No Brasil muita gente já está preparando pra pular carnaval, mesmo com pandemia, e eu aqui aparecendo só agora com uma análise de 2020. Era pra ter feito lá pro fim ou começo do ano? Com certeza. Mas quem sou eu pra conseguir manter um ritmo desses?
Então vamos ver os dados.
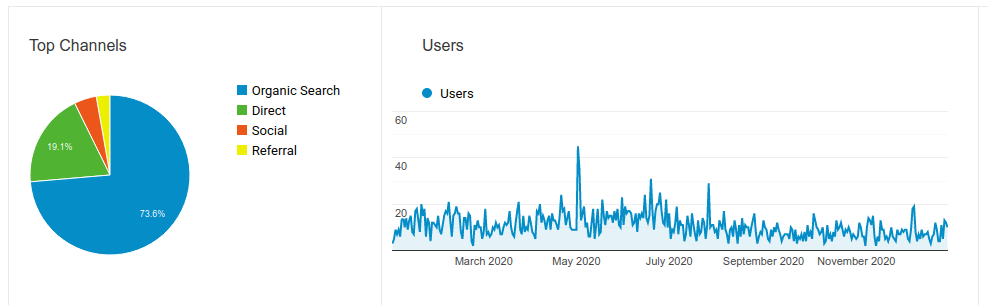
Esse foi o tráfego anual. Nada de muita novidade. Média de 10 pessoas acessando por dia. Algum repique em maio (o que fiz em maio?) mas nada assombroso. Quase 3/4 do tráfego vindo de... busca orgânica? Quase 20% de links diretos (imagino que posts no twitter e no telegram). É... não foi um ano muito bom em tráfego mas a culpa é toda minha. Fui bem negligente quanto ao conteúdo. Acho que postei 4 ou 5 artigos só durante 2020.
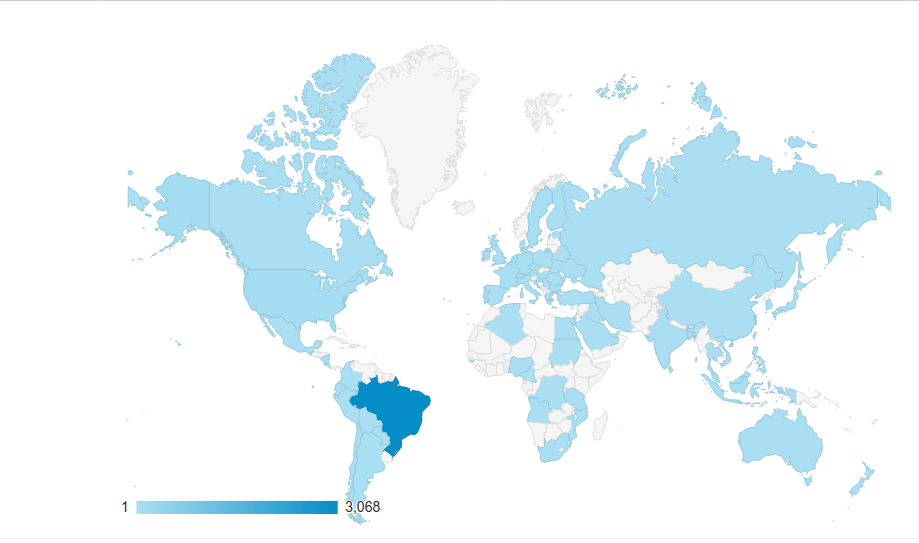
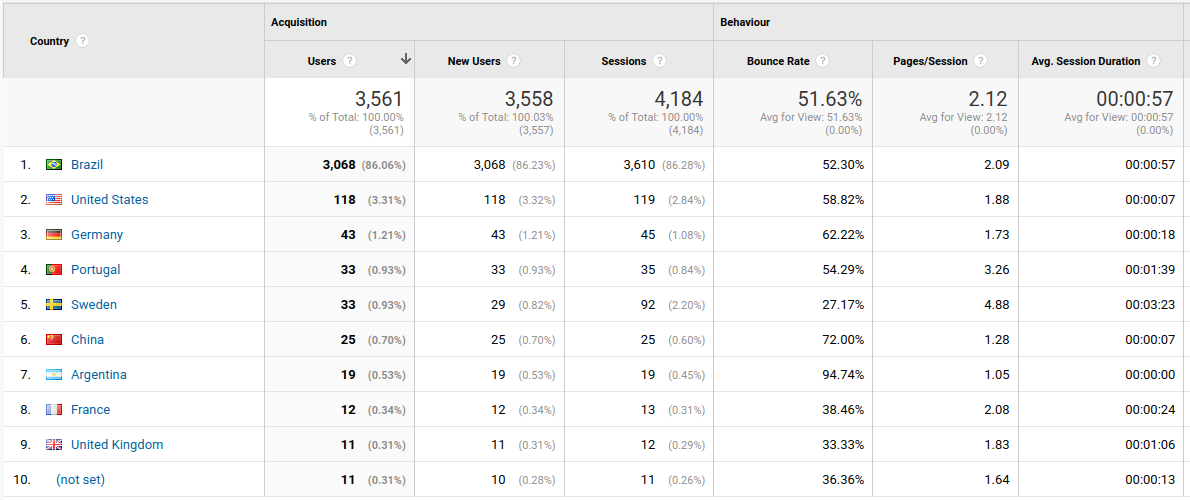
