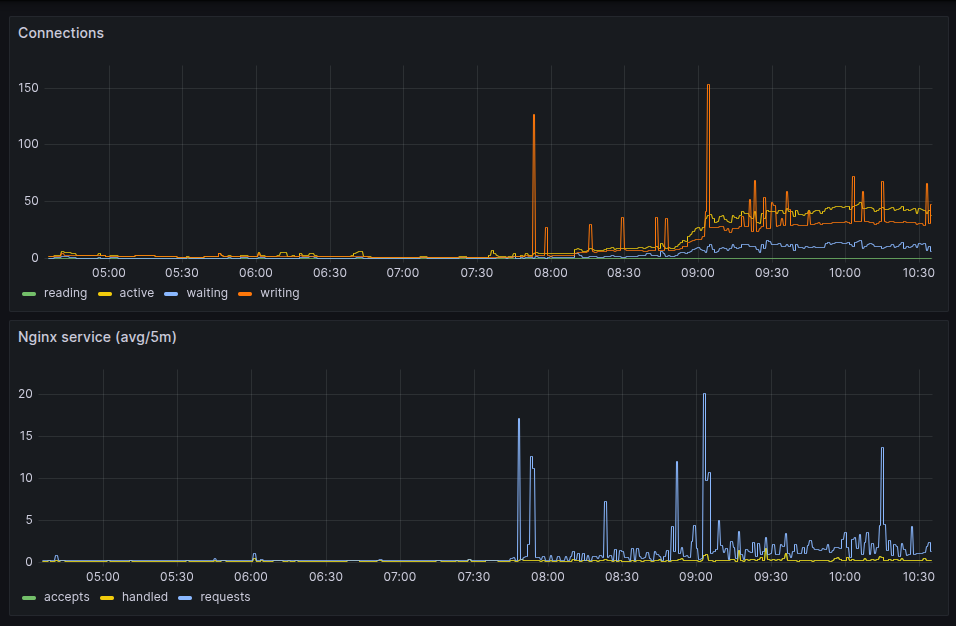
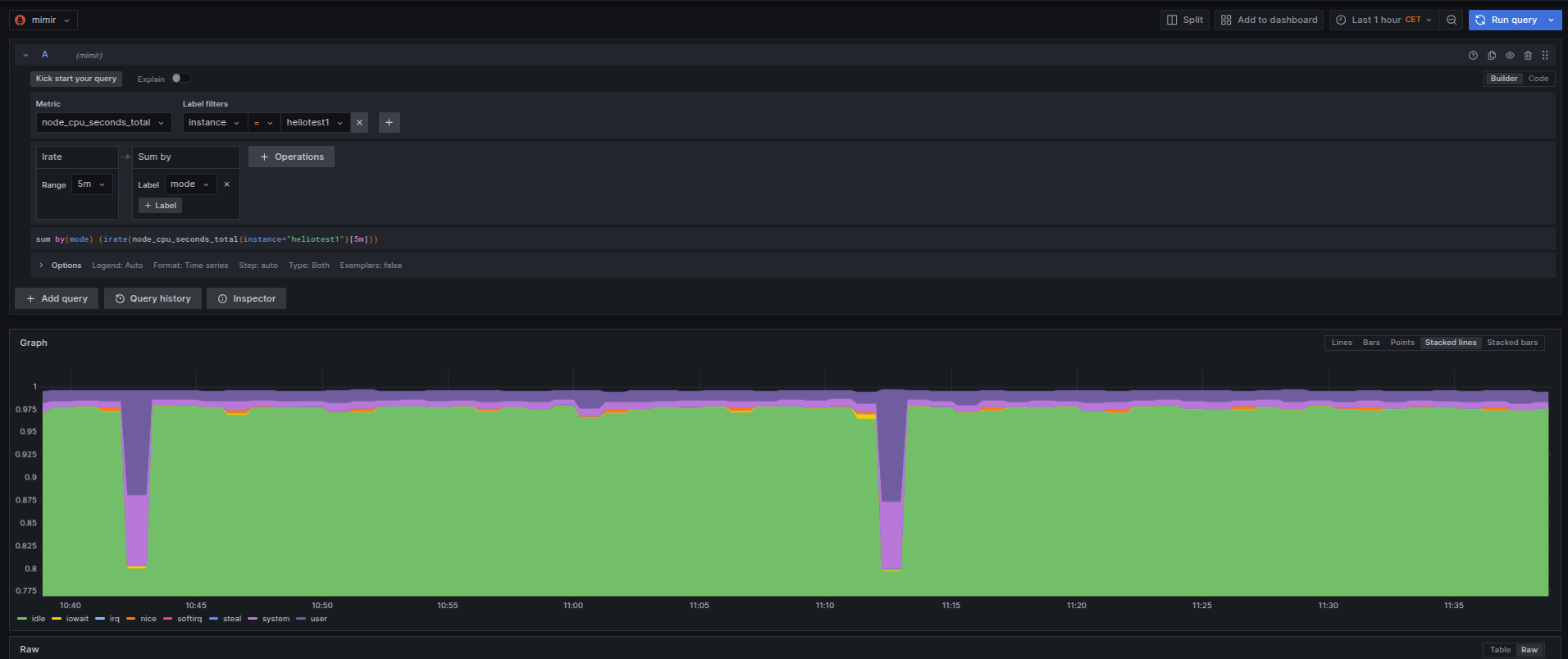
Seguindo o artigo expondo as métricas do nginx pro prometheus, aqui está o resultado olhado no grafana.
Como os valores
server_accepts_total,
server_handled_total e
server_requests_total
são do tipo counter,
eu usei um irate(__variável__[5m])
pra mostrar no gráfico da forma acima.
E como coletei esses dados? Eu já tinha comentado no artigo configurando o grafana alloy pra monitorar VMs que uso o alloy. Então foi adicionando uma entrada extra nele.
[...]
discovery.relabel "metrics_agent" {
targets = array.concat(
[{
__address__ = "localhost:9090",
}],
)
rule {
source_labels = ["__address__"]
target_label = "instance"
}
}
[...]
prometheus.scrape "nginx_metrics" {
targets = discovery.relabel.metrics_agent.output
forward_to = [prometheus.remote_write.prod.receiver]
}
Agora fica mais fácil entender o que acontece com as páginas servidas e se tem realmente alguma lentidão.
Estou inaugurando uma categoria nova, observability, ou... observabilidade na língua pátria. Nunca comentei nada por aqui, mas nos últimos anos em que trabalhei na Ericsson, o fiz dentro do time que mantinha o Prometheus. Prometheus é um conhecido sistema de monitoração dentro de clusters Kubernetes, ou k8s pros já iniciados.
Não era um trabalho glorioso que contribuia pro projeto. Não diretamente. Era mais sobre compilar a partir dos fontes com o sistema oficial da empresa, que era Suse (e talvez ainda seja) e passar por alguns testes em cima dos helm charts que construíamos. Além de algumas verificações de segurança.
Segurança aliás foi uma das poucas coisas que contribuí pro projeto open source. Reportei algumas vulnerabilidades encontradas pelos nossos scanners em alguns pacotes usados. Geralmente em javascript/npm.
O tempo passou, fui demitido, e acabei em outro emprego.
No emprego atual não existe tanta demanda assim por k8s. Até tem alguma coisa, mas o negócio mesmo gira em torno de VMs com Linux. Então nada de Prometheus pra esses casos. Mas existem alternativas. Uma delas é usar um programa "agente" rodando nessas VMs e enviar pra um "Prometheus" os dados ao invés de esperar que um Prometheus real busque o dado, como é o caso dentro de um cluster k8s.
Pra isso instalei o mimir do Grafana. Mimir, aquele deus que cortam a cabeça e Odin a preserva pra ouvir seus conselhos, funciona como um remote write de Prometheus. Em linguagem mais simples, é onde os dados ficam guardados. Um DB dos dados coletados. E é possível fazer o Grafana, aquele dos dashboards, ler esses dados dele.
Eu segui os passos de instalação em VM ao invés de usar k8s pro mimir.
É mais fácil pra gerenciar o espaço em disco e aumentar se necessário.
E também no cloud provider que usamos, custa mais barato assim.
A configuração que fiz é assim em /etc/grafana/mimir.yaml:
multitenancy_enabled: false
no_auth_tenant: <token>
blocks_storage:
backend: filesystem
bucket_store:
sync_dir: /var/mimir/tsdb-sync
filesystem:
dir: /var/mimir/data/tsdb
tsdb:
dir: /var/mimir/tsdb
compactor:
data_dir: /var/mimir/compactor
sharding_ring:
kvstore:
store: memberlist
distributor:
ring:
instance_addr: 127.0.0.1
kvstore:
store: memberlist
ingester:
ring:
instance_addr: 127.0.0.1
kvstore:
store: memberlist
replication_factor: 1
ruler_storage:
backend: filesystem
filesystem:
dir: /var/mimir/rules
server:
http_listen_address: localhost
http_listen_port: 9009
log_level: warn
grpc_server_max_recv_msg_size: 2147483647
grpc_server_max_send_msg_size: 2147483647
store_gateway:
sharding_ring:
replication_factor: 1
usage_stats:
enabled: true
limits:
ingestion_burst_size: 3500000
ingestion_rate: 100000
max_global_series_per_user: 100000000
max_label_names_per_series: 50
max_query_parallelism: 224
out_of_order_time_window: "5m"
Essa é a maneira mais simples possível. O token é que será usado em todo lugar pra validar as conexões. De grafana aos cliente alloy. E usando nginx pra gerenciar os certificados SSL e conectar a port 443 com a interna 9009, onde roda o mimir.
