 Existem vários sites na Internet que fornecem a informação de qual IP você está usando. Eu uso bastante pra verificar se minha conexão via TOR está funcionando corretamente.
Existem vários sites na Internet que fornecem a informação de qual IP você está usando. Eu uso bastante pra verificar se minha conexão via TOR está funcionando corretamente.
Infelizmente os sites que fornecem essa informação passaram a pedir alguma forma de autenticação ou aprovação de cookies, o que é muito chato uma vez que só quero a informação do IP.
Então pra resolver o problema eu fiz eu mesmo um CGI pra dizer qual IP acessou o site. É simples, mas funcional. Divirtam-se!
Terminada minha maratona pessoal de participações em conferências e eventos em geral, eu decidi dedicar algum tempo pra atualizar meus sistemas.
Meu desktop passou de Ubuntu 20.04 pra 21.10. Decidi simplesmente largar o LTS e abraçar os releases intermediários. Tive alguns problemas com o snapd, que deu uns crashes de kernel, mas no fim tudo deu certo. Uma boa experiência de ambiente desktop com KDE Plasma mais recente.
No servidor eu atualizei pro último Debian estável. Eu sempre espero um pouco pra fazer isso, até sair a correção .1 do release, e foi o que fiz no final. Mas um dos problemas que tive foram meus scripts em python. Muitos deles foram feitos há mais de 10 anos e estavam rodando felizes com python 2.7. O upgrade pra Debian bullseye acabou com essa alegria. Apenas python3 restou e muita coisa parou de funcionar. Posso dizer que até agora não encontrei tudo que quebrou após o upgrade, mas devagar estou corrigindo.
Então aproveitando o embalo eu decidi também fazer o upgrade do raspberrypi. Mesmo sendo raspbian, é Debian. E passei pro bullseye. Assim como o servidor, o upgrade em si foi bem tranquilo. Super suave.
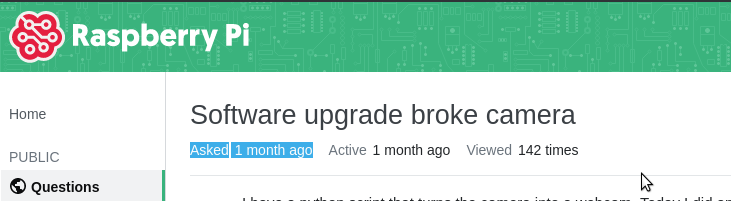
Então percebi que meu as fotos pararam de funcionar.
tl;dr: basicamente o antigo suporte ao picamera deixou de existir. Foi trocado pela libcamera, que não tem suporte em python ainda.
https://github.com/waveform80/picamera/issues/697
O que é possível fazer agora? Aliás o que eu fiz pra contornar isso? Bom... não ficou bonito, mas funciona. Chamei um dos programas que vem com o libcamera e salva fotos em jpeg usando subprocess.
class LibCameraInterface:
def __init__(self, sleep_time=30): None
def get_image(self, destination):
debug("LibCameraInterface.get_image()")
import subprocess
width, height = IMGSIZE
command = f"/usr/bin/libcamera-jpeg --width={width} --height={height} -o {destination}"
subprocess.call(command.split())
Eu aproveitei e dei uma boa refatorada no código. Ficou mais simples e pronto pra trocar. Criei duas classes, LibCameraInterface e CameraInterface. A ideia é voltar ao CameraInterface uma vez que tenha algum tipo de suporte em python. Por enquanto nem pygame funciona mais.
O resultado é quase o mesmo. Quase. Pelo libcamera as imagens ficaram mais escura durante a noite.
O antes:

O depois:

