. Após terminar a tentativa de envio do mail, ele simplesmente fecha a conexão e pede que tente novamente. Se o servidor tentar novamente, muito provavelmente não é uma máquina de SPAM. Como essa tentativa seguida faz parte do protocolo SMTP, servidores legítimos continuaram tentando enquanto spammers vão pra outra pobre vítima.
No último hackathon que participei eu tentei fazer um port desse daemon pro Linux. Encontrei um port já em andamento chamado obspamd no github, que estava com o build quebrado, e consegui arrumar o que estava com problemas. Minha idéia era fazer um daemon funcional e completo portado pra Linux, com autoconf e configure. E foi num dos bug reports que eu estava respondendo que alguém mandou outra mensagem avisando que existia um port já bem funcional do mesmo, o greyd.
Fiquei surpreso ao descobrir que até site oficial já tinha, o http://greyd.org, pois eu nunca tinha ouvido falar. Até onde vi não existem pacotes para ele em Debian ou em Ubuntu. Então boa parte da instalação foi feita manualmente.
O que eu gostaria de fazer com o obspamd, de criar um sistema de build com autoconfigure, já está pronto no greyd. Além disso ele já implementa as chamadas de kernel pra adicionar as regras de firewall necessárias pro funcionamento do greyd.
Por quê do firewall? Tanto o original, spamd, quanto o greyd funcionam ouvindo na porta 8025. Então todo pacote que não foi classificado, baseado em IP de origem, ao tentar conectar na porta 25, padrão de mail, é redirecionado à porta 8025. O greyd segue com a conexão e marca esse tipo de pacote como provável whitelist (lista branca). Na segunda tentativa de conexão esse pacote já vai direto pro servidor de mail, que no meu caso é um postfix. Esse controle é feito através do firewall iptables com regras no PREROUTING e ipset do kernel, marcando tipos de pacote com IP de origem. E precisa do módulo conntrack do kernel.
Como é um programa bem recente, não existem pacotes pra ele. Ao menos em Debian/Ubuntu. Então ele ainda exige a compilação e instalação manual.
Para baixar o greyd diretamente do github:
# git clone https://github.com/mikey-austin/greyd.git
Pra compilação, eu escolhi usar sqlite3 como formato de arquivo de whitelist, então precisei incluir os cabeçalhos e bibliotecas referentes.
# apt-get install libsqlite3-dev libnetfilter-log-dev libnetfilter-conntrack-dev \
libpcap0.8 libspf2-dev # cd greyd # autoreconf -vi # ./configure \ --with-sqlite \ --with-netfilter \ --with-spf \ --bindir=/usr/bin \ --sbindir=/usr/sbin \ --sysconfdir=/etc \ --docdir=/usr/share \ --libdir=/usr/lib \ --localstatedir=/var \ GREYD_PIDFILE=/var/run/greyd.pid \ GREYLOGD_PIDFILE=/var/run/greylogd.pid \ DEFAULT_CONFIG=/etc/default/greyd.conf # make
O greyd também precisa que sejam criados 2 usuários: greyd e greydb, que controlam daemon e base de dados da lista. No seu repositório existe um diretório que ajuda a criar pacotes. Nele é possível ver os comandos pra realizar essa tarefa manualmente em greyd/packages/debian/postinst:
# adduser --quiet --system --home /var/run/greyd --group \
--uid 601 --gecos "greyd" --shell /bin/false --disabled-login greyd
# adduser --quiet --system --home /var/lib/greyd --group
--uid 602 --gecos "greydb" --shell /bin/false --disabled-login greydb
Em seguida é preciso criar o diretório onde a base de dados em squlite3 ou bsddb será escrita.
# mkdir -p /var/greydb # chown -R greydb:greydb /var/greydb
Com a configuração de compilação, as configuração serão armazenadas em /etc/default/greyd.conf. O spamd do OpenBSD por padrão roda em um ambiente chroot() pra proteção do sistema. Eu não consegui fazer o mesmo com o greyd. As configurações que estou usando no momento são (usando diff pra comparar):
# diff -u ./etc/greyd.conf /etc/default/greyd.conf
--- ./etc/greyd.conf 2016-07-07 13:47:43.000000000 -0300
+++ /etc/default/greyd.conf 2016-07-08 09:49:28.000000000 -0300
@@ -5,8 +5,8 @@
#
# Debugging options and more verbose logs.
#
-debug = 0
-verbose = 0
+debug = 1
+verbose = 1
daemonize = 1
#
@@ -17,7 +17,7 @@
#
# Address to listen on.
#
-bind_address = "127.0.0.1"
+bind_address = "200.123.234.321"
#
# Main greyd port.
@@ -32,7 +32,7 @@
#
# Enable listening on IPv6 socket.
#
-enable_ipv6 = 0
+enable_ipv6 = 1
bind_address_ipv6 = "::1"
#
@@ -60,7 +60,7 @@
#
# Chroot enable & location for main daemon.
#
-chroot = 1
+chroot = 0
chroot_dir = "/var/empty/greyd"
#
@@ -82,11 +82,13 @@
# Specify the maximum number of connections.
#
# max_cons = 800
+max_cons = 30
#
# Specify the maximum number of blacklisted connections to tarpit.
#
# max_cons_black = 800
+max_cons_black = 30
#
# The firewall configuration.
@@ -114,8 +116,8 @@
#
section database {
#driver = "/usr/lib/greyd/greyd_bdb_sql.so"
- #driver = "/usr/lib/greyd/greyd_sqlite.so"
- driver = "/usr/lib/greyd/greyd_bdb.so"
+ driver = "/usr/lib/greyd/greyd_sqlite.so"
+ #driver = "/usr/lib/greyd/greyd_bdb.so"
path = "/var/greyd"
db_name = "greyd.db"
Em geral ele funciona apenas na interface de loopback, mas por usar um Debian mais velho, o Wheezy, precisei ajustar pra ouvir na interface pública, a eth0.
Feito isso, basta iniciar o daemon e o daemon de controle de log:
# /etc/init.d/greylogd start # /etc/init.d/greyd start
Para quem já usa sistemas com systemd:
# systemctl start greylogd # systemctl start greyd
O próprio systemd cuidará de adicionar e habilitar esses serviços.
Mas ainda falta o firewall. São necessárias algumas regras na inicialização:
# ipset create greyd-whitelist hash:ip family inet hashsize 1024 maxelem 65536 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j LOG --log-prefix "[GREYD WHITED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j NFLOG --nflog-group 155 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -m set \
--match-set greyd-whitelist src -j ACCEPT # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD 25 DNAT]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j DNAT \
--to-destination 200.123.234.321:8025 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD 25 REDIRECTED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j REDIRECT \
--to-ports 8025 # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 25 -j LOG \
--log-prefix "[GREYD FAILED]" # iptables -t nat -A PREROUTING -p tcp -m tcp --dport 8025 -j LOG \
--log-prefix "[GREYD 8025 JAILED]" # iptables -t filter -A INPUT -p tcp --dport smtp -j ACCEPT # iptables -t filter -A INPUT -p tcp --dport 8025 -j ACCEPT
Eu adicionei mais logs pra poder também acompanhar os pacotes, pra ver se estão sendo marcados ou não de acordo.
De início eu fiquei na dúvida se eu estava recebendo algum e-mail ou não, mas logo percebi que estava funcionando de acordo.