Falando dos clientes, esses eu instalei primeiro o grafana-agent, que faz a mesma coisa. Mas a página de configuração já avisava que estava defasado e que era pra migrar pro alloy. Então resolvi fazer isso logo ao invés de esperar parar de funcionar.
A primeira configuração que fiz pro grafana-agent em /etc/grafana-agent.yaml era a seguinte:
server:
log_level: info
metrics:
global:
scrape_interval: 1m
wal_directory: '/var/lib/grafana-agent'
configs:
# Example Prometheus scrape configuration to scrape the agent itself for metrics.
# This is not needed if the agent integration is enabled.
- name: agent
host_filter: false
scrape_configs:
- job_name: agent
static_configs:
- targets: ['localhost:9090']
relabel_configs:
- source_labels: [__address__]
replacement: <nome do servidor>
target_label: instance
action: replace
remote_write:
- url: https://<endereço do mimir>/api/v1/push
headers:
X-Scope-OrgID: <token>
integrations:
agent:
enabled: true
node_exporter:
enabled: true
include_exporter_metrics: true
disable_collectors:
- "mdadm"
É possível ver que dentro de remote_write eu coloco o endereço do mimir em url com REQUEST_URI apontando pra /api/v1/push e que adiciono um header X-Scope-OrgID com o mesmo token pra validar.
E isso funcionava.
Mas tive de mudar pro alloy. E a configuração, que usa uma sintaxe própria (e bastante bizarra), é a seguinte:
root@heliotest1:~# cat /etc/alloy/config.alloy
prometheus.exporter.unix "company" {
enable_collectors = ["cpu", "disk", "filesystem", "systemd"]
cpu {
guest = true
info = true
}
disk { }
filesystem {
mount_timeout = "3s"
}
systemd {
enable_restarts = true
start_time = true
}
}
prometheus.remote_write "production" {
endpoint {
url = "http://<endereço do mimir>/api/v1/push"
headers = {
"X-Scope-OrgID" = "<token>",
}
queue_config { }
metadata_config { }
}
}
// Collect metrics from Kubernetes pods and send them to prod.
prometheus.scrape "first" {
targets = prometheus.exporter.unix.company.targets
forward_to = [prometheus.remote_write.production.receiver]
}
Eu copiei alguns valores do manual de configuração, como o que é visto em filesystem.
Efetivamente não vi se faz muita diferença isso ou não.
Feito isso, os agentes alloy começam a enviar os dados pro mimir.
Na configuração do mimir é possível ver que eu aumentei alguns parâmetros pra aguentar a quantidade de dados recebidos como grpc_server_max_recv_msg_size/grpc_server_max_send_msg_size.
O passo final é adicionar essa origem no grafana pra gerar as dashboards. A origem tem de escolher como se fosse um prometheus.
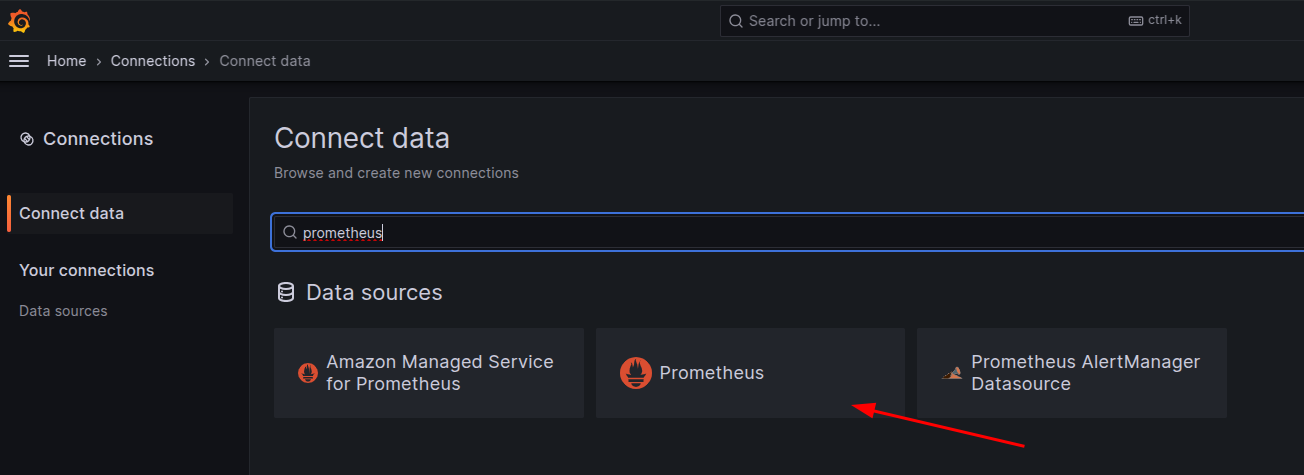
Em seguida a configuração.
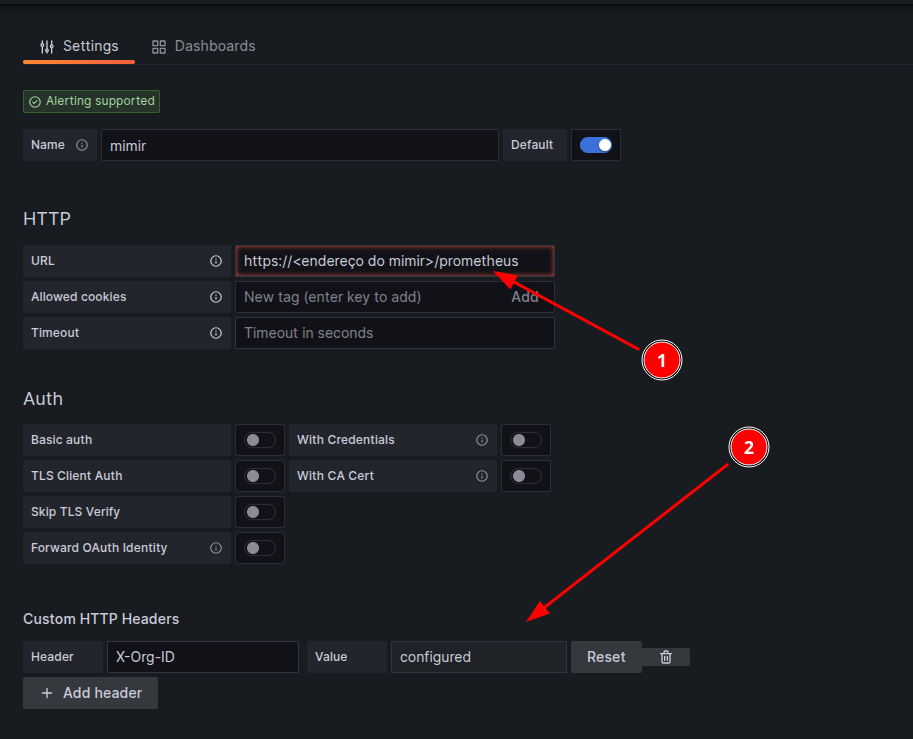
Note que o endereço do mimir [1] passa a usar a REQUEST_URI /prometheus e que o é preciso adicionar um campo de header X-Org-ID [2] onde estará o valor do token configurado no mimir. Feito isso, basta usar o mimir como se fosse um Prometheus e gerar seus dashboards.
Boa diversão!

Esses dias eu peguei um problema no servidor web, nginx. Não nele especificamente. Mas um usuário estava reclamando que estava super lento pra carregar as páginas.
A questão então é como ver como e quanto está o nginx. Infelizmente a versão open source não fornece muita coisa. Só uma versão texto de estatísticas.
Não é grande coisa mas pelo menos já é ALGUMA COISA.
Agora como monitorar isso no Grafana?
A resposta são open metrics. E isso não tem.
Não tinha.
Fiz um programa em Go que converte essas estatísticas em open metrics e expõe na porta 9090 no endpoint /metrics.
Pra ter isso funcionando, é preciso primeiro subir a configuração de estatísticas no nginx.
server {
listen 127.0.0.1:8080;
location /api {
stub_status;
allow 127.0.0.1;
deny all;
}
}
Eu salvei no arquivo statistics.conf e coloquei em /etc/nginx/conf.d.
E bastou um reload pra ter funcionado.
❯ curl localhost:8080/api
Active connections: 2
server accepts handled requests
21 21 322
Reading: 0 Writing: 1 Waiting: 1
Agora é rodar o programa e apontar pra esse endpoint.
❯ ./nginx-openmetrics/nginx-openmetrics --service=http://localhost:8080/api
[2025-08-22T14:11:45] (INFO): 🚚 fetching data from:http://localhost:8080/api
[2025-08-22T14:11:45] (INFO): 🎬 starting service at port:9090
E a porta fica exposta pras métricas serem coletadas pelo prometheus ou grafana alloy. Ou qualquer outro programa que faça scrape de dados no padrão open metrics.
❯ curl localhost:9090/metrics
# HELP active_connections The number of active connections
# TYPE active_connections gauge
active_connections 1
# HELP reading_connections The number of active reading connections
# TYPE reading_connections gauge
reading_connections 0
# HELP server_accepts_total The total number of server accepted connections
# TYPE server_accepts_total counter
server_accepts_total 22
# HELP server_handled_total The total number of server handled connections
# TYPE server_handled_total counter
server_handled_total 22
# HELP server_requests_total The total number of server requests
# TYPE server_requests_total counter
server_requests_total 333
# HELP waiting_connections The number of waiting connections
# TYPE waiting_connections gauge
waiting_connections 0
# HELP writing_connections The number of active writing connections
# TYPE writing_connections gauge
writing_connections 1
E fica exposto em todas as interfaces.
