
Meu novo queridinho de programação é um raspberrypi. Tenho feito coisas interessantes com ele usando Python. E em breve teremos a PyCon Sweden acontecendo por aqui. Então resolvi criar um robôzinho de twitter pra postar snapshots da apresentação. Pretendo colocar minha webcam externa nele (uso pros hangouts) e deixar ele pegando as imagens da conferência e postando.
No script a mensagem é estática, mas eu pretendo alterar para algo que pegue uma lista com horários, nomes e temas pra deixar tudo junto na postagem. Vai ficar interessante.
O código parcialmente feito, que veio o obamawatch, é esse aqui:
#! /usr/bin/python -u
# -*- coding: utf-8 -*-
"""
Based in:
http://stackoverflow.com/questions/15870619/python-webcam-http-streaming-and-image-capture
"""
SAVEDIR = "/tmp"
import pygame
import pygame.camera
import time
import sys
import os
import twitter
import ConfigParser
configuration = "/home/helio/.twitterc"
def TweetPhoto():
"""
"""
print "Pygame init"
pygame.init()
print "Camera init"
pygame.camera.init()
# you can get your camera resolution by command "uvcdynctrl -f"
cam = pygame.camera.Camera("/dev/video1", (1280, 720))
print "Camera start"
cam.start()
time.sleep(1)
print "Getting image"
image = cam.get_image()
time.sleep(1)
print "Camera stop"
cam.stop()
timestamp = time.strftime("%Y-%m-%d_%H%M%S", time.localtime())
year = time.strftime("%Y", time.localtime())
filename = "%s/%s.jpg" % (SAVEDIR, timestamp)
print "Saving file %s" % filename
pygame.image.save(image, filename)
cfg = ConfigParser.ConfigParser()
print "Reading configuration: %s" % configuration
if not os.path.exists(configuration):
print "Failed to find configuration file %s" % configuration
sys.exit(1)
cfg.read(configuration)
cons_key = cfg.get("TWITTER", "CONS_KEY")
cons_sec = cfg.get("TWITTER", "CONS_SEC")
acc_key = cfg.get("TWITTER", "ACC_KEY")
acc_sec = cfg.get("TWITTER", "ACC_SEC")
print "Autenticating in Twitter"
# App python-tweeter
# https://dev.twitter.com/apps/815176
tw = twitter.Api(
consumer_key = cons_key,
consumer_secret = cons_sec,
access_token_key = acc_key,
access_token_secret = acc_sec
)
print "Posting..."
tw.PostMedia(status = "Testing python twitter and PostMedia() for #pyconse timestamp=%s" % timestamp,
media = filename)
print "Removing media file %s" % filename
os.unlink(filename)
if __name__ == '__main__':
try:
TweetPhoto()
except KeyboardInterrupt:
sys.exit(0)
Acabei usando /dev/video1 pois estava testando a webcam no laptop, que já tem outra webcam interna e quando rebootei com a câmera externa, acabou jogando a dele pra esse device.
Outra melhoria que implementei foi a de mover os tokens de autenticação pra um arquivo externo e ler via ConfigParser(). Assim fica mais limpo o código e possível de enviar pro github (e sem mandar suas chaves privadas junto :).
![]() Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
Vou descrever aqui mais uma dica de uso que um processo ou ferramenta. Como faz vários anos que programo em python, em certo ponto achei razoável adicionar uma variável e parâmetro pra debug. Então todos meu programas em python em geral tem uma estrutura mais ou menos assim:
#! /usr/bin/python
def debug(msg):
print "DEBUG: %s" % msg
class MinhaClasse:
código
código
código
if __name__ == '__main__':
o = MinhaClasse()
o.main()
Então o que faço em geral é ter uma função debug(), mesmo que use classe e orientação à objetos, pra facilitar a chamada. Porque eu uso a função? Se eu usar como método dentro da classe, tem de chamar toda vez como self.debug(). Como não vejo muita vantagem nisso, prefiro definir sempre como função no topo do código.
Mas esse é um exemplo pra mostrar o princípio. O que uso é um pouco mais elaborado que isso. Vamos melhorar esse código pra entender melhor criando alguns métodos como __init__() e main().