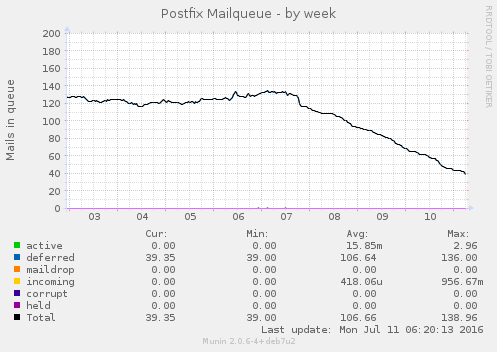
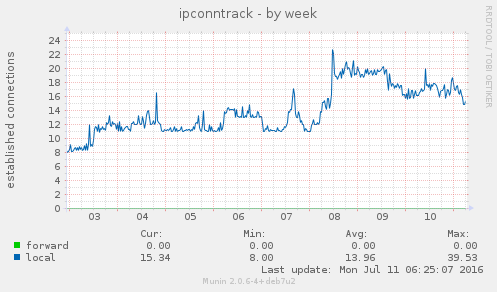
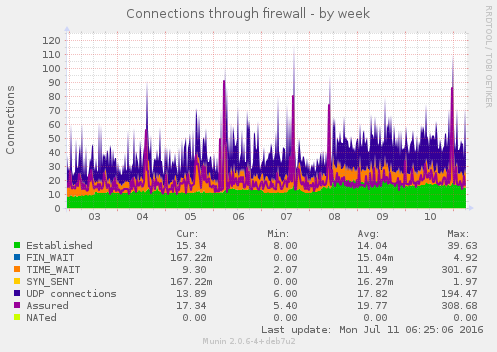
A fila de mails indesejados, que ficavam travados por não ter endereço de retorno, praticamente zeraram. O uso de memória aumento um pouco, assim como o conntrack no kernel. Por enquanto nada absurdo. E parece estar funcionando bem até agora. Se não respondi algum mail seu, já sabe o motivo.
Acabaram os SPAMs? Não! Spam é spam. Enquanto houver mail, existirá spammers. É fácil de implementar e barato. Mas eles diminuíram. E ao saber que estou gastando a conexão deles fazendo nada já me alegra o suficiente.
Meu próximo passo será gerar um pacote no meu ppa no launchpad: https://launchpad.net/~helioloureiro
Pra saber mais como lutar contra spam: http://antispam.br/

Reusando o código que escrevi pra tirar snapshots durante a PyConSe e publicar automaticamente no Twitter, escrevi um pequeno aplicativo pra raspberypi com Python pra pegar o mesmo tipo de imagem, mas da minha janela, e ir acompanhando a evolução do tempo ao longo do dia e do ano. Essa é a imagem que ilustra o início do post.
Acho que será legal fazer uma animação das imagens mostrando o sol que brilha até quase 11 da noite, o inverno que escurece às 2 da tarde, e a neve chegando. E tudo postando no Twitter.
As ferramentas são as mais simples possível: um raspberrypi conectado com um dongle wifi e uma webcam USB creative (que aliás uso pra participar dos hangouts). E sempre Python pra fazer tudo.


Descobri que o Forecast.IO fornece uma API com JSON pra buscar a previsão do tempo atual e até 10 dias, com permissão de 1000 queries por dia de forma gratuita. Perfeito pro meu pequeno projeto. O mais difícil foi fazer a conversão da temperatura de Farenheit pra Celsius (meus dias de vestibulando já se foram faz muito tempo), mas pedi ajuda à Internet pra isso. Fiz uma pequena função que retorna os dados que quero em forma de um array.
import requests
import json
import time
"""
Um monte de código por aqui
[...]
""""
def get_content():
timestamp = time.strftime("Date: %Y-%m-%d %H:%M", time.localtime())
msg = []
msg.append("Stockholm")
msg.append(timestamp)
url = "https://api.forecast.io/forecast/%s/%s" % (wth_key, wth_loc)
req = requests.get(url)
jdata = json.loads(req.text)
summary = jdata["currently"]["summary"]
temp = jdata["currently"]["temperature"]
temp = Far2Celsius(temp)
msg.append(u"Temperature: %s°C" % temp)
msg.append("Summary: %s" %summary)
return msg
A primeira coisa que precisei alterar foi a adição de textos à imagem. Tendo a informação vinda do Forecast.IO, eu precisava modificar a imagem pra que ela aparecesse. No início eu usei uma fonte de cor branca, mas logo percebi que preto ficava com um contraste melhor. Mas quando chegar o inverno, época em que os dias são realmente muito curtos por aqui, vou precisar pensar numa forma pra trocar para branco. Mas no momento usei as bibliotecas do PIL que manipulam imagem em Python.
import Image
import ImageFont, ImageDraw, ImageOps
IMGSIZE = (1280, 720)
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
"""
Um monte de código por aqui
[...]
""""
def WeatherScreenshot():
msg = get_content()
if not msg:
msg = "Just another shot at %s" % \
time.strftime("%H:%M", time.localtime())
if msg:
msg_body = "\n".join(msg[1:])
im = Image.open(filename)
# just get truetype fonts on package ttf-mscorefonts-installer
try:
f_top = ImageFont.truetype(font="Arial", size=60)
except TypeError:
# older versions hasn't font and require full path
arialpath = "/usr/share/fonts/truetype/msttcorefonts/Arial.ttf"
f_top = ImageFont.truetype(arialpath, size=60)
try:
f_body = ImageFont.truetype(font="Arial", size=20)
except TypeError:
# older versions hasn't font and require full path
arialpath = "/usr/share/fonts/truetype/msttcorefonts/Arial.ttf"
f_body = ImageFont.truetype(arialpath, size=20)
txt = Image.new('L', IMGSIZE)
d = ImageDraw.Draw(txt)
d.text( (10, 10), msg[0], font=f_top, fill=255)
position = 80
for m in msg[1:]:
d.text( (10, position), m, font=f_body, fill=255)
position += 20
w = txt.rotate(0, expand=1)
im.paste(ImageOps.colorize(w, BLACK, BLACK), (0,0), w)
im.save(filename)
descobri que a versão de raspbian que estou usando, baseado em Debian Wheezy, tem uma API um pouco diferente e pode precisar que a fonte com o path completo seja passada no argumento.
Outra alteração foi mudar a chamada pra webcam capturar a imagem que era uma função mas modifiquei pra uma thread. Assim o tempo fica consistente. Do contrário ao invés de mostrar 12:00 apareceria algo como 12:03 (o tempo pra adquirir a imagem).
import threading
def WeatherScreenshot():
th = threading.Thread(target=GetPhoto)
th.start()
msg = get_content()
th.join()
E já que mencionei a imagem, esse foi o maior problema até agora. Descobri que não existe uma forma muito confiável de inicializar a webcam. Às vezes ela adquiri a imagem de forma bonitinha, às vezes fica super exposta, outras vezes sub.

E não tem nada que dê um feedback sobre a qualidade. Li vários artigos com dicas de uso com pygame, que é a forma que uso, e com opencv também, mas todas com o mesmo princípio. Basicamente fazem um start() no framework da webcam, que inicializa a webcam, adquirem um número de imagens aleatórios (alguns dizem 30) e esperam pelo melhor ao capturar a imagem. Nada que retorne um indicador de qualidade. Nada.
