
Resolvi aproveitar que meu desktop está menos sobrecarregado e rodar os testes novamente pra comparar com os do artigo anterior, revisitando o artigo de shell lento com python3.13.
❯ time python3.13 20M-touch.py; time python3.13t 20M-touch.py
________________________________________________________
Executed in 396.13 secs fish external
usr time 231.65 secs 479.00 micros 231.65 secs
sys time 158.26 secs 803.00 micros 158.26 secs
________________________________________________________
Executed in 22.31 mins fish external
usr time 495.80 secs 0.00 millis 495.80 secs
sys time 820.21 secs 1.22 millis 820.20 secs
De 621 pra 396s já foi um ganho significativo de desempenho. Mas abaixo dos 374s do primeiro artigo, shell é lento?
O python3.13t, quer permite desabilitar o GIL, continua lento. Eu esqueci de desabilitar o GIL e não deveria fazer diferença. Mas fez. 22 minutos. Melhor que os 31 minutos do artigo anterior.
E com GIL desabilitado?
❯ time env PYTHON_GIL=0 python3.13t 20M-touch.py
________________________________________________________
Executed in 22.63 mins fish external
usr time 506.53 secs 381.00 micros 506.53 secs
sys time 822.23 secs 825.00 micros 822.23 secs
Não mudou muita coisa. O jeito é aceitar que é isso e seguir em frente. Segura o choro que dói menos.
Quando escrevi o artigo Shell é lento? python teve uma performance miserável. Pra não chamar de outra coisa.
Resolvi então dar uma revisitada no teste e rodando o python3.13. A cada versão de python dizem que a performance é melhorada. Nada melhor que tirar a prova. E além disso a versão 3.13 permite desabilitar o GIL, o Global Interpreter Locker. Não se se faz alguma diferença num teste desses, mas vamos tentar.
Eu mantive o mesmo programa que rodei da outra vez:
#! /usr/bin/env python3
for i in range(20000000):
with open("arq-python3", "w") as fd:
None
E o resultado:
helio@goosfraba❯ time python3.13 20M-touch.py
________________________________________________________
Executed in 621.80 secs fish external
usr time 384.60 secs 998.00 micros 384.60 secs
sys time 229.78 secs 0.00 micros 229.78 secs
Demorou mais que o teste anterior. Se antes foi miserável, essa aqui... Mas antes de botar a culpa no Python, vamos rodar a versão em Go e olhar se os tempos mudaram. O código de Go também continua o mesmo:
package main
import (
"log"
"os"
)
func main() {
for i := 0; i < 20000000; i++ {
fd, err := os.Create("arq-go")
fd.Close()
if err != nil {
log.Fatal(err)
}
}
}
E depois daquela compilada básica:
helio@goosfraba❯ go build -o 20M-touch 20M-touch.go
helio@goosfraba❯ time ./20M-touch
________________________________________________________
Executed in 295.12 secs fish external
usr time 88.50 secs 0.20 millis 88.50 secs
sys time 199.48 secs 1.03 millis 199.47 secs
Realmente baixou o Exu-tranca-sistema no HDD. Da época em que fiz o primeiro teste pra cá a mudança foi a adição de um disco extra de 12 TB. E afetou bastante a performance. De 148s pra 295s com o binário em Go. Nesse caso é melhor rodar o este com cada linguagem pra ver as diferenças no sistema novo e ter um equilíbrio maior entre os resultados.
helio@goosfraba❯ time perl 20M-touch.pl
________________________________________________________
Executed in 260.95 secs fish external
usr time 61.45 secs 1.31 millis 61.45 secs
sys time 195.20 secs 0.04 millis 195.20 secs
helio@goosfraba❯ time bash 20M-touch.sh
________________________________________________________
Executed in 443.89 secs fish external
usr time 213.20 secs 1.26 millis 213.20 secs
sys time 227.43 secs 0.04 millis 227.43 secs
E pra melhorar o escope de testes, adicionei ainda a versão em C++:
#include <iostream>
#include <fstream>
using namespace std;
int main() {
for (int i=0;i<20000000;i++) {
ofstream MyFile("arq-cpp");
MyFile.close();
}
}
O resultado:
helio@goosfraba❯ time ./20M-touch-cpp
________________________________________________________
Executed in 205.39 secs fish external
usr time 39.56 secs 359.00 micros 39.56 secs
sys time 163.64 secs 911.00 micros 163.64 secs
O resultados foram então (do mais rápido pro mais lento):
Enquanto C++ manteve a performance esperada, perl deu um show. Eu pessoalmente achei que Go! ficou devendo, ainda mais se comparado com C++. Mas python... python fracassou miseravelmente. E de novo.