#! /usr/bin/python
import getopt
DEBUG = False
def debug(msg):
if DEBUG:
print "DEBUG: %s" % msg
class MinhaClasse:
def __init__(self):
debug("Construtor da classe")
def fazalgo(self):
debug("Fazendo algo")
def main(self):
debug("Chamando main")
self.fazalgo()
if __name__ == '__main__':
try: opts, args = getopt.getopt(sys.argv[1:], "d") for opt, arg in opts: if opt == "-d": DEBUG = True debug("DEBUG ENABLED") except getopt.GetoptError: pass
if os.environ.has_key("DEBUG"): DEBUG = True
o = MinhaClasse()
o.main()
Primeiramente eu adicione algum tipo de verificação de opção. Pode ser com getopt como argparse. Como é uma opção simples, pra verificar o parâmetro "-d", de debug ativo, usei getopt. Em seguida usei uma variável global DEBUG, que fica como padrão em False, ou seja, desligado.
Quando faço a chamada na parte de baixo, onde __name__ é '__main__', verifico a opção via flag ou via variável de shell. Isso quer dizer que se eu usar o script de 2 formas, terei debug ativado:
> ./meuscript.py -d
ou
> env DEBUG=1 ./meuscript.py
a segunda forma ajuda no caso de ter um sistema mais complexo e um shell script chamar seu programa. Daí se vários scripts verificarem as variáveis de shell pra buscar por DEBUG (ou $DEBUG), fica fácil ativar/desativar.
E assim até hoje eu debugo meus programas. Claro que fiz alguns aperfeiçoamentos como uma função que imprime o nome do método que está rodando.
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
Assim, dentro de um método, posso usar debug da seguinte forma:
class MinhaClasse:
def __init__(self):
debug(__funcname__)
E isso ajuda ao imprimir o nome da função corrente, da mesma forma que se usa a macro__FUNCTION__ em C. Essa dica eu achei recentement no StackOverflow:
http://stackoverflow.com/questions/5067604/determine-function-name-from-within-that-function-without-using-traceback
E por último, e acabei com o tempo refinando meu debug(). Ao invés de de somente aceitar string, eu fiz um seletor de tipo pra imprimir qualquer variável, inclusive dicionários no formato json pra ficar mais fácil ler.
#! /usr/bin/python
import json
import getopt
DEBUG = False
def debug(msg):
""" Debug helper """
if DEBUG:
if type(msg) == type("abc"):
# it is ok
None
elif type(msg) == type({}):
msg = "%s" % json.dumps(msg, indent=4)
elif type(msg) == type([]):
msg = "[ %s ]" % ", ".join(msg)
msg = "DEBUG(%s): %s" % (__file__, msg)
print msg
syslog.syslog(syslog.LOG_DEBUG, msg)
def __funcname__(depth=0):
"""
To print function names like __func__ in C.
"""
return "__function__: " + sys._getframe(depth + 1).f_code.co_name + "()"
class MinhaClasse:
def __init__(self):
debug(__funcname__)
debug("Construtor da classe")
self.nome = "Helio"
self.sobrenome = "Loureiro"
debug("Nome: %s" % self.nome)
debug("Sobrenome: %s" % self.sobrenome)
self.dados = {}
def fazalgo(self):
debug(__funcname__)
debug("Fazendo algo")
for k, v in self.dados.items():
debug("%s => %s" % (k, v) )
def main(self):
debug(__funcname__)
self.dados = { "Nome" : self.nome,
"Sobrenome" : self.sobrenome }
debug(self.dados)
self.fazalgo()
if __name__ == '__main__':
try:
opts, args = getopt.getopt(sys.argv[1:], "d")
for opt, arg in opts:
if opt == "-d":
DEBUG = True
debug("DEBUG ENABLED")
except getopt.GetoptError:
pass
if os.environ.has_key("DEBUG"):
DEBUG = True
o = MinhaClasse()
o.main()
Como escrevi anteriormente, não é um padrão fazer isso. Existem módulos que ajudam a debuggar de forma até mais profunda. Eu gosto de escrever minhas mensagens de debug pra filtrar melhor as mensagens e poder ver o que realmente importa. Então fica aqui a dica.