DISCARDFRAMES = 2 * 30
def GetPhoto():
filename = None
pygame.init()
pygame.camera.init()
elif os.path.exists("/dev/video0"):
device = "/dev/video0"
if not device:
print "Not webcam found. Aborting..."
sys.exit(1)
# you can get your camera resolution by command "uvcdynctrl -f"
cam = pygame.camera.Camera(device, IMGSIZE)
cam.start()
time.sleep(3)
counter = 10
while counter:
if cam.query_image():
break
time.sleep(1)
counter -= 1
# idea from https://codeplasma.com/2012/12/03/getting-webcam-images-with-python-and-opencv-2-for-real-this-time/
# get a set of pictures to be discarded and adjust camera
for x in xrange(DISCARDFRAMES):
while not cam.query_image():
time.sleep(1)
image = cam.get_image()
image = cam.get_image()
Basicamente um método de tentativa e erro. Por isso que iniciei a chamada à webcam como thread. Como as webcams USB tem CPU própria, não tem - até onde pesquisei - uma API confiável pra verificar se o balanço de branco normalizou antes de capturar a imagem. Só retornam a própria imagem. Tosco.
Então resolvi fazer um outro script como módulo, que basicamente mapeia toda a imagem em seu tamanho e cria um dicionário do tipo "COR: quantas vezes". Descobri que valores RGB (pega o valor de R + G + B, soma e divide por 3 pra ter a média) acima de 235 já indicam super exposição. Não só isso. Como eu conto a quantidade que aquele valor RGB aparece, sempre que um valor sobressai acima de 15% do total, já indica uma imagem ruim. Não é um dos melhores métodos científicos, mas tem funcionando bem (verifiquei nas imagens já adquiridas e salvas). Os tempos de aquisição de imagem mudaram de até 1 minuto pra em torno de 10 minutos. Mas por enquanto com qualidade muito melhor.
import Image
def brightness(filename):
"""
source: http://stackoverflow.com/questions/6442118/python-measuring-pixel-brightness
"""
img = Image.open(filename)
#Convert the image te RGB if it is a .gif for example
img = img.convert ('RGB')
RANK = {}
#coordinates of the pixel
X_i,Y_i = 0,0
(X_f, Y_f) = img.size
#Get RGB
for i in xrange(X_i, X_f):
for j in xrange(Y_i, Y_f):
#print "i:", i,",j:", j
pixelRGB = img.getpixel((i,j))
R,G,B = pixelRGB
br = sum([R,G,B])/ 3 ## 0 is dark (black) and 255 is bright (white)
if RANK.has_key(br):
RANK[br] += 1
else:
RANK[br] = 1
color_order = []
pic_size = X_f * Y_f
print "Picture size:", pic_size
for k in sorted(RANK, key=RANK.get, reverse=True):
amount = RANK[k]
# if low than 15%, ignore
if amount < (.15 * pic_size):
continue
print k, "=>", RANK[k]
color_order.append(k)
if color_order:
print color_order
return -1
return 0
O código todo está disponível no meu github.
https://github.com/helioloureiro/snapshot-twitter
E provavelmente devo lançar um gif animado posteriormente com o decorrer do clima ao longo do ano.
Tenho alguns problemas como concorrência no caso de tentar adquirir uma imagem ao mesmo tempo que a crontab tentar fazer isso (implementei uma API em REST pra isso, mas não é algo pra publicar :). Devo implementar algum tipo de lock usando /tmp, mas algo simples.
E agora no verão, com sol até quase 11 horas da noite, tenho também um pequeno problema de negação de serviço que às vezes acontece.


Ainda não descobri um módulo em Python pra mitigar isso :)

Eu nunca escrevi sobre séries ou filmes por aqui, mas essa série da HBO vale como uma exceção.
É uma comédia que satiriza o ambiente de startups do vale do silício, nos EUA. Pra quem está pensando em abrir um negócio no modelo de startup, com software livre principalmente, vale a pena assitir. Vai ter algo especifico de software livre? Vai ter GNU vs Linux? Não, não é uma série sobre tecnologia nesse nível. É sobre o ambiente de competição de startups. É mais sobre a área de negócios, mas não faltam referências a servidores, cloud, etc.
Como qualquer comédia que se espera, tem um grupo disfuncional que trabalha na startup que é tema da série. Geeks anti-sociais no bom estilo que precisam trabalhar em grupo mesmo não sabendo nem conversar entre si. E por aí segue a série, com uma ótima visão de problemas de startup, como o uso de SCRUM por um time que não acredita em agile, mandar tudo pra nuvem sem nem ao menos saber o que é nuvem, prometer algo que não tem prazo pra entregar, e por aí. E a pressão! A pressão pra virar uma startup rentável enquanto é dito o mantra "dinheiro não é importante, o importante é ter valor" e não ter dinheiro pra pagar os funcionários.
Mesmo com o tom de comédia traz uma ótima reflexão sobre o insano mundo de startups e a forma bizarra que se tornou tocar o negócio, desde a captação de investidores anjos (não tão anjos assim) quanto a perda de controle da empresa para esses novos donos.
Eu assisti apenas as 2 primeiras temporadas, mas recomendo. É uma aula de MBA em forma de comédia.
Nem mal instalei o Ubuntu 16.04 com KDE5 e já quebrei o sistema. Não sei bem o que fiz, mas as fontes ficaram simplesmente impossível de enxergar. E olha que estou usando o desktop numa TV de 47 polegadas de LED.
Tentei de tudo quanto foi jeito pra tentar ao menos ler os menus do KDE5, mas estava impossível. Tentei reverter alguma possível mudança feita removendo os diretórios ~/.kde* ~/.config/k* e... nada! Continuei com fontes micro.
Dando uma pesquisada na Internet encontrei alguns problemas semelhantes pra quem tinha placa NVIDIA, meu caso, que alguma atualização mudou os DPI (dot per inch, ou pontos por polegada) que afeta diretamente a resolução.
Encontrei uma boa descrição com solução no askubuntu: http://askubuntu.com/questions/197828/how-to-find-and-change-the-screen-dpi
Eu alterei o /etc/X11/Xsession.d/99x11-common_start e adicionei antes do fim a seguinte linha:
xrandr --dpi 96
E problema resolvido.
Só não entendi muito bem como cai nesse tipo de problema. Talvez algum update no driver da NVIDIA.
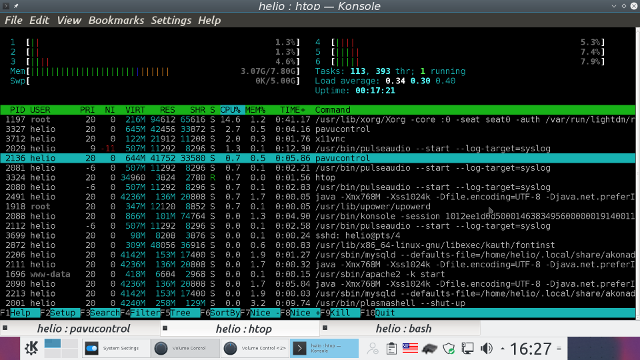
Ultimamente andei bastante ocupado e com pouco tempo pra escrever por aqui. Parte disso por conta de ser parte da organização da PyConSe (Python Conference Sweden) e o evento aconteceu logo agora em maio. Então estava bastante ocupado por cuidando de mandar fazer camisetas, adesivos, e fliers, verificar invoices, checar hotel, etc.