E fui tentar rodar com o GIL desabilitado e...
helio@goosfraba❯ time env PYTHON_GIL=0 python3.13 20M-touch.py
Fatal Python error: config_read_gil: Disabling the GIL is not supported by this build
Python runtime state: preinitialized
________________________________________________________
Executed in 4.91 millis fish external
usr time 2.03 millis 1.09 millis 0.95 millis
sys time 2.85 millis 0.02 millis 2.83 millis
Vou precisar compilar um python3.13 com a configuração que permite desabilitar o GIL...
Update: compilei um pacote do AUR.
==> Creating package "python313-freethreaded"...
-> Generating .PKGINFO file...
-> Generating .BUILDINFO file...
-> Generating .MTREE file...
-> Compressing package...
==> Leaving fakeroot environment.
==> Finished making: python313-freethreaded 3.13.3-1 (Mon 12 May 2025 06:04:15 PM CEST)
==> Cleaning up...
E vamos aos resultados:
helio@goosfraba❯ time env PYTHON_GIL=0 python3.13t 20M-touch.py
________________________________________________________
Executed in 31.58 mins fish external
usr time 14.01 mins 0.00 millis 14.01 mins
sys time 17.25 mins 1.96 millis 17.25 mins
Python continua parecendo que bateu uma feijuca antes de rodar os testes. Não que remover o GIL fosse mudar muita coisa uma vez que o teste é sequencial. Mas podia ter melhorado um pouco.
Enquanto isso também descobri o porquê dos testes estarem mais lentos: tem algum treco do yay compilando. Sei lá eu o que é uma vez que estou conectado remotamente.

Pra quem me segue no Mastodon, sabe que (ou pelo menos vê) que envio um #TootThursday toda quinta-feira. Primeiro o que é isso? Nos tempos de Twitter surgiu o #FollowingFriday, ou #FF pros mais íntimos, que servia pra você indicar perfis interessantes pros outros seguirem. Nessa mesma época eu implementei um script pra fazer isso por mim já que todos que sigo eu considero interessantes.
Pra manter o mesmo espírito no Mastodon, passei a usar o #TootThursday. Como o limite de caracteres é bem mais alto no Mastodon, não é preciso criar um #TT e é possível usar o nome inteiro. E assim sigo postando toda quinta-feira.
Eu andei reparando que meu envio de sugestões estava sempre em 4 ou 5 pessoas. Sempre. E meu programa pra fazer o envio usa 10% da lista de pessoas que sigo, algo que está em mais de 500 hoje em dia no perfil @helioloureiroBR.
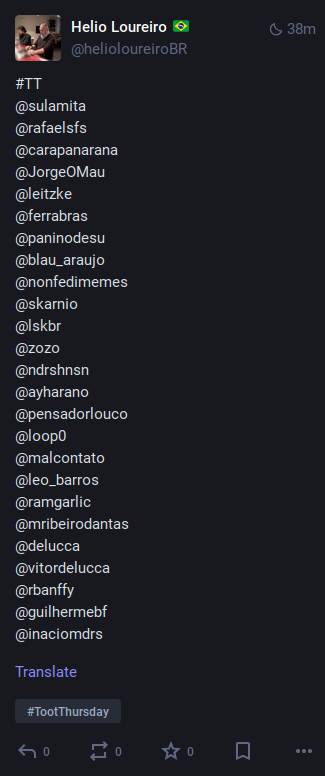
Olhei manualmente o uso de account_following( ) e eu estava recebendo somente 40 entradas, mesmo com limite em nulo.