Ambas bem escuras. A segunda eu mudei um pouco a posição da câmera, mas mesmo pegando a iluminação dos prédios fica bem escura. E não achei ainda um jeito de melhorar isso.
Talvez um upgrade pra próxima versão.
UPDATE:
Eu tinha esquecido de postar o link do programa no github. Aqui está ele.
https://github.com/helioloureiro/snapshot-twitter/blob/master/weather-twitter.py
Update 2022-12-09: fui revisitar o artigo e percebi que não tinha colocado o link pro bug no github. Então adicionei.
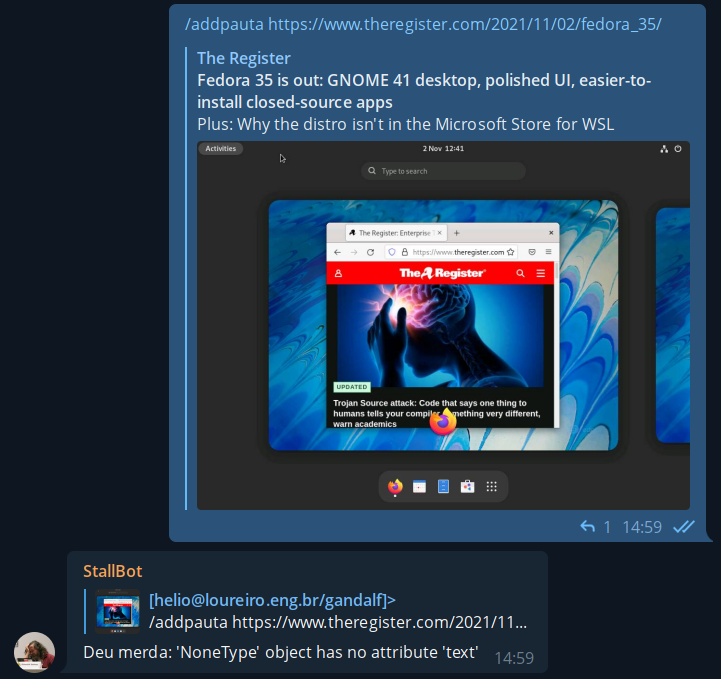
E foi assim que tudo começou. Com um singelo e modesto "deu merda". Primeiramente uma rápida introdução pra explicar o que isso significa: temos um bot pra adicionar assuntos nas pautas do canal Unix Load On. O bot roda em Python no raspberrypi3 que tenho aqui em casa. O mesmo que fica tirando fotos pela janela e mostra no twitter no perfil @helio_weather.
Então temos essa função "/addpauta" com um estilo de inglês a la Raimundos pra adicionar novos links. O programa no bot rodava um código com módulo requests pra pegar a página e buscar o título do artigo. Só isso. Então não era algo esperado pra ter o resultado "deu merda". Mas deu.
Olhando a mesma URL usando o ipython:
> ipython3
Python 3.9.7 (default, Sep 10 2021, 14:59:43)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.20.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import requests
In [2]: url = "https://www.theregister.com/2021/11/02/fedora_35/"
In [3]: r = requests.get(url)
In [4]: r.status_code
Out[4]: 103
In [5]: r.text
Out[5]: ''
então é isso. O webserver retorna 103, que é uma nova RFC, e espera que você continue pegando o conteúdo. Só que o módulo requests não faz isso.
Existe um bug aberto no github sobre esse problema onde eles relatam que o comportamento não é bem do requests, mas da urllib3, que é parte do core do Python. Traduzindo em miúdos: não tem solução e talvez façam uma correção no Python 3.10.
Atualizar todo o Python só pra corrigir um erro besta desses? Entra em cena o curl, que já comentei em usando curl pra monitorar um site. Não o curl propriamente dito, mas a pycurl. Tanto curl quanto pycurl passam dando tchauzinho por esse problema de manipular a resposta 103. E mandam aquele abraço pra urllib3.
Olhando via script:
> curl -s https://www.theregister.com/2021/11/02/fedora_35/ | head -10
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Fedora 35 released with GNOME 41 desktop • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2021/11/02/fedora35.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2021/11/02/fedora_35/" />
fazendo o mesmo em Python:
import pycurl
from io import BytesIO
def curl(url):
crl = pycurl.Curl()
crl.setopt(crl.URL, url)
b_obj = BytesIO()
crl.setopt(crl.WRITEDATA, b_obj)
crl.setopt(crl.FOLLOWLOCATION, True)
crl.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; rv:78.0) Gecko/20100101 Firefox/78.0')
crl.perform()
crl.close()
return b_obj.getvalue().decode('utf-8')
print(curl("https://www.theregister.com/2021/11/02/fedora_35/"))
então fica aqui a lição: onde a requests falhar, pycurl estará lá pra te salvar.

Hoje pode parecer que vou escrever sobre política, mas não vou. Talvez um pouco.
Durante os anos do governo Obama muita gente não percebeu até o Snowden jogar a coisa toda no ventilador, mas monitoração tinha virado algo comum. Sem mandado e até fora do país.
Pra celebrar esse grandioso acontecimento eu criei na época um programinha em python que ficava tirando foto de mim a partir da webcam do laptop. Qual a graça disso?
Eu já escrevi aqui sobre como usei esses screenshots pra fazer um vídeo bacana em usando python pra capturar a webcam. A ideia do programa batizado "obamawatcher.py" era a mesma.
Mas passado o frenesi da época, eu acabei esquecendo dele. Até que esses dias, funçando alguma outra coisa que não lembro, encontrei aqui encostado. E resolvi dar um peteleco nele e renovar tudo.
Então agora tem um script com repositório e tudo no github:
https://github.com/helioloureiro/obamawatcher
Claro que ainda tem muita coisa pra acertar, mas o que fiz foi manter o programa original, que usa pygame pra acessar a webcam, tirar a foto e pyinotify2 pra avisar você disso por mensagem no desktop, e adicionar a funcionalidade de ter na barra de tarefas do KDE. Sim, KDE. Segura esse choro. Utilizei PySide2 pra fazer em QT, então é KDE na veia. Não sei se funciona com Gnome e afins. Vou esperar um feedback. Mas por enquanto está funcionando no KDE e fica a cara do Obama lá te olhando na barra de tarefas. Quando vai bater a foto usa pynotify2 pra enviar uma mensagem pra você sorrir pra câmera.
Com o resultado é possível depois juntar as imagens e montar um gif animado como esse:

Quem olhar o código fonte vai notar que botei uma certa barreira de horário pra ele funcionar.
hour = int(time.strftime("%H", time.localtime()))
if hour < HOURSTART or hour > HOURSTOP:
print(f"Not a good time: {hour}")
continue
Isso é pra evitar pegar alguma foto sua com pouco ou nenhuma roupa, uma vez que os hábitos de home-office nos tornaram menos... sucetíveis a continuar vestidos.
Está ainda em desenvolvimento e devo ainda colocar algo como boilerplate pra ter ele ativado no autostart do KDE (e Gnome e ainda outros).
Divirta-se!


Não tem sido muito fácil manter o site atualizado com informações semanalmente como eu planejava, mas eu já esperava por isso. Ao menos tenho escrito com mais frequência que antes.
Um dos motivos é que tenho participados de organização de hackathons (como descrevi uma parte em Rodando desafios de uma hackathon com Python) e ontem foi para palestrar na BSD Day.
Eu não sabia muito bem sobre o que palestrar, então fiz relacionado à programação em Python, em como substituir o que poderia ser feito em shell script por Python. Foi um live coding, que está apresentado aqui. Boa diversão!