Mas o assunto não é a PyConSE, que pretendo descrever num próximo post (estou aguardando a publicação dos vídeos pra fazer isso), e sim um canal que lançamos faz algum tempo, o Unix Load On.
Canal do Unix Load On no Youtube
Temos um grupo no Telegram de pythonzeiros (ou seriamos pythoneiros?) que deixaram o Brasil e moram atualmente na europa. Inicialmente era um grupo de somente expatriados na europa, mas virou algo mais amplo e geral, com todos que estão fora país. Como para nós fica difícil participar de hangouts feitos pelos grupos no Brasil, criamos um nosso. Gravamos quinzenalmente às 10 da noite no horário local (timezone +02:00), o que é atualmente 5 horas da tarde no Brasil (quando Brasil entra em horário de verão e a europa sai, a diferença fica em 3 horas). E falamos por aproximadamente 2 horas, com aqueles 5 minutos técnicos pra "já vai acabar".
Os Hangouts em geral tem pouca participação de pessoas no Brasil pelo horário (é duro competir com happy hour), mas têm bem mais audiência depois. Comentamos sobre assuntos gerais em tecnologia, mas sempre com uma pitada de python e software livre. Vamos de política de privacidade a mercado, variando bastante os assuntos e os escopos cobertos.
Recentemente adicionamos ainda uma forma de receber sugestões de assuntos para serem comentados. Se quiser enviar uma sugestão basta acessar aqui:
Também temos uma landing page no Facebook, mas serve mais pra coletar comentários e facilitar a publicação dos próximos hangouts por lá.
Se é um ativista de software livre do tipo fanático, não se preocupe da página estar no Facebook pois usamos o Hangout pra fazer os programas e depois publicamos no Youtube. Então não é mesmo pra você.
Esses são os episódios já gravados. Se quiser acampanhar ou mesmo participar do próximo, o mesmo será gravado dia 27 de maio.
Episódio alfa
Episódio beta
Episódio RC1
Episódio RC2

Quando do lançamento da versão LTS do Ubuntu, a 16.04, vi várias receitas exotéricas de upgrade. Depois do terceiro ou quarto artigo que li, tive a nítida sensação de que um copiou do outro, pois seguiam mais ou menos os mesmos passos.
Como eu não tinha tentado o upgrade, pois eu sempre espero um pouco pra fazer o upgrade já que é normal que vários bugs apareçam e depois de mais ou menos 1 mês estão corrigidos, achei que realmente essas formas de upgrade eram necessárias uma vez que o sistema de init mudou do 14.04 de sysvinit pra systemd no 16.04.
Agora finalmente fiz o upgrade e usei a forma anterior. Não sei o motivo de ninguém ter mencionado mas... a forma de fazer upgrade é rodando o seguinte comando:
sudo do-release-upgrade
Pronto! Upgrade será feito. Como todo bom upgrade, vai dar umas zique-ziras que se resolve com um reboot seguido de "dpkg --configure -a" e "apt-get -f install", mas nada de muito grande.
Desculpem se foi curto, mas upgrade é coisa simples. Sempre foi.

Meu novo queridinho de programação é um raspberrypi. Tenho feito coisas interessantes com ele usando Python. E em breve teremos a PyCon Sweden acontecendo por aqui. Então resolvi criar um robôzinho de twitter pra postar snapshots da apresentação. Pretendo colocar minha webcam externa nele (uso pros hangouts) e deixar ele pegando as imagens da conferência e postando.
No script a mensagem é estática, mas eu pretendo alterar para algo que pegue uma lista com horários, nomes e temas pra deixar tudo junto na postagem. Vai ficar interessante.
O código parcialmente feito, que veio o obamawatch, é esse aqui:
#! /usr/bin/python -u
# -*- coding: utf-8 -*-
"""
Based in:
http://stackoverflow.com/questions/15870619/python-webcam-http-streaming-and-image-capture
"""
SAVEDIR = "/tmp"
import pygame
import pygame.camera
import time
import sys
import os
import twitter
import ConfigParser
configuration = "/home/helio/.twitterc"
def TweetPhoto():
"""
"""
print "Pygame init"
pygame.init()
print "Camera init"
pygame.camera.init()
# you can get your camera resolution by command "uvcdynctrl -f"
cam = pygame.camera.Camera("/dev/video1", (1280, 720))
print "Camera start"
cam.start()
time.sleep(1)
print "Getting image"
image = cam.get_image()
time.sleep(1)
print "Camera stop"
cam.stop()
timestamp = time.strftime("%Y-%m-%d_%H%M%S", time.localtime())
year = time.strftime("%Y", time.localtime())
filename = "%s/%s.jpg" % (SAVEDIR, timestamp)
print "Saving file %s" % filename
pygame.image.save(image, filename)
cfg = ConfigParser.ConfigParser()
print "Reading configuration: %s" % configuration
if not os.path.exists(configuration):
print "Failed to find configuration file %s" % configuration
sys.exit(1)
cfg.read(configuration)
cons_key = cfg.get("TWITTER", "CONS_KEY")
cons_sec = cfg.get("TWITTER", "CONS_SEC")
acc_key = cfg.get("TWITTER", "ACC_KEY")
acc_sec = cfg.get("TWITTER", "ACC_SEC")
print "Autenticating in Twitter"
# App python-tweeter
# https://dev.twitter.com/apps/815176
tw = twitter.Api(
consumer_key = cons_key,
consumer_secret = cons_sec,
access_token_key = acc_key,
access_token_secret = acc_sec
)
print "Posting..."
tw.PostMedia(status = "Testing python twitter and PostMedia() for #pyconse timestamp=%s" % timestamp,
media = filename)
print "Removing media file %s" % filename
os.unlink(filename)
if __name__ == '__main__':
try:
TweetPhoto()
except KeyboardInterrupt:
sys.exit(0)
Acabei usando /dev/video1 pois estava testando a webcam no laptop, que já tem outra webcam interna e quando rebootei com a câmera externa, acabou jogando a dele pra esse device.
Outra melhoria que implementei foi a de mover os tokens de autenticação pra um arquivo externo e ler via ConfigParser(). Assim fica mais limpo o código e possível de enviar pro github (e sem mandar suas chaves privadas junto :).
Agora estou totalmente preparado para participar.
![]()
Agradeço ao Elias Lima pela montagem. Ficou perfeito e... sem barriga! Domo arigatô gozaimashita!
![]() Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
#! /usr/bin/python
def debug(msg):
print "DEBUG: %s" % msg
class MinhaClasse:
código
código
código
if __name__ == '__main__':
o = MinhaClasse()
o.main()
Então o que faço em geral é ter uma função debug(), mesmo que use classe e orientação à objetos, pra facilitar a chamada. Porque eu uso a função? Se eu usar como método dentro da classe, tem de chamar toda vez como self.debug(). Como não vejo muita vantagem nisso, prefiro definir sempre como função no topo do código.
Mas esse é um exemplo pra mostrar o princípio. O que uso é um pouco mais elaborado que isso. Vamos melhorar esse código pra entender melhor criando alguns métodos como __init__() e main().