❯ netstat -nat | grep 9090 | grep -i listen
tcp6 0 0 :::9090 :::* LISTEN
O programa faz o update dos dados a cada 15 segundos. Pra não sobrecarregar.
E ainda falta dar uma melhorada com a entrada como serviço do systemd. Devo fazer isso hoje.
Próximo passo será gerar um pacote debian dele pra instalar fácil.
Update: Fri Aug 22 04:23:45 PM CEST 2025
Tá lá o arquivo pro systemd.
E está funcionando no sistema que estou testando.
root@server:/# systemctl status nginx-openmetrics.service
● nginx-openmetrics.service - nginx open metrics service
Loaded: loaded (/etc/systemd/system/nginx-openmetrics.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2025-08-22 14:08:17 UTC; 16min ago
Main PID: 314061 (nginx-openmetri)
Tasks: 7 (limit: 19076)
Memory: 4.0M
CPU: 47ms
CGroup: /system.slice/nginx-openmetrics.service
└─314061 /usr/sbin/nginx-openmetrics --service=http://localhost:8080/api
Aug 22 14:08:17 internal systemd[1]: Started nginx open metrics service.
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78433] (INFO): nginx-open-metrics-service (1.0-9)
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78441] (INFO): 🚚 fetching data from:http://localhost:8080/api
Aug 22 14:08:17 internal nginx-openmetrics[314061]: [2025-08-22T14:08:17.78442] (INFO): 🎬 starting service at port:9090

Eu descrevi o uso do sensor temper com raspberrypi no artigo
monitorando a temperatura da sala dos servidores.
O que eu não contei ali foi que eu passei a monitorar outros parâmetros mostrado pelo programa sensor.
O sensor faz parte do pacote lm-sensor no Ubuntu.
Rodando o programa com parâmetro -j mostra a saída em format JSON.
❯ sensors -j
{
"coretemp-isa-0000":{
"Adapter": "ISA adapter",
"Package id 0":{
"temp1_input": 61.000,
"temp1_max": 100.000,
"temp1_crit": 100.000,
"temp1_crit_alarm": 0.000
},
"Core 0":{
"temp2_input": 52.000,
"temp2_max": 100.000,
"temp2_crit": 100.000,
"temp2_crit_alarm": 0.000
},
"Core 4":{
"temp6_input": 54.000,
"temp6_max": 100.000,
"temp6_crit": 100.000,
"temp6_crit_alarm": 0.000
},
"Core 8":{
"temp10_input": 61.000,
"temp10_max": 100.000,
"temp10_crit": 100.000,
"temp10_crit_alarm": 0.000
},
"Core 9":{
"temp11_input": 61.000,
"temp11_max": 100.000,
"temp11_crit": 100.000,
"temp11_crit_alarm": 0.000
},
"Core 10":{
"temp12_input": 61.000,
"temp12_max": 100.000,
"temp12_crit": 100.000,
"temp12_crit_alarm": 0.000
},
"Core 11":{
"temp13_input": 61.000,
"temp13_max": 100.000,
"temp13_crit": 100.000,
"temp13_crit_alarm": 0.000
},
"Core 12":{
"temp14_input": 59.000,
"temp14_max": 100.000,
"temp14_crit": 100.000,
"temp14_crit_alarm": 0.000
},
"Core 13":{
"temp15_input": 59.000,
"temp15_max": 100.000,
"temp15_crit": 100.000,
"temp15_crit_alarm": 0.000
},
"Core 14":{
"temp16_input": 59.000,
"temp16_max": 100.000,
"temp16_crit": 100.000,
"temp16_crit_alarm": 0.000
},
"Core 15":{
"temp17_input": 60.000,
"temp17_max": 100.000,
"temp17_crit": 100.000,
"temp17_crit_alarm": 0.000
}
},
"thinkpad-isa-0000":{
"Adapter": "ISA adapter",
"fan1":{
"fan1_input": 2191.000
},
"CPU":{
"temp1_input": 59.000
},
"GPU":{
ERROR: Can't get value of subfeature temp2_input: Can't read
},
"temp3":{
"temp3_input": 59.000
},
"temp4":{
"temp4_input": 0.000
},
"temp5":{
"temp5_input": 59.000
},
"temp6":{
"temp6_input": 59.000
},
"temp7":{
"temp7_input": 59.000
},
"temp8":{
ERROR: Can't get value of subfeature temp8_input: Can't read
}
},
"ucsi_source_psy_USBC000:001-isa-0000":{
"Adapter": "ISA adapter",
"in0":{
"in0_input": 0.000,
"in0_min": 0.000,
"in0_max": 0.000
},
"curr1":{
"curr1_input": 0.000,
"curr1_max": 0.000
}
},
"BAT0-acpi-0":{
"Adapter": "ACPI interface",
"in0":{
"in0_input": 12.909
},
"power1":{
"power1_input": 0.000
}
},
"iwlwifi_1-virtual-0":{
"Adapter": "Virtual device",
"temp1":{
"temp1_input": 42.000
}
},
"ucsi_source_psy_USBC000:002-isa-0000":{
"Adapter": "ISA adapter",
"in0":{
"in0_input": 0.000,
"in0_min": 0.000,
"in0_max": 0.000
},
"curr1":{
"curr1_input": 3.000,
"curr1_max": 0.000
}
},
"nvme-pci-0200":{
"Adapter": "PCI adapter",
"Composite":{
"temp1_input": 44.850,
"temp1_max": 85.850,
"temp1_min": -273.150,
"temp1_crit": 86.850,
"temp1_alarm": 0.000
},
"Sensor 1":{
"temp2_input": 47.850,
"temp2_max": 65261.850,
"temp2_min": -273.150
},
"Sensor 2":{
"temp3_input": 44.850,
"temp3_max": 65261.850,
"temp3_min": -273.150
}
},
"acpitz-acpi-0":{
"Adapter": "ACPI interface",
"temp1":{
"temp1_input": 59.000
}
}
}
Essa saída de comando é do laptop de trabalho, onde estou escrevendo esse artigo.
É possível ver que aparecem alguns erros como ERROR: Can't get value of subfeature temp2_input: Can't read
e que alguns dados não tem valor como em { "coretemp-isa-0000":{ "Adapter": "ISA adapter" } }.
Quando fiz pro servidor, eu acabei meio que escrevendo o código na mão.
sensors = shellExec("/usr/bin/sensors -j")
logger.debug(f"sensors: {sensors}")
jResp = json.loads(sensors)
resp = list()
resp.append("#HELP server_board_temperature_celsius the server board current temperatures")
resp.append("#TYPE server_board_temperature_celsius gauge")
device_1 = "nvme-pci-2b00"
device_2 = "k10temp-pci-00c3"
composite = jResp[device_1]["Composite"]["temp1_input"]
logger.info(f"device: {device_1}, composite, temperature: {composite}")
resp.append("server_board_temperature_celsius{device=\"" + device_1 + "\",sensor=\"composite\"} " + "%0.2f" % composite )
sensor_1 = jResp[device_1]["Sensor 1"]["temp2_input"]
resp.append("server_board_temperature_celsius{device=\"" + device_1 + "\",sensor=\"sensor_1\"} " + "%0.2f" % sensor_1 )
sensor_2 = jResp[device_1]["Sensor 2"]["temp3_input"]
resp.append("server_board_temperature_celsius{device=\"" + device_1 + "\",sensor=\"sensor_2\"} " + "%0.2f" % sensor_2 )
tctl = jResp[device_2]["Tctl"]["temp1_input"]
resp.append("server_board_temperature_celsius{device=\"" + device_2 + "\",sensor=\"tctl\"} " + "%0.2f" % tctl )
tccd3 = jResp[device_2]["Tccd3"]["temp5_input"]
resp.append("server_board_temperature_celsius{device=\"" + device_2 + "\",sensor=\"tccd3\"} " + "%0.2f" % tccd3 )
tccd5 = jResp[device_2]["Tccd5"]["temp7_input"]
resp.append("server_board_temperature_celsius{device=\"" + device_2 + "\",sensor=\"tccd5\"} " + "%0.2f" % tccd5 )
resp.append("")
Então essa semana eu gastei um tempo pra fazer um script mais genérico.
Aparecem agora todos os dados que saem com valor no comando sensor -j, mas em contrapartida não sei exatamente o que são.