Dos países que acessaram, Brasil ganha de longe. Ainda bem pois o conteúdo é em geral na língua tupiniquim. Mas interessante ver outros países com China e França na métrica, mesmo que tenham sido só uns 20 acessos cada.
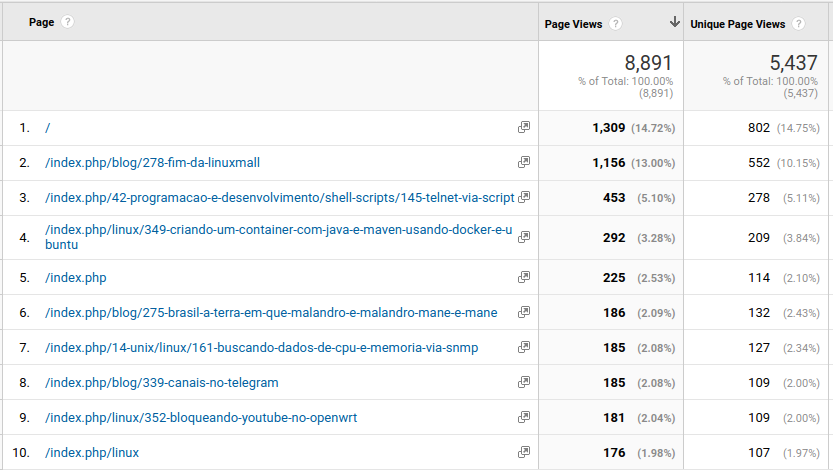
Esses são os links mais acessados. A página orgânica é a frente do site. Interessante ver o interesse no artigo sobre o final da Linux Mall, que deixou muitas saudades. E... telnet via script? não achei que isso tivesse tanto interesse.
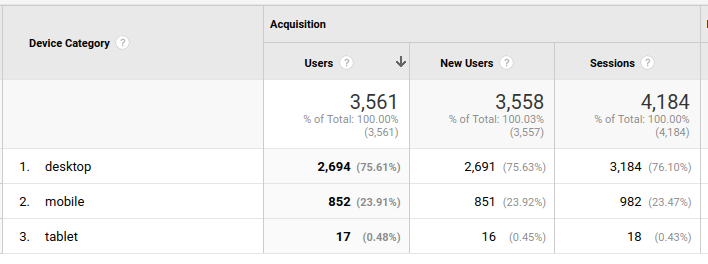
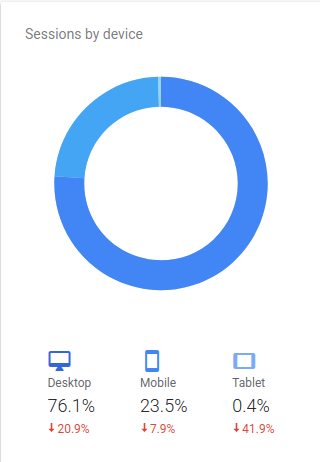
Maioria dos acessos vindo de desktops, com uma pequena parcela vindo de telefone. E alguns bem perdidos com tablet. Então toda a gritaria de avisos que o google manda sobre site não adaptado pra dispositivos móveis eu posso solenemente ignorar. Longa vida aos desktops!