In [14]: u = tt.mastodon.account_following(id=tt.me.id, limit=None) In [15]: len(u) Out[15]: 40
Abri um bug report no GitHub, mas lá mesmo vi a sugestão pra usar account_following( ) com fetch_remaining( ), o que testei aqui.
In [16]: u = tt.mastodon.account_following(id=tt.me.id, limit=80) In [17]: len(u) Out[17]: 80 In [18]: u = tt.mastodon.account_following(id=tt.me.id, limit=500) In [19]: len(u) Out[19]: 80 In [20]: u2 = tt.mastodon.fetch_remaining(u) In [21]: len(u2) Out[21]: 525
E realmente deu certo.
Agora o script está corrigido pra pegar mais pessoas que sigo e selecionar os 10%.
Se quiser olhar o bug report no GitHub, esse é o link: https://github.com/halcy/Mastodon.py/issues/376
No Mastodon mesmo o Mauricio Castro (@
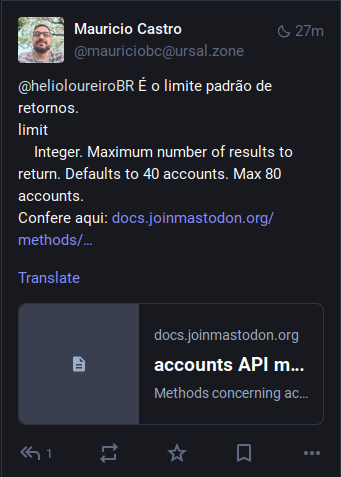
Mas vamos ver se o meu bug report ajuda a melhorar a documentação sobre isso.
UPDATE: escrevi o artigo e esqueci de apontar pro script, caso alguém queira usar ou copiar alguma parte. Ele está aqui: https://github.com/helioloureiro/homemadescripts/blob/master/mastodon-toot-thursday.py
Com a migração pra rede Mastodon, eu agora sigo alguns bots que postam notícias, como esse do UOL que postou uma notícia sobre tubarões.
O problema é só com os links encurtados pelo t.co do Twitter. Eles simplesmente não funcionam no tor-browser. Simplesmente não consigo receber o destino desses links.

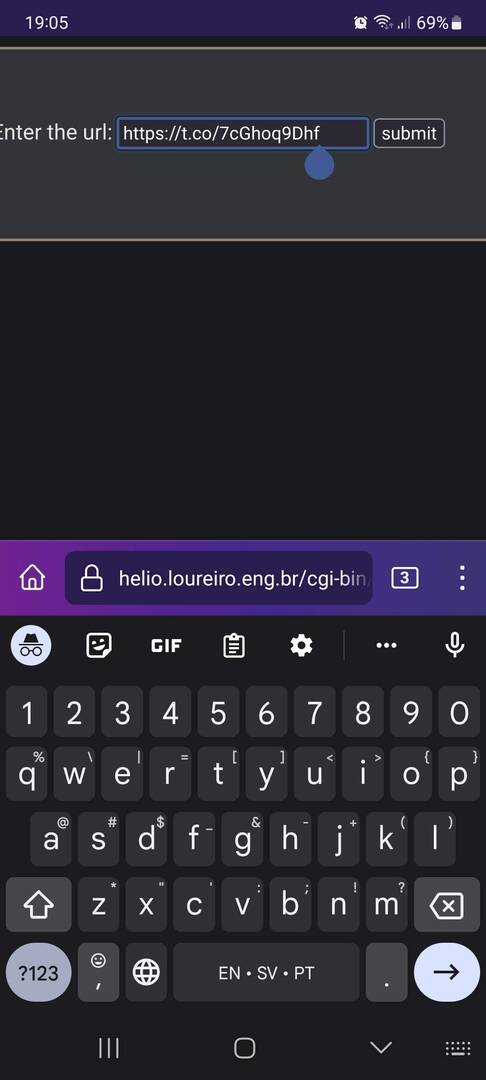
A solução que encontrei foi criar um pequeno script em CGI usando python que recebe a URL, busca o link destino e redireciona o browser.