#! /usr/bin/python
import getopt
DEBUG = False
def debug(msg):
if DEBUG:
print "DEBUG: %s" % msg
class MinhaClasse:
def __init__(self):
debug("Construtor da classe")
def fazalgo(self):
debug("Fazendo algo")
def main(self):
debug("Chamando main")
self.fazalgo()
if __name__ == '__main__':
try: opts, args = getopt.getopt(sys.argv[1:], "d") for opt, arg in opts: if opt == "-d": DEBUG = True debug("DEBUG ENABLED") except getopt.GetoptError: pass
if os.environ.has_key("DEBUG"): DEBUG = True
o = MinhaClasse()
o.main()
Primeiramente eu adicione algum tipo de verificação de opção. Pode ser com getopt como argparse. Como é uma opção simples, pra verificar o parâmetro "-d", de debug ativo, usei getopt. Em seguida usei uma variável global DEBUG, que fica como padrão em False, ou seja, desligado.
Quando faço a chamada na parte de baixo, onde __name__ é '__main__', verifico a opção via flag ou via variável de shell. Isso quer dizer que se eu usar o script de 2 formas, terei debug ativado:
> ./meuscript.py -d
ou
> env DEBUG=1 ./meuscript.py
a segunda forma ajuda no caso de ter um sistema mais complexo e um shell script chamar seu programa. Daí se vários scripts verificarem as variáveis de shell pra buscar por DEBUG (ou $DEBUG), fica fácil ativar/desativar.
E assim até hoje eu debugo meus programas. Claro que fiz alguns aperfeiçoamentos como uma função que imprime o nome do método que está rodando.
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
Assim, dentro de um método, posso usar debug da seguinte forma:
class MinhaClasse:
def __init__(self):
debug(__funcname__)
E isso ajuda ao imprimir o nome da função corrente, da mesma forma que se usa a macro__FUNCTION__ em C. Essa dica eu achei recentement no StackOverflow:
http://stackoverflow.com/questions/5067604/determine-function-name-from-within-that-function-without-using-traceback
E por último, e acabei com o tempo refinando meu debug(). Ao invés de de somente aceitar string, eu fiz um seletor de tipo pra imprimir qualquer variável, inclusive dicionários no formato json pra ficar mais fácil ler.
#! /usr/bin/python
import json
import getopt
DEBUG = False
def debug(msg):
""" Debug helper """
if DEBUG:
if type(msg) == type("abc"):
# it is ok
None
elif type(msg) == type({}):
msg = "%s" % json.dumps(msg, indent=4)
elif type(msg) == type([]):
msg = "[ %s ]" % ", ".join(msg)
msg = "DEBUG(%s): %s" % (__file__, msg)
print msg
syslog.syslog(syslog.LOG_DEBUG, msg)
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
class MinhaClasse:
def __init__(self):
debug(__funcname__)
debug("Construtor da classe")
self.nome = "Helio"
self.sobrenome = "Loureiro"
debug("Nome: %s" % self.nome)
debug("Sobrenome: %s" % self.sobrenome)
self.dados = {}
def fazalgo(self):
debug(__funcname__)
debug("Fazendo algo")
for k, v in self.dados.items():
debug("%s => %s" % (k, v) )
def main(self):
debug(__funcname__)
self.dados = { "Nome" : self.nome,
"Sobrenome" : self.sobrenome }
debug(self.dados)
self.fazalgo()
if __name__ == '__main__':
try:
opts, args = getopt.getopt(sys.argv[1:], "d")
for opt, arg in opts:
if opt == "-d":
DEBUG = True
debug("DEBUG ENABLED")
except getopt.GetoptError:
pass
if os.environ.has_key("DEBUG"):
DEBUG = True
o = MinhaClasse()
o.main()
Como escrevi anteriormente, não é um padrão fazer isso. Existem módulos que ajudam a debuggar de forma até mais profunda. Eu gosto de escrever minhas mensagens de debug pra filtrar melhor as mensagens e poder ver o que realmente importa. Então fica aqui a dica.
![]()
O software livre é tido como um movimento social por várias pessoas. Pelo mesmo motivo muitas outras associam software livre com socialismo ou comunismo, o que já foi desmentido pelo próprio criador do termo software livre: Richard Stallman.
Eu mesmo imaginava que a função social do software livre como a imagem acima, que peguei do projeto de uma colega de trabalho, Eduscope[1]. Era algo que tornaria o mundo melhor e menos desigual, lutando contra as grandes corporações que controlavam o mundo. Essa última parte era outra forma de dizer "sou contra a Microsoft e tudo que ela representa".
E se foram mais de 10 anos com software livre. Linux completou 20 anos. Projeto GNU, 30. E o mundo?
O mundo não ficou menos desigual. Pela situação atual da economia americana, eu diria que até ficou muito mais desigual. O Brasil teve uma melhoria de condição de vida das famílias em geral, olhando num panorama dos últimos 10 anos - e descartando um pouco a crise atual, mas não foi causada pelo software livre. Enquanto isso as empresas de software livre como RedHat, Canonical e Google se tornaram uma corporação tão grande e poderosa como a própria Microsoft, com os mesmo tipos de problemas que tentávamos combater antes.
Onde está esse lado social? Cadê???
Pensando sobre isso, comecei a olhar por outro lado: quais são as empresas de sucesso atualmente? A Forbes lista as principais como sendo:
Se filtrarmos por empresas de tecnologia somente, o ranking fica assim:
Ignorando que a Microsoft disse que "ama o Linux", já que a contribuição dela com software livre é pouca e em geral cobre mais a adaptação ao seu ambiente de cloud, o Azure, todas as demais têm algum envolvimento com software livre. Seja como parte de sua estratégia de negócios, seja como seus produtos ou serviços (o que volta à estratégia). Então é possível ver que software livre é um sucesso no mundo dos negócios, mas ainda não tem nenhum lado social. E no fim empresas cresceram e acabaram virando grandes corporações como anteriormente.
Mas eu pessoalmente acho que surgiu um lado social do software livre que é bem diferente desse de melhoria das condições das populações mais pobrel (continua sendo obrigação do governo) e do fim das grandes corporações. Vou usar o mercado em que trabalho como exemplo pra isso, o de telecomunicações.
Se observar o mercado de telecom de 20 anos atrás, no surgimento do Linux, esse era um mercado dominado por grandes empresas e padrões rígidos. Tudo era definido pela ITU-T ou IEEE com custos altíssimos de aquisição de material. Então existiam poucos interessados - a menos que tivessem muito capital pra entrar nesse mercado - e os equipamentos eram muito caros, o que refletia diretamente nos valores cobrados dos usuários, que tinham basicamente um serviço de voz e nada mais.
Pensando em 10 anos atrás, 2006, esse mercado já tinha sofrido algumas baixas com o surgimento do Skype, que iniciou uma migração sem volta pra serviços de VoIP. Skype não foi o único responsável por VoIP, mas arruinou boa parte das operadoras que tinham como seu negócio a venda de chamadas internacionais. Em 2006 voz ainda era o maior gerador de receita das empresas, mas a banda larga já estava gerava uma outra boa parte e mostrava que estava crescendo. Mas os celulares mais modernos, smartphones, ainda não eram uma realidade próxima pra muita gente.