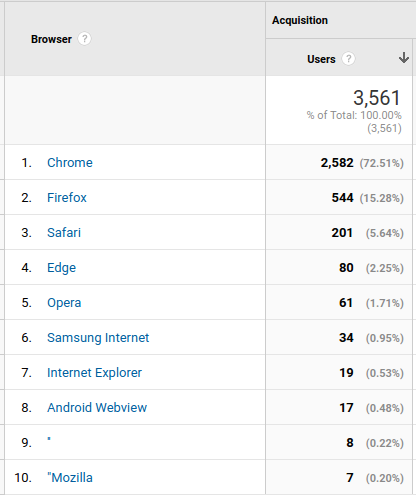
E na guerra dos navegadores, Chrome nadando de braçadas. Firefox atrás mas muito atrás. Ao menos não vejo mais as estatísticas com vários acessos de Internet Explorer, se bem que ainda apareceram 19.
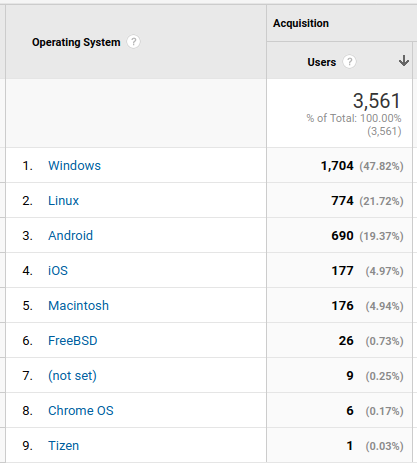
Em termos de sistemas operacionais... é... algumas coisas não mudam. Maioria dos acessos por Windows. Triste estatística. Interessante que tive 1 acesso de 1 Tizen.
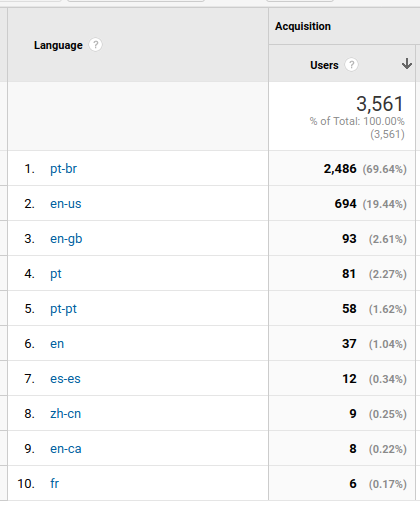
E a linguagem do navegador? Maioria de brasileiros. Interessante notar Tchéccia (nem sei como escreve em português, mas é a antiga República Tcheca).
E é isso. Não um posto longo, mas apenas pra guardar de lembrança e comparar com o próximo em 2022.
Se você tentou usar o pip, o gerenciador de módulos do python, nos últimos tempos então deve ter dado de cara com o seguinte erro:
/tmp > pip search conda
ERROR: Exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/cli/base_command.py", line 224, in _main
status = self.run(options, args)
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/commands/search.py", line 62, in run
pypi_hits = self.search(query, options)
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/commands/search.py", line 82, in search
hits = pypi.search({'name': query, 'summary': query}, 'or')
File "/usr/lib/python3.6/xmlrpc/client.py", line 1112, in __call__
return self.__send(self.__name, args)
File "/usr/lib/python3.6/xmlrpc/client.py", line 1452, in __request
verbose=self.__verbose
File "/usr/local/lib/python3.6/dist-packages/pip/_internal/network/xmlrpc.py", line 46, in request
return self.parse_response(response.raw)
File "/usr/lib/python3.6/xmlrpc/client.py", line 1342, in parse_response
return u.close()
File "/usr/lib/python3.6/xmlrpc/client.py", line 656, in close
raise Fault(**self._stack[0])
xmlrpc.client.Fault: <Fault -32500: "RuntimeError: PyPI's XMLRPC API has been temporarily disabled due to unmanageable load and will be deprecated in the near future. See https://status.python.org/ for more information.">
Olhando no link apontado pelo erro, temos uma bela mensagem de erro.