O script é basicamente esse aqui:
#! /usr/bin/python3
import cgi
import requests
def renderPage():
print("Content-type: text/html;utf-8\n")
print("""
<label for="link">Enter the url:
<input id="link" name="link" type="text" />
<input type="submit" value="submit" />
""")
form = cgi.FieldStorage()
url = form.getvalue("link")
if url is None:
renderPage()
else:
req = requests.get(url)
print(f"Location: {req.url}\n\n")
O pessoal de javascript deve morrer de desgosto de ver uma interface tão simplificada e que usa o servidor pra gerar a respostas. Mas é o que sei fazer. No fim eu simplesmente salvo o link no bookmarks e abro o mesmo cada vez que preciso usar. Então é copiar o link da barra de url, abrir o bookmarks, clicar no link salvo do CGI, ir na caixa de diálogo, colar a url e pressionar o botão "submit".

Daí é só colar o link e deixar a mágica acontecer.

O link pra quem quiser usar o serviço é esse aqui:
Acabei de lançar um sistema fácil pra fazer loteria de participantes na PyCon Suécia.
Ia fazer web, mas depois mudei de idéia e passei pra console com dialog.
./simple-lottery-eventbrite.py --csvfile=/Users/ehellou/Downloads/PyconSweden2022-Attendee_Summary_Report_91481040875_20221027_1516.csv --dialog
Ele abrirá e perguntará quantos rounds quer rodar (ou quantos vencedores ganharão).
Em seguida ele permite confirmar o ganhador o cancelar, no caso da pessoa não estar na sala.
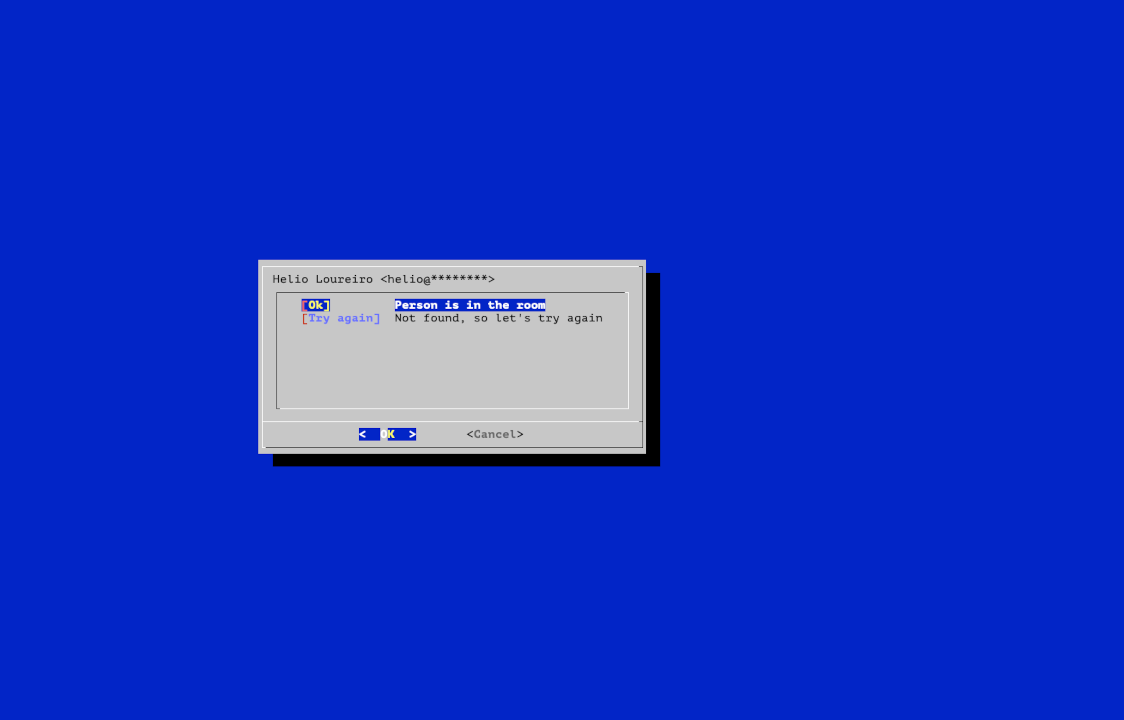
E por fim salva um log dos ganhadores, com o email correto.
O repositório está no github.