Sem mais delongas, aqui o código:
#! /usr/bin/env -S uv run --script
#
# /// script
# dependencies = [
# "uvicorn",
# "fastapi"
# ]
# ///
import argparse
import sys
import subprocess
import logging
import json
import re
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse
import uvicorn
DEFAULTS = {"port": 9090, "path": "/metrics"}
__version__ = "0.1.0"
logger = logging.getLogger(__file__)
consoleOutputHandler = logging.StreamHandler()
formatter = logging.Formatter(
fmt="[%(asctime)s] (%(levelname)s) %(message)s", datefmt="%Y-%m-%d %H:%M:%S"
)
consoleOutputHandler.setFormatter(formatter)
logger.addHandler(consoleOutputHandler)
logger.setLevel(logging.INFO)
def shellExec(command: str) -> str:
"run a command and return its output"
try:
# result = subprocess.getoutput(command, errors=subprocess.DEVNULL)
result = subprocess.check_output(
command, stderr=subprocess.DEVNULL, encoding="utf-8"
)
logger.debug(f"shellExec: {result}")
return result
except Exception as e:
logger.error(f"Error executing shell command '{command}': {e}")
return f"Error: {e}"
class SensorMetrics:
open_metrics: dict = {}
def generateMetrics(self) -> list:
self.dataReset()
sensors_output = shellExec(["sensors", "-j"])
logger.debug(f"sensors: {sensors_output}")
sensorsJSON = json.loads(sensors_output)
# sensorsJSON = {
# "thinkpad-isa-0000": {
# "Adapter": "ISA adapter",
# "fan1": {"fan1_input": 2786.000},
# "CPU": {"temp1_input": 69.000},
# "GPU": {},
# "temp3": {"temp3_input": 69.000},
# "temp4": {"temp4_input": 0.000},
# "temp5": {"temp5_input": 69.000},
# "temp6": {"temp6_input": 69.000},
# "temp7": {"temp7_input": 69.000},
# "temp8": {},
# }
# }
self.getOpenMetrics([], sensorsJSON)
return []
def dataReset(self):
self.open_metrics = {}
def getOpenMetrics(self, header: list, data_dict: dict):
if isinstance(data_dict, dict):
for k, v in data_dict.items():
logger.debug(f"k={k}, v={v}")
if isinstance(v, dict):
self.getOpenMetrics(header + [k], v)
else:
logger.debug(
f"Value is not dictionary: header={header}, k={k}, v={v}"
)
try:
v = float(v)
except ValueError:
logger.debug(f"invalid value: {v}")
continue
metric_head = self.generateMetricHeader(header, k)
metric_description = " ".join(header)
metric_description += f" {k}"
if metric_head in self.open_metrics:
logger.error(f"metric name '{metric_head}' already exists")
self.open_metrics[metric_head] = {
"value": v,
"description": metric_description,
}
logger.debug(
f"Adding: metric_head={metric_head}, value={v}, description='{metric_description}'"
)
else:
logger.debug(f"Not dictionary: header={header}, data_dict={data_dict}")
def generateMetricHeader(self, header: list, key: str) -> str:
metric_header = "_".join(header)
metric_header = re.sub(" ", "_", metric_header)
return f"{metric_header}_{key}"
if __name__ == "__main__":
parse = argparse.ArgumentParser(
description="Script to expose the sensors as open metrics"
)
parse.add_argument(
"--port", type=int, default=DEFAULTS["port"], help="Port to listen"
)
parse.add_argument(
"--path", default=DEFAULTS["path"], help="The path to serve the metrics"
)
parse.add_argument(
"--version",
action=argparse.BooleanOptionalAction,
help="Print version and exit",
)
parse.add_argument(
"--printout",
action=argparse.BooleanOptionalAction,
help="Print the exposed metrics found in the system",
)
parse.add_argument("--loglevel", default="info", help="Logging level")
args = parse.parse_args()
if args.loglevel != "info":
logger.setLevel(args.loglevel.upper())
if args.version is True:
print(sys.argv[0], __version__)
sys.exit(0)
if args.printout is True:
mts = SensorMetrics()
mts.generateMetrics()
for k, v in mts.open_metrics.items():
description = v["description"]
print(f"#HELP {k} {description}")
print(f"#TYPE {k} gauge")
print(f"{k}: {v['value']}")
sys.exit(0)
app = FastAPI()
@app.get(args.path, response_class=PlainTextResponse)
async def metrics():
logger.info(f"serving web page on {args.path}")
mts = SensorMetrics()
mts.generateMetrics()
resp = list()
for k, v in mts.open_metrics.items():
description = v["description"]
resp.append(f"#HELP {k} {description}")
resp.append(f"#TYPE {k} gauge")
resp.append(f"{k}: {v['value']}")
return "\n".join(resp)
logger.info(f"starting service on port {args.port}")
uvicorn.run(app, host="127.0.0.1", port=args.port)
O código pode ser encontrado aqui:
Como pode ser visto no cabeçalho:
#! /usr/bin/env -S uv run --script
#
# /// script
# dependencies = [
# "uvicorn",
# "fastapi"
# ]
# ///
abracei com força a dica do querido Riverfount, que mostrou que o uv podia fazer isso.
E passei a adotar o pacote logging ao invés de enviar prints pro terminal.
logger = logging.getLogger(__file__)
consoleOutputHandler = logging.StreamHandler()
formatter = logging.Formatter(
fmt="[%(asctime)s] (%(levelname)s) %(message)s", datefmt="%Y-%m-%d %H:%M:%S"
)
consoleOutputHandler.setFormatter(formatter)
logger.addHandler(consoleOutputHandler)
logger.setLevel(logging.INFO)
Eu sempre amarro esse singleton de logging, logger, com função do argparse pra poder modificar
o nível.
Começo sempre com info, mas usando o parâmetro --loglevel=debug eu mudo pro nível debug.
Torna prático e flexível pra gerenciar logs de funcionamento.
Além disso o logging usa STDERR pra enviar as mensagens.
Olhando agora pra parte de execução do script shell, onde sensors -j é chamado:
def shellExec(command: str) -> str:
"run a command and return its output"
try:
# result = subprocess.getoutput(command, errors=subprocess.DEVNULL)
result = subprocess.check_output(
command, stderr=subprocess.DEVNULL, encoding="utf-8"
)
logger.debug(f"shellExec: {result}")
return result
except Exception as e:
logger.error(f"Error executing shell command '{command}': {e}")
return f"Error: {e}"
Uso como função ao invés de método da classe. Acho que fica mais simples. E poder rodar script do shell dentro de uma classe não parece lá muito como uma propriedade da classe em si.
Notem que inicialmente eu tentei usar subprocess.getoutput( ).
O problema são aquelas mensagens de erros que eu comentei acima,
ERROR: Can't get value of subfeature temp2_input: Can't read,
que saem junto.
Isso quebra a chamada do json.loads( ).
Tentei usar o parâmetro errors=subprocess.DEVNULL, mas aparentemente o subprocess.getoutput( ) não herda isso.
Então não funciona.
O jeito foi usar subprocess.check_output( ).
A grande diferença é que o primeiro aceita string, então poderia usar simplemente "sensors -j" como argumento.
No subprocess.check_output( ), o parâmetro precisa ser uma lista.
Tem de ser passado como ["sensors", "-j"] que não é o fim do mundo, só um pouco mais chato.
A classe SensorMetrics está bem simples de entender no começo.
Acho que a única parte que precisa de um pouco mais de cuidado pra olhar é o método getOpenMetrics( ).
def getOpenMetrics(self, header: list, data_dict: dict):
if isinstance(data_dict, dict):
for k, v in data_dict.items():
logger.debug(f"k={k}, v={v}")
if isinstance(v, dict):
self.getOpenMetrics(header + [k], v)
else:
logger.debug(
f"Value is not dictionary: header={header}, k={k}, v={v}"
)
try:
v = float(v)
except ValueError:
logger.debug(f"invalid value: {v}")
continue
metric_head = self.generateMetricHeader(header, k)
metric_description = " ".join(header)
metric_description += f" {k}"
if metric_head in self.open_metrics:
logger.error(f"metric name '{metric_head}' already exists")
self.open_metrics[metric_head] = {
"value": v,
"description": metric_description,
}
logger.debug(
f"Adding: metric_head={metric_head}, value={v}, description='{metric_description}'"
)
else:
logger.debug(f"Not dictionary: header={header}, data_dict={data_dict}")
Esse é um método recursivo. Olhando pra uma estrutura como essa aqui:
{
"coretemp-isa-0000":{
"Package id 0":{
"temp1_input": 61.000,
"temp1_max": 100.000,
"temp1_crit": 100.000,
"temp1_crit_alarm": 0.000
}
}
}
O loop quebra o dicionário recebido em k, v, ou "key" e "value".
Na primeira vez que recebe, os dados ficam assim:
{"Package id 0":{"temp1_input": 61.000,"temp1_max": 100.000,"temp1_crit": 100.000,"temp1_crit_alarm": 0.000 }}
Então ele se chama de novo, mas passa no parâmetro header a primeira chave que encontrou: coretemp-isa-0000.
{"temp1_input": 61.000,"temp1_max": 100.000,"temp1_max": 100.000,"temp1_crit_alarm": 0.000 }
Como value ainda é um dictionário, testando com isinstance( ), então ele
adiciona a chave Package id 0 na lista de headers e roda mais uma vez:
Como é um for-loop, ele pega essas chaves e valores.
Daí como tem o histórico do que veio antes dentro de header, fica fácil montar a estrutura.
Basta juntar tudo com "_" como separador.
def generateMetricHeader(self, header: list, key: str) -> str:
metric_header = "_".join(header)
metric_header = re.sub(" ", "_", metric_header)
return f"{metric_header}_{key}"
E é isso que é feito no método generateMetricHeader( ).
Espero que agora tenha ficado um pouco mais claro o que foi que eu fiz nesse programa. E o porquê de não saber se o valor é temperatura em Celsius ou o que seja, uma vez que esse dado não existe na estrutura em JSON gerada. Ou se é tensão em Volts. Fica tudo no mesmo balaio.
Nota: a manpage do sensors descreve que toda temperatura é por padrão em °C pra temperatura.
E também descreve que eu deveria estar usando o parâmetro "-J", que sai no formato que preciso.
Isso fica pra versão 0.2.0 do script 😊.