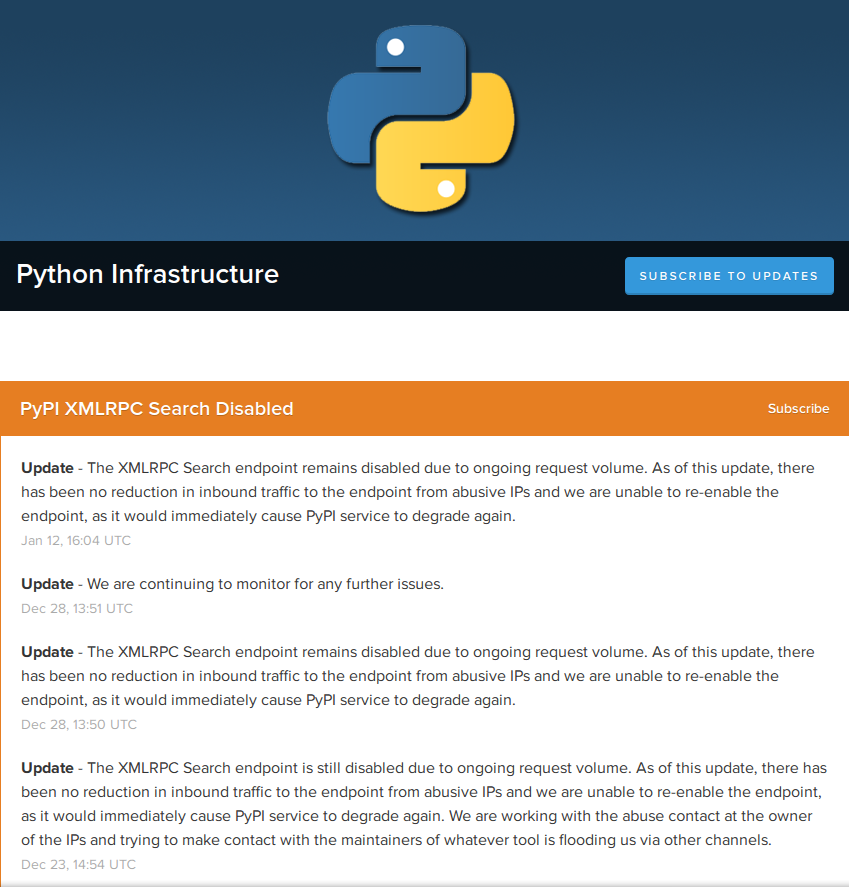
As mensagens no site são as seguintes:
Traduzindo em miúdos: o site não está aguentando o tráfego. Simples assim.
Não vou entrar no mérito de como o site foi feito, se com flash, django, ou o que quer que seja que esse não é o ponto. O ponto é que fizeram uma péssima arquitetura. Um único ponto de controle que não sustenta o tráfego.
Quantos anos existe o Debian Mais de 25 já. O Debian criou uma solução pra isso já faz mais de uma década: repositórios com mirrors e pacotes assinados. Ao rodar o comando apt ou apt-get, uma listagem dos arquivos disponíveis é verificada. Se a informação do arquivo for a mesma do arquivo local, não é baixado. Isso diminui em muito a carga em cima dos servidores.
Já os pacotes pip usam um formato xml que provavelmente é baixado toda vez. Não só isso: não existe um pip stable, unstable e testing. A cada nova pequena versão do pacote, um novo arquivo é gerado. Isso torna cache dessa list impossível de ser mantido por qualquer mirror. E é o mesmo problema que se encontra em npm, compose, etc.
O contraponto de ter esse arquivo sempre atualizado é ter as versões mais recentes dos pacotes, módulos ou classes que se esteja usando. Mas o custo é alto em termos de capacidade de rede pra aguentar esse tráfego. O resultado é esse que vemos com o pip.
Terá solução? Acredito que sim. Mas sem re-pensar na arquitetura do pip, como receber módulos novos e atualizações, vai ser apenas como enxugar gelo.
