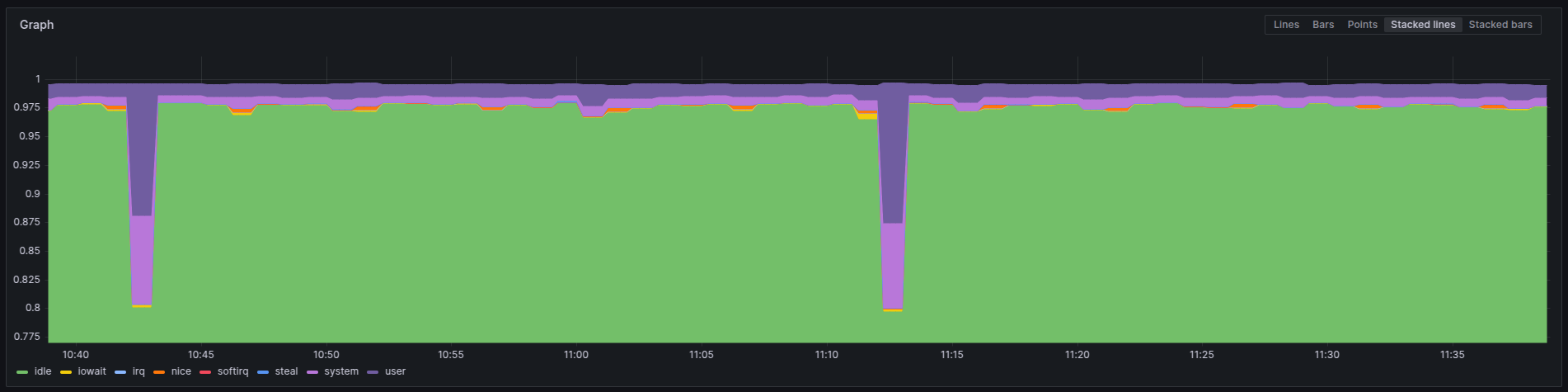
Estou inaugurando uma categoria nova, observability, ou... observabilidade na língua pátria. Nunca comentei nada por aqui, mas nos últimos anos em que trabalhei na Ericsson, o fiz dentro do time que mantinha o Prometheus. Prometheus é um conhecido sistema de monitoração dentro de clusters Kubernetes, ou k8s pros já iniciados.
Não era um trabalho glorioso que contribuia pro projeto. Não diretamente. Era mais sobre compilar a partir dos fontes com o sistema oficial da empresa, que era Suse (e talvez ainda seja) e passar por alguns testes em cima dos helm charts que construíamos. Além de algumas verificações de segurança.
Segurança aliás foi uma das poucas coisas que contribuí pro projeto open source. Reportei algumas vulnerabilidades encontradas pelos nossos scanners em alguns pacotes usados. Geralmente em javascript/npm.
O tempo passou, fui demitido, e acabei em outro emprego.
No emprego atual não existe tanta demanda assim por k8s. Até tem alguma coisa, mas o negócio mesmo gira em torno de VMs com Linux. Então nada de Prometheus pra esses casos. Mas existem alternativas. Uma delas é usar um programa "agente" rodando nessas VMs e enviar pra um "Prometheus" os dados ao invés de esperar que um Prometheus real busque o dado, como é o caso dentro de um cluster k8s.
Pra isso instalei o mimir do Grafana. Mimir, aquele deus que cortam a cabeça e Odin a preserva pra ouvir seus conselhos, funciona como um remote write de Prometheus. Em linguagem mais simples, é onde os dados ficam guardados. Um DB dos dados coletados. E é possível fazer o Grafana, aquele dos dashboards, ler esses dados dele.
Eu segui os passos de instalação em VM ao invés de usar k8s pro mimir.
É mais fácil pra gerenciar o espaço em disco e aumentar se necessário.
E também no cloud provider que usamos, custa mais barato assim.
A configuração que fiz é assim em /etc/grafana/mimir.yaml:
multitenancy_enabled: false
no_auth_tenant: <token>
blocks_storage:
backend: filesystem
bucket_store:
sync_dir: /var/mimir/tsdb-sync
filesystem:
dir: /var/mimir/data/tsdb
tsdb:
dir: /var/mimir/tsdb
compactor:
data_dir: /var/mimir/compactor
sharding_ring:
kvstore:
store: memberlist
distributor:
ring:
instance_addr: 127.0.0.1
kvstore:
store: memberlist
ingester:
ring:
instance_addr: 127.0.0.1
kvstore:
store: memberlist
replication_factor: 1
ruler_storage:
backend: filesystem
filesystem:
dir: /var/mimir/rules
server:
http_listen_address: localhost
http_listen_port: 9009
log_level: warn
grpc_server_max_recv_msg_size: 2147483647
grpc_server_max_send_msg_size: 2147483647
store_gateway:
sharding_ring:
replication_factor: 1
usage_stats:
enabled: true
limits:
ingestion_burst_size: 3500000
ingestion_rate: 100000
max_global_series_per_user: 100000000
max_label_names_per_series: 50
max_query_parallelism: 224
out_of_order_time_window: "5m"
Essa é a maneira mais simples possível. O token é que será usado em todo lugar pra validar as conexões. De grafana aos cliente alloy. E usando nginx pra gerenciar os certificados SSL e conectar a port 443 com a interna 9009, onde roda o mimir.