Rodando simplemente pelo shell, temos a seguinte saída (que pode mudar de acordo com seu hardware):
❯ sensors
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +61.0°C (high = +100.0°C, crit = +100.0°C)
Core 0: +53.0°C (high = +100.0°C, crit = +100.0°C)
Core 4: +57.0°C (high = +100.0°C, crit = +100.0°C)
Core 8: +61.0°C (high = +100.0°C, crit = +100.0°C)
Core 9: +61.0°C (high = +100.0°C, crit = +100.0°C)
Core 10: +61.0°C (high = +100.0°C, crit = +100.0°C)
Core 11: +61.0°C (high = +100.0°C, crit = +100.0°C)
Core 12: +60.0°C (high = +100.0°C, crit = +100.0°C)
Core 13: +60.0°C (high = +100.0°C, crit = +100.0°C)
Core 14: +60.0°C (high = +100.0°C, crit = +100.0°C)
Core 15: +60.0°C (high = +100.0°C, crit = +100.0°C)
thinkpad-isa-0000
Adapter: ISA adapter
fan1: 2199 RPM
CPU: +60.0°C
GPU: N/A
temp3: +60.0°C
temp4: +0.0°C
temp5: +60.0°C
temp6: +60.0°C
temp7: +60.0°C
temp8: N/A
ucsi_source_psy_USBC000:001-isa-0000
Adapter: ISA adapter
in0: 0.00 V (min = +0.00 V, max = +0.00 V)
curr1: 0.00 A (max = +0.00 A)
BAT0-acpi-0
Adapter: ACPI interface
in0: 12.91 V
power1: 0.00 W
iwlwifi_1-virtual-0
Adapter: Virtual device
temp1: +43.0°C
ucsi_source_psy_USBC000:002-isa-0000
Adapter: ISA adapter
in0: 0.00 V (min = +0.00 V, max = +0.00 V)
curr1: 3.00 A (max = +0.00 A)
nvme-pci-0200
Adapter: PCI adapter
Composite: +45.9°C (low = -273.1°C, high = +85.8°C)
(crit = +86.8°C)
Sensor 1: +48.9°C (low = -273.1°C, high = +65261.8°C)
Sensor 2: +45.9°C (low = -273.1°C, high = +65261.8°C)
acpitz-acpi-0
Adapter: ACPI interface
temp1: +60.0°C
❯ ./sensors-open-metrics.py --printout
#HELP coretemp-isa-0000_Package_id_0_temp1_input coretemp-isa-0000 Package id 0 temp1_input
#TYPE coretemp-isa-0000_Package_id_0_temp1_input gauge
coretemp-isa-0000_Package_id_0_temp1_input: 66.0
#HELP coretemp-isa-0000_Package_id_0_temp1_max coretemp-isa-0000 Package id 0 temp1_max
#TYPE coretemp-isa-0000_Package_id_0_temp1_max gauge
coretemp-isa-0000_Package_id_0_temp1_max: 100.0
#HELP coretemp-isa-0000_Package_id_0_temp1_crit coretemp-isa-0000 Package id 0 temp1_crit
#TYPE coretemp-isa-0000_Package_id_0_temp1_crit gauge
coretemp-isa-0000_Package_id_0_temp1_crit: 100.0
#HELP coretemp-isa-0000_Package_id_0_temp1_crit_alarm coretemp-isa-0000 Package id 0 temp1_crit_alarm
#TYPE coretemp-isa-0000_Package_id_0_temp1_crit_alarm gauge
coretemp-isa-0000_Package_id_0_temp1_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_0_temp2_input coretemp-isa-0000 Core 0 temp2_input
#TYPE coretemp-isa-0000_Core_0_temp2_input gauge
coretemp-isa-0000_Core_0_temp2_input: 61.0
#HELP coretemp-isa-0000_Core_0_temp2_max coretemp-isa-0000 Core 0 temp2_max
#TYPE coretemp-isa-0000_Core_0_temp2_max gauge
coretemp-isa-0000_Core_0_temp2_max: 100.0
#HELP coretemp-isa-0000_Core_0_temp2_crit coretemp-isa-0000 Core 0 temp2_crit
#TYPE coretemp-isa-0000_Core_0_temp2_crit gauge
coretemp-isa-0000_Core_0_temp2_crit: 100.0
#HELP coretemp-isa-0000_Core_0_temp2_crit_alarm coretemp-isa-0000 Core 0 temp2_crit_alarm
#TYPE coretemp-isa-0000_Core_0_temp2_crit_alarm gauge
coretemp-isa-0000_Core_0_temp2_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_4_temp6_input coretemp-isa-0000 Core 4 temp6_input
#TYPE coretemp-isa-0000_Core_4_temp6_input gauge
coretemp-isa-0000_Core_4_temp6_input: 58.0
#HELP coretemp-isa-0000_Core_4_temp6_max coretemp-isa-0000 Core 4 temp6_max
#TYPE coretemp-isa-0000_Core_4_temp6_max gauge
coretemp-isa-0000_Core_4_temp6_max: 100.0
#HELP coretemp-isa-0000_Core_4_temp6_crit coretemp-isa-0000 Core 4 temp6_crit
#TYPE coretemp-isa-0000_Core_4_temp6_crit gauge
coretemp-isa-0000_Core_4_temp6_crit: 100.0
#HELP coretemp-isa-0000_Core_4_temp6_crit_alarm coretemp-isa-0000 Core 4 temp6_crit_alarm
#TYPE coretemp-isa-0000_Core_4_temp6_crit_alarm gauge
coretemp-isa-0000_Core_4_temp6_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_8_temp10_input coretemp-isa-0000 Core 8 temp10_input
#TYPE coretemp-isa-0000_Core_8_temp10_input gauge
coretemp-isa-0000_Core_8_temp10_input: 66.0
#HELP coretemp-isa-0000_Core_8_temp10_max coretemp-isa-0000 Core 8 temp10_max
#TYPE coretemp-isa-0000_Core_8_temp10_max gauge
coretemp-isa-0000_Core_8_temp10_max: 100.0
#HELP coretemp-isa-0000_Core_8_temp10_crit coretemp-isa-0000 Core 8 temp10_crit
#TYPE coretemp-isa-0000_Core_8_temp10_crit gauge
coretemp-isa-0000_Core_8_temp10_crit: 100.0
#HELP coretemp-isa-0000_Core_8_temp10_crit_alarm coretemp-isa-0000 Core 8 temp10_crit_alarm
#TYPE coretemp-isa-0000_Core_8_temp10_crit_alarm gauge
coretemp-isa-0000_Core_8_temp10_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_9_temp11_input coretemp-isa-0000 Core 9 temp11_input
#TYPE coretemp-isa-0000_Core_9_temp11_input gauge
coretemp-isa-0000_Core_9_temp11_input: 66.0
#HELP coretemp-isa-0000_Core_9_temp11_max coretemp-isa-0000 Core 9 temp11_max
#TYPE coretemp-isa-0000_Core_9_temp11_max gauge
coretemp-isa-0000_Core_9_temp11_max: 100.0
#HELP coretemp-isa-0000_Core_9_temp11_crit coretemp-isa-0000 Core 9 temp11_crit
#TYPE coretemp-isa-0000_Core_9_temp11_crit gauge
coretemp-isa-0000_Core_9_temp11_crit: 100.0
#HELP coretemp-isa-0000_Core_9_temp11_crit_alarm coretemp-isa-0000 Core 9 temp11_crit_alarm
#TYPE coretemp-isa-0000_Core_9_temp11_crit_alarm gauge
coretemp-isa-0000_Core_9_temp11_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_10_temp12_input coretemp-isa-0000 Core 10 temp12_input
#TYPE coretemp-isa-0000_Core_10_temp12_input gauge
coretemp-isa-0000_Core_10_temp12_input: 66.0
#HELP coretemp-isa-0000_Core_10_temp12_max coretemp-isa-0000 Core 10 temp12_max
#TYPE coretemp-isa-0000_Core_10_temp12_max gauge
coretemp-isa-0000_Core_10_temp12_max: 100.0
#HELP coretemp-isa-0000_Core_10_temp12_crit coretemp-isa-0000 Core 10 temp12_crit
#TYPE coretemp-isa-0000_Core_10_temp12_crit gauge
coretemp-isa-0000_Core_10_temp12_crit: 100.0
#HELP coretemp-isa-0000_Core_10_temp12_crit_alarm coretemp-isa-0000 Core 10 temp12_crit_alarm
#TYPE coretemp-isa-0000_Core_10_temp12_crit_alarm gauge
coretemp-isa-0000_Core_10_temp12_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_11_temp13_input coretemp-isa-0000 Core 11 temp13_input
#TYPE coretemp-isa-0000_Core_11_temp13_input gauge
coretemp-isa-0000_Core_11_temp13_input: 66.0
#HELP coretemp-isa-0000_Core_11_temp13_max coretemp-isa-0000 Core 11 temp13_max
#TYPE coretemp-isa-0000_Core_11_temp13_max gauge
coretemp-isa-0000_Core_11_temp13_max: 100.0
#HELP coretemp-isa-0000_Core_11_temp13_crit coretemp-isa-0000 Core 11 temp13_crit