Olhando esse mesmo mercado hoje em dia, o que aconteceu? Grandes fornecedores de equipamentos simplesmente faliram, como foi o caso da Nortel. Outros se juntaram pra poder sobreviver. Mas a quantidade de fornecedores não aumentou, muito pelo contrário, apenas diminuiu. De onde veio a concorrência que destruiu seu mercado? Veio de IT. Com isso o mercado de telecom se transformou em ICT, Information and Communications Technology, ou Tecnologia da informação e da telecomunicação. Regras fixas que levavam anos, talvez décadas , pra serem definidas foram trocadas por métodos ágeis e softwares mais leves. Normas ITU-T foram trocadas por RFCs da IETF. Empresas que não tinham nenhum conhecimento sobre telecom começaram a tentar esse mercado. A Apple, uma inovadora nesse sentido, simplesmente quebrou todos os paradigmas de telefonia com o lançamento do iPhone. Junto veio o Android. E com isso milhões de programadores começaram a lançar seus apps pra esse mundo novo. O mundo abraçou dados e IP, e voz, antes o carro chefe de mercado, virou um acessório de pouco uso.
Onde está o lado social e software livre nisso? Se pensar nesses momentos, de 20 anos atrás, 10 e agora, verá que o custo do uso de telefonia despencou pro usuário, permitindo mais pessoas participarem desse ambiente. Claro que eu não me refiro a isso como o fator social. Eu me refiro ao montante de receita, que diminuiu pra fornecedores e operadoras, mas não pro mercado como um todo. Essa receita foi dividia com novas empresas.
O que pra mim foi o lado totalmente social proporcionado pelo software livre foi o surgimento de startups. O mercado de telefonia foi totalmente canibalizado por empresas como Skype, Whatsapp, Google Hangout, Facebook Messenger, Viber, Actor, Telegram, etc. O software livre permitiu que pequenas empresas - algumas viraram gigantes - o usassem como base do seu modelo de negócios e participassem de um mercado que até então era totalmente negado a elas. Como exemplo, Whatsapp começou como uma pequena empresa com seus servidores baseados em FreeBSD e Erlang, ambos softwares livres. E todas as startups que existem atualmente se baseiam de um jeito ou de outro em software livre. Seja como base do seu negócio ou seja como ambiente de desenvolvimento.
E isso não foi só no mercado de telecom. O mesmo aconteceu com outros mercados, como o Netflix nos faz lembrar.
Então esse é o lado social que o software livre trouxe em todas as áreas. Se há 10 anos atrás todo mundo só pensava que um emprego bom, com salário razoável, era só vivendo dentro de uma grande corporação, o software livre hoje em dia permite que ele trabalhe de casa pra uma startup que combine com seu modo de vida e seu jeito de pensar, ou mesmo em empreender pra ter sua própria startup.
Software livre ensinou a pescar, e, sim, dividiu o bolo. Que venha mais software livre.
[1] Pra quem quiser saber mais sobre esse interessante projeto de educação, o site é Eduscope. Mas basicamente foi um experimento de acesso à informação em locais muito pobres, como Paquistão. Os sistemas rodavam Ubuntu e as pessoas o usam pra auto-aprendizado (continua funcionando). Criado por uma ex-colega de trabalho como projeto científico de aprendizado.
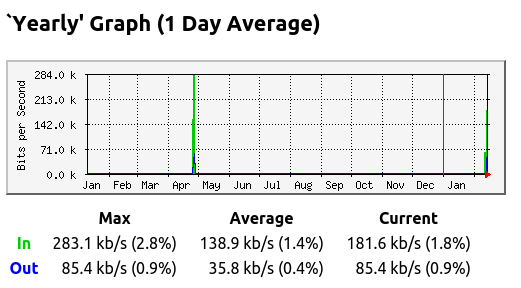
Depois de quase um ano parado, resolvi colocar meu PC desktop pra funcionar. Pelo gráfico do MRTG é possível ver como ele foi pouco utilizado nos últimos tempos (em geral uso meu laptop atualmente).
Mas como tenho um disco de 2 TB nele e com o fim do serviço de cloud storage Copy, que eu usava, resolvi reativar pra usar com OwnCloud. Como já ia ligar mesmo, até pensei em usar no quarto como dispositivo de TV pra assistir Netflix e, quem sabe, até jogar Steam, já tinha uma placa Nvidia justamente pra isso (que comprei pra jogar com o pessoal e fiz isso umas... 3 vezes talvez).
O primeiro problema foi... que nem ligava. Tenho uma placa PCI-E da Nvidia e a placa onboard, Intel. Nenhuma delas dava sinal de vida. Então iniciei o procedimento de debug do hardware, pra tentar fazer o desktop voltar à vida. Removi o cabo de energia de todos os periféricos que tenho: HDs, unidade de DVD, etc. Removi também a placa Nvidia. E sem sucesso. Sem nenhum sinal de vida (e vídeo).

Algumas placas mães têm um par de pinos para reset. Talvez a minha tenha, mas se ficou 1 ano parado, com certeza que não tenho nem manual. Então usei o método mais fácil de reset da configuração da BIOS: removi a bateria e deixei uns 30 segundos fora. Com isso consegui que o computador ligasse e enviasse o sinal de vídeo pela placa onboard.
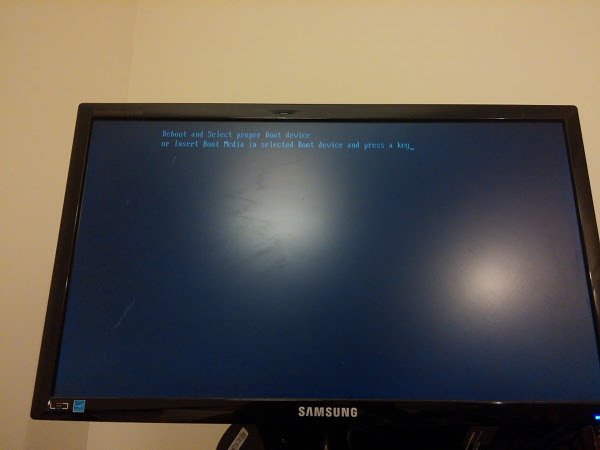
Uma vez com sinal de vídeo, foi a vez de reconectar os periféricos. Coloquei energia nos HDs (tenho 2) e na unidade de DVD. Como estava com o desktop no quarto, usei uma placa wifi pra ter acesso à Internet. Tudo ok e boot funcionando.
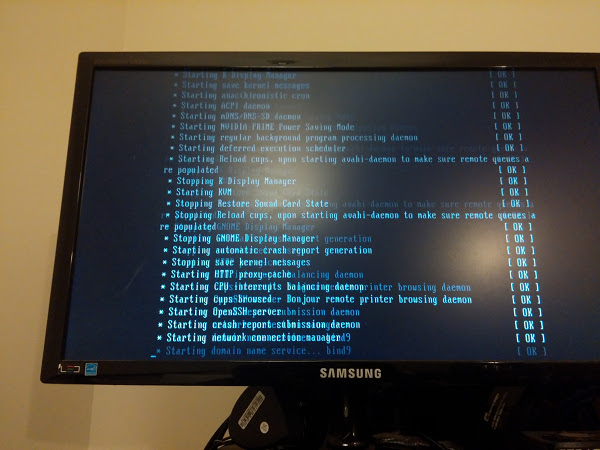
O próximo passo? Reconectar a placa Nvidia e fazer o sinal de vídeo funcionar por ela. Fiz isso e... nada. Usando um cabo HDMI no lado do PC, testei o monitor e a conexão com o cabo usand um Playstation 3. Funcionou perfeitamente. O que seria então da placa Nvidia? Lembrei que existia um parâmetro na BIOS que perguntava qual placa usar como padrão. Fiz a configuração e apontei pra placa na PCI-E. E nada...