Falando dos clientes, esses eu instalei primeiro o grafana-agent, que faz a mesma coisa. Mas a página de configuração já avisava que estava defasado e que era pra migrar pro alloy. Então resolvi fazer isso logo ao invés de esperar parar de funcionar.
A primeira configuração que fiz pro grafana-agent em /etc/grafana-agent.yaml era a seguinte:
server:
log_level: info
metrics:
global:
scrape_interval: 1m
wal_directory: '/var/lib/grafana-agent'
configs:
# Example Prometheus scrape configuration to scrape the agent itself for metrics.
# This is not needed if the agent integration is enabled.
- name: agent
host_filter: false
scrape_configs:
- job_name: agent
static_configs:
- targets: ['localhost:9090']
relabel_configs:
- source_labels: [__address__]
replacement: <nome do servidor>
target_label: instance
action: replace
remote_write:
- url: https://<endereço do mimir>/api/v1/push
headers:
X-Scope-OrgID: <token>
integrations:
agent:
enabled: true
node_exporter:
enabled: true
include_exporter_metrics: true
disable_collectors:
- "mdadm"
É possível ver que dentro de remote_write eu coloco o endereço do mimir em url com REQUEST_URI apontando pra /api/v1/push e que adiciono um header X-Scope-OrgID com o mesmo token pra validar.
E isso funcionava.
Mas tive de mudar pro alloy. E a configuração, que usa uma sintaxe própria (e bastante bizarra), é a seguinte:
root@heliotest1:~# cat /etc/alloy/config.alloy
prometheus.exporter.unix "company" {
enable_collectors = ["cpu", "disk", "filesystem", "systemd"]
cpu {
guest = true
info = true
}
disk { }
filesystem {
mount_timeout = "3s"
}
systemd {
enable_restarts = true
start_time = true
}
}
prometheus.remote_write "production" {
endpoint {
url = "http://<endereço do mimir>/api/v1/push"
headers = {
"X-Scope-OrgID" = "<token>",
}
queue_config { }
metadata_config { }
}
}
// Collect metrics from Kubernetes pods and send them to prod.
prometheus.scrape "first" {
targets = prometheus.exporter.unix.company.targets
forward_to = [prometheus.remote_write.production.receiver]
}
Eu copiei alguns valores do manual de configuração, como o que é visto em filesystem.
Efetivamente não vi se faz muita diferença isso ou não.
Feito isso, os agentes alloy começam a enviar os dados pro mimir.
Na configuração do mimir é possível ver que eu aumentei alguns parâmetros pra aguentar a quantidade de dados recebidos como grpc_server_max_recv_msg_size/grpc_server_max_send_msg_size.
O passo final é adicionar essa origem no grafana pra gerar as dashboards. A origem tem de escolher como se fosse um prometheus.
Em seguida a configuração.