#TYPE coretemp-isa-0000_Core_11_temp13_crit gauge
coretemp-isa-0000_Core_11_temp13_crit: 100.0
#HELP coretemp-isa-0000_Core_11_temp13_crit_alarm coretemp-isa-0000 Core 11 temp13_crit_alarm
#TYPE coretemp-isa-0000_Core_11_temp13_crit_alarm gauge
coretemp-isa-0000_Core_11_temp13_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_12_temp14_input coretemp-isa-0000 Core 12 temp14_input
#TYPE coretemp-isa-0000_Core_12_temp14_input gauge
coretemp-isa-0000_Core_12_temp14_input: 61.0
#HELP coretemp-isa-0000_Core_12_temp14_max coretemp-isa-0000 Core 12 temp14_max
#TYPE coretemp-isa-0000_Core_12_temp14_max gauge
coretemp-isa-0000_Core_12_temp14_max: 100.0
#HELP coretemp-isa-0000_Core_12_temp14_crit coretemp-isa-0000 Core 12 temp14_crit
#TYPE coretemp-isa-0000_Core_12_temp14_crit gauge
coretemp-isa-0000_Core_12_temp14_crit: 100.0
#HELP coretemp-isa-0000_Core_12_temp14_crit_alarm coretemp-isa-0000 Core 12 temp14_crit_alarm
#TYPE coretemp-isa-0000_Core_12_temp14_crit_alarm gauge
coretemp-isa-0000_Core_12_temp14_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_13_temp15_input coretemp-isa-0000 Core 13 temp15_input
#TYPE coretemp-isa-0000_Core_13_temp15_input gauge
coretemp-isa-0000_Core_13_temp15_input: 61.0
#HELP coretemp-isa-0000_Core_13_temp15_max coretemp-isa-0000 Core 13 temp15_max
#TYPE coretemp-isa-0000_Core_13_temp15_max gauge
coretemp-isa-0000_Core_13_temp15_max: 100.0
#HELP coretemp-isa-0000_Core_13_temp15_crit coretemp-isa-0000 Core 13 temp15_crit
#TYPE coretemp-isa-0000_Core_13_temp15_crit gauge
coretemp-isa-0000_Core_13_temp15_crit: 100.0
#HELP coretemp-isa-0000_Core_13_temp15_crit_alarm coretemp-isa-0000 Core 13 temp15_crit_alarm
#TYPE coretemp-isa-0000_Core_13_temp15_crit_alarm gauge
coretemp-isa-0000_Core_13_temp15_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_14_temp16_input coretemp-isa-0000 Core 14 temp16_input
#TYPE coretemp-isa-0000_Core_14_temp16_input gauge
coretemp-isa-0000_Core_14_temp16_input: 61.0
#HELP coretemp-isa-0000_Core_14_temp16_max coretemp-isa-0000 Core 14 temp16_max
#TYPE coretemp-isa-0000_Core_14_temp16_max gauge
coretemp-isa-0000_Core_14_temp16_max: 100.0
#HELP coretemp-isa-0000_Core_14_temp16_crit coretemp-isa-0000 Core 14 temp16_crit
#TYPE coretemp-isa-0000_Core_14_temp16_crit gauge
coretemp-isa-0000_Core_14_temp16_crit: 100.0
#HELP coretemp-isa-0000_Core_14_temp16_crit_alarm coretemp-isa-0000 Core 14 temp16_crit_alarm
#TYPE coretemp-isa-0000_Core_14_temp16_crit_alarm gauge
coretemp-isa-0000_Core_14_temp16_crit_alarm: 0.0
#HELP coretemp-isa-0000_Core_15_temp17_input coretemp-isa-0000 Core 15 temp17_input
#TYPE coretemp-isa-0000_Core_15_temp17_input gauge
coretemp-isa-0000_Core_15_temp17_input: 61.0
#HELP coretemp-isa-0000_Core_15_temp17_max coretemp-isa-0000 Core 15 temp17_max
#TYPE coretemp-isa-0000_Core_15_temp17_max gauge
coretemp-isa-0000_Core_15_temp17_max: 100.0
#HELP coretemp-isa-0000_Core_15_temp17_crit coretemp-isa-0000 Core 15 temp17_crit
#TYPE coretemp-isa-0000_Core_15_temp17_crit gauge
coretemp-isa-0000_Core_15_temp17_crit: 100.0
#HELP coretemp-isa-0000_Core_15_temp17_crit_alarm coretemp-isa-0000 Core 15 temp17_crit_alarm
#TYPE coretemp-isa-0000_Core_15_temp17_crit_alarm gauge
coretemp-isa-0000_Core_15_temp17_crit_alarm: 0.0
#HELP thinkpad-isa-0000_fan1_fan1_input thinkpad-isa-0000 fan1 fan1_input
#TYPE thinkpad-isa-0000_fan1_fan1_input gauge
thinkpad-isa-0000_fan1_fan1_input: 2191.0
#HELP thinkpad-isa-0000_CPU_temp1_input thinkpad-isa-0000 CPU temp1_input
#TYPE thinkpad-isa-0000_CPU_temp1_input gauge
thinkpad-isa-0000_CPU_temp1_input: 60.0
#HELP thinkpad-isa-0000_temp3_temp3_input thinkpad-isa-0000 temp3 temp3_input
#TYPE thinkpad-isa-0000_temp3_temp3_input gauge
thinkpad-isa-0000_temp3_temp3_input: 60.0
#HELP thinkpad-isa-0000_temp4_temp4_input thinkpad-isa-0000 temp4 temp4_input
#TYPE thinkpad-isa-0000_temp4_temp4_input gauge
thinkpad-isa-0000_temp4_temp4_input: 0.0
#HELP thinkpad-isa-0000_temp5_temp5_input thinkpad-isa-0000 temp5 temp5_input
#TYPE thinkpad-isa-0000_temp5_temp5_input gauge
thinkpad-isa-0000_temp5_temp5_input: 60.0
#HELP thinkpad-isa-0000_temp6_temp6_input thinkpad-isa-0000 temp6 temp6_input
#TYPE thinkpad-isa-0000_temp6_temp6_input gauge
thinkpad-isa-0000_temp6_temp6_input: 60.0
#HELP thinkpad-isa-0000_temp7_temp7_input thinkpad-isa-0000 temp7 temp7_input
#TYPE thinkpad-isa-0000_temp7_temp7_input gauge
thinkpad-isa-0000_temp7_temp7_input: 60.0
#HELP ucsi_source_psy_USBC000:001-isa-0000_in0_in0_input ucsi_source_psy_USBC000:001-isa-0000 in0 in0_input
#TYPE ucsi_source_psy_USBC000:001-isa-0000_in0_in0_input gauge
ucsi_source_psy_USBC000:001-isa-0000_in0_in0_input: 0.0
#HELP ucsi_source_psy_USBC000:001-isa-0000_in0_in0_min ucsi_source_psy_USBC000:001-isa-0000 in0 in0_min
#TYPE ucsi_source_psy_USBC000:001-isa-0000_in0_in0_min gauge
ucsi_source_psy_USBC000:001-isa-0000_in0_in0_min: 0.0
#HELP ucsi_source_psy_USBC000:001-isa-0000_in0_in0_max ucsi_source_psy_USBC000:001-isa-0000 in0 in0_max
#TYPE ucsi_source_psy_USBC000:001-isa-0000_in0_in0_max gauge
ucsi_source_psy_USBC000:001-isa-0000_in0_in0_max: 0.0
#HELP ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_input ucsi_source_psy_USBC000:001-isa-0000 curr1 curr1_input
#TYPE ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_input gauge
ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_input: 0.0
#HELP ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_max ucsi_source_psy_USBC000:001-isa-0000 curr1 curr1_max
#TYPE ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_max gauge
ucsi_source_psy_USBC000:001-isa-0000_curr1_curr1_max: 0.0
#HELP BAT0-acpi-0_in0_in0_input BAT0-acpi-0 in0 in0_input
#TYPE BAT0-acpi-0_in0_in0_input gauge
BAT0-acpi-0_in0_in0_input: 12.909
#HELP BAT0-acpi-0_power1_power1_input BAT0-acpi-0 power1 power1_input
#TYPE BAT0-acpi-0_power1_power1_input gauge
BAT0-acpi-0_power1_power1_input: 0.0
#HELP iwlwifi_1-virtual-0_temp1_temp1_input iwlwifi_1-virtual-0 temp1 temp1_input
#TYPE iwlwifi_1-virtual-0_temp1_temp1_input gauge
iwlwifi_1-virtual-0_temp1_temp1_input: 43.0
#HELP ucsi_source_psy_USBC000:002-isa-0000_in0_in0_input ucsi_source_psy_USBC000:002-isa-0000 in0 in0_input
#TYPE ucsi_source_psy_USBC000:002-isa-0000_in0_in0_input gauge
ucsi_source_psy_USBC000:002-isa-0000_in0_in0_input: 0.0
#HELP ucsi_source_psy_USBC000:002-isa-0000_in0_in0_min ucsi_source_psy_USBC000:002-isa-0000 in0 in0_min
#TYPE ucsi_source_psy_USBC000:002-isa-0000_in0_in0_min gauge