Seria minha placa Nvidia a outra opção, que era PCI? Com certeza não, mas testei. E nada. Então removi a placa e dei uma boa limpada, aspirando todo o pó que estava por lá. Aproveitei e limpei o PC inteiro por dentro. Foi tanto pó que dava pra fazer tranquilamente uma duna depois. Mas voltando ao PC... nada. Nem sinal de vídeo pela Nvidia. Ao conectar pela placa Onboard, tudo funcionando.
Pelo Linux eu podia ver que o sistema X tentava ativar pela placa, que era reconhecida pelo lspci, mas simplesmente ela não respondia. Foi então que comecei a achar que a placa tinha queimado.
Mas placa de vídeo queimar ou estragar por falta de uso??? Eu descartei a parte do "queimar". O que poderia ser?
Outra opção poderia ser... energia! Sim, podia ser minha fonte de alimentação que não conseguia fornecer a energia necessária pra placa. Mas como medir isso? Tenho até um multímetro, mas eu teria de medir a tensão de alimentação do barramento PCI-E. Fora que uma esbarrada em algum ponto energizado e... PUFF! Lá se vai o PC inteiro.
Resolvi arriscar na solução mais barata e comprar um fonte nova. Afinal a minha era de 350W de potência, e uma nova, de 500W, não faria mal algum. Passado alguns dias, uma vez que a compra foi via Internet, a fonte chegou e voltei à obra.
Trocada a fonte, reconectados os cabos, e...
Sim, já liguei na TV e saiu funcionando. Era realmente a fonte de alimentação. Melhor, gastei muito menos que comprar outra placa de vídeo (e que não iria funcionar).


Qual o motivo da fonte de alimentação ter falhado? Em geral as fontes passam por processos de qualidades mais baixos que os outros componentes de PC. Como usa componentes que lidam com potência mais alta que o resto do PC, usa alguns capacitores à óleo. Se você algum dia ligou a fonte do PC de 110 V em 220 V, já viu esse óleo espirrando e fazendo fumaça. Eu acho que com o tempo parado, alguns desses componentes ressecaram, perdendo eficiência. Mesmo o ventilador da fonte já fazia muito barulho.
Se eu tivesse medido as saídas da fonte no conector eu descobriria isso? Eu acho que não. O PC ligava e funcionava, o que significa que ele enviava a voltagem esperada. O que acontecia era que a corrente era baixa e não suficiente pra alimentar a placa Nvidia, que deve consumir bastante. Esse tipo de falha não é tão fácil de pegar com multímetro.
Enfim meu PC está de volta e, como esperado, não fiz absolutamente nada nele. Tem o OwnCloud, mas já recebi uma mensagem de erro de que ele não é seguro o suficiente pra estar nos repositórios :(
Steam? Sincronizei. Quem sabe algum dia eu jogue. O que preciso agora é de um teclado wireless.

2016 já começou para mim com oportunidades de acompanhar alguns assuntos interessantes. E no caso eu pude assistir uma palestra de Richard Stallman na aula magna da universidade de Estocolmo, Suécia. Pra quem não sabe e associa Suécia com cachorro são bernardo, chocolates e alpes para esquiar, essa é a Suíça. Suécia é um país mais ao norte da Europa, da região que vieram os vikings. Se já jogou Skyrim, é daquela região que é cheia de gelo quase que o ano inteiro. Além do frio e dias escuros no inverno (assim como dias longos no verão), a Suécia é um país com bastante igualdade social. Então a palestra do Stallman atraiu meu interesse pois eu gostaria de ver quais seriam os argumentos sobre software livre num país onde o uso do mesmo não influencia em uma mudança social. Como falar de liberdade para um povo livre? E não me refiro ao quesito econômico somente, mas também em igualdade de gêneros, igualdade de oportunidades, enfim igualdade em tudo!
Eu já vi várias vezes as palestras dele no Brasil, e até algumas vezes pela Internet Então eu esperava alguns argumentos diferentes do que estou acostumado a ouvir, mas no fim a palestra foi muito interessante sob vários pontos de vista. Infelizmente os pontos que vou descrever a seguir mostram totalmente o ponto de vista do interlocutor. Conforme ele ia falando, meu nível de interesse aumentava com as coisas que eu realmente queria ouvir. Assim que conseguir um link pra algum vídeo gravado da palestra, estarei disponibilizando para quem mais pessoas possam ter opiniões próprias sobre o que ele falou (ou até deixou de falar). O que descrevo abaixo eu confirmei com alguns amigos que estavam por lá, apenas para ter certeza que não tinha sido engano meu ou algum erro de tradução do inglês que entendi dele.

Acho que nunca tinha ouvido ele mencionar BSD antes. Dessa vez ele não só mencionou como disse que não baseou seu sistema livre em BSD pois na época, 82/83, o Unix BSD estava muito enraizado e misturado com o sistema proprietário da AT&T. Esse foi o motivo que o levou a criar um sistema GNU: garantir que o sistema seria completamente livre de qualquer código proprietário. Ele também disse que ajudou a incentivar a criação de um BSD totalmente livre.
Pela história dos BSD, essa época não era exatamente quando acontecia o processo da AT&T pelo uso de seu código por sistemas BSDs (na verdade contra a BSDi) e que resultou no padrão BSD4.4-Lite, de onde surgiram os BSDs modernos como FreeBSD, DragonFly, OpenBSD, Netbsd, etc. Isso aconteceu no final dos anos 80, início dos 90. mas eu acho que já devia estar acontecendo discussões nesse sentido, assim como algumas visitas de advogados. Sabemos como a história termina (e graças a ela que houve uma janela de falta de sistema operacional livre que permitiu o surgimento do Linux).
Eu sabia que Stallman atuou diretamente na padronização POSIX, mas não sabia que tinha colaborado com os BSDs. A colaboração pode até ter sido pela criação do GCC, que permitiu em muito a criação dos sistemas BSDs completamente livres da atualidade, ou mesmo pela POSIX, mas foi interessante saber quem ele participou disso.
E ele terminou dizendo que BSDs atualmente são software livre. Talvez depois da discussão com Theo de Raadt, criador do sistema OpenBSD, ele tenha repensado seus critérios sobre software livre e sistemas operacionais, uma vez que ele nunca tinha dito isso.
 Claro que não poderiam faltar as críticas ao Ubuntu. Mas ele falou algo que finalmente chegou ao ponto da questão: não existe nenhum outro sistema baseado em GNU/Linux com tantos usuários como o Ubuntu. Sim, isso mesmo. Stallman dirige suas críticas ao Ubuntu por conta de seu sucesso. Não, ele não é contra o sucesso de uma distribuição de Linux (ou como ele gosta de dizer, GNU/Linux). O problema pela visão dele é que o Ubuntu pode e está influenciando uma grande parcela de usuários e, principalmente novos usuários, sobre software livre. Se não for passada a mensagem certa, esses usuários não entenderão a fundo o que é software livre pela visão de Stallman, onde liberdade deve vir antes de facilidade de uso. Quem busca liberdade, tem de estar preparado para sofrer (palavras dele).