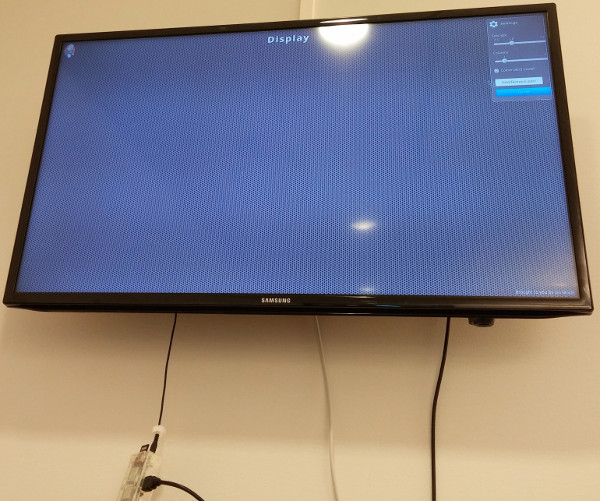
No nosso ambiente de desenvolvimento utilizamos Jenkins pra Continuous Integration, ou seja, a cada "commit" de código, compilar e testar a versão de uma forma automatizada. Cada um pode conectar no servidor Jenkins e visualizar o status do build, mas deixamos um display aberto para que todos possam ver como as coisas andam (e não deixar um release quebrado parado pra sempre).
Nada melhor que usar um raspberrypi pra essa atividade, já que é um dispositivo pequeno e com baixo consumo de energia. Aliás é o treco pendurando pra baixo da TV. O único incoveniente é que pra mostrar mais de um servidor Jenkins, as opções atuais são pra utilizar algum código javascript que faz com que a tela troque de URL.
Essas soluções funcionam muito bem em PCs x86_32 e x86_64, mas em um raspberrypi... as limitações de CPU são grandes. Como os browsers que suportam isso são chrome/chromium e firefox, o efeito indesejado é essa "lentidão" em renderizar a página, como mostra a imagem.
Outro problema é que seu um dos servidores Jenkins estiver fora do ar, esses javascripts "quebram", não fazendo a transição pra url seguinte.
Pra completar o problema, decidimos mudar de chromium pra epyphany, pois o mesmo usa muito menos memória que o chromium, e menos CPU. Mas nem tudo é perfeito: o epyphany não suporta script pra trocar entre várias URLs como o chrome.
Durante essas trocas browsers e experimentos, troquei umas mensagens com o Gustavo Noronha, vulgo Kov, que é um dos mantenedores do epyphany, perguntando sobre as possibilidades do mesmo. Ele disse que epyphany não suportava esse tipo de plugin, mas que eu poderia escrever minha própria aplicação em webkit. Então...

Demorou. Acho que trocamos essas mensagens, via twitter, lá pro meio de outubro. Já é quase Natal. Mas finalmente escrevi alguma coisa.
Comecei com um pequeno script baseado num código em C++ com Qt:
#include
#include
int main(int argc, char **argv){
QApplication app(argc, argv);
QWebView wv;
QWebPage *page = wv.page();
QWebSettings *settings = page->settings();
settings->setAttribute(QWebSettings::JavascriptEnabled, true);
settings->setAttribute(QWebSettings::PluginsEnabled, true);
wv.load(QUrl("http://www.youtube.com"));
wv.show();
return app.exec();
Acabei trocando o script simples pra uma classe em python, e usando threads. O que era simples ficou um pouco mais... vamos chamar de "refinado". Mas está funcionando. E com menos memória e CPU, que era o objetivo inicial.
Quem quiser dar uma brincada ou mesmo usar, o código está disponível no GitHub:

Como sempre acontece, foram publicados os vídeos do FISL15. Eu, como bom nerd, baixei todos eles usando wget.
wget -nH -np -r --mirror http://hemingway.softwarelivre.org/fisl15/high/
Eu comecei baixando sem a opção "--mirror", mas como são 18 GB de vídeos, não consegui terminar no mesmo dia. E pra não sobrescrever, acabei usando esse parâmetro pra baixar somente os vídeos faltantes ou que estavam pela metade.
No fim acabei com um diretório com vídeos como esses:
sala40t-high-201405071002.ogv
sala40t-high-201405071059.ogv
sala40t-high-201405071200.ogv
sala40t-high-201405071309.ogv
sala40t-high-201405071400.ogv
sala40t-high-201405071505.ogv
sala40t-high-201405071559.ogv
sala40t-high-201405071704.ogv
sala40t-high-201405081002.ogv
sala40t-high-201405081059.ogv
sala40t-high-201405081201.ogv
sala40t-high-201405081302.ogv
E agora? Quem é quem? Olhar um por um na grade palestras do FISL15?
Então novamente usei python pra salvar o dia. É um código bem simples que faz análise do HTML das grades, por dia, e cria um link do arquivo em outro diretório, TODOS, com formato "Título - Autor.ogv". Pra facilitar.
#! /usr/bin/python
# -*- coding: utf-8 -*-
"""
System to get titles and authors from FISL15 presentations,
and match them to video files, already downloaded.