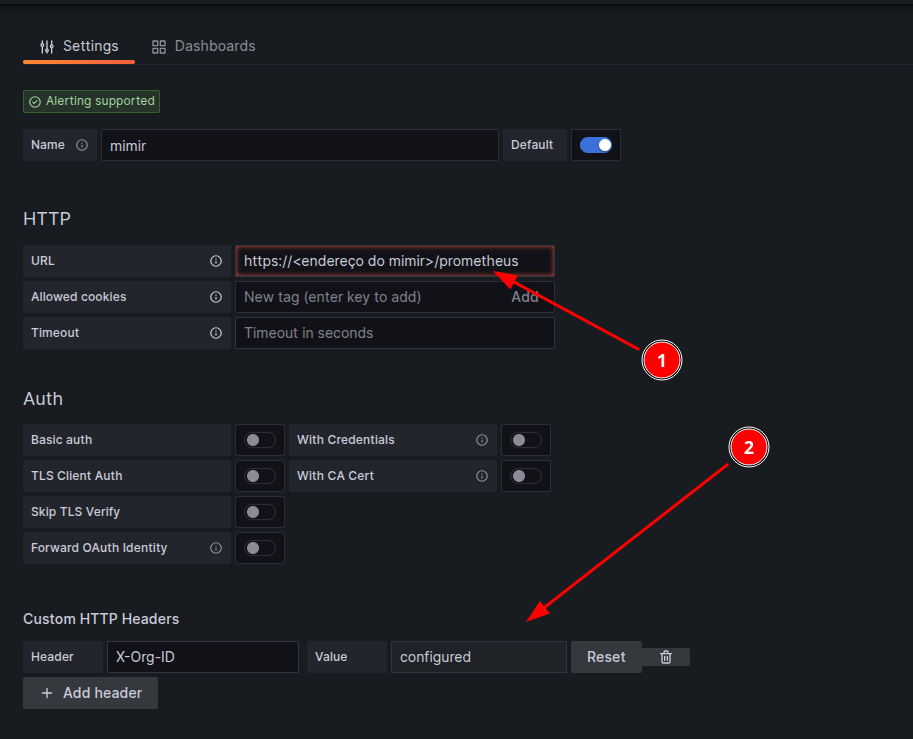
Note que o endereço do mimir [1] passa a usar a REQUEST_URI /prometheus e que o é preciso adicionar um campo de header X-Org-ID [2] onde estará o valor do token configurado no mimir. Feito isso, basta usar o mimir como se fosse um Prometheus e gerar seus dashboards.
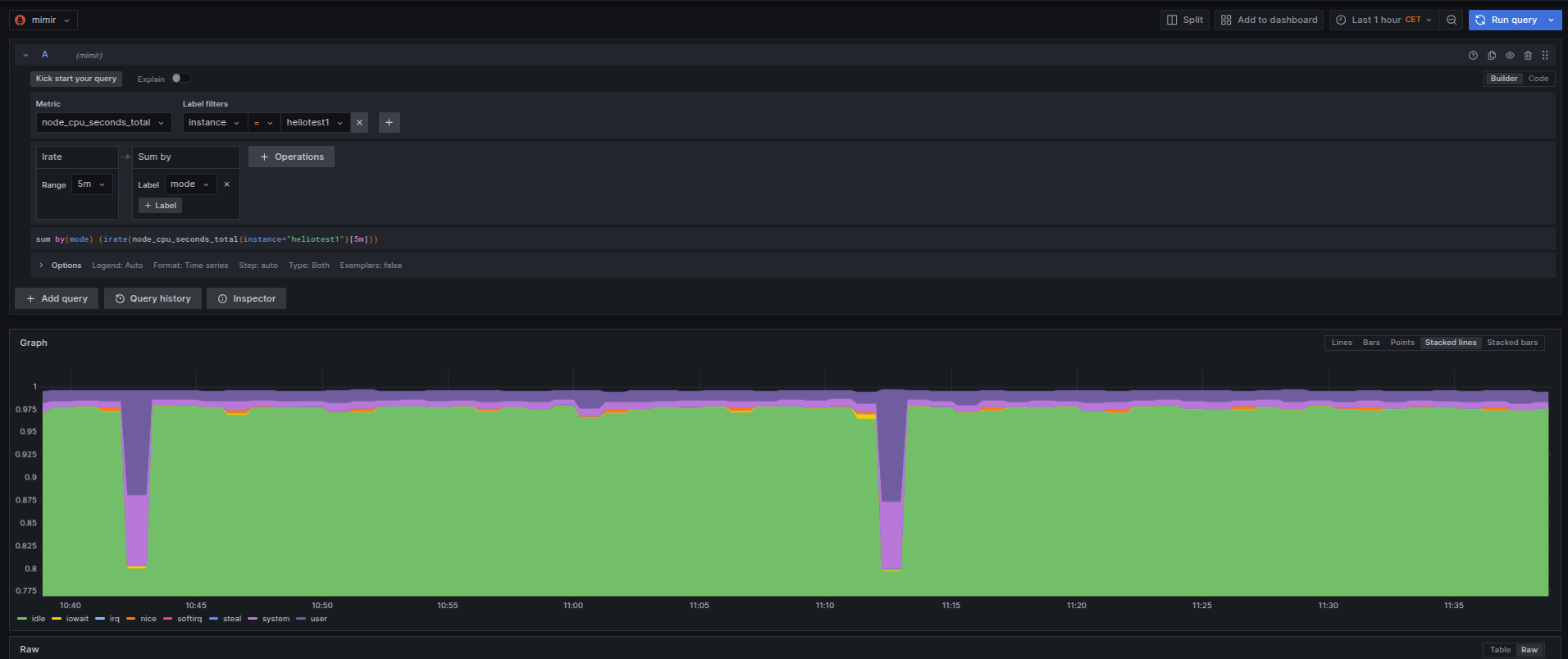
Boa diversão!