Claro que não poderiam faltar as críticas ao Ubuntu. Mas ele falou algo que finalmente chegou ao ponto da questão: não existe nenhum outro sistema baseado em GNU/Linux com tantos usuários como o Ubuntu. Sim, isso mesmo. Stallman dirige suas críticas ao Ubuntu por conta de seu sucesso. Não, ele não é contra o sucesso de uma distribuição de Linux (ou como ele gosta de dizer, GNU/Linux). O problema pela visão dele é que o Ubuntu pode e está influenciando uma grande parcela de usuários e, principalmente novos usuários, sobre software livre. Se não for passada a mensagem certa, esses usuários não entenderão a fundo o que é software livre pela visão de Stallman, onde liberdade deve vir antes de facilidade de uso. Quem busca liberdade, tem de estar preparado para sofrer (palavras dele).
Stallman é muito hábil nesse sentido. Ele não defende nenhuma distro, assim como não recomenda nenhuma especificamente. Deixa cada um usar a que melhor lhe servir, mas pede para que se lembre que o importante é a liberdade, de poder usar como quiser. E que uma distro de software livre deve permitir copiar, modificar, redistribuir e não criar restrições quanto seu uso. Sempre. Fora isso, nem prós, nem contras. Ele avisou que existem distros recomendadas pelas FSF e GNU, que garantem a liberdade irrestrita de seus usuários e que ele recomenda - distros em geral, não uma em específico -, mas que podem usar qualquer distro. Sem dramas, sem ataques, só assim, tranquilamente.
Como eu já havia dito antes e repito, não existe esse dilema. E assim também disse Stallman. Não importa licença: se respeitar as 4 liberdades é software livre. E pronto. E ele pediu carinhosamente para não se referir mais como open source, apenas como free software para lembrar a todos como a liberdade é importante. Um ponto interessante que ele comentou foi em relação à diferença entre o ponto de vista de free software em relação ao open source: free software se preocupa em sempre criar uma comunidade, enquanto open source não, apenas com o ponto de vista de melhoramento do software. Não sei se concordo muito com isso, pois vejo várias comunidades de open source, inclusive mesmo com a própria Microsoft. Perguntado sobre isso, ele apenas desconversou.
Ele recomendou o não uso de disco blu-ray, aqueles que parecem um DVD mas tem 50 GB de capacidade de armazenamento, pois os mesmo usam DRM (Digital Rights Management - Gerenciamento de direitos autorais digitais), o que significa que o disco não é seu, e que precisa de uma chave criptográfica para poder assistir seu conteúdo, chave essa que não existe em softwares livres.
Era basicamente o mesmo com o DVD, mas por descuido de uma empresa que foi à falência, essas chaves foram descobertas por um hacker e portadas como software livre.
Eu particularmente não sabia disso sobre os blu-rays, mesmo porque nem assisto blu-ray. Foi uma geração de tecnologia de armazenamento que eu simplesmente pulei. Exceto no meu PS3.
Como o assunto enveredou por DRM, chegamos ao ponto da discussão sobre Amazon e Netflix, onde todo software deles tem um componente de DRM. Esse DRM permite que Amazon remova livros de seu HD sem ao menos pedir consentimento do usuário, violando claramente as 4 liberdades de software. E usou como exemplo o livro 1984 de George Orwell, que apesar de estar em domínio público, foi removido de todos os dispositivos Kindle devida a uma infração de copyright alegada por uma editora.
Netfllix apareceu na mesma categoria por não permitir baixar seus filmes para assistir posteriormente, controlando o comportamento do usuário.
Falando de filmes e conteúdo multimídia, no fim chegamos ao tema da pirataria. Segundo Stallman pirataria não existe pois nenhum bem é saqueado de ninguém, ninguém perde dinheiro com cópia. Então o que se convencionou chamar como pirataria não existe. Existe a cópia digital de conteúdo, que nunca traz danos ao seu dono, pois nada é roubado ou extraído. Só copiado. Ele ainda pediu para evitar o termo "pirataria" e usar o termo "cópia digital".
A parte de vigilância pela Internet tomou boa parte da palestra de 2 horas. Segundo Stallman temos de tentar ao máximo fugir do vigilantismo que ocorre atualmente. Infelizmente a fórmula recomendada por ele não parece lá muito fácil de seguir:
Então a idéia central não é não usar redes sociais, mas usar para compartilhar conhecimento, não informações pessoais. O restante pede um tipo de vida mais frugal. Muito mais.
Stallman falou sobre negócios na área de software livre, para minha surpresa. Claro que a proposta de monetização segundo ele, não soa como algo que funcione na vida real. Disse que os sites podem sim monetizar com propaganda, mas a propaganda tem de garantir a liberdade do usuário, não fazendo nenhum tipo de "tracking". Então o projeto GNU está preparando um framework de monetização onde todos doarão dinheiro pra plataforma e, conforme acessarmos os sites participantes, esses serão remunerados pela audiência. Isso me fez lembrar um pouco do ECAD. E não vi muito um modelo claro de negócio que sustente software livre dessa maneira, mas ao menos o assunto está em pauta por lá.
Também tem o fato da própria FSF estar lançando uma campanha para conseguir novos membros, pra poder pagar por sua estrutura. Com esse tipo de problema de arrecadação financeira, não vejo um desenrolar muito brilhante num modelo de negócios que eles venham a gerir. Mas cabe a cada um decidir experimentar e participar. Ou não.
Não, ele não falou nada disso. Aliás usou o logo do Linux com pinguim preto, não o azul. Não sei quem começou a propagar essa distorção, mas Linux não tem código proprietário. Só sincronizar os fontes com o repositório git e verificar.
Foi uma palestra interessante com uma abordagem bem diferente da que estou acostumado a assistir. Apesar de mostrar bastante moderação e comedimento em suas palavras, quando chegamos no tema de vigilantismo só faltou mesmo o Stallman colocar um chapéu de papel alumínio. Ele é até coerente em suas palavras, dizendo pra não usar nenhum tipo de cartão de crédito, e só pagar em dinheiro, pois todos podem e estão sendo monitorados em suas ações. Pura verdade. Mas é difícil abrir mão dessas facilidades. E muito.
Ao final de sua palestra, não vi muitos ouvintes comovidos por suas palavras. O que ouvi foi um seco "é... foi legal", mas ninguém se empolgou em seguir totalmente o que Stallman falou. Nem sobre vigilantismo, nem sobre software livre, já que muitas pessoas usam MacOSX para trabalhar por aqui. E muitos usam Ubuntu também. Talvez por isso o auditório não tenha ficado cheio, mostrando vários assentos disponíveis durante a palestra.
Mas pelo fato de ter ouvido ele dizer que BSD é software livre e que não existe open source, só software livre, pra mim isso já valeu a palestra inteira.
Ele comentou que software livre constrói também comunidades que se baseiam no respeito e, se sua comunidade tem conflito, para evitá-la ou trocar por uma com o verdadeiro espírito do software livre, de ajuda e positivismo. Mas esse ponto da palestra dele eu deixo pra comentar em outra oportunidade.
Depois da chamada para ajuda à FSF na BR-Linux, Projeto GNU precisa da nossa contribuição – e não de brigas internas na comunidade, resolvi me associar a ela para ajudar. Afinal nada mais prazeroso que escrever meus artigos como um membro da FSF.
E um recado que nunca pode ser esquecido: free software é software livre, não gratuito.
Também fiz uma contribuição à FreeBSD Foundation, só pra manter o equilíbrio do universo. Ao menos do universo de software livre.
Page 16 of 36