To download all videos (18 GB):
wget -nH -np -r --mirror http://hemingway.softwarelivre.org/fisl15/high/
Presentations grid:
http://papers.softwarelivre.org/papers_ng/public/new_grid?day=9
LICENSE:
"THE BEER-WARE LICENSE" (Revision 42):
Helio Loureiro wrote this file. As long as you retain this notice you
can do whatever you want with this stuff. If we meet some day, and you think
this stuff is worth it, you can buy me a beer in return.
Helio Loureiro"
This email address is being protected from spambots. You need JavaScript enabled to view it.
"""
from BeautifulSoup import BeautifulSoup
import urllib2
import re
import os
import sys
URL="http://papers.softwarelivre.org/papers_ng/public/new_grid?day="
DAYS = [7, 8, 9, 10]
# My directory to find videos. Probably you need to fix it.
TARGETDIR = "%s/Videos/FISL15" % os.environ.get('HOME')
if not os.path.exists(TARGETDIR + "/TODOS"):
os.mkdir(TARGETDIR + "/TODOS")
for day in DAYS:
page = urllib2.urlopen("%s%d" %(URL, day))
soup = BeautifulSoup(page.read())
for html in soup.findAll('div', "slot-list"):
for d in html.findAll('div'):
a = d.find('div', "author")
t = d.find('div', "title")
l = d.find('a')
# if empty info, move on
if not a or not t or not l:
continue
# wordlist clean up
author = re.sub("\n", "", a.string)
author = re.sub(" ","", author)
title = re.sub("\n", "", t.string)
title = re.sub(" ", "", title)
title = re.sub("/", "", title) #avoiding directory issues
link = l.get('href')
# since wget kept the directory structure, it is easy
dirvideo = re.sub("http://hemingway.softwarelivre.org", TARGETDIR, link)
# is the video over there?
status = False
if os.path.exists(dirvideo):
status = True
# False here could trigger urllib2 to download video
print author, ",",
print title, ",",
print link, ",",
print status
if status:
videoname = "%s/TODOS/%s - %s.ogv" % (TARGETDIR, title, author)
if os.path.exists(videoname):
continue
try:
os.link(dirvideo, videoname)
except:
# Added this because titles w/ strings "/" where causing issues,
# so I had to check. GNU/Linux was the problem (Stallman's fault).
print "Failed to link %s to %s" % (dirvideo, videoname)
sys.exit(1)
print "Created: %s" % videoname
Em algum momento eu devo publicar o mesmo no GitHub. Sob a BWL.
Publiquei o código aqui: https://github.com/helioloureiro/FISL15_video_downloader-
Tá! Eu sei que tem um tracinho a mais ali no final do link, mas eu fiz errado e agora fica assim mesmo.

Pra agitar um pouco mais as coisas na empresa, e trazer um pouco de inovação no modo de pensar e trabalhar, preparei um coding dojo.
Os desafios, peguei de dojopuzzles.com, que é um .com mas o conteúdo é totalmente em português, mas nada que um google translator não resolvesse pra usar em inglês.
Faltava um contador e um semáforo pra ver o estado do código. Procurei pelos relógios/cronômetros de pomodoro, mas não achei um que realmente me agradasse. Existem várias soluções, mas muitas são pequenas demais pra apresentar numa tela projetada.
O semáforo, encontrei depois a solução do Danilo Bellini, o dose, que é escrito em python com wxwindows. É uma boa solução, mas ainda faltava o cronômetro.
Foi então que resolvi botar a mão na massa e criar meu próprio sistema. Usei PyQT pra desenhar a janela principal. Claro que não fiz tudo na mão: eu usei o qt4-designer pra agilizar tudo e deixar quase pronto, deixando o python pra somente pegar os valores e interagir o mínimo possível.

O sistema ainda precisa de umas melhorias, com certeza. Ele é burro ao ponto de ficar em loop rodando com python a cada 5s todo arquivo que estiver lá. Então eu preciso melhorar pra poder usar outras linguagens além de python. Nisso eu vi que a solução do Danilo é mais inteligente, pois usa um "watchdog()" pra verificar se houve mudança no arquivo antes de rodar. Então já inclui no "roadmap" tentar implementar isso. Também achei que faz falta um som ou alarme pra avisar do tempo. Vou ver se consigo incluir um do tipo do NBA, que vai tocando quando o tempo está acabando (a partir de 10s). Isso vai dar mais "visibilidade" durante os dojos.
Quem quiser participar, ou só dar uma olhada, o código está no github: codingdojocontrol