ucsi_source_psy_USBC000:002-isa-0000_in0_in0_min: 0.0
#HELP ucsi_source_psy_USBC000:002-isa-0000_in0_in0_max ucsi_source_psy_USBC000:002-isa-0000 in0 in0_max
#TYPE ucsi_source_psy_USBC000:002-isa-0000_in0_in0_max gauge
ucsi_source_psy_USBC000:002-isa-0000_in0_in0_max: 0.0
#HELP ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_input ucsi_source_psy_USBC000:002-isa-0000 curr1 curr1_input
#TYPE ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_input gauge
ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_input: 3.0
#HELP ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_max ucsi_source_psy_USBC000:002-isa-0000 curr1 curr1_max
#TYPE ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_max gauge
ucsi_source_psy_USBC000:002-isa-0000_curr1_curr1_max: 0.0
#HELP nvme-pci-0200_Composite_temp1_input nvme-pci-0200 Composite temp1_input
#TYPE nvme-pci-0200_Composite_temp1_input gauge
nvme-pci-0200_Composite_temp1_input: 45.85
#HELP nvme-pci-0200_Composite_temp1_max nvme-pci-0200 Composite temp1_max
#TYPE nvme-pci-0200_Composite_temp1_max gauge
nvme-pci-0200_Composite_temp1_max: 85.85
#HELP nvme-pci-0200_Composite_temp1_min nvme-pci-0200 Composite temp1_min
#TYPE nvme-pci-0200_Composite_temp1_min gauge
nvme-pci-0200_Composite_temp1_min: -273.15
#HELP nvme-pci-0200_Composite_temp1_crit nvme-pci-0200 Composite temp1_crit
#TYPE nvme-pci-0200_Composite_temp1_crit gauge
nvme-pci-0200_Composite_temp1_crit: 86.85
#HELP nvme-pci-0200_Composite_temp1_alarm nvme-pci-0200 Composite temp1_alarm
#TYPE nvme-pci-0200_Composite_temp1_alarm gauge
nvme-pci-0200_Composite_temp1_alarm: 0.0
#HELP nvme-pci-0200_Sensor_1_temp2_input nvme-pci-0200 Sensor 1 temp2_input
#TYPE nvme-pci-0200_Sensor_1_temp2_input gauge
nvme-pci-0200_Sensor_1_temp2_input: 50.85
#HELP nvme-pci-0200_Sensor_1_temp2_max nvme-pci-0200 Sensor 1 temp2_max
#TYPE nvme-pci-0200_Sensor_1_temp2_max gauge
nvme-pci-0200_Sensor_1_temp2_max: 65261.85
#HELP nvme-pci-0200_Sensor_1_temp2_min nvme-pci-0200 Sensor 1 temp2_min
#TYPE nvme-pci-0200_Sensor_1_temp2_min gauge
nvme-pci-0200_Sensor_1_temp2_min: -273.15
#HELP nvme-pci-0200_Sensor_2_temp3_input nvme-pci-0200 Sensor 2 temp3_input
#TYPE nvme-pci-0200_Sensor_2_temp3_input gauge
nvme-pci-0200_Sensor_2_temp3_input: 45.85
#HELP nvme-pci-0200_Sensor_2_temp3_max nvme-pci-0200 Sensor 2 temp3_max
#TYPE nvme-pci-0200_Sensor_2_temp3_max gauge
nvme-pci-0200_Sensor_2_temp3_max: 65261.85
#HELP nvme-pci-0200_Sensor_2_temp3_min nvme-pci-0200 Sensor 2 temp3_min
#TYPE nvme-pci-0200_Sensor_2_temp3_min gauge
nvme-pci-0200_Sensor_2_temp3_min: -273.15
#HELP acpitz-acpi-0_temp1_temp1_input acpitz-acpi-0 temp1 temp1_input
#TYPE acpitz-acpi-0_temp1_temp1_input gauge
acpitz-acpi-0_temp1_temp1_input: 60.0
Os dados aparecem no #HELP simplesmente sem os _.
Talvez eu devesse melhorar e fazer com que alguns valores fosse labels do valor maior.
Mas por enquanto está funcionando assim.
E pra rodar como serviço:
❯ ./sensors-open-metrics.py
[2025-12-12 19:54:43] (INFO) starting service on port 9090
INFO: Started server process [1078630]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:9090 (Press CTRL+C to quit)
[2025-12-12 19:54:53] (INFO) serving web page on /metrics
INFO: 127.0.0.1:52250 - "GET /metrics HTTP/1.1" 200 OK
Em outro terminal:
❯ curl localhost:9090/metrics
#HELP coretemp-isa-0000_Package_id_0_temp1_input coretemp-isa-0000 Package id 0 temp1_input
#TYPE coretemp-isa-0000_Package_id_0_temp1_input gauge
coretemp-isa-0000_Package_id_0_temp1_input: 62.0
#HELP coretemp-isa-0000_Package_id_0_temp1_max coretemp-isa-0000 Package id 0 temp1_max
#TYPE coretemp-isa-0000_Package_id_0_temp1_max gauge
coretemp-isa-0000_Package_id_0_temp1_max: 100.0
#HELP coretemp-isa-0000_Package_id_0_temp1_crit coretemp-isa-0000 Package id 0 temp1_crit
#TYPE coretemp-isa-0000_Package_id_0_temp1_crit gauge
coretemp-isa-0000_Package_id_0_temp1_crit: 100.0
#HELP coretemp-isa-0000_Package_id_0_temp1_crit_alarm coretemp-isa-0000 Package id 0 temp1_crit_alarm
[...]
Pra rodar como serviço do systemd em /etc/systemd/system/sensors-open-metrics.service:
[Unit]
Description=Temperature sensors
Wants=network-online.target
After=network-online.target nginx.service
[Service]
Restart=always
User=root
Group=root
WorkingDirectory=/tmp
ExecStart=/usr/local/bin/sensors-open-metrics.py
TimeoutStopSec=5s
[Install]
WantedBy=multi-user.target
E finalmente adicionando em /etc/alloy/config.alloy:
[...]
discovery.relabel "temperature_metrics" {
targets = array.concat(
[{
__address__ = "localhost:9090",
}],
)
rule {
source_labels = ["__address__"]
target_label = "instance"
replacement = "nome_do_servidor"
}
}
prometheus.scrape "temperature_metrics" {
targets = discovery.relabel.temperature_metrics.output
forward_to = [prometheus.remote_write.prod.receiver]
job_name = "temperature"
}
Daí é só evocar o Grafana e partir por gráficos.
Update: atualizado em
Sat Dec 13 02:43:59 PM CET 2025
com mais informação sobre a parte de script.

Por motivos que não cabem aqui, temos alguns servidores instalados em uma sala na empresa. E essa sala tem um ar-condicionado pra manter a temperatura sob controle.
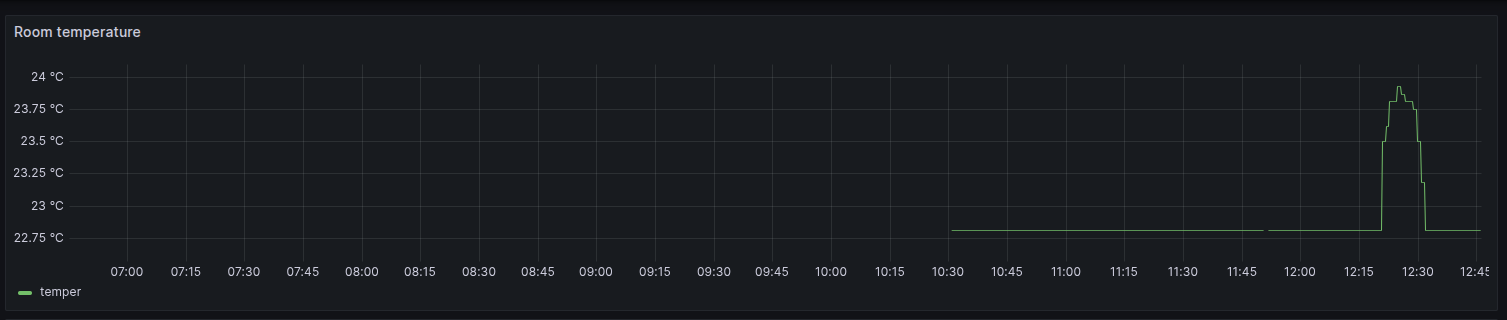
Um belo dia estou olhando os dados no Grafana e noto que essas máquinas não reportaram dados (não temos alertas enviados pelo Grafana, mas o porquê disso fica pra um outro dia). Entro na sala e a temperatura estava simplemente... 32°C. Era verão na Suécia, que é curto mas tem seus dias bem quentes. E o hardware das máquinas desligaram pra proteção.
Entre entrar em contato com técnico do ar-condicionado e deixar a sala aberta pra ventilar, ficamos com aquele gosto amargo de não ter nenhum dado sobre a temperatura.
A solução? raspberrypi!
Ele tem um sensor que é vendido na Internet.
O sensor já chegou mas não o raspberrypi. O motivo deve ser porque compramos um modelo que funciona como KVM e tem algumas coisas a mais.
Então aqui a descrição de como botar o serviço pra funcionar em Linux.
Existe um software descrito na página do produto que aponta pro seguinte repositório no GitHub:
Mas o repositório parece abandonado. Já faz 7 anos que ninguém manda nenhum commit. E o código não funciona com a versão mais moderna do sensor.
O que fazer? Patch!
Então corrigi o programa e criei um fork do repo original.
Então temos o software pronto pra funcionar. Ou quase.
Antes é preciso corrigir as permissões de leitura e escrita do dispositivo.
E pra isso eu criei uma pequena regra no udev em
/etc/udev/rules.d/90-temperature-sensor.rules
KERNEL=="hidraw[0-9]*", SUBSYSTEM=="hidraw", SUBSYSTEMS=="usb", ATTRS{idVendor}=="3553", ATTRS{idProduct}=="a001", MODE="0666", SYMLINK+="temper"
Pegando a saída do kernel:
# dmesg | grep -i temper
[ 5.152423] usb 1-10.4: Product: TEMPer2
[ 6.769788] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.0/0003:3553:A001.0005/input/input14
[ 6.826541] hid-generic 0003:3553:A001.0005: input,hidraw4: USB HID v1.11 Keyboard [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input0
[ 6.826720] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.1/0003:3553:A001.0006/input/input15
[ 6.827067] hid-generic 0003:3553:A001.0006: input,hidraw5: USB HID v1.10 Device [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input1
[ 939.507362] usb 1-10.4: Product: TEMPer2
[ 939.521617] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.0/0003:3553:A001.000B/input/input26
[ 939.580825] hid-generic 0003:3553:A001.000B: input,hidraw4: USB HID v1.11 Keyboard [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input0
[ 939.581808] input: PCsensor TEMPer2 as /devices/pci0000:00/0000:00:14.0/usb1/1-10/1-10.4/1-10.4:1.1/0003:3553:A001.000C/input/input27
[ 939.582035] hid-generic 0003:3553:A001.000C: input,hidraw5: USB HID v1.10 Device [PCsensor TEMPer2] on usb-0000:00:14.0-10.4/input1
É possível ver que o dispositivo aparece como dois devices:
/dev/hidraw4
e
/dev/hidraw5.
Eu tentei usar a permissão 0644 primeiro, mas essa não funcionou pra ler os dados. Então tive de mudar pra 0666 mesmo sendo algo que só lê informação.
Feita essa etapa, ainda não estamos prontos pra rodar o programa temper.py.
Ainda é preciso instalar a dependência: serial.
Se seu sistema é baseado em debian/ubuntu:
> sudo apt install -y python3-serial
Se não for, talvez seja mais fácil fazer com virtualenv.
E pra isso eu atualmente uso o uv
> uv venv venv
> source venv/bin/activate
(venv)> uv pip install serial
Tendo tudo pronto, chegamos ao momento da verdade:
(venv)> ./temper.py
Bus 001 Dev 011 3553:a001 TEMPer2_V4.1 25.6C 78.0F - 22.8C 73.1F -
Pegando a saída como JSON permite ver melhor o que é cada um desses resultados.
(venv)> ./temper.py --json
[
{
"vendorid": 13651,
"productid": 40961,
"manufacturer": "PCsensor",
"product": "TEMPer2",
"busnum": 1,
"devnum": 11,
"devices": [
"hidraw4",
"hidraw5"
],
"firmware": "TEMPer2_V4.1",
"hex_firmware": "54454d506572325f56342e3100000000",
"hex_data": "808009f64e200000800108e94e200000",
"internal temperature": 25.5,
"external temperature": 22.81
}
]
Então a primeira temperatura lida, de /dev/hidraw4, é 25.5°C interna do dispositivo.
A segunda, /dev/hidraw5, é de 22.81°C e externa, do cabo.
Temos as leituras e os dados. Como mandar isso pro Grafana?
Eu primeiramente tentei fazer em shell script e mandar o dados pro mimir, que é onde eu agrego as métricas.
Fracassei miseravelmente.
Não existe uma forma muito fácil de enviar um dados pro lá. O formato que o alloy usa é protobuf, que é um dado comprimido em snappy, etc.
Qual outra alternativa?
Expor o dado como open metric pro alloy pegar e enviar.
Pode parecer simples mas... precisamos de um servidor web pra isso.
Algo que temos fácil em python.
Então usando uvicorn e fastapi podemos ter tudo funcionando.
E é possível importar o temper.py como módulo.
E é preciso incrementar nosso virtualenv (ou pacotes) com esses pacotes:
> sudo apt install -y python3-uvicorn python3-fastapi
ou
(venv)> uv pip install uvicorn
(venv)> uv pip install fastapi
Sem mais delongas, eis aqui o código do monitor.py:
#! /usr/bin/env python3
import subprocess
import argparse
import logging
import threading
import time
try:
import temper
except ImportError as e:
print(f"Error importing temper module: {e}")
print("Make sure python3-serial is installed: sudo apt-get install python3-serial")
exit(1)
import uvicorn
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse
CELSIUS = "\u2103"
DEFAULT_PORT = 8000
TEMPERATURE_MAX = 25.0
logger = logging.getLogger(__file__)
consoleOutputHandler = logging.StreamHandler()
formatter = logging.Formatter(
fmt="[%(asctime)s] (%(levelname)s) %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
consoleOutputHandler.setFormatter(formatter)
logger.addHandler(consoleOutputHandler)
logger.setLevel(logging.INFO)
def shellExec(command: str) -> str:
'run a command and return its output'
try:
return subprocess.getoutput(command)
except Exception as e:
logger.error(f"Error executing shell command '{command}': {e}")
return f"Error: {e}"
app = FastAPI()
# Global temperature monitor instance (will be set in main)
temperature_monitor = None
@app.get("/metrics", response_class=PlainTextResponse)
async def metrics():
if temperature_monitor is None or temperature_monitor.temperature_current is None:
return ""
temperature_current = temperature_monitor.temperature_current
logger.info(f"/metrics: {temperature_current}{CELSIUS}")
data_lines = list()
data_lines.append("#HELP server_room_temperature_celsius the room with servers current temperature")
data_lines.append("#TYPE server_room_temperature_celsius gauge")
data_lines.append(f"server_room_temperature_celsius {temperature_current}")
data_lines.append("")
return "\n".join(data_lines)
class TemperatureMonitor:
'A class that handle the temperature monitoring'
port: int = DEFAULT_PORT
temperature_max: float = TEMPERATURE_MAX
temperature_current: float|None = None
alert_lock: bool = False
def __init__(self, port=None, temperature_max=None) -> None:
if port:
self.port = port
if temperature_max:
self.temperature_max = temperature_max
def monitor(self) -> None:
th = threading.Thread(target=self.webserver)
th.daemon = True # Make it a daemon thread
th.start()
try:
while True:
self.update()
time.sleep(15)
except KeyboardInterrupt:
logger.info("Monitoring stopped by user")
except Exception as e:
logger.error(f"Error in monitoring loop: {e}")
raise
def webserver(self) -> None:
uvicorn.run(app, host="127.0.0.1", port=self.port)
def update(self) -> None:
'Read the output from the command'
try:
tp = temper.Temper().read()
if not tp or len(tp) == 0:
logger.warning("No temperature devices found")
self.temperature_current = None
return
self.temperature_current = tp[0].get('external temperature')
if self.temperature_current is not None:
logger.info(f"🌡️ current temperature: {self.temperature_current}{CELSIUS}")
else:
logger.warning("External temperature reading is None")
except Exception as e:
logger.error(f"Error reading temperature sensor: {e}")
self.temperature_current = None
if __name__ == '__main__':
parse = argparse.ArgumentParser(description="script to monitor temperature")
parse.add_argument("--loglevel", default="info", help="the logging level (default=info)")
parse.add_argument("--tempmax", type=float, default=TEMPERATURE_MAX, help="maximum temperature before raising alert")
parse.add_argument("--port", type=int, default=DEFAULT_PORT, help="port to listen the service")
args = parse.parse_args()
# Validate log level
valid_log_levels = ['DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL']
if args.loglevel.upper() not in valid_log_levels:
print(f"Invalid log level: {args.loglevel}. Valid options: {', '.join(valid_log_levels)}")
exit(1)
if args.loglevel.upper() != "INFO":
logger.setLevel(args.loglevel.upper())
# Validate temperature threshold
if args.tempmax <= 0:
print("Temperature threshold must be greater than 0")
exit(1)
# Validate port number
if not (1 <= args.port <= 65535):
print("Port must be between 1 and 65535")
exit(1)
# Create temperature monitor instance
temperature_monitor = TemperatureMonitor(args.port, args.tempmax)
temperature_monitor.monitor()
Eu tenho integrado uma parte de alerta que usa outro sistema, mas removi pra deixar o código fazendo somente o que é preciso.
No alloy, adicionei as seguintes linhas:
discovery.relabel "temperature_sensor" {
targets = array.concat(
[{
__address__ = "localhost:8000",
}],
)
rule {
source_labels = ["__address__"]
target_label = "instance"
replacement = "temper"
}
}
prometheus.scrape "temperature_sensor" {
targets = discovery.relabel.temperature_sensor.output
forward_to = [prometheus.remote_write.prod.receiver]
job_name = "agent"
}
Tudo pronto.
Ou quase.
Falta rodar o monitor.py que mostrei acima como serviço.
E pra isso usamos o systemd.
Basta criar o arquivo /etc/systemd/system/temperature-monitor.service
e iniciar.
[Unit]
Description=Temperature monitoring service
After=network.target
[Service]
User=helio
Group=helio
WorkingDirectory=/home/helio/temperature-sensor
ExecStart=/home/helio/temperature-sensor/monitor.sh
Restart=always
[Install]
WantedBy=multi-user.target
O script monitor.sh é pra somente ler o virtualenv corretamente:
#! /usr/bin/env bash
die() {
echo "ERROR: $@" >&2
echo "[$(date)] exiting with error"
exit 1
}
program="$0"
root_dir=$(readlink -f $program)
root_dir=$(dirname $root_dir)
cd $root_dir
source venv/bin/activate || \
die "failed to read virtualenv"
exec ./monitor.py
E iniciando o serviço:
> sudo systemctl daemon-reload
> sudo systemctl enable --now temperature-monitor
O que resta é criar um gráfico pra métrica server_room_temperature_celsius
e partir pro abraço.
Update: [Fri Sep 12 05:30:00 PM CEST 2025] acabo de perceber que o repositório que fiz fork é na verdade um fork de outro, que parece ser bem mais completo.
